






ShuffleNet
Channel Shuffle Operation
ShuffleNet网络主要创新点在于对于组卷积的重新设计。在传统设计中,网络结构主要受限于昂贵的poingwise卷积,这种
1
∗
1
1*1
1∗1的卷积核在计算量上耗费巨大,为了解决这种问题,以前的网络提出了组卷积(group conv)的方法实现稀疏卷积,这种方法在前面的ResNext中使用过,但这种方法也有副作用,即不同组的通道信息没有关联,如下图a所示。
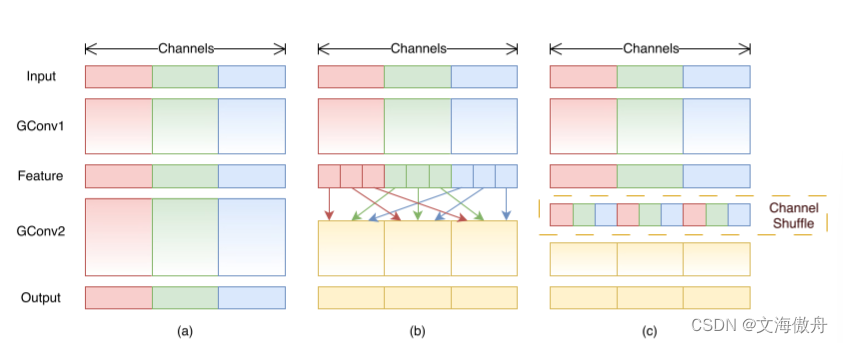
而如果通过(b)中的设计对每一个group进行再划分,使不同大group中的小组进行shuffle打乱,便可以实现每一个group中的信息连通。
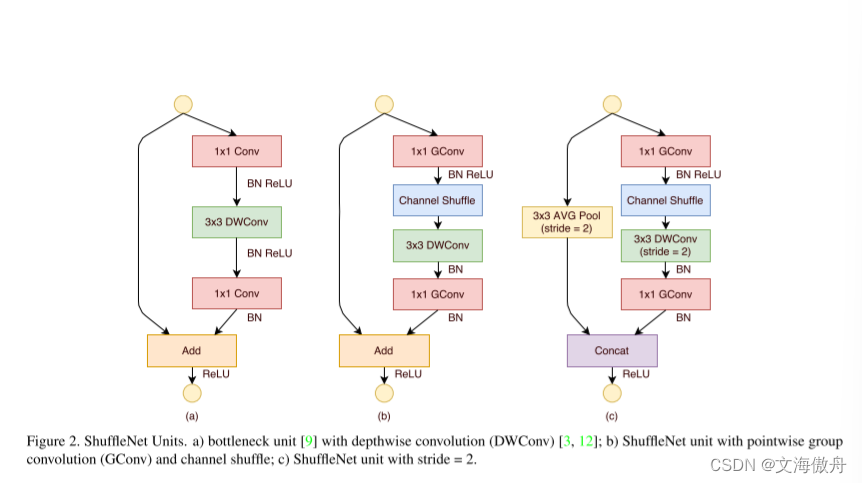
shuffleNet Unit
对于在分组卷积网络中加入channel shuffle模块,以下图中(a)为模板,可以在1*1卷积后加入channel shuffle操作,该模块对于图片尺寸等信息没有改变。
EfficientNet
网络思路
EfficientNet不同于传统网络设计,以ResNet为例,其通过模块设计增加网络深度来提高网络准确率。但实际中有多个因素可以影响网络准确率,例如深度、宽度和图片输入分辨率等。在投入更多计算资源时如何合理分配这些资源来增加深度、宽度等,以使网络在给定资源的条件下达到最高效率。
于是问题可以转变成一个最优化问题,即定义网络为
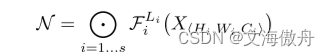
在初始配置为
d
e
p
t
h
=
α
,
w
i
d
t
h
=
β
,
r
e
s
o
l
u
t
i
o
n
=
γ
depth=\alpha, width=\beta, resolution=\gamma
depth=α,width=β,resolution=γ
通过提升提高资源配置使网络达到
d
e
p
t
h
=
α
θ
,
w
i
d
t
h
=
β
θ
,
r
e
s
o
l
u
t
i
o
n
=
γ
θ
depth=\alpha^{\theta}, width=\beta^{\theta},resolution=\gamma^{\theta}
depth=αθ,width=βθ,resolution=γθ
我们希望可以使
A
c
c
u
r
a
c
y
(
N
(
d
,
w
,
r
)
)
Accuracy(N(d,w,r))
Accuracy(N(d,w,r))达到最高,这其中的初始参数depth,width,resolution通过small grip search得到,而
θ
\theta
θ则是用户指定的系数。
网络结构
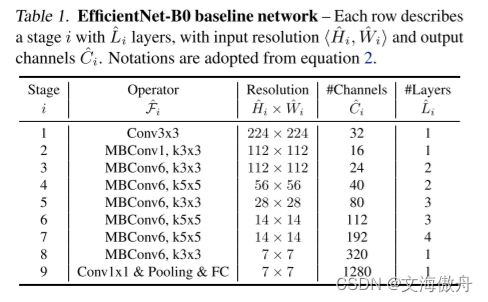
EfficientNet_bo
为了使网络在扩展中得到最好性能,我们想要设计一个基准网络,只有基准网络性能够好,其在扩展后的性能才能维持。基准网络结构如下:
Transformer中的multi-head self-attention
Scaled Dot-Product Attention
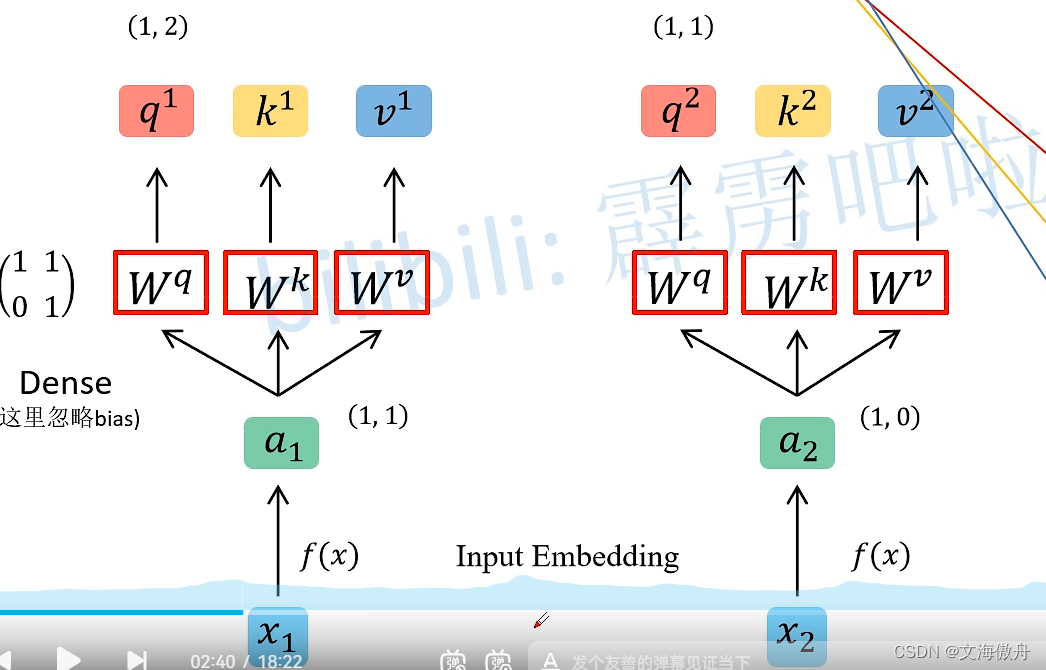
对于输入x进行input Embedding操作得到a,再将x和
W
q
,
W
k
,
W
v
W^{q},W^{k},W^{v}
Wq,Wk,Wv矩阵相乘得到对应q,k,v,这里的W矩阵可以通过学习得到。

之后通过注意力公式
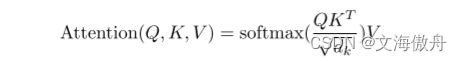
这里
Q
,
K
,
V
Q,K,V
Q,K,V是对应q,k,v组合起来的矩阵,通过计算可以对应b矩阵,这便是注意力机制的输出。
Multi-Head attention
Multi-Head attention在前面的基础上将其中的每一个q,k,v平分为两个部分,再用类似shuffleNet中的思想将取部分组成一个新的head
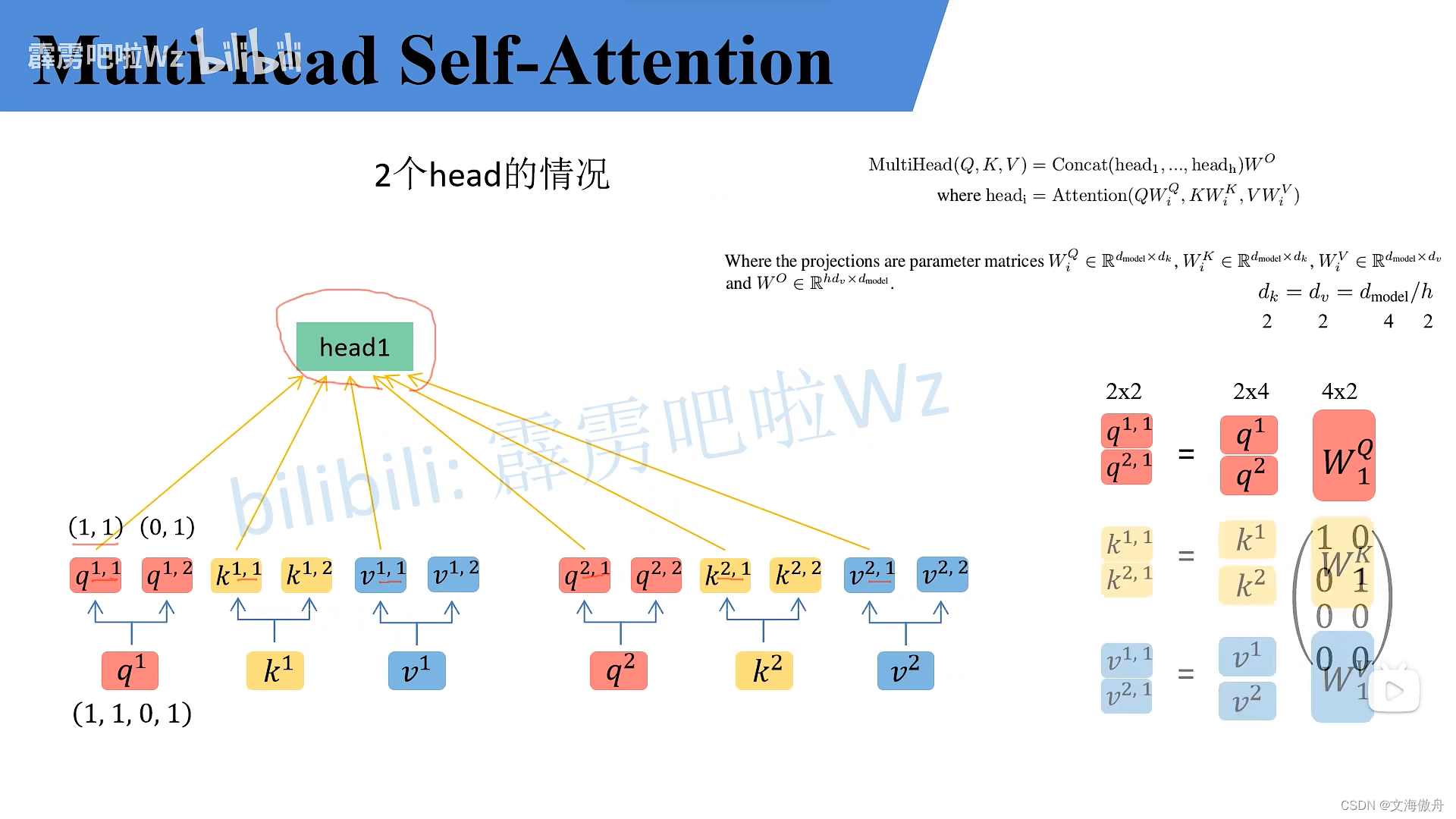
最后使用
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
2
)
W
O
w
h
e
r
e
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
MultiHead(Q,K,V)=Concat(head_1,...,head_2)W^{O} where head_i = Attention(QW^{Q}_i,KW^{K}_i,VW^{V}_i)
MultiHead(Q,K,V)=Concat(head1,...,head2)WOwhereheadi=Attention(QWiQ,KWiK,VWiV)进行拼接
代码练习
VGG猫狗游戏
迁移学习主要使用已有模型的参数进行训练自己的数据,一般需要自己修改最后几层全连接结构。以VGG16为例
model-vgg=torchvision.models.vgg16(pretrained=True)
model_vgg.classifier._modules['6']=torch.nn.Linear(4096,2)
model_vgg.classifier._modules['7']=torch.nn.LogSoftmax(dim=1)
最后训练结果为

ART艺术鉴赏
通过ResNet18进行迁移学习
model=torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad=False
model.fc=torch.nn.Linear(model.fc.in_features,49)
model.to(device)
其余模块基本不变。在训练了3轮之后,最后准确率达到62.5

本周问题
在最后的艺术鉴赏问题中,本地自己运行的代码训练集最终可以达到90的准确率,但测试集的结果最终上传平台只有40多的准确率,不知道是不是过拟合的原因。















 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









