






前言
先在train.py文件和test.py文件中,加入下面的代码,防止出 OMP: Error #15 这个错
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"1. 生成完整的配置文件和工作目录
1.1 终端运行下面的代码
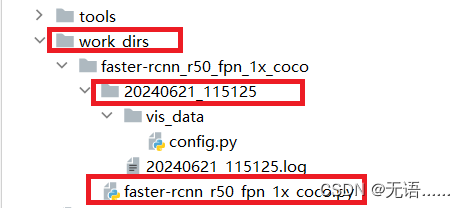
python ./tools/train.py ./configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py会报错,但会生成work_dirs文件夹(2024年6月21日11点51分25秒运行的,生成了文件夹)
work_dirs 文件夹里的 faster-rcnn_r50_fpn_1x_coco.py 就是完整的配置文件,改代码在这个文件里改,不要去改 configs 文件夹里的文件
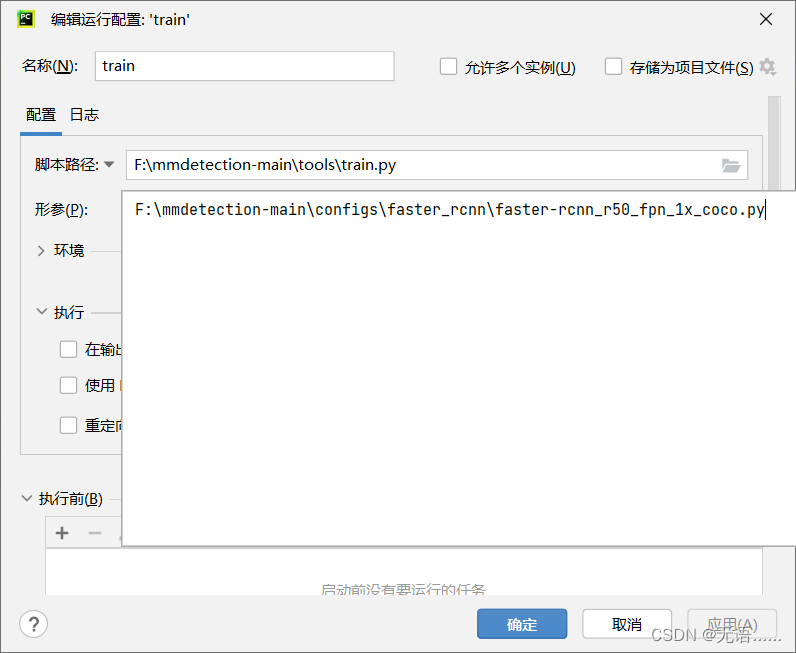
1.2 运行配置运行
报错,不知道为啥,错误里的那个文件也有,就是报错 而且也没有生成具体运行时间的文件夹

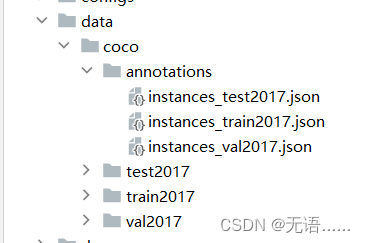
2. 添加数据集
3. 训练自定义数据集需要改的地方
1. 在 mmdetection-main\mmdet\datasets\coco.py 文件中
将原来的coco数据集的类别和调色板注释掉换成自定义数据集的类别和调色板
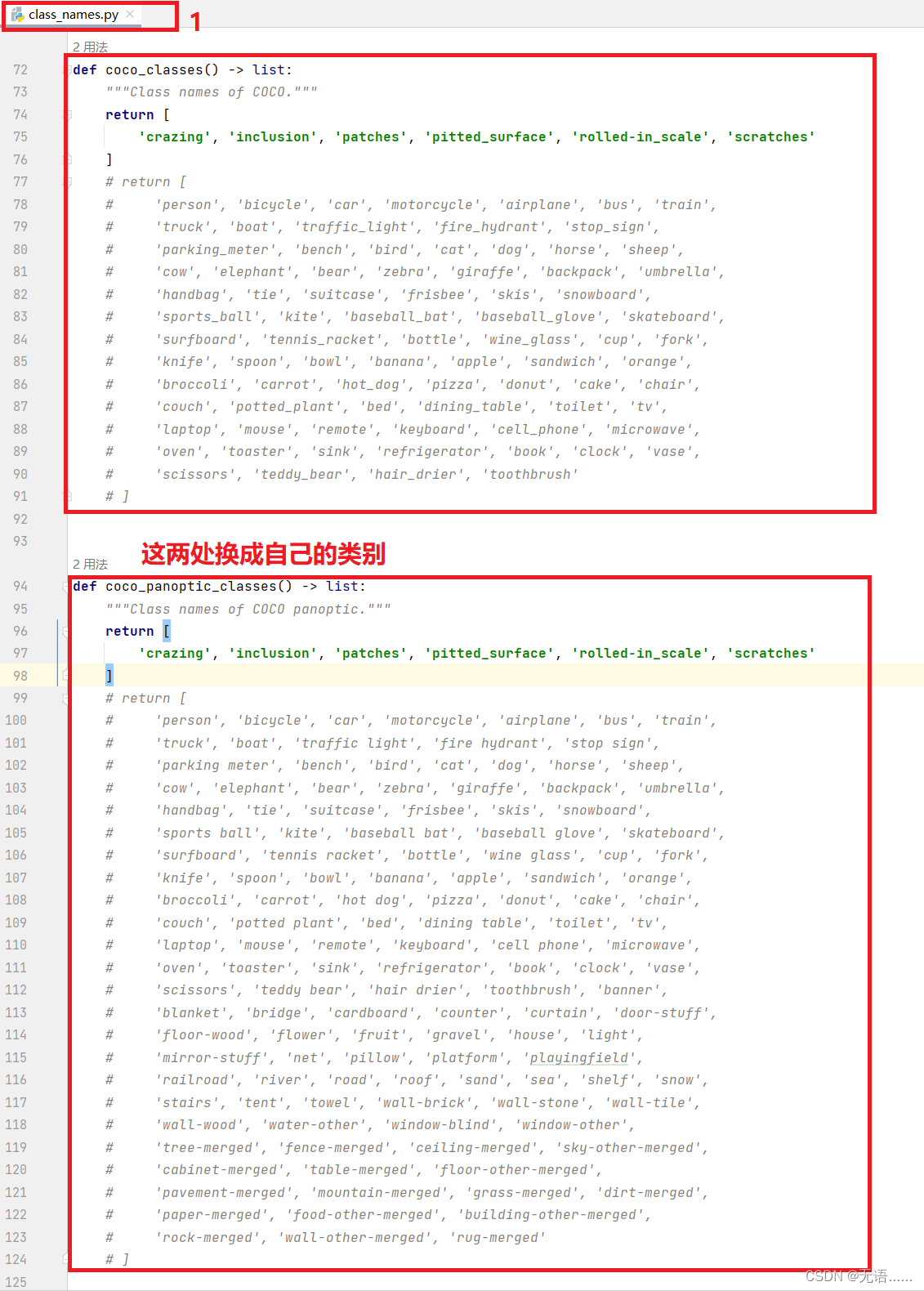
2. 在 mmdetection-main\mmdet\evaluation\functional\class_names.py 文件中
将原来的coco数据集的类别注释掉换成自定义数据集的类别,注意有两处
3. 本文的data文件夹布局和coco数据集的布局一样,只是将图片和标注文件的内容换成了自定义数据集的
所以配置文件(上面的 mmdetection-main\work_dirs\faster-rcnn_r50_fpn_1x_coco\
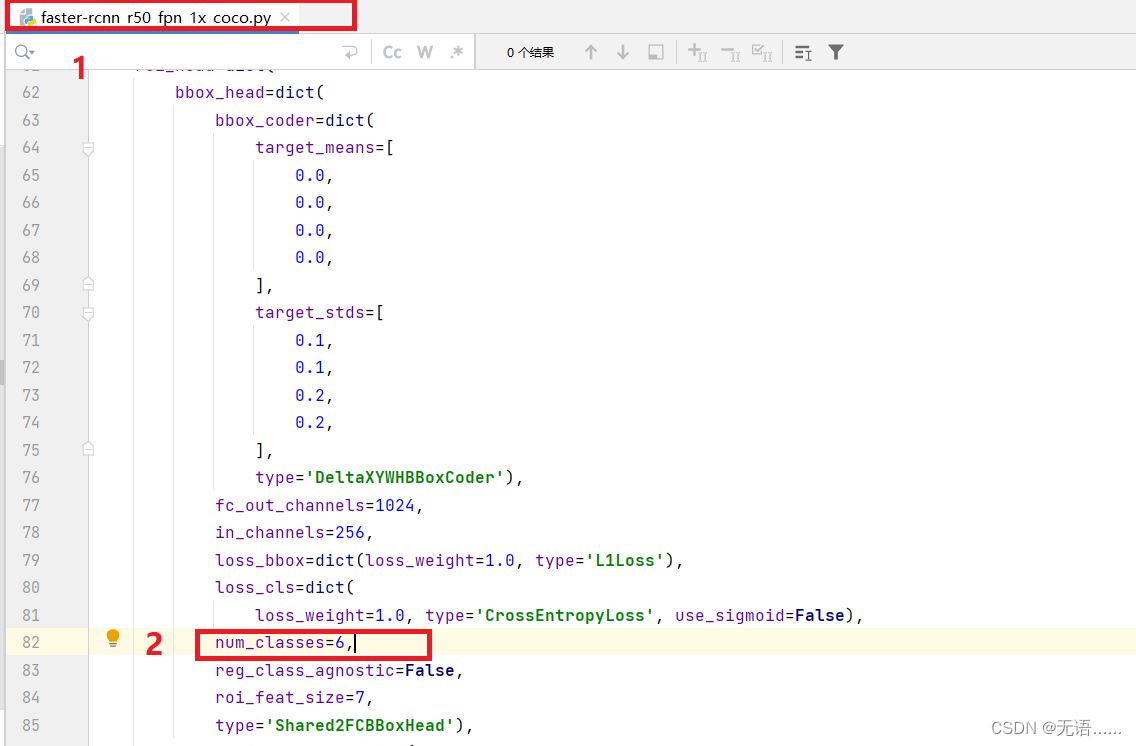
faster-rcnn_r50_fpn_1x_coco.py 文件)中的训练集测试集验证集路径都不需要改,只要改 num_classes
coco数据集有 80 个类别,我的自定义数据集有 6 类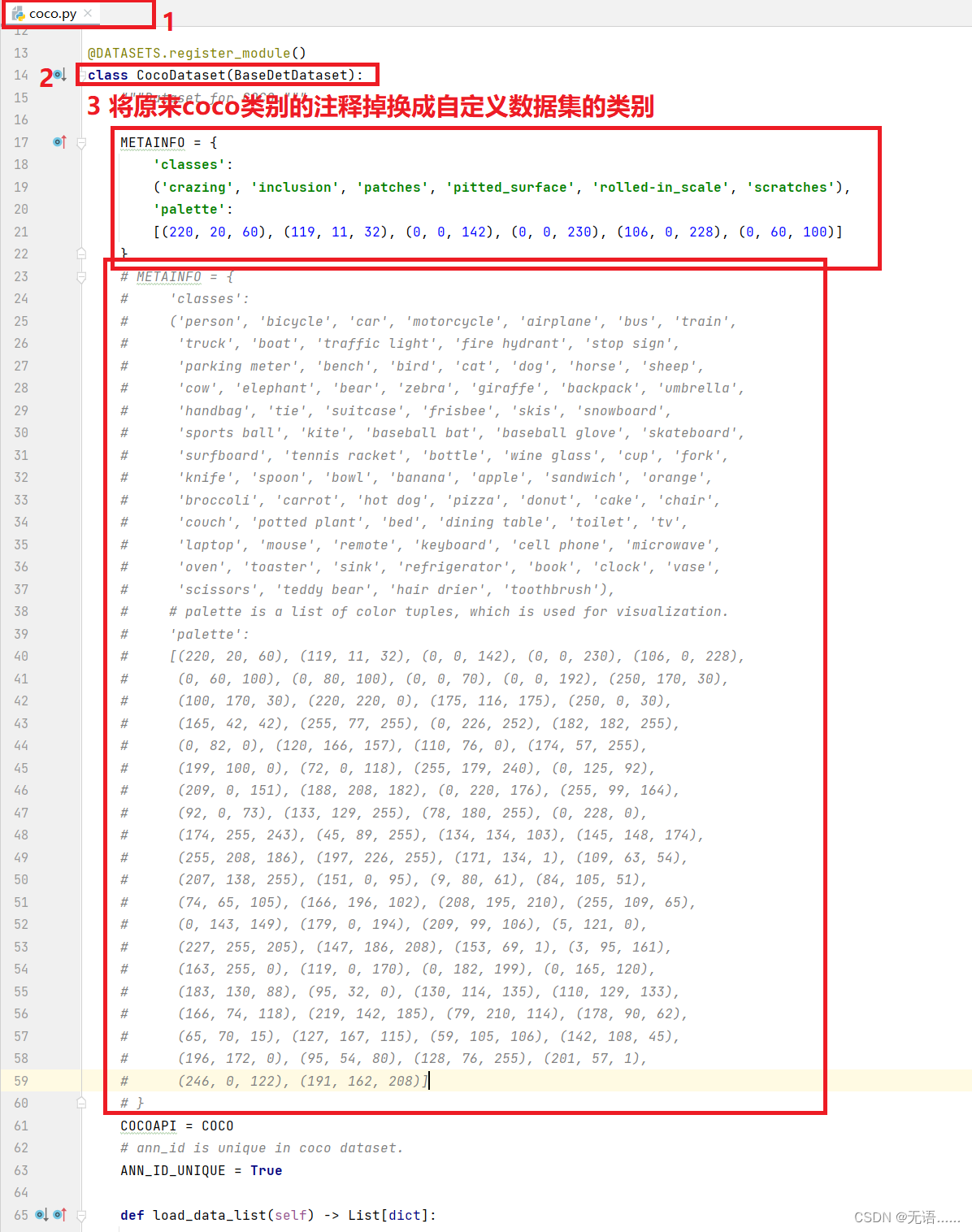
4. 训练
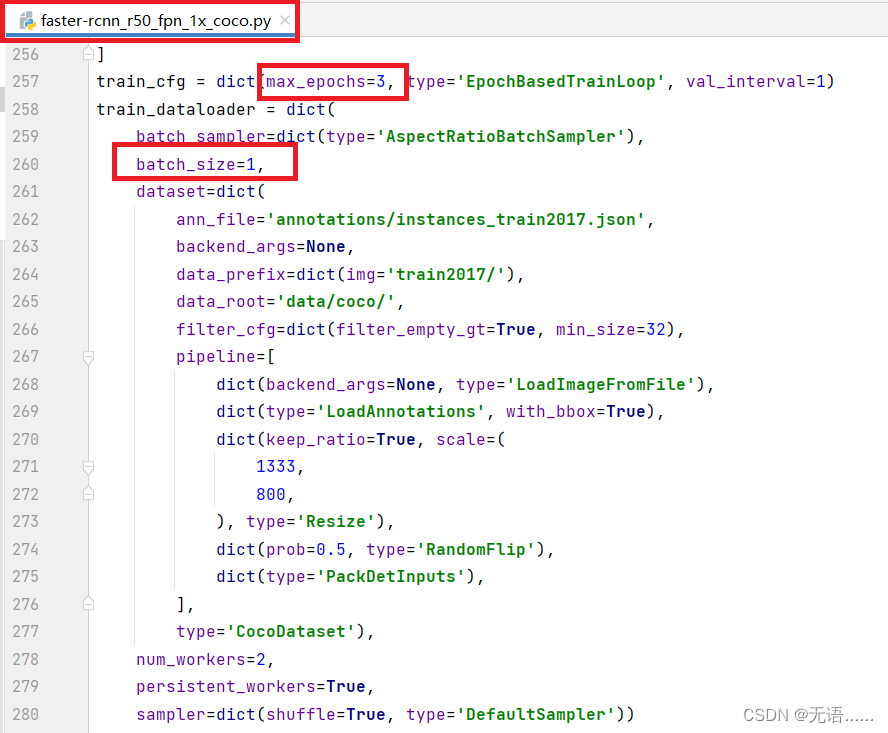
python .\tools\train.py .\work_dirs\faster-rcnn_r50_fpn_1x_coco\faster-rcnn_r50_fpn_1x_coco.py因为我电脑配置低,所以改一下配置将训练时的设置 epoch=3,batch_size=1,
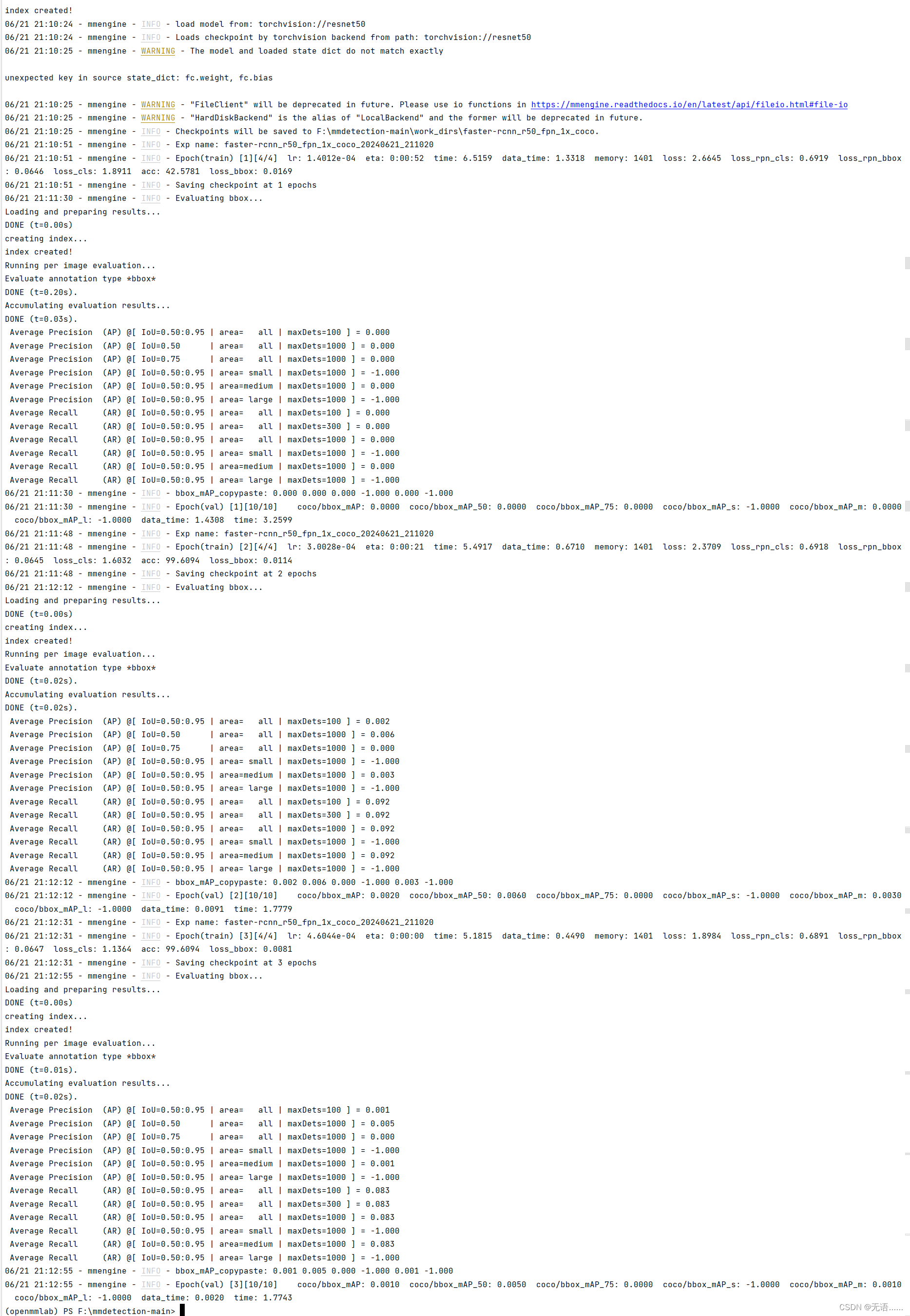
训练结果如下图
5. 测试
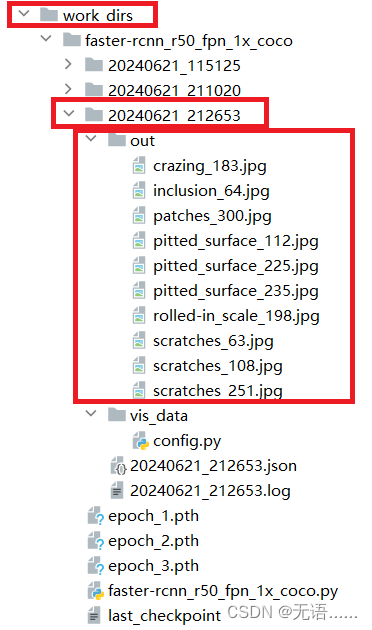
python .\tools\test.py .\work_dirs\faster-rcnn_r50_fpn_1x_coco\faster-rcnn_r50_fpn_1x_coco.py .\work_dirs\faster-rcnn_r50_fpn_1x_coco\epoch_3.pth --show-dir out

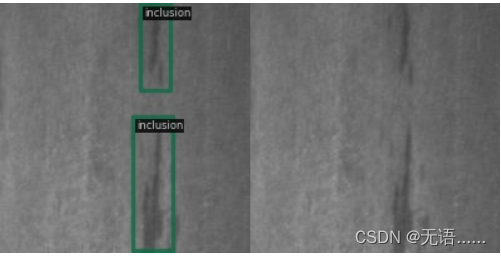
测试结果保存在 out 文件夹里
参考文档:MMDetection新手安装使用教程(无限踩坑)_mmdetection安装-CSDN博客
mmdetection自定义数据集训练_mmdetection训练自己的数据-CSDN博客
2024年6月21日,于笔记本电脑上















 4271
4271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









