







上篇文章只是给出了DPM模型的一个案例,本篇文章就来详细介绍一下DPM模型参数设置的意义。
当打开Discrete Phase模型时,会弹出下图的窗口,我们来逐项分析选项的设置意义。

1.Interaction
表示双向耦合,即连续相和离散相之间的相互影响。
耦合VS非耦合
非耦合:当不勾选Interaction选项,DPM颗粒的唯一用途是用于后处理,通过后处理中的粒子轨迹能够看到流场的变化。颗粒可以受到传热传质的影响,但相应的变化(如蒸发液滴的蒸汽)不会影响溶液的流动。

耦合:当勾选Interaction选项,颗粒会影响流体的流动,如当曳力作用于粒子时,存在的动量交换会改变流体的流动,这些影响作为DPM SOURCE传递到连续相。一般情况下,如果我们考虑粒子受力情况,我们的工况都应该是考虑到双向耦合的。

2.Particle Treatment
表示颗粒追踪方式,有稳态和非稳态之分。
稳态VS非稳态
稳态:如果不勾选Unsteady Particle Tracking,则表示稳态追踪,则在粒子释放后,将对其进行跟踪,直到它根据边界类型(指文章十六中的Escape、Trap边界),到达其最终目的才会停止追踪。在稳态追踪下,如果粒子无法到达这些边界,那么就会停留在其中,计算会不完全。
后处理中显示Particle Residence Time(粒子停留时间),同时控制面板显示number tracked = 146, escaped = 146。
以文章16中的案例为例,我们使用的就是稳态追踪,Wall边界设置为Reflect、Outlet边界设置为Escape,表示粒子遇到Wall会反弹,只有遇到Outlet才会从流场中流出。计算结果显示,最大的粒子停留时间达到了725s;number tracked = 146, escaped = 142, incomplete = 4,共146个粒子,有4个没有流出。

非稳态:如果勾选Unsteady Particle Tracking,表示非稳态追踪,则将按一定的时间步长对每个粒子进行追踪,而不一定到达指定边界,计算达到时间步长之后,则更新连续相。应当指出,Unsteady Particle Tracking和连续相的稳态非稳态无关。
3.Tracking
参数Max.Number of Steps
可能会有同学有疑问,不是说粒子不遇到特定边界类型就会一直追踪吗?上面的例子有4个粒子没有从流出中流出,为什么还是停止计算了呢?
这是因为我们在DPM模型设置指定了Max.Number of Steps,表示计算次数,类似于稳态计算中的迭代次数。如果在此之前所有粒子逸出,那么停止追踪。如果粒子一直不逸出,达到最大计算次数,仍然会停止追踪粒子。

我们将这个数值由50000改成500后,粒子最大停留时间变为了11.4s;number tracked = 146, escaped = 130, incomplete = 16,有16个粒子没有逸出。
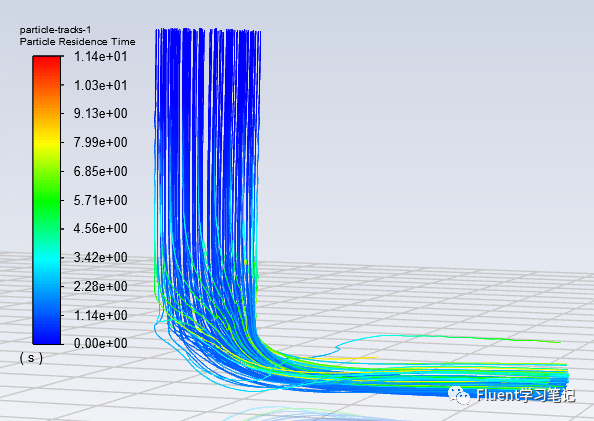
将Max.Number of Steps仍然等于50000,如果将Wall边界设置为Trap、Outlet边界设置仍为Escape时,结果显示最大的粒子停留时间为7.68s;number tracked = 146, escaped = 115, trapped = 31,从Outlet流出115,被壁面捕获31。

总结来说,就是稳态时,要么所有粒子完全到达指定边界,要么计算达到Max.Number of Steps设置的最大值,这两种情况下对于粒子的追踪才会停止。
参数Specify length scale:输入公式中的L,控制积分时间步长的参数,L与积分时间步长成正比,相当于粒子再次求解其运动方程和更新其轨迹之前的移动距离。显然其值越小颗粒运动越精确。

参数Step length factor:输入λ,λ与积分时间步长成反比,等于通过当前连续相位控制体积所需的时间步长数。其值越大,颗粒运动。

4.Physical Models
表示DPM模型中,可以对颗粒考虑力和其他的作用,如碰撞、破裂等。

从上到下依次为:
Thermophoretic Force:热泳力
Saffnan Lift Force:萨夫曼升力
Virtual Mass Force:虚拟质量力
Pressure Gradient Force:压力梯度力
Erosion / Accretion:侵蚀/积聚
DEM Collision:DEM碰撞
Stochastic Collision:随机碰撞
Breakup:颗粒破裂
5.UDF
可以通过UDF的方式对颗粒所受到的体积力、DPM源项及时间步长等进行指定。同样也可以通过求解输运方程的方式对DPM模型进行求解。
需要指出,DPM模型的UDF和普通的UDF形式上不太相同,DEFINE宏中间一般包含DPM关键字。如DEFINE_DPM_BC、DEFINE_DPM_BODY_FORCE

6.Numerics
控制粒子跟踪的数值方案以及热量和质量方程
如Tracking Options用来控制求解方程的误差,其中Accuracy Control允许在指定公差内求解运动方程。
Coupled Heat-Mass Solution表示热质耦合,使用耦合ODE解算器,对液滴、燃烧或多组分粒子进行容错控制,从而实现相应方程的求解。

7.Parallel
用于控制对离散相模型的并行处理,包含控制并行执行离散阶段计算的计算节点的参数。包含三种方法,分别为Message Passing(信息传递),Shared Memory(分享内存)和Hybrid(前两种方法的混合)。关于并行计算,由于2020版本的Fluent不再有串行的概念,因此掌握并行计算的概念很有必要,尤其对并行UDF而言。
8.总结
对于DPM模型,第6点和第7点一般保持默认即可,不必更改。物理模型的选择和UDF的使用可能较多。下次我们详细介绍一下Injection的设置中可能存在的一些问题
以上案例的cas和dat文件均可以免费获取,需要的朋友,只需要点赞关注收藏一键三连后私信我即可哦















 2376
2376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









