









目录
说明:本篇文章主要借鉴于抖音恩培大佬的代码,大佬的github地址为:enpeizhao (enpei) (github.com)
感兴趣的朋友也可以关注大佬的抖音号!
技术要点:
-
脸部姿态估计识别与检测
-
帧率检测
-
目标物体三个角度x、y、z估计
主要应用:
-
家庭应用:检测孩子是否在看电视,看了多久,距离多远,保护孩子用眼安全
-
驾驶监督应用:检测司机是否有疲劳驾驶风险(可以从脸部姿态做进一步估计)
-
自动驾驶:利用单目RGB图像进行深度距离估计,避免了使用激光雷达等高成本的距离估计
-
人脸识别:轻量化的人脸识别应用,后期可以将此功能引用于嵌入式设备,实现轻量化应用
画面展示:
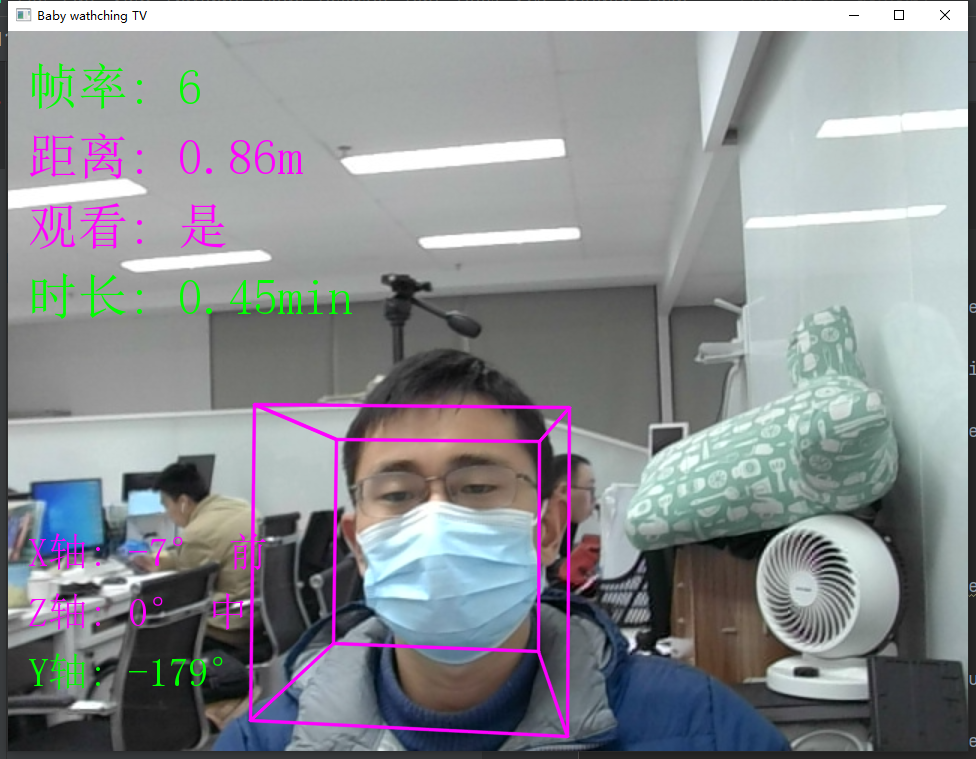
准备工作:
硬件准备:
win10系统, RGB摄像头
软件准备:
python3.7, Pycham(vs code或其他编译器)
构建环境:
conda create -n tv python=3.7tv表示要创建环境的名字,我这里用“tv”来代替环境名字
激活环境:
conda activate tv需要安装库:
conda install dlib
pip install opencv-contrib-python权重文件下载:
https://github.com/enpeizhao/CVprojects/releases/tag/Models
(恩培大佬github下载地址)
开始预测:
全部指令代码参数配置如下:
python demo.py --命令=参数 -h, --help 显示帮助
--mode MODE 运行模式:collect,train,distance,run对应:采集、训练、评估距离、主程序
--label_id LABEL_ID 采集照片标签id.
--img_count IMG_COUNT
采集照片数量
--img_interval IMG_INTERVAL
采集照片间隔时间
--display DISPLAY 显示模式,取值1-5
--w W 画面宽度
--h H 画面高度这个小项目里边使用的是较为简单的opencv内置人脸识别算法,缺点就是精度可能有限,整体过程需要执行下面三个步骤:
1.采集图片
python demo.py --mode='collect' --label_id=1 --img_count=2 --img_interval=2
python demo.py --mode='collect' --label_id={人脸ID} --img_count={该ID采集照片数量,一般1-3张即可} --img_interval={照片采集间隔(秒)};
2.修改标签文件
在目录./face_mode/label.txt下的label文件,里边的每行代表一个人,如1,**表示label_id=1的人脸叫**;
3.训练模型
执行python demo.py --mode='train'训练人脸识别模型,模型是对应的./face_model/model.yml权值文件!
4.启动主程序
python demo.py --mode='run' --w={宽度} --{高度} --display={显示模式},display取值对应:
1:人脸框(人脸检测,识别label中有的人脸)
2:68个人脸关键点(关键点检测)
3:人脸梯形框框(三维深度估计)
4:人脸方向指针(主要就是利用角度的识别)
5:人脸三维坐标系(三维坐标系)
全部代码:
"""
借鉴恩培大佬源码!
主要功能:检测孩子是否在看电视,看了多久,距离多远
使用技术点:人脸检测、人脸识别(采集照片、训练、识别)、姿态估计
"""
import cv2, time
from pose_estimator import PoseEstimator
import numpy as np
import dlib
from utils import Utils
import os
from argparse import ArgumentParser
class MonitorBabay:
def __init__(self):
# 人脸检测
self.face_detector = dlib.get_frontal_face_detector()
# 人脸识别模型:pip uninstall opencv-python,pip install opencv-contrib-python
self.face_model = cv2.face.LBPHFaceRecognizer_create()
# 人脸68个关键点
self.landmark_predictor = dlib.shape_predictor("./assets/shape_predictor_68_face_landmarks.dat")
# 站在1.5M远处,左眼最左边距离右眼最右边的像素距离(请使用getEyePixelDist方法校准,然后修改这里的值)
self.eyeBaseDistance = 65
# pose_estimator.show_3d_model()
self.utils = Utils()
# 采集照片用于训练
# 参数
# label_index: label的索引
# save_interval:隔几秒存储照片
# save_num:存储总量
def collectFacesFromCamera(self,label_index,save_interval,save_num):
cap = cv2.VideoCapture(0)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
fpsTime = time.time()
last_save_time = fpsTime
saved_num = 0
while True:
_, frame = cap.read()
frame = cv2.flip(frame,1)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = self.face_detector(gray)
for face in faces:
if saved_num < save_num:
if (time.time() - last_save_time) > save_interval:
self.utils.save_face(face,frame,label_index)
saved_num +=1
last_save_time = time.time()
print('label_index:{index},成功采集第{num}张照片'.format(index = label_index,num = saved_num))
else:
print('照片采集完毕!')
exit()
self.utils.draw_face_box(face,frame,'','','')
cTime = time.time()
fps_text = 1/(cTime-fpsTime)
fpsTime = cTime
frame = self.utils.cv2AddChineseText(frame, "帧率: " + str(int(fps_text)), (10, 30), textColor=(0, 255, 0), textSize=50)
frame = cv2.resize(frame, (int(width)//2, int(height)//2) )
cv2.imshow('Collect data', frame)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
# 训练人脸模型
def train(self):
print('训练开始!')
label_list,img_list = self.utils.getFacesLabels()
self.face_model.train(img_list, label_list)
self.face_model.save("./face_model/model.yml")
print('训练完毕!')
# 获取两个眼角像素距离
def getEyePixelDist(self):
cap = cv2.VideoCapture(0)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
# 姿态估计
self.pose_estimator = PoseEstimator(img_size=(height, width))
fpsTime = time.time()
while True:
_, frame = cap.read()
frame = cv2.flip(frame,1)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = self.face_detector(gray)
pixel_dist = 0
for face in faces:
# 关键点
landmarks = self.landmark_predictor(gray, face)
image_points = self.pose_estimator.get_image_points(landmarks)
left_x = int(image_points[36][0])
left_y = int(image_points[36][1])
right_x = int(image_points[45][0])
right_y = int(image_points[45][1])
pixel_dist = abs(right_x-left_x)
cv2.circle(frame, (left_x, left_y), 8, (255, 0, 255), -1)
cv2.circle(frame, (right_x, right_y), 8, (255, 0, 255), -1)
# 人脸框
frame = self.utils.draw_face_box(face,frame,'','','')
cTime = time.time()
fps_text = 1/(cTime-fpsTime)
fpsTime = cTime
frame = self.utils.cv2AddChineseText(frame, "帧率: " + str(int(fps_text)), (20, 30), textColor=(0, 255, 0), textSize=50)
frame = self.utils.cv2AddChineseText(frame, "像素距离: " + str(int(pixel_dist)), (20, 100), textColor=(0, 255, 0), textSize=50)
# frame = cv2.resize(frame, (int(width)//2, int(height)//2) )
cv2.imshow('Baby wathching TV', frame)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
# 运行主程序
def run(self,w,h,display):
model_path = "./face_model/model.yml"
if not os.path.exists(model_path):
print('人脸识别模型文件不存在,请先采集训练')
exit()
label_zh = self.utils.loadLablZh()
self.face_model.read(model_path)
cap = cv2.VideoCapture(0)
width = w
height = h
print(width,height)
# 姿态估计
self.pose_estimator = PoseEstimator(img_size=(height, width))
fpsTime = time.time()
zh_name = ''
x_label = ''
z_label = ''
is_watch = ''
angles = [0, 0, 0]
person_distance = 0
watch_start_time = fpsTime
watch_duration = 0
# fps = 12
# videoWriter = cv2.VideoWriter('./record_video/out'+str(time.time())+'.mp4', cv2.VideoWriter_fourcc(*'H264'), fps, (width,height))
while True:
_, frame = cap.read()
frame = cv2.resize(frame,(width,height))
frame = cv2.flip(frame,1)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = self.face_detector(gray)
for face in faces:
x1,y1,x2,y2 = self.utils.getFaceXY(face)
face_img = gray[y1:y2,x1:x2]
try:
# 人脸识别
idx, confidence = self.face_model.predict(face_img)
zh_name = label_zh[str(idx)]
except cv2.error:
print('cv2.error')
# 关键点
landmarks = self.landmark_predictor(gray, face)
# 计算旋转矢量
rotation_vector, translation_vector = self.pose_estimator.solve_pose_by_68_points(landmarks)
# 计算距离
person_distance = round(self.pose_estimator.get_distance(self.eyeBaseDistance),2)
# 计算角度
rmat, jac = cv2.Rodrigues(rotation_vector)
angles, mtxR, mtxQ, Qx, Qy, Qz = cv2.RQDecomp3x3(rmat)
if angles[1] < -15:
x_label = '左'
elif angles[1] > 15:
x_label = '右'
else:
x_label = '前'
if angles[0] < -15:
z_label = "下"
elif angles[0] > 15:
z_label = "上"
else:
z_label = "中"
is_watch = '是' if( x_label =='前' and z_label == '中') else '否'
if is_watch == '是':
now = time.time()
watch_duration += ( now - watch_start_time)
watch_start_time= time.time()
if display == 1:
# 人脸框
frame = self.utils.draw_face_box(face,frame,zh_name,is_watch,person_distance)
if display == 2:
# 68个关键点
self.utils.draw_face_points(landmarks,frame)
if display == 3:
# 梯形方向
self.pose_estimator.draw_annotation_box(
frame, rotation_vector, translation_vector,is_watch)
if display == 4:
# 指针
self.pose_estimator.draw_pointer(frame, rotation_vector, translation_vector)
if display == 5:
# 三维坐标系
self.pose_estimator.draw_axes(frame, rotation_vector, translation_vector)
# 仅测试单人
break
cTime = time.time()
fps_text = 1/(cTime-fpsTime)
fpsTime = cTime
frame = self.utils.cv2AddChineseText(frame, "帧率: " + str(int(fps_text)), (20, 30), textColor=(0, 255, 0), textSize=50)
color = (255, 0, 255) if person_distance <=1 else (0, 255, 0)
frame = self.utils.cv2AddChineseText(frame, "距离: " + str(person_distance ) +"m", (20, 100), textColor=color, textSize=50)
color = (255, 0, 255) if is_watch =='是' else (0, 255, 0)
frame = self.utils.cv2AddChineseText(frame, "观看: " + str(is_watch ), (20, 170), textColor=color, textSize=50)
#
duration_str = str(round((watch_duration/60),2)) +"min"
frame = self.utils.cv2AddChineseText(frame, "时长: " + duration_str, (20, 240), textColor= (0, 255, 0), textSize=50)
color = (255, 0, 255) if x_label =='前' else (0, 255, 0)
frame = self.utils.cv2AddChineseText(frame, "X轴: {degree}° {x_label} ".format(x_label=str(x_label ),degree = str(int(angles[1]))) , (20, height-220), textColor=color, textSize=40)
color = (255, 0, 255) if z_label =='中' else (0, 255, 0)
frame = self.utils.cv2AddChineseText(frame, "Z轴: {degree}° {z_label}".format(z_label=str(z_label ),degree = str(int(angles[0]))) , (20, height-160), textColor=color, textSize=40)
frame = self.utils.cv2AddChineseText(frame, "Y轴: {degree}°".format(degree = str(int(angles[2]) )),(20, height-100), textColor=(0, 255, 0), textSize=40)
# videoWriter.write(frame)
# frame = cv2.resize(frame, (int(width)//2, int(height)//2) )
cv2.imshow('Baby wathching TV', frame)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
m = MonitorBabay()
# 参数设置
parser = ArgumentParser()
parser.add_argument("--mode", type=str, default='run',
help="运行模式:collect,train,distance,run对应:采集、训练、评估距离、主程序")
parser.add_argument("--label_id", type=int, default=1,
help="采集照片标签id.")
parser.add_argument("--img_count", type=int, default=3,
help="采集照片数量")
parser.add_argument("--img_interval", type=int, default=3,
help="采集照片间隔时间")
parser.add_argument("--display", type=int, default=1,
help="显示模式,取值1-5")
parser.add_argument("--w", type=int, default=960,
help="画面宽度")
parser.add_argument("--h", type=int, default=720,
help="画面高度")
args = parser.parse_args()
mode = args.mode
if mode == 'collect':
print("即将采集照片.")
if args.label_id and args.img_count and args.img_interval:
m.collectFacesFromCamera(args.label_id,args.img_interval,args.img_count)
if mode == 'train':
m.train()
if mode == 'distance':
m.getEyePixelDist()
if mode == 'run':
m.run(args.w,args.h,args.display)END~
















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











