






导语:F1是Google的分布式数据库,问世以来一直受到大家的关注。其中分布式查询引擎怎么实现,也一直是数据库界最关心的问题之一。F1团队在VLDB2018上发表了论文详细论述该话题。本文是对该问题的详细剖析,十分值得架构师和数据库从业人员学习。
F1 是起源于 Google AdWords 的分布式 SQL 查询引擎,跟底下的 Spanner 分布式存储搭配,开启了分布式关系数据库——所谓 NewSQL 的时代。我们今天说的是 F1 团队在 VLDB2018 上发的文章 F1 Query: Declarative Querying at Scale [1],它和之前我们说的 F1 几乎是两个东西。
F1 Query 是一个分布式的 SQL 执行引擎,现在大数据领域流行的 Presto、Spark SQL、Hive 等等,都可以算在这个范畴里。类似地,F1 Query 也支持对各种不同数据源的查询,既可以是传统的关系表、也可以是 Parquet 这样的半结构化数据。
这样一来,不同数据格式的壁垒也被打破了:你可以在一个系统里完成对不同数据源的 Join,无论数据以什么形式存放在哪里。商业上管这个叫 Federated Query 或者 DataLake,几家云计算巨头都有类似的产品。
那 F1 Query 的贡献在哪里呢?
F1 Query 定义了三种不同类型的查询执行模式,根据查询的数据量大小或执行时间,将用户查询划分成:
单机执行(Centralized Execution)
分布式执行(Distributed Execution)
批处理执行(Batch Execution)
前两个是交互式的,即客户端会等待结果返回。最后一个批处理更像是 ETL:客户端输入任务之后就不再管了,查询结果会被写到指定的地方。
单机执行
单机执行对应我们熟悉的 OLTP 查询,例如单表点查、带索引的 Join 等。这类查询本身已经足够简单,只需几毫秒就能做完,处理它们的最好方式就是在收到请求的机器上立即执行。
在 F1 Query 系统中有 F1 Server 和 F1 Worker 等角色。F1 Server 负责接收客户端请求,如果它判断这个查询应当使用单机而不是分布式方式执行,它就亲力亲为、直接执行并返回结果。
这样的行为和绝大多数单机 OLTP 数据库是一致的,例如 MySQL 采用的是 Thread Pool + Dispatcher 的处理模型,Thread Pool 的规模是一定的,Dispatcher 根据高低优先级分派执行任务。最终一个请求只会被一个线程处理,换句话说,对某个查询来说其执行过程是单线程的。
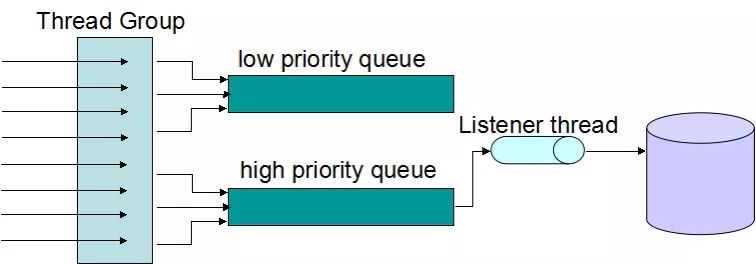
▲ MySQL 的线程池处理模型,一般存在多个 Thread Group,图中描绘了一个 Thread Group
F1 Query 单机查询的执行器同样也是教科书式的 Valcano 模型,但也无可厚非——对 OLTP 来说这已经足够好。如下图所示,从顶层算子开始递归地调用 GetNext(),每次取出一行数据,直到没有更多数据为止。各个算子只需要实现 GetNext() 接口即可,简单清晰。
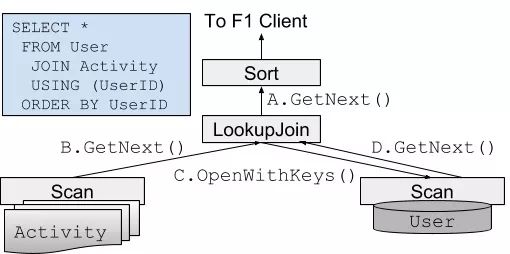
分布式执行
F1 Query 对更复杂的查询,例如没有索引的 Join 或聚合等,则采取分布式查询的方式。大部分 OLAP 查询、尤其是 Ad-hoc 的查询都落在这一分类中。这种情况下,分布式导致的网络、调度等 Overhead 已经远小于查询本身的成本;而且随着数据量的增加,单节点内存显然不够用了。
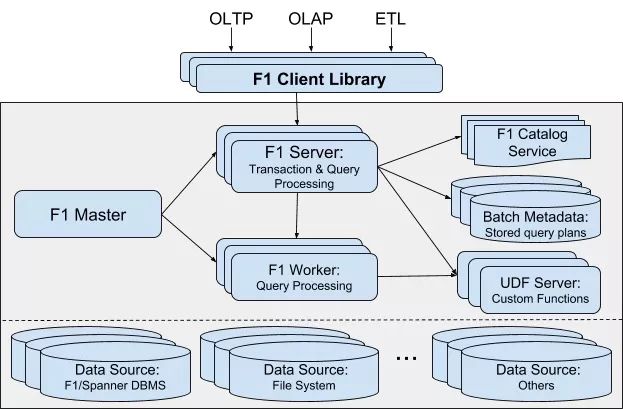
▲ *F1 Query 的系统架构,主要包含 F1 Master、F1 Server、F1 Worker 三个角色,其他 Catalog、UDF Server、Batch Metadata 用于存储查询相关的 Metadata 等*
这时,上图中的 F1 Worker 就派上用场了。F1 Server 此时仅仅作为协调者存在,将任务分配给多个 Worker,直到 Worker 的任务全都完成,再把结果汇总发给客户端。
这个模式眼熟吗?你可能会想到 Greenplum 这类的数据仓库,已经很接近了。最相似的我认为是 Presto。Presto 是 Facebook 开发的一套分布式 SQL 引擎,如果单单只看 F1 Query 的分布式查询,和 Presto 大同小异。
与单机执行不同的是,分布式查询中的算子可以有多个实例(Instance)并行执行,每个实例负责其中一部分数据。在 F1 Query 里这样一个数据分片被称为 Fragment,在 Spark SQL 里叫 Partition,在 Presto 里叫 Split。
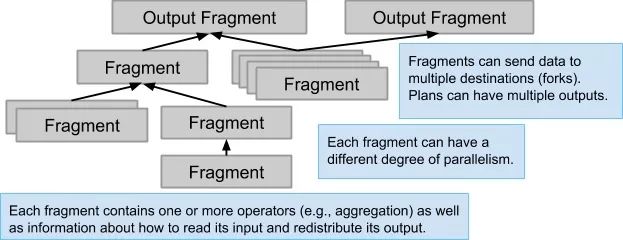
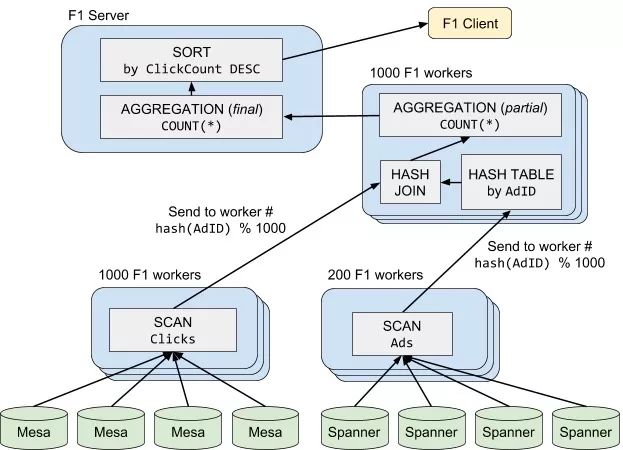
下面的例子是一个 Join-Aggregation-Sort 的查询,它分成了 4 个阶段:
Scan(Clicks)被分配给 1000 个 F1 Worker 上并行拉取数据,并根据每一行数据的Hash(AdID)发送给对应的HashJoin分片,即一般说的 shuffle 过程;Scan(Ads)被分配给 200 个 F1 Worker 上并行拉取数据,并且也以同样的方式做 shuffle;HashJoin及PartialAggregation:根据 Join Key 分成了 1000 个并行任务,各自做 Join 计算,并做一次聚合;最后,F1 Server 把各个分片的聚合结果再汇总起来,返回给客户端。
Presto 具有的缺陷,F1 Query 分布式查询同样也有,比如:
纯内存的计算方式,无法利用磁盘的存储空间,某些查询可能面临内存不足;
没有 Fault-tolerance,对于一个涉及上千台 Worker 的查询,任何一台的重启都会导致查询失败。
批处理执行
F1 Query 还有个独特的批处理执行,这个模式定位于更大的数据量、更久的查询时间;另一方面,它的结果不再是返回给客户端,而是将查询结果写到指定的地方,例如 Colossus(第二代 GFS)上。
上一节我们提道,Presto 的模式没有 Fault-tolerance,这对于长时间运行的批处理任务是致命的,查询失败的概率会大大增加。批处理查询首先要解决的就是 Fault-tolerance 问题:必须能以某种方式从 Worker 节点的失败中恢复。
解决这个问题有两条路可走:一是 MapReduce 的模式,将计算分成若干个阶段(Stage),而中间结果持久化到 HDFS 这样的分布式文件系统上;二是 Spark RDD 模式,通过记录祖先(Lineage)信息,万一发生节点失败,就通过简单的重算来恢复丢失的数据分片,这样数据就可以放在内存里不用落盘。
Spark 的做法显然是更先进的,原因有很多,这里只说最重要的 2 条。欲知详情可以看我之前的博客文章《一文读懂 Apache Spark》[2]。
Spark 的计算基本在内存中,只有当内存不够时才会溢出到磁盘,而 MR 的中间结果必须写入外部文件系统;
Spark 可以把执行计划 DAG 中相互不依赖的 Stage 并行执行,而 MR 只能线性地一个接一个 Stage 执行。
但是出乎意料的是,F1 Query 采用的是前者,也就是 MR 模式。这其中的原因我们不得而知,我猜想和 Google 自家的 FlumeJava 不够给力有关系。
如下图。左边的 Physical Plan 和上一节的分布式查询是一样的,不同之处是在批处理模式下,它被转换成一系列的 MR 任务,之后交给调度器(Scheduler)去处理即可。
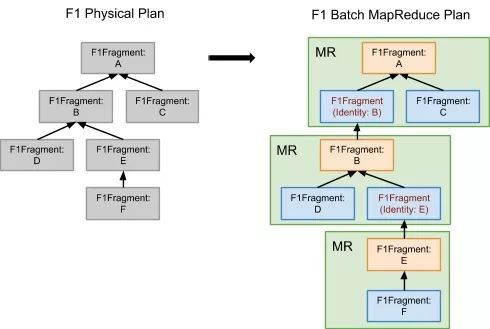
相比分布式执行,批处理模式下各个步骤都会持久化到外部文件系统(因为 MapReduce 的特性所致)。不仅如此,Pipeline 式的执行也没法进行。以上一节提到的 HashJoin 为例,左边 Clicks 的 Scan 和 HashJoin 原本是可以 Pipeline 执行的,但是在批处理模式下,必须等到 Scan(Clicks) 这个阶段完成才能进行下一步的 HashJoin 阶段。
单机并行执行
除了上面聊的 F1 Query 所支持的 3 种查询模式之外,事实上还有一种处理模型位于单线程执行和分布式执行之间:单机的并行执行。初看这似乎与分布式执行很相似,但又有些不同:
不用考虑单个 Worker 的失败恢复,因为它们都在同一个进程里;
各个 Worker 线程的内存是共享的,它们之间交换数据无需考虑网络通讯代价。
这种模式在传统的关系型数据库上很常见,尤其是 Postgres、SQL Server 这类以 OLAP 查询见长的选手。以 Postgres 为例,在开启并行查询的情况下,查询优化器会根据代价选择是否生成并行执行计划;如果生成了并行执行计划,执行器会调度多个 Worker 一起完成工作。
下图是一个 Postgres 上并行 Hash Join 的例子,从执行计划上看和上一节几乎一样,但是这里不再需要对数据做 Shuffle:Hash Join 所用的 Hash Table 本身是全局共享的。
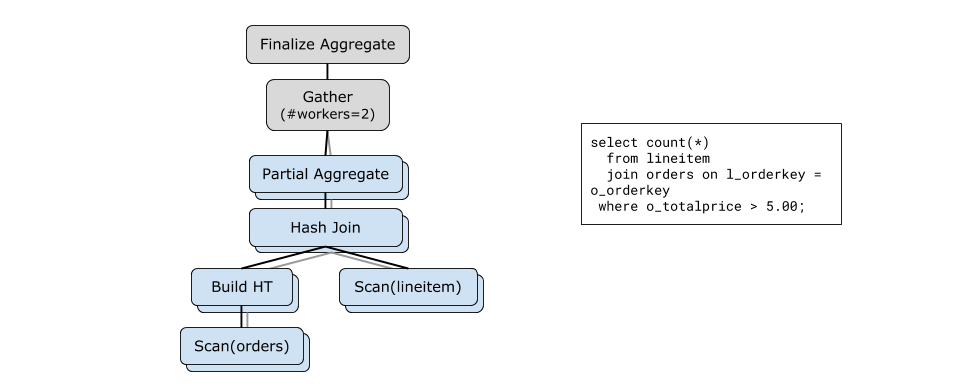
Parallel Hash Join 并非只有这一种做法。SQL Server 就更接近分布式执行的方案:把 Hash Key 相同的数据 shuffle 到同一个分片上——但这个 shuffle 只是逻辑上的,不需要真的做 IO。
相比分布式查询,单机并行的最大优势在于响应速度更快,因为省去了大量的网络 IO 时间,而且调度一个 Worker 线程要比调度一个 Worker 机器快得多。
但别忘了,单机运算能力的 scale up 成本非常高,并且是存在上限的。对于 Google 之类的互联网公司,绝大部分查询都超出了单机的存储或计算能力,我猜测这也是 F1 Query 并未考虑单机并行的理由。
对 F1 Query 的评价
从论文描述的情况来看,F1 Query 还不算个完善、成熟的系统,其定位更像是一个解决业务需求的胶水系统,而非 Spanner 这样的“硬核”技术。它追求的是够用就好。很多地方其实还有不小的改进空间,举几个例子:
对交互式查询,选择分布式还是单机计算目前还是基于启发式规则。
三种模式的执行计划是用一样的优化器生成的。但是客观的说,这其中的差别可是不小的。
优化器是基于规则的。之所以不做 CBO,论文给出的解释是数据源众多,不容易估算代价。
批处理模式下用 Spark 取代 MR 的模式是更好的选择。
F1 Query 希望用一套系统解决所有 OLTP、OLAP、ETL 需求、用一套系统访问数据中心里各种格式的数据,这两点才是 F1 Query 的核心竞争力。
SQL 执行模式总结
从数据库的视角看,理想的数据库应当隐藏掉查询执行的种种细节,只要用户输入一个声明(例如 SQL),就能以最优的方式执行查询给出答案。F1 Query 做了个勇敢的尝试,它将多种执行模型揉合在一个系统中,共享同一套优化器和算子,以较低的开发成本获得其中最优的执行性能(在理想情况下)。
下面的表格总结了 4 种执行模式的优势和不足。
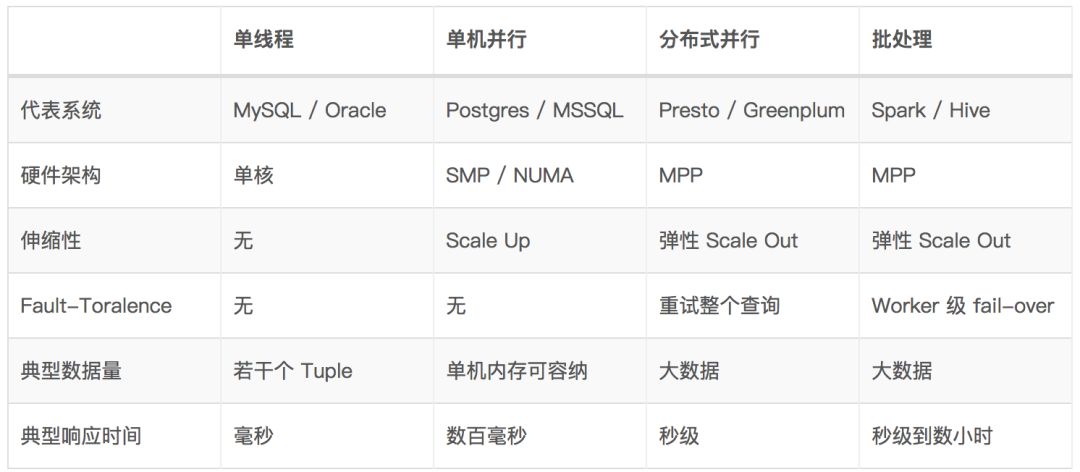
总而言之,所谓 No Free Lunch[3] —— 没有最优的方案,数据量是决定能选用哪个执行模式的前提。实践中,先确保数据量能够承载的下,再谈优化也就明白多了。
References
F1 Query: Declarative Querying at Scale
MySQL Thread Pool Implementation
Presto 实现原理和美团的使用实践 - 美团技术团队
文中链接:
[1] http://www.vldb.org/pvldb/vol11/p1835-samwel.pdf
[2] https://ericfu.me/apache-spark-in-nutshell/
[3] https://en.wikipedia.org/wiki/No_free_lunch_theorem

关注DRDS乐园公众号,获取更多分布式数据库相关信息。
活动预告:
11 月 23 ~ 24 日,GIAC 全球互联网架构大会将于上海举行。GIAC 是高可用架构技术社区推出的面向架构师、技术负责人及高端技术从业人员的技术架构大会。今年的 GIAC 已经有微软,腾讯、阿里巴巴、蚂蚁金服,华为,科大讯飞、新浪微博、京东、七牛、美团点评、饿了么,才云,格灵深瞳,Databricks,等公司专家出席。
本期 GIAC 大会上,数据库和大数据部分精彩的议题如下:

参加 GIAC,盘点2018最新技术。点击“阅读原文”了解大会更多详情。















 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









