







导读:美图日益增长的庞大数据和计算任务,对大数据集群的计算能力、存储能力、稳定性、扩展性等都提出了较大的挑战。目前美图技术团队针对大数据集群做了系列的优化,通过对计算引擎进行改造而达到算力的提升,通过对集群的不断优化提升稳定性的同时规范集群使用。在大数据集群优化的实践中,我们也总结了一些实践经验,也期待和大家有更多的探讨。
 作者简介:余谦,来自数据智能部的大数据部团队,2018 年 2 月加入美图,大数据基础组负责人,从事多年大数据相关工作,积累了较丰富的海量数据处理经验。
作者简介:余谦,来自数据智能部的大数据部团队,2018 年 2 月加入美图,大数据基础组负责人,从事多年大数据相关工作,积累了较丰富的海量数据处理经验。
集群概述
如今大数据在各行业的应用越来越广泛,运营基于数据跟踪运营效果,产品基于数据分析提升转化率,开发基于数据衡量系统优化效果等。美图公司有美拍、美图秀秀、美颜相机等多个app,部分app 会基于大数据做个性化推荐、搜索、报表分析、反作弊、广告等,整体对大数据的业务需求比较多、应用也比较广泛。促使大数据集群需要支持广泛的业务线及应用,驱动这些业务增长,让数据的使用更为高效。
在这里主要想和大家分享下我们两大集群Hadoop&Spark 集群的优化与演进的一些具体经验与尝试。Hadoop 集群主要是用于离线报表计算, Spark 集群主要用于用户个性化推荐、反作弊相关等。当前有 PB 级的历史总量,每天的增量也在近百TB ,每天近万个计算任务,内部有比较多的业务线,并且各业务线比较广泛地运用到数据。这些日益增长的庞大数据和计算任务,充分考验大数据集群的计算能力、存储能力、稳定性、扩展性等。在早期的时候我们有遇到如下问题:稳定性差、组件瓶颈、算力低、组件bug 多、集群成本高、业务方使用缺乏规范、以及数据安全的问题。
针对以上业务背景、技术挑战以及历史问题,促使我们需要对大数据集群不断的迭代优化,以应对各种挑战。我们先对计算引擎进行改造以达到提升算力的目标,其次通过集群的优化在稳定性的提升的同时规范了集群的使用,但是仍然存在不满足当前的算力情况,所以我们正在自研ad-hoc 系统,以及通过采集任务画像信息去匹配任务的最佳参数和最佳引擎。
首先我们看一下现在的技术框架,如图一:
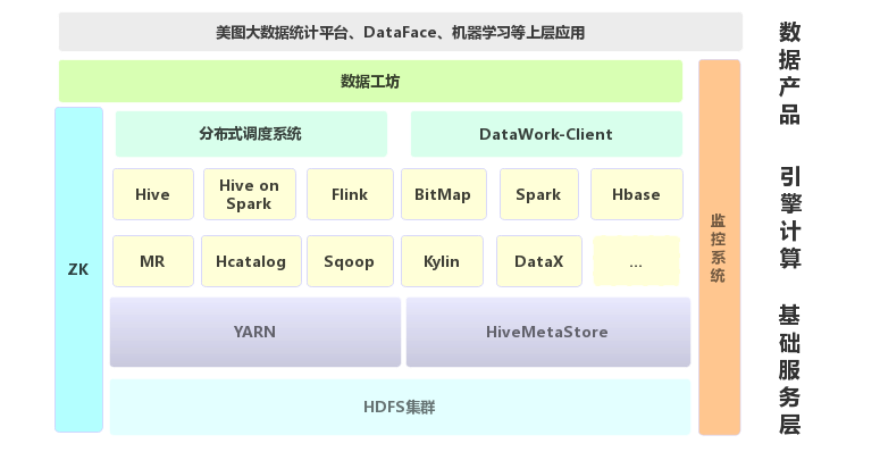
图一目前的技术架构
我们将此技术架构分为三层:
1. 数据产品层:有美图大数据统计平台、dataface 数据可视化平台、机器学习等上层应用,主要用于连接用户与服务,降低数据使用门槛,展现数据价值。这里重点说一下数据工坊,数据工坊是大数据部门自主研发的集数据采集、导入导出、离线计算、实时计算等功能于一体的数据开放平台。业务方有任何数据使用的需求都可以在数据工坊上自助完成。
2. 引擎计算层:提供计算服务,包括交互式查询、即席查询、离线任务计算、数据导入导出、数据分析等服务。由于美图业务的特殊性以及多样性,我们无法通过一个统一的工具去cover 所有业务场景,于是我们引入了这些最适合自身业务的组件。
3. 基础服务层:负责数据的存储、元数据的存储以及任务的计算环境支持。
在数据产品层和引擎计算层间,我们也做了相应的组件作为连接数据产品层和引擎计算层的桥梁:
1. 分布式调度系统:用户管理作业间依赖关系,根据用户任务配置定时调度作业管理的工具;
2. DataWork-client:支持执行 SQL 以及 SQL file (包含权限校验、 SQL 校验),将执行完的结果数据导出到集群上实现 Hadoop&Spark 集群数据互通,并支持上传文件到 hdfs ,支持多种文件格式导出,任务结束邮件通知用户,日志输出等级自定义。接入方式可以是 java-sdk 和Shell 客户端
引擎改造
我们为什么需要对引擎做改造?首先随着公司业务快速的增长,受限于Hive 引擎本身运行机制的低效,频繁的磁盘 IO ,网络请求都会成为计算瓶颈,使得Hive 对任务的实效性不能得到很好的保证。考虑到 Hive引擎已经无法满足当前需求,所以我们对引擎进行了改造,以实现更高效的计算引擎。
其次在资源使用上其对内存依赖较小,不太适合我们当前128G内存的机型,从而导致资源不能合理地被利用。
基于上面几个原因,我们开始着手对引擎做相应改造。我们将Hive 引擎升级为了 Hive on Spark 引擎。选择Hive on Spark 引擎主要基于以下几点考量:
1. 语法上能支持标准的Hive SQL;
2. 性能上能给业务带来较大的提升;
3. 迁移成本上对业务方上是透明,没有任何迁移成本。
将Hive 升级至 Hive on Spark ,我们也做了详细的规划和预演,确保在保证业务的情况下,能顺利的完成升级。在整个的升级过程中,主要有六大步:
1. 第一步:由于Hive on Spark 对版本之前的匹配度是极其敏感,若没有选择到最好的版本可能会带来较大的影响,例如:性能达不到预期、对 SQL 语句的兼容性达不到最佳状态、较多的未知风险等。于是团队开始调研选择最佳的Hive与Spark 的版本组合,整个过程中我们对 10 多个Hive 和 Spark 版本进行组合,最后发现 Hive-2.3.3 on Spark-2.2.2 是一个适合当前业务的最佳版
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









