






01
引言
在今年的敏捷团队建设中,我通过Suite执行器实现了一键自动化单元测试。Juint除了Suite执行器还有哪些执行器呢?由此我的Runner探索之旅开始了!
自然语言(Natural language)通常是指一种自然地随文化演化的语言,自然语言是人类交流和思维的主要工具。与自然语言相对的是逻辑语言,自然语言是人脑与人脑的交际工具 ,逻辑语言是人脑与电脑的交际工具,计算机语言具备自然语言人脑与人脑的交际又具备逻辑语言人脑与电脑的交际。人脑与人脑的交际如要高效需以最简洁的表达,如:
为思佳偶情如火,索尽枯肠夜不眠。
自古姻缘皆分定,红丝岂是有心牵。
事非干己休多管,话不投机莫强言。
观棋不语真君子,把酒多言是小人。
春有百花秋有月,夏有凉风冬有雪。
若还四季不饮酒,空负人间好时节。
世间文字八万个,唯有情字最杀人。
人有生老三千疾,唯有相思不可医。
本是青灯不归客,却因浊酒恋红尘。
既具美感又能完美表达中心思想。
所谓大道至简(基本原理、方法和规律)是极其简单的,简单到一两句话就能说明白。使用计算机语言用于人与人之间的交际工具时也是适用的。
02
实践对比理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。从设计稿出发,提升页面搭建效率,亟需解决的核心问题有:
2.1 大道至简
【Java】
//key = sNo_dNo_bType
private Map<String, Processor> processorMap = new HashMap<>();
//糟糕实现
private Processor getProcessor(DataDto dataDto) {
//无必要的循环 未理解hash表原理
for (Map.Entry<String, Processor> entry : processorMap.entrySet()){
if (entry.getKey().contains(dataDto.getSellerNo())){
String[] keyArr = entry.getKey().split("_");
if (keyArr[1].contains(dataDto.getDeptNo()) && keyArr[2].equals(dataDto.getBizType())) {
return entry.getValue();
}
}
}
return null;
}
//优秀实现
private Processor getProcessor(DataDto dataDto) {
String key = dataDto.getSNo() + "_" + dataDto.getDNo() + "_" + dataDto.getBType();
return processor = processorMap.get(key);
}解析:
1.通过阅读两种实现代码,优秀实现更容易理解,逻辑更清晰。
2.“糟糕实现”原因在于未真正理解MashMap数据结构原理,采用了线性查找方式,将逻辑实现变得复杂。
3.代码层级嵌套,且对key的处理逻辑分散。
实践建议:对于不同数据结构实现应优先选择配套的读写实现,“糟糕实现”中hash数据结构实现却使用了线性访问方式。
2.2 站在巨人的肩膀上
【Java】
//对null对象验证
//普通实现
public String trim(String message) {
if (message != null) {
return message.trim();
}
return message;
}
//优秀实现
public String trim(String message) {
return Optional.ofNullable(message).orElse("").trim();
}
//对null&“”验证
//普通实现
if (message != null && !"".equals(message)) {
return message.trim();
}
//优秀实现
if(StringUtils.isNotEmpty(message)){
return message.trim();
}
//对List数据分组
List<String> nameList = new ArrayList<>(Arrays.asList("A-name","B-name","C-name","A-name"));
//普通实现
Map<String, List<String>> map = new HashMap<>();
for (String name : nameList) {
String[] split = name.split("-");
List<String> names = map.get(split[0]);
if (null == names) {
names = new ArrayList<>();
}
names.add(name);
map.put(split[0], names);
}
//优秀实现
Map<String, List<String>> nameMap = nameList.stream()
.collect(Collectors.groupingBy(o -> o.split("-")[0]));解析:
1.通过使用高版本JDK和工具包(巨人的肩膀)使用代码逻辑更新简单、明了;
2.使用工具类实现逻辑一致,基本已具备常识储备,阅读代码时无须再理解逻辑。
实践建议:优先使用工具类提供的方法,经过多次验证的代码出现Bug的概率更低,将无必要的重复造轮子的时间专注与核心业务。
2.3 合理使用语言特性
【Java】
//创建对象
//普通实现
public class Personnel {
/**
* 姓名 必填
*/
private String name;
/**
* 年龄
*/
private int age;
/**
* 性别
*/
private int sex;
/**
* 身份证号 必填
*/
private String idNumber;
/**
* 地址
*/
private String address;
}
//无法明确对象必填数据与可选数据
//当对象属性较多时 容易遗漏必填数据
//错误会被延迟到测试阶段
Personnel personnel = new Personnel()
personnel.setName("张三");
personnel.setIdNumber("123123123123123123");
//优秀实现
public class Personnel {
/**
* 姓名 必填
*/
private String name;
/**
* 年龄
*/
private int age;
/**
* 性别
*/
private int sex;
/**
* 身份证号 必填
*/
private String idNumber;
/**
* 地址
*/
private String address;
/**
* @deprecated 使用带参数的构造方法
*/
@Deprecated
public Personnel() {
}
//利用构造函数提示必填属性
public Personnel(String name, String idNumber) {
this.name = name;
this.idNumber = idNumber;
}
}
//明确对象必填数据与可选数据
//减少因必填数据遗漏所造成的重复测试
//当属性较多时可采用build类优化构造方法参数过的问题
Personnel personnel = new Personnel("张三","123123123123123123")
//普通实现
public class Response {
protected String requestNo;
protected int code;
protected String message;
/**
* @Deprecated 使用带参数的构造方法
* {@link ResponseBuild#success(String)}
* {@link ResponseBuild#error(String, StatusCode)}
*/
public Response() {
}
public Response(String requestNo, int code, String message) {
this.requestNo = requestNo;
this.code = code;
this.message = message;
}
}
//返回成功
//Response response = new Response();
Response response = new Response("123213",200,"成功");
if(失败){
response.getCode(300);
response.setMessage("失败")
}else{
response.getCode(200);
response.setMessage("成功")
}
//优秀实现
public final class WebResponseBuild {
private WebResponseBuild() {
throw new IllegalStateException("Utility class");
}
public static <T> WebResponse<T> success(String requestNo) {
return new WebResponse<>(requestNo, DEFAULT_SUCCESS.getCode(), DEFAULT_SUCCESS.getMessage(), null);
}
public static <T> WebResponse<T> success(String requestNo, T data) {
return new WebResponse<>(requestNo, DEFAULT_SUCCESS.getCode(), DEFAULT_SUCCESS.getMessage(), data);
}
public static <T> WebResponse<T> error(String requestNo, StatusCode messageCode) {
return new WebResponse<>(requestNo, messageCode.getCode(), messageCode.getMessage(), null);
}
public static <T> WebResponse<T> error(String requestNo, int code, String message) {
return new WebResponse<>(requestNo, code, message, null);
}
}
if(失败){
return WebResponseBuild.error("123213",StatusCode.PARAMETER_IS_NULL)
}
return WebResponseBuild.success("123213")
personnel.setName("张三");解析:
1.Java在创建对象指定必要参数是友好API的一种表现。在无独立配套说明文档的情况能明确对象创建条件,避免代码与文档脱节情况造成的使用难度增加。
2.减少相似代码( personnel.setName("张三") )所占主逻辑篇幅,使主逻辑的逻辑保持清晰。
3.封装API工具类,降低API使用成本,客户端更轻。因为没有服务提供者更清楚业务逻辑。
实践建议:提供更易使用的API,可以降低对API文档的依赖性,代码既文档。
2.4 保持代码卷面整洁
【Java】
//逻辑说明:只保留 PD 属性数据//普通实现
private void removeBatch(PoBatchRel batchRel) {
//相似的逻辑就高度的聚合
if (batchRel == null) {
return;
}
if (CollectionUtils.isEmpty(batchRel.getBatchAttrList())) {
return;
}
//隐含数据只有一条 PD 属性数据的情况,如果当仅有的一条数据不是
//PD属性数据时,对后续逻辑存在在二次处理
//这样会造成同一个逻辑分散到多个地方,代码零散逻辑不易理解
if (batchRel.getBatchAttrList().size() == 1) {
return;
}
Iterator<BatchAttr> lit = batchRel.getBatchAttrList().iterator();
while (lit.hasNext()) {
BatchAttr batchAttr = lit.next();
if (!BatAttrMapping.PD.getKeyOmc().equals(batchAttr.getBatchKey())) {
//修改入参数据造成逻辑执行上下文数据不一致,对于异常情况要保留原始数据时数据丢失
//造成多处日志输出须要多处日志结合分析,增加日志排查难度
//过多的相似日志增加日志量
lit.remove();
}
}
}
//逻辑说明:只保留 PD 属性数据
//优秀实现1
private List<BatchAttr> getProductionDateAttr(PoBatchRel batchRel) {
List<BatchAttr> batchAttrList = new ArrayList<>();
if (Objects.nonNull(batchRel)
&& CollectionUtils.isNotEmpty(batchRel.getBatchAttrList())) {
for (BatchAttr batchAttr : batchRel.getBatchAttrList()) {
if (BatAttrMapping.PD.getKey().equals(batchAttr.getBatchKey())) {
batchAttrList.add(batchAttr);
}
}
}
return batchAttrList;
}
//优秀实现2
private List<BatchAttr> getProductionDateAttr(PoBatchRel batchRel) {
if (Objects.nonNull(batchRel)) {
//保证不出现NullPointerException
List<BatchAttr> batchAttrs = Optional.ofNullable(batchRel.getBatchAttrList())
.orElse(new ArrayList<>(0));
return batchAttrs.stream()
.filter(o -> Objects.equals(BatAttrMapping.PD.getKeyOmc(), o.getBatchKey()))
.collect(Collectors.toList());
}
return new ArrayList<>(0);
}解析:
将相似逻辑可以聚合,以减少占用主逻辑篇篇幅。
实践建议:优先使用工具类提供的方法,经过多次验证的代码出现Bug的概率更低,将无必要的重复造轮子的时间专注与核心业务。
2.5 保持业务流程主体框架明了
1.主流程中只保留业务编排主逻辑;
2.将数据处理前后的数据处理工作(入参必填数据校验、入参转换内部业务对象、出参对象转换等)封装为独立的类或方法;
3.每个方法保持职责单一。
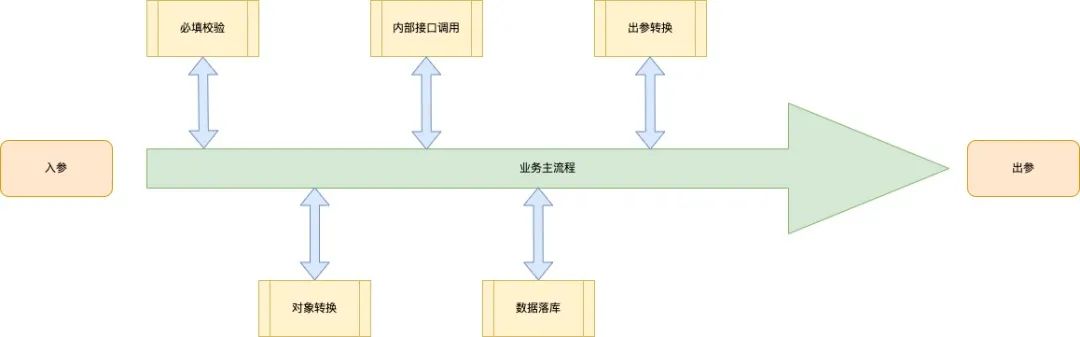
图1 逻辑主流程框架
阅读代码时能快速明确主逻辑,不被过多的细节所牵绊。
2.6 禁止项
1.
1.禁止超千行代码类;
类文件超千行说明承载的职责不单一,应该通过合理的化分功能减少类文件代码行数。
2.禁止超百行代码块;
方法块超百行对于阅读代码时需要记忆的内容较多,增加阅读难度,同样也存在职责不单一问题。
3.禁止跨类调用通过修改入参对象内容返回结果的设计实现;
违背的面向对象编程思想中基本接口编程的指导思想,在不知道实现细节的情况下无法别确其职责,类之间耦合度高维护难度大。
03
推荐理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。从设计稿出发,提升页面搭建效率,亟需解决的核心问题有: 111
《编写高质量代码:改善Java程序的151个建议》 作者:秦小波
《大话设计模式》 作者:程杰
IntelliJ IDEA 插件 SonarLint
SonarLint 是一个免费的 IDE 扩展,可在编写代码时查找和修复错误、漏洞和代码异味;与拼写检查器一样,SonarLint 会即时突出显示问题,并提供快速修复或明确的补救指导,以帮助在代码提交之前对其进行清理。可帮助所有经验和技能水平的开发人员编写高效、安全的代码。
04
总结理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
大道至简是个人认为代码整洁之道核心指导思想。保持业务流程主逻辑清晰明了,如骨架一般。细节实现部分使用现有工具减少大量低功能重复代码,再合理利用语言特性避免低级错误与相似重复逻辑。
面向对象编程要做到在不需要了解细节就能够快速明确业务主要逻辑,就要尽量将细节从主逻辑中隐去。将细节封装到各业务对象中。只对外提供高度抽象接口。如何使用JDK 所提供的Api一样。
以上是在工作中所见所遇,各系统都存在与示例中普通实现一样的逻辑,千行方法,万行类,重复造轮子等问题,造成系统代码臃肿,维护难不断增加。
不积跬步,无以至千里。以上为跬步以此来抛砖引玉。

参考阅读:
本文由高可用架构转载。技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿














 1826
1826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









