







论文阅读
Exploring Self-attention for Image Recognition
作者:Hengshuang Zhao,CUHK;Jiaya Jia,CUHK;Vladlen Koltun,Intel Labs
来源:CVPR2020
论文:paper
代码:code
摘要
- self-attention可以作为图像识别模型的基本组成部分
- 本文考虑两种形式:
pairwise self-attention和patch self-attention- pairwise self-attention:本质上是一个集合操作
- patchwise self-attention:比卷积更强大
- 性能:conv < pairwise self-attention < patchwise self-attention
:
Ⅰ引言
-
离散卷积操作( ∗ \ast ∗):
( F ∗ k ) ( p ) = ∑ s + t = p F ( s ) k ( t ) \begin{align}(F \ast k)(p) = \sum_{s+t=p} F(s)k(t) \end{align} (F∗k)(p)=s+t=p∑F(s)k(t)其中:F是一个离散函数,k是一个离散滤波器。
卷积的优点:平移不变性(在图像F上应用相同的滤波器k)
卷积的缺点:缺乏旋转不变性,滤波器的稳定性问题(聚合的领域信息不能适应内容) -
self-attention操作
-
pairwise self-attention :是NLP中使用的标准dot-product attention的推广。与卷积不同,它本质上是一个集合运算,且不为特定的位置固定权重(如式(1)所示),且对排列和基数不变。
表现:增加自关注算子的占用(例如,从3×3到7×7补丁),甚至使其不规则,而不会对参数的数量产生任何影响 -
patchwise self-attention :与卷积相同,有能力唯一地识别其足迹中的特定位置,但不具备排列不变性或基数不变性。
-
Ⅱ 相关工作
- convolution networks
- self-attention
Ⅲ Self-attention Networks
- 在图像识别中,卷积层有两个作用:
- 特征聚合:通过卷积核将所有位置的特征聚合起来
- 特征变换:由连续的线性映射和非线性标量函数来完成,这些连续映射和非线性操作使特征空间破碎,从而产生复杂的分段映射。
- 替代卷积 = 构造Network(特征聚合,特征变换)。特征变换可以通过感知器来进行处理,因此重点是构建特征聚合。
3.1 Pairwise Self-attention
-
pairwise如下式所示:
y i = ∑ j ∈ R ( i ) α ( x i , x j ) ⊙ β ( x j ) \color{red}\begin{align}y_{i} = \sum_{j\in R(i)}\alpha(x_{i},x_{j})\odot \beta(x_{j})\end{align} yi=j∈R(i)∑α(xi,xj)⊙β(xj)
其中: ⊙ \odot ⊙ 表示哈达玛积(对应元素相乘),i 是特征向量 x i x_{i} xi 的空间索引(即,在特征图中的位置), R i R_{i} Ri 表示一组索引,指定聚合哪些特征向量来构造新的特征。
函数 β \beta β产生的特征向量 β ( x j ) \beta(x_{j}) β(xj) 是由自适应权重向量 α ( x i , x j ) \alpha(x_{i},x_{j}) α(xi,xj) 聚合得到的
函数 α \alpha α 是计算用于结合转移特征 β ( x j ) \beta(x_{j}) β(xj) 的权重 α ( x j ) \alpha(x_{j}) α(xj) 。将 α \alpha α 分解为:
α ( x i , x j ) = γ ( δ ( x i , x j ) ) \color{red}\begin{align}\alpha(x_{i},x_{j}) = \gamma(\delta(x_{i},x_{j}))\end{align} α(xi,xj)=γ(δ(xi,xj))
其中:关系函数 δ \delta δ 输出一个可以代表特征 x i , x j x_{i},x_{j} xi,xj 的向量;函数 γ \gamma γ 将向量映射成另外一个可以与 β ( x j ) \beta(x_{j}) β(xj) 结合的向量(如式2所示)。
-
函数 γ \gamma γ 使我们能够探索产生不同维度的向量之间的关系 δ \delta δ,这些向量不需要匹配 β ( x j ) \beta(x_{j}) β(xj) 的维数。它还允许我们在权重 a l p h a ( x i , x j ) alpha(x_{i},x_{j}) alpha(xi,xj) 的构造中引入其他的可训练变换,使该构造更具表现力。这个函数的表现形式: γ \gamma γ={线性→ReLU→线性}。 γ \gamma γ 的输出维度不需要与 δ \delta δ 的输出维度相匹配,因为注意力权重可以在一组通道中共享。
-
本文探索的 δ \delta δ的形式有:
-
① Summation: δ ( x i , x j ) = φ ( x i ) + ψ ( x j ) \delta(x_{i},x_{j}) = \varphi (x_{i}) + \psi (x_{j}) δ(xi,xj)=φ(xi)+ψ(xj)
-
② Substraction: δ ( x i , x j ) = φ ( x i ) − ψ ( x j ) \delta(x_{i},x_{j}) = \varphi (x_{i}) - \psi (x_{j}) δ(xi,xj)=φ(xi)−ψ(xj)
-
③ Concatemtation: δ ( x i , x j ) = [ φ ( x i ) , ψ ( x j ) ] \delta(x_{i},x_{j}) = [ \varphi (x_{i}) , \psi (x_{j}) ] δ(xi,xj)=[φ(xi),ψ(xj)]
-
④ Hadamard product: δ ( x i , x j ) = φ ( x i ) ⊙ ψ ( x j ) \delta(x_{i},x_{j}) = \varphi (x_{i}) \odot \psi (x_{j}) δ(xi,xj)=φ(xi)⊙ψ(xj)
-
⑤ Dot product: δ ( x i , x j ) = φ ( x i ) T ψ ( x j ) \delta(x_{i},x_{j}) = \varphi (x_{i})^T \psi (x_{j}) δ(xi,xj)=φ(xi)Tψ(xj)
其中: φ \varphi φ 和 ψ \psi ψ 是可训练的变换,如线性映射,并且具有匹配的输出维度。①②④ 与变换的维度相同,③ 的维度将会翻倍,⑤ 的维度为1.
-
-
位置编码(position encoding)
- 归一化:将特征图上的水平坐标和垂直坐标归一化为每个维度的 [-1, 1]
- 映射:将归一化后的二维坐标通过一个可训练的线性层将它们映射到网络中每一层的适当范围
- 输出:对于在特征图中每个位置 i ,线性映射会输出一个二维的位置特征 p i p_{i} pi
- 相对位置信息: p i − p j p_{i} - p_{j} pi−pj
3.2 Patchwise Self-attention
-
patchwise如下式所示:
y i = ∑ j ∈ R ( i ) α ( x R ( i ) ) j ⊙ β ( x j ) \color{red}\begin{align}y_{i} = \sum_{j\in R(i)}\alpha(x_{R(i)})_{j}\odot \beta(x_{j})\end{align} yi=j∈R(i)∑α(xR(i))j⊙β(xj)其中: x R ( i ) x_{R(i)} xR(i) 表示 R i R_{i} Ri 中特征向量的patch; α ( x R ( i ) \alpha(x_{R(i)} α(xR(i) 表示与patch x R ( i ) x_{R(i)} xR(i) 有相同的空间维度的tensor。
与pairwise self-attention不同,patchwise sel-attention不是关于特征的集合操作。它不具备排列不变性或者基数不变性:权重向量 α ( x R ( i ) ) \alpha(x_{R(i)}) α(xR(i)) 可以按位置单独索引特征向量 x j x_{j} xj ,并且可以混合不同位置的特征向量的信息。因此,patchwise sel-attention比卷积更强大。
α ( x R ( i ) ) \alpha(x_{R(i)}) α(xR(i))可以分解为:
α ( x R ( i ) ) = γ ( δ ( x R ( i ) ) ) \color{red}\begin{align}\alpha(x_{R(i)}) = \gamma(\delta(x_{R(i)})) \end{align} α(xR(i))=γ(δ(xR(i)))
本文探索的 α ( x R ( i ) ) \alpha(x_{R(i)}) α(xR(i))的形式有:
- ① Srar-product: α ( x R ( i ) ) = [ φ ( x i ) T ψ ( x j ) ] ∀ j ∈ R ( i ) \alpha(x_{R(i)}) = [\varphi (x_{i}) ^T \psi (x_{j})]_{\forall j \in R(i)} α(xR(i))=[φ(xi)Tψ(xj)]∀j∈R(i)
- ② Clique-product: α ( x R ( j ) ) = [ φ ( x k ) T ψ ( x j ) ] ∀ j , k ∈ R ( i ) \alpha(x_{R(j)}) = [\varphi (x_{k}) ^T \psi (x_{j})]_{\forall j,k \in R(i)} α(xR(j))=[φ(xk)Tψ(xj)]∀j,k∈R(i)
- ③ Concatenation: α ( x R ( i ) ) = [ φ ( x i ) , [ ψ ( x j ) ] ∀ j ∈ R ( i ) ] \alpha(x_{R(i)}) = [\varphi (x_{i}) , [\psi (x_{j})]_{\forall j \in R(i)}] α(xR(i))=[φ(xi),[ψ(xj)]∀j∈R(i)]
3.3 Self-attention Block
-
patchwise 和 pairwise self-attention可以用来构造残差块,残差快既可以特征聚合又可以特征转换。
-
本文的self-attention如图所示:
-

分析:输入特征张量(通道维数C)通过两个处理流。左边的流通过计算函数 δ \delta δ (通过映射 φ \varphi φ 和 ψ \psi ψ )和随后的映射 γ \gamma γ 来评估注意力权重 α \alpha α 。右边的流应用线性变换 β \beta β,变换输入特征并降低其维数来进行有效处理。然后通过Hadamard积将两个流的输出聚合起来。组合的特征经过归一化和元素非线性处理,并由最后的线性层加粗样式处理,该层将其维数扩展回C。
3.4 Network Architectures
- 三种体系结构:

-
Backbone:
- SAN的主干有五个阶段,每个阶段具有不同的空间分辨率,产生分辨率降低系数为 32。
- 每个阶段包括多个自我关注模块。连续的阶段由过渡层连接,从而降低空间分辨率并扩展通道维度。最后一个阶段的输出由一个分类层处理,该分类层包括全局平均池化、一个线性层和一个softmax。
-
Transition:
- 过渡层降低了空间分辨率,从而减少了计算负担,扩大了接受域。过渡层包括一个 batch 归一化层,一个ReLU, 2×2 最大池化(stride = 2),和一个线性映射扩展通道维度。
-
Footprint of self-attention
- local footprint R ( i ) R_{(i)} R(i) 控制了上下文的数量。我们将内存占用大小设置为 7×7。在第一阶段,由于该阶段的高分辨率和随后的内存消耗,内存占用被设置为 3×3。注意,增加 footprint size 对成对自关注中的参数数量没有影响。
-
Instantiations
- 每个阶段的自关注块数量可以调整,以获得不同容量的网络。在表 1 所示的网络中,最后四个阶段使用的自注意块数量分别与 ResNet26、ResNet38 和 ResNet50中剩余的块数量相同。
Ⅳ Comparison

-
Convolution:
- 卷积运算具有与图像内容无关的固定卷积核权重;
- 卷积运算不适应输入的内容;
- 卷积核的权重可以在不同的通道中变化。
-
Scalar attention:
- 通常具有的形式:
y i = ∑ j ∈ R ( i ) ( φ ( x i ) T ψ ( x j ) ) β ( x j ) \begin{align}y_{i} = \sum_{j\in R(i)} ( \varphi (x_{i})^T \psi (x_{j})) \beta(x_{j})\end{align} yi=j∈R(i)∑(φ(xi)Tψ(xj))β(xj) - 与卷积不同的是,根据图像的内容,聚合权重可以在不同的位置变化;
- φ ( x i ) T ψ ( x j ) ) \varphi (x_{i})^T \psi (x_{j})) φ(xi)Tψ(xj))是标量可以在所有通道中共享;
- 这种结构不能适应不同渠道的注意力权重;
- 解决方案:引入多个头可以在一定程度上缓解
- 通常具有的形式:
-
Vector attention(本文):
- 在 pairwise attention 中,关系函数 δ \delta δ 可以产生输出向量;通过 γ \gamma γ 映射,将输出向量映射到正确的维度
- 在 patchwise attention 中,将卷积一般化;该运算为沿着特征映射的所有位置产生位置向量,这些位置随着通道维度变化。
Ⅴ实验
- 数据库:ImageNet
5.1 Implementation
- 参数设置:
- 从头开始训练所有模型100次;
- 使用基础学习率为0.1的余弦学习率调度。
- 在ImageNet上应用标准数据增强,包括对224×224补丁的随机裁剪、随机水平翻转和归一化;
- 在8个gpu上使用mini batch size为256的同步SGD;
- 使用系数为0.1的标签平滑正则化;
- 动量衰减和重量衰减分别设为0.9和1e-4;
- 卷积网络基线是ResNet26、ResNet38和ResNet50
- 对于自关注块,我们默认使用r1 = 16和r2 = 4(参见图1的符号);
- 共享相同关注权重的通道数设置为8
5.2 与卷积网络的比较
- 与卷积网络的比较:

5.3 消融实验
- 关系函数:

- 映射函数:

- 转换函数:

- footprint size:

- 位置编码:

5.4 鲁棒性
- 对旋转图像的零样本泛化
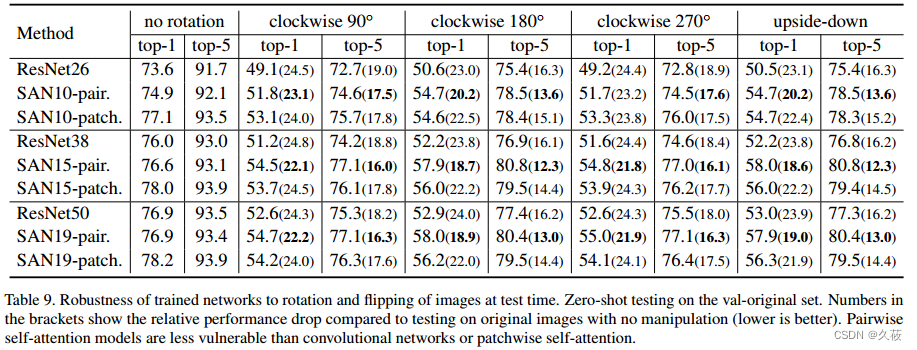
- 对对抗攻击的鲁棒性

Ⅵ 参考
[1] Hengshuang Zhao, Jiaya Jia, and Vladlen Koltun. Exploring self-attention for image recognition. In CVPR, 2020. 1, 2, 3, 4















 994
994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









