







联邦推荐系统综述
朱智韬1,2, 司世景1, 王健宗1, 肖京1
1平安科技(深圳)有限公司
2中国科学技术大学
摘要:在联邦学习范式中,原始数据被本地存储在独立的用户客户端中,而脱敏数据被发送到中心服务器中加以聚合,这给众多领域提供了一种新颖的设计思路。考虑到传统推荐系统的研究方向集中于提高推荐效果,在资源节约、跨领域推荐、隐私保护等方面还具有很大改进空间,如何将联邦学习与推荐系统结合以解决这些问题成为当前的一个研究热点。对近年来基于联邦学习的推荐系统进行了全面的总结、比较与分析,首先介绍了推荐系统的传统实现方式及面临的瓶颈;然后引入了联邦学习范式,描述了联邦学习在隐私保护、利用多领域用户数据两方面给推荐系统带来的增益,以及二者结合的技术挑战,进而详细说明了现有的联邦推荐系统部署方式;最后,对联邦推荐系统未来的研究进行了展望与总结。
关键词: 联邦学习 ; 推荐系统 ; 隐私保护 ; 协同过滤 ; 深度学习

论文引用格式:
朱智韬, 司世景, 王健宗, 等. 联邦推荐系统综述[J]. 大数据, 2022, 8(4): 105-132.
ZHU Z T, SI S J, WANG J Z, et al. Survey on federated recommendation systems[J]. Big Data Research, 2022, 8(4): 105-132.

0 引言
伴随着互联网的快速发展,信息过载问题成为每个人的生活中一个愈发严重的阻碍。作为解决信息过载问题的有效解决方案,推荐系统(recommendation system,RS)在商业网站和信息分发应用中普遍存在。它们利用用户的各种知识和数据生成个性化推荐结果,是抵御客户无意义浏览和商家无用数据推送的利器。一般来说,推荐列表立足于格式化存储的三方面信息:用户喜好、项目属性、用户与项目的交互记录。此外,还可能使用其他附加信息,如时间和空间数。推荐系统服务的最终目标是提高营业额,根据不同的应用场景,服务提供者可能会采取不同的路径来实现这一目标,包括向目标用户推荐合适商品以直接增加销售量,以及推送匹配用户兴趣的娱乐内容以提高用户黏度,从而使广告获得更多的曝光率等。但毫无疑问,各种隐私保护法规的颁布对跟踪用户足迹的程序的要求将变得越来越严格。越来越多的大企业开始意识到隐私保护和数据安全合规的必要性,并出现了基于联邦学习(federated learning,FL)等机制的隐私保护措施。
本文对推荐系统、联邦学习以及两者的结合进行了概述。首先阐述推荐系统的作用机制,然后介绍联邦学习的发展源流,最终的目标是在不破坏数据隐私和遵守安全原则的前提下,探索最大限度地利用数据的联邦推荐方法。
1 推荐系统
在实践中,推荐系统已经被广泛应用于书籍和CD、音乐、电影、新闻、笑话和网页等推荐中。根据推荐机制的不同,传统推荐模型主要分为协同过滤式推荐系统、基于内容的推荐系统和混合推荐系统。而后深度学习方法的兴起为推荐系统的研究带来了新的机遇,本文也将举例说明其结合思想。
1.1 协同过滤推荐系统
协同过滤算法的核心思想是根据相似用户或相似物品来提供商品推荐或预测,其包括两个维度:基于邻域和基于模型。最初的邻域算法集中在用户之间的相似性上,被称为基于用户的协同过滤(user-based collaborative filtering, UCF);基于项目的协同过滤(item-based collaborative filtering,ICF)方法则关注类似项目的评分。基于邻域的协同过滤推荐的关键是计算不同用户、不同项目之间的相似度。表1给出了比较常用的相似度度量方法。

基于邻域的协同过滤系统过去非常成功,得到了广泛使用,但受到可扩展性不足(最近邻算法需要的计算量随着用户数和项目数的增长而快速增长,不适合应用于数据量较大的场景)的限制。因此,有学者提出了一种基于模型的协同过滤(modelbased collaborative filtering,MCF)算法,利用机器学习或数据挖掘等算法,通过训练数据对复杂模式进行学习和识别,得到学习模型,然后根据学习模型对数据集进行智能预测。常用的模型协同过滤算法有隐语义协同过滤模型、隐因子模型等。
此外,还有其他路径的协同过滤推荐算法,如将推荐问题转化为节点选择问题的图模型推荐算法、模拟人类推理因果关系的不定性的贝叶斯网络协同过滤模型、聚焦用户属性特征的聚类协同过滤模型等。
作为目前使用非常广泛的推荐算法,协同过滤推荐系统工程实现简单,模型通用性强,效果显著,但始终面临着严重的数据稀疏(用户仅对数据库中可用项目的极少部分进行评分)与冷启动(新用户与新物品缺少评分数据作为可学习的历史信息)问题,并且通常使用的浅层模型无法学习到用户和项目的深层次特征。
1.2 基于内容的推荐系统
基于内容的推荐系统(content-based recommendation system,CB)算法通过寻找与用户已选择项目具有相似属性的物品进行推荐。Pazzani M J等人对基于内容的推荐策略架构进行了宏观介绍,这种推荐只需要两类信息,即对项目特征的描述和用户过去的偏好信息,不需要大量的用户评分历史来生成推荐列表(避免了评分数据稀疏问题)。实现的关键点在于对项目和用户偏好进行建模,并计算其相似性(此时提取新项目的特征即可进行冷启动)。Salton G等人提出的向量空间模型是非常常用的内容建模方法。基于内容的推荐系统可解释性强,可以更好地解决冷启动问题,对于小众领域也有较好的推荐效果,其缺点在于推荐精准度较低、无法挖掘用户深层次的潜在兴趣,导致推荐新颖度不高、较难分发长尾标的物,并且这种方法的有效性与可扩展性受到人工设计特征提取方法的严重制约,常常会遇到特征提取困难的问题。
1.3 混合推荐系统
类似于集成学习通过有效整合不同算法降低系统性误差的思想,混合推荐系统搭配使用不同的推荐算法给出最终的推荐结果,避免单一算法固有的问题,实现较任意单一算法更佳的推荐效果。此外,一些混合推荐算法融合了包括图像、音频、文本在内的多源异质辅助信息,能够有效解决数据稀疏和冷启动问题。但囿于辅助信息的复杂性(如异质性、多模态、数据提供方限制等),相关方法的研究仍然面临着严峻挑战。
值得一提的是,基于其他方法的推荐系统也各有千秋,如基于社交网络的、基于人口数据的、基于心理学的、基于大数据的,等等。每一种推荐算法都有其优缺点,本文篇幅有限,不做深入阐述。
1.4 基于深度学习的推荐系统
随着算力的跨越式提高,深度学习已经成为互联网人工智能的一个利器。神经体系结构在有监督和无监督学习任务中都获得了巨大的成功。自然地,深度学习也在推荐系统领域得到了广泛应用,并且得益于其在非线性转换、表征学习、序列模型以及灵活性方面的优势,成为当前的最优模型。
深度学习在推荐系统中的应用最早可以追溯到2007年Salakhutdinov R等人发表的一篇将受限玻尔兹曼机应用于推荐系统的文章。常用的深度学习模型有多层感知机、卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、注意力模型、自编码器、神经自回归分布估计、对抗网络、受限玻尔兹曼机、深度强化学习等,这些模型在推荐系统上得到了广泛的应用。
基于深度学习的推荐系统通常将与各类用户和项目相关的数据作为输入,利用深度学习模型学习用户和项目的隐表示,并基于这种隐表示为用户生成项目推荐。目前构建深度学习推荐算法最常见的一种范式是多层感知机,其可将非线性变换添加到现有的推荐系统方法中,如果需要整合附加信息(图像、文本、语音、视频等),则会采用CNN、RNN模型来提取相关信息。
而后根据所采用的神经网络的不同结构,演变出了不同的深度学习推荐模型。
通过增加深度神经网络结构的层数和复杂度,AutoRec引入了自编码器,如图1所示,利用单隐层神经网络模型,结合协同过滤的共现矩阵,得到用户/物品向量的自编码,后续生成用户对物品的预估评分并用于排序。
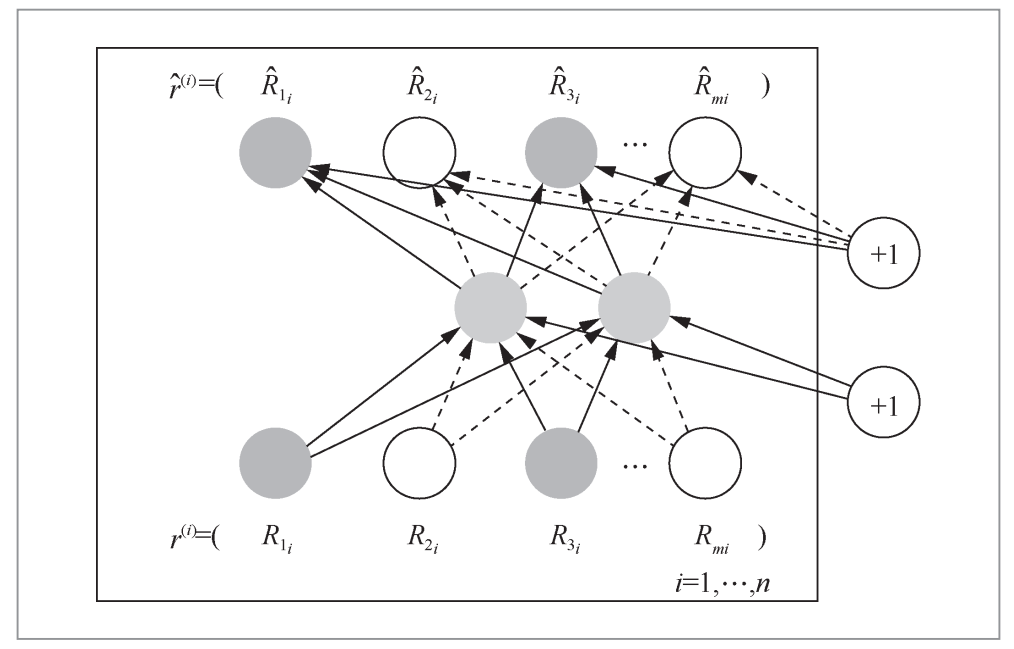
图1 自编码器深度推荐系统
通过丰富特征交叉方式演变出了神经协同过滤(neural collaborative filtering,NCF),图2中摈弃了矩阵分解中的简单内积操作,“多层神经网络+输出层”让用户/物品向量进行更充分的交叉,引入更多的非线性特征,增强对稀疏特征的学习能力。
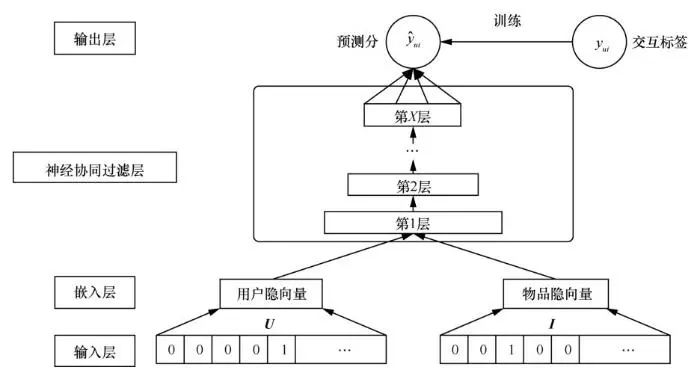
图2 神经协同过滤
通过引入注意力机制,在嵌入层与多层感知机之间加入注意力层,演变出了深度兴趣网络(deep interest network, DIN),以及融合了序列模型以模拟用户喜好变化过程的深度兴趣进化网络(deep interest evolution network,DIEN)、使用胶囊网络提取用户的多样兴趣并引入基于标签的注意力机制的动态路径选择多兴趣网络(multi-interest network with dynamic routing,MIND)等。
而对于因子分解机模型的各种深度学习演化,克服了协同过滤对稀疏矩阵泛化能力不强的困难,包括神经因子分解机(neural factorization machine,N
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









