







一、本期课程内容概述
本节课的主讲老师是【安泓郡】。教学内容主要包括以下三个部分:
1.大模型部署背景
2. 大模型部署方法
3.LMDeploy介绍以及实战
二、学习收获
- 大模型部署的定义
大模型部署,即把训练成熟的机器学习或深度学习模型嵌入实际应用场景,使之能对外提供实时服务。这一过程涵盖模型从训练环境向生产环境的迁移,旨在使模型在现实业务中发挥效用。它是解锁机器学习/深度学习价值的核心步骤,因为唯有通过部署,模型才能从理论走向实践,为企业或个人创造实质性收益。 - 大模型部署面临的挑战
- 计算量巨大
- 大模型(如大型语言模型、视觉模型等)由于其庞大的参数规模(数亿至数百亿参数),在推理阶段需要进行大量的矩阵运算和张量操作,导致计算量显著增加。这种高强度的计算需求对硬件平台的计算能力提出极高要求,特别是对CPU、GPU、NPU等计算单元的算力、浮点运算性能以及并行处理能力。
- 显存开销巨大
- 除了计算需求,大模型的权重参数存储占用大量显存。例如,一个70亿参数的模型仅权重就需要约14GB的显存。此外,模型在推理过程中可能还需要额外的显存来暂存中间结果、缓存激活值、保持注意力机制中的Key/Value等,进一步加剧显存压力。
- 特别是在边缘设备或资源受限的环境下,有限的显存容量可能无法容纳整个模型,使得模型无法一次性加载或运行,这就需要采用诸如模型切分、动态加载等技术来缓解显存瓶颈。
- 访存瓶颈
非专业人士很难察觉到这一点- 大模型在推理过程中频繁地进行数据读取(从内存或硬盘)和写回(到内存或显存),由于现代计算机体系结构中CPU与内存、内存与显存之间的带宽有限,大规模数据传输可能导致严重的访存延迟。
- 高频的IO操作会成为性能瓶颈,特别是在模型内部存在深度依赖关系或者数据依赖复杂的情况下,频繁的缓存未命中会导致大量的等待时间,严重影响模型推理的实时性。
- 动态请求
- 应用场景中,用户请求往往是动态变化且不可预测的,大模型需要快速响应这些请求,进行实时推理。然而,大模型回复时的Token是逐个生成的,可能导致响应时间延长,无法满足实时服务的要求。
- 动态请求还可能引发负载波动,对部署系统的弹性伸缩能力提出考验。为了保证服务质量,部署方案需具备高效的资源调度机制,能够在短时间内适应请求量的变化,避免因瞬间高并发请求导致的系统过载或服务中断。
- 计算量巨大
- 大模型部署常用方法
- 模型剪枝
模型剪枝是一种通过识别并移除模型中对整体性能影响较小的冗余参数或子结构,以简化模型、减少计算资源需求的技术。其基本思想是,在保持模型预测能力的前提下,对模型进行“瘦身”,使之更适合实际部署环境。剪枝过程中,通常先对模型参数的重要性进行评估,然后依据评估结果设定阈值,将不重要的参数剔除或削弱其影响力,最后对剪枝后的模型进行微调以恢复精度。 - 知识蒸馏
知识蒸馏是一种将大型复杂模型(教师模型)的知识迁移到小型精简模型(学生模型)的过程。原理上,教师模型不仅输出最终预测结果,还通过其丰富的中间层特征表达高级抽象知识。学生模型则在训练时不仅学习样本标签,还模仿教师模型的这些中间层输出。通过这种知识转移,学生模型能够在保持较低复杂度的同时,继承教师模型的部分乃至大部分性能。 - 模型量化
模型量化是将模型参数及运算从高精度浮点数表示转换为低精度(如定点数、二进制等)表示的方法。其原理在于利用人眼对视觉信息的容忍度以及神经网络对参数微小变化的相对鲁棒性,牺牲一定的数值精度换取模型大小和计算效率的显著提升。量化过程通常包括离散化模型参数、调整激活函数以适应低精度计算,并对量化后的模型进行重新训练或微调以恢复精度损失。量化技术可以应用于模型的存储和推理阶段,有效降低硬件资源消耗,尤其适用于移动设备和嵌入式系统。
- 模型剪枝
- LMDeploy简介及核心功能
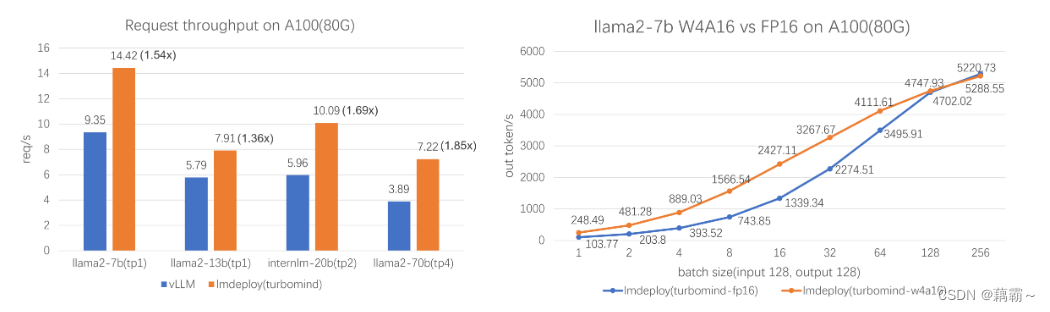
LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。 这个强大的工具箱提供以下核心功能:- 高效的推理:LMDeploy 开发了 Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性。推理性能是 vLLM 的 1.8 倍
- 可靠的量化:LMDeploy 支持权重量化和 k/v 量化。4bit 模型推理效率是 FP16 下的 2.4 倍。量化模型的可靠性已通过 OpenCompass 评测得到充分验证。
- 便捷的服务:通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
- 有状态推理:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。
- LMDeploy性能
LMDeploy TurboMind 引擎拥有卓越的推理能力,在各种规模的模型上,每秒处理的请求数是 vLLM 的 1.36 ~ 1.85 倍。在静态推理能力方面,TurboMind 4bit 模型推理速度(out token/s)远高于 FP16/BF16 推理。在小 batch 时,提高到 2.4 倍。
三、个人体会
- 了解到了大模型部署的难点,想要走向实践要踩得坑还很多
- 我曾经多卡部署过Qwen1.5-72B,在请求并发超过2时就会出问题,现在还没解决问题,回头用LMDeploy试试
- 写完作业后,新增体会,推理速度是真的快
四、本期作业
https://blog.csdn.net/weixin_45609124/article/details/138050191














 745
745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









