







 本文详细介绍了在InternStudio平台上使用Xtuner进行模型微调的过程,包括环境设置、数据集准备、模型选择、配置文件操作和模型整合,以及将模型上传至OpenXLab并尝试部署的应用实例。
本文详细介绍了在InternStudio平台上使用Xtuner进行模型微调的过程,包括环境设置、数据集准备、模型选择、配置文件操作和模型整合,以及将模型上传至OpenXLab并尝试部署的应用实例。
一、学习笔记
https://blog.csdn.net/weixin_45609124/article/details/137938882
二、基础作业
- . 训练自己的小助手认知
在InternStudio 平台中,跟着老师的教程文档走都是没有问题的,我这里稍微记录下在其他平台上的操作流程,方便日后自己使用。- 微调工具Xtuner环境准备
# 如果你是在其他平台: # conda create --name xtuner0.1.17 python=3.10 -y # 激活环境 conda activate xtuner0.1.17 # 拉取 0.1.17 的版本源码 git clone -b v0.1.17 https://github.com/InternLM/xtuner # 无法访问github的用户请从 gitee 拉取: # git clone -b v0.1.15 https://gitee.com/Internlm/xtuner # 进入源码目录 cd /xtuner # 从源码安装 XTuner pip install -e '.[all]' - 数据集准备
老师在教程中准备数据集时,应该是为了节省大家的时间,选择了将同一条数据循环写入文件10000次,这样会导致微调后的模型过拟合,我们可以在一万条正常的对话数据里混入两千条和小助手相关的数据集,这样模型同样可以在不丢失对话能力的前提下学到XX大佬的小助手这句话。我们也可以了解Xtuner支持的数据集格式,自己动手制作。
数据集格式可参考官方示例:单轮对话、多轮对话 - 模型准备
Xtuner目前支持的模型有InternLM2、InternLM、Llama 3、Llama 2、Llama 、ChatGLM3、ChatGLM2、Qwen、Baichuan、Baichuan2、Mixtral 8x7B、DeepSeek MoE、Gemma。根据自己的硬件条件选择参数大小合适的模型。如果有遇到模型下载问题的小伙伴,可以看一下我的第三节作业。 - 快速上手流程
# 列出所有内置配置文件 # xtuner list-cfg # 假如我们想找到 internlm2-1.8b 模型里支持的配置文件 xtuner list-cfg -p internlm2_1_8b # 使用 XTuner 中的 copy-cfg 功能将 config 文件复制到指定的位置,方便我们进行修改 xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config #编辑配置文件 pretrained_model_name_or_path 模型存放路径 alpaca_en_path 数据集存放路径 evaluation_inputs 验证数据 #常规方式启动 xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train #使用 deepspeed 来加速训练 xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2 # 模型续训 xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train --resume /root/ft/train/iter_600.pth # 模型转换 # xtuner convert pth_to_hf ${配置文件地址} ${权重文件地址} ${转换后模型保存地址} xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_768.pth /root/ft/huggingface # 进行模型整合 # xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH} xtuner convert merge /root/ft/model /root/ft/huggingface /root/ft/final_model #使用 --adapter 参数与完整的模型进行对话 xtuner chat /root/ft/model --adapter /root/ft/huggingface --prompt-template internlm2_chat - 小结
最终将数据集、模型文件、微调配置文件整理为以下结构:|-- ft/ |-- config/ |-- internlm2_1_8b_qlora_alpaca_e3_copy.py |-- model/ |-- tokenizer.model |-- config.json |-- tokenization_internlm2.py |-- model-00002-of-00002.safetensors |-- tokenizer_config.json |-- model-00001-of-00002.safetensors |-- model.safetensors.index.json |-- configuration.json |-- special_tokens_map.json |-- modeling_internlm2.py |-- README.md |-- configuration_internlm2.py |-- generation_config.json |-- tokenization_internlm2_fast.py |-- data/ |-- personal_assistant.json |-- generate_data.py - 作业截图
数据集、模型文件、配置文件已准备好
原神启动,哦,不对,Xtuner启动!!!
看着满屏的日志,内心还是些许慌张的,生怕突然停掉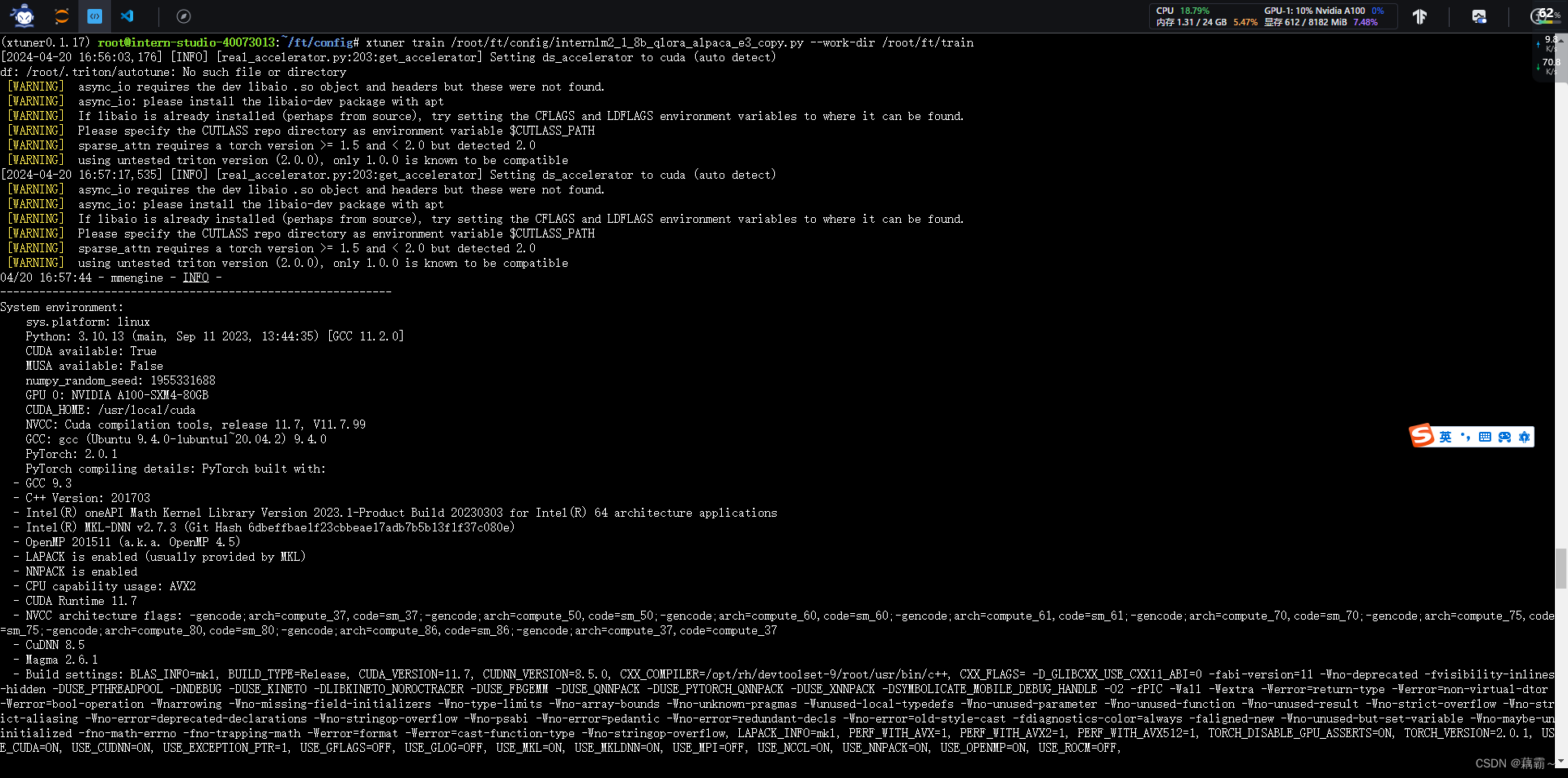
训练完成后,装换为Huggingface 格式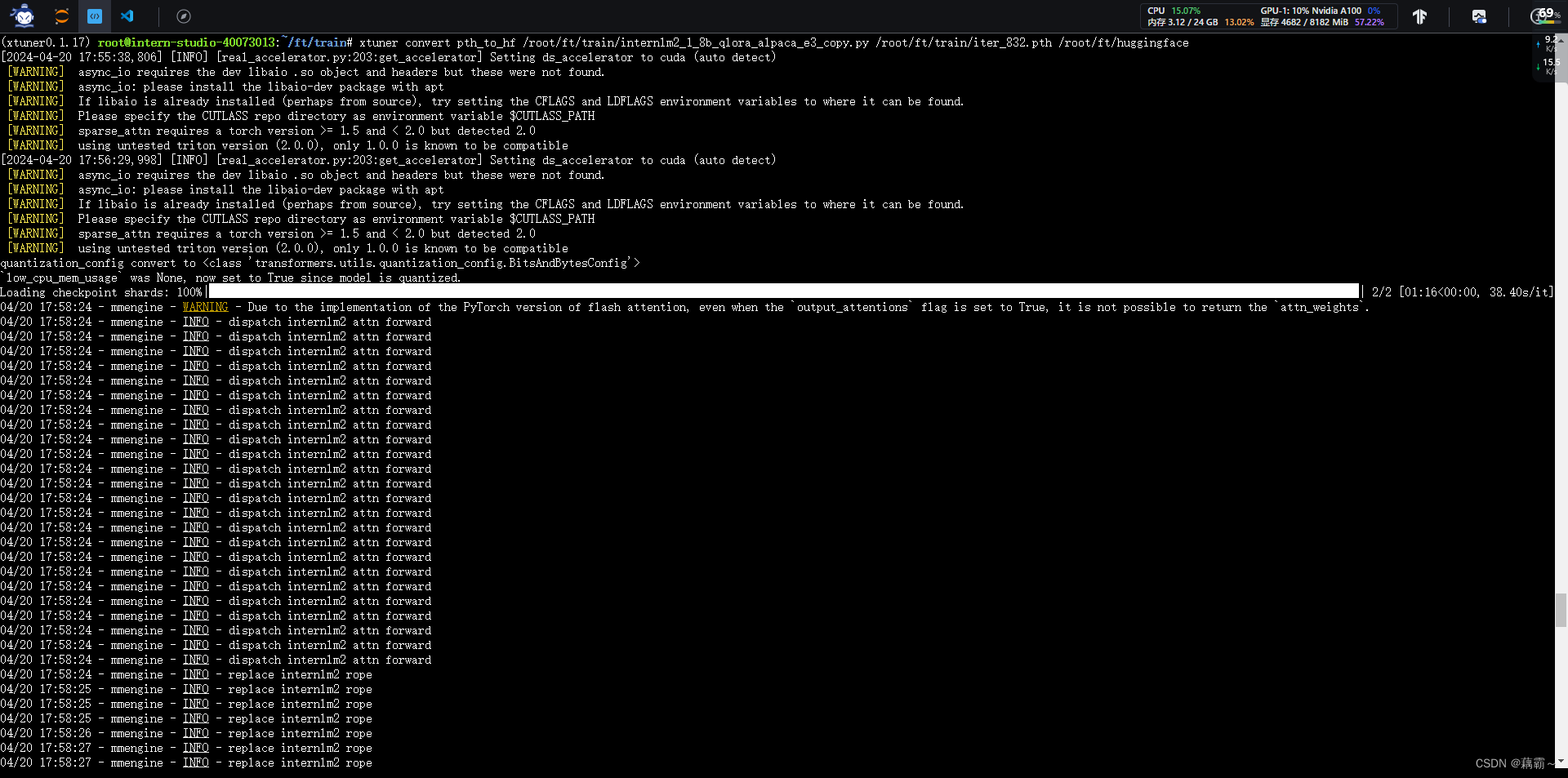
进行模型整合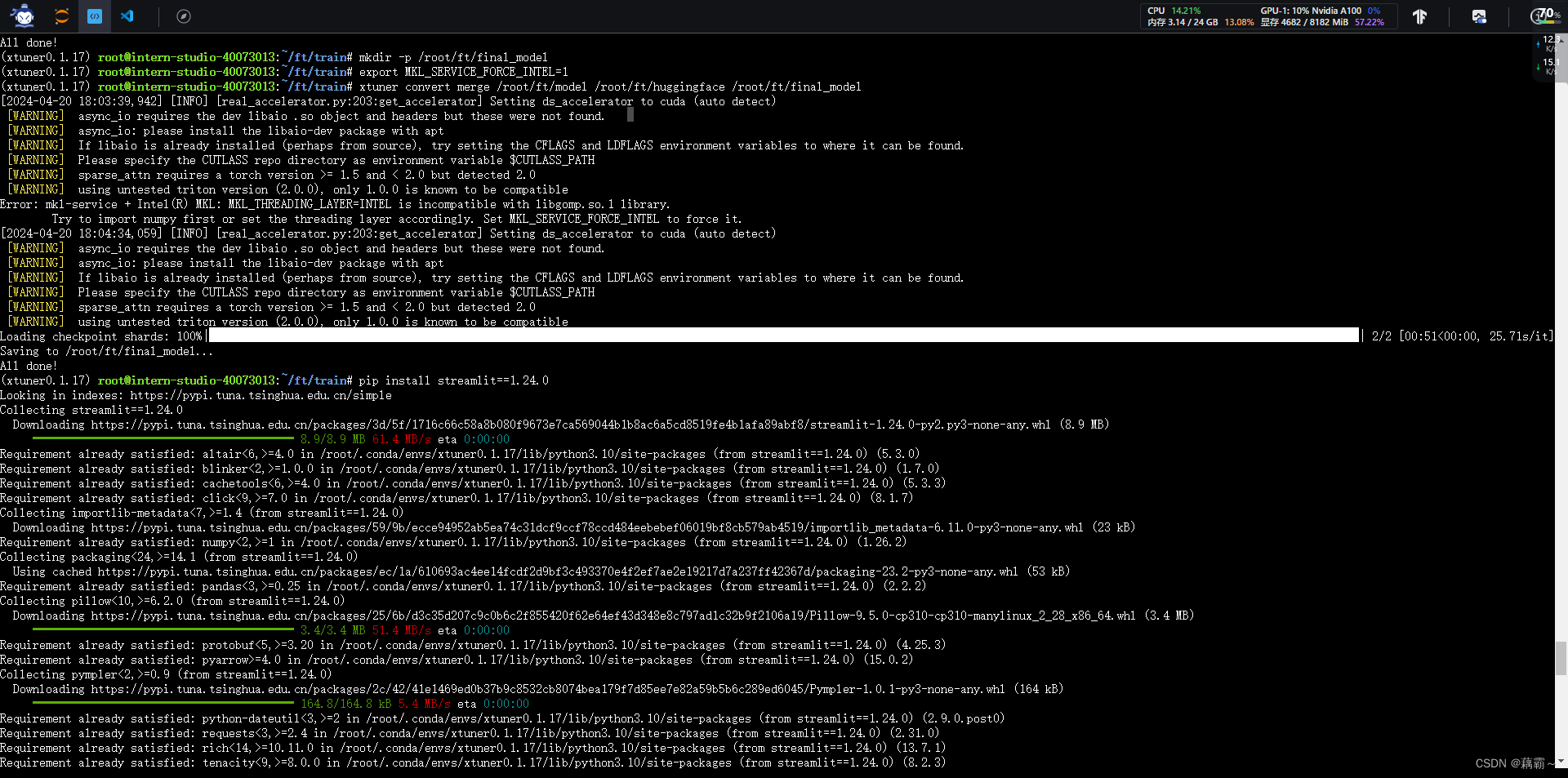
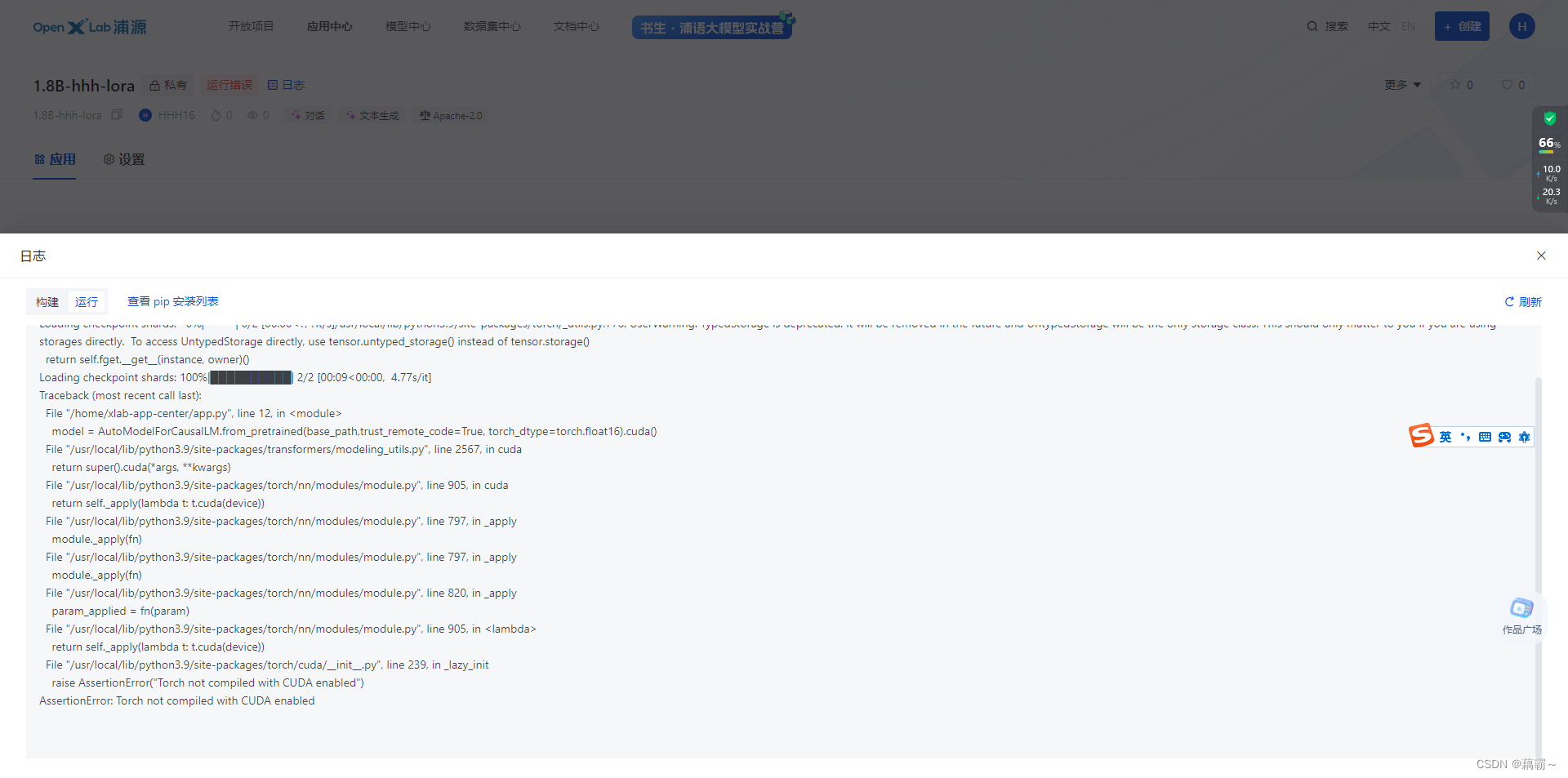
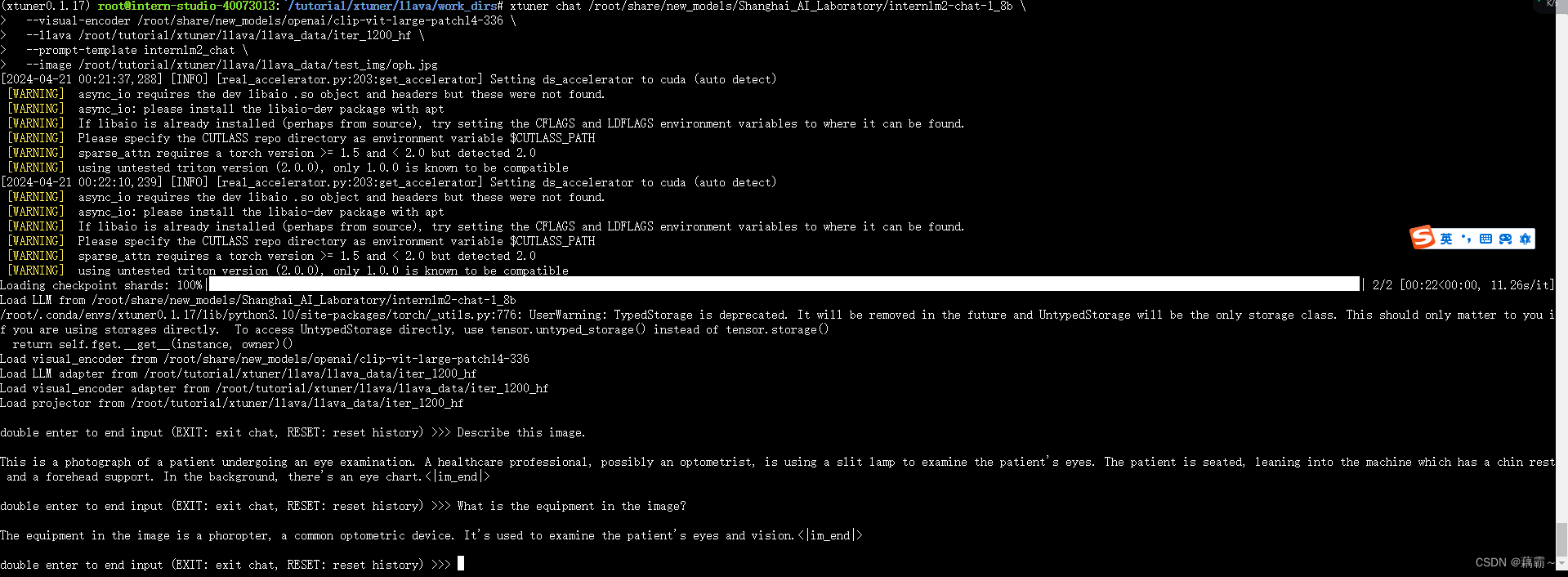
启动web版本
最终效果
- 微调工具Xtuner环境准备
















 645
645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









