






Note:
Click here to download the full example code
Working with Heterogeneous Graphs
Author: Quan Gan, Minjie Wang, Mufei Li, George Karypis, Zheng Zhang
在此教程中,我们将要学到以下内容:
- 异构图形数据的示例和典型应用。
- 在DGL中创建和处理异构图。
- 实现Relational-GCN(一种流行的GNN模型)以用于异构图形输入。
- 训练模型以解决节点分类任务。
异构图或简称为异形图,是包含不同类型的节点和边的图。 不同类型的节点和边缘倾向于具有不同类型的属性,这些属性旨在捕获每个节点和边缘类型的特征。 在图神经网络的上下文中,根据其复杂性,可能需要使用具有不同维数的表示来对某些节点和边类型进行建模。
通过使用异物图类及其关联的API,DGL支持在此类异质图上进行图神经网络计算。
异构图的实例
许多图形数据集表示各种类型的实体之间的关系。 本节概述了几个图形用例,这些用例显示了这种关系,并且可以将它们的数据表示为异形图。
引文图
计算机器协会发布了一个ACM数据集,其中包含200万篇论文,其作者,出版地点以及被引用的其他论文。 该信息可以表示为异构图。
下图显示了ACM数据集中的几个实体及其之间的关系(摘自Shi et al., 2015)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JSnwHzZH-1580472377665)(https://s3.us-east-2.amazonaws.com/dgl.ai/tutorial/hetero/acm-example.png#)]](https://i-blog.csdnimg.cn/blog_migrate/daef606fe3c9483152fb38d2a26983e4.png)
该图具有三种类型的实体,分别对应于论文,作者和发表会议。 它还包含连接以下内容的三种类型的边:
- 作者与论文相对应的关系
- 发表会议与论文相对应的关系
- 论文之间被引用的关系
推荐系统
推荐系统中使用的数据集通常包含用户和项目之间的交互关系。 例如,数据可以包括用户用来给电影进行评级,我们可以将这种交互关系建模为异位图。
这些异构图中有两种类型的节点:用户和电影。 边缘将用户和电影连接起来。 此外,如果一个交互标记有一个等级,则每个等级值可以对应于不同的边缘类型。 下图显示了作为异构图的用户-项目交互的实例。
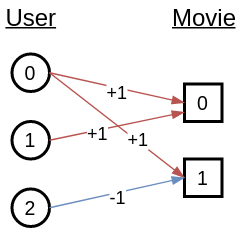
知识图谱
知识图在本质上是异构的。 例如,在维基数据中,Barack·Obama是人类的一个实例,其配偶是Michelle·Obama,而Barack·Obama的职业是政治家。 这些关系如下图所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UOEEgWen-1580472714728)(https://s3.us-east-2.amazonaws.com/dgl.ai/tutorial/hetero/kg-example.png)]](https://i-blog.csdnimg.cn/blog_migrate/986d791919c835e16722354384f306a0.png)
Creating a heterograph in DGL
您可以在DGL终使用API dgl.heterograph() 来创建一个异形图。dgl.heterograph()的参数是字典,其键为形式为(srctype, edgetype, dsttype),含义为(初始节点类型,边的类型,终止节点类型)。这样的元组称为规范边类型。其值是用于初始化图形结构(即,边实际连接到哪些节点)的数据。
例如,以下代码创建了前面显示的用户与项目交互的异形图。
#字典的每个值都是一个元组的列表。
# 节点是从零开始的整数ID。 不同类型的节点ID具有单独的计数。
import dgl
ratings = dgl.heterograph(
{('user', '+1', 'movie') : [(0, 0), (0, 1), (1, 0)],
('user', '-1', 'movie') : [(2, 1)]})
DGL支持从各种数据源创建图形。 以下代码创建与上面相同的图。
# 使用科学矩阵创建图形。
import scipy.sparse as sp
plus1 = sp.coo_matrix(([1, 1, 1], ([0, 0, 1], [0, 1, 0])), shape=(3, 2))
minus1 = sp.coo_matrix(([1], ([2], [1])), shape=(3, 2))
ratings = dgl.heterograph(
{('user', '+1', 'movie') : plus1,
('user', '-1', 'movie') : minus1})
print(plus1)
print()
print(minus1)
#使用networkx 图创建图形。
import networkx as nx
plus1 = nx.DiGraph()
plus1.add_nodes_from(['u0', 'u1', 'u2'], bipartite=0)
plus1.add_nodes_from(['m0', 'm1'], bipartite=1)
plus1.add_edges_from([('u0', 'm0'), ('u0', 'm1'), ('u1', 'm0')])
# 为了简化示例,重调用minus1对象。
# 这也意味着您可以为不同的关系使用不同的图形数据源。
ratings = dgl.heterograph(
{('user', '+1', 'movie') : plus1,
('user', '-1', 'movie') : minus1})
# 从边缘索引创建
ratings = dgl.heterograph(
{('user', '+1', 'movie') : ([0, 0, 1], [0, 1, 0]),
('user', '-1', 'movie') : ([2], [1])})
Out:
(0, 0) 1
(0, 1) 1
(1, 0) 1
(2, 1) 1
Manipulating heterograph
您可以使用ACM数据集创建更形象的异构图。 为此,请首先下载数据集,如下所示:
import scipy.io
import urllib.request
data_url = 'https://s3.us-east-2.amazonaws.com/dgl.ai/dataset/ACM.mat'
data_file_path = '/tmp/ACM.mat'
urllib.request.urlretrieve(data_url, data_file_path)
data = scipy.io.loadmat(data_file_path)
print(list(data.keys()))
Out:
['__header__', '__version__', '__globals__', 'TvsP', 'PvsA', 'PvsV', 'AvsF', 'VvsC', 'PvsL', 'PvsC', 'A', 'C', 'F', 'L', 'P', 'T', 'V', 'PvsT', 'CNormPvsA', 'RNormPvsA', 'CNormPvsC', 'RNormPvsC', 'CNormPvsT', 'RNormPvsT', 'CNormPvsV', 'RNormPvsV', 'CNormVvsC', 'RNormVvsC', 'CNormAvsF', 'RNormAvsF', 'CNormPvsL', 'RNormPvsL', 'stopwords', 'nPvsT', 'nT', 'CNormnPvsT', 'RNormnPvsT', 'nnPvsT', 'nnT', 'CNormnnPvsT', 'RNormnnPvsT', 'PvsP', 'CNormPvsP', 'RNormPvsP']
数据集按其类型存储节点信息:P代表文章,A代表作者,C代表会议,L代表主题代码,依此类推。 关系存储为键XvsY下的SciPy稀疏矩阵,其中X和Y可以是任何节点类型代码。
以下代码打印出一些有关论文作者关系的统计信息。
print(type(data['PvsA']))
print('#Papers:', data['PvsA'].shape[0])
print('#Authors:', data['PvsA'].shape[1])
print('#Links:', data['PvsA'].nnz)
Out:
<class 'scipy.sparse.csc.csc_matrix'>
#Papers: 12499
#Authors: 17431
#Links: 37055
在DGL中将此SciPy矩阵转换为异构图很简单。
pa_g = dgl.heterograph({('paper', 'written-by', 'author') : data['PvsA']})
# 等价于(较短)API,用于创建具有两种节点类型的异位图:
pa_g = dgl.bipartite(data['PvsA'], 'paper', 'written-by', 'author')
您可以轻松打印出类型名称和其他结构信息。
print('Node types:', pa_g.ntypes)
print('Edge types:', pa_g.etypes)
print('Canonical edge types:', pa_g.canonical_etypes)
# 节点和边被分配了从零开始的整数ID,每种类型都有自己的计数。
# 要区分不同类型的节点和边,请指定类型名称作为参数。
print(pa_g.number_of_nodes('paper'))
# 如果规范边缘类型名称是唯一可区分的,则可以将其简化为仅一个边缘类型名称。
print(pa_g.number_of_edges(('paper', 'written-by', 'author')))
print(pa_g.number_of_edges('written-by'))
print(pa_g.successors(1, etype='written-by')) # 获取ID为1的论文的作者
#pa_g.successors(v, etype='X')表示获取出发节点为v,边类型为‘X’的终止节点
# 只要行为明确,就可以省略类型名称参数。
print(pa_g.number_of_edges()) # 仅一种边缘类型,可以省略edge type参数
Out:
Node types: ['paper', 'author']
Edge types: ['written-by']
Canonical edge types: [('paper', 'written-by', 'author')]
12499
37055
37055
tensor([3532, 6421, 8516, 8560])
37055
同构图只是异种图的一种特殊情况,它只有一种类型的节点和边。 在这种情况下,所有API与DGLGraph中的API完全相同。
# 文章-引用-文章图是一个同构图
pp_g = dgl.heterograph({('paper', 'citing', 'paper') : data['PvsP']})
#等效于一下较简单的API
pp_g = dgl.graph(data['PvsP'], 'paper', 'cite')
# 所有ntype和etype参数都可以省略,因为行为是明确的。
print(pp_g.number_of_nodes())
print(pp_g.number_of_edges())
print(pp_g.successors(3))
Out:
12499
30789
tensor([1361, 2624, 8670, 9845])
使用论文作者,论文-论文和论文-主题关系创建ACM图的子集。 同时,还添加相反的关系以为后面的部分做准备。
G = dgl.heterograph({
('paper', 'written-by', 'author') : data['PvsA'],
('author', 'writing', 'paper') : data['PvsA'].transpose(),
('paper', 'citing', 'paper') : data['PvsP'],
('paper', 'cited', 'paper') : data['PvsP'].transpose(),
('paper', 'is-about', 'subject') : data['PvsL'],
('subject', 'has', 'paper') : data['PvsL'].transpose(),
})
print(G)
Out:
Graph(num_nodes={'paper': 12499, 'author': 17431, 'subject': 73},
num_edges={('paper', 'written-by', 'author'): 37055, ('author', 'writing', 'paper'): 37055, ('paper', 'citing', 'paper'): 30789, ('paper', 'cited', 'paper'): 30789, ('paper', 'is-about', 'subject'): 12499, ('subject', 'has', 'paper'): 12499},
metagraph=[('paper', 'author'), ('paper', 'paper'), ('paper', 'paper'), ('paper', 'subject'), ('author', 'paper'), ('subject', 'paper')])
元图(或网络结构图)是异构图的有用总结。 用作异位图的模板,它表明了网络中存在多少类型的对象以及可能存在的链接。
DGL提供了对元图的轻松访问,可以使用外部工具将其可视化。
# 使用 graphviz创建元图.
import pygraphviz as pgv
def plot_graph(nxg):
ag = pgv.AGraph(strict=False, directed=True)
for u, v, k in nxg.edges(keys=True):
ag.add_edge(u, v, label=k)
ag.layout('dot')
ag.draw('graph.png')
plot_graph(G.metagraph)
Learning tasks associated with heterographs
涉及异构图的一些典型学习任务包括:
- 节点分类和回归以预测每个节点的类或估计与之关联的值。
- 链接预测以预测在一对节点之间是否存在某种类型的边缘,或预测特定节点与哪些其他节点连接(以及此类连接的边缘类型)。
- 图形分类/回归将整个异位图分配给目标类别之一或估计与之相关的数值。
在本教程中,我们为第一个任务设计了一个简单的示例。
A semi-supervised node classification example
我们的目标是使用我们刚创建的ACM学术图来预测论文的出版会议。 为了进一步简化任务,我们仅关注在三个会议上发表的论文:KDD,ICML和VLDB。 其他所有文章均未标记,因此成为半监督设置。
以下代码从原始数据集中提取这些论文,并准备训练,验证和测试拆分。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
pvc = data['PvsC'].tocsr()
# 找到所有在 KDD, ICML, VLDB三个会议论文上发表的文章
c_selected = [0, 11, 13] # 三个数字分别代表KDD, ICML, VLDB
p_selected = pvc[:, c_selected].tocoo()
# 生成标记
labels = pvc.indices
labels[labels == 11] = 1
labels[labels == 13] = 2
labels = torch.tensor(labels).long()
# 拆分产生训练集、验证集和测试集
pid = p_selected.row
shuffle = np.random.permutation(pid)
train_idx = torch.tensor(shuffle[0:800]).long()
val_idx = torch.tensor(shuffle[800:900]).long()
test_idx = torch.tensor(shuffle[900:]).long()
Relational-GCN on heterograph
我们使用Relational-GCN来学习图中的节点表示。 其消息传递方程式如下:
h
i
(
l
+
1
)
=
σ
(
∑
r
∈
R
∑
j
∈
N
r
(
i
)
W
r
(
l
)
h
j
(
l
)
)
h_i^{(l+1)} = \sigma\left(\sum_{r\in \mathcal{R}} \sum_{j\in\mathcal{N}_r(i)}W_r^{(l)}h_j^{(l)}\right)
hi(l+1)=σ
r∈R∑j∈Nr(i)∑Wr(l)hj(l)
分解方程式,您会发现计算包含两个部分:
- 每种关系 r r r内的消息计算和聚合
- 归约合并来自多种关系的结果
按照这种原理,在异位图上执行消息传递共分两个步骤。
- 每种边缘类型的消息传递
- 多种类型的信息归约聚合
import dgl.function as fn
class HeteroRGCNLayer(nn.Module):
def __init__(self, in_size, out_size, etypes):
super(HeteroRGCNLayer, self).__init__()
# W_r for each relation
self.weight = nn.ModuleDict({
name : nn.Linear(in_size, out_size) for name in etypes
})
def forward(self, G, feat_dict):
#input输入是每一种节点特征的字典
funcs = {}
for srctype, etype, dsttype in G.canonical_etypes:
# 计算 W_r * h
Wh = self.weight[etype](feat_dict[srctype])
# 将其存入图中以便于信息传递
G.nodes[srctype].data['Wh_%s' % etype] = Wh
# 指定每个关系的消息传递函数:(message_func,reduce_func)。
# 请注意,结果将保存到相同的目标特征“ h”,这暗示了聚合的类型明智的约简。
funcs[etype] = (fn.copy_u('Wh_%s' % etype, 'm'), fn.mean('m', 'h'))
# 触发多种类型的消息传递。
# 第一个参数是每个关系的消息传递函数(message passing functions)
# 第二个是类型明智的reduce functions,可以是“ sum”,“ max”,“ min”,“ mean”,“ stack”
G.multi_update_all(funcs, 'sum')
# 返回更新的节点特征(以字典形式表示)
return {ntype : G.nodes[ntype].data['h'] for ntype in G.ntypes}
通过堆叠两个HeteroRGCNLayer创建一个简单的GNN。 由于节点不具有输入功能,因此使其嵌入可训练。
class HeteroRGCN(nn.Module):
def __init__(self, G, in_size, hidden_size, out_size):
super(HeteroRGCN, self).__init__()
# 使用可训练的节点嵌入作为无特征输入。
embed_dict = {ntype : nn.Parameter(torch.Tensor(G.number_of_nodes(ntype), in_size))
for ntype in G.ntypes}
for key, embed in embed_dict.items():
nn.init.xavier_uniform_(embed)
self.embed = nn.ParameterDict(embed_dict)
# 创建神经网络层
self.layer1 = HeteroRGCNLayer(in_size, hidden_size, G.etypes)
self.layer2 = HeteroRGCNLayer(hidden_size, out_size, G.etypes)
def forward(self, G):
h_dict = self.layer1(G, self.embed)
h_dict = {k : F.leaky_relu(h) for k, h in h_dict.items()}
h_dict = self.layer2(G, h_dict)
#获取文章预测结果
return h_dict['paper']
Train and evaluate
训练和评估该网络。
# 创建模型. 模型有三个输出,分别对应任务中的三个会议
model = HeteroRGCN(G, 10, 10, 3)
opt = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
best_val_acc = 0
best_test_acc = 0
for epoch in range(100):
logits = model(G)
# 仅针对标记节点计算损失。
loss = F.cross_entropy(logits[train_idx], labels[train_idx])
pred = logits.argmax(1)
train_acc = (pred[train_idx] == labels[train_idx]).float().mean()
val_acc = (pred[val_idx] == labels[val_idx]).float().mean()
test_acc = (pred[test_idx] == labels[test_idx]).float().mean()
if best_val_acc < val_acc:
best_val_acc = val_acc
best_test_acc = test_acc
opt.zero_grad()
loss.backward()
opt.step()
if epoch % 5 == 0:
print('Loss %.4f, Train Acc %.4f, Val Acc %.4f (Best %.4f), Test Acc %.4f (Best %.4f)' % (
loss.item(),
train_acc.item(),
val_acc.item(),
best_val_acc.item(),
test_acc.item(),
best_test_acc.item(),
))
Out:
Loss 1.0744, Train Acc 0.5125, Val Acc 0.5000 (Best 0.5000), Test Acc 0.5034 (Best 0.5034)
Loss 0.9467, Train Acc 0.5138, Val Acc 0.5000 (Best 0.5000), Test Acc 0.5034 (Best 0.5034)
Loss 0.7998, Train Acc 0.5938, Val Acc 0.5200 (Best 0.5200), Test Acc 0.5142 (Best 0.5142)
Loss 0.5926, Train Acc 0.8863, Val Acc 0.7200 (Best 0.7200), Test Acc 0.6692 (Best 0.6692)
Loss 0.3870, Train Acc 0.9488, Val Acc 0.7100 (Best 0.7500), Test Acc 0.7538 (Best 0.7504)
Loss 0.2405, Train Acc 0.9650, Val Acc 0.7400 (Best 0.7500), Test Acc 0.7638 (Best 0.7504)
Loss 0.1557, Train Acc 0.9750, Val Acc 0.7400 (Best 0.7500), Test Acc 0.7739 (Best 0.7504)
Loss 0.1103, Train Acc 0.9762, Val Acc 0.7500 (Best 0.7500), Test Acc 0.7806 (Best 0.7504)
Loss 0.0838, Train Acc 0.9775, Val Acc 0.7600 (Best 0.7600), Test Acc 0.7781 (Best 0.7806)
Loss 0.0646, Train Acc 0.9850, Val Acc 0.7600 (Best 0.7600), Test Acc 0.7789 (Best 0.7806)
Loss 0.0504, Train Acc 0.9950, Val Acc 0.7400 (Best 0.7600), Test Acc 0.7781 (Best 0.7806)
Loss 0.0405, Train Acc 1.0000, Val Acc 0.7700 (Best 0.7700), Test Acc 0.7772 (Best 0.7781)
Loss 0.0342, Train Acc 1.0000, Val Acc 0.7700 (Best 0.7800), Test Acc 0.7764 (Best 0.7764)
Loss 0.0292, Train Acc 1.0000, Val Acc 0.7700 (Best 0.7800), Test Acc 0.7730 (Best 0.7764)
Loss 0.0252, Train Acc 1.0000, Val Acc 0.7600 (Best 0.7800), Test Acc 0.7730 (Best 0.7764)
Loss 0.0222, Train Acc 1.0000, Val Acc 0.7800 (Best 0.7800), Test Acc 0.7739 (Best 0.7764)
Loss 0.0199, Train Acc 1.0000, Val Acc 0.7700 (Best 0.7800), Test Acc 0.7714 (Best 0.7764)
Loss 0.0181, Train Acc 1.0000, Val Acc 0.7600 (Best 0.7800), Test Acc 0.7688 (Best 0.7764)
Loss 0.0168, Train Acc 1.0000, Val Acc 0.7600 (Best 0.7800), Test Acc 0.7672 (Best 0.7764)
Loss 0.0157, Train Acc 1.0000, Val Acc 0.7600 (Best 0.7800), Test Acc 0.7621 (Best 0.7764)
What’s next?
- 在此处查看我们在PyTorch中的完整实现。
- 完整的异构图API参考。
- 我们还提供以下模型示例:
图卷积矩阵完成https://arxiv.org/abs/1706.02263 _,我们在MXNet中实现。
异构图注意力网络需要根据给定的元路径(即由边类型组成的路径模板)将异位图转换为同类图。 我们提供dgl.transform.metapath_reachable_graph()来执行此操作。 在此处查看完整的实现。
Metapath2vec需要根据给定的元路径生成随机的行走路径。 请在此处参考完整的metapath2vec实现。
Total running time of the script: ( 0 minutes 7.850 seconds)
下载完整代码:5_hetero.py
下载完整代码:5_hetero.ipynb

















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









