






ACU2E-Net:一种用于超声图像中软组织结构分割的新型预测-细化注意网络
摘要:
超声图像中解剖结构的分割是一项具有挑战性的任务,因为存在散斑噪声、衰减、阴影、纹理不均匀和边界模糊等伪影继承于模态。本文提出了一种新的基于注意力的预测-细化网络,称为ACU2E-Net,用于超声图像中软组织结构的分割。该网络由两个模块组成:一个预测模块,它建立在我们新提出的关注坐标卷积的基础上;提出了一种新型的多头残差细化模块,该模块由三个并行残差细化模块组成。注意坐标卷积通过感知目标解剖结构的形状和位置信息来提高分割精度。提出的多头残差细化模块通过残差细化和集成策略的结合,减少了分割偏差和方差。此外,它避免了集成方法中常见的多遍训练和推理。为了证明我们方法的有效性,我们从12个不同的成像中心收集了甲状腺超声扫描的综合数据集,并将我们提出的网络与最先进的分割方法进行了评估。与最先进的模型进行比较,证明了我们新设计的网络在甲状腺横切面和矢状面图像上的竞争力。消融研究表明,所提出的模块将基线模型的分割Dice得分从79.62%提高到80.97%和82.92%,同时将横向和矢状面的方差分别从6.12%降低到4.67%和3.21%。
1 介绍
医学超声成像是一种安全、无创的实时成像方式,利用高频声波提供人体结构图像。与其他成像方式相比,如计算机断层扫描(CT)和磁共振成像(MRI),超声成像便宜,便携,更普遍。然而,超声图像是从手持探头获得的,因此依赖于操作员,并且容易受到许多伪影的影响,例如重斑点噪声,阴影和模糊的边界。这增加了从邻近组织中分割感兴趣的解剖结构的困难。
许多非深度学习模型(例如:活动轮廓[1,2]、图切[3]和超像素[4])和深度学习模型(如卷积神经网络(CNN)[5]、全连接网络(FCN)[6]、U-Net[7]及其变体[8,9])已经被提出并应用于超声图像分割。然而,由于超声图像的噪声特性,常规方法通常产生较差的结果。尽管与传统方法相比,深度模型已经取得了很大的进步,但从超声图像中准确分割软组织结构仍然是一项具有挑战性的任务[10]。与一般物体在自然图像分割中具有不同的形状和位置不同,超声中的解剖结构图像具有相似的位置和形状模式。然而,这些几何特征在分割深度模型中很少使用,因为它们难以表示和编码[11]。由于超声图像质量相对较低,这变得更加成问题,这进一步增加了在不同组织中区分这些几何结构的难度,从而使甲状腺叶等软组织的测量容易受到主观人为误差的影响[10]。
当考虑使用单一深度学习模型对超声图像进行分割时,由于边界和纹理模糊,它产生的分割预测具有高偏差,并且由于其噪声和异质性而产生高方差。为了解决这个问题,引入了多模型集成方法[12],包括bagging和boosting技术[13]。然而,训练多个模型进行集成在计算上是昂贵的。为了解决计算成本问题,提出了快照集成等方法[14],该方法通过一次训练模型,同时通过学习率退火技术节省了优化路径上的多组模型权值。但是,这种方法仍然需要多次运行推理过程。为了解决这个问题,许多多级预测-细化深度模型(如HourglassNet[15]、Connected U-Net (U-Net)[16]、Recurrent Residual Refinement network (R3Net)[17]和Boundary Aware Saliency object detection network (BAS-Net)[18])被开发出来,通过它们的级联模块来预测和逐步细化分割结果。这种策略能够减少分割偏差,但对方差的影响有限,这意味着它们在整个数据集上的平均性能可能很好,但它们不太可能对不同的输入图像产生稳定的预测。
为了克服这些挑战,我们提出了一种新的基于注意力的预测-细化架构ACU2E-Net,它由基于我们新提出的注意力坐标卷积(AC-Conv)和多头残差细化模块(MH-RRM)块构建的预测模块组成。我们提出的模型利用超声图像中存在的解剖位置和形状约束来减少分割结果的偏差和方差,同时避免了多次训练和推理。总之,本文的贡献有两个方面:(a)一种新的关注坐标卷积,通过感知超声图像的几何(例如形状和位置)信息来提高分割精度;(b)基于多头残差细化模块的预测-细化ACU2E-Net结构,将集成思想与预测-细化策略相结合,提高了分割精度。我们在从12个参与中心收集的甲状腺超声扫描的综合数据集上测试了我们的方法,并与现有模型相比取得了最先进的性能。
本文的其余部分组织如下。第2节描述了所提出方法的网络架构,第3节给出了实验结果。第四部分是本文的结束语和今后的工作方向。
2 提出的方法
2.1网络体系结构
我们新提出的ACU2E-Net网络架构如图1所示。我们的ACU2E-Net由两个主要部分组成:一个预测模块,ACU2-Net,和一个多头残差细化模块,MH-RRM。预测模块改编自U2-Net[19],用我们新提出的AC-Conv取代了普通卷积层。细化模块由ACU2-Net的一组并行排列的变体组成。更具体地说,MH-RRM被配置为具有三个看起来像“E”字符的细化头(参见图1的右侧,因此被命名为E- module)。表1说明了我们提出的ACU2E-Net中子网的详细配置。表1中的空白细胞表明没有这样的阶段。

图1。ACU2E网络的架构。它由两个主要组件组成:(左)预测模块ACU2 Net,它是从U2 Net改编而来的,用我们新提出的AC Conv代替了普通卷积;(右)E模块:多头残差细化模块,由三个并行排列的ACU2-Net变体组成:ACU2-Net-Ref7、ACU2-Net-Ref5和ACU2-Nt-Ref3。术语AC-CBR表示AC Conv+BacthNorm+ReLU。
表1 我们新提出的ACU2E-Net子网络的详细配置。其中,'I'、'M'和'O'表示每个AC-RSU块的输入通道数(𝐶𝑖𝑛)、中间通道数和输出通道数(𝐶𝑜𝑢𝑡)。'En_i'和'De_j'分别表示编码器和解码器阶段。在'AC-RSU-𝐿'中的数字'𝐿'表示我们的注意力坐标引导残差U块的高度。

2.2. 注意坐标引导卷积
在超声图像中,像甲状腺这样的软组织结构似乎具有可预测的位置和形状模式,可以用来辅助分割过程。Liu等人提出了坐标卷积(CoordConv)[20],如图2(a)所示,用来解决坐标变换问题。给定输入特征图 𝑀𝑖𝑛(ℎ × 𝑤 × 𝑐),CoordConv 可以描述为 𝑀𝑜𝑢𝑡 = 𝑐𝑜𝑛𝑣(𝑐𝑎𝑡(𝑀𝑖𝑛, 𝑀𝑖, 𝑀𝑗)),其中 𝑀𝑖 和 𝑀𝑗 分别表示行和列坐标映射。然而,由于不同层次的特征上的坐标映射(𝑀𝑖, 𝑀𝑗)几乎是恒定的,将它们直接与不同层次的特征图 𝑀𝑖𝑛 连接在一起可能会降低网络的泛化能力,因为它们对应的卷积权重负责同步其值尺度与特征图 𝑀𝑖𝑛 以及提取几何信息。为解决这个问题,我们提出了图2(b)中显示的 AC-Conv 块。我们的 AC-Conv 在特征图和坐标映射连接之前添加了一种类似于空间注意力的操作: 𝑀𝑜𝑢𝑡 = conv(cat(𝑀𝑖𝑛, Sig(conv(𝑀𝑖𝑛)) ⋅ cat(𝑀𝑖, 𝑀𝑗))) (1) 其中 Sig(⋅) 是 Sigmoid 函数。

图2。(a)原始Coord-Conv和(b)我们提出的AC-Conv的结构。
这个类似于空间注意力的操作在这里起到两个作用:(i) 作为一个同步层,减小了 𝑀𝑖𝑛 与{𝑀𝑖, 𝑀𝑗}之间的尺度差异;(ii) 重新加权每个像素的坐标,而不是使用常数坐标映射,以在当前输入特征图的注意力图的引导下捕捉更重要的几何信息。
然后,我们通过将U2-Net中使用的残差U块(RSU)中的卷积层替换为我们新提出的AC-Conv,构建了我们的注意力坐标引导的RSU,因此命名为AC-RSU。与原始RSU相比,我们的AC-RSU能够从不同的感受野中提取纹理和几何特征。因此,我们的预测模块ACU2-Net(图1左侧)以及细化E模块中的三个子网络ACU2-Net-Ref7、ACU2-Net-Ref5和ACU2-Net-Ref3(图1右侧)都是基于提出的AC-RSU构建的。
2.3.并行多头残差细化模块
为了进一步提高准确性,许多预测-精炼模型,如Stacked HourglassNet [15]、R3-Net [17]、Stagewise Refinement Model (SRM) [21]和BAS-Net [18],都被设计成通过级联的子网络递归或渐进地精炼粗略结果:𝑃𝑐 = 𝐹𝑝(𝑋), 𝑃1r = 𝐹1r(𝑃𝑐),..., 𝑃nr = 𝐹nr(𝑃n-1r),如图3(a)所示。理论上,最后的输出𝑃nr是最准确的,因此通常被视为最终结果。这种级联的精炼策略能够减少分割结果的偏差。然而,在实践中,来自这种网络的超声图像分割结果通常由于图像质量较低和甲状腺边界模糊而具有较大的方差。多模型集成策略 [22] 可以用来减少预测偏差和方差。然而,直接集成多个深度模型需要大量计算和时间成本。因此,我们提出将集成策略嵌入到精炼模块中。

图3。(a)级联细化模块和(b)并行细化模块的说明。粗体表示最终结果。
具体来说,我们设计了一个简单而有效的并行多头残差精炼模块,即MH-RRM。本文中MH-RRM的头数设置为三个 {𝐹1𝑟, 𝐹2𝑟, 𝐹3𝑟},如图1右侧所示。然后,给定输入图像𝑋,我们模型的最终分割结果可以描述为𝑃𝑟 = 𝑎𝑣𝑔(𝑃1𝑟, 𝑃2𝑟, 𝑃3𝑟),其中𝑃𝑐 = 𝐹𝑝(𝑋),𝑃1𝑟 = 𝐹1𝑟(𝑃𝑐),𝑃2𝑟 = 𝐹2𝑟(𝑃𝑐),𝑃3𝑟 = 𝐹3𝑟(𝑃𝑐)。图3(b)展示了我们新提出的预测-精炼体系结构与并行精炼模块的语义工作流程。正如我们所看到的,级联精炼模块,如图3(a),和并行精炼模块,如图3(b),可以分别与“提升”和“装袋” [13] 的概念相关联。
2.4 训练和推理
在训练过程中,E模块的三个精炼输出𝑅(1), 𝑅(2)和𝑅(3)将与独立计算的损失一起进行监督,同时还有来自预测模块的七个侧面输出𝑆(𝑖) (𝑖 = {1, 2, 3, 4, 5, 6, 7}) 和一个融合输出𝑆𝑓𝑢𝑠𝑒,如图1所示。整个模型使用定义为二进制交叉熵(BCE)的损失进行端到端训练,定义如下:

其中𝐿是总损失,𝐿𝑆(𝑖), 𝐿𝑆(𝑓𝑢𝑠𝑒)和𝐿𝑅(𝑗)是侧面输出、融合输出和精炼输出的相应损失。𝜆𝑆(𝑖), 𝜆𝑆(𝑓𝑢𝑠𝑒)和𝜆𝑅(𝑗)是它们的相应权重,用于强调不同的输出。在我们的实验中,所有的权重𝜆都被设置为1.0。在推理步骤中,取𝑅(1), 𝑅(2)和𝑅(3)的平均值作为最终的预测结果。
3.实验结果
作为一个案例研究,我们评估了我们提出的模型在超声扫描中甲状腺组织分割问题上的性能。
3.1、甲状腺超声
甲状腺是位于锁骨正上方颈部基部的一个蝴蝶状器官,左右叶由中间一条称为峡部的狭窄组织连接(见图4)。
甲状腺超声检测是可视化或观察甲状腺以诊断甲状腺异常的最常见方法[23]。作为常规甲状腺超声工作流程的一部分,临床医生依次扫描甲状腺的左叶和右叶。对每一侧的扫描包括在横向(TRX)平面上的扫描(如图4(a)所示)和在矢状(SAG)平面上进行的扫描(见图4(b))。作为甲状腺诊断的一部分,临床医生在TRX和SAG扫描中手动测量甲状腺的大小。为了做到这一点,临床医生翻阅TRX和SAG扫描的所有帧,手动定位/分割甲状腺,并测量TRX和SAG视图的最大尺寸[24]。这是一项高认知负荷、耗时的任务。因此,需要提供一种自动化的方法,从组织体积的超声扫描中分割甲状腺(和一般的解剖结构),以克服或至少改进这种手动过程。
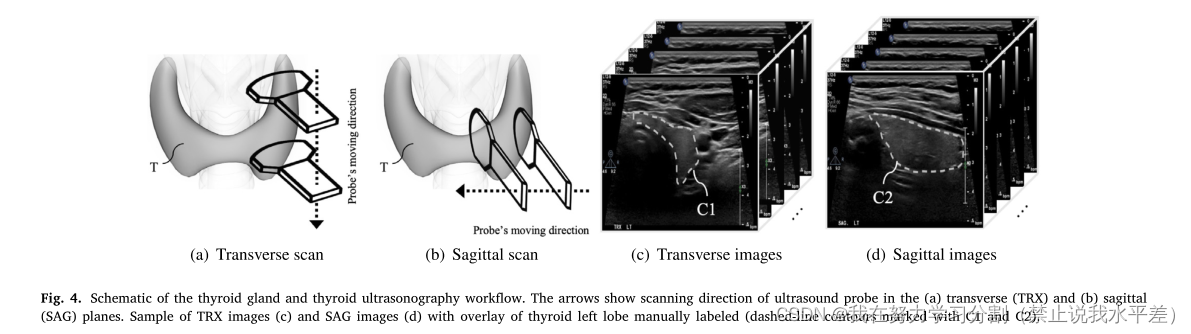
图4所示。甲状腺示意图和甲状腺超声检查工作流程。箭头表示超声探头在(a)横切面(TRX)和(b)矢状面(SAG)的扫描方向。TRX图像(c)和SAG图像(d)的样本,手动标记甲状腺左叶覆盖(虚线轮廓标记为C1和C2)。
3.2 甲状腺的数据集
据我们所知,现有的公共甲状腺数据集都不适合大规模的基于学习的方法。例如,DDTI[25]数据集只包含480张图像。这个数据集是专门为结节分类设计的,其中大多数图像被裁剪并且只包含部分甲状腺组织。另一个例子是MICCAI[26]的TN-SCUI2020挑战,该挑战主要为结节分割提供数据集。TN-SCUI2020图像也被裁剪,并且禁止使用挑战之外的数据[27]。open- cas上的另一个公共数据集,一个用于验证和基准化计算机辅助手术系统的开放数据集集合[28]。它在横向上仅由16个dicom组成。这些数据集都不适合大规模临床应用。为了解决这个问题,我们从一个卫生区域内的12个成像中心收集了一个全面的甲状腺超声数据集。更具体地说,回顾性收集了700例年龄在18-82岁(平均49.6±14.9)岁之间的患者的777次超声扫描,这些患者在成像中心接受甲状腺超声检查。我们的回顾性研究得到了参与中心的健康研究伦理委员会的批准。
扫描分为:(1)TRX数据集和(2)SAG数据集。每个数据集被分成三个子集,分别用于训练、验证和测试。表2说明了每个子集中的卷数量和相应的片。为了保证结果的可泛化性和适当的数据分离,在训练开始前,将属于这100个患者的图像作为一个保留集,仅用于测试数据,以确保在训练集、验证集和测试集中没有共同的患者。图像是从GE和Philips的800 × 600或1024 × 768或1054 × 802超声设备获取的多帧图像中提取的。数据集中多帧图像的frameCount在80 ~ 395帧之间。这些图像由5名经验丰富的超声技师(具有≥5年甲状腺超声检查经验)手动标记,并由3名放射科医生进行验证。为了节省标记时间,训练集中的超声扫描每隔三到五片标记一次。但是验证集和测试集是逐片标记的,以便进行准确的体积评估。在本文中,我们基于TRX和SAG对应的二维图像标记训练了两种不同的甲状腺分割模型。在验证和测试中,逐片获得分割掩码,然后串联在一起进行体积评估。
表2甲状腺数据集中TRX和SAG甲状腺扫描次数。“Vol#”和“Slice#”分别表示卷的数量及其对应的标记切片。

3.3. 评价指标
体积Dice分数(以下简称𝐷𝑖𝑐𝑒)[29]及其标准偏差(标记为𝜎)被用作评估我们方法的整体性能的度量标准。具体而言,Dice分数定义如下:
𝐷𝑖𝑐𝑒 = 2 ∗ |𝑃 ∩ 𝐺| |𝑃 | + |𝐺| (3)
其中,𝑃是大小为(ℎ × 𝑤 × 𝑐)的扫描体积的预测分割掩模,𝐺是大小为(ℎ × 𝑤 × 𝑐)的甲状腺扫描的地面真相掩模。Dice分数的值范围在0到1之间,值越高表示分割性能越好。
Dice分数越高表示性能越好。Dice分数的标准偏差计算如下:
𝜎 = √ 1 𝑁 𝛴𝑁 𝑖=1(𝐷𝑖𝑐𝑒𝑖 − 𝐷𝑖𝑐𝑒𝜇 ) (4)
其中,𝑁是测试体积的数量,而𝐷𝑖𝑐𝑒𝜇表示整个测试集的平均体积Dice分数。本文中,每个测试集的平均Dice分数(𝐷𝑖𝑐𝑒)以及标准偏差(𝜎)都会被报告。
3.4. 本文提出的神经网络模型
使用PyTorch 1.12.0[30]实现。我们使用指定的训练、验证和测试集来评估我们模型的性能。在训练过程中,首先将输入图像的大小调整为160 × 160 × 3,然后随机裁剪为144 × 144 × 3。使用在线随机水平和垂直翻转来扩充数据集。训练批大小设置为12。模型权重初始化采用默认的He统一初始化[31]。使用Adam优化器[32],学习率为1e-3,没有权重衰减。训练损失在5万次迭代后收敛,耗时约24小时。在测试过程中,输入图像被调整为160 × 160 × 3的大小,并输入到模型中。下采样和上采样均采用双线性插值。我们的培训和测试过程都是在12核,24线程PC上进行的,配备AMD Ryzen Threadripper 2920x 4.3 GHz CPU (128 GB RAM)和NVIDIA GTX 1080 Ti GPU。
3.5. 消融研究
3.5.1 为了验证我们的AC-Conv的有效性,我们将改编后的U2-Net中的plain Conv (plain Conv)[33]替换为以下变体来进行消融研究:SE-Conv[34]通过其挤压和激励块显式地建模通道相互依赖性,CBAM-Conv[35]通过其通道和空间注意块来细化特征映射,CoordConv[20]通过使用坐标通道使卷积访问其自己的输入坐标,以及我们的AC-Conv。TRX测试集的结果显示在表3的顶部(前五行)。正如我们所看到的,我们使用AC-Conv的ACU2-Net(表3的第五行)在Dice得分和标准偏差휎方面给出了最好的结果。这进一步表明,联合感知几何和空间信息的策略比单独的基于空间注意力(CBAM)或基于坐标(CoordConv)的方法更有效。
表3 不同卷积块和细化架构的消融研究。Ref7是CU2-Net-Ref7的缩写。实验在TRX甲状腺检测仪上进行。红色、绿色和蓝色表示最佳、第二和第三最佳的表现。进行两两t检验并报告p值。

3.5.2. MH-RRM(E模块)
为验证我们的MH-RRM(E模块)的性能,我们还进行了不同精炼配置的消融研究,包括级联RRM Ref3(Ref5(Ref7))、具有相同RRM分支的并行RRM avg(Ref𝑘,Ref𝑘,Ref𝑘) {𝑘 = 3, 5, 7} 和融合的并行RRM conv(Ref7, Ref5, Ref3),在推理中,将并行精炼输出通过卷积层融合,而不是进行平均。表3的底部显示了关于RRM的消融结果,表明级联RRM、具有相同分支的并行RRM以及融合的并行RRM都不如我们提出的MH-RRM。基于TRX数据集上的消融研究性能,我们评估了TRX和SAG数据集的最佳模型,这在表4中呈现。
3.6. 与最先进技术的比较
我们将我们的ACU2E-Net与其他11个最先进(SOTA)模型进行比较,包括U-Net [7]及其五个变种,Res U-Net [36],Dense U-Net [37],Attention U-Net [8],U-Net++ [9]和U2-Net [19],以及包括Stacked HourglassNet [15],Stagewise Refinement Model (SRM)[21],C-U-Net [16],R3-Net [17]和BASNet [18]在内的五个预测-精炼模型。
3.6.1. 定量比较
表4显示了我们的ACU2E-Net与其他最先进(SOTA)模型的定量比较。表的顶部部分包括与经典的U-Net及其变种(如Attention U-Net)的比较,而表的底部部分显示了与涉及预测-精炼策略的模型(如R3-Net)的比较。可以观察到我们提出的ACU2E-Net在TRX和SAG图像上均获得了最高的Dice分数。此外,我们提出的并行精炼模块大大提高了Dice分数,分别在TRX和SAG数据集中将其与基准U-Net模型相比提高了5.6%和5.35%,并将标准偏差𝜎分别降低了2.66%和1.35%。对于原始的U2-Net模型,单帧的推理时间为0.0170秒,而对于提出的ACU2Net,推理时间为0.0354秒。网络的性能和复杂性与在表5中显示的基线模型进行了比较。
总的来说,与基线U2-Net相比,我们可以观察到由于提出的Attentive CoordConv,Dice分数提高了1.63%,再加上多头模块带来的额外2.05%的提高。类似地,IoU从基线到Attentive CoordConv提高了2.30%,从Attentive CoordConv到MH-RRM提高了3.0%。

分别为完整模型。尽管计算时间有所增加,但所提出的方法在骰子得分和IoU指标方面提供了更准确的结果。
3.6.2. 为了进一步评估我们模型的稳健性,我们在图5中绘制了我们的模型和其他11个SOTA模型的成功率曲线[38]。
成功率定义为扫描预测次数(分数高于某些骰子阈值)与总扫描次数的比率。成功率越高表示性能越好,因此顶部曲线(ACU2E-Net)优于其他曲线。正如我们所看到的,我们提出的ACU2E-Net在TRX和SAG测试集上都以较大的边际优于其他模型。为了进一步评估我们的分割方法的鲁棒性,我们在开放cas[28]上的公共数据集上测试了ACU2E-Net(在我们的内部数据集上训练)。该数据集由16个横向视图的dicom组成,并由医学专家提供地面真相。将[28]中提出的所有方法的骰子得分指标与我们提出的模型(包括基线U2Net、ACU2-Net (AttentionCoordConv)和完整提出的模型ACU2E-Net)进行比较

补充文件。对于评估的16个骰子,我们的模型在平均骰子得分方面始终优于其他方法。我们已经进行了两两t检验,并在补充文件中报告了p值,这表明我们提出的方法具有统计学意义。
3.6.3. TRX和SAG甲状腺图像的样本分割结果如图6和图7所示。正如我们所看到的,ACU2E-Net(我们的)能够产生更准确的分割结果。具体而言,图6显示了一个均匀的TRX甲状腺叶,具有较重的闪烁噪声和模糊的边界。Res U-Net、U-Net++、SRM、C-U-Net、R3Net和BASNet无法捕获准确的边界。其他模型,如U-Net、Dense U-Net、Attention U-Net、U2-Net和Stacked HourglassNet在分割甲状腺左上角细长区域时失败。图7显示了异质SAG视图甲状腺的分割结果,其中包含几个复杂的结节。我们可以看到,我们的ACU2E-Net仍然比其他模型产生相对更好的结果。
4. 在本文中,我们提出了一种新的基于注意力的预测-细化网络,称为ACU2E-Net,用于超声图像中软组织结构的分割。该分割网络建立在我们新提出的AC-Conv块的基础上,充分利用了超声图像中感兴趣的解剖结构的几何信息。此外,开发了一种新的并行多头细化模块mrrm,将集成策略与残差细化方法相结合,对分割结果进行细化。通过我们的案例研究结果,改进的分割有助于准确计算甲状腺体积,这将有助于临床医生早期诊断甲状腺问题。
与任何医学影像研究一样,我们的数据集也有局限性。我们的图像是在12个不同的放射学中心由不同的技术人员在不同的设备上,在不同的病人群体上收集的,这是这项研究的一个优势。然而,所有的中心都在一个卫生区域内,我们没有包括弥漫性甲状腺疾病的图像,如桥本甲状腺炎或多结节性甲状腺肿。本研究完成的消融研究和与SOTA模型的比较证明了我们模型的有效性和鲁棒性。我们提出的网络可以应用于其他软组织的分割(例如:
肝、脾、肾)和肿瘤(如肝、脾、肾)。
肝细胞癌(HCC)在肝脏或皮下肿块,其中一些我们计划在未来的研究中进行调查。此外,我们计划使用其他计算智能算法来解决软组织分割问题。















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









