







解决卡在 critical point 的第一种办法:BatchSize (大小的选择与优缺点)
将一笔大型资料分若干批次计算 loss 和梯度,从而更新参数。每看完一个epoch 就把这笔大型资料打乱(shuffle),然后重新分批次。这样能保证每个 epoch 中的 batch 资料不同,避免偶然性。
一、batch
回顾epoch、shuffle
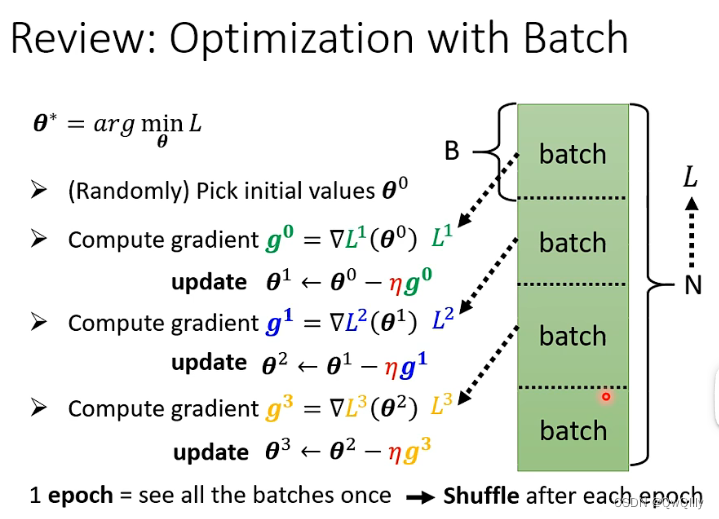
1. 运算时间对比
设大批次含有20笔资料,小批次含有1笔资料,那么大批次就是看完20笔资料后再更新参数,而小批次则是看1笔资料就更新一次参数,总共更新20次。我们可以看到大批次的单次运算时间长但效果好,小批次的单次运算时间短但效果差,需要运算多次效果才好。
batch size大还是小?都有好处

考虑 gpu “并行计算”,大的 BatchSize 并不一定时间比较长
刚刚讲的运算时间是针对单次更新,而在1 个 epoch 中,小批次反而耗时更长,大批次耗时更短。原因是:同样是60000笔资料,小批次要更新60000次,而大批次只要更新60次,更新速度又是差不多的,最后叠加起来肯定是大批次耗时更少。不过,GPU 平行运算的能力也有它的极限,当 Batch Size 真的非常非常巨大的时候,GPU 在跑完一个 Batch 后计算出 Gradient 所花费的时间,还是会随著 Batch Size 的增加而逐渐增长
总结:没有平行运算时,单次更新大批次耗时更长;有平行运算时,单次更新大小批次耗时差不多,而 1 个 epoch中大批次耗时更短。
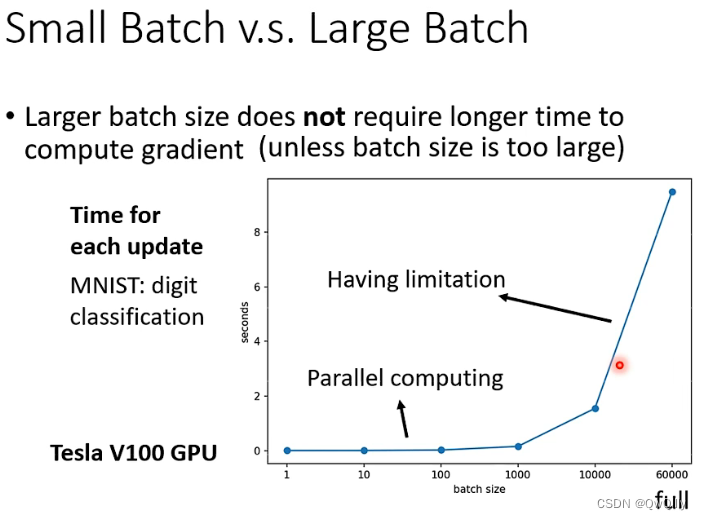
反而是,batch size小的时候,要跑完一个epoch所用的update时间更长,所以时间方面的比较真不好说~
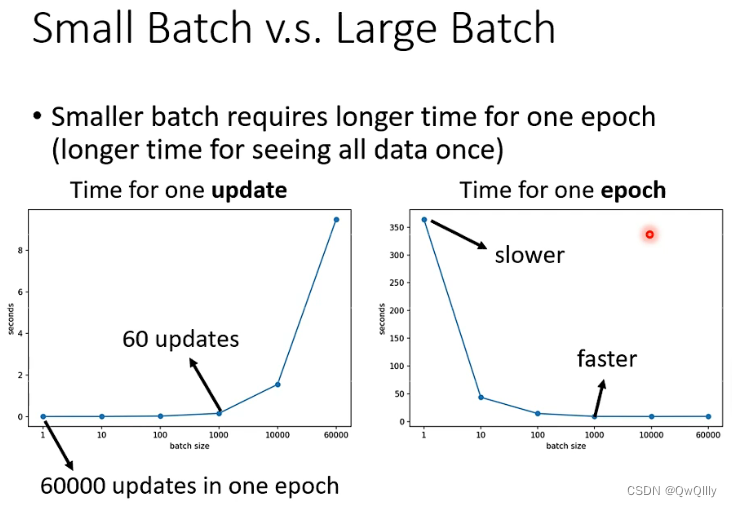

2. 性能对比
小批次有更好的性能,由图可知同一个模型,同一个网络,training误差随着batch size 的增大而增大,testing 的误差也是。如果是 model bias 的问题,那么在 size 小的时候也会表现差,而不会等到 size 变大才差。所以这是Optimization issue(优化问题)导致大批次性能差。
①小批次有更好的性能
由图可知同一个模型,同一个网络,training 误差随着 batch size 的增大而增大,testing 的误差也是。根据之前学到的内容,如果是 model bias 的问题,那么在 BatchSize 小的时候也会表现差,而不会等到 size 变大才差。所以这是Optimization issue(优化问题)导致大批次性能差。
② 小批次在更新参数时会有 Noisy ⇒ 有利于训练
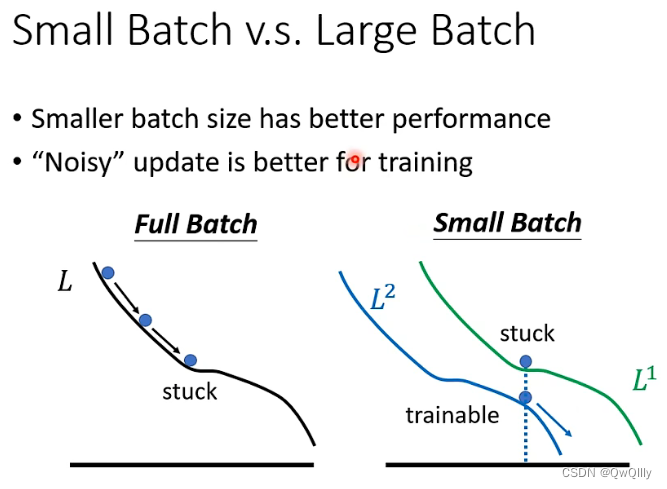
粗略分析,可能是由于小batchsize时,噪声更多,更不容易困住。
每次更新的时候,用的 loss 函数会有差异(如右图),因为不同的 batch 用不同的 loss function。换了个 loss 函数就更不容易卡住
③ 小批次可以避免Overfitting ⇒ 有利于测试(Testing)
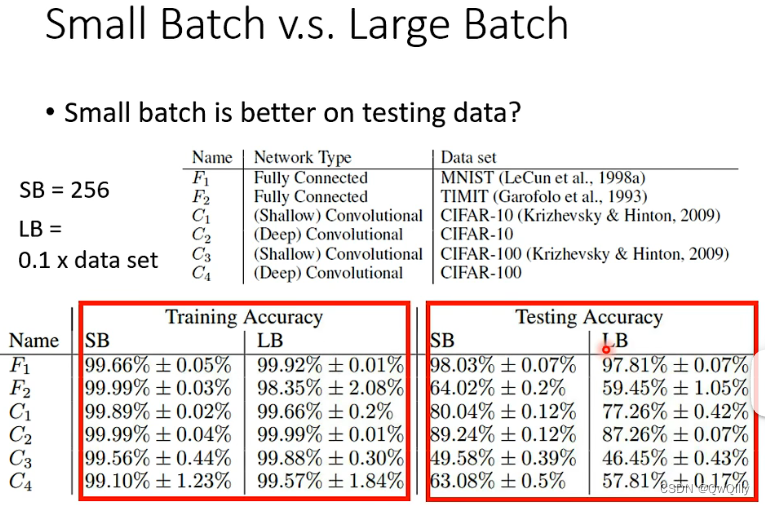
实验表明,就算在训练集上效果差不多,在测试集上可以看出小batchsize效果更好!
红框框中可以看出在训练时 SB(小批次)和 LB(大批次)的准确率都高,但是在咋样的0000testing 时,SB 的准确率还是比较高,而LB的准确率则更差点,此时 LB 面临的问题是 overfitting。
所以大批次在 training 时会遇到优化问题,而在 testing 时会遇到过拟合问题。
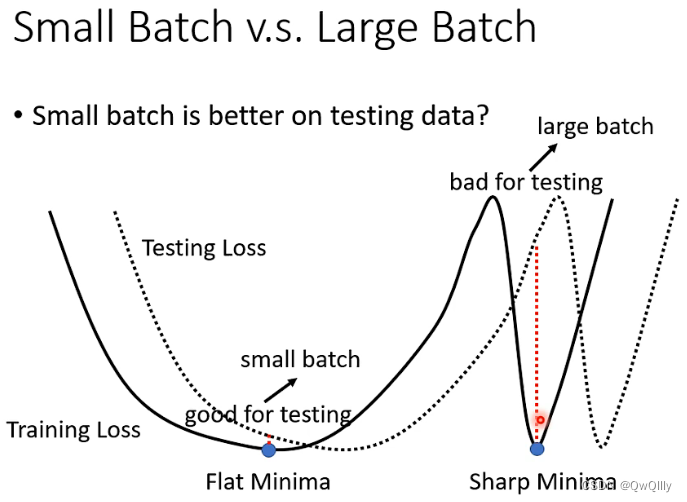
原因可能是,假设测试集损失与训练集损失有一个左右的平移,小batchsize是缓慢更新接近目标的,曲线更平缓,不容易预测差别太大。但大batchsize是看完所有数据再更新的,可能会更陡峭,此时平移后会发生较大改变。
总结
对于 Batch size 而言,大和小都有各自的优势和劣势,所以 Batch size 的大小也就成了一个需要调整的 Hyperparameter,它会影响训练速度与优化效果。
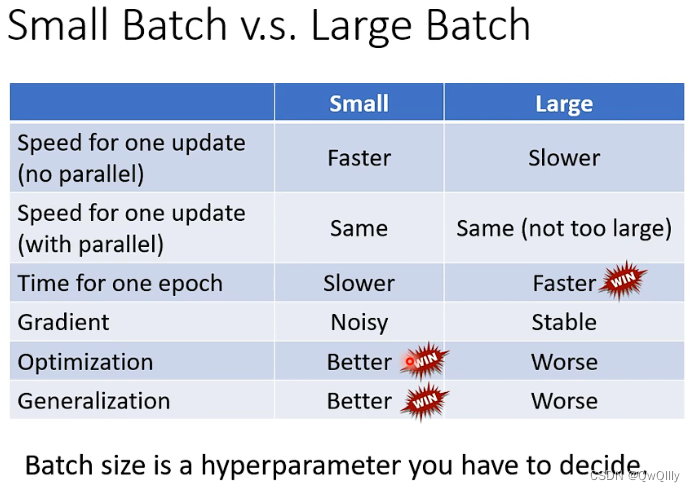
现在需要选择合适的batchsize,兼顾两者优点

解决卡在 critical point 的第二种办法
二、momentum(动量)
来源
考虑物理世界,运动的物理会有动量,有顺着速度方向运动的趋势
在物理中,重物借用惯性,能够滚得更远。将这种思想应用于梯度下降中,能使参数在面临临界点时,能随着这种惯性越过越过当前局部最优值,避免训练中卡在 critical point (一般的梯度下降:往 梯度移动 的反方向 更新参数)
特点:在更新现在的梯度下降方向的时候,每一次仅利用 前一次 的梯度下降方向
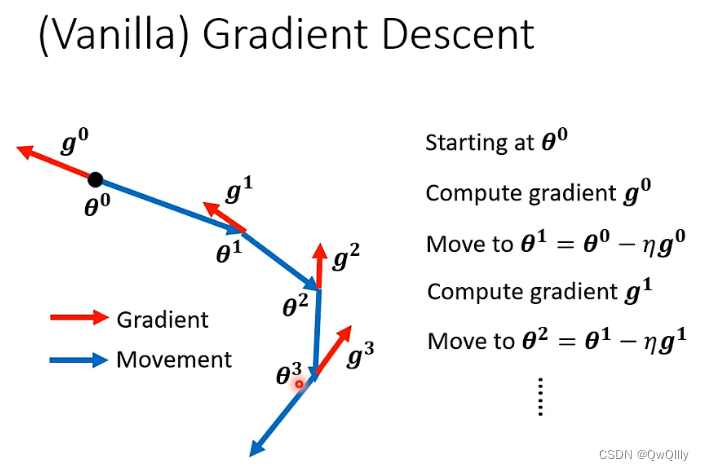
一般的(香草的)梯度下降方法
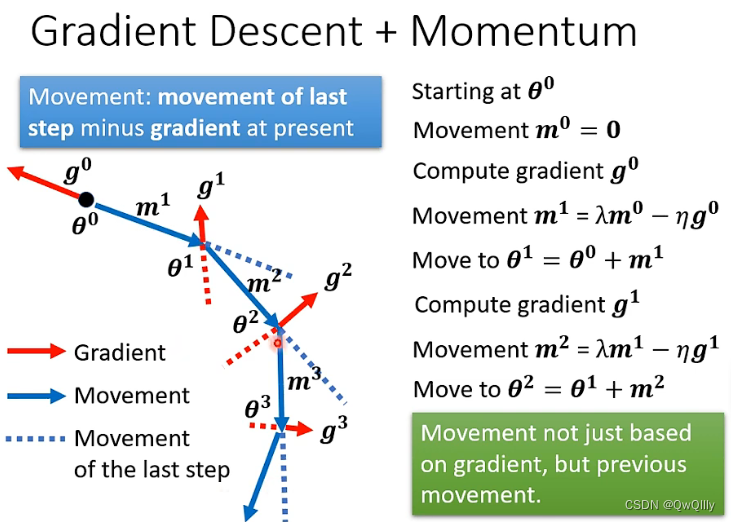
加入momentum 后
Gradient Descent + Momentum(考虑动量)⇒ 综合梯度 + 前一步的方向
① 特点:在更新现在的梯度下降方向的时候,考虑在此之前计算过的 所有的 梯度下降方向(矢量求和)
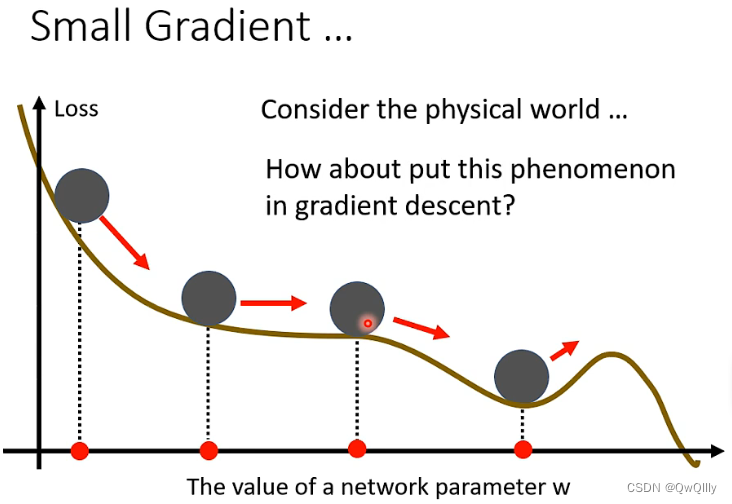
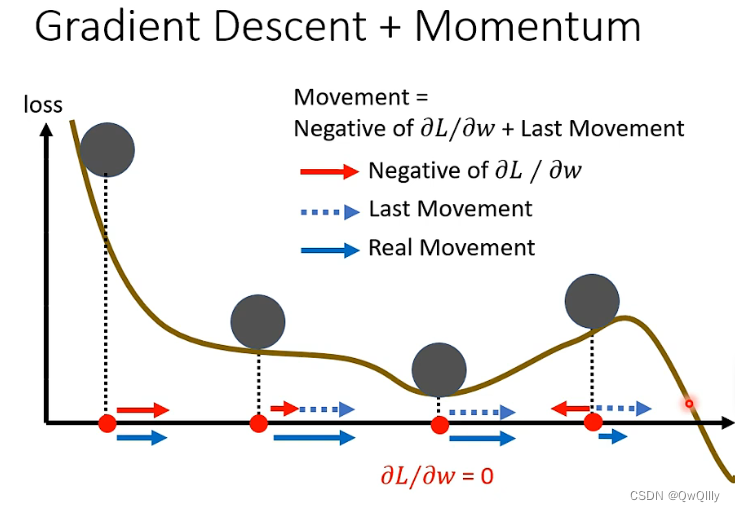
② 移动方向:梯度更新产生的距离和上一步产生的惯性距离之和。第三个球位于临界点,梯度更新产生的距离虽然是 0,但是还有上一步惯性距离,所以球能越过临界点,假如第四个球的上一步惯性距离大于梯度距离,则球可能可以越过山顶
动量也是与g有关,可以写成如下表达方式

加上动量后,损失运动的方式:不会停留在梯度=0的地方,遇到上坡时由于惯性也会继续往前试试寻找下坡。。。
三、总结
















 1432
1432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









