






目录
摘要
本文介绍了深度学习中的两个重要概念:批次(batch)和动量(momentum)。批次是将训练数据分成一组组小批量进行计算和参数更新的方法,可以提高训练效率和优化结果。动量是在梯度下降的基础上,加入上一步移动方向的结果来更新参数,可以避免在非关键点处卡住。此外,文章还介绍了自动调整学习率的方法。通过根据不同参数的梯度值来调整学习率,可以在梯度较大时减小学习率,在梯度较小时增大学习率,从而提高训练效果。具体的方法包括RMSProp和学习率衰减。最后,文章介绍了学习率衰减和热身的方法。学习率衰减是随着训练的进行,逐渐减小学习率,以平滑地到达最优点。热身是先增大学习率,再逐渐减小,可以帮助模型更快地收敛。
ABSTRACT
This article introduces two important concepts in deep learning: batch and momentum. Batch refers to the method of dividing training data into small batches for calculation and parameter updates, which can improve training efficiency and optimize results. Momentum is a technique that incorporates the direction of the previous step's movement into the gradient descent process, which helps to avoid getting stuck at non-critical points.In addition, the article also discusses the method of automatically adjusting the learning rate. By adjusting the learning rate based on the gradient values of different parameters, we can decrease the learning rate when the gradient is large and increase it when the gradient is small, thus improving training performance. Specific methods include RMSProp and learning rate decay.Furthermore, the article introduces learning rate decay and warm-up techniques. Learning rate decay gradually reduces the learning rate as training progresses to smoothly reach the optimal point. Warm-up involves initially increasing the learning rate and then gradually decreasing it, which can help the model converge faster.
一、批次(batch)与动量(momentum)
1.batch
在计算微分时,不是对所有的数据算出来的Loss值做微分,而是将所有的数据分成一个一个的batch。一个batch是一个B,在更新参数时,拿B的资料计算Loss,计算gradient,再更新参数;另一组参数也是类似,拿B的资料计算Loss,计算gradient,再更新参数,以此类推。不会将所有的数据计算loss,而是将资料分成一个一个的batch,所有的batch计算过一遍就叫做一个epoch。在每一个epoch开始前,会分一次batch。每一个epoch分的batch都不一样。在把所有的资料分成一个一个的batch时,这个过程就叫做Shuffle。
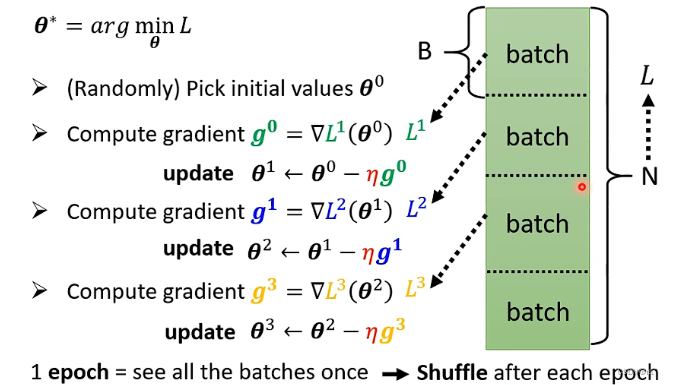
为什么训练时需要用batch?
假设现在有20个训练资料,左边是没有用batch的(或者说它的batch size就是全部的训练资料)、右边的batch size为1。左边的需要把所有的资料看过一次,才能计算loss值,计算gradient,然后更新一次参数。右边的更新一次参数只要一个B的batch资料,在一个epoch里面,就需要更新20次参数。
比较左边和右边:
左边的蓄力时间较长,因为需要把所有的资料都看过一遍。右边的蓄力时间短,每看到一笔资料就需要更新一次参数。
左边比较稳,右边的就比较陡。

batch size 比较大的训练资料计算loss、gradient、更新参数的时间不一定比batch size 小的时间长,以识别数字为例,在batch size为1-1000时相差不大(GPU可以做平行运算,所以计算1000个资料的时间并不是1个资料的1000倍),但是batch size超过一定界限,计算的时间会随着batch size的增大而增大。
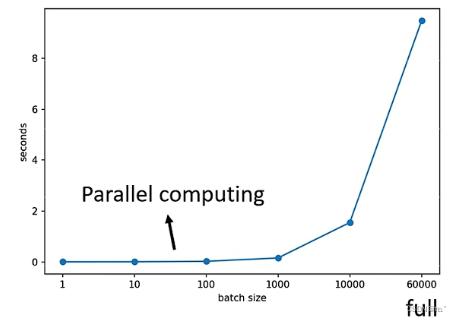
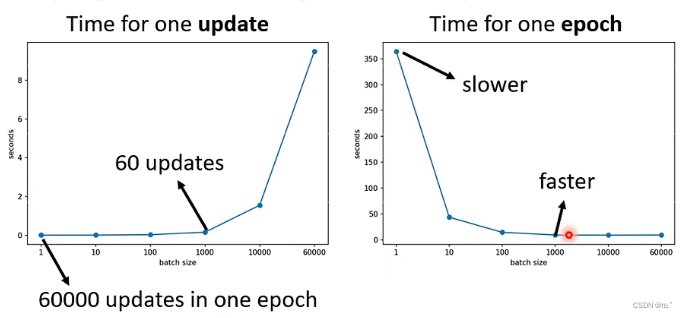
因为有平行运算的能力,当 batch size 小的时候,跑完一个epoch花费的时间比大的batch size的多。例如:batch size为1的时候与batch size为1000的时候时间差不多,但是,batch size为1的时候跑完一个epoch的时间为350+,batch size为1000的时候跑完一个epoch的时间只要20。这个时候 batch size 为1000的时间更短,更有效率。所以考虑平行运算时,batch size比较大的一个epoch花费的时间更少。
综上来说,batch size 大的似乎更好,但是比较batch size 大小的好坏还需要考虑到稳定还是陡,比较陡的gradient反而可以帮助训练。例如:左边为MNISTY的影像辨识例子、右边为CIFAR-10的影像辨识例子。横轴为batch size的大小,纵轴为正确率。batch size越大,validation上的结果就越差。在training上也是如此。这是optimization不理想所导致的问题。
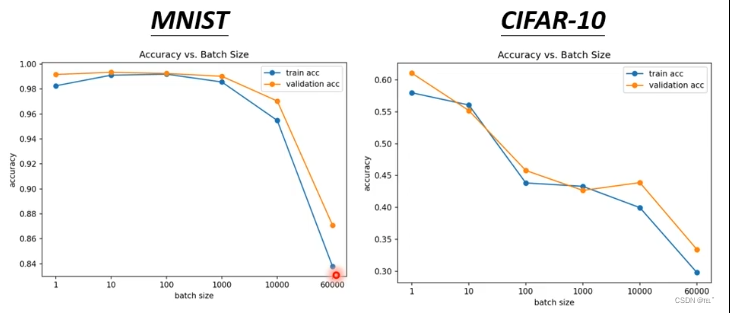
为什么小的batch size得到更好的结果呢?为什么比较陡的更有利于训练呢?
因为如果是full batch的话,沿着loss function更新参数,遇到local minima、saddle point时就无法用gradient decent的方法更新了。
如果是small batch的话,因为每次用一个batch来计算loss,根据loss来更新参数。每次更新参数用到的loss function都是有差异的,第一次用L1、第二次用L2。假设第一次更新时用L1计算gradient为0,这就卡住了。但是L2的gradient不一定为0,可以继续更新,所以比较陡的反而更有利于训练。
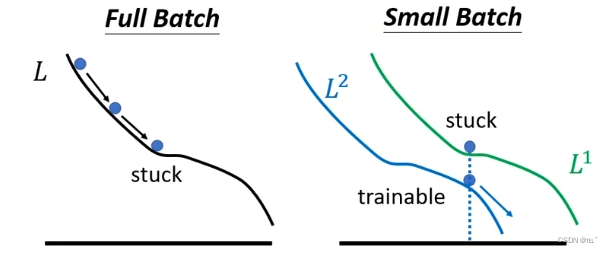
小的batch size对测试资料有帮助:
假设在训练时,大的batch size和小的batch size在训练资料上都训练到一样好,会发现小的batch size在测试资料上有更好的效果。例如:训练了六个network,小的batch size=256,大的batch size=6000。在大的batch size和小的batch size在训练资料上都训练到一样好时,在测试时,小的batch size比大的batch size得到的效果好。
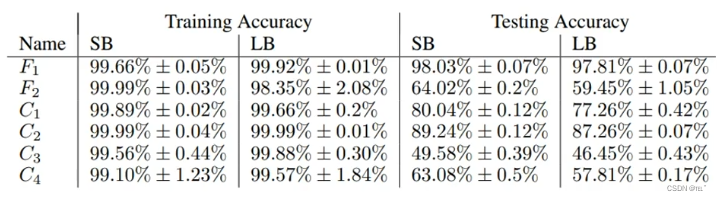
为什么 小的batch size对测试资料有帮助呢?
在Training loss上可能有很多的local minima,loss值趋近于0,如果一个local minima两边斜率很大,则这个local minima为sharp minima;如果一个local minima两边斜率很小,则这个local minima为flat minima。在Testing loss上,flat minima在Training loss和Testing loss上不会差很多;但是sharp minima在Training loss和Testing loss上会差很多。大的batch size会更容易得出sharp minima;小的batch size会更容易得出flat minima。
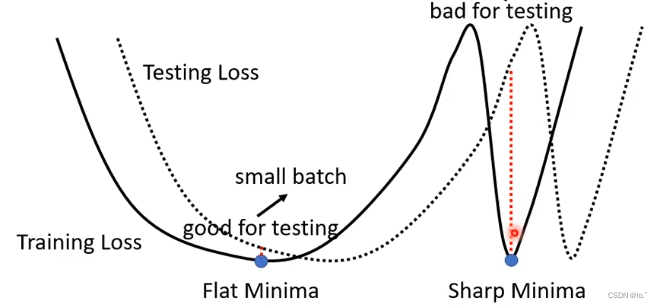
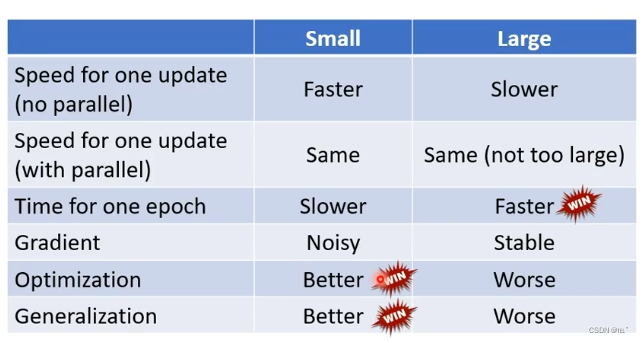
Small Batch vs Large Batch
在没有平行运算的情况下,Small Batch比 Large Batch更有效率;
在有平行运算的情况下,Small Batch与Large Batch运算时间没有太大差距,除非大的超出一定界限;
在一个epoch时间内,Large Batch比Small Batch更快,Large Batch更有效率;
Small Batch比较陡,Large Batch比较稳定;
比较noisy的batch size比比较stable 的batch size在训练和测试时占有优势。
2. momentum
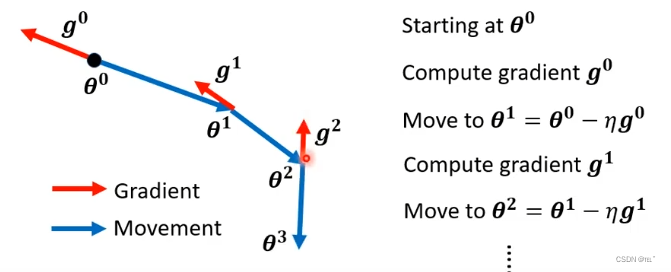
Gradient Descent:
计算Gradient,沿着Gradient的反方向更新参数;再计算下一个位置的Gradient,沿着Gradient的反方向更新参数,以此类推。
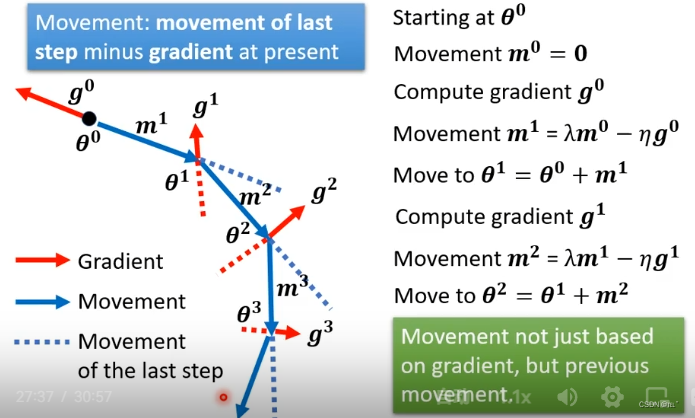
Gradient Descent + Momentum:
不是沿着Gradient的反方向更新参数,而是沿着Gradient的反方向加上前一步移动的方向的结果来更新参数。初始参数为 θ ,前一步的movement为0,计算 θ 的gradient,移动的方向为gradient的方向加上前一步的方向,以此类推。
二、自动调整学习效率
随着参数的更新,loss值越来越小保持在一定值不再下降,这并不是critical point(gradient的值为0)。如图可知,虽然loss不再下降,gradient并没有变的很小,还在波动。这可能是gradient在如图中来回震荡。
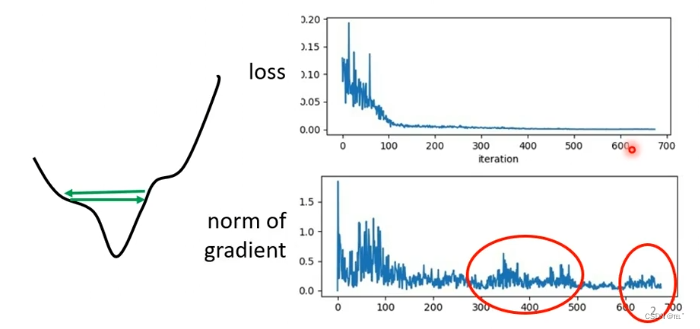
如果不是critical point,那是什么导致Training卡住呢?
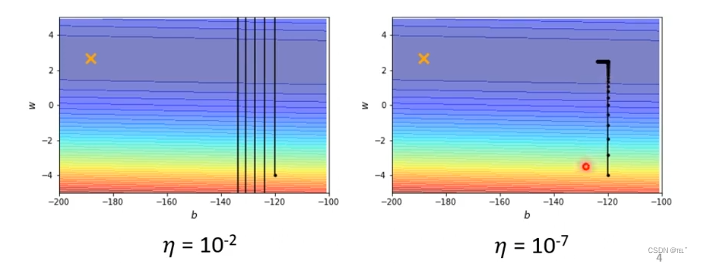
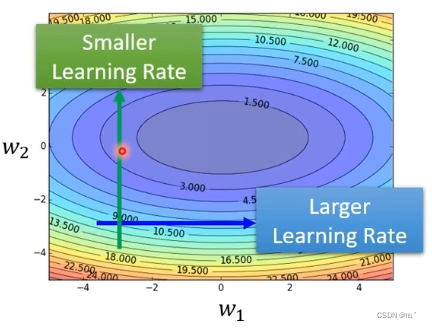
如图error surface,最低点为X的地方,从黑点位置作为初始点,做gradient decent。学习效率设置为0.1,参数在两端震荡,loss不会降低,gradient仍然很大。学习效率设置为0.0000001,不再震荡,但是训练无法到达终点。
把gradient decent做的更好的方法是设置每一个参数的学习效率。不同的参数需要不同的学习效率。如果在某一个方向上,gradient值很小(比较平稳),那么应该把学习效率调高;如果在某一个方向上,gradient值很大(比较陡峭),那么应该把学习效率调低。
原来的gradient decent:
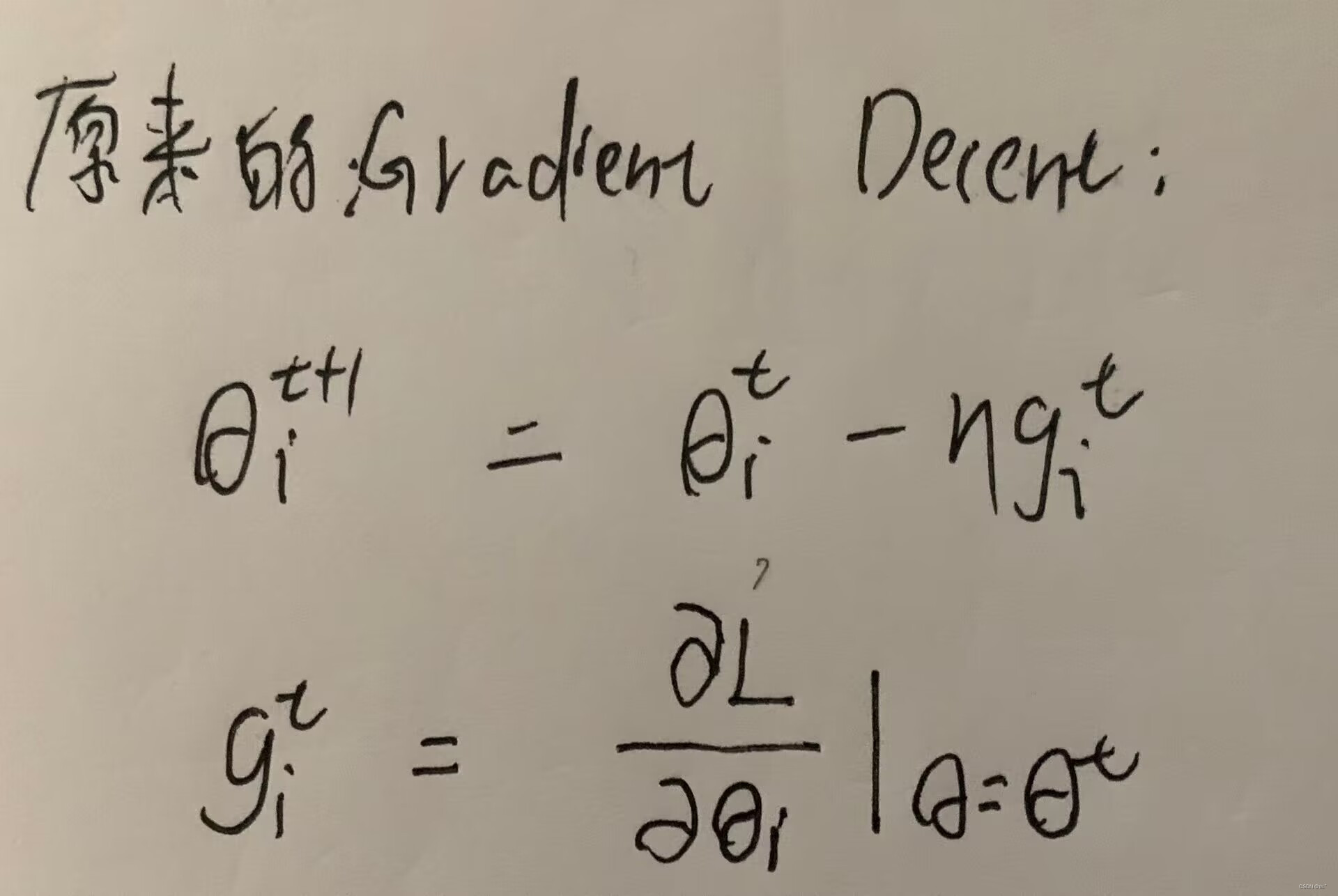
改进的gradient decent:
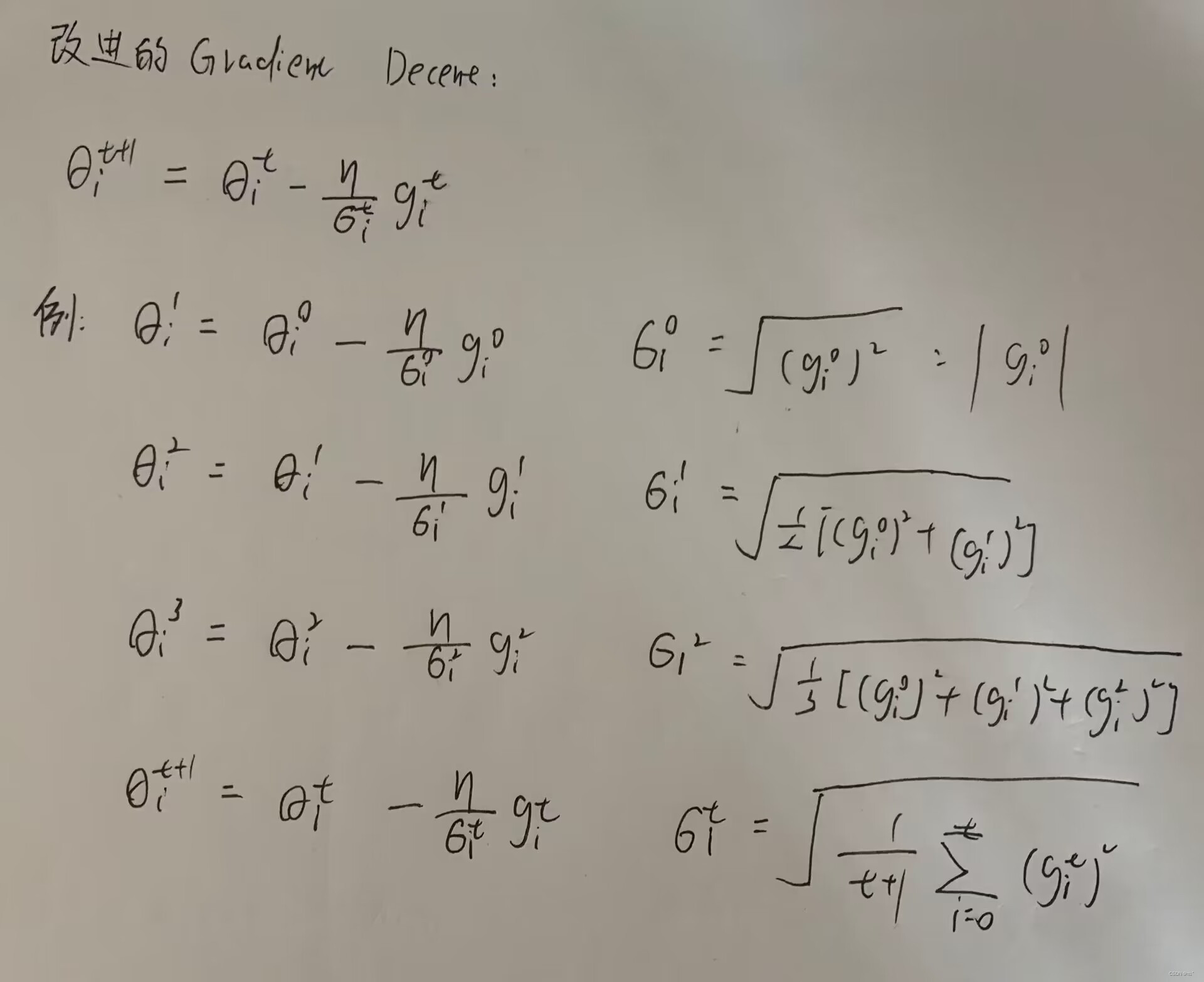
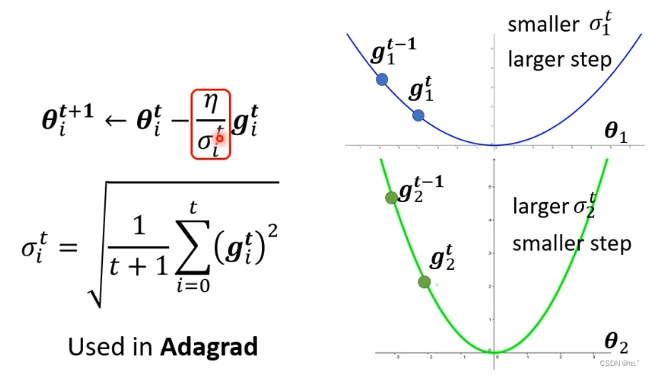
能在gradient值大(坡度大)的时候减少学习效率,gradient值小(坡度小)的时候增大学习效率的原因:
gradient值小代入到σ,σ就小,学习效率就大;gradient值大代入到σ,σ就大,学习效率就小。
动态调整学习效率RMSProp:
参数α 需要自己调整,如果觉得gradient重要,那么α设置为趋近于0;如果觉得gradient不重要,那么α设置为趋近于1。
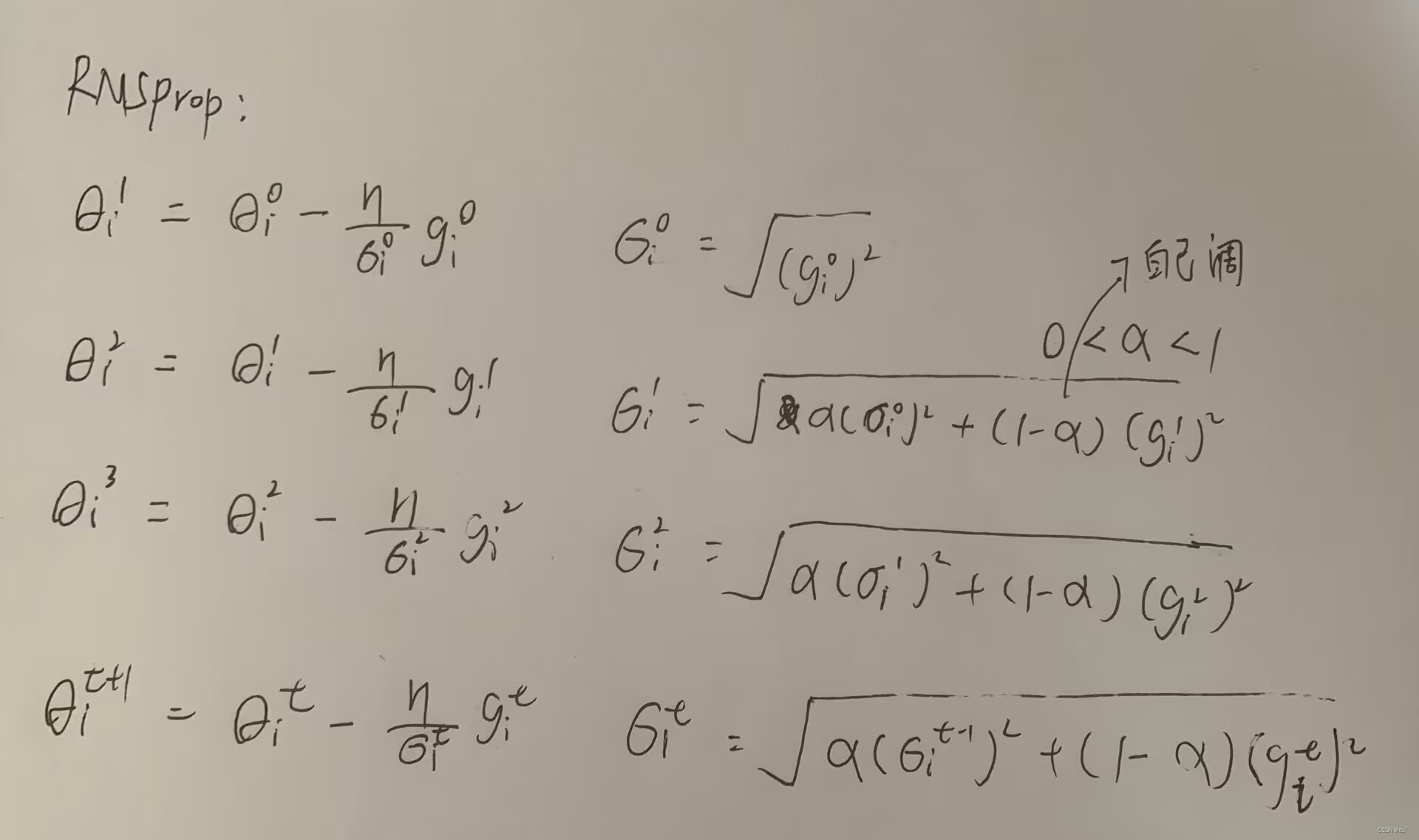
加上自动调整学习效率:
刚刚更新了100000次卡在了红色外置,通过RMSProp+momentum可以继续更新。因为在红色位置gradient很小,通过RMSProp+momentum可以自动调整学习效率。在左边突然爆炸的原因是gradient很小,则σ就小,学习效率就大,但是也可以调整回来。
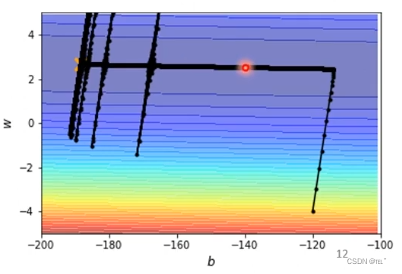
Learning Rate Scheduling:
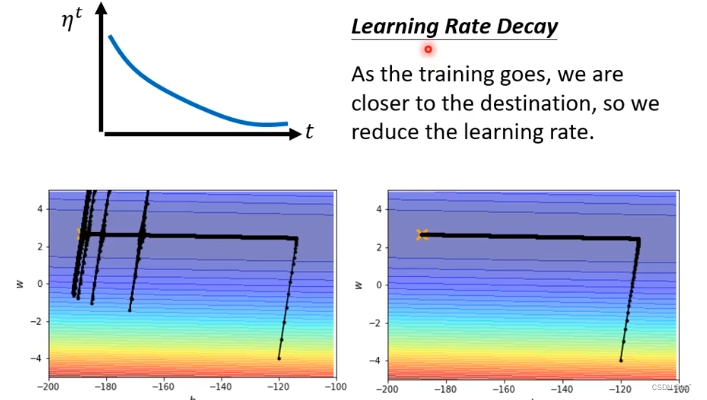
1. Learning Rate Decay
随着时间的进行,随着参数的更新,让η 越来越小。因为一开始距离目标很远,随着参数更新,距离目标越来越近,把Learning Rate减小,让参数更新减小。上述爆炸的问题,就可以用这种方法解决,可以平顺的到达终点。
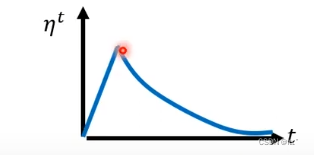
2.Warm Up
把Learning Rate先变大,后变小。
总结
本文介绍了深度学习中的两个重要概念:批次(batch)和动量(momentum)。批次是将训练数据分成多个小批次进行计算和参数更新,可以提高训练效率和稳定性。动量是在梯度下降算法中引入的一种优化方法,通过考虑之前的参数更新方向来更新参数,可以加快训练速度和避免陷入局部最优解。此外,文中还介绍了自动调整学习效率的方法,包括RMSProp和学习率衰减等。这些方法可以根据梯度的大小和方向来自动调整学习效率,提高训练的效果和稳定性。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









