






利用正弦图外推法提高有限角度CT重建的泛化能力
由于是有限角,所以就稍微看看吧
为了提高图像质量,文献中提出了许多CT图像重建算法,这些算法可以分为基于模型的方法和基于深度学习的方法。例如,滤波反投影(FBP)作为一种有代表性的分析方法,被广泛用于高效地重建高质量的图像。然而,FBP更喜欢全方位视角的收购,这使得将其用于Lact不是最优的。投影角范围的减少(有时是极端的)降低了商业CT重建算法的有效性。为了克服这一挑战,提出了基于迭代正则化的算法来利用待重建图像的先验知识,以获得更好的LACT重建性能。请注意,这些迭代算法的计算成本通常很高,并且需要仔细地逐个调整超参数。
目前,深度学习技术已被广泛应用于CT,并显示出良好的重建性能。通过进一步将迭代算法与动态链式算法相结合,提出了一系列迭代框架和相应设计的神经网络模块。ADMMNet在重构问题中引入了神经网络模型,并取得了显著的效果。此外,DuDoNet、ADMM-CSNET和Lain++在投影域中增加了增强模块来改进重建结果,这启发了我们在模型设计中融合双域学习。尽管基于深度学习的算法已经获得了最先进的性能,但众所周知,它们也很容易过度拟合训练数据,这在实践中是不可取的。然后提出了MetaInvNet来改进稀疏视图投影的重建性能,表现出良好的模型泛化能力。他们试图为具有UNet的迭代HQSCG模型找到更好的初始化,并在这样的场景中获得更好的泛化性能。但他们仍然把重点放在拥有大量获得性预测的情况下,这限制了他们的模型在实践中的应用。如何在从实际数据中学习时获得一个具有高度普适性的模型仍然是一个困难的问题。为了在LACT重建中保持模型的泛化能力,我们提出了一种用于恢复高质量CT图像的模型,称为ExtraPolationNetwork(EPNet)。在该模型中,利用双域学习来强调图像域和投影域之间的数据一致性,并引入了外推模块。建议的外推模块有助于补充投影域中遗漏的信息,并为重建提供额外的细节。大量的实验结果表明,该模型在NIH-AAPM数据集上达到了最先进的性能。此外,该研究还在额外的数据集新冠肺炎和LIDC上取得了更好的泛化性能。
方法:
模型是通过N次迭代展开HQS-CG算法来构建的。具体地说,利用Init-CNN模块在每次迭代中为共轭梯度(CG)算法寻找更好的初始化。该模块的输入由来自图像域和投影域的重建图像组成。在图像域中,对基本的HQS-CG模型进行重新训练,并使用CG模块进行重建。在投影域,首先使用提出的外推层(EPL)来估计额外的正弦图。然后,我们使用正弦图增强网络(SENET)对外推的正弦图进行内嵌,并使用Radon反转层(RIL)来重建它们,RIL具有向后传播梯度到前一层的能力。
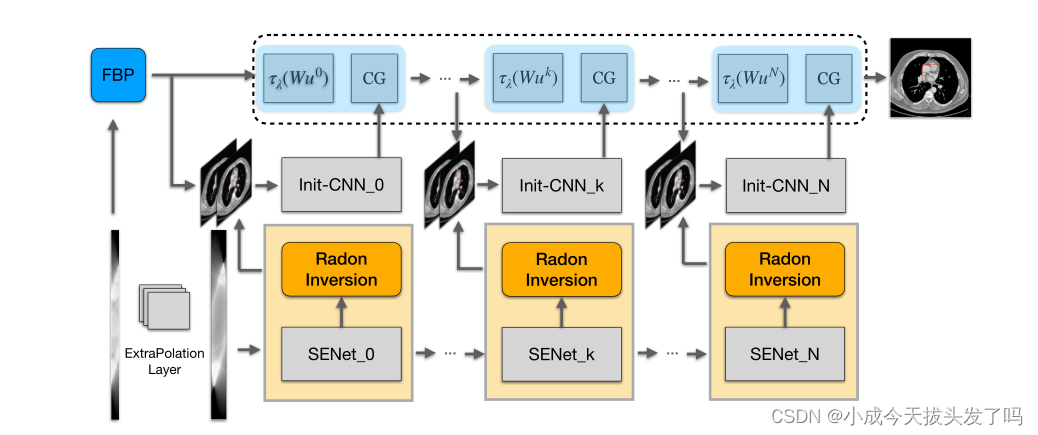
它通过图像域和正弦图域中的两条平行流水线重建CT图像。在正弦图域中,在SENET之前提出了一个外推层,以获取图像细节的额外先验信息。然后将重建的正弦图域和图像域的图像拼接在一起,然后用“Init-CNN”模块为共轭梯度算法提供更准确的初始化估计。

Init-CNN和RIL:实现了具有跳过连接的重型Unet结构的Init-CNN模块,从而稳定了训练。此外,重型Unet在不同的步骤中共享参数,这被证明是更强大的最终重建。DuDoNet首先引入了Radon反转层(RIL),它建立了用于重建的双域学习。在这里,我们使用该模块从投影域获得重建图像。
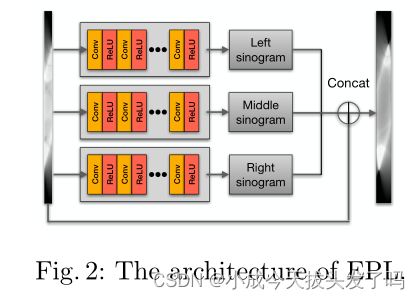
EPL:如前所述,角度范围的缩小是有限角度场景中的主要瓶颈。此外,通常的插补技术不适用于这种情况。但很少有研究人员考虑使用CNN来外推正弦图,因为正弦图包含了相应图像的空间和时间(或视角)信息,因此可以提供更多的图像细节。与图像域的差异相比,不同数据分布的正弦图在时间维度上也具有相似性。为了利用这一优势,提出了一个称为“外推层(EPL)”的模块,用于在SENET之前外推正弦图。
如图2所示,EPL模块由三个并行的卷积神经网络组成,其中左网络和右网络用于预测相应侧的相邻正弦图,中间网络用于对输入进行去噪。然后,将这三个网络的输出连接起来,然后对拟议的监督进行如下定义: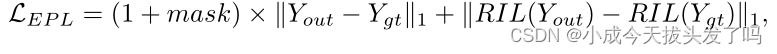
其中,Y_OUT是预测的正弦图,Y_GT是对应的地面真值,MASK是强调双边预测的二进制矩阵。在这里,我们利用RIL来实现预测的双域一致性,这使得嵌入到整个模型中的模块估计更加准确。
SENet:对于外推的正弦图,我们首先使用SENET来增强正弦图的质量,它被设计成如图3所示的轻型CNN。最后,通过RIL将增强的正弦图映射到图像域,这将有助于减少双域学习中的不同优化方向。SENET的目标如下:
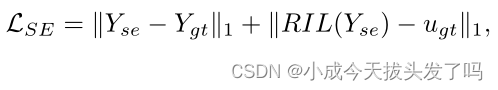
其中,Y_SE是增强的正弦图,Y_GT和U_GT分别是对应的地面真实正弦图和图像。
损失函数:通过以上模块,EPNet的完整目标函数定义为: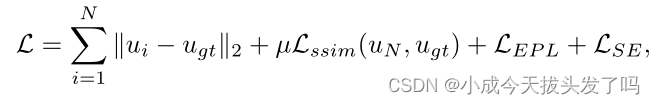
其中N是展开的后骨HQS-CG模型的总迭代次数,{u}i=1:N是每次迭代的重建图像,Lssim是SSIM损失。
创新点在于模型结构,模块几乎现有,但研究工作扎实做了,没什么可挑剔。
论文:DDOS-GUARD (sci-hub.se)![]() https://sci-hub.se/10.1007/978-3-030-87231-1_9
https://sci-hub.se/10.1007/978-3-030-87231-1_9
 https://github.com/mars11121/EPNet
https://github.com/mars11121/EPNet














 3605
3605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









