






竞赛任务是利用数据驱动的重建技术从有限视角的扇形光束测量中恢复乳房模型幻影图像。这项挑战的独特之处在于,参赛者获得了一组地面真实图像及其无噪音的子采样正弦图(以及相关的有限视角过滤反投影图像),但没有获得实际的正向模型。
团队名称:robust-and-stable
完成工作:首先在一个数据驱动的几何校准步骤中估计扇形光束的几何。在随后的两步程序中,设计一个迭代的端到端网络,能够计算出接近精确的解决方案。(损失低到无法想象)
方法结构:
第一步:数据驱动的几何图形识别
第二步:预训练的U-Net作为计算支柱网络
第三步:迭代方案
方法内容(摘原文翻译,其中小部分增加自己的理解和解释,公式截原文的图,水印很恶心):
第一步
我们重建工作的第一步是从提供的训练数据中学习未知的前向算子(FBP算子)。断层扇形光束测量的连续版本是基于计算线积分。
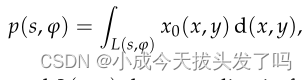
其中x0是未知图像,L(s, )表示扇形光束坐标中的一条线,即
是扇形旋转角度,s是编码传感器的位置。在一个理想化的情况下,扇形光束模型由以下几何参数指定(见图)。
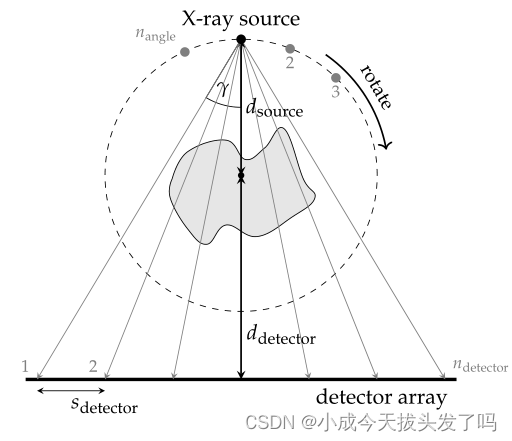
d_source - X射线源到原点的距离
d_detector - 探测器阵列到原点的距离
n_detector - 探测器元素的数量 为1024
s_detector - 探测器元素沿阵列的间距 设定1
n_angle - 扇形旋转角的数量 128个
∈[0, 2π]
n_angle - 旋转角的离散列表
这里假设积分只沿有限的线测量,由m =n_detector * n_angle决定。在AAPM DL-Sparse-View挑战赛中,所产生的前向算子参数是存在严重缺陷的,因为只获得了扇形旋转角n_angle的数量。此外,挑战赛的参与者并不了解几何设置--只知道要进行扇形光束的测量。我们通过一个数据驱动的估计策略来解决这种信息缺乏的问题,该策略将上述一组参数与给定的训练数据相匹配。为此,我们首先观察到之前的参数化是多余的,在不丧失一般性的情况下,我们可以假设s_detector = 1(通过适当地重新缩放d_detector)。此外,如果视场角γ是已知的,那么关系
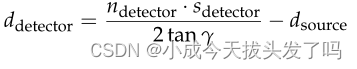 ...............................公式2.1
...............................公式2.1
可以用来消除另一个参数。因此,扇形光束的几何形状实际上是由减少的参数集(d_source, n_detector, n_angle,j)决定的。训练数据提供了成对的离散图像x0∈图像域及其模拟扇形光束测量值y0∈R128*1024=m,从中可以得出尺寸n_angle=128和n_detector=1024。我们确定视场为γ=arcsin(256/d_source),这样,离散图像中的最大刻圆正好包含在每个扇形线内,这是扇形光束CT的一个常见选择。因此,上述公式导致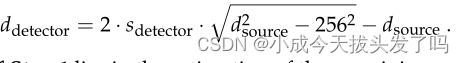
步骤1的主要困难在于对其余参数(d_source,j)的估计。为此,我们在PyTorch中从头开始实现了离散扇形光束变换(连同其相应的过滤反投影)。我们实现的一个独特的方面是使用了一个矢量的数字积分,通过自动微分的方式实现了对几何参数导数的有效计算。这一特点可以被用于数据驱动的参数识别,例如,通过梯度下降。更确切地说,我们对前向模型使用射线驱动的数值积分,并使用像素驱动和基于正弦图加权的滤波反投影(使用汉明滤波)。
除了参数(d_source,j),我们还为正向和反向变换分别引入了可学习的正向缩放因子s_fwd和反向缩放因子s_fbp。它们说明了在选择距离的离散单位与实际的物理距离单位之间的模糊性。
如前所述,我们以类似深度学习的方式估计已实现的前向算子F[θ_fan]∈[R:m×N]的自由参数θ_fan=(s_fwd, d_source,j)∈R130:计算导数dF/dθfan的能力使我们能够利用M = 4000张正弦图-图像pairs(也就是x0和y0的pairs),用梯度下降的变体实现
 .......................................公式2.2
.......................................公式2.2
最后通过求解

来确定s_fbp,同时保持已经确定的参数不变。从现在开始,我们将使用简短的符号F和FBP分别表示估计的算子F[θfan]和FBP[θ_fan, s_fbp]。
第一步的备注:(1) 显然,公式(2.2)是不凸的,因此不清楚梯度下降是否能够准确估计底层扇形梁的几何形状。事实上,标准的梯度下降法被发现对θfan的初始化非常敏感,并且卡在不好的局部极值中。为了克服这个问题,我们用坐标下降法来解决(2.2),该方法交替地对sfwd、dsource和j进行优化,并采用单独的学习率。我们发现这种策略能有效地解释不同参数的梯度大小的巨大偏差。
事实上,我们观察到了快速收敛和对θfan的可靠识别,与初始化无关。
(2)原则上,(2.2)的策略只需要少量的训练样本就能成功。然而,当验证所述策略对测量噪声的稳健性时,我们发现采用更多的训练数据是有益的。
(3) 在估计了准确的扇形光束的几何形状之后,我们仍然注意到我们的前向模型中存在着系统误差。我们怀疑这是由于与AAPM挑战的真正的正向模型相比,数字整合的细微差别造成的。在补偿中,我们计算了训练集上的(按像素计算的)平均误差,作为对模型偏差的附加修正
第二步
我们重建方案的核心是由一个标准的UNet架构U[θ]:R_N→R_N构成。它首先作为一个残差网络被用来对稀疏视图过滤的反投影图像进行后处理,也就是说,我们考虑重建映射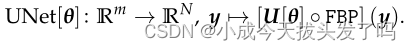
输入是正弦数据y,经过FBP得到图像,输入U-Net做后处理。
可学习的参数θ是从挑战赛提供的M=4000个正弦图-图像对{(yi0, xi0)}集合中训练的。这是通过标准的经验风险最小化来实现的,也就是说,通过(近似)解决 ...............................公式2.3
...............................公式2.3
x0是groundtruth,最小化上述映射产生的损失,后面加一个正则化项。
后处理网络由于具有跳过连接的多尺度编码器-解码器结构,UNet-架构在处理图像-图像问题时非常有效。因此,解决(2.3)通常是开箱即用的,不需要复杂的初始化或优化策略(甚至在看似无望的情况下[HA20])。利用一个更强大的或记忆效率更高的网络将是有益的,然而,我们更愿意保持我们的工作流程尽可能的简单,因此决定坚持使用标准的UNet作为主要的计算构件。
第三步(个人认为此处的一致性层作用明显,但总感觉没必要,直接上残差不可以吗?)
在这一步,我们讨论我们的主要重建方法。它通过以下的迭代过程将步骤1中的(近似的)前向模型F(以及由FBP进行的相关反演)纳入其中: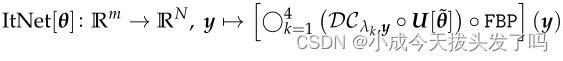 .........公式2.4
.........公式2.4
为了获得可学习的参数θ=[ ˜θ, λ1, λ2, λ3, λ4]和第k个数据一致性层
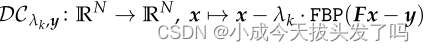
此处为迭代优化过程,x是U-Net优化过的图像,经过正向算子处理后减去真值正弦y,得到正弦域的损失(Fx-y),将该损失进行FBP得到噪声,再用U-Net生成的图像x减去噪声。依照此逻辑进行双域优化,实际上是用图像噪声在正弦域的体现来优化图像,也就是此处用的groundtruth是正弦数据而非图像数据。
在该模型下的最终效果:

哦,替当时其他参赛队伍感慨一下,人间不值得,这还做个球,这个队伍做出来的效果在视觉上已经跟label没啥差别了,最终损失在数值上看,领先了第二名一个数量级。
论文:
https://arxiv.org/pdf/2106.00280.pdf
源码:















 6141
6141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









