







KNN用于分类问题
KNN 是一种分类与回归方法,他通过计算实例x与训练集中所有实例的距离,取距离最近的k个实例中,将出现最多的类别y作为自己所属的类别y。
(1)模型:没有显示模型
(2)策略:KNN中往往使用多数表决法,为什么使用它呢?如果分类的损失函数为0-1损失函数,那么它的误分类率为:
P
(
Y
≠
f
(
X
)
)
=
1
−
P
(
Y
=
f
(
X
)
P(Y\neq f(X)) =1-P(Y = f(X)
P(Y=f(X))=1−P(Y=f(X)
给定区域的k个训练实例点集合为
N
k
(
x
)
N_k(x)
Nk(x)。如果区域的类别是
c
j
c_j
cj,那么误分类率为
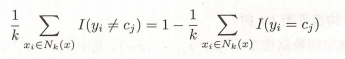
经验风险为:
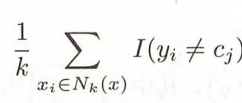
要使得经验风险最小,就要使得下列式子最大。即我们要取最多的
c
j
c_j
cj作为所属类别。
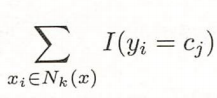
在KNN求最小经验函数的过程中,要确定两个因素,分别是距离度量和k值。
距离度量
KNN是计算输入实例到每一个训练实例的距离,那么距离的度量的很重要。

用
L
p
L_p
Lp来定义距离:
L
p
(
x
i
,
x
j
)
=
(
∑
l
=
1
n
∣
x
i
(
l
)
−
x
j
(
l
)
∣
p
)
1
p
L_p(x_i,x_j) = (\sum_{l=1} ^{n}|x_i^{(l)}-x_j ^{(l)}| ^p) ^{\frac{1}{p}}
Lp(xi,xj)=(l=1∑n∣xi(l)−xj(l)∣p)p1
当p = 1时是曼哈顿距离(Manhattan distance),这时候正方形边上的点和远点的距离相等,这是1-范式,表示对应点的坐标差值的绝对值之和;当p = 2时 是欧式距离(Euclidean disdance),这个时候圆上的点到原点的距离相等,这是2-范式;当
p
=
∞
p = \infty
p=∞ 最外面正方形边上的点到原点的距离相等,是
∞
\infty
∞-范式,表示各个坐标距离的最大值
k值的选择
当距离度量确定后,就是选择K值,不同的K值影响输入实例的类别,如图

上图就是KNN的算法图,当我们选择K=3 的时候距离绿色原点最近的三个实例在实线圆中,那么红色三角的类别数量最多,那么绿色圆的类别跟红色三角的类别相等。当K=5的时候,距离绿色圆最近的的5个实例在虚线园中,这时候,蓝色方形的数目最多,那么绿色圆的类别就等于蓝色放形的类别。那如何选择K呢?一般采用交叉验证的方法来选取K,同时一般将K定为奇数。
KNN 算法
1 . 根据给定的距离度量,在训练集T中找到与x最相近的k个点,涵盖k个点x的领域记为
N
k
(
x
)
N_k(x)
Nk(x)
2 . 在
N
k
(
x
)
N_k(x)
Nk(x)中根据多数表决来决定x的类别y
####################################################################
"""
补充知识点
1. itertools 中combinations 方法
conbinations(iterable,r)可以创建迭代器返回所有长度为r的子序列
2. zip(iterable,...) 参数为可迭代对象,返回一个以元组为元素的列表,其中第i
个元组包含每个参数的第i个元素,返回长度为最短的参数长度
3. sklearn.model_selection.train_test_split(*arrays,**options)用于制作训
练数据和测试数据,其中arrays,分隔对象同样长度的列表或数组、矩阵,test_size
两种方法指定(1)小数,表示test数据集比例(2)整数,在数据集个数范围内;
train_size与test_size相似;random_state:这是将分割的training和testing
集合打乱的个数设定。
4. np.linalg.norm(求范数)
x_norm = np.linalg.norm(x,ord,axis,keepding=False)
x 表示矩阵;ord表示凡是类型,ord默认为二范式,ord=1为一范式,ord=np.inf
为无穷范式;axis表示处理类型,axis=1求多个行向量范式,axis=0求多个列向
量范式,axis默认是求矩阵范式;keepding是否保持矩阵的二维特性,
True表示保持
5. max(num, key=lambda x:x[0]),x:x[]字母可以随便改 表示求中括号[]里面
维度的最大值,[0]按照第一维,[1]按照第二维
6. from collections import Counter 的用法:counter一个dist的子类用于
统计字符出现的个数
7. sorted(dict1.items(),key=lambda x:x[1]),x表示元组,x[1]对值,x[0]对键
从小到大排序,排序结果为带有元组的列表
"""
from itertools import combinations
list1 = [1, 2, 3, 4]
list2 = [i for i in combinations(list1,2)]
print(list2)
#################################################################
"""
距离
"""
import math
from itertools import combinations
def L(x,y,p=2):
if len(x)==len(y) and len(x)>1:
sum = 0
for i in range(len(x)):
sum += math.pow(abs(x[i]-y[i]),p)
return math.pow(sum,1/p)
else:
return 0
"""
例3.1
"""
x1 = [1,1]
x2 = [5,1]
x3 = [4,4]
for i in range(1,5):
r = {'1-{}'.format(c) : L(x1,c,i) for c in [x2,x3]}
print(min(zip(r.values(),r.keys())))
#########################################################################
"""
KNN算法
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()
"""
knn 有predict、score
"""
data = np.array(df.iloc[:100, [0, 1, -1]])
X, y = data[:,:-1], data[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
class KNN:
# init()用于参数的输入。n_neighors 为临近点个数,p为距离度量
def __init__(self,X_train,y_train,n_neighbors = 3,p =2):
self.X_train = X_train
self.y_train = y_train
self.n = n_neighbors
self.p = p
# predict() 输入x,预测x对应的标签y
"""
1. 找出最距离x最近的k个点,存入一个列表中(自己的idea:算出所有点距离,排序取前三个)
先取3个点存入knn_list里面,再将剩下的点的dist与knn_list中dist最大的
点做比较,如果存在比knn_list[maxindex][0]要小的点,则替换
2. 算出这k个点中哪个类的数目更多,则判断x的类标签为,数目最多的类
求出k个点的所有类别,用counter来计算k中类别数目,存储结果为字典,
再通过sorted排序来求出数目最多的类标签,返回类标签
"""
def predict(self,X):
knn_list = []
for i in range(self.n):
dist = np.linalg.norm(X-self.X_train[i],ord = self.p)
knn_list.append((dist,self.y_train[i]))
for i in range(self.n,len(self.X_train)):
max_index =knn_list.index(max(knn_list,key = lambda x:x[0]))
dist = np.linalg.norm(X-self.X_train[i],self.p)
if knn_list[max_index][0]> dist:
knn_list[max_index]= (dist,self.y_train[i])
knn = [k[-1] for k in knn_list]
count_pairs = Counter(knn)
max_count =sorted(count_pairs.items(),key = lambda x:x[1])[-1][0]
return max_count
#score() 用于判断测试集x预测的y与实际测试集中y的正确率
def score(self,X_test,y_test):
correct = 0
for X,y in zip(X_test,y_test):
label = self.predict(X)
if label == y:
correct +=1
return correct/len(X_test)
clf = KNN(X_train, y_train)
print(clf.score(X_test, y_test))
test_point = [5.0,4.0]
print('Test Point is:{}'.format(clf.predict(test_point)))
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.plot(test_point[0], test_point[1], 'bo', label='test_point')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()
"""
自己的idea
"""
class KNN2:
def __init__(self,X_train,y_train,n_neighter = 3, p = 2):
self.X_train = X_train
self.y_train = y_train
self.n = n_neighter
self.p = p
def predict(self,X):
knn_list1=[]
for i in range(len(self.X_train)):
dist = np.linalg.norm(X-self.X_train[i],self.p)
knn_list1.append((dist,self.y_train[i]))
knn_list2 = sorted(knn_list1,key = lambda x:x[0])
knn_list=[]
for i in range(3):
knn_list.append(knn_list2[i])
knn = [k[-1] for k in knn_list]
knn_count = Counter(knn)
max_count = sorted(knn_count)[-1]
return max_count
def score(self,X_test,y_test):
correct = 0
for X,y in zip(X_test,y_test):
label = self.predict(X)
if label == y:
correct +=1
return correct/len(X_test)
clf2 = KNN2(X_train, y_train)
print(clf2.score(X_test, y_test))
test_point = [5.0,4.0]
print('Test Point is:{}'.format(clf2.predict(test_point)))
########################################################################
"""
scikit-learn knn 实例
sklearn.neighbors.KNeighborsClassifier
n_neighbors:临近点数量
p:距离度量
algorithm:近邻短发('auto','ball_tree','kd_tree','brute')
weighte:确认近邻的权重
"""
from sklearn.neighbors import KNeighborsClassifier
clf_sk = KNeighborsClassifier()
print(clf_sk)
print(clf_sk.fit(X_train,y_train))
print(clf_sk.score(X_test,y_test))
predicted = clf_sk.predict(X_test)
print(predicted)入代码片
KNN做回归
KNN做回归运算,就是将求距离实例x最近的k个值的均值。就是x对应的y值
构造平衡kd树
为什么要构造平衡kd树呢?我们直到训练数据主要是进行KNN的搜索,但是当特征维度特别大的时候,这种计算十分耗时,为了减少计算距离的次数,可以采用kd树的方法。
直接上实例来了解如何构造平衡kd树:
给定一个二位空间的数据集
T
=
(
2
,
3
)
T
,
(
5
,
4
)
T
,
(
9
,
6
)
T
,
(
4
,
7
)
T
,
(
8
,
1
)
T
,
(
7
,
2
)
T
T = {(2,3)^T,(5,4)^T,(9,6)^T,(4,7)^T,(8,1)^T,(7,2)^T}
T=(2,3)T,(5,4)T,(9,6)T,(4,7)T,(8,1)T,(7,2)T

最终得到下图

回顾总结
对感知机和k近邻算法进行总结,这两种方法都是可以解决二分类问题,下面是不同点:
- 感知机,要求数据是线性可分,虽然对于数据不可分的时候,也有相应的感知机算法。感知机使用所有的数据集找一个能分割两类的超平面。当找到这个超平面后,输入实例,根据超平面来判断新的实例类别,他保留了超平面结构,遗弃了训练集。
- k近邻算法,找到局部信息即距离实例x最近的k个点的信息。他要存储训练集。
3.如何选择呢?当数据线性可分的时候,用感知机,当数据线性不可分,值能使用周围数据进行分类判断的时候,用k近邻算法
资料:
《统计学习方法》
代码:https://github.com/fengdu78/lihang-code















 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









