







在实际工作中我们并不会直接创建线程而是从线程池中取线程,你知道为什么吗?
这是因为线程过多会带来额外的开销,例如创建和销毁线程的开销、调度线程频繁上下文切换开销等等,这些开销会降低计算机的整体性能。而线程池通过维护多个线程,等待分配执行任务,这样做一方面避免了处理任务时频繁创建销毁线程的开销,另一方面又避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
再深入一点,你知道线程池通过什么技术维护多个线程,和等待管理者分配可并发执行任务吗?
看到这个问题你应该能想到“池化技术”、“阻塞队列”但内部的实现原理可能不太清楚,下面让我们来一起深入一下线程池的内部实现原理。
线程池核心设计与实现
我们以JDK 1.8 提供的 ThreadPoolExecutor 类入手,深入学习它的设计与实现。
2.1 总体设计
首先来看一下ThreadPoolExecutor的UML类图,了解下ThreadPoolExecutor的继承关系。
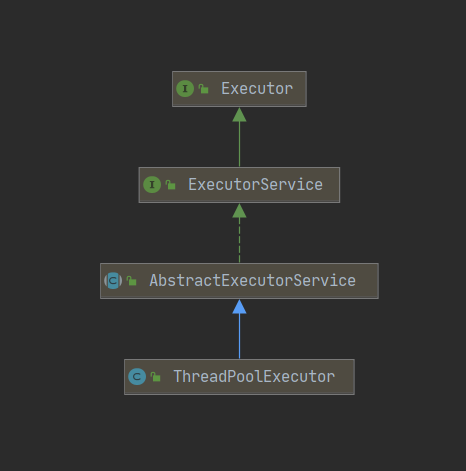
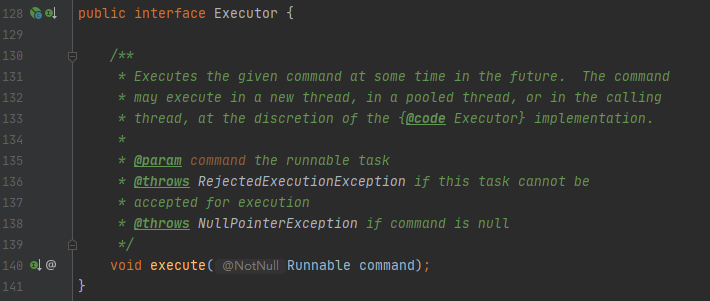
ThreadPoolExecutor 实现的顶层接口是 Executor,Executor提供了一种解耦思想,将任务提交和任务执行进行解耦。用户只需提供Runnable对象,将任务提交到执行器(Executor)中,无需关注如何创建和调度线程来执行任务。Executor类代码如下:
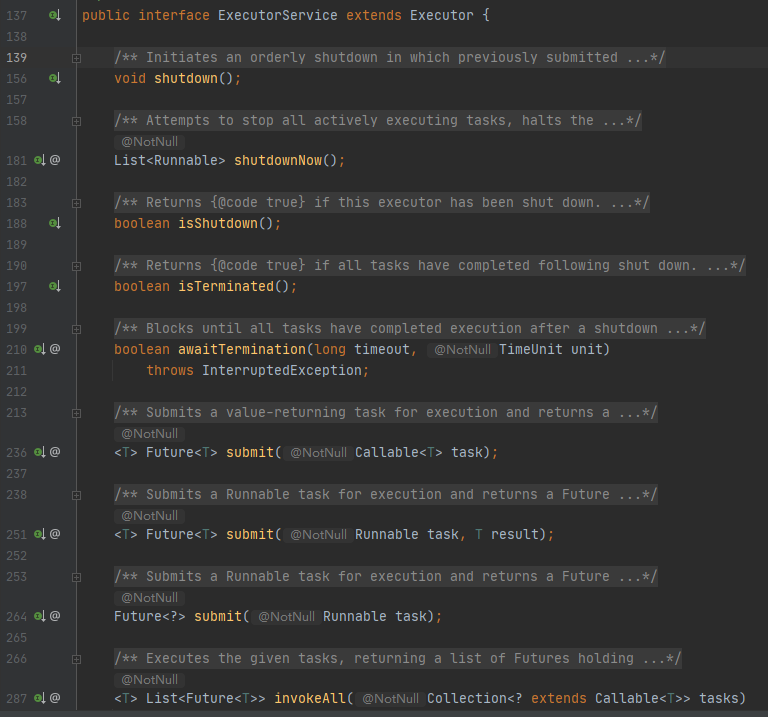
ExecutorService接口在Executor的基础上增加了一些能力:
(1)扩充执行任务的能力。
(2)提供了管控线程池的方法。
部分代码如下如所示:
AbstractExecutorService 则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。
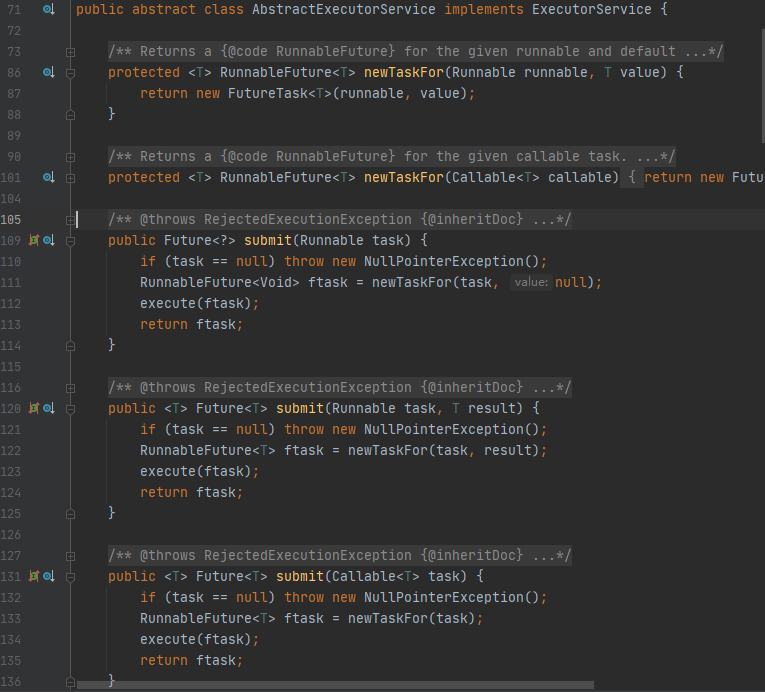
最下层的实现类ThreadPoolExecutor实现最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
ThreadPoolExecutor是如何运行,如何同时维护线程和执行任务的呢?其运行机制如下图所示:
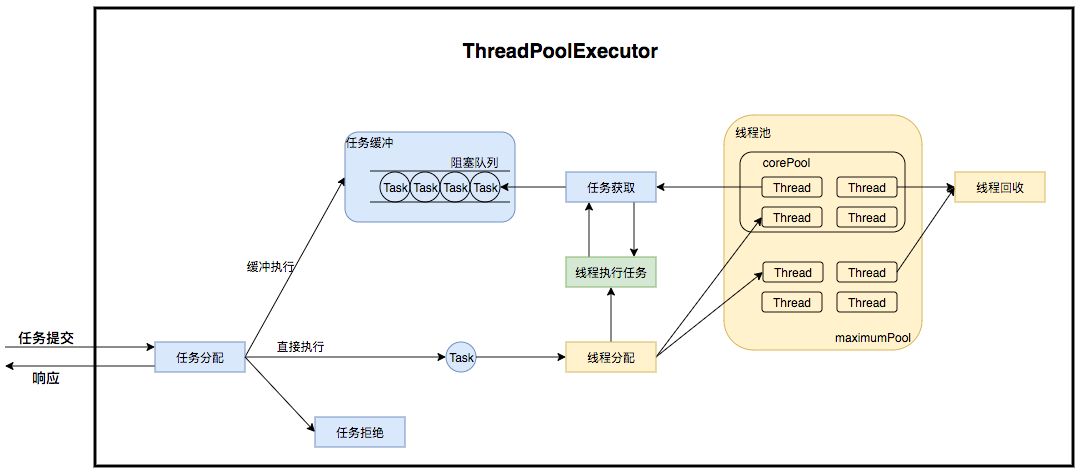
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。线程池的运行主要分成两部分:任务管理、线程管理。任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:(1)直接申请线程执行该任务;(2)缓冲到队列中等待线程执行(3)拒绝该任务。线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
接下来,我们会按照以下三个部分去详细讲解线程池运行机制:
- 线程池如何维护自身状态。
- 线程池如何管理任务。
- 线程池如何管理线程。
2.2 生命周期管理
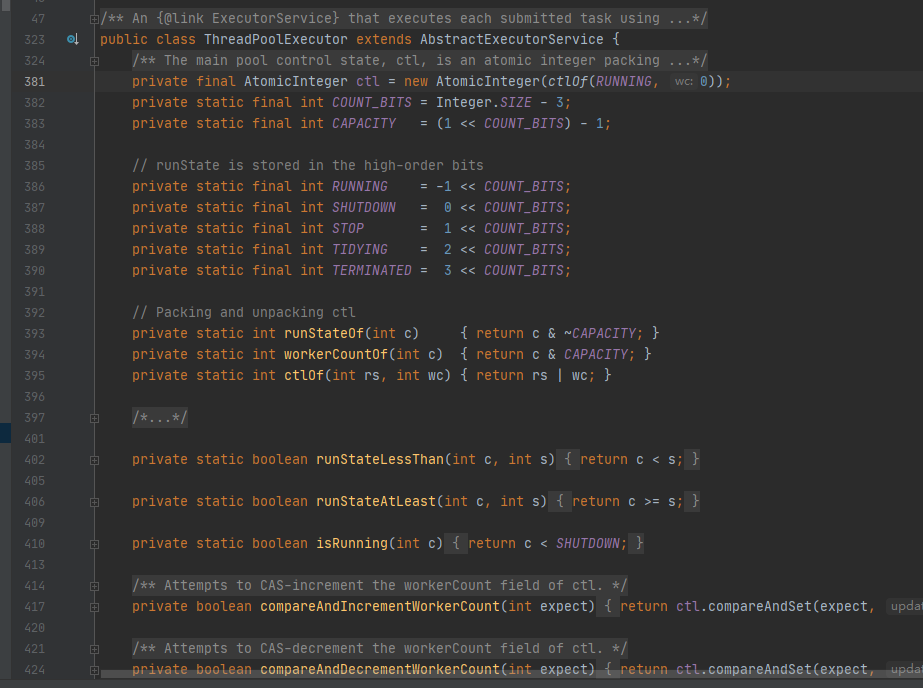
线程池运行的状态,并不是用户显式设置的,而是伴随着线程池的运行,由内部来维护。线程池内部使用一个变量维护两个值:运行状态(runState)和线程数量 (workerCount)。在具体实现中,线程池将运行状态(runState)、线程数量 (workerCount)两个关键参数的维护放在了一起,如下代码所示:

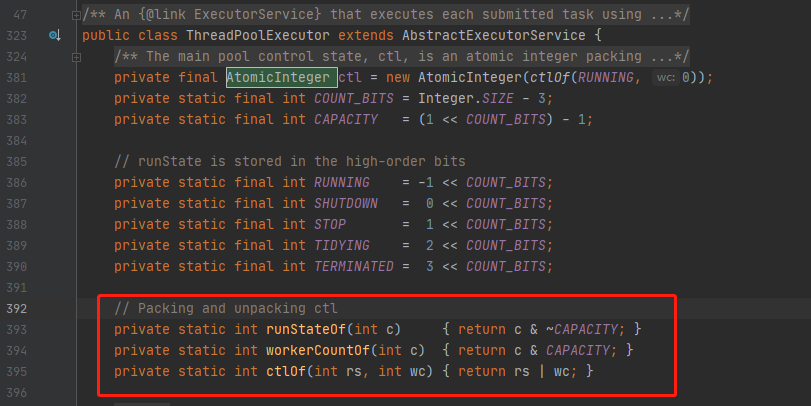
ctl这个AtomicInteger类型,是对线程池的运行状态和线程池中有效线程的数量进行控制的一个字段, 它同时包含两部分的信息:线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount),高3位保存runState,低29位保存workerCount,两个变量之间互不干扰。用一个变量去存储两个值,可避免在做相关决策时,出现不一致的情况,不必为了维护两者的一致,而占用锁资源。通过阅读线程池源代码也可以发现,经常出现要同时判断线程池运行状态和线程数量的情况。线程池也提供了若干方法去供用户获得线程池当前的运行状态、线程个数。这里都使用的是位运算的方式,相比于基本运算,速度也会快很多。
关于内部封装的获取生命周期状态、获取线程池线程数量的计算方法如以下代码所示:
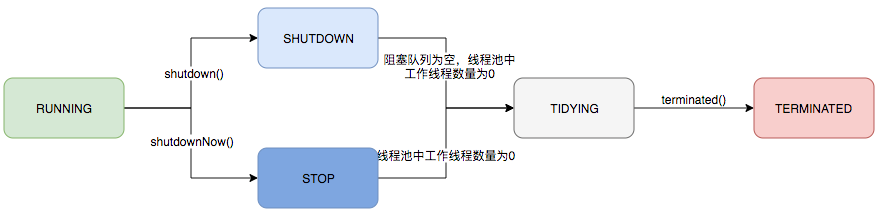
ThreadPoolExecutor的运行状态有5种,分别为:

其生命周期转换如下入所示:
2.3 任务执行机制
2.3.1 任务调度
任务调度是线程池的主要入口,当用户提交了一个任务,接下来这个任务将如何执行都是由这个阶段决定的。了解这部分就相当于了解了线程池的核心运行机制。
首先,所有任务的调度都是由execute方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。
其代码如下:
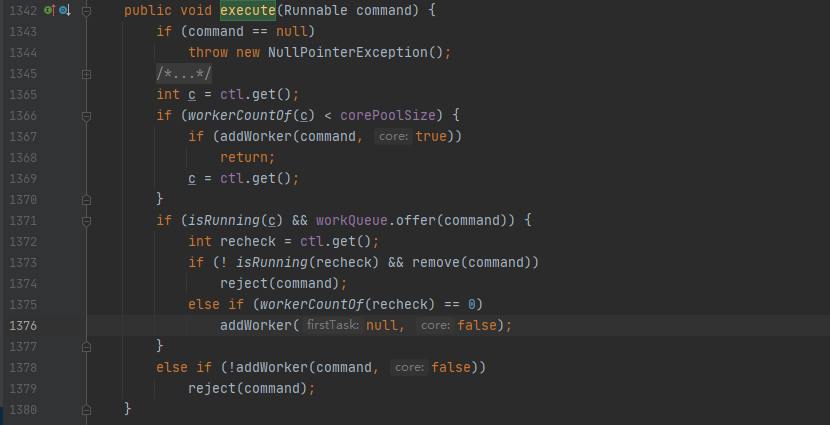
其执行过程如下:
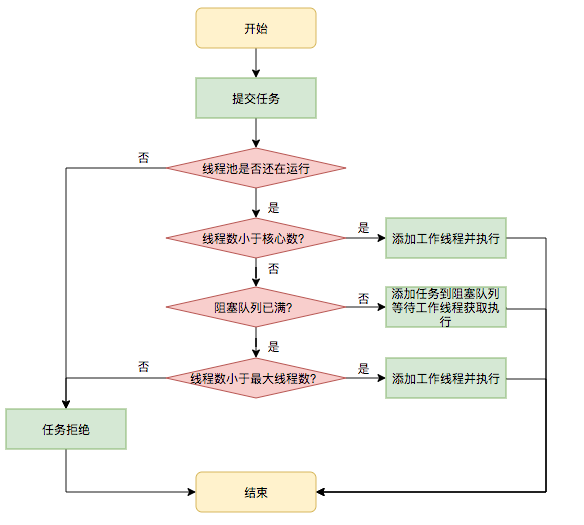
- 首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
- 如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
- 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
其执行流程如下图所示:
2.3.2 任务缓冲
任务缓冲模块是线程池能够管理任务的核心部分。线程池的本质是对任务和线程的管理,而做到这一点最关键的思想就是将任务和线程两者解耦,不让两者直接关联,才可以做后续的分配工作。线程池中是以生产者消费者模式,通过一个阻塞队列来实现的。阻塞队列缓存任务,工作线程从阻塞队列中获取任务。
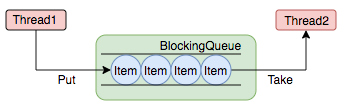
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
下图中展示了线程1往阻塞队列中添加元素,而线程2从阻塞队列中移除元素:
使用不同的队列可以实现不一样的任务存取策略。在这里,我们可以再介绍下阻塞队列的成员:

2.3.3 任务申请
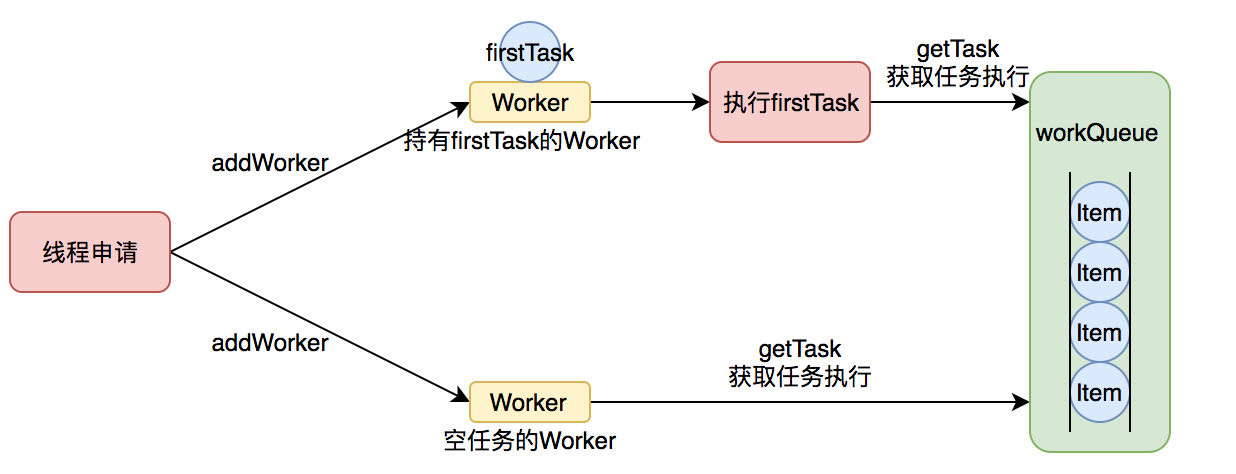
由上文的任务分配部分可知,任务的执行有两种可能:一种是任务直接由新创建的线程执行。另一种是线程从任务队列中获取任务然后执行,执行完任务的空闲线程会再次去从队列中申请任务再去执行。第一种情况仅出现在线程初始创建的时候,第二种是线程获取任务绝大多数的情况。
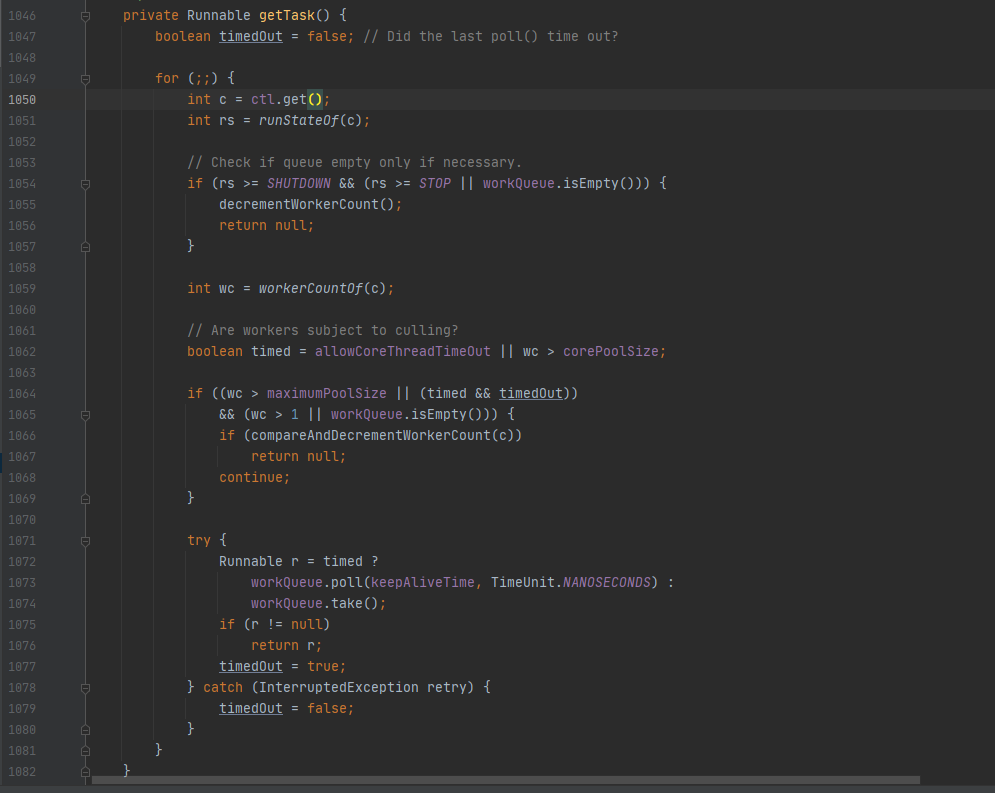
线程需要从任务缓存模块中不断地取任务执行,帮助线程从阻塞队列中获取任务,实现线程管理模块和任务管理模块之间的通信。这部分策略由getTask方法实现。
执行代码如下图所示:
执行流程如下图所示:
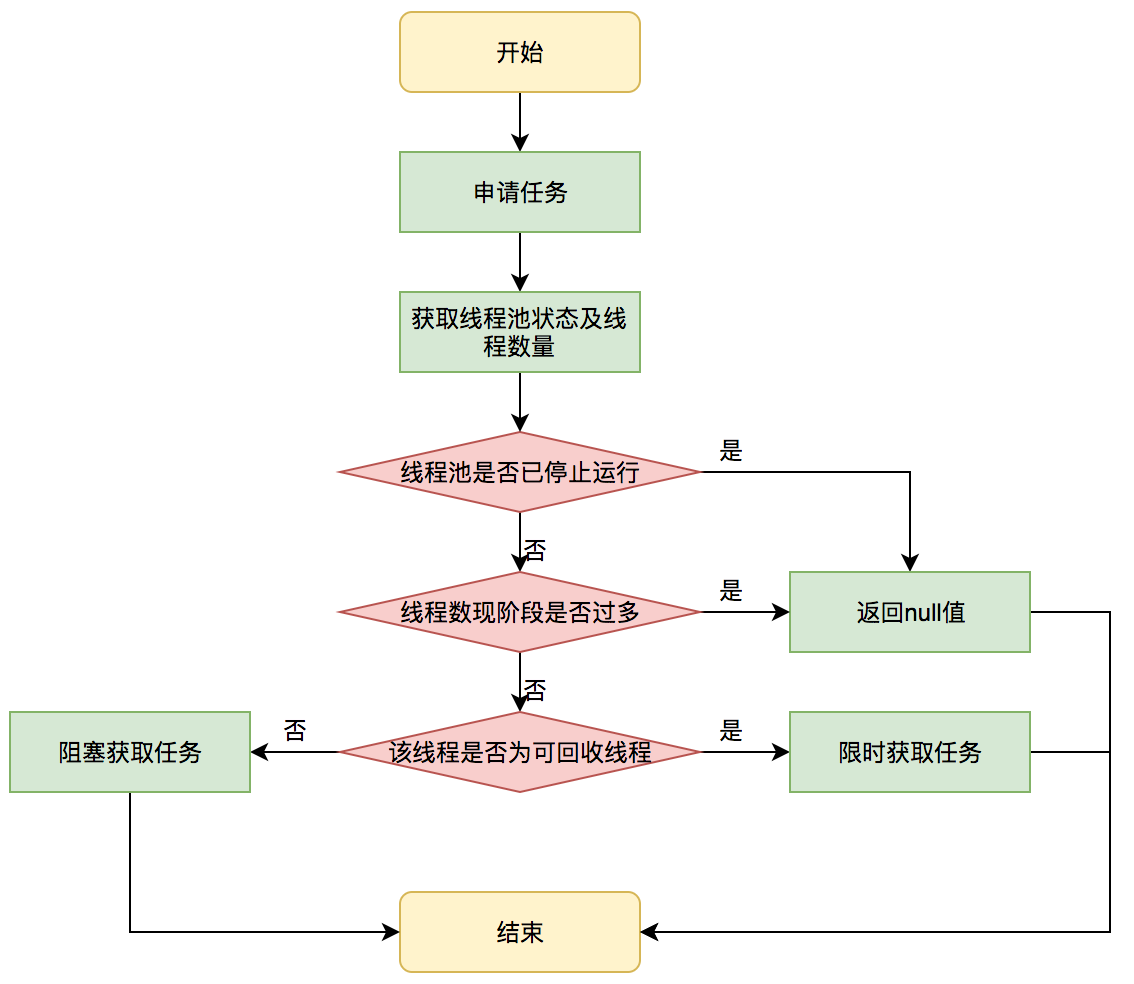
getTask这部分进行了多次判断,为的是控制线程的数量,使其符合线程池的状态。如果线程池现在不应该持有那么多线程,则会返回null值。工作线程Worker会不断接收新任务去执行,而当工作线程Worker接收不到任务的时候,就会开始被回收。
2.3.4 任务拒绝
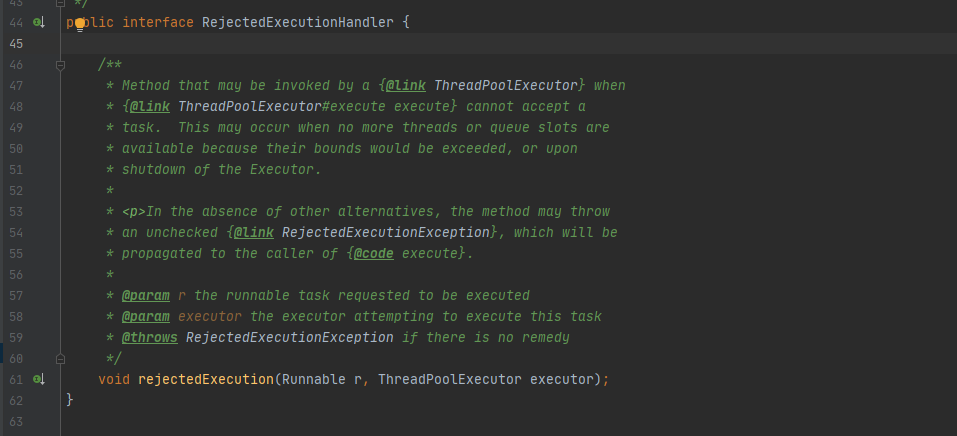
任务拒绝模块是线程池的保护部分,线程池有一个最大的容量,当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。
拒绝策略是一个接口,其设计如下:
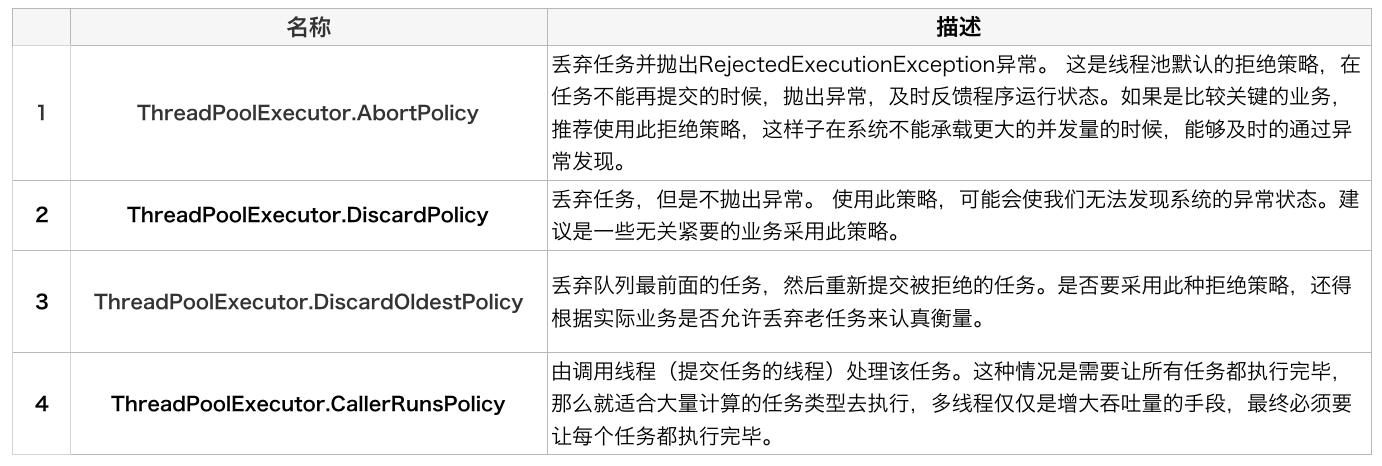
用户可以通过实现这个接口去定制拒绝策略,也可以选择JDK提供的四种已有拒绝策略,其特点如下:
2.4 Worker线程管理
2.4.1 Worker线程
线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程Worker。我们来看一下它的部分代码:
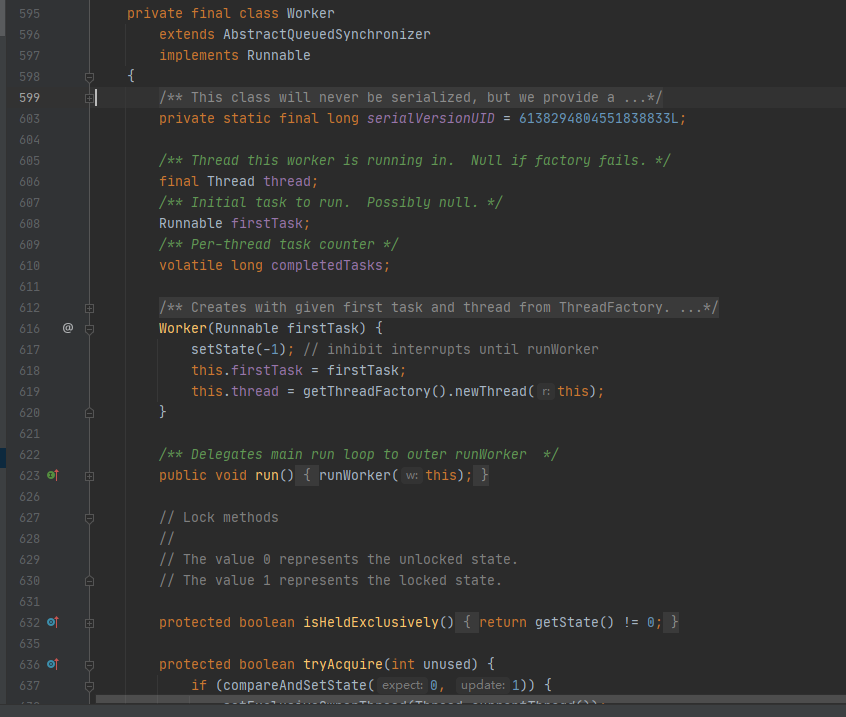
Worker这个工作线程,实现了Runnable接口,并持有一个线程thread,一个初始化的任务firstTask。thread是在调用构造方法时通过ThreadFactory来创建的线程,可以用来执行任务;firstTask用它来保存传入的第一个任务,这个任务可以有也可以为null。如果这个值是非空的,那么线程就会在启动初期立即执行这个任务,也就对应核心线程创建时的情况;如果这个值是null,那么就需要创建一个线程去执行任务列表(workQueue)中的任务,也就是非核心线程的创建。
Worker执行任务的代码如下图所示:
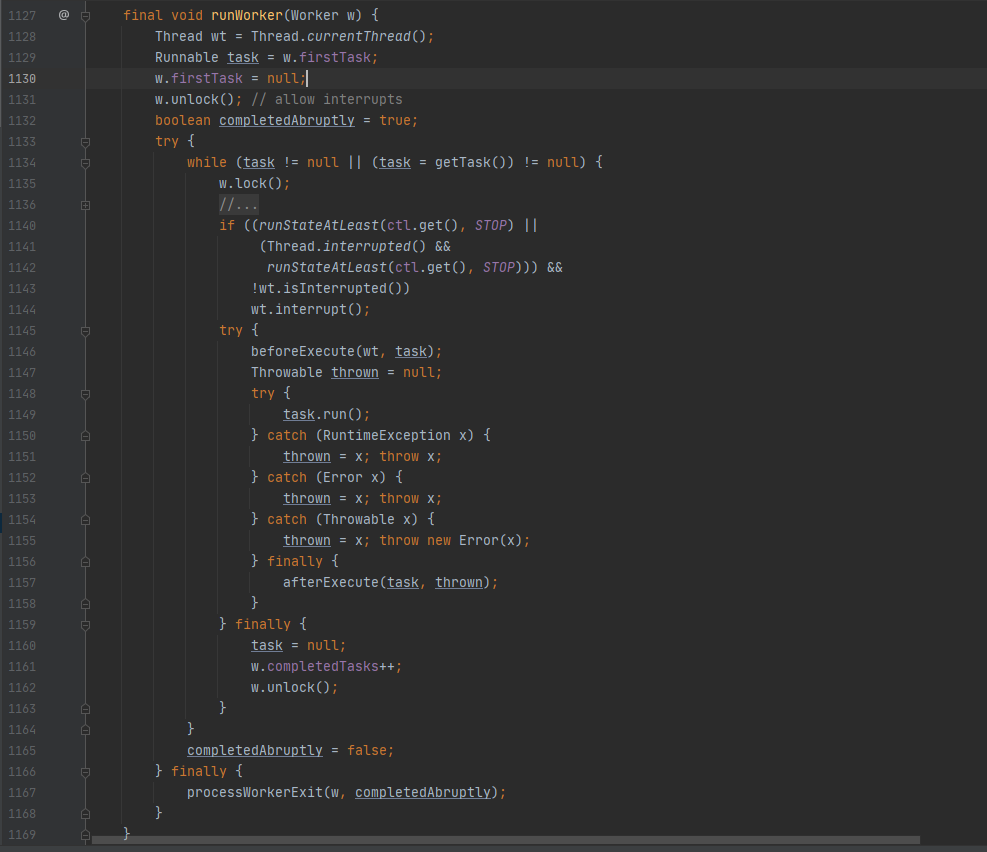
Worker执行任务的模型如下图所示:
线程池需要管理线程的生命周期,需要在线程长时间不运行的时候进行回收。线程池使用一张Hash表去持有线程的引用,这样可以通过添加引用、移除引用这样的操作来控制线程的生命周期。这个时候重要的就是如何判断线程是否在运行。
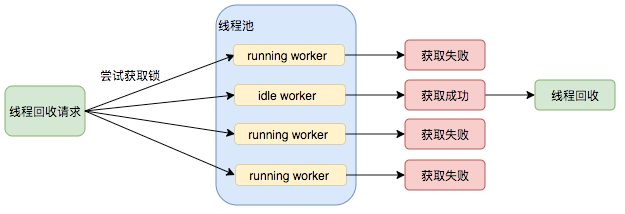
Worker是通过继承AQS,使用AQS来实现独占锁这个功能。没有使用可重入锁ReentrantLock,而是使用AQS,为的就是实现不可重入的特性去反应线程现在的执行状态。
1.lock方法一旦获取了独占锁,表示当前线程正在执行任务中。 2.如果正在执行任务,则不应该中断线程。 3.如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断。 4.线程池在执行shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;如果线程是空闲状态则可以安全回收。
在线程回收过程中就使用到了这种特性,回收过程如下图所示:
2.4.2 Worker线程增加
增加线程是通过线程池中的addWorker方法,该方法的功能就是增加一个线程,该方法不考虑线程池是在哪个阶段增加的该线程,这个分配线程的策略是在上个步骤完成的,该步骤仅仅完成增加线程,并使它运行,最后返回是否成功这个结果。addWorker方法有两个参数:firstTask、core。firstTask参数用于指定新增的线程执行的第一个任务,该参数可以为空;core参数为true表示在新增线程时会判断当前活动线程数是否少于corePoolSize,false表示新增线程前需要判断当前活动线程数是否少于maximumPoolSize。
部分源码如下图所示:
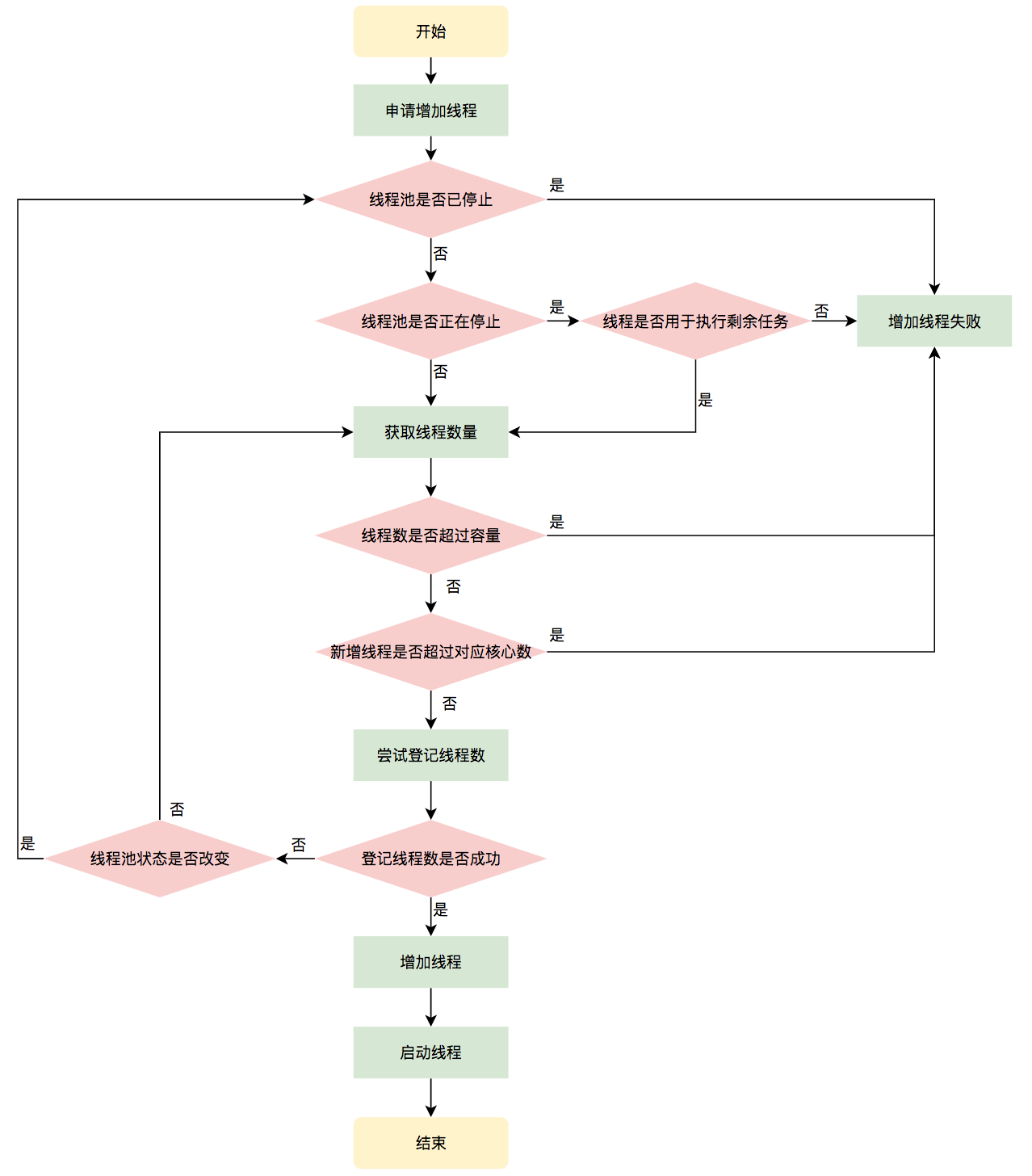
执行流程如下图所示:
2.4.3 Worker线程回收
线程池中线程的销毁依赖JVM自动的回收,线程池做的工作是根据当前线程池的状态维护一定数量的线程引用,防止这部分线程被JVM回收,当线程池决定哪些线程需要回收时,只需要将其引用消除即可。Worker被创建出来后,就会不断地进行轮询,然后获取任务去执行,核心线程可以无限等待获取任务,非核心线程要限时获取任务。当Worker无法获取到任务,也就是获取的任务为空时,循环会结束,Worker会主动消除自身在线程池内的引用。
代码如下图所示:
线程销毁流程如下图所示:
事实上,在这个方法中,将线程引用移出线程池就已经结束了线程销毁的部分。但由于引起线程销毁的可能性有很多,线程池还要判断是什么引发了这次销毁,是否要改变线程池的现阶段状态,是否要根据新状态,重新分配线程。
2.4.4 Worker线程执行任务
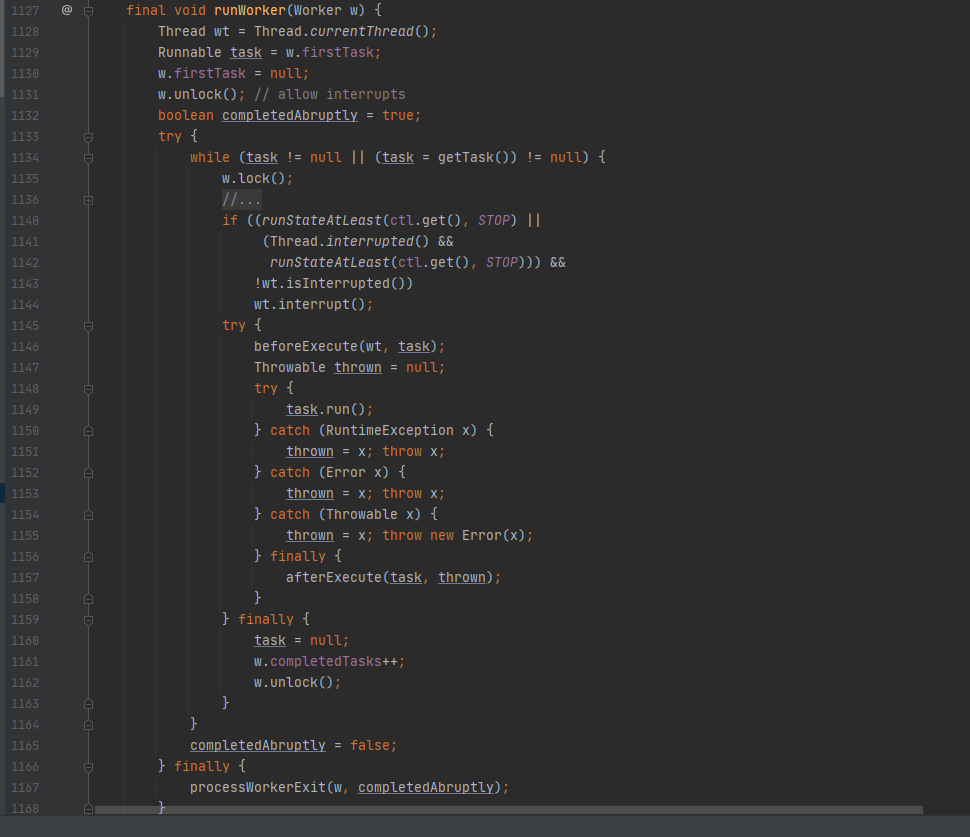
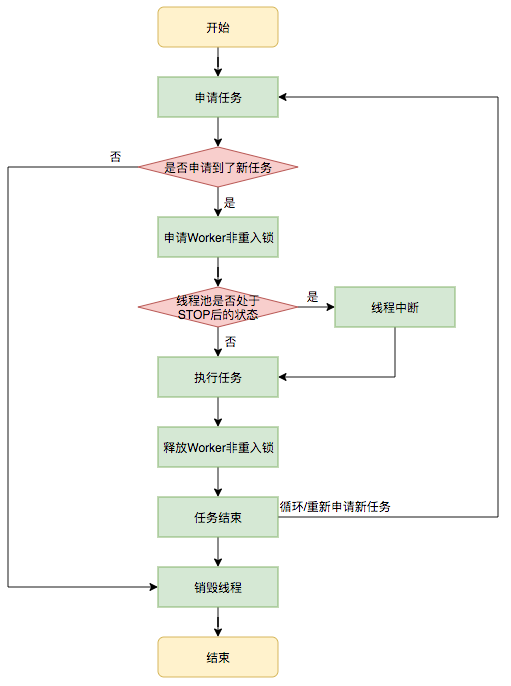
在Worker类中的run方法调用了runWorker方法来执行任务,runWorker方法的执行过程如下:
1.while循环不断地通过getTask()方法获取任务。
2.getTask()方法从阻塞队列中取任务。
3.如果线程池正在停止,那么要保证当前线程是中断状态,否则要保证当前线程不是中断状态。
4.执行任务。
5.如果getTask结果为null则跳出循环,执行processWorkerExit()方法,销毁线程。
代码如下图所示:
执行流程如下图所示:
参考资料
- [1] JDK 1.8源码
- [2] 深入理解Java线程池:ThreadPoolExecutor
- [3]《Java并发编程实践》
- [4] Java线程池实现原理及其在美团业务中的实践
作者简介
鑫茂,2022年3月参加工作,从事Java后台开发。
高度自律,中度代码洁癖,喜欢Java,看到美的东西就会拼命研究。闲暇之余,喜读思维方法、哲学心理学以及历史等方面的书,偶尔写些文字。
希望通过文章,结识更多同道中人。
写在最后
编码是一个技术活需要不断深入研究,我建议大家多带着问题去通过源码系统性学习,少看一些简单的博文或八股文,切记走马观花,要脚踏实地,亲身实践。















 3640
3640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









