







- 用于智能驾驶场景的语义分割
- 是第一个具有目标类别语义标签的视频集合。
- 数据集包括700多张精准标注的图片用于强监督学习,可分为训练集、验证集、测试集。
- 在 CamVid 数据集中通常使用 11 种常用的类别来进行分割精度的评估,分别为:
- 道路 (Road)
- 交通标志(Symbol)
- 汽车(Car)
- 天空(Sky)
- 行人道(Sidewalk)
- 电线杆 (Pole)
- 围墙(Fence)
- 行人(Pedestrian)
- 建筑物(Building)
- 自行车(Bicyclist)
- 树木(Tree)。
- 提供32个ground truth语义标签,将每个像素与语义类别之一相关联。
- 数据是从驾驶汽车的角度拍摄的,驾驶场景增加了观察目标的数量和异质性。
- Cambridge-driving标签视频数据库(CamVid)是第一个包含对象类语义标签的视频集合,其中包含元数据。
- 提供超过10分钟的高质量30Hz连续镜头,对应的语义标记图像为1Hz,部分为15Hz。
- CamVid数据库提供了与对象分析研究人员相关的四个贡献:
- 手动指定700多幅图像的逐像素语义分割,然后由第二个人检查并确认其准确性。
- 数据库中高质量、高分辨率的彩色视频图像有益于对驾驶场景或自我运动感兴趣的人,数据是有价值的长时间数字化视频。
- 制作者拍摄了相机颜色响应和内部物理的标定序列,并计算了序列中每一帧的三维相机姿态。
- 为了支持扩展该数据库或其他数据库,制作者还提供了定制的标签软件,帮助用户为其他图像和视频绘制精确的类标签。通过测量算法在三个不同领域的性能来评估数据库的相关性:多类目标识别、行人检测和标签传播。
- 官网下载即可。
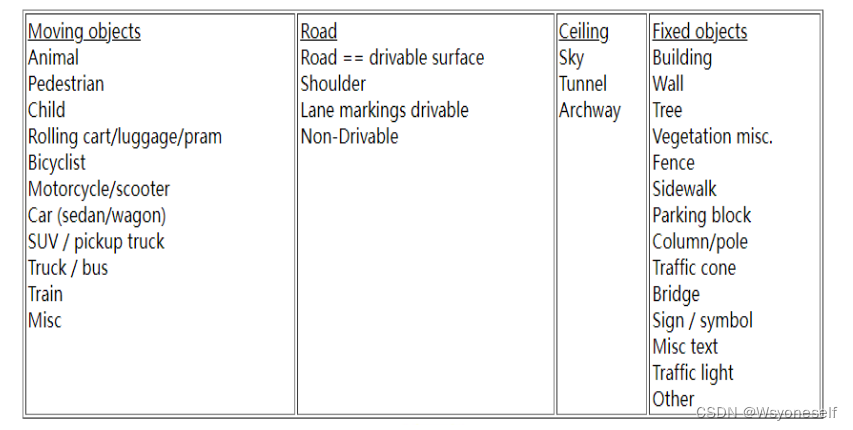
- 类别标签:

- 大类别进行细分:

















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









