







MapReduce
一、MapReduce概述
1.1 MapReduce定义
\quad \quad MapReduce是一个用于处理海量数据的分布式计算框架,并发运行在一个Hadoop集群上。
1.2 MapReduce优缺点
优点
- MapReduce易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一摸一样的。就是因为这个特点使得MapReduce编程变得非常流行 - 良好的拓展性
当你的计算资源不能得到满足得时候,你可以通过简单的增加机器来扩展它的计算能力 - 高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是Hadoop内部完成的 - 适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力
缺点
- 不擅长事实计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果 - 不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化,因为MapReduce自身的设计特点决定了数据源必须是静态的 - 不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
1.3 应用场景
\quad \quad MapReduce的应用场景主要表现在从大规模数据中进行计算,不要求及时返回结果的场景,比如如下典型应用:
- 单词统计
- 简单的数据统计
- 搜索引擎建立索引
- 搜索引擎中,统计最流行的k个搜索词
- …
二、MapReduce框架原理
2.1 MapReduce执行过程

两个重要的进程
1、 JobTracker
- 主进程,承担着资源管理和任务管理,监控的角色。负责接收客户作业提交,调度任务到作节点上运行,并提供诸如监控工作节点状态及任务进度等主管理功能,一个MapReduce集群有一个jobtracker,一般运行在可靠的硬件上。
- tasktracker是通过周期性的心跳来通知jobtracker其当前的健康状态,每一次心跳包含了可用的map和reduce任务数目、占用的数目以及运行中的任务详细信息。Jobtracker利用一个线程池来同时处理心跳和客户请求。
2、 TaskTracker
- 从进程,干活,运行Map Task和Reduce Tack
- 由jobtracker指派任务,实例化用户程序,在本地执行任务并周期性地向jobtracker汇报状态。在每一个工作节点上永远只会有一个tasktracker
工作原理
- JobTracker一直在等待JobClient提交作业
- TaskTracker每隔3秒向JobTracker发送心跳询问有没有任务可做,如果有,让
其派发任务给它执行 - Slave主动向master拉生意
三大阶段:
- Map
- Reduce
- Shuffle
2.2 MapReduce计算流程

单机程序计算流程
- 输入数据—>读取数据—>处理数据—>写入数据—>输出数据
Hadoop中MapReduce计算流程
1、 input data(输入数据)
2、—>存储在HDFS中:每个文件切分成多个一定大小(hdfs2中默认128M)的block(默认3个备份)存储在多个节点(DataNode)上。
3、—> InputFormat:MR框架基础类之一,对数据进行格式转化。
- 数据分割(Data Split)
- 记录读取器(Record Reader):每读取一条记录,调用map函数
4、—> Split:压缩文件不能切分,一个文件对应一个map
- 每个Split包含后一个Block中开头部分的数据(解决记录跨Block问题)
5、—>map:将前面切分的数据做map处理(将数据进行分类,输出(k,v)键值对数据)
6、—>shuffle&sort:将相同的数据放在一起,并对数据进行排序处理
7、—>reduce:将map输出的数据进行hash计算,对每个map数据进行统计计算
8、—>OutputFormat:格式化输出数据,存储到HDFS中的一个目录上
下面来详细看一下shuffl阶段

Shuffle阶段
\quad \quad
Shuffle又叫“洗牌”,可以说是MapReduce的核心,是MapReduce奇迹发生的地方,横贯Map端和Reduce端。
1.Map端shuffle: 写到缓冲区;溢写;分区;合并;排序;
\quad \quad inputsplit(输入切片)->map(每一个切片对应一个map)->map输出的数据,放入环形溢写缓冲区(默认100M,达到80M进行溢写,写入到本地文件)-> partition,sort(快速排序),溢写到磁盘->数据合并(①减少数据写入磁盘的数据量 ② 减少网络传输的数据量 , 数据压缩) ->fetch (通过jobtracker,知道的宏观信息,reduce,找到指定的map主动fetch数据)
\quad \quad Map处理后的数据会以(key,value)键值对的形式存在缓冲区(buffer in memory),缓冲区大小默认为100M,达到80M进行溢写,写入到本地文件也就是溢写操作(spill to disk)。溢写磁盘的过程是由一个线程来完成,溢写之前包括Partition(分区)和Sort(快排),分区和排序都有默认实现,其中分区是按照“hash值%reduce数量”进行分区的,分区之后的数据会进入到不同的Reduce。溢写之后会在磁盘上生成多个文件,多个文件会通过Merge线程完成文件的合并,由多个小文件生成一个大文件。
2.Reduce端shuffle:
->溢写,排序(归并排序),merger(数据合并①减少数据量 ② 提高执行效率)->reduce(汇总,聚合的过程)->output(hdfs)
2.3 MapReduce编程模型
1、MapReduce分而治之的思想
MapReduce映射
- 分:Map,把复杂的问题分解为若干简单的
- 合:reduce
2、MapReduce编程分Map和Reduce阶段
MapReduce编程执行步骤
- 准备MapReduce的输入数据
- 准备Mapper数据
- Shuffle
- Reduce处理
- 结果输出
3、编程模型
程序员只需要编写Map和Reduce函数
-
借鉴函数式编程方式
-
用户只需要实现两个函数接口:
-
Map(in_key,in_value)
—>(out_key,intermediate_value) list
-
Reduce(out_key,intermediate_value) list
—>out_value list
-
三、Hadoop Streaming
\quad \quad MapReduce和HDFS采用Java实现,默认提供Java编程接口。为了可以运用多种语言进行工作,产生了多种编程工具。
3.1 Hadoop Streaming简介
\quad \quad Hadoop Streaming 是Hadoop提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer 作业。Hadoop Streaming 使用了 Unix 的标准输入输出作为 Hadoop 和其他编程语言的开发接口,因此在其他的编程语言所写的程序中,只需要将标准输入作为程序的输入,将标准输出作为程序的输出就可以了。
3.2 Streaming原理

- 在 hadoop streaming 中,mapper 和 reducer 都是可执行文件,它们从标准输入流读取数据,使用标准输出流输出数据。
- mapper 和 reducer 会一行一行的读取数据,根据分隔符(默认为 tab)将读入的数据切分为 key 和 value,同时,输出的数据也需要是一个 key,value 对,在第一个 tab 分隔符前的会被认为是 key,后面的都作为 value。如,输出时 print("%s\t%s", %(key, value))
3.3 运行任务流程
1、将数据传输到HDFS上
2、写一个map函数,主要进行一个键值对的输出
3、写一个reduce函数,主要对上述键值对进行合并,并以键值对的形式输出
4、写一个脚本命令,调用Streaming工具
前面说过,Streaming的基本过程与linux管道类似,所以可以在本地先进行简单的测试。 这里的测试只能测试程序的逻辑基本符合预期,作业的属性设置
更多的参数设置见官方文档
3.4 Streaming优点
1、开发效率高
- 方便移植Hadoop平台,只需按照一定的格式从标准输入读取数据、向标准输出写数据就可以
- 原有的单机程序稍加改动就可以在Hadoop平台进行分布式处理
- 容易单机调试
cat input | mapper | sort | reducer > output
2、程序运行效率高
- 对于CPU密集的计算,有些语言如C/C++编写的程序可能比用Java编写的程序效率更高一些
3、便于平台进行资源控制
- Streaming框架中通过limit等方式可以灵活地限制应用程序使用的内存等资源
3.5 Streaming局限
- Streaming默认只能处理文本数据,如果要对二进制数据进行处理,比较好的方法是将二进
制的key和value进行base64的编码转化成文本即可 - 两次数据拷贝和解析(分割),带来一定的开销
四、 MapReduce小案例
\quad \quad
为了测试所写的map与reduce函数是否正确,先在本地进行测试,然后上传Hadoop 集群运行任务。
运行环境:Python 2.7.5; Hadoop 2.6.5
4.1 WordCount——统计单词词频
需求:现有一文本,要求统计文本中所出现不同单词的次数

- Split阶段:首先大文件被切分成多份,假设这里被切分成了三份,每一行代表一份。
- Map阶段:一一映射,解析出每个单词,并在后边记上数字1。需要编程一个Map函数
- Shuffle阶段:将每一份中的单词分组到一起,并默认按照字母进行排序,框架自带
- Reduce阶段:将相同的单词进行累加。需要编程一个Reduce函数
- Final result:将结果输入到HDFS中的一个目录中
本地测试
1、通过Xshell上传The_Man_of_Property.txt文本到本地

2、编写map函数——以<key,1>的形式输出文本所有单词
vim map.py
# coding=UTF-8
import sys
import re
p = re.compile(r'\w+')#compile 函数用于编译正则表达式,生成一个Pattern对象
for line in sys.stdin:#sys.stdin标准化输入
ss=line.strip().split(' ')
for s in ss:
if len(p.findall(s)) < 1:
continue
s = p.findall(s)[0].lower()
if s.strip()!="":
print "%s\t%s" % (s,1)
验证map函数:
- 取数据中的前两行进行测试
head -n 2 The_Man_of_Property.txt | python map.py

ok,输出准确。下面来写reduce函数
3、编写Reduce函数——以<key,value>的形式统计每个单词频数
该阶段只需要将相同word数量累加起来
vim red.py
#-*- coding:UTF-8 -*-
import sys
current_word = None
sum = 0
for line in sys.stdin:
word,val=line.strip().split('\t')
if current_word == None:
current_word = word
elif current_word!=word:
print '%s\t%s'%(current_word,sum)
current_word = word
sum=0
sum+=int(val)
print '%s\t%s'%(current_word,str(sum))#这一句不能丢弃,最后一个词的统计量也要输出
验证:
cat The_Man_of_Property.txt|python map.py|sort -k1|python red.py
\quad \quad
其中,命令中包含的sort -k1【是指以map输出数据键进行排序】工作在MR计算的combine阶段自动帮我们完成
结果:
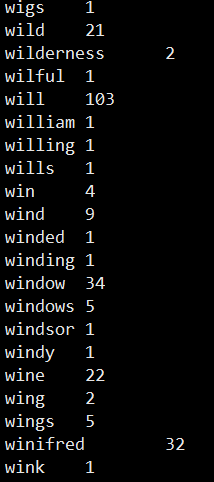
到此,本地测试结束
上Hadoop集群运行
前提:
\quad \quad
启动集群
start-all.sh
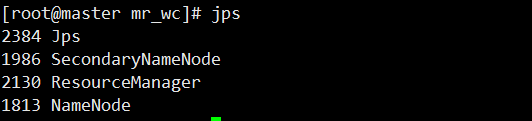
成功
1、将数据上传到HDFS
1.1 先在HDFS中创建一个data目录(也可以在hdfs已有的目录上传)
hadoop fs -mkdir /data

1.2 将文件上传到hdfs中data目录下
hadoop fs -put The_Man_of_Property.txt /data

2、创建一个运行脚本
2.1 首先需要找到一些路径
- 找到hadoop-streaming
find / -name 'hadoop-streaming*.jar'

第一个就是我们要找的目标即hadoop-streaming-2.6.1.jar路径
2.2 编写脚本
vim run.sh
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_FILE_PATH_1="/data/The_Man_of_Property.txt"
#INPUT_FILE_PATH_1="/data/1.data"
OUTPUT_PATH="/output/wc"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-reducer "python red.py" \
-file ./map.py \
-file ./red.py
- 其中
OUTPUT_PATH="/output/wc"是输出路径,也就是说我们想把结果最终放在哪里
3、启动脚本
sh -x run.sh
结果:
[root@master mr_wc]# sh -x run.sh
+ HADOOP_CMD=/usr/local/src/hadoop-2.6.1/bin/hadoop
+ STREAM_JAR_PATH=/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar
+ INPUT_FILE_PATH_1=/data/The_Man_of_Property.txt
+ OUTPUT_PATH=/output/wc
+ /usr/local/src/hadoop-2.6.1/bin/hadoop fs -rmr -skipTrash /output/wc
rmr: DEPRECATED: Please use 'rm -r' instead.
rmr: `/output/wc': No such file or directory
+ /usr/local/src/hadoop-2.6.1/bin/hadoop jar /usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar -input /data/The_Man_of_Property.txt -output /output/wc -mapper 'python map.py' -reducer 'python red.py' -file ./map.py -file ./red.py
20/12/17 21:55:13 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.
packageJobJar: [./map.py, ./red.py, /tmp/hadoop-unjar2730361812041545000/] [] /tmp/streamjob521228067383488185.jar tmpDir=null
20/12/17 21:55:14 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.233.130:8032
20/12/17 21:55:15 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.233.130:8032
20/12/17 21:55:16 INFO mapred.FileInputFormat: Total input paths to process : 1
20/12/17 21:55:16 INFO mapreduce.JobSubmitter: number of splits:2
20/12/17 21:55:16 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1608212089320_0001
20/12/17 21:55:17 INFO impl.YarnClientImpl: Submitted application application_1608212089320_0001
20/12/17 21:55:17 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1608212089320_0001/
20/12/17 21:55:17 INFO mapreduce.Job: Running job: job_1608212089320_0001
20/12/17 21:55:27 INFO mapreduce.Job: Job job_1608212089320_0001 running in uber mode : false
20/12/17 21:55:27 INFO mapreduce.Job: map 0% reduce 0%
20/12/17 21:55:50 INFO mapreduce.Job: map 100% reduce 0%
20/12/17 21:55:57 INFO mapreduce.Job: map 100% reduce 100%
20/12/17 21:55:58 INFO mapreduce.Job: Job job_1608212089320_0001 completed successfully
20/12/17 21:55:58 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1026038
FILE: Number of bytes written=2381298
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=635790
HDFS: Number of bytes written=92691
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=121896
Total time spent by all reduces in occupied slots (ms)=15192
Total time spent by all map tasks (ms)=40632
Total time spent by all reduce tasks (ms)=5064
Total vcore-seconds taken by all map tasks=40632
Total vcore-seconds taken by all reduce tasks=5064
Total megabyte-seconds taken by all map tasks=124821504
Total megabyte-seconds taken by all reduce tasks=15556608
Map-Reduce Framework
Map input records=2866
Map output records=110509
Map output bytes=805014
Map output materialized bytes=1026044
Input split bytes=198
Combine input records=0
Combine output records=0
Reduce input groups=9000
Reduce shuffle bytes=1026044
Reduce input records=110509
Reduce output records=9000
Spilled Records=221018
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=508
CPU time spent (ms)=7240
Physical memory (bytes) snapshot=489558016
Virtual memory (bytes) snapshot=6230503424
Total committed heap usage (bytes)=259362816
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=635592
File Output Format Counters
Bytes Written=92691
20/12/17 21:55:58 INFO streaming.StreamJob: Output directory: /output/wc
任务成功
4、查看结果
hadoop fs -ls /output/wc

hadoop fs -cat /output/wc/part-00000
部分结果:
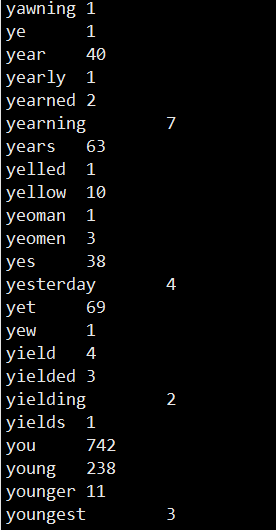
同时可以在网址下载结果

4.2 统计指定单词词频
需求:现有一文本,一单词本,要求只统计文本中包含单词本中每一个单词的次数。
分析:与4.1类似,但此案例有一约束:只统计其包含单词的词频,因此需要重写map函数
- 首先我们需要将单词本所含单词提取出来
- 然后过滤文本
本地测试
1、通过Xshell上传The_Man_of_Property.txt文本、white_list单词本到本地

2、编写map函数——以<key,1>的形式输出文本含有单词本中的所有单词
vim map.py
# coding=UTF-8
import sys
import re
#从单词本中 提取指定单词
def read_local_file_func(f):
word_set = set()
file_in = open(f,'r')
for line in file_in:
word=line.strip()
word_set.add(word)
return word_set
# map函数
def mapper_func(white_list_fd):
word_set = read_local_file_func(white_list_fd)
p=re.compile(r'\w+')
for line in sys.stdin:
ss=line.strip().split(' ')
for s in ss:
array_s=p.findall(s)
for word in array_s:
if word.strip()!=""and (word in word_set):
print '%s\t%s'%(word.lower(),1)
if __name__=="__main__":
module = sys.modules[__name__]
func = getattr(module,sys.argv[1])
args = None
if len(sys.argv)>1:
args = sys.argv[2:]
func(*args)#*args使函数可以接收任意多个参数,将实参数转换为列表使用
验证map函数:
cat The_Man_of_Property.txt | python map.py mapper_func white_list | head

ok
3、编写Reduce函数
直接使用4.1案例的reduce即可,为了方便,还是把它copy下来
#-*- coding:UTF-8 -*-
import sys
current_word = None
sum = 0
for line in sys.stdin:
word,val=line.strip().split('\t')
if current_word == None:
current_word = word
elif current_word!=word:
print '%s\t%s'%(current_word,sum)
current_word = word
sum=0
sum+=int(val)
print '%s\t%s'%(current_word,str(sum))#这一句不能丢弃,最后一个词的统计量也要输出
验证:
cat The_Man_of_Property.txt |python map.py mapper_func white_list |sort -k1|python red1.py

大功告成
上Hadoop运行
4.3 统计用户购买了哪些订单
需求:现有一订单流水单,数据格式为

要求以sort1 1,2 的格式统计用户都购买了哪些订单
本地测试
1、通过Xshell上传数据到本地
2、编写map函数
vim map.py
import sys
for line in sys.stdin:
key = line.strip().split('\t')
print '\t'.join(key)
#print key
验证:

3、编写reduce函数;
vim red.py
import sys
cur = None
cur_list = []
for line in sys.stdin:
ss = line.strip().split('\t')
key = ss[0]
val = ss[1]
if cur == None:
cur = key
elif cur!=key:
print '%s\t%s'%(cur,','.join(cur_list))
cur = key
cur_list = []
cur_list.append(val)
print '%s\t%s'%(cur,','.join(cur_list))
4、测试:
[root@master mr_sec]# cat 1.data |python map.py |sort -k1 |python red.py
sort1 1,2
sort2 3,54,88
sort6 22,58,888
成功
4.4 MapReduce join
需求:
已知:
- a集合,可理解为用户——消费金额
aaa1 123
aaa2 123
aaa3 123
- b集合,可理解为用户——购买商品
aaa1 hadoop
aaa2 java
aaa3 python
输出join后的结果:
aaa1 123 hadoop
aaa2 123 java
aaa3 123 python
分析: 通过mapper对两个数据集格式化后保存到HDFS,再启动一个mr对两个数据集进行合并
1、上传数据到本地
2、编写map
- 2.1 map_a.py
vim map_a.py
import sys
for line in sys.stdin:
ss = line.strip().split(' ')
key = ss[0]
val = ss[1]
print "%s\t1\t%s" % (key, val)
验证:

- 2.1 map_b.py
vim map_b.py
import sys
for line in sys.stdin:
ss = line.strip().split(' ')
key = ss[0]
val = ss[1]
print "%s\t2\t%s" % (key, val)
验证:

- 可以看到对集合a,b集合增加了一个标识(1,2),是为了方便在join的时候判断两个集合的数据接收到了。
3、编写reduce函数
- 这个阶段的工作就是将前面输出的两个集合合并
vim red_join.py
import sys
val_1 = ""
for line in sys.stdin:
key, flag, val = line.strip().split('\t')
if flag == '1':
val_1 = val
elif flag == '2' and val_1 != "":
val_2 = val
print "%s\t%s\t%s" % (key, val_1, val_2)
val_1 = ""
4、上传数据到HDFS中
hadoop fs -put a_join.txt /data
hadoop fs -put b_join.txt /data

5、编写run脚本
vim run.sh
set -e -x
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_FILE_PATH_A="/data/a_join.txt"
INPUT_FILE_PATH_B="/data/b_join.txt"
OUTPUT_A_PATH="/output/a"
OUTPUT_B_PATH="/output/b"
OUTPUT_JOIN_PATH="/output/join"
#$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_A_PATH $OUTPUT_B_PATH $OUTPUT_JOIN_PATH
#$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_JOIN_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_A \
-output $OUTPUT_A_PATH \
-mapper "python map_a.py" \
-file ./map_a.py \
# Step 2.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_B \
-output $OUTPUT_B_PATH \
-mapper "python map_b.py" \
-file ./map_b.py \
# Step 3.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $OUTPUT_A_PATH,$OUTPUT_B_PATH \
-output $OUTPUT_JOIN_PATH \
-mapper "cat" \
-reducer "python red_join.py" \
-file ./red_join.py \
-jobconf stream.num.map.output.key.fields=2 \
-jobconf num.key.fields.for.partition=1
6、启动脚本
sh -x run.sh
7、查看结果

参考资料:
https://blog.csdn.net/IronmanJay/article/details/107476172
未完待续















 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









