






内存及CPU占用:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
xxxx xxx 20 0 10.9g 1.3g 67004 S 2483 0.5 23:37.22 python【MindSpore Dataset】在使用Dataset处理数据过程中内存占用高,怎么优化?
1. 背景说明
针对一些资源(CPU和Memory)比较紧张的环境,在进行数据预处理时会出现CPU占用过高,或者内存占用高的情况。
主要原因如下:
-
用户在使用mindspore.dataset进行数据集加载、预处理时,mindspore.dataset主要是使用Host侧CPU和Memory资源。
-
而Dataset的经典处理流程如下:
**Dataset(...)->.map(...)->.map(...)->.batch(...)->.create_dict_iterator(...)其中每个节点之间都有一个队列用来缓存数据(会占用内存),进而实现整个流程的Pipeline,另外部分参数的默认值(如:并行度高导致内存占用高)适用于服务器环境,所以对于CPU和Memory比较紧张的环境,需要通过配置、参数或者脚本优化来进一下的减少内存占用。
那么可以参考如下方法降低CPU/内存的占用。
2. 报错举例
- 日志报错输出 - LLVM ERROR: out of memory
参考链接:华为云论坛_云计算论坛_开发者论坛_技术论坛-华为云
- 日志输出告警 - Memory consumption is more than ..., which may cause oom error. 参考链接:yolov4使用mosaic数据增强后,内存不足,无明显告警和报错下自动退出 · Issue #I4JUOX · MindSpore/mindspore - Gitee.com
- 日志报错输出 - dataset/util/arena.cc ... cudaHostAlloc failed, ret[2], out of memory
参考链接:华为云论坛_云计算论坛_开发者论坛_技术论坛-华为云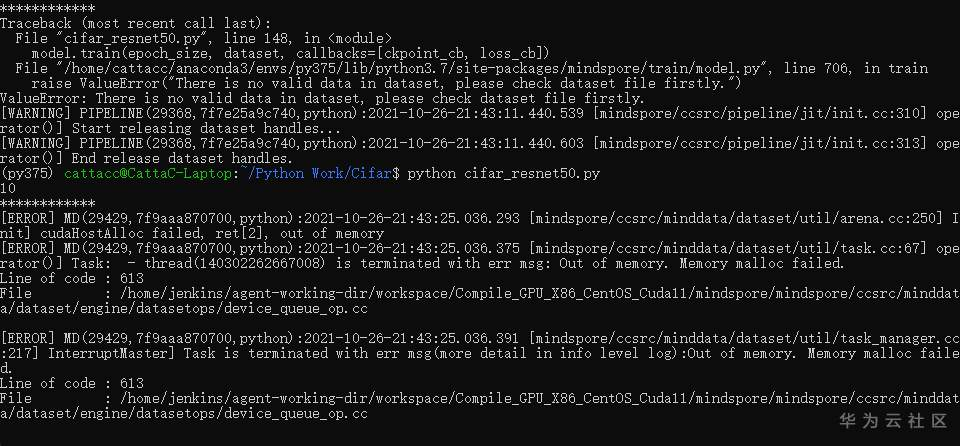
3. 现有状态说明
以ImageNet数据集为例,其样本个数为128w+,典型的数据预处理流程如下:
import multiprocessing
import mindspore as ms
import mindspore.dataset as ds
from mindspore.communication.management import init, get_rank, get_group_size
dataset_path = "/data2/ImageNet_Original/train"
batch_size = 32
train_image_size = 224
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=12, shuffle=True)
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
# define map operations
random_crop_decode_resize_op = ds.vision.c_transforms.RandomCropDecodeResize(train_image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
random_horizontal_flip_op = ds.vision.c_transforms.RandomHorizontalFlip(prob=0.5)
normalize_op = ds.vision.c_transforms.Normalize(mean=mean, std=std)
hwc2chw_op = ds.vision.c_transforms.HWC2CHW()
type_cast_op = ds.transforms.c_transforms.TypeCast(ms.int32)
data_set = data_set.map(operations=random_crop_decode_resize_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=random_horizontal_flip_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=normalize_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=12)
# apply batch operations
data_set = data_set.batch(batch_size, drop_remainder=True)
count = 0
for item in data_set.create_dict_iterator(output_numpy=True):
count += 1
if count % 1000 == 0:
print("count: {}".format(count))
机器配置如下:
CPU: Intel(R) Xeon(R) CPU E7-4890 v2 @ 2.80GHz ,核数:120 内存:250G
当前脚本运行后内存及cpu占用如下:
3. 优化方法及效果
1) 通过配置预取大小减少内存占用
在定义数据集**Dataset对象前,设置Dataset数据处理预取的大小,ds.config.set_prefetch_size(2)。
脚本变化:
ds.config.set_prefetch_size(2) PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
xxxx xxx 20 0 11.0g 1.5g 66652 S 2993 0.6 19:43.85 python内存及CPU占用:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
xxxx xxx 20 0 10.9g 1.3g 67004 S 2483 0.5 23:37.22 python2) 通过减少数据集加载类**Dataset参数num_parallel_workers减少内存占用
在定义**Dataset对象时,设置其参数num_parallel_workers为1。
脚本变化:
28c28
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=12, shuffle=True)
---
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=1, shuffle=True)
内存及CPU占用:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
xxxx xxx 20 0 9900300 1.0g 66652 S 1455 0.4 12:53.03 python
复制复制3) 通过减少数据预处理操作.map(...)参数num_parallel_workers减少内存占用
如果对**Dataset对象进一步使用了.map(...)操作,可以设置.map(...)的参数num_parallel_workers为1。
脚本变化:
40,44c40,44
data_set = data_set.map(operations=random_crop_decode_resize_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=random_horizontal_flip_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=normalize_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=12)
---
data_set = data_set.map(operations=random_crop_decode_resize_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=random_horizontal_flip_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=normalize_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=1)
内存及CPU占用:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
xxxx xxx 20 0 9900300 1.0g 66652 S 1455 0.4 12:53.03 python3) 通过减少数据预处理操作.map(...)参数num_parallel_workers减少内存占用
如果对**Dataset对象进一步使用了.map(...)操作,可以设置.map(...)的参数num_parallel_workers为1。
脚本变化:
40,44c40,44
data_set = data_set.map(operations=random_crop_decode_resize_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=random_horizontal_flip_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=normalize_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=12)
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=12)
---
data_set = data_set.map(operations=random_crop_decode_resize_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=random_horizontal_flip_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=normalize_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=1)
内存及CPU占用:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
xxxx xxx 20 0 5845040 746140 66668 S 170.9 0.3 3:49.30 python
4) 通过减少数据batch操作.batch(...)参数num_parallel_workers减少内存占用
如果对**Dataset对象进一步使用了.batch(...)操作,可以设置.batch(...)的参数num_parallel_workers为1。
脚本变化:
47c47
data_set = data_set.batch(batch_size, drop_remainder=True)
---
data_set = data_set.batch(batch_size, drop_remainder=True, num_parallel_workers=1)
内存及CPU占用:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
xxxx xxx 20 0 5328916 496948 66652 S 187.4 0.2 3:25.25 python
5) 通过减少数据map操作.map(...)的个数来减少内存占用
如果有多个.map(...)操作,可以将多个.map(...)操作合并为一个。
脚本变化:
34,37c34,39
random_crop_decode_resize_op = ds.vision.c_transforms.RandomCropDecodeResize(train_image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
random_horizontal_flip_op = ds.vision.c_transforms.RandomHorizontalFlip(prob=0.5)
normalize_op = ds.vision.c_transforms.Normalize(mean=mean, std=std)
hwc2chw_op = ds.vision.c_transforms.HWC2CHW()
---
trans = [
ds.vision.c_transforms.RandomCropDecodeResize(train_image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
ds.vision.c_transforms.RandomHorizontalFlip(prob=0.5),
ds.vision.c_transforms.Normalize(mean=mean, std=std),
ds.vision.c_transforms.HWC2CHW()
]
40,43c42
data_set = data_set.map(operations=random_crop_decode_resize_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=random_horizontal_flip_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=normalize_op, input_columns="image", num_parallel_workers=1)
data_set = data_set.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=1)
---
data_set = data_set.map(operations=trans, input_columns="image", num_parallel_workers=1)
内存及CPU占用:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
xxxx xxx 20 0 4665328 496364 66652 S 128.2 0.2 4:30.55 python
6) 通过减少数据shuffle操作.shuffle(...)的buffer_size大小来减少内存占用
如果有.shuffle(...)操作,减少buffer_size的大小,因为这个是内存缓存的shuffle,是需要缓存buffer_size大小样本在内存中进行shuffle,所以buffer_size越大,占用的内存也越大。
7) 通过减少数据.batch(...)参数batch_size的大小减少内存占用
如果有.batch(...)操作,减少batch_size的大小,可以减少batch操作缓存的数据量,尽而减少内存占用。
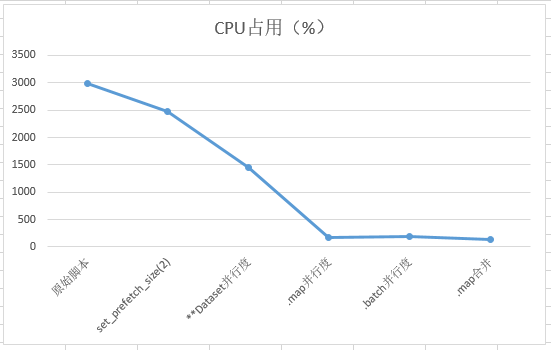
4. 总结
使用各种优化后内存、CPU占用如下:
















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









