






离散数学
关系
各域(属性值)之间的笛卡尔积(求全部组合)的子集,即某几行数据的集合
自反 、反自反、 对称、 反对称
从形式上看,自反 、反自反、 对称、 反对称与传递是对关系内元素之间相等性的约束。自反、反自反是对有序对内元素是否存在相同的约束;对称、反对称是两个有序对之间内容是否相同;传递是多个有序对之间是否存在中间相同要素。从含义上看,自反、 对称与传递是对相等的细化。自反考虑的是自己与自己之间是否在某种关系上相同,如同名、同类、同内容等关系都是自反关系,因为自己与自己的肯定同名、同类、同内容。对称考虑的是在某种关系上方向是否可以互换,如朋友、同学等关系是对称关系,因为这些关系是双向的,而父子、母女等关系不是对称关系,因为不能反过来说。传递是关系的延伸性,即是否可以由局部进行推广的性质,如大小、相等等关系。反自反、反对称则是对不同的细化。反自反要求元素与自身不存在某种关系,如大、小、多、少,不能说自己比自己大、自己比自己多。反对称是方向上的不同,同样是一些反映差异的关系,如张三年龄大于李四成立,不能同时存在李四年龄大于张三成立。
计算机网络
虚电路
分组交换方式可以分为数据报和虚电路两种。
数据报特点:协议简单,无须建立连接,无须为每次通信预留带宽资源;抵抗网络故障的能力很强,适合于突发性强的通信业务;传输时延大,不适用于大数据量、实时性要求高的业务。
虚电路是一种面向连接型的分组交换方式,是将数据报和电路交换这两种技术的优点结合,以达到较好的数据传输效果。在虚电路方式中,分组发送前,需要在发送方与接收方之间建立一条逻辑通路,每个分组除了包含数据之外还包含一个虚电路标识符。在预先建好的路径上每个节点都知道把这些分组引导到哪里去,不再需要路由选择判定。之所以被称为虚电路,是因为这条电路不是专用的。分组有序!
stp交换机生成树协议
能在增加冗余链路(防止某些链路故障,增加可靠性)的同时又不会有冗余链路的缺点,如广播风暴(交换机相连广播域也是会增大的,当一台主机发送广播帧…),主要问题还是在于增加冗余链路后会成环,这样广播帧在不断地发送,stp通过构造最小生成树,使得逻辑链路为树即使物理链路为环,并且在某些链路损坏后自动使用冗余链路且保持最小生成树
vlan
因为交换机相连广播域也是会增大的,于是用多个交换机连起来的大局域网会广播风暴(和上面广播风暴的不同,这里主要是说发送一个广播帧整个大网络都被迫收到),为了分割这种网络的广播域,既可以用路由器(不随便转发广播帧),也可以让交换机自身提供一些功能以实现。
比如
通过允许提前设置交换机的各端口,分配各端口对应的vlan号,并且允许设置各端口的端口类型(软件层面,比如用0,1,2标识)。这里要求提供三种类型(需要同时存在于一台交换机)
①access类型:该端口实现了一个交换机形成的局域网后的vlan的划分,广播只会发给同一个vlan,该端口通常用于个人主机。
对于交换机,若从该类型端口传入(存储)数据包,则为数据包添上该端口的vlan号。转发数据包给access类型端口的时候会看vlan号是否相同,同则去掉vlan号再转发给该端口,不同直接不转发(烂掉),
②trunk类型:通常是用于连接两台交换机的端口(如A,B两台交换机,连接的时候线的一端是A的trunk端口,另一端是B的trunk端口),也可以是路由器与交换机。
对于交换机,对trunk端口传入(存储)的数据包打上标签即该端口的vlan号。转发给trunk端口的时候,数据包的vlan号和该trunk端口相同时则去vlan号转发,不同则直接转发。
IP协议
不可靠无连接
动态路由选择
路由表通过协议自动求得(静态是人自己写)
rip
向邻居路由器发送自己的路由表(每一项是自己到各网络需要经历的路由器个数(来衡量距离),即所谓的距离向量),然后对方择优更新
ospf
使用泛洪法向同一自治系统内所有路由器发送自己到邻居的链路状态信息(自己到邻居路由器的链路的代价(时延、网速)),每个路由器都有一个数据库,存放这些链路状态信息,最终各路由器的数据库完全一致,此时dijikstra最短路径求出路由表(相比于rip多了额外的信息,而不是传送路由表)
bgp
用于自治系统之间的寻址
涉及很多因素,因此目标是找到较好路径且不兜圈子(而不是最优,因为有的自治系统很贱不让你经过使得无法最优)
每个自治系统派一个(部分)路由器充当外交官,与其他自治系统的外交官交换网络可达性
icmp
两个经典应用
ping
traceroute
返回从起点到终点需要经历的路由器
原理是发送icmp回送报文,从ttl=1开始发,于是在第一个路由器就停下,且返回一个时间超过的icmp差错报文,然后再令ttl=2以此类推
tcp和udp
tcp面向字节流,面向连接,可靠传输,流量控制,拥塞控制,常用于文件传输
udp面向报文,无连接,不可靠,速度快,常用于视频聊天及时性
java
深拷贝和浅拷贝
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。但深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象
机器学习
感知机
knn
kd树:用于快速搜寻离当前节点最近的k个邻居节点(原本的knn很慢,需要当前节点对所有节点分别求距离然后得出最近的k个邻居节点)。对于一个k维空间,使用二叉树,每次对一个维度(递增、按顺序、取余循环)即,二叉树每一层就是当前维度的划分,第0层对空间第0维划分,1对1,第1层有2个节点,因为第0层已经将空间分为两半,所以第1层要对两个子空间划分,即两次划分操作,每一层的每一个节点都是一次划分操作,每次划分操作其实就是用超平面划分空间,具体说,将当前子空间的所有点按照当前层对应维度排序得出中位数点作为分割点
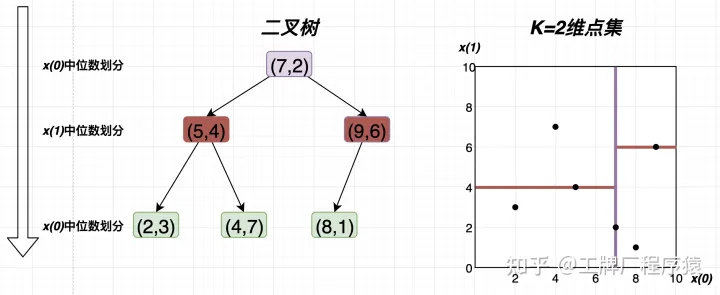 比如
比如
对于根节点,处于第0层就是对第0维划分,首先对当前空间(此时是整个空间)的所有点按照第0维排序,如下
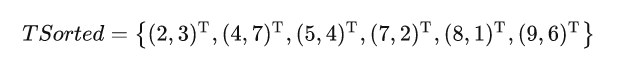 7是中位数,于是以直线x(0)=7作为超平面(图中竖线)划分原空间,于是得出了两个子空间,一左一右,根节点是(7,2),然后第1层二叉树的两个节点分别做如上操作,得出图中两条横线,比如第1层的第0个节点,对当前空间所有点(即左半边所有点)按照第1维排序,即(2,3)、(5,4)、(4,7),显然中位数是4,于是树节点是(5,4);可以想象如果是3维空间,那么每次用于划分的超平面就是一个平面
7是中位数,于是以直线x(0)=7作为超平面(图中竖线)划分原空间,于是得出了两个子空间,一左一右,根节点是(7,2),然后第1层二叉树的两个节点分别做如上操作,得出图中两条横线,比如第1层的第0个节点,对当前空间所有点(即左半边所有点)按照第1维排序,即(2,3)、(5,4)、(4,7),显然中位数是4,于是树节点是(5,4);可以想象如果是3维空间,那么每次用于划分的超平面就是一个平面
决策树
ID3
每次选取属性作为树节点时,选择信息增益最大的(即原来的熵与确定了某个属性后的熵(条件熵)之差),使得不确定性不断减小,这样叶节点中的数据大都是同一类的,纯度很高
c4.5
id3倾向于选择特征值多的特征,极端点,比如使用编号作为特征,这会使得条件熵为0而导致信息增益最大(一方面是公式得出,另一方面是特征值多导致划分出来的子集都很小,于是纯度容易比较高),但这毫无意义,c4.5使用信息增益率最大,与信息增益不同在于会对属性值多的属性进行惩罚,缩放信息增益的大小,这就是信息增益率。
其次引入了剪枝避免分的过细导致过拟合
而且能够对连续的属性处理,比如温度,0~40,找到最佳划分数字,比如第一种划分,以10为边界,0~10与10~40,第二种划分可以是任意其他数,用是否大于或小于边界将连续化为离散
cart树
使用基尼系数,相比于熵计算量小很多
svm
对于硬间隔svm,目标是找到一个超平面,在能够分对类的基础上,使得离该超平面最近的点(支持向量)与超平面的距离相比于其他超平面最大。由于每一个样本点都是一个不等式约束,所以约束条件多且难以求解,于是先使用高数里面的拉格朗日乘子法将带约束优化问题化为无约束(准确说是变成了约束乘子alpha>=0),此时仍然求解困难,然后又考察原问题的对偶问题(min max交换),发现是强对偶(minmax==maxmin)问题,所以将原问题化为求解对偶问题,又因为是强对偶,就可以使用kkt条件帮助化简,最后再使用smo求解,smo就是只允许1个变量活动,其余固定,然后这时候其余变量相当于常量,式子则非常简单,我们可以通过求导求出活动变量的解析解,相当于每次只更新一个变量,但对于svm,有等式约束,一个变量被优化成新的值会导致破坏约束,因此用两个变量就好了,比如前面的变量小了,那后面的变量再大一点就可以仍然满足等式约束了
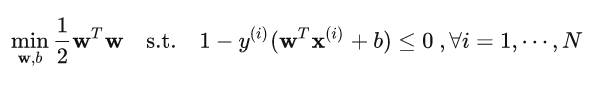
下图是原问题,可见需要求解w和b,维度分别是d和1,所以原问题规模就是d+1,然而事实是参数通常比样本还多(像深度学习)即d+1>>N,所以说对偶问题将问题规模缩小了
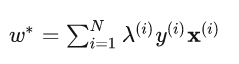
 软间隔svm相当于考虑实际情况,因为实际通常会有噪声使得无法完美线性可分(前提为不是特别严重的噪声),那就允许svm犯一点小错,但也不应太过分
软间隔svm相当于考虑实际情况,因为实际通常会有噪声使得无法完美线性可分(前提为不是特别严重的噪声),那就允许svm犯一点小错,但也不应太过分

adaboost
根据分类误差率em和adaboost提供的权重计算得出当前分类器的权重
em
作用:用于解决含有隐变量的参数估计问题,因为此时极大似然估计失效,求解困难
原理:想求参数则需要知道隐变量的值,而求隐变量的值要通过参数求出,直接先随机初始化参数,把参数确定下来,然后通过jensen不等式或者elbo和kl散度构造下确界Q函数,通过迭代新的theta最大化下界来最大化原式
步骤:E步求期望,M步最大化期望,反复迭代,这两步本质就是做一件事,即最大化下界Q函数
即
θ
i
+
1
=
arg max
θ
Q
(
θ
,
θ
i
)
\theta_{i+1} =\argmax \limits_{\theta} Q(\theta,\theta_i)
θi+1=θargmaxQ(θ,θi),只是把Q函数拆成两步。
深度学习
实例分割和语义分割
前者将所有个体区分即个体均不同色(相当于目标检测精细版),语义区分物体的类别,即同类上同色,
yolov1
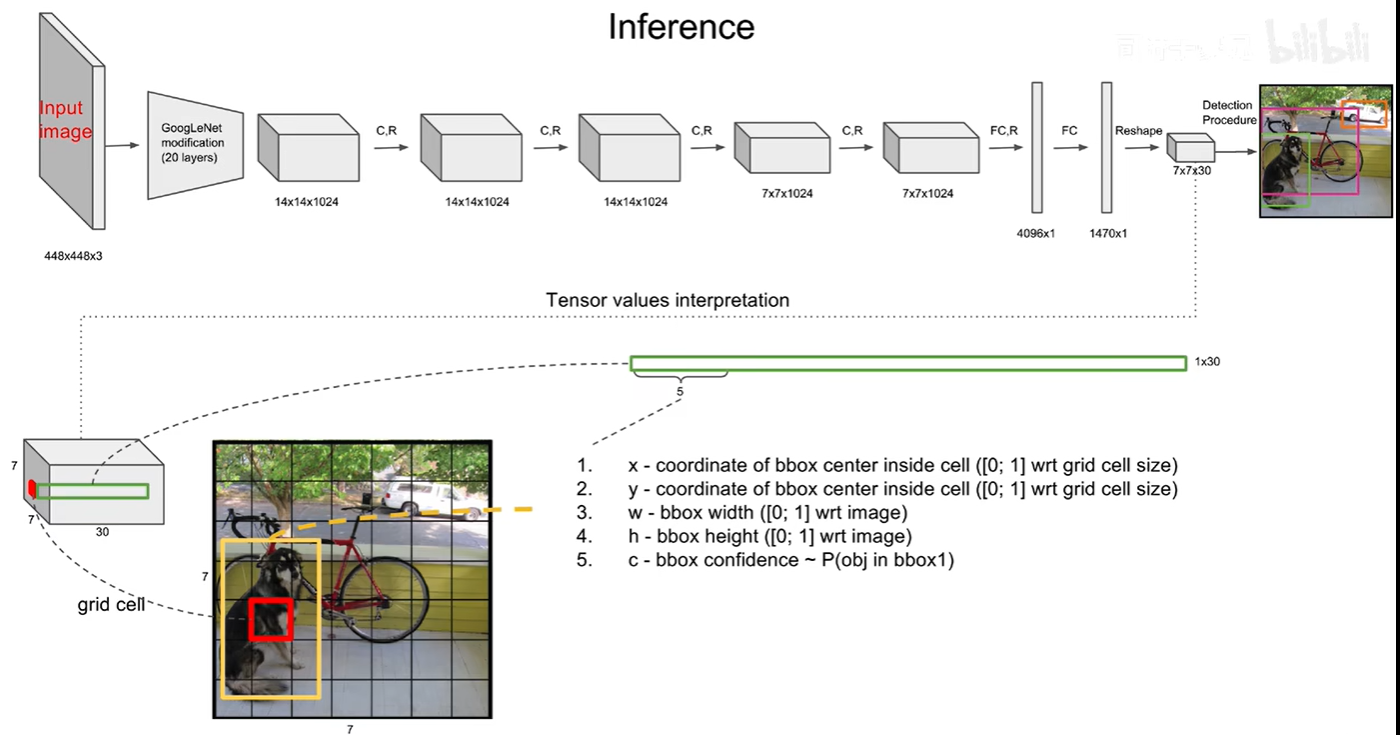
将图片逻辑上分成多个网格grid,没有真的分,预测头的大小是 30*grid*grid(假设batch=1,后面同),只是说在训练的时候预测头的每一个grid需要负责输出目标中心落在当前grid的bbox,这样训练使得以后网络预测的时候也输出落在grid的bbox而不是其他地方,30=(2*5+20),5=x,y,w,h,c, c=confidence置信度,20=训练集包含的类别数(因此使用的训练集决定了网络预测类别的数目),2=输出两个bbox,留一个做备胎。
训练过程
原生标签:一张图被人工标注好的的所有bbox位置及其类别
训练所用标签:将原生标签改造为:bbox中心落在某个grid中则该grid预测的两个bbox都是该bbox,c都是1,类别采用one-hot,仅对应类别为1其余为0
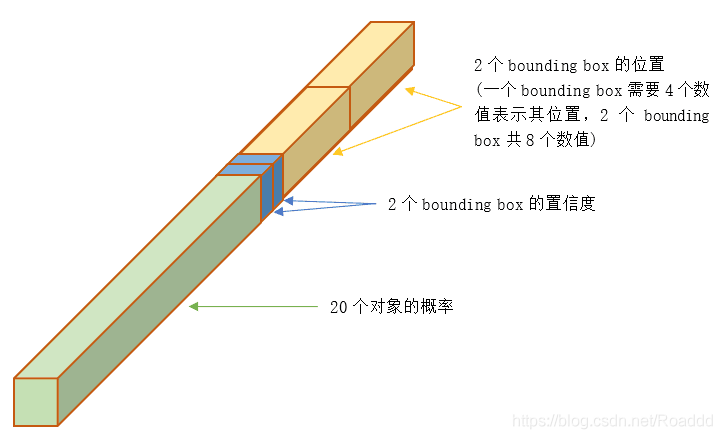
求loss:
yolov1的B=2即有一个备胎,
1
i
j
o
b
j
1_{ij}^{obj}
1ijobj部分,意思是只取confidence大的那个bbox做损失计算即只有1个bbox对obj负责,
1
i
j
n
o
o
b
j
1_{ij}^{noobj}
1ijnoobj部分则两个bbox都要计算loss
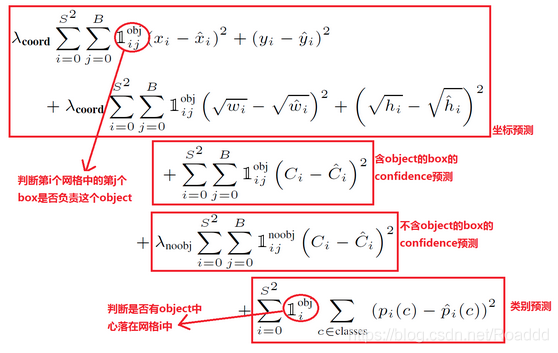 对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏相同的尺寸对IOU的影响更大。而sum-square error loss中对同样的偏移loss是一样。
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏相同的尺寸对IOU的影响更大。而sum-square error loss中对同样的偏移loss是一样。
为了缓和这个问题,作者用了一个巧妙的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。
推理过程
缺点
- yolov1对边界框的预测施加了很强的空间约束,因为每个网格只能预测两个框并且只能包含一个物体类别。这限制了预测的数量,比如成群的鸟或相邻猫狗都无法预测(一群鸟的bbox中心点均落在同一grid但一个grid只能选一个bbox出来,那就只能框一只)(相邻猫狗只可检出其一)。
- 模型是从数据集中,学习边界框,所以很难检测不同长宽比的对象,没有提前设计好锚框anchor。
数据库
三大范式
属性不可再分,非主键属性都要依赖于主键属性,消除间接依赖(非主键属性都要完全依赖于主键属性)
三者层层递进,满足3必然满足12
数据库特性
1、综合统一
SQL语言集数据定义语言DDL(CREATE、ALTER、DROP)、数据操纵语言DML(SELECT、UPDATE、INSERT、DELETE)、数据控制语言DCL(更改数据库用户或角色权限的语句grant)的功能于一体,语言风格统一,可以独立完成数据库生命周期中的全部活动,包括定义关系模式、录入数据以建立数据库、查询、更新、维护、数据库重构、数据库安全性控制等一系列操作要求,
2、高度非过程化
非关系数据模型的数据操纵语言是面向过程的语言,用其完成某项请求,必须指定存取路径。而用SQL语言进行数据操作,用户只需提出“做什么”,而不必指明“怎么做”,因此用户无需了解存取路径,存取路径的选择以及SQL语句的操作过程由系统自动完成。这不但大大减轻了用户负担,而且有利于提高数据独立性。
3、面向集合的操作方式
SQL语言采用集合操作方式,不仅查找结果可以是元组的集合,而且一次插入、删除、更新操作的对象也可以是元组的集合。
关系和关系模式
关系模式”和“关系”的区别,类似于面向对象程序设计中”类“与”对象“的区别。”关系“是”关系模式“的一个实例,你可以把”关系”理解为一张带数据的表,而“关系模式”是这张数据表的表结构(学生(学号,姓名,年龄,性别,系,年级))。
数据库设计过程
需求分析-》画出ER图-》ER图转为关系模式图-》设计物理存储结构
外键
B表为某个属性建立外键,外键一定是某表A的主键,保证数据的参照完整性,提高系统健壮性。
域
相同数据类型的集合,比如都是int,都是char,都是string
关系代数
关系代数是一种抽象的过程查询语言,用对关系的运算来表达查询,运算对象是关系,结果也是
c语言
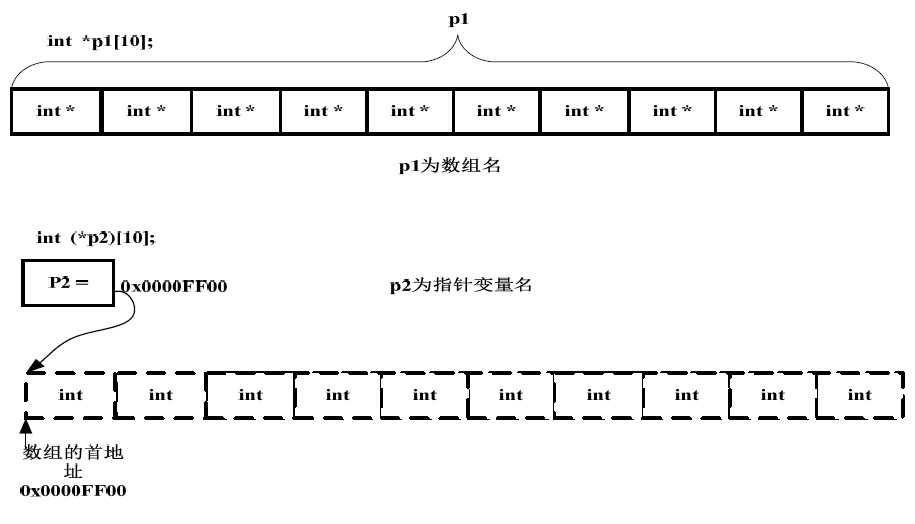
int *p1[10];
int (*p2)[10];
p[]->p是数组
(*p)->p是指针
每次上课问这个问题,总有弄不清楚的。这里需要明白一个符号之间的优先级问题。
“[]”的优先级比“*”要高。p1 先与“[]”结合,构成一个数组的定义,数组名为p1,int 修饰的是数组的内容,即数组的每个元素。那现在我们清楚,这是一个数组,其包含10 个指向int 类型数据的指针,即指针数组。至于p2 就更好理解了,在这里“()”的优先级比“[]”高,“”号和p2 构成一个指针的定义,指针变量名为p2,int 修饰的是数组的内容,即数组的每个元素。数组在这里并没有名字,是个匿名数组。那现在我们清楚p2 是一个指针,它指向一个包含10 个int 类型数据的数组,即数组指针。我们可以借助下面的图加深理解:
操作系统
死锁四个必要条件
互斥
请求与保持
不可剥夺
循环等待
同步四个原则
让权等待
空闲让进
忙则等待
有限等待
操作系统功能及其特性
cpu、内存、设备、文件、接口管理
虚拟异步并发共享
数据结构
最短路径
floyd
最开始只允许经过1号顶点进行中转,接下来只允许经过1和2号顶点进行中转……允许经过1~n号所有顶点进行中转,求任意两点之间的最短路程,相当于动态规划,最外层是k,表示从i号顶点到j号顶点只经过前k号点的最短路程。时间 O ( n 3 ) O(n^3) O(n3)
dijkstra
假设从2出发求单源最短路径,一开始distance数组就是2到各顶点距离,无法一步到的设为正无穷,然后每次从distance找到最小的值的索引 idx,并且最小的值对应的visited[idx]被设为true,表示该距离就是最短距离,确定好了不用变,用该idx节点去搜索未被确认最短距离的节点,若源点到最小点再到新点的距离比原来小(即若用了中转站后距离更小)则更新(用的是源点到最小点再到新点的距离来更新),时间 O ( n 2 ) O(n^2) O(n2),因为要确定n-1个最小值,则需要n-1轮,每一轮当前最小节点可能紧邻n个节点,所以
最小生成树
prim
从任一点开始,和dijk那样搞一个distance数组,取最小,用该最小的节点到其他点的距离更新distance数组,要取v-1次顶点最小值,每次也是探索v个节点,所以时间 O ( V 2 ) O(V^2) O(V2)
kruskal
先对所有边按权重从小到大排序,每次选当前最小的边(选过的不看),并看该边是否将原本不连通的两个节点联通了,不是则看下一条最小的边,时间 O ( E l o g E ) O(ElogE) O(ElogE),E是边数,因此不适合
软件工程
黑盒测试和白盒测试
前者把软件看成黑盒,设计输入看输出是否正确又叫功能测试
后者是知道具体代码,针对代码设计特定的输入,
alpha测试与beta测试
简单来说α测试就是公司内部员工假装自己是各类用户,来进行使用,从而发现使用过程终会出现的问题,软件的表现、界面等。从而找出软件需要改进的地方。
β测试就是让真正对软件一无所知的用户来使用软件,找出自己认为的错误,提交给程序员
α测试一般在公司内部,程序员就在身边,环境也由公司提供。而β测试,则是在实际的操作环境中,程序员并不在身边,一切由用户主导
项目
①取输入图像的roi进行处理,一开始roi是整张图片,在识别出装甲板后,roi修改成装甲板bbox的若干倍(因为机器人不会瞬移),减少计算量提高识别准确度。首先装甲板旁边是有两个发光灯条(两红或两蓝)用于辅助识别装甲板,
②这时候我们降低roi的曝光,减少背景光的干扰。相当于画面中只有灯是比较亮的,其他部分很暗。比如敌方机器人是红色,则用r通道-b通道,这样对于红色的机器人,相减后的灯条部分一定是大于0的,反之蓝色机器人对应灯条部分的灰度值很小,
③于是经过阈值化处理后只会留下红色灯条,并且也去除了一些亮斑和噪声。
④然后对灰度图进行形态学的膨胀操作,使得灯条边缘更好地连在一起,
⑤这时候就可以使用opencv提供的findContours函数寻找到所有最外层的边缘了。
⑥然后根据边缘的长宽比、面积等筛选出属于灯条的边缘,这时候得到一堆灯条边缘了(因为roi可能有多个机器人,所以会出现多个灯条),
⑦最后再一次根据比如相邻两个灯条距离,是否平行等筛选出一对最符合的灯条边缘,














 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









