






 该文详述了一次实验,旨在利用图像处理和目标检测技术定位小麦头。实验涉及数据预处理、训练FasterR-CNN模型、在Kaggle环境中使用GPU加速训练,并通过IoU、阈值和精度等指标评估模型性能。过程中遇到并解决了Jupyter环境问题、数据加载错误、版本不兼容警告和图像显示问题。
该文详述了一次实验,旨在利用图像处理和目标检测技术定位小麦头。实验涉及数据预处理、训练FasterR-CNN模型、在Kaggle环境中使用GPU加速训练,并通过IoU、阈值和精度等指标评估模型性能。过程中遇到并解决了Jupyter环境问题、数据加载错误、版本不兼容警告和图像显示问题。
实验目的
- 小麦来自世界各地。密度的小麦植株经常重叠;风会使得照片模糊;外观会因成熟度,颜色,基因型和头部方向而异。
- 使用图像处理和目标检测完成小麦头的位置的标定。
- 完成训练并现场验证后上传指定的输出文件进行验证评分。
实验环境
WIN10、pytorch、anaconda3+jupyter notebook、Kaggle官方服务器
实验过程
分析数据集的数据分布和特征
- Test:包含22张的测试图片,不公开,用于评分。
- Train:包含3400张的来自世界各地的小麦图像。
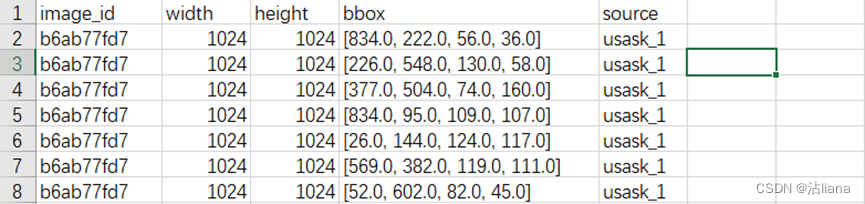
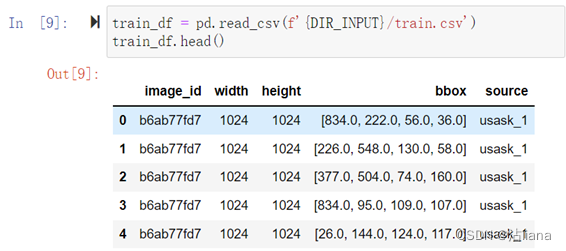
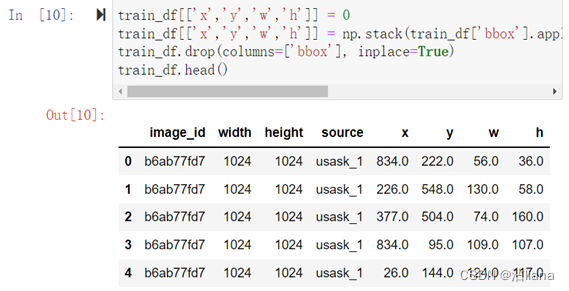
- Train.csv:训练集的标签信息,第1列为图像id,第2、3列分别为图像宽高,第4列为标签框的左上角x、y轴坐标以及宽高,形如:b6ab77fd7,1024,1024,[834.0, 222.0, 56.0, 36.0]。
- csv中的字段:
image_id - 唯一的图像 ID
width, height - 图像的宽度和高度
bbox - 一个边界框,格式化为 [xmin, ymin, width, height] 的 Python 样式列表。
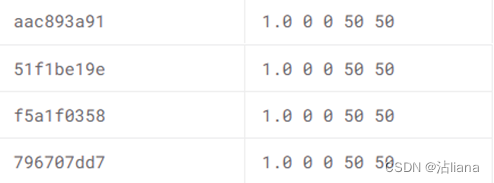
- 输出文件(形如下图):提交CSV文件, 第1列为图像id,第2列为标定信息字符串(信任值confidence用于排序计算指标顺序,左上角x、y轴坐标,目标框的宽高)。
把数据拷下来命名文件夹为wheatdata:

读取内容:
训练数据大小:

Image_id的数量(不重复):

Train图片数量:

与文件描述一致,数据集没下错。
图片大小:

查看数据标注的分布:

一张图中标注数的范围为1-116。
相应的数据处理
这里写了一个读入图片的类WheatDataset。通过该类的初始化可以方便的读取图片。
类函数init:

赋值,分别为图片id、对应图片、图片地址和图片转换。
类函数getitem:
获取所有训练图像的标签,imgs_label_dict字典键、值分别为图像以及图像中小麦头对应的bounding box, 同一个图像中可能含有多个小麦头,因此键值为列表,每个元素格式为[xmin, ymin, width, height]
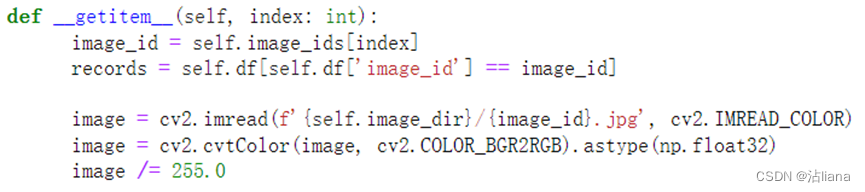
先是将图片id进行赋值,记录下对应的id是否对等,然后将图片通过地址读入,并进行图片的处理,具体原理如下图:

imshow是用来显示图片的,如
I = imread(‘XX’));
figure,imshow(I);
而有时为了数据处理,要把读取的图片信息转化为更高的精度,
I = double(imread(‘XX’));
为了保证精度,经过了运算的图像矩阵I其数据类型会从unit8型变成double型。如果直接运行imshow(I),我们会发现显示的是一个白色的图像。这是因为imshow()显示图像时对double型是认为在0-1范围内,即大于1时都是显示为白色,而imshow显示uint8型时是0~255范围。而经过运算的范围在0-255之间的double型数据就被不正常得显示为白色图像了。
有两个解决方法:
1> imshow(I/256); -----------将图像矩阵转化到0-1之间
2> imshow(I,[]); -----------自动调整数据的范围以便于显示.
从实验结果看两种方法都解决了问题,但是从显示的图像看,第二种方法显示的图像明暗黑白对比的强烈些。
然后返回其他参数:
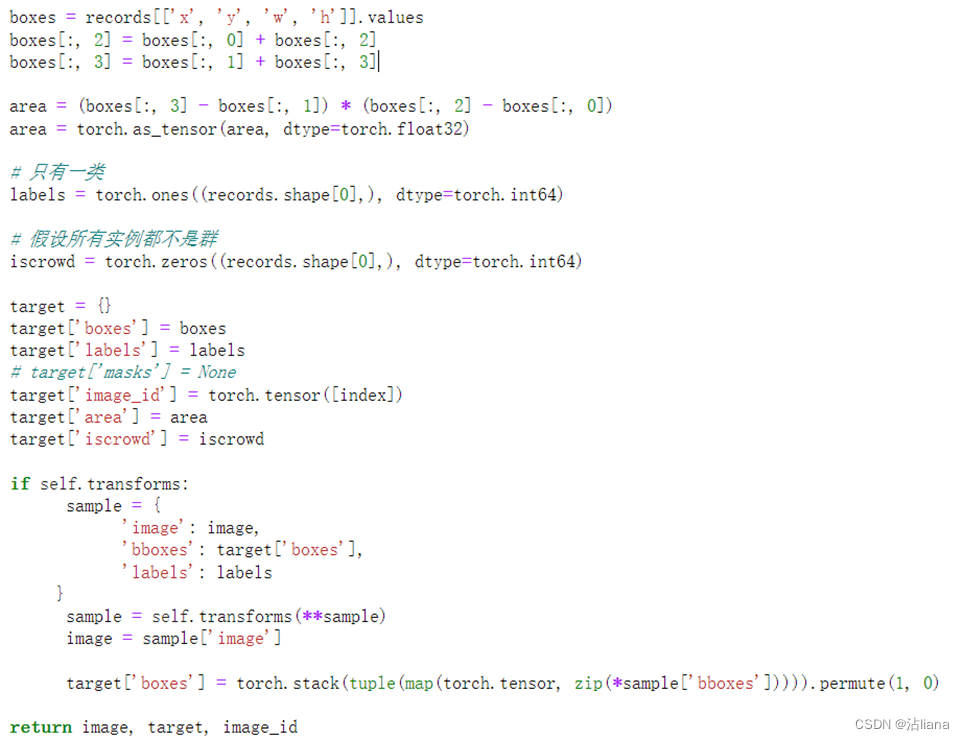
这里把bbox换成了x,y,w,h。试验更换结果如下:
Train与valid的transform转换定义函数:

训练集将图片一半旋转,一半不旋转;然后转换为tensor,并归一化至[0-1]。
测试集只将图片转换为tensor并归一化至[0-1]。
选择合适的模型进行训练
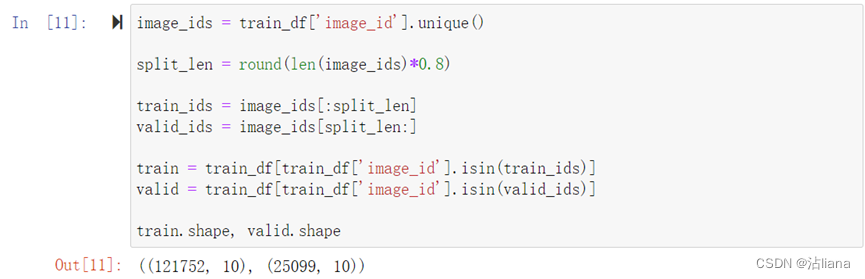
将数据集分为训练集与验证集,比例8:2。
创建train_data与valid_data:

这里选择的是faster R-CNN模型。直接创建一个Faster R-CNN预训练模型:

需要将模型调整至合适训练的大小,先输出模型最后一层看看:

可以看到,最后一层的线性层输出特征数量需要更改。将这层替换成输出特征大小为2:

再输出最后一层看看:

可以用了。
使用pytorch的dataloader进行训练模型:
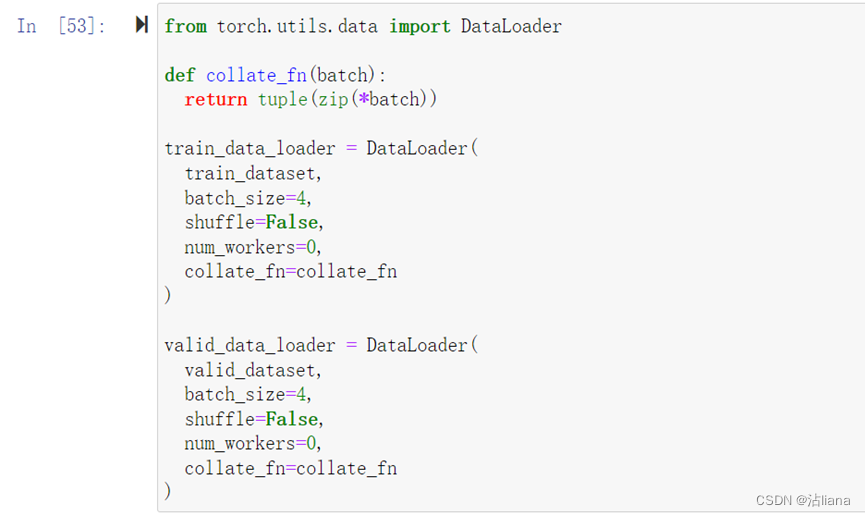
含义:

创建参数:
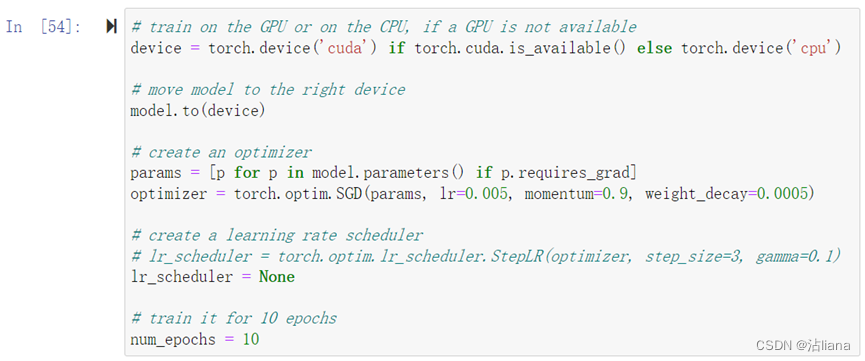
使用的SGD进行回归。 步长设的0.005,动量设置的0.9,L2正则化项系数设为0.0005。
我的电脑用的是arm的显卡,所以只能用cpu进行训练。但实在是太慢了,最后使用的kaggle官方的服务器,使用 GPU 加速深度学习训练,特别快。
创建一个new notebook:

添加wheat-detection的数据集:
设置为GPU加速:
开始训练:
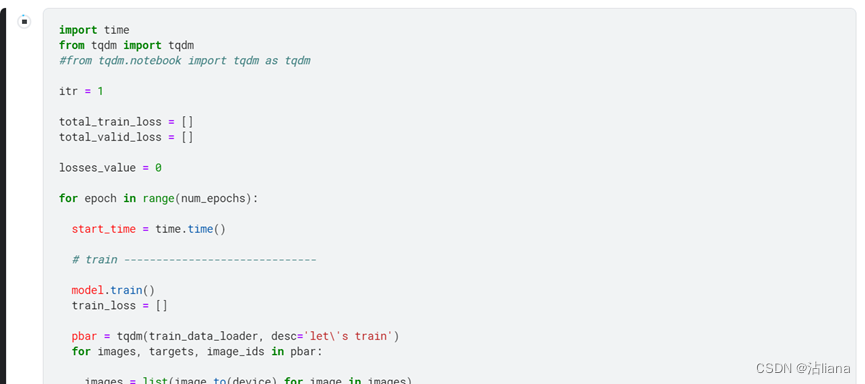
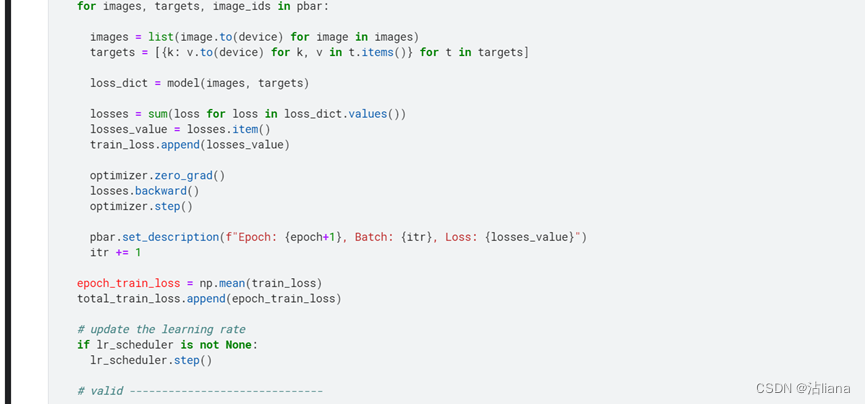

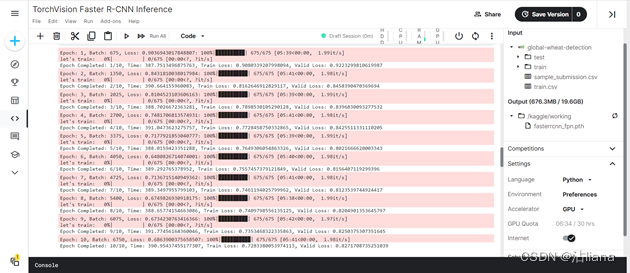
设置的epoch为10,等一段时间可以看到训练结束。
画图查看损失函数loss:

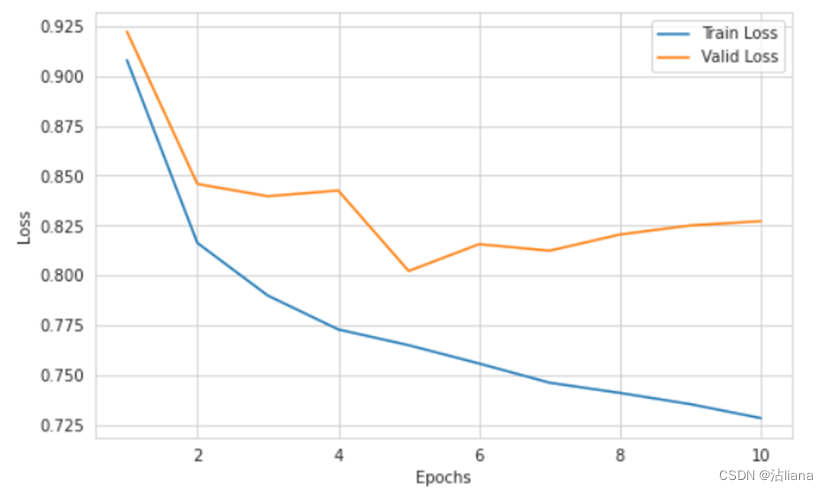
最后保存模型:

可以在运行文件夹下看到保存的pth文件。
然后需要把pth文件导出来用来预测,如下:
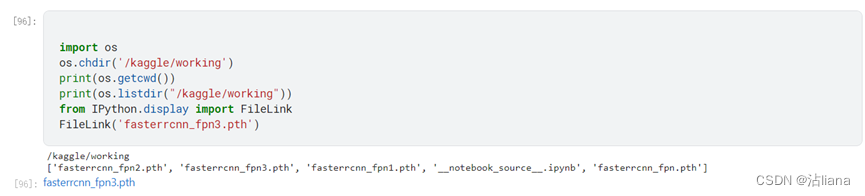
只要输入上面的代码就会返回一个网址,点击网址就可以下载文件了。
这里找了两张图片看了看预测结果:
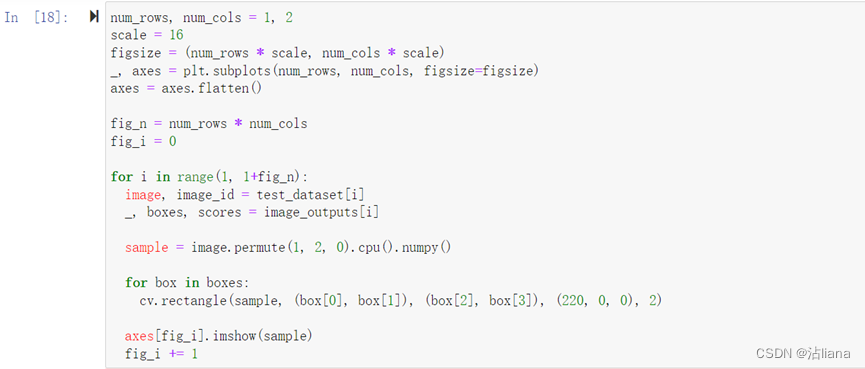
如下面这个:

还有这个:

甚至还有连一个都识别不出来的……还是很玄学。
验证测试集,提交输出文件
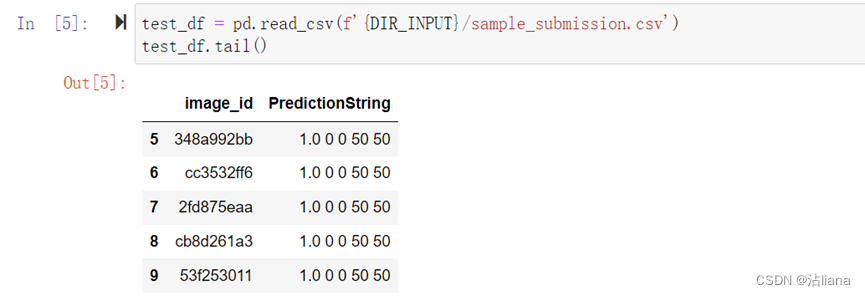
读入模型:
将已给的结果csv读入,用于进行预测比较。
定义test的模型定义:

设置test的模型:

使用dataloader进行测试网络配置:
进行预测模型载入:

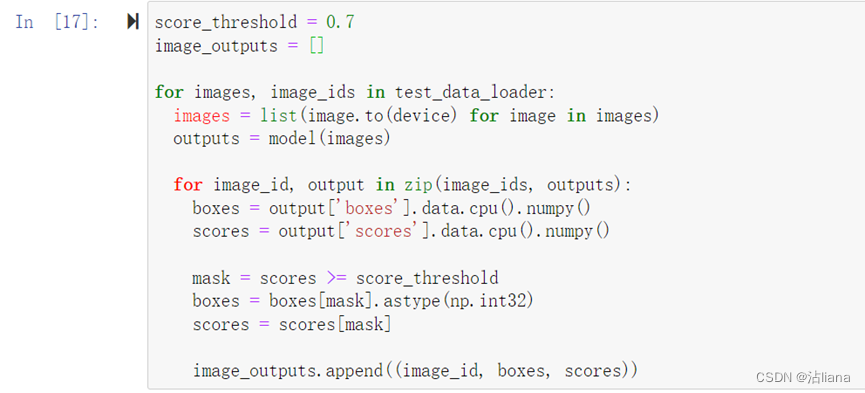
开始预测:
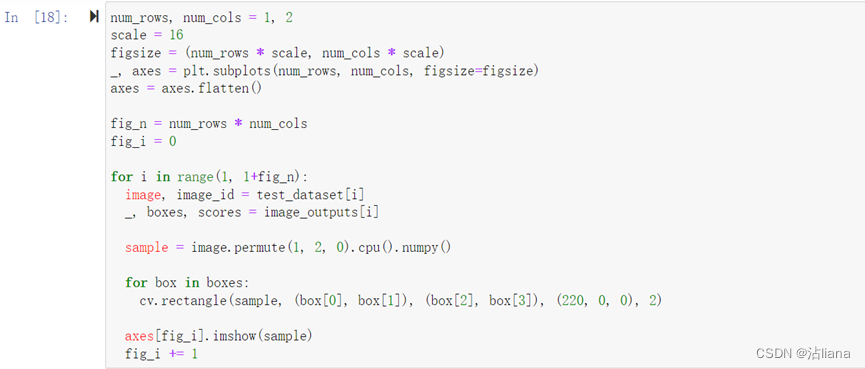
通过图片看看预测结果:
对结果进行保存:
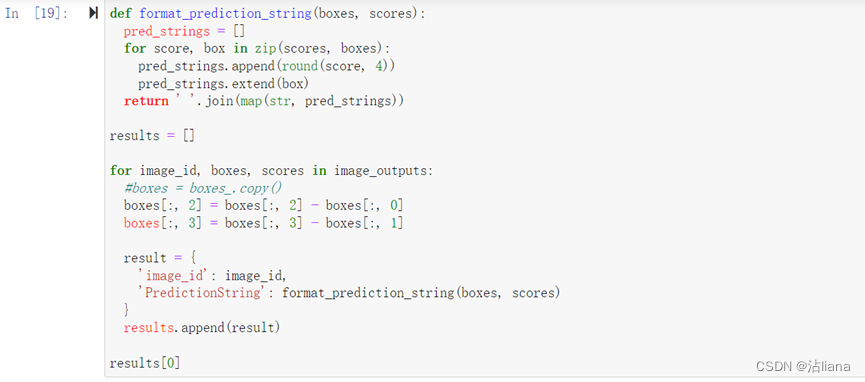

将最终的结果csv保存:

将该csv进行评分即可。
根据评判指标对输出进行评分
通过使用老师给的eval.py文件进行评分。
评分标准:
- IoU(如右图上):预测框为蓝色,正确标定框为
橘黄色,IoU等于两个框交集面积与并集面积的
比值。
- Threshold(阈值):表示标定命中的评判分界线,
如阈值为0.5时,IoU > 0.5则表示命中。
- Precision(精度):真阳性(TP)为检测命中的目标(小麦头)的数目,假阳性(FP)为检
测未命中的目标的数目,假阴性(FN)为检测未命中的非目标的数目。
- Average precision(平均精度如右图下):符合阈值条件下的上述精度下
计算得到单张图像的平均精度。
实验问题
1、IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/
首先很多博客说是jupyter的版本过低了,但是卸载再重装也不行:
pip uninstall jupyter
pip install jupyter
因为报错也说了可能和ipywidgets有关,就下载这个包后还是不行:
pip install ipywidgets
找出终极绝招,jupyer官方文档:https://ipywidgets.readthedocs.io/en/stable/user_install.html
就是说如果你的jupyter和你运行代码的kernel不是一个环境的话:

conda install -n base -c conda-forge widgetsnbextension
conda install -n py36 -c conda-forge ipywidgets
首先进入base环境运行:
conda install -c conda-forge widgetsnbextension
然后在自己的虚拟环境中运行(如虚拟环境名为myconda):
source activate myconda
conda install -c conda-forge ipywidgets
2、DataLoader worker (pid(s) 19728, 20240, 13828, 16776) exited unexpectedly
我所使用的CPU运行,最初是batchsize为10,同时使用4线程进行读取,此时会报错。
查阅网上的回答,说最可能的原因是:
- cuda 虚拟环境的共享内存不足,解决办法是,要么改成更小的batchsize,
- 将numworkers = 4注释掉,不用多进程。
解决过程:
1、只将batchsize改小,变为2,依旧报错
2、将进程num_workers=get_dataloader_workers()改为0、1、2可以使用
2、BrokenPipeError: [Errno 32] Broken pipe
原因:
在训练过程中,设置的num_workers过大

修改为 num_workers=0 即可。(后面用kaggle服务器就不需要修改了)
- num_worker参数理解
下面作者讲的很详细,大致就是设置参数大的话,例如参数为10,就可以有10个线程来加载batch到内存。当然参数设置过大,而自己内存不够的情况下,就会出现线程管道破裂,即broken pipe ,所以一般默然设置为0.
当然:如果num_worker设为0,意味着每一轮迭代时,dataloader不再有自主加载数据到RAM这一步骤(因为没有worker了),而是在RAM中找batch,找不到时再加载相应的batch。缺点当然是速度更慢。
具体参考以下链接。
https://blog.csdn.net/qq_24407657/article/details/103992170
__3、UserWarning: torch.meshgrid: __in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ..\aten\src\ATen\native\TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
解决方法:
应该是torch版本不匹配。将return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
修改为return _VF.meshgrid(tensors, **kwargs, indexing = ‘ij’) # type: ignore[attr-defined],警告解除。
4、Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
在Python中,使用 matplotlib 的函数:plt.imshow(ndarray) 将输入数组显示为彩色 ( RGB ) 图像时。而且,只在处理彩色图像时出现错误提示,显示为空白图像;处理灰度图像时函数运行正常、显示图像。
原因:
plt.imshow() 函数设置:
对于二维数组(灰度图像),函数会自动将输入数据归一化变换至[0,1],然后显示。
对于三维数组(彩色图像),plt.imshow() 函数并不会自动对输入数据归一化处理,而是对数据取值范围提出要求:如果是float型数据,取值范围应在[0,1];如果是int型数据,取值范围应在[0,255]。
我遇到的情况是:在之前的数据处理步骤有一些矩阵运算,数据类型变为 float64 型。输入二维数组(显示为灰度图像)时,因为函数会进行归一化处理,不受影响。输入三维数组(显示为彩色图像)时,就需要先转换到相应的数据类型和取值范围,才能在 plt.imshow() 函数中正常显示。
解决方法
方法一:plt.imshow(ndarray.astype(‘uint8’))
将 float 型数据截短转换成 uint8 型数据。
方法二:plt.imshow(ndarray/255)
将数据缩放到[0,1]。
本实验选择的是第二种方法。
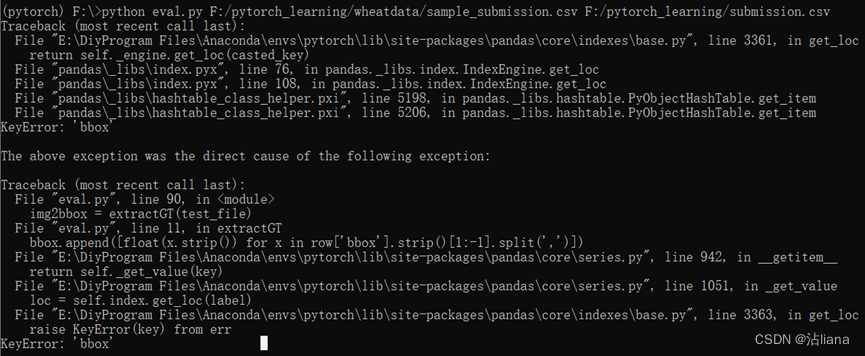
5、使用评分py文件进行测试的时候,报错:
实验总结
这次实验感觉不是很偏向图像处理的方面了,而像使用机器学习进行图像的识别及训练,对基础的图像知识不需要太多的了解。不过也从这次实验,对机器学习及fast R-CNN模型有了更深层次的了解。也通过这次实验,了解了kaggle这个平台,用服务器真的方便很多,还不用配环境,以后有机会也会试着参加一下kaggle的比赛。本次课程也圆满的结束了,感谢老师。
参考网址
https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html
https://www.kaggle.com/c/global-wheat-detection
https://www.kaggle.com/code/pestipeti/pytorch-starter-fasterrcnn-train/notebook
https://www.kaggle.com/code/kaushal2896/global-wheat-detection-starter-eda/notebook

















 2536
2536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









