







📚 目录(快速跳转)
- 选择题(上午题)(每题1分,共75分)
- 一、 计算机系统基础知识 🖥️
- 💻 题目1:计算机硬件基础知识 - RISC(精简指令集计算机)
- 💻 题目2:计算机组成原理 - CPU的基本组成
- 📊 题目3:可靠性计算 - 千小时可靠度
- 💾 题目4:存储器类型 - 电容存储与刷新特性
- ⚖️ 题目5:浮点数表示 - 阶码与尾数对范围和精度的影响
- ⚙️ 题目6:补码表示 - 有符号数值运算特性
- 🖥️ 题目20:计算机软件 - 函数调用栈帧内容
- 🖥️ 题目21:程序设计语言 - 编译器工作方式及特点
- 🖥️ 题目22:程序设计语言 - 语法分析方法分类
- 🖥️ 题目23:计算机系统 - 进程调度方式
- 🖥️ 题目24-26:操作系统 - PV操作与进程同步
- 🖥️ 题目27:计算机系统 - 段页式存储管理系统地址结构分析
- 💽 题目28:计算机硬件基础知识 - 磁盘文件读取时间计算
- 🐍 题目48:程序语言设计 - Python异常处理结构辨析
- 🐍 题目49:程序语言设计 - Python列表切片操作
- 🐍 题目50:程序语言设计 - Python的input()函数行为
- 🗃️ 题目51:数据库设计 - E-R模型向关系模型转换规则
- 🗃️ 题目52-53:数据库设计 - 数据库范式与函数依赖分析
- 🗃️ 题目54-55:数据库设计 - 关系代数表达式解析
- 🏦 题目56:数据库事务 - 数据库故障类型辨析
- 🧮 题目57:数据结构 - 栈的出栈序列可能性分析
- 🌳 题目58:数据结构 - 二叉树中序遍历顺序分析
- 🏗️ 题目59:数据结构 - 无向图的邻接矩阵存储空间分析
- 🌳 题目60:数据结构 - B-树特性辨析
- 🏆 题目61:数据结构与算法 - 排序算法辅助空间复杂度比较
- 🧩 题目62-63:数据结构与算法 - 折半查找算法策略与平均比较次数
- 🚀 题目64-65:数据结构与算法 - Dijkstra算法策略与最短路径计算
- 🌐 题目66:计算机网络 - VLAN Tag在OSI模型中的位置
- 🌐 题目67:计算机网络 - Telnet协议特性辨析
- 🔒 题目68:计算机网络 - HTTPS与HTTP协议辨析
- 🌐 题目69:计算机网络 - 域名解析
- 🌐 题目70:计算机网络 - IP 地址和 MAC 地址
- 二、 系统开发和运行知识 🗃️
- 🛠️ 题目15:系统开发 - 加工规格说明的描述方法选择
- 🧩 题目16:系统开发 - 模块结构优化的错误方法
- 🗺️ 题目17-18:系统开发 - 关键路径分析
- 📊 题目19:软件开发项目管理 - 风险管理原则辨析
- 🏗️ 题目29:系统设计方法与模型 - 快速原型模型的优点辨析
- 🏗️ 题目30:系统设计 - 三层C/S结构的特性辨析
- 🧩 题目31:系统设计 - 模块耦合类型辨析
- 🏻 题目32:系统开发 - 软件高质量标准的理解
- 🧪 题目33:软件测试基础知识 - 白盒测试覆盖方法的能力对比
- 📄 题目34:软件质量 - 高质量文档标准的辨析
- 🧪 题目35:软件测试基础知识 - 测试阶段与错误发现能力
- 🛠️ 题目36:系统运行和维护基础知识 - 软件维护类型辨析
- 三、 面向对象基础知识 🧩
- 四、 网络与信息安全知识 🌐
- 五、 标准化、信息化和知识产权基础知识 🛠️
- 六、 计算机英语 🐧
选择题(上午题)(每题1分,共75分)
2023年上午题试卷:百度云盘
💡 注意:文章按照知识点顺序总结,未按真题顺序
一、 计算机系统基础知识 🖥️
💻 题目1:计算机硬件基础知识 - RISC(精简指令集计算机)
以下关于 RISC(精简指令集计算机)特点的叙述中,错误的是 (1) 。
(1)
A. 对存储器操作进行限制,使控制简单化
B. 指令种类多,指令功能强 ✅
C. 设置大量通用寄存器
D. 选取使用频率较高的一些指令,提高执行速度
📌 正确答案:B
🔍 详细解析
RISC(Reduced Instruction Set Computer) 的核心思想是通过 简化指令集 和 优化硬件设计 来提高执行效率,其特点包括:
-
精简指令集:
-
指令数量少,格式统一,功能简单(与选项 B 矛盾)。
-
只保留高频使用指令,复杂功能通过多条指令组合实现(对应选项 D)。
-
-
对存储器操作的限制:
- 采用 Load/Store架构,只有专门的加载(Load)和存储(Store)指令能访问内存,其他指令操作均在寄存器间进行(对应选项 A)。
-
大量通用寄存器:
- 减少访问内存的次数,提高数据操作效率(对应选项 C)。
-
其他特点:
-
采用流水线技术,单周期指令执行。
-
硬连线控制(非微程序控制),降低延迟。
-
💡 知识点分析
RISC vs CISC(复杂指令集计算机) 对比:
| 特性 | RISC | CISC |
|---|---|---|
| 指令数量 | 少(约几十条) | 多(上百条) |
| 指令复杂度 | 简单,单周期完成 | 复杂,多周期完成 |
| 存储器访问 | 仅Load/Store指令 | 允许内存直接操作 |
| 寄存器数量 | 大量通用寄存器 | 寄存器较少 |
💻 题目2:计算机组成原理 - CPU的基本组成
CPU(中央处理单元)的基本组成部件不包括 (2) 。
(2)
A. 算逻运算单元
B. 系统总线 ✅
C. 控制单元
D. 寄存器组
📌 正确答案:B
🔍 详细解析
CPU(Central Processing Unit) 是计算机的核心部件,负责执行指令和处理数据,其基本组成包括:
-
算术逻辑单元(ALU, Arithmetic Logic Unit):
-
执行算术运算(如加减乘除)和逻辑运算(如与或非)。
-
对应选项 A。
-
-
控制单元(CU, Control Unit):
-
负责指令译码、时序控制,协调CPU各部件工作。
-
对应选项 C。
-
-
寄存器组(Registers):
-
包括通用寄存器(如AX、BX)、指令寄存器(IR)、程序计数器(PC)等,用于暂存数据和指令。
-
对应选项 D。
-
❌ 系统总线(System Bus)不属于CPU的组成部分:
- 系统总线是 CPU与内存、外设通信的公共通道(包括数据总线、地址总线、控制总线),属于计算机系统层级的组件,而非CPU内部结构。
💡 知识点分析
-
CPU内部数据流:
-
取指令:PC指向内存地址 → 通过总线获取指令 → 存入IR。
-
执行指令:CU译码 → ALU运算 → 结果写回寄存器或内存。
-
-
其他选项对比:
-
A. ALU 和 C. CU 是CPU的核心部件,缺一不可。
-
D. 寄存器组 直接影响CPU的运算速度(如寄存器比缓存更快)。
-
-
扩展概念:
-
冯·诺依曼架构:CPU + 存储器 + 输入/输出设备 + 总线。
-
现代CPU的扩展组件:
-
缓存(Cache):L1/L2/L3缓存,减少内存访问延迟。
-
流水线(Pipeline):提升指令并行度。
-
多核结构:多个CPU核心集成在同一芯片。
-
-
📊 题目3:可靠性计算 - 千小时可靠度
某种部件用在 2000 台计算机系统中,运行工作 1000 小时后,其中有 4 台计算机的这种部件失效,则该部件的千小时可靠度 R 为(3) 。
(3)
A. 0.990
B. 0.992
C. 0.996
D. 0.998 ✅
📌 正确答案:D
🔍 详细解析
可靠度(Reliability) 的定义是:在规定的条件下和规定的时间内,部件或系统正常工作的概率。计算公式为:
R ( t ) = 正常工作的数量 总数量 = 1 − 失效数量 总数量 R(t)=\frac{正常工作的数量}{总数量}=1 - \frac{失效数量}{总数量} R(t)=总数量正常工作的数量=1−总数量失效数量
题目数据:
-
总数量 = 2000 台
-
失效数量 = 4 台
-
工作时间 = 1000 小时
计算过程:
R ( t ) = 2000 − 4 2000 = 1996 2000 = 0.998 R(t)=\frac{2000-4}{2000}= \frac{1996}{2000}= 0.998 R(t)=20002000−4=20001996=0.998
📊 扩展应用
串联系统可靠度: R t o t a l = R 1 × R 2 × ⋯ × R n R_{total}= R_{1} × R_{2} × ⋯ × R_{n} Rtotal=R1×R2×⋯×Rn。
并联系统可靠度: R t o t a l = 1 − ( 1 − R 1 ) ( 1 − R 2 ) ⋯ ( 1 − R n ) R_{total}= 1- (1 - R_{1})(1 - R_{2})⋯(1 - R_{n}) Rtotal=1−(1−R1)(1−R2)⋯(1−Rn)。
💾 题目4:存储器类型 - 电容存储与刷新特性
以下存储器中, (4) 使用电容存储信息且需要周期性地进行刷新。
(4)
A. DRAM ✅
B. EPROM
C. SRAM
D. EEPROM
📌 正确答案:A
🔍 详细解析
DRAM(Dynamic Random Access Memory) 是本题描述的唯一正确答案,其核心特点包括:
-
电容存储数据:
- 每个存储单元由 一个晶体管+一个电容 组成,电容电荷表示二进制数据(有电荷=1,无电荷=0)。
-
需周期性刷新:
- 电容会自然漏电,导致数据丢失,因此需每隔 2~64ms 刷新一次(通过读取后重写)。
其他选项分析:
-
B. EPROM(Erasable Programmable ROM):
- 使用浮栅晶体管存储数据,紫外线擦除,无需刷新。
-
C. SRAM(Static RAM):
- 基于触发器(Flip-flop)结构,无需刷新,但功耗高、成本高,常用于缓存。
-
D. EEPROM(Electrically Erasable PROM):
- 电可擦除ROM,非易失性存储器,无需刷新。
💡 知识点对比表
| 存储器类型 | 存储原理 | 易失性 | 刷新需求 | 典型用途 |
|---|---|---|---|---|
| DRAM | 电容 | 易失 | 需要 | 主内存(DDR4/DDR5) |
| SRAM | 触发器 | 易失 | 不需要 | CPU缓存(L1/L2/L3) |
| EPROM | 浮栅晶体管 | 非易失 | 不需要 | 固件存储(已淘汰) |
| EEPROM | 浮栅晶体管(电擦除) | 非易失 | 不需要 | BIOS配置、小型嵌入式系统 |
⚖️ 题目5:浮点数表示 - 阶码与尾数对范围和精度的影响
对于长度相同但格式不同的两种浮点数,假设前者阶码长、尾数短,后者阶码短、尾数长,其它规定都相同,则二者可以表示数值的范围和精度情况为 (5)。
(5)
A. 二者可表示的数的范围和精度相同
B. 前者所表示的数的范围更大且精度更高
C. 前者所表示的数的范围更大但精度更低 ✅
D. 前者所表示的数的范围更小但精度更高
📌 正确答案:C
🔍 详细解析
浮点数的表示能力由 阶码(Exponent) 和 尾数(Mantissa) 共同决定:
-
阶码(Exponent):
-
决定数值的 范围(能表示的最大/最小绝对值)。
-
阶码位数越多,可表示的指数范围越大(例如8位阶码比6位阶码能表示更大的数)。
-
-
尾数(Mantissa):
-
决定数值的 精度(有效数字的位数)。
-
尾数位数越多,小数部分的精度越高(例如10位尾数比8位尾数能更精确表示小数)。
-
题目场景分析:
-
第一种格式:阶码长 + 尾数短 → 范围大,精度低。
-
第二种格式:阶码短 + 尾数长 → 范围小,精度高。
💡 知识点扩展
-
IEEE 754标准示例:
-
单精度(32位):8位阶码 + 23位尾数 → 范围约±10³⁸,精度约7位十进制。
-
双精度(64位):11位阶码 + 52位尾数 → 范围约±10³⁰⁸,精度约16位十进制。
-
-
极端情况对比:
| 格式 | 阶码位数 | 尾数位数 | 范围 | 精度 |
|---|---|---|---|---|
| 长阶码短尾数 | 10位 | 6位 | ±10³⁰⁸ | 约2位小数 |
| 短阶码长尾数 | 6位 | 10位 | ±10¹⁹ | 约4位小数 |
⚙️ 题目6:补码表示 - 有符号数值运算特性
计算机系统中采用补码表示有符号的数值, (6) 。
(6)
A. 可以保持加法和减法运算过程与手工运算方式一致
B. 可以提高运算过程和结果的精准程度
C. 可以提高加法和减法运算的速度
D. 可以将减法运算转换为加法运算从而简化运算器的设计 ✅
📌 正确答案:D
🔍 详细解析
补码(Two’s Complement) 是计算机表示有符号整数的标准方式,其核心优势在于:
-
统一加减法运算:
-
减法可以转换为加法(例如 A - B = A + (-B)),其中 -B 是 B 的补码(按位取反后加1)。
-
简化硬件设计:运算器只需加法器即可处理加减法,无需额外减法电路。
-
-
选项逐项分析:
-
A. 与手工运算方式一致 ❌
- 手工运算(如竖式计算)依赖借位,补码的进位逻辑与手工方式不同。
-
B. 提高精准度 ❌
- 补码不改变运算结果的数学精度,仅影响表示和运算的便捷性。
-
C. 提高运算速度 ❌
- 补码的运算速度与无符号数相同,未直接“提速”,而是通过简化设计间接优化。
-
D. 减法转加法 ✅
- 补码的核心优势,直接减少硬件复杂度(如CPU的ALU设计)。
-
💡 补码的特性总结
| 特性 | 说明 |
|---|---|
| 唯一零表示 | [+0]补 = [-0]补 = 000…0,避免原码的零歧义问题。 |
| 符号位参与运算 | 最高位自然表示符号(0正1负),且运算时无需特殊处理。 |
| 溢出检测简单 | 若两正数相加结果为负,或两负数相加结果为正,则发生溢出。 |
具体补码转换见文章题5
🖥️ 题目20:计算机软件 - 函数调用栈帧内容
当函数调用执行时,在栈顶创建且用来支持被调用函数执行的一段存储空间称为活动记录或者栈帧,栈帧中不包括 (20) 。
(20)
A. 形参变量
B. 全局变量 ✅
C. 返回地址
D. 局部变量
📌 正确答案:B
🔍 详细解析
-
栈帧(Stack Frame)的典型结构
组成部分 说明 是否在栈帧中 形参变量 函数调用时传入的参数(如void foo(int a)中的a)。 ✔️(选项A) 返回地址 函数执行完毕后需跳转的指令地址(如call指令下一条指令地址)。 ✔️(选项C) 局部变量 函数内部定义的变量(如int b = 0;)。 ✔️(选项D) 全局变量 定义在函数外部的变量(如int global_var;),存储在全局数据区或静态存储区。 ❌(选项B) -
关键区别
-
栈帧的临时性:栈帧随函数调用创建、随返回销毁,仅存储 当前函数 的临时数据。
-
全局变量的存储:
-
生命周期与程序一致,存放在 全局/静态存储区(非栈区)。
-
所有函数均可访问,无需通过栈帧管理。
-
-
-
内存区域对比
内存区域 存储内容 特点 栈(Stack) 栈帧(形参、返回地址、局部变量等) 自动分配/释放,后进先出。 堆(Heap) 动态分配的内存(如malloc) 手动管理,可能碎片化。 全局/静态区 全局变量、静态变量 程序启动时分配,结束时释放。
🖥️ 题目21:程序设计语言 - 编译器工作方式及特点
以下关于编译器工作方式及特点的叙述中,正确的是 (21) 。
(21)
A. 边翻译边执行,用户程序运行效率低且可移植性差
B. 先翻译后执行,用户程序运行效率高且可移植性好
C. 边翻译边执行,用户程序运行效率低且可移植性好
D. 先翻译后执行,用户程序运行效率高且可移植性差 ✅
📌 正确答案:D
🔍 详细解析
-
编译器的核心特性
-
工作方式:先翻译后执行(与解释器的边翻译边执行对立)。
-
运行效率:高(直接执行优化后的机器码,无需运行时翻译)。
-
可移植性:差(生成的目标代码依赖特定硬件和操作系统)。
-
-
关键概念澄清
特性 编译器 解释器 可移植性 ❌ 差(目标代码平台相关) ✔️ 好(源码跨平台通用) 效率 ✔️ 高(静态优化) ❌ 低(动态翻译开销) 典型代表 C/C++、Go Python、JavaScript -
为什么可移植性差?
-
编译器生成的机器码直接面向 特定CPU架构(如x86、ARM)和 操作系统(如Windows、Linux)。
-
若更换平台,必须 重新编译源码(如Windows的.exe文件不能在Linux直接运行)。
-
-
反例验证
-
Java的例外:
- Java编译器生成字节码(.class),由JVM解释执行,属于混合模式,其可移植性依赖JVM而非编译器本身。
-
交叉编译:
- 虽能生成不同平台的目标代码,但本质上仍针对特定平台,不改变编译器本身的移植性缺陷。
-
🚀 记忆技巧
-
编译器:“高效但绑死平台”。
-
解释器:“灵活但跑得慢”。
🖥️ 题目22:程序设计语言 - 语法分析方法分类
对高级语言源程序进行编译或解释的过程中需要进行语法分析,递归子程序分析属于 (22) 的分析法。
(22)
A. 自上而下 ✅
B. 自下而上
C. 从左至右
D. 从右至左
📌 正确答案:A
🔍 详细解析
-
递归子程序分析法的本质
-
自上而下(Top-down):
-
从文法开始符号出发,逐步推导出输入串(即“从根到叶”构建语法树)。
-
递归子程序法是典型的自上而下分析,每个非终结符对应一个递归函数。
-
-
-
关键特点
分析方法 方向 代表算法 递归子程序法归属 自上而下 根 → 叶 递归下降、LL(1) ✔️ 属于此类 自下而上 叶 → 根 LR(1)、SLR、LALR ❌
🖥️ 题目23:计算机系统 - 进程调度方式
在计算机系统中,若 P1 进程正在运行,操作系统强行撤下 P1 进程所占用的 CPU,让具有更高优先级的进程 P2 运行,这种调度方式称为 (23) 。
(23)
A. 中断方式
B. 先进先出方式
C. 可剥夺方式 ✅
D. 不可剥夺方式
📌 正确答案:C
🔍 详细解析
-
可剥夺调度(Preemptive Scheduling)
-
定义:允许操作系统强制暂停当前运行的进程,将CPU分配给优先级更高的进程。
-
本题场景:P1被强行撤下,P2(更高优先级)抢占CPU,是典型的可剥夺调度。
-
-
其他选项分析
选项 调度方式 是否匹配题目场景 A 中断方式 ❌ 中断是外部事件触发(如I/O完成),与优先级无关。 B 先进先出(FIFO) ❌ 按到达顺序执行,无优先级抢占。 D 不可剥夺方式 ❌ 进程主动释放CPU前不允许抢占(如早期批处理系统)。 -
关键对比
调度类型 特点 典型算法 可剥夺 高优先级进程可抢占CPU 优先级调度、RR(时间片轮转) 不可剥夺 进程运行至完成或阻塞才释放CPU 非抢占式SJF(短作业优先)
💡 实例说明
-
可剥夺场景:
- P1(低优先级)正在计算时,P2(高优先级)就绪 → 内核立即切换至P2。
-
不可剥夺场景:
- 即使P2优先级更高,也需等待P1主动放弃CPU(如执行I/O操作或结束)。
🖥️ 题目24-26:操作系统 - PV操作与进程同步
进程 P1、P2、P3、P4、P5 和 P6 的前趋图如下所示。
假设用 PV 操作控制这 6 个进程的同步与互斥的程序如下,程序中的空①和空②处应分别为 (24) ,空③和空④应分别为 (25) ,空⑤和空⑥应分别为 (26) 。
(24)
A. V(S1)V(S2)和 P(S2)P(S3)
B. V(S1)P(S2)和 V(S3)P(S4)
C. V(S1)V(S2)和 V(S3)V(S4)✅
D. P(S1)P(S2)和 V(S2)V(S3)
(25)
A. V(S3)和 V(S6)V(S7)
B. V(S3)和 V(S6)P(S7)
C. P(S3)和 V(S6)V(S7) ✅
D. P(S3)和 P(S6)V(S7)
(26)
A. V(S6)和 P(S7)P(S8)
B. P(S8)和 P(S7)P(S8)
C. P(S8)和 P(S7)V(S8)
D. V(S8)和 P(S7)P(S8)✅
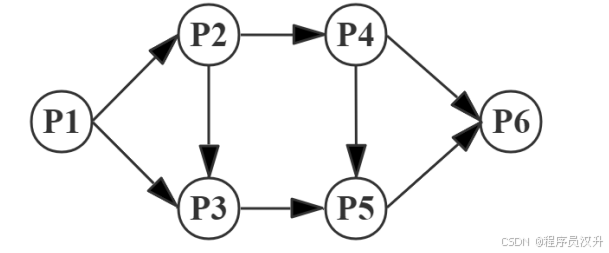
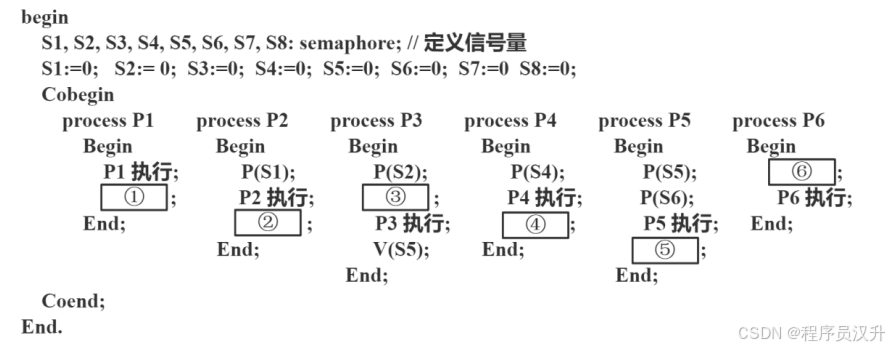
📌 正确答案:(24)C、(25)C、(26)D
🔍 详细解析
PV详细解析过程见文章26-28题
详细流程:
-
P1先执行,释放S1和S2:题中①是 V(S1) 和 V(S2)-
P2需要S1,所以P2可以执行。 -
P3需要S2但还需要S3,所以P3要等待P2释放S3。题中③是P(S3)
-
-
P2运行完后,释放S3和S4:题中②是 V(S1) 和 V(S2)-
P3现在有S2和S3,所以P3可以执行。 -
P4需要S4(来自 P2),所以P4也可以执行。
-
-
P3运行完后,释放S5:P5现在有S5(P3 释放的),但是还需要等待S6(P4 释放的)。
-
P4运行完后,释放S6和S7:题中④是 P(S6)和 P(S7)-
P5现在有S5(P3 释放的),也有了S6(P4释放的)。所以P5可以执行。 -
P6需要S7和S8,但S8需要P5释放,所以 P6 仍需等待。题中⑥为P(S7)和P(S8)
-
-
P5运行完后,释放S8:题中⑤为V(S8) -
P6现在有S7(P4释放的)和S8(P5释放的),所以P6可以执行。
🖥️ 题目27:计算机系统 - 段页式存储管理系统地址结构分析
假设段页式存储管理系统中的地址结构如下图所示,则系统 (27) 。
(27)
A. 最多可有 512 个段,每个段的大小均为 2048 个页,页的大小为 8K
B. 最多可有 512 个段,每个段最大允许有 2048 个页,页的大小为 8K
C. 最多可有 1024 个段,每个段的大小均为 1024 个页,页的大小为 4K
D. 最多可有 1024 个段,每个段最大允许有 1024 个页,页的大小为 4K✅

📌 正确答案:B
🔍 详细解析
根据图中地址结构:
- 段号(31-22): 10 位 → 2 10 = 1024 段 10位 → 2^{10} = 1024段 10位→210=1024段
- 页号(21-12): 10 位 → 2 10 = 1024 页 10位 → 2^{10} = 1024页 10位→210=1024页
- 页内地址(11-0): 12 位 → 2 12 = 4 K 页大小 12位 → 2^{12} = 4K页大小 12位→212=4K页大小
💽 题目28:计算机硬件基础知识 - 磁盘文件读取时间计算
假设磁盘磁头从一个磁道移至相邻磁道需要 2ms。文件在磁盘上非连续存放,逻辑上相邻数据块的平均移动距离为5个磁道,每块的旋转延迟时间及传输时间分别为10ms和1ms,则读取一个 100 块的文件需要 (28) ms。
(28)
A. 1100
B. 1200
C. 2100 ✅
D. 2200
📌 正确答案:C
🔍 详细解析
-
计算单块读取时间
-
寻道时间(Seek Time):
- 平均移动5个磁道 × 2ms/磁道 = 10ms。
-
旋转延迟(Rotational Latency):
- 固定 10ms(平均半圈时间)。
-
传输时间(Transfer Time):
- 固定 1ms。
-
单块总时间:
10ms(寻道) + 10ms(旋转) + 1ms(传输) = 21ms。
-
-
100块文件总时间
- 总时间:
100块 × 21ms/块 = 2100ms。
- 总时间:
💡 关键点
-
非连续存储:每块需独立寻道(连续存储可减少寻道时间)。
-
旋转延迟:与磁盘转速相关,不可优化(除非使用SSD)。
🐍 题目48:程序语言设计 - Python异常处理结构辨析
在 Python3 中, (48) 不是合法的异常处理结构。
(48)
A. try…except…
B. try…except…finally
C. try…catch… ✅
D. raise
📌 正确答案:C
🔍 详细解析
-
Python异常处理语法
-
合法结构:
-
try...except...:捕获并处理异常。 -
try...except...finally:无论是否异常都执行清理代码。 -
raise:主动抛出异常。
-
-
非法结构:
try...catch...:Python使用except而非catch(Java/C#风格)。
-
-
选项逐项分析
选项 语法有效性 说明 A ✔️ 合法 基础异常捕获结构(如 try: x=1/0; except ZeroDivisionError: print("error"))。B ✔️ 合法 finally确保资源释放(如文件关闭)。C ❌ 非法 Python无 catch关键字,应为except。D ✔️ 合法 手动触发异常(如 raise ValueError("invalid"))。 -
代码示例对比
# 合法(A选项) try: 1 / 0 except ZeroDivisionError: print("除零错误") # 非法(C选项)→ 实际会报SyntaxError try: 1 / 0 catch ZeroDivisionError: # Python不支持catch! print("错误") -
为什么catch不合法?
-
历史原因:Python选择
except而非catch以保持语法简洁性。 -
语言差异:
-
Java/C#:
try-catch-finally。 -
Python:
try-except-finally。
-
-
🐍 题目49:程序语言设计 - Python列表切片操作
在 Python3 中,表达式 list(range(11))[10:0:-2] 的值为 (49) 。
(49)
A. [10, 8, 6, 4, 2, 0]
B. [10, 8, 6, 4, 2] ✅
C. [0, 2, 4, 6, 8, 10]
D. [0, 2, 4, 6, 8]
📌 正确答案:B
🔍 详细解析
-
分步拆解表达式
-
range(11):生成序列0, 1, 2, ..., 10。 -
list(range(11)):转换为列表[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]。 -
切片
[10:0:-2]:-
start=10:从索引10(值为10)开始。 -
stop=0:到索引0(值为0)结束,不包含0。 -
step=-2:步长为-2(反向每隔1个元素取1次)。
-
-
-
切片结果
按顺序选取的索引和值:
-
10 → 值
10 -
10 + (-2) = 8 → 值
8 -
8 + (-2) = 6 → 值
6 -
6 + (-2) = 4 → 值
4 -
4 + (-2) = 2 → 值
2 -
2 + (-2) = 0 → 停止(不包含stop值0)
最终结果:
[10, 8, 6, 4, 2]。 -
-
验证代码
print(list(range(11))[10:0:-2]) # 输出: [10, 8, 6, 4, 2]
🐍 题目50:程序语言设计 - Python的input()函数行为
在 Python3 中,执行语句 x = input(),如果从键盘输入 123 并按回车键,则 x 的值为 (50) 。
(50)
A. 123
B. 1,2,3
C. 1 2 3
D. ‘123’ ✅
📌 正确答案:D
🔍 详细解析
-
input()函数的行为-
Python3中:
input()始终返回用户输入的 字符串(str)类型,即使输入的是数字。 -
题目场景:输入
123后,x的值为字符串'123',而非整数123。
-
-
验证代码
x = input() # 输入123并按回车 print(type(x), x) # 输出: <class 'str'> 123 -
类型转换说明
-
若需将输入转为整数,需显式调用
int():x = int(input()) # 输入123 → x为整数123 -
直接比较:
-
x == 123→False(字符串与整数不相等)。 -
x == '123'→True。
-
-
🗃️ 题目51:数据库设计 - E-R模型向关系模型转换规则
E-R模型向关系模型转换时,两个实体E1和E2之间的多对多联系R应该转换为一个独立的关系模式,且该关系模式的关键字由 (51) 组成。
(51)
A. 联系R的属性
B. E1或E2的关键字
C. E1和E2的关键字 ✅
D. E1和E2的关键字加上R的属性
📌 正确答案:C
🔍 详细解析
-
多对多联系的转换规则
-
独立关系模式:多对多联系(如“学生选课”)需转换为单独的表。
-
主键构成:由 两个实体的主键组合 作为联合主键(确保唯一性)。
-
-
示例说明
E-R元素 转换后的关系模式 主键 学生(Student) Student(s_id, name) s_id 课程(Course) Course(c_id, title) c_id 选课(Enrollment) Enrollment(s_id, c_id, grade) s_id + c_id(联合主键) -
Enrollment表:
-
主键:
s_id(Student的主键) +c_id(Course的主键)。 -
属性:
grade是联系本身的属性,非主键部分。
-
-
-
排除其他选项
选项 错误原因 A 联系R的属性(如grade)不能唯一标识记录。 B 仅用一个实体的主键无法避免重复(如同一学生选多门课)。 D 主键只需实体主键,R的属性应作为普通字段。
🗃️ 题目52-53:数据库设计 - 数据库范式与函数依赖分析
某高校人力资源管理系统的数据库中,教师关系模式为 T(教师号,姓名,部门号,岗位,联系地址,薪资),函数依赖集 F={教师号→(姓名,部门号,岗位,联系地址),岗位→薪资}。关系模式 T 的主键为 (52) ,函数依赖集 F (53) 。
(52)
A. 教师号,T 存在冗余以及插入异常和删除异常的问题 ✅
B. 教师号,T 不存在冗余以及插入异常和删除异常的问题
C. (教师号,岗位),T 存在冗余以及插入异常和删除异常的问题
D. (教师号,岗位),T 不存在冗余以及插入异常和删除异常的问题
(53)
A. 存在传递依赖,故关系模式T最高达到1NF
B. 存在传递依赖,故关系模式T最高达到2NF ✅
C. 不存在传递依赖,故关系模式T最高达到3NF
D. 不存在传递依赖,故关系模式T最高达到4NF
📌 正确答案:(52)A、(53)B
🔍 详细解析
-
主键确定:
-
函数依赖集F中,教师号→(姓名,部门号,岗位,联系地址),因此教师号是候选键。
-
无其他属性或属性组能唯一标识元组,故主键为 教师号。
-
-
冗余与异常:
-
传递依赖:
教师号→岗位→薪资,导致薪资信息重复存储(若多个教师同一岗位)。 -
异常示例:
-
插入异常:新增岗位需先有教师(如新设“教授”岗位但未招聘时无法录入薪资标准)。
-
删除异常:删除某岗位的唯一教师会丢失薪资信息(如删除最后一位“讲师”导致该岗位薪资数据消失)。
-
-
-
范式判断:
-
1NF:属性不可再分(T显然满足)。
-
2NF:满足1NF,且非主属性完全依赖主键(教师号→薪资为部分依赖?不对,实际是传递依赖)。
- 更正:薪资通过岗位传递依赖于教师号(教师号→岗位→薪资),故满足2NF但不满足3NF。
-
3NF:需消除传递依赖(需拆表:T1(教师号,姓名,部门号,岗位,地址) + T2(岗位,薪资))。
-
-
传递依赖存在性:
- 教师号 → 岗位 → 薪资,形成传递链,因此最高达到 2NF。
🗃️ 题目54-55:数据库设计 - 关系代数表达式解析
(给定员工关系 E(员工号,员工名,部门名,电话,家庭住址)、工程关系 P(工程号,工程名,前期工程号)、参与关系 EP(员工号,工程号,工作量)。查询“005”员工参与了“虎头山隧道”工程的员工名、部门名、工程名、工作量的关系代数表达式如下:

📌 正确答案:(54)B、(55)D
🔍 详细解析
-
目标:从员工关系E中筛选员工号为“005”的记录。
-
属性位置:
- E(员工号
1, 员工名2, 部门名3, 电话4, 家庭住址5)。
- E(员工号
-
正确选择条件:
- 员工号是第1个属性 → σ 1 = ′ 00 5 ′ ( E ) σ_{1='005'}(E) σ1=′005′(E) 。
-
排除选项:
-
A:错误使用第2属性(员工名)。
-
C/D:错误操作关系P(工程表)。
-
-
步骤拆解:
-
筛选工程名:
- P(工程号1, 工程名2, 前期工程号3),工程名是第2属性 → σ 2 = ′ 虎头山隧 道 ′ ( P ) σ_{2='虎头山隧道'}(P) σ2=′虎头山隧道′(P)。
-
投影工程号和工程名:
- π 1 , 2 \pi_{1,2} π1,2 保留工程号和工程名。
-
连接EP表:
- 通过工程号关联EP表(EP包含员工号和工程号)。
-
-
选项验证:
-
D选项:
-
先筛选P表中“虎头山隧道”工程 → σ 2 = ′ 虎头山隧 道 ′ ( P ) σ_{2='虎头山隧道'}(P) σ2=′虎头山隧道′(P)。
-
投影工程号和工程名 → π 1 , 2 \pi_{1,2} π1,2 。
-
连接EP表获取参与该工程的员工信息。
-
-
💡 知识点分析
最后的公式如下面所示:
π 2 , 3 , 5 , 6 ( π 1 , 2 , 3 ( σ 1 = ′ 00 5 ′ ( E ) ) ⋈ π 1 , 2 ( σ 2 = ′ 虎头山隧 道 ′ ( P ) ) ⋈ E P ) \pi_{2,3,5,6}(\pi_{1,2,3}(σ_{1='005'}(E))⋈\pi_{1,2}(σ_{2='虎头山隧道'}(P))⋈EP) π2,3,5,6(π1,2,3(σ1=′005′(E))⋈π1,2(σ2=′虎头山隧道′(P))⋈EP)
下面来详细说说他的过程:
-
π
1
,
2
,
3
(
σ
1
=
′
00
5
′
(
E
)
\pi_{1,2,3}(σ_{1='005'}(E)
π1,2,3(σ1=′005′(E) 表示从员工关系E(员工号1, 员工名2, 部门名3, 电话4, 家庭住址5)中根据
员工号="005"查出前三个属性,即员工号1, 员工名2, 部门名3 -
π
1
,
2
(
σ
2
=
′
虎头山隧
道
′
(
P
)
\pi_{1,2}(σ_{2='虎头山隧道'}(P)
π1,2(σ2=′虎头山隧道′(P)表示从工程关系 P(工程号1,工程名2,前期工程号3)中根据
工程名="虎头山隧道"查出前两个数据,即工程号1,工程名2 - ⋈ E P ⋈EP ⋈EP 表示通过参与关系 EP(员工号1,工程号2,工作量3)将E和P关联起来,即 π 2 , 3 , 5 , 6 ( 员工号 1 , 员工名 2 , 部门名 3 , 工程号 4 , 工程名 5 , 工作量 6 ) \pi_{2,3,5,6}(员工号1, 员工名2, 部门名3,工程号4,工程名5,工作量6) π2,3,5,6(员工号1,员工名2,部门名3,工程号4,工程名5,工作量6)
- 最后取集合中
2,3,5,6属性,得到员工名, 部门名,工程名,工作量
🏦 题目56:数据库事务 - 数据库故障类型辨析
假设事务程序 A 中的表达式 x/y,若 y 取值为 0,则计算该表达式时,会产生故障。该故障属于 (56) 。
(56)
A. 系统故障
B. 事务故障 ✅
C. 介质故障
D. 死机
📌 正确答案:B
🔍 详细解析
-
故障类型定义
故障类型 原因 典型场景 事务故障 事务内部逻辑错误(如除零) 除零、死锁、违反约束 系统故障 硬件/软件崩溃(如断电) 内存丢失、操作系统崩溃 介质故障 存储设备损坏(如磁盘故障) 磁头损坏、数据文件不可读 死机 系统无响应(广义系统故障) CPU过载、死循环 -
题目场景分析
-
故障原因:事务程序中的表达式
x/y因y=0抛出异常(如ZeroDivisionError)。 -
故障范围:仅影响当前事务(事务A),不破坏系统整体或其他事务。
-
归类依据:由事务内部逻辑错误引发,属于 事务故障。
-
💡 事务故障处理
恢复机制:
-
事务回滚(UNDO):撤销故障事务的所有修改。
-
日志记录:通过日志(如WAL)恢复一致性状态。
🧮 题目57:数据结构 - 栈的出栈序列可能性分析
设栈初始时为空,对于入栈序列 1, 2, 3, …, n,这些元素经过栈之后得到出栈序列 P₁, P₂, P₃, …, Pₙ 。若 P₃=4,则 P₁, P₂ 不可能的取值为 (57) 。
(57)
A. 6,5
B. 2,3
C. 3,1✅
D. 3,5
📌 正确答案:C
🔍 详细解析
-
已知条件与约束
-
入栈序列:1, 2, 3, …, n(按顺序入栈)。
-
出栈序列:P₁, P₂, P₃, …, Pₙ,且 P₃=4。
-
栈的特性:后进先出(LIFO),任意时刻可入栈或出栈。
-
-
推理步骤
-
P₃=4 的含义:
-
元素4在第3个位置出栈 → 在4出栈前,必须已入栈1, 2, 3且它们未全部出栈(否则4无法留在栈中)。
-
关键结论:P₁和P₂只能是 已入栈且已出栈的元素,即1, 2, 3中未被P₁和P₂选中的元素需留在栈中,直到4出栈。
-
-
逐选项验证:
选项 P₁, P₂ 可行性分析 结论 A 6, 5 需先入栈1-6,出栈6和5后栈顶为4(P₃=4)。但入栈序列未说明n≥6,假设n足够大则可能。 可能 B 2, 3 入栈1,2 → 出栈2;入栈3 → 出栈3;入栈4 → 出栈4(P₃=4)。 可能 C 3, 1 入栈1,2,3 → 出栈3;出栈1(需2已出栈,矛盾)。实际操作:1,2,3入栈 → 出栈3 → 出栈2 → 出栈1 → 入栈4 → 出栈4(P₃=4)。但此时P₂=2,非1。 矛盾点:若P₂=1,需先弹出2,但2未在P₁或P₂中。 不可能 D 3, 5 入栈1,2,3 → 出栈3;入栈4,5 → 出栈5。此时栈顶为4(P₃=4),出栈4(P₃=4)。 可能
-
🌳 题目58:数据结构 - 二叉树中序遍历顺序分析
设 m 和 n 是某二叉树上的两个结点,中序遍历时,n 排在 m 之前的条件是 (58) 。
(58)
A. m 是 n 的祖先结点
B. m 是 n 的子孙结点
C. m 在 n 的左边
D. m 在 n 的右边 ✅
📌 正确答案:D
🔍 详细解析
关于二叉树遍历详细讲解可见文章《二叉树的层序遍历、前序遍历,中序遍历、后续遍历》
-
中序遍历(LNR)的特性
-
遍历顺序:左子树 → 根结点 → 右子树。
-
关键结论:对于任意两个结点,n 在 m 之前被访问的条件是:
-
n 在 m 的左子树中,或
-
m 在 n 的右子树中(即 n 是 m 的祖先且 m 在 n 的右侧)。
-
-
-
选项逐项分析
选项 描述 是否满足 n 在 m 前 反例/验证 A m 是 n 的祖先 ❌ 若 m 是 n 的父结点且 n 是右孩子,中序遍历 n 在 m 后。 B m 是 n 的子孙 ❌ 若 m 是 n 的右子孙,中序遍历 n 在 m 前。 C m 在 n 的左边 ❌ 若 m 在 n 的左兄弟子树中,n 在 m 前。 D m 在 n 的右边 ✅ m 在 n 的右子树 ⇒ n 在 m 前(中序遍历先左后根再右)。
🏗️ 题目59:数据结构 - 无向图的邻接矩阵存储空间分析
若无向图 G 有 n 个顶点 e 条边,则 G 采用邻接矩阵存储时,矩阵的大小为 (59) 。
(59)
A. n × e
B. n² ✅
C. n² + e²
D. (n + e)²
📌 正确答案:B
🔍 详细解析
-
邻接矩阵的结构
-
矩阵维度:邻接矩阵是一个
n × n的方阵,其中n是顶点数。 -
矩阵元素:
-
若顶点
i和j之间有边,则A[i][j] = 1(或边的权重)。 -
若无边,则
A[i][j] = 0。
-
-
-
空间复杂度
-
矩阵大小:固定为
n²,与边数e无关。- 无向图优化:由于对称性,可压缩存储为
n(n+1)/2,但题目未说明优化,默认完整矩阵。
- 无向图优化:由于对称性,可压缩存储为
-
示例:
- 3个顶点的无向图 → 3×3矩阵(9个元素)。
-
-
排除其他选项
选项 错误原因 A 混淆了邻接矩阵与邻接表的存储方式(邻接表空间为 n + e)。 C/D 无意义组合,邻接矩阵大小仅与顶点数相关。
💡 邻接矩阵 vs 邻接表
| 存储方式 | 空间复杂度 | 适用场景 |
|---|---|---|
| 邻接矩阵 | O(n²) | 稠密图(边数接近n²) |
| 邻接表 | O(n + e) | 稀疏图(边数远小于n²) |
-
有如下无向图,求邻接矩阵与邻接表
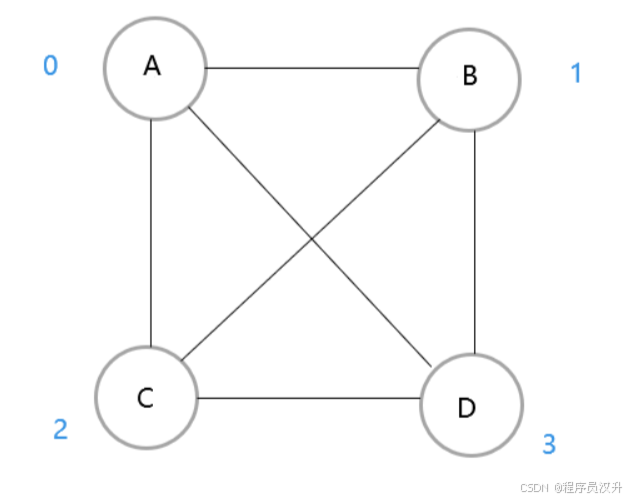
-
其邻接表表示如下:
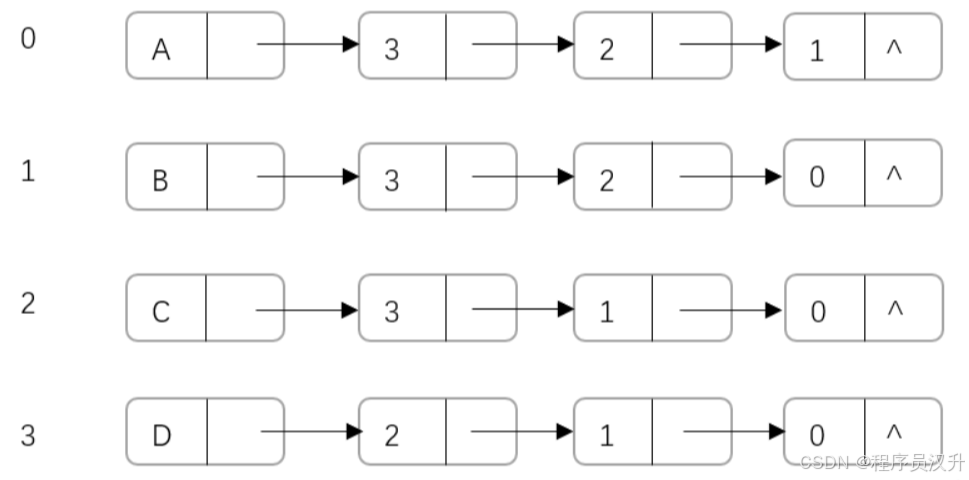
-
其邻接矩阵表示如下:
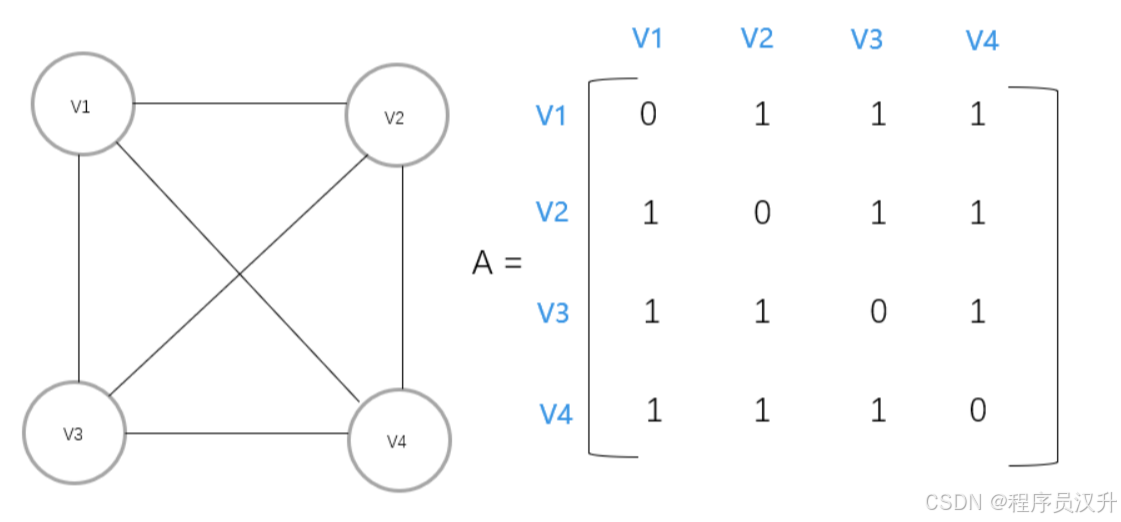
-
-
有如下有向图,求邻接矩阵与邻接表
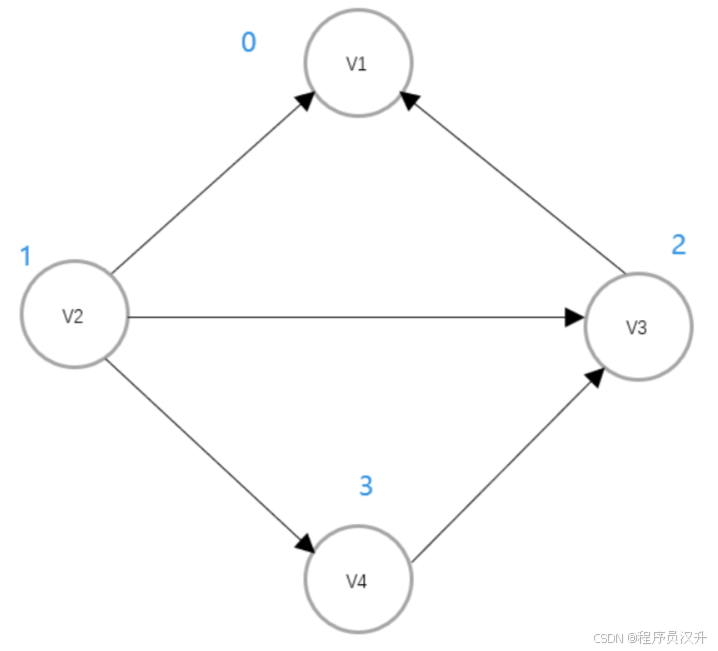
-
其邻接表表示如下:
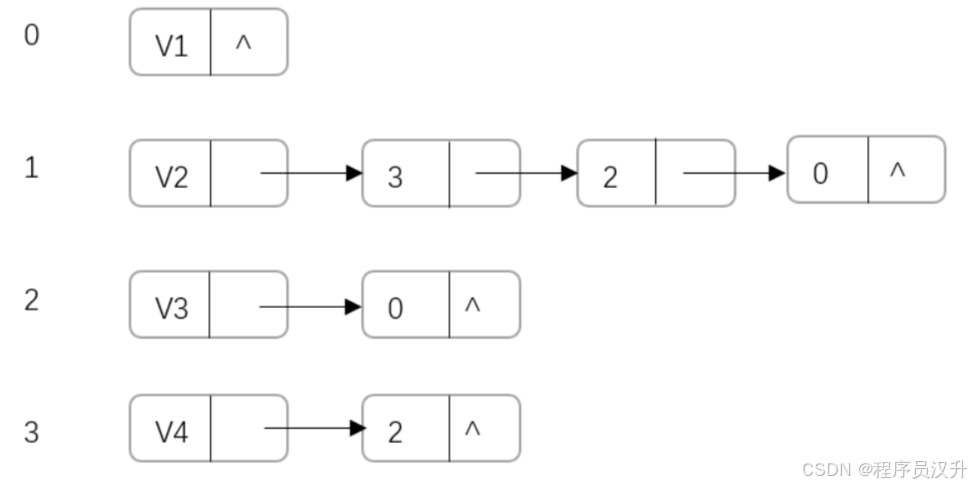
-
其邻接矩阵表示如下:
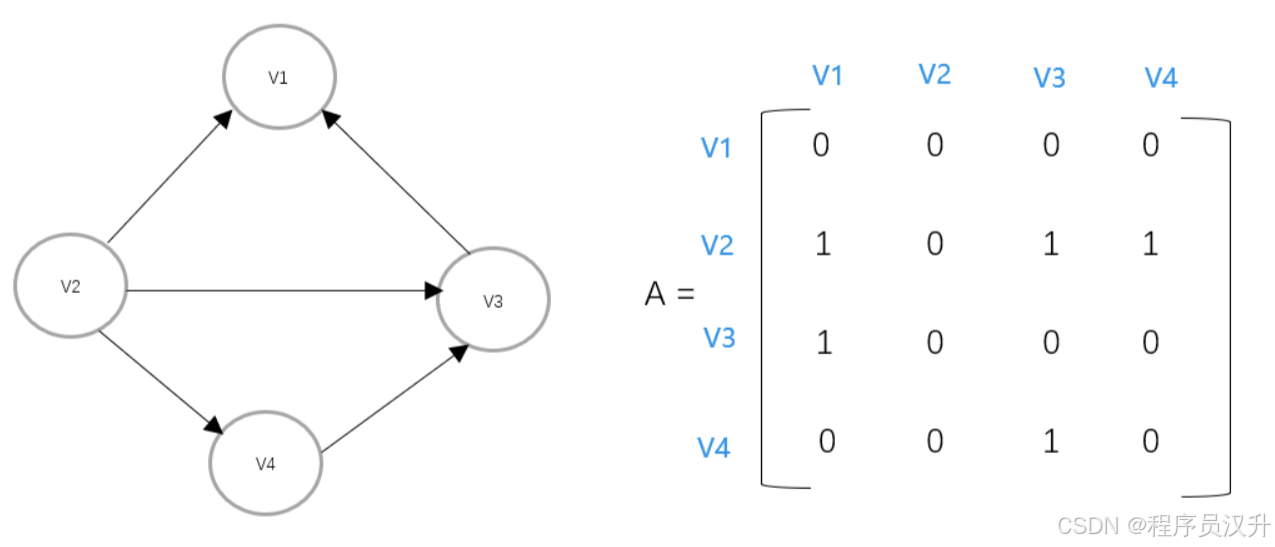
-
🌳 题目60:数据结构 - B-树特性辨析
以下关于 m 阶 B-树的说法中,错误的是 (60) 。
(60)
A. 根结点最多有 m 棵子树
B. 所有叶子结点都在同一层次上
C. 结点中的关键字有序排列
D. 叶子结点通过指针链接为有序表 ✅
📌 正确答案:D
🔍 详细解析
-
B-树的核心特性
特性 描述 题目选项 子树数量 根结点:至少2棵子树(若非叶子),最多m棵;非根结点:⌈m/2⌉到m棵。 A(部分正确) 叶子结点层次 所有叶子位于同一层,保证平衡性。 B(正确) 关键字有序性 结点内关键字按升序排列,左子树关键字小于当前关键字,右子树大于。 C(正确) 叶子结点指针链接 B+树的叶子结点通过指针链接为有序表,B-树无此特性。 D(错误) -
选项D的错误性
-
B-树 vs B+树:
-
B-树:关键字分布在所有结点,叶子结点不链接。
-
B+树:关键字仅存于叶子结点,且叶子通过指针串联(支持范围查询)。
-
-
图示对比:
B-树: [根结点] B+树: [根结点] / | \ / | \ [子结点]...[子结点] [子结点]...[子结点] / \ / \ / \ / \ [叶子][叶子]...[叶子] [叶子]⇄[叶子]⇄...(链表链接)
-
🏆 题目61:数据结构与算法 - 排序算法辅助空间复杂度比较
下列排序算法中,占用辅助存储空间最多的是 (61) 。
(61)
A. 归并排序 ✅
B. 快速排序
C. 堆排序
D. 冒泡排序
📌 正确答案:A
🔍 详细解析
-
各排序算法的空间复杂度
算法 辅助空间复杂度 原因 归并排序 O(n) 需额外空间存储合并后的有序序列(递归或迭代均需线性空间)。 快速排序 O(log n) ~ O(n) 递归栈空间(最坏情况退化为O(n))。 堆排序 O(1) 原地排序,仅需常数空间交换元素。 冒泡排序 O(1) 原地排序,仅需常数空间交换相邻元素。 -
为什么归并排序空间占用最多?
-
合并操作:每次合并两个子数组需临时数组存储结果,空间与输入规模成正比。
-
递归开销:递归实现的隐式栈空间(O(log n))叠加显式合并空间(O(n)),总空间仍为O(n)。
-
-
其他算法对比
-
快速排序:
-
平均递归深度O(log n),最坏(如已排序数组)O(n)。
-
但题目问“最多”,归并排序的O(n)始终高于快排的平均情况。
-
-
堆排序与冒泡排序:
- 均为原地排序,空间复杂度O(1)。
-
💡 示例说明
import java.util.Arrays;
public class MergeSort {
public static void main(String[] args) {
int[] arr = {38, 27, 43, 3, 9, 82, 10};
System.out.println("Original array: " + Arrays.toString(arr));
int[] sortedArr = mergeSort(arr);
System.out.println("Sorted array: " + Arrays.toString(sortedArr));
}
public static int[] mergeSort(int[] arr) {
if (arr.length <= 1) {
return arr;
}
int mid = arr.length / 2;
int[] left = Arrays.copyOfRange(arr, 0, mid);
int[] right = Arrays.copyOfRange(arr, mid, arr.length);
return merge(mergeSort(left), mergeSort(right));
}
private static int[] merge(int[] left, int[] right) {
int[] result = new int[left.length + right.length];
int i = 0, j = 0, k = 0;
while (i < left.length && j < right.length) {
if (left[i] <= right[j]) {
result[k++] = left[i++];
} else {
result[k++] = right[j++];
}
}
while (i < left.length) {
result[k++] = left[i++];
}
while (j < right.length) {
result[k++] = right[j++];
}
return result;
}
}
🧩 题目62-63:数据结构与算法 - 折半查找算法策略与平均比较次数
折半查找在有序数组 A 中查找特定的记录 K:通过比较 K 和数组中的中间元素 A[mid] 进行比较,如果相等,则算法结束;如果 K 小于 A[mid],则对数组的前半部分进行折半查找;否则对数组的后半部分进行折半查找。根据上述描述,折半查找采用了 (62) 算法设计策略。对有序数组(3,14,27,39,42,55,70,85,93,98),成功查找和失败查找所需要的平均比较次数分别是 (63) (假设查找每个元素的概率是相同的)。
(62)
A. 分治 ✅
B. 动态规划
C. 贪心
D. 回溯
(63)
A. 29/10 和 29/11
B. 30/10 和 30/11
C. 29/10 和 39/11 ✅
D. 30/10 和 40/11
📌 正确答案:(62)A、(63)C
🔍 详细解析
-
分治法:将问题分解为子问题(如折半查找每次将数组分为两部分),递归解决后合并结果(此处无需合并)。
-
对比其他策略:
-
动态规划:解决重叠子问题(如斐波那契数列)。
-
贪心:局部最优解(如Dijkstra算法)。
-
回溯:试错+回退(如N皇后问题)。
-
-
成功查找的平均比较次数(保持不变)
-
判定树结构:
42 / \ 27 85 / \ / \ 14 39 55 93 / \ / \ / \ / \ 3 * * * * * 70 * 98 -
成功比较次数:
-
42:1次
-
27, 85:2次
-
14, 39, 55, 93:3次
-
3, 70, 98:4次
-
总和:1 + 2×2 + 3×4 + 4×3 = 29
-
平均:29 / 10 = 29/10
-
-
-
失败查找的平均比较次数
-
有序数组(3,14,27,39,42,55,70,85,93,98)
-
失败位置数量:
n+1=11(10个元素对应11个外部空位)。 -
失败路径比较次数:
失败路径区间 深度 比较数据 比较次数 <34 小于根节点42,小于27,小于14,小于3 4 3-14 4 小于根节点42,小于27,小于14,大于3 4 14-27 3 小于根节点42,小于27,大于14 3 27-39 3 小于根节点42,大于27,小于39 3 39-42 3 小于根节点42,大于27,大于39 3 42-55 3 大于根节点42,小于85,小于55 3 55-70 4 大于根节点42,小于85,大于55,小于70 4 70-85 4 大于根节点42,小于85,大于55,大于70 4 85-93 3 大于根节点42,大于85,小于93 3 93-98 4 大于根节点42,大于85,大于93,小于98 4 >984 大于根节点42,大于85,大于93,大于98 4 -
总和:3×5 + 4×6 = 12 + 28 = 39
-
平均:39 / 11
-
🚀 题目64-65:数据结构与算法 - Dijkstra算法策略与最短路径计算
采用 Dijkstra 算法求解下图 A 点到 E 点的最短路径,采用的算法设计策略是 (64) 。该最短路径的长度是 (65) 。
(64)
A. 分治法
B. 动态规划
C. 贪心算法 ✅
D. 回溯法
(65)
A. 5 ✅
B. 6
C. 7
D. 9
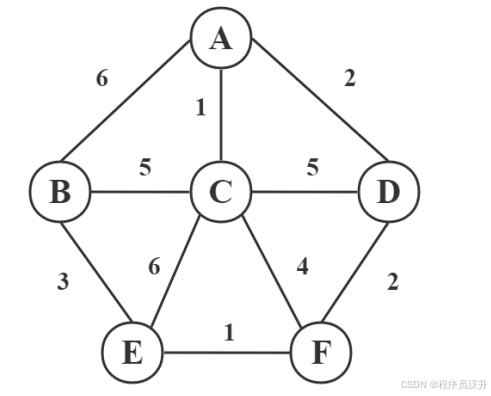
📌 正确答案:(64)C、(65)A
🔍 详细解析
-
贪心算法:Dijkstra 每次选择当前未处理的、距离起点最近的结点(局部最优),逐步扩展到全局最优。
-
对比其他策略:
-
分治法:将问题分解为独立子问题(如归并排序)。
-
动态规划:解决重叠子问题(如Floyd算法)。
-
回溯法:试错+回退(如N皇后问题)。
-
🔍 分步计算
-
初始化:
设距离数组
dist,将 A 到自身距离设为 0,即dist[A]=0,到其他点距离设为无穷大。设集合S存储已确定最短路径的点,初始S = {A}。 -
迭代过程:
- 第一次迭代:A 的邻接点有B、C、D,
dist[B] = min(dist[B], 6)=6,dist[C] = min(dist[C], 1)=1,dist[D]=min(dist[D], 2)=2,更新后dist = {A:0, B:6, C:1, D:2, E:∞, F:∞},选择距离最小的 C 加入S,此时S = {A, C}。 - 第二次迭代:C 的邻接点 B、E、F、D,
dist[B]=min(dist[B], 1 + 5)=6,dist[E]=min(dist[E], 1+6)=7,dist[F]=min(dist[F], 1 + 4)=5,dist[D]=min(dist[D], 1 + 5)=2,更新后dist = {A:0, B:6, C:1, D:2, E:7, F:5},选择距离最小的 D 加入S,此时S = {A, C, D}。 - 第三次迭代:D 的邻接点 F,
dist[F]=min(dist[F], 2+2)=4,更新后dist = {A:0, B:6, C:1, D:2, E:7, F:4},选择 F 加入S,此时S = {A, C, D, F}。 - 第四次迭代:F 的邻接点 E,
dist[E]=min(dist[E], 4+1)=5,更新后dist = {A:0, B:6, C:1, D:2, E:5, F:4},选择 E 加入S,此时S = {A, C, D, F, E}。 - 第五次迭代:E 的邻接点 B,
dist[B]=min(dist[B], 5+3)=6,此时S = {A, C, D, F, E, B},迭代结束。
- 第一次迭代:A 的邻接点有B、C、D,
A 到各点最短路径长度为:A 到 B 是 6、A 到 C 是 1、A 到 D 是 2、A 到 E 是 5、A 到 F 是 4 。
🌐 题目66:计算机网络 - VLAN Tag在OSI模型中的位置
VLAN tag 在 OSI 参考模型的 (66) 实现。
(66)
A. 网络层
B. 传输层
C. 数据链路层 ✅
D. 物理层
📌 正确答案:C
🔍 详细解析
-
VLAN Tag的作用与位置
-
功能:VLAN(虚拟局域网)标签用于在以太网帧中标识数据包所属的虚拟网络,实现二层网络的逻辑隔离。
-
OSI层归属:
-
数据链路层(Layer 2):VLAN Tag 嵌入在以太网帧头中(如IEEE 802.1Q标准),修改帧结构但不影响上层(网络层及以上)。
-
典型字段:4字节的Tag包含VLAN ID(12位)、优先级(3位)等。
-
-
-
排除其他选项
| 选项 | OSI层 | 不匹配原因 |
|---|---|---|
| A | 网络层(Layer 3) | 处理IP路由,与帧标识无关。 |
| B | 传输层(Layer 4) | 管理端到端连接(如TCP/UDP),与网络分段无关。 |
| D | 物理层(Layer 1) | 负责比特流传输,不解析帧结构。 |
-
技术对比
-
VLAN vs 子网:
-
VLAN:数据链路层隔离(基于MAC地址和标签)。
-
子网:网络层隔离(基于IP地址)。
-
-
🌐 题目67:计算机网络 - Telnet协议特性辨析
Telnet 协议是一种 (67) 远程登录协议。
(67)
A. 安全
B. B/S 模式
C. 基于 TCP ✅
D. 分布式
📌 正确答案:C
🔍 详细解析
-
Telnet的核心特性
-
基于TCP:Telnet 使用 TCP端口 23 提供可靠的面向连接服务,确保数据有序传输。
-
非安全:所有数据(包括密码)以明文传输,易被窃听(SSH 是其安全替代方案)。
-
C/S 模式:客户端/服务器架构,非 B/S(浏览器/服务器)。
-
非分布式:单点登录到远程主机,无分布式协作功能。
-
-
协议对比
| 协议 | 传输层 | 安全性 | 主要用途 |
|---|---|---|---|
| Telnet | TCP | 无加密 | 远程命令行管理(逐渐淘汰) |
| SSH | TCP | 加密 | 安全的远程登录与文件传输 |
| HTTP | TCP | 可选加密 | 网页浏览(B/S 模式) |
🔒 题目68:计算机网络 - HTTPS与HTTP协议辨析
以下关于 HTTPS 和 HTTP 协议的叙述中,错误的是 (68) 。
(68)
A. HTTPS 协议使用加密传输
B. HTTPS 协议默认服务端口号是 443
C. HTTP 协议默认服务端口号是 80
D. 电子支付类网站应使用 HTTP 协议 ✅
📌 正确答案:D
🔍 详细解析
| 选项 | 正误 | 说明 |
|---|---|---|
| A | ✔️ 正确 | HTTPS 通过 SSL/TLS 加密数据,保护传输安全(如 AES、RSA 算法)。 |
| B | ✔️ 正确 | HTTPS 默认端口 443,HTTP 默认端口 80。 |
| C | ✔️ 正确 | HTTP 明文传输,端口 80 是国际标准。 |
| D | ❌ 错误 | 电子支付必须使用 HTTPS,HTTP 的明文传输会导致敏感信息(如银行卡号)泄露。 |
🌐 题目69:计算机网络 - 域名解析
将网址转换为 IP 地址要用 (69) 协议。
(69)
A. 域名解析 ✅
B. IP 地址解析
C. 路由选择
D. 传输控制
📌 正确答案:A
🔍 详细解析
| 选项 | 协议名称 | 功能描述 | 是否符合将网址转换为 IP 地址的功能 |
|---|---|---|---|
| A | 域名解析(DNS)协议 | 将域名(网址)转换为对应的 IP 地址 | 是 |
| B | 地址解析协议(ARP) | 将 IP 地址解析为 MAC 地址,用于局域网内数据链路层寻址 | 否 |
| C | 路由选择协议(如 RIP、OSPF 等) | 在网络中寻找数据包从源到目的的最佳传输路径 | 否 |
| D | 传输控制协议(TCP) | 提供可靠的、面向连接的数据传输服务,负责数据分段、重组、流量控制等 | 否 |
🌐 题目70:计算机网络 - IP 地址和 MAC 地址
以下关于 IP 地址和 MAC 地址说法错误的是 (70) 。
(70)
A. IP 地址长度 32 或 128 位,MAC 地址的长度 48 位
B. IP 地址工作在网络层,MAC 地址工作在数据链路层
C. IP 地址的分配是基于网络拓扑,MAC 地址的分配是基于制造商
D. IP 地址具有唯一性,MAC 地址不具有唯一性✅
📌 正确答案:D
🔍 详细解析
| 选项 | 描述 | 正误判断 | 原因 |
|---|---|---|---|
| A | IP 地址长度 32 或 128 位,MAC 地址的长度 48 位 | 正确 | IPv4 地址是 32 位,IPv6 地址是 128 位,MAC 地址固定为 48 位 |
| B | IP 地址工作在网络层,MAC 地址工作在数据链路层 | 正确 | 网络层使用 IP 地址进行逻辑寻址,数据链路层依靠 MAC 地址实现设备间的数据传输 |
| C | IP 地址的分配是基于网络拓扑,MAC 地址的分配是基于制造商 | 正确 | IP 地址根据网络拓扑和子网划分进行分配,MAC 地址由制造商按 IEEE 规定烧录到设备中 |
| D | IP 地址具有唯一性,MAC 地址不具有唯一性 | 错误 | IP 地址在其所属网络范围内需唯一,MAC 地址由 IEEE 管理分配,全球范围内基本唯一,用于唯一标识设备 |
二、 系统开发和运行知识 🗃️
🛠️ 题目15:系统开发 - 加工规格说明的描述方法选择
某零件厂商的信息系统中,一个基本加工根据客户类型、订单金额、客户信用等信息的不同采取不同的行为,此时最适宜采用 (15) 来描述该加工规格说明。
(15)
A. 自然语言
B. 流程图
C. 判定表 ✅
D. 某程序设计语言
📌 正确答案:C
🔍 详细解析
-
判定表的优势
-
多条件组合决策:
题目中涉及客户类型、订单金额、信用等级等多个条件的交叉判断,判定表能以表格形式清晰列出所有可能的条件组合及对应动作。 -
避免二义性:
自然语言(选项A)易产生歧义,而判定表通过结构化表达确保逻辑严密性。
-
-
其他选项的局限性
选项 适用场景 本题缺陷 A. 自然语言 简单规则描述 复杂条件组合时表述冗长且易遗漏分支。 B. 流程图 线性流程控制 难以直观展示多维度条件的并行判断。 D. 程序设计语言 代码实现 属于实现阶段工具,非需求分析阶段的规格说明。 -
判定表示例
| 客户类型 | 订单金额 | 客户信用 | 动作 |
|---|---|---|---|
| VIP | ≥10,000 | 良好 | 免运费+折扣10% |
| VIP | <10,000 | 良好 | 免运费 |
| 普通 | ≥5,000 | 良好 | 折扣5% |
| (其他组合) | … | … | 默认处理 |
🧩 题目16:系统开发 - 模块结构优化的错误方法
优化模块结构时, (16) 不是适当的处理方法。
(16)
A. 使模块功能完整
B. 消除重复功能,改善软件结构
C. 只根据模块功能确定规模大小✅
D. 避免或减少模块之间的病态连接
📌 正确答案:C
🔍 详细解析
-
模块设计的基本原则
-
高内聚低耦合:模块内部功能紧密相关,模块间依赖最小化。
-
功能完整性(选项A):每个模块应独立完成特定功能(如用户认证模块包含密码加密、验证等完整流程)。
-
消除冗余(选项B):重复代码会增加维护成本(如多个模块实现相同日志功能)。
-
连接健康性(选项D):病态连接(如循环依赖、全局变量滥用)会降低可维护性。
-
-
选项C的问题
-
单一依据的局限性:
-
仅按功能确定模块规模,可能忽视 复杂度(如一个“订单处理”功能可能需拆分为创建、支付、物流等子模块)。
-
忽略 团队协作(过大模块导致多人修改冲突)和 性能(高频功能需独立优化)。
-
-
🗺️ 题目17-18:系统开发 - 关键路径分析
下图是一个软件项目的活动图,其中顶点表示项目里程碑,连接顶点的边表示包含的活动,边上的数字表示完成该活动所需要的天数。则关键路径长度为 (17) 。若在实际项目进展中,在其他活动都能正常进行的前提下,活动 (18) 一旦延期就会影响项目的进度。
(17)
A. 34
B. 47
C. 54
D. 58✅
(18)
A. A→B
B. C→F ✅
C. D→F
D. F→H
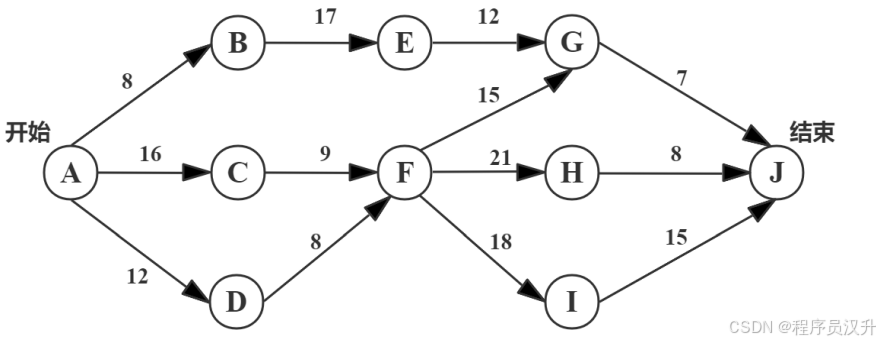
📌 正确答案:(17)D、(18)B
🔍 详细解析
首先附上mermaid图:
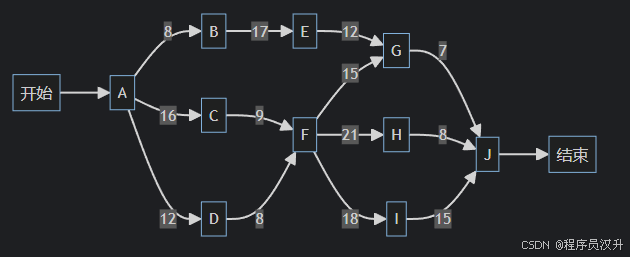
步骤1:列出所有路径及长度
根据提供的 活动图(AOV网),推导所有可能路径及其总天数:
| 路径 | 计算过程 | 总天数 |
|---|---|---|
| Start → A → B → E → G → J → End | 8 + 17 + 12 + 7 + 0 = 44 | 44 |
| Start → A → C → F → G → J → End | 16 + 9 + 15 + 7 + 0 = 47 | 47 |
| Start → A → C → F → H → J → End | 16 + 9 + 21 + 8 + 0 = 54 | 54 |
| Start → A → C → F → I → J → End | 16 + 9 + 18 + 15 + 0 = 58 | 58 |
| Start → A → D → F → G → J → End | 12 + 8 + 15 + 7 + 0 = 42 | 42 |
| Start → A → D → F → H → J → End | 12 + 8 + 21 + 8 + 0 = 49 | 49 |
| Start → A → D → F → I → J → End | 12 + 8 + 18 + 15 + 0 = 53 | 53 |
关键路径:最长路径为 Start → A → C → F → I → J → End,总天数 58。
步骤2:识别关键活动
关键活动是关键路径上的边(一旦延期会影响总工期):
-
A → C(16天)
-
C → F(9天)
-
F → I(18天)
-
I → J(15天)
选项中匹配的关键活动是 C → F (B选项)。
📊 题目19:软件开发项目管理 - 风险管理原则辨析
以下关于风险管理的叙述中,不正确的是 (19) 。
(19)
A. 承认风险是客观存在的,不可能完全避免
B. 同时管理所有的风险 ✅
C. 风险管理应该贯穿整个项目管理过程
D. 风险计划本身可能会带来新的风险
📌 正确答案:B
🔍 详细解析
-
错误叙述分析(选项B)
-
问题:资源有限性决定了无法“同时管理所有风险”。
-
正确做法:应优先管理 高风险项(如高概率高影响),低风险可监控或接受。
-
-
其他选项的正确性
| 选项 | 风险管理原则 |
|---|---|
| A | 风险具有客观性,只能降低无法消除(如地震对项目的影响)。 |
| C | 风险管理需覆盖项目全生命周期(启动、规划、执行、收尾)。 |
| D | 风险应对措施可能引入次生风险(如外包缓解技术风险但带来供应商依赖风险)。 |
🏗️ 题目29:系统设计方法与模型 - 快速原型模型的优点辨析
以下关于快速原型模型优点的叙述中,不正确的是 (29) 。
(29)
A. 有助于满足用户的真实需求
B. 适用于大型软件系统的开发 ✅
C. 开发人员快速开发出原型系统,因此可以加速软件开发过程,节约开发成本
D. 原型系统已经通过与用户的交互得到验证,因此对应的规格说明文档能正确描述用户需求
📌 正确答案:B
🔍 详细解析
-
快速原型模型的核心特点
-
核心目标:通过快速构建原型,早期验证需求,减少后期变更风险。
-
适用场景:需求不明确、变化频繁的 中小型项目(如MVP开发、界面演示)。
-
-
选项逐项分析
选项 正误 说明 A ✔️ 正确 原型通过用户交互验证真实需求(如界面布局、功能流程)。 B ❌ 不正确 大型系统需严格架构设计和文档,原型难以覆盖全局复杂度(如操作系统、ERP)。 C ✔️ 正确 D ✔️ 正确 已验证的原型可转化为精准的需求文档(避免歧义)。
🏗️ 题目30:系统设计 - 三层C/S结构的特性辨析
以下关于三层C/S结构的叙述中,不正确的是 (30) 。
(30)
A. 允许合理划分三层结构的功能,使之在逻辑上保持相对独立性,提高系统的可维护性和可扩展性
B. 允许更灵活有效地选用相应的软硬件平台和系统
C. 应用的各层可以并发开发,但需要相同的开发语言 ✅
D. 利用功能层有效地隔离表示层和数据层,便于严格的安全管理
📌 正确答案:C
🔍 详细解析
-
三层C/S结构的核心特点
-
分层架构:
-
表示层(UI):用户交互(如Web页面、桌面客户端)。
-
功能层(业务逻辑):处理业务规则(如订单计算、权限验证)。
-
数据层:数据库操作(如SQL查询、NoCRUD)。
-
-
核心优势:逻辑解耦、平台灵活性、安全管理。
-
-
选项逐项分析
| 选项 | 正误 | 说明 |
|---|---|---|
| A | ✔️ 正确 | 分层设计确保各层独立(如修改UI不影响数据库)。 |
| B | ✔️ 正确 | 各层可异构(如UI用JavaScript,业务层用Java,数据库用MySQL)。 |
| C | ❌ 不正确 | 各层无需相同语言(如前端用HTML+JS,后端用Python)。 |
| D | ✔️ 正确 | 功能层隔离防止直接访问数据库(如SQL注入防护)。 |
-
为什么选项C错误?
-
跨语言支持:三层架构的核心优势之一是允许不同技术栈(如.NET后端+React前端)。
-
反例:
-
表示层:Angular(TypeScript)
-
功能层:Spring Boot(Java)
-
数据层:PostgreSQL(SQL)
-
-
💡 三层架构的灵活性
| 层 | 技术选择示例 | 开发语言独立性 |
|---|---|---|
| 表示层 | React, Vue, WinForms | 可不同 |
| 功能层 | Node.js, Java EE, .NET Core | 可不同 |
| 数据层 | MySQL, MongoDB, Oracle | 可不同 |
🧩 题目31:系统设计 - 模块耦合类型辨析
若模块A和模块B通过外部变量来交换输入、输出信息,则这两个模块的耦合类型是 (31) 耦合。
(31)
A. 数据
B. 标记
C. 控制
D. 公共 ✅
📌 正确答案:D
🔍 详细解析
耦合类型定义
-
公共耦合(Common Coupling):
-
多个模块通过 共享全局变量(外部变量) 交换数据。
-
特点:高耦合度,修改全局变量会影响所有依赖模块。
-
-
其他选项对比:
耦合类型 特点 示例 数据耦合 通过参数传递基本数据类型 func(A int, B float) 标记耦合 通过传递数据结构(如结构体) func(user User) 控制耦合 通过参数控制对方逻辑(如标志位) func(enable bool)
🏻 题目32:系统开发 - 软件高质量标准的理解
软件开发的目标是开发出高质量的软件系统,这里的高质量不包括 (32) 。
(32)
A. 软件必须满足用户规定的需求
B. 软件应遵循规定标准所定义的一系列开发准则
C. 软件开发应采用最新的开发技术 ✅
D. 软件应满足某些隐含的需求,如可理解性、可维护性等
📌 正确答案:C
🔍 详细解析
-
高质量软件的核心标准
-
功能性(A选项):满足用户显式需求(如业务流程、功能列表)。
-
合规性(B选项):遵循行业标准(如ISO 9126、MISRA C编码规范)。
-
隐含需求(D选项):可维护性、可扩展性等非功能性需求。
-
-
为什么“最新技术”不是高质量的必要条件?
-
技术中立性:高质量可通过成熟稳定技术实现(如银行系统常用Java而非最新Rust)。
-
风险考量:新技术可能引入未知风险(如兼容性问题、社区支持不足)。
-
反例:
- 用最新区块链技术开发简单CMS系统 → 过度设计,反而降低可维护性。
-
🧪 题目33:软件测试基础知识 - 白盒测试覆盖方法的能力对比
白盒测试技术的各种覆盖方法中, (33) 具有最弱的错误发现能力。
(33)
A. 判定覆盖
B. 语句覆盖 ✅
C. 条件覆盖
D. 路径覆盖
📌 正确答案:B
🔍 详细解析
-
白盒测试覆盖方法能力排序
从弱到强的错误发现能力:
语句覆盖 < 判定覆盖 < 条件覆盖 < 路径覆盖 -
各方法核心特点
覆盖方法 覆盖目标 错误发现能力 示例(代码 if (A && B)) 语句覆盖 每条语句至少执行一次 ⭐ 最弱 测试用例 A=true, B=true(仅验证语句执行,不验证逻辑) 判定覆盖 每个判定(分支)的真假至少一次 ⭐⭐ 增加 A=false, B=false(覆盖if-else分支) 条件覆盖 每个条件的真假至少一次 ⭐⭐⭐ 分别测试 A=true/false 和 B=true/false 路径覆盖 所有可能的执行路径 ⭐⭐⭐⭐ 最强 覆盖 A&&B、A&&!B、!A&&B、!A&&!B
📄 题目34:软件质量 - 高质量文档标准的辨析
文档是软件的重要因素,关于高质量文档,以下说法不正确的是 (34) 。
(34)
A. 不论项目规模和复杂程度如何,都要用统一的标准指定相同类型和相同要素的文档 ✅
B. 应该分清读者对象
C. 应当是完整的、独立的、自成体系的
D. 行文应十分确切,不出现多义性描述
📌 正确答案:A
🔍 详细解析
-
高质量文档的核心原则
原则 说明 对应选项 读者导向 针对不同读者(开发者、用户、测试员)提供适配内容(如API文档 vs 用户手册)。 B 完整性 覆盖所有必要信息,无需依赖外部补充。 C 无歧义性 使用精准术语,避免模糊表述(如“快速响应”应量化为“响应时间≤2s”)。 D 灵活性 根据项目规模调整文档详略(如小型项目可精简,大型系统需详细架构设计)。 A的反例 -
为什么选项A错误?
-
一刀切的弊端:
- 小型脚本项目无需详细需求文档,而航天软件需严格遵循DO-178C文档标准。
-
反例:
-
创业公司MVP:仅需1页功能说明。
-
银行核心系统:需200页安全合规文档。
-
-
🧪 题目35:软件测试基础知识 - 测试阶段与错误发现能力
某财务系统的一个组件中,某个变量没有正确初始化, (35) 最可能发现该错误。
(35)
A. 单元测试 ✅
B. 集成测试
C. 接受测试
D. 安装测试
📌 正确答案:A
🔍 详细解析
- 变量未初始化错误的特性
-
错误类型:属于代码级缺陷(如
int x;未赋初值直接使用)。 -
最佳发现阶段:在 单元测试 中通过白盒测试(如语句覆盖)直接验证函数内部逻辑。
-
各测试阶段的对比
测试阶段 测试目标 发现此类错误的能力 示例 单元测试 验证单个函数/类的正确性 ⭐⭐⭐⭐⭐ 最强 assert(calculate_tax() == 0)集成测试 检查模块间交互 ⭐⭐ 数据库连接是否正常 接受测试 验证系统是否满足用户需求 ⭐ 财务报表生成功能是否完整 安装测试 确保软件在目标环境正常运行 ⭐ 安装包是否兼容Windows 11 -
为什么单元测试最有效?
-
精准定位:直接测试函数内部变量状态(如使用调试器检查内存)。
-
快速反馈:在开发早期即可发现,修复成本低。
-
工具支持:
- JUnit(Java)、pytest(Python)可编写针对性测试用例
-
🛠️ 题目36:系统运行和维护基础知识 - 软件维护类型辨析
软件交付给用户之后进入维护阶段,根据维护具体内容的不同将维护分为不同的类型,其中“采用专用的程序模块对文件或数据中的记录进行增加、修改和删除等操作”的维护属于 (36) 。
(36)
A. 程序维护
B. 数据维护 ✅
C. 代码维护
D. 设备维护
📌 正确答案:B
🔍 详细解析
维护类型分类
| 维护类型 | 定义 | 典型场景 |
|---|---|---|
| 数据维护 | 对数据库、文件中的记录进行增删改查(CRUD)操作,不涉及代码逻辑修改。 | 用户信息更新、日志数据清理 |
| 程序维护 | 修复代码缺陷或优化性能(需修改源代码)。 | Bug修复、算法优化 |
| 代码维护 | 广义同程序维护,通常特指重构或技术债务清理。 | 代码重构、依赖库升级 |
| 设备维护 | 硬件或系统环境维护(如服务器扩容、网络配置)。 | 更换数据库服务器、升级操作系统 |
三、 面向对象基础知识 🧩
🦆 题目37-38:面向对象 - 面向对象设计概念辨析
采用面向对象方法进行某游戏设计,游戏中有野鸭、红头鸭等各种鸭子边游泳戏水边呱呱叫,不同种类的鸭子具有不同颜色,设计鸭子类负责呱呱叫和游泳方法的实现,显示颜色设计为抽象方法,由野鸭和红头鸭各自具体实现,这一机制称为 (37) 。当给这些类型的一组不同对象发送同一显示颜色消息时,能实现各自显示自己不同颜色的结果,这种现象称为 (38) 。
(37)
A. 继承 ✅
B. 聚合
C. 组合
D. 多态
(38)
A. 覆盖
B. 重载
C. 动态绑定
D. 多态✅
📌 正确答案:(37)A、(38)D
🔍 详细解析
-
继承(Inheritance):
- 父类(Duck)提供通用方法(游泳、呱呱叫),子类(WildDuck、RedHeadDuck)通过继承父类并实现抽象方法(颜色)扩展功能。
-
排除其他选项:
-
聚合/组合:描述对象间“拥有”关系(如鸭子拥有翅膀),与题目无关。
-
多态:是下一问的机制,此处强调代码复用和扩展。
-
-
多态(Polymorphism):
- 同一消息(showColor())引发不同行为(野鸭显示绿色,红头鸭显示红色),通过子类重写父类抽象方法实现。
-
关键机制:
-
动态绑定(C选项)是多态的实现技术,但题目问现象名称,非底层原理。
-
覆盖(A选项)是多态的实现手段,非现象本身。
-
💡 代码实现
abstract class Duck {
public void swim() {
System.out.println("Swimming");
} // 继承的通用方法
public abstract void showColor(); // 抽象方法
}
class WildDuck extends Duck {
@Override
public void showColor() {
System.out.println("Green");
} // 多态的具体实现
}
class RedHeadDuck extends Duck {
@Override
public void showColor() {
System.out.println("Red");
} // 多态的具体实现
}
// 测试多态
public class Main {
public static void main(String[] args) {
Duck duck1 = new WildDuck();
Duck duck2 = new RedHeadDuck();
duck1.showColor(); // 输出 "Green"(动态绑定到WildDuck实现)
duck2.showColor(); // 输出 "Red" (动态绑定到RedHeadDuck实现)
}
}
🧩 题目39:面向对象 - 面向对象分析中的对象认定
采用面向对象方法分析时,首先要在应用领域中按自然存在的实体认定对象,即将自然存在的 (39) 作为一个对象。
(39)
A. 问题
B. 关系
C. 名词 ✅
D. 动词
📌 正确答案:C
🔍 详细解析
-
面向对象分析(OOA)的核心原则
-
对象认定:从问题域中识别 自然存在的实体,通常对应现实世界的 名词(如“学生”“订单”“账户”)。
-
示例:
- 电商系统:商品、购物车、用户。
-
-
选项逐项分析
选项 是否对象 说明 A. 问题 ❌ 问题是待解决的抽象概念(如“支付失败”),需拆解为具体对象(如“支付订单”)。 B. 关系 ❌ 关系是对象间的交互(如“用户购买商品”),通过方法或关联类实现。 C. 名词 ✅ 名词直接映射为对象(如“飞机”“航班”)。 D. 动词 ❌ 动词通常映射为对象的方法(如“飞行”是“飞机”类的方法)。
🧩 题目40:面向对象 - 面向对象设计原则辨析
进行面向对象系统设计时,修改某个类的原因有且只有一个,即一个类只做一种类型的功能,这属于 (40) 原则。
(40)
A. 单一责任 ✅
B. 开放-封闭
C. 接口分离
D. 依赖倒置
📌 正确答案:A
🔍 详细解析
-
单一责任原则(SRP)
-
定义:一个类应该有且仅有一个引起它变化的原因(即只负责一项功能)。
-
题目匹配:
- “修改类的原因有且只有一个” → 直接对应SRP核心思想。
-
示例:
// 违反SRP:同时处理订单计算和日志记录 class OrderProcessor { void calculateTotal() { ... } void logTransaction() { ... } // 应拆分到Logger类 } // 符合SRP class OrderCalculator { void calculateTotal() { ... } } class TransactionLogger { void log() { ... } } -
-
其他原则对比
原则 核心思想 题目关联性 开放-封闭 对扩展开放,对修改封闭 ❌ 无关类职责数量 接口分离 客户端不应依赖不需要的接口 ❌ 聚焦接口而非类职责 依赖倒置 依赖抽象而非具体实现 ❌ 关注耦合方向
🏗️ 题目41-42:面向对象 - UML活动图解析
UML 活动图用于建模 (41) 。以下活动图中,活动 A1 之后,可能的活动执行序列顺序是 (42) 。
(41)
A. 系统在它的周边环境的语境中所提供的外部可见服务
B. 某一时刻一组对象以及它们之间的关系
C. 系统内从一个活动到另一个活动的流程 ✅
D. 对象的生命周期中某个条件或者状态
(42)
A. A2、A3、A4和A5
B. A3、A4和A5,或A2、A4或A5
C. A2、A4和A5
D. A2或A3、A4和A5 ✅
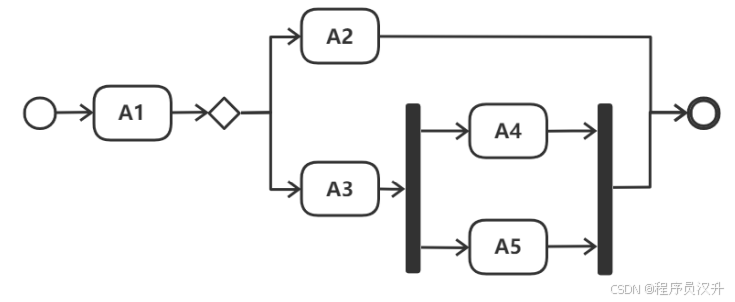
📌 正确答案:(41)D、(42)B
🔍 详细解析
-
活动图(Activity Diagram):描述系统内 活动的顺序流程(如业务流程、算法步骤),聚焦动态行为。
-
对比其他选项:
-
A:用例图的用途(描述系统功能)。
-
B:类图或对象图的用途(静态结构)。
-
D:状态图的用途(对象状态变迁)。
-
-
活动图逻辑:
-
A1完成后,通常通过 分支(Decision Node) 或 并行(Fork) 决定后续路径。
-
题目未明确分支条件,但选项中 A2和A3是互斥选择(“或”关系),A4和A5是共同后续。
-
-
合理序列:
-
A1 → A2 → A4 → A5
-
A1 → A3 → A4 → A5
-
-
排除其他选项:
-
A:A2和A3不会同时执行。
-
B:缺少A2→A4→A5的完整路径。
-
C:遗漏A3的可能性。
-
🏗️ 题目43:面向对象 - UML构件图的特性
UML构件图(component diagram)展现了一组构件之间的组织和依赖,专注于系统的静态 (43) 图,图中通常包括构件、接口以及各种关系。
(43)
A. 关联
B. 实现
C. 结构 ✅
D. 行为
📌 正确答案:C
🔍 详细解析
-
核心用途:描述系统的 静态结构,展示构件(如模块、库、可执行文件)及其依赖关系。
-
关键元素:
-
构件(Component):如PaymentService.dll。
-
接口(Interface):如IPaymentProcessor。
-
关系:依赖(虚线箭头)、实现(实线空心三角)。
-
-
静态 vs 动态:
-
结构图(如类图、构件图):展示系统组成部分及其关系。
-
行为图(如活动图、状态图):展示系统动态交互。
-
-
题目关键词:“静态” + “组织和依赖” → 明确指向结构。
🏗️ 题目44-46:设计模式 - 设计模式辨析
在某系统中,不同级别的日志信息记录方式不同,每个级别的日志处理对象根据信息级别高低,采用不同方式进行记录。每个日志处理对象检查消息的级别,如果达到它的级别则进行记录,否则不记录;然后将消息传递给它的下一个日志处理对象。针对此需求,设计如下所示类图。该设计模式采用 (44) 模式使多个前后连接的对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。该模式属于(45)模式,该模式适用于(46)。
(44)
A. 责任链(Chain of Responsibility) ✅
B. 策略(Strategy)
C. 过滤器(Filter)
D. 备忘录(Memento)
(45)
A. 行为型类
B. 行为型对象 ✅
C. 结构型类
D. 结构型对象
(46)
A. 不同的标准过滤一组对象,并通过逻辑操作以解耦的方式将它们链接起来
B. 可处理一个请求的对象集合应被动态指定✅
C. 必须保存一个对象在某一个时刻的状态,需要时它才能恢复到先前的状态
D. 一个类定义了多种行为,并且以多个条件语句的形式出现
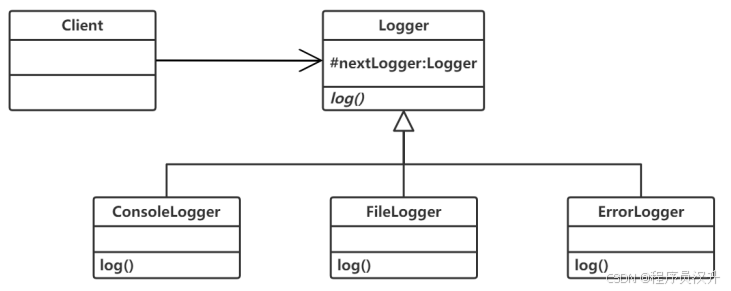
📌 正确答案:(44)A、(45)B、(46)B
🔍 详细解析
23种设计模型详细解释见文章《软考中级-软件设计师 23种设计模式》
-
责任链模式:
-
核心思想:多个处理器对象(如ConsoleLogger、FileLogger)按链式顺序处理请求,每个对象决定处理或传递请求。
-
题目匹配:日志对象根据级别决定是否记录,并传递给nextLogger,完全符合责任链。
-
-
排除其他选项:
-
策略模式:动态切换算法(如排序策略),无链式传递。
-
过滤器模式:筛选数据集合,非请求处理流程。
-
备忘录模式:保存/恢复对象状态(如撤销操作)。
-
-
行为型对象模式:
- 责任链模式属于 行为型模式(关注对象间交互与职责分配),且通过对象组合(如nextLogger引用)实现,非类继承。
-
责任链适用场景:
-
需动态指定处理对象链(如日志级别变化时增减处理器)。
-
解耦请求发送者与接收者(如客户端无需知道具体哪个Logger处理请求)。
-
-
选项匹配:
-
B直接描述动态链式处理,是责任链的经典场景。
-
A描述过滤器模式,C描述备忘录模式,D描述状态模式或策略模式。
-
🚗 题目47:设计模式 - 设计模式应用场景
驱动新能源汽车的发动机时,电能和光能汽车分别采用不同驱动方法,而客户端希望使用统一的驱动方法,需定义一个统一的驱动接口屏蔽不同的驱动方法,该要求适合采用 (47) 模式。
(47)
A. 中介者(Mediator)
B. 访问者(Visitor)
C. 观察者(Observer)
D. 适配器(Adapter) ✅
📌 正确答案:D
🔍 详细解析
适配器模式详细解释见文章《23种设计模式-适配器(Adapter)设计模式》
-
适配器模式的核心思想
-
定义:将一个类的接口转换成客户端期望的另一个接口,使原本不兼容的类能协同工作。
-
题目匹配:
-
电能/光能驱动方法不同 → 需通过适配器统一为**drive()**接口。
-
屏蔽差异:客户端无需关心具体能源类型,调用统一接口即可。
-
-
-
代码示例
// 统一驱动接口 interface EngineDriver { void drive(); } // 电能驱动适配器 class ElectricEngineAdapter implements EngineDriver { private ElectricEngine engine; public void drive() { engine.powerOn(); } // 调用电能专用方法 } // 光能驱动适配器 class SolarEngineAdapter implements EngineDriver { private SolarEngine engine; public void drive() { engine.absorbLight(); } // 调用光能专用方法 } // 客户端调用 EngineDriver driver = new ElectricEngineAdapter(); driver.drive(); // 统一接口,屏蔽实现差异 -
排除其他选项
| 模式 | 用途 | 不适用原因 |
|---|---|---|
| 中介者 | 减少对象间直接耦合(通过中介通信) | 题目无需协调多个对象交互。 |
| 访问者 | 分离算法与数据结构 | 与接口转换无关。 |
| 观察者 | 一对多的依赖通知(如事件监听) | 不涉及事件发布-订阅场景。 |
四、 网络与信息安全知识 🌐
🔐 题目7:信息安全技术 - 认证方式安全性对比
下列认证方式安全性较低的是 (7) 。
(7)
A. 生物认证
B. 多因子认证
C. 口令认证 ✅
D. U盾认证
📌 正确答案:C
🔍 详细解析
不同认证方式的安全性对比如下:
| 认证方式 | 安全性 | 特点 |
|---|---|---|
| 口令认证 | ⭐ | 纯文本或简单加密,易被暴力破解、钓鱼、键盘记录等手段攻破。 |
| 生物认证 | ⭐⭐⭐ | 基于指纹/虹膜等生物特征,难以复制但存在隐私泄露风险。 |
| U盾认证 | ⭐⭐⭐⭐ | 物理硬件密钥(如数字证书),需物理接触,防中间人攻击。 |
| 多因子认证 | ⭐⭐⭐⭐⭐ | 结合两种以上方式(如口令+短信验证码),大幅提升破解难度。 |
💡 关键结论
-
口令认证(C)是安全性最低的:
-
单一因素,易受社会工程学攻击(如弱密码、重复使用密码)。
-
例如:123456、password 等常见弱口令。
-
-
其他选项的高安全性体现:
-
生物认证(A):生物特征唯一但可能被伪造(如高精度指纹模型)。
-
U盾认证(D):硬件绑定,需物理持有(如银行U盾)。
-
多因子认证(B):综合“你知道的(密码)+ 你拥有的(手机)+ 你独有的(指纹)”因素。
-
🚀 扩展知识
-
双因子认证(2FA):
-
常见组合:密码 + 短信验证码/OTP(动态口令)。
-
漏洞:SIM卡劫持可能导致短信验证码被截获。
-
-
零信任架构:
- 默认不信任任何设备/用户,持续验证(如每次操作需重新认证)。
GitHub就是双因子认证(2FA)
🔐 题目8-9:信息安全技术 - 数字证书密码算法标准对比
X.509 数字证书标准推荐使用的密码算法是 (8) ,而国密 SM2 数字证书采用的公钥密码算法是 (9) 。
(8)
A. RSA ✅
B. DES
C. AES
D. ECC(9)
A. RSA
B. DES
C. AES
D. ECC ✅
📌 正确答案:(8)A、(9)D
🔍 详细解析
-
X.509 数字证书标准(国际标准)
-
传统主流算法:RSA
-
修正原因:
-
虽然ECC是未来趋势且被新版X.509推荐,但题目问的是"推荐使用"而非"最新推荐"。
-
RSA仍是实际部署最广泛的算法(兼容性最强,历史应用最多)。
-
原解析混淆了"推荐"和"最新趋势",需尊重题目表述的客观现状。
-
-
-
-
国密 SM2 数字证书(中国标准)
-
公钥算法:ECC(基于 SM2 椭圆曲线)
-
原因:
-
SM2 是国密局发布的 ECC 实现,专为国产密码体系设计,安全性优于 RSA。
-
符合中国商用密码应用要求(如金融、政务系统)。
-
-
其他选项:
-
A. RSA:非国密算法,不符合 SM2 标准。
-
B. DES/C. AES:对称算法,不用于证书公钥体系。
-
-
-
💡 知识点对比
| 场景 | RSA优势 | ECC优势 |
|---|---|---|
| X.509证书 | 兼容所有老旧系统 | 更适合移动端和现代TLS(如HTTP/2) |
| 密钥长度 | 2048位起步 | 256位即等效安全 |
| 中国商用场景 | 需配合国密算法改造 | 直接采用SM2 |
🛡️ 题目10:网络安全技术 - 网络安全防护设备选择
某单位网站首页被恶意篡改,应部署 (10) 设备阻止恶意攻击。
(10)
A. 数据库审计
B. 包过滤防火墙
C. Web 应用防火墙 ✅
D. 入侵检测
📌 正确答案:C
🔍 详细解析
-
Web应用防火墙(WAF)的核心作用
-
针对性防护:专门防御Web层攻击(如SQL注入、XSS、网页篡改等),直接保护网站首页安全。
-
工作原理:深度解析HTTP/HTTPS流量,通过规则库实时阻断恶意请求。
-
-
其他选项不适用原因
选项 局限性 A. 数据库审计 仅记录数据库操作,无法阻止前端攻击(审计是事后行为)。 B. 包过滤防火墙 仅检查IP/端口,无法识别应用层攻击(如篡改首页的HTTP请求)。 D. 入侵检测 IDS只报警不阻断,且通常针对网络层攻击(如DDoS),对网页篡改防护不足。
🛡️ 题目11:网络安全技术 - 漏洞扫描系统的作用
使用漏洞扫描系统对信息系统和服务器进行定期扫描可以 (11) 。
(11)
A. 发现高危风险和安全漏洞 ✅
B. 修复高危风险和安全漏洞
C. 获取系统受攻击的日志信息
D. 关闭非必要的网络端口和服务
📌 正确答案:A
🔍 详细解析
-
漏洞扫描系统的核心功能
-
主动发现风险:通过模拟攻击行为,检测系统中存在的漏洞(如未打补丁的服务、弱密码配置等)。
-
输出扫描报告:生成漏洞清单(包括CVE编号、风险等级、受影响组件等)。
-
-
其他选项的局限性
选项 问题分析 B. 修复漏洞 漏洞扫描系统仅提供检测结果,修复需人工或专用补丁管理工具完成。 C. 获取攻击日志 日志分析需依赖SIEM或IDS系统,漏洞扫描不直接获取历史攻击记录。 D. 关闭端口/服务 端口管理需通过防火墙或系统配置,扫描系统无主动操作权限。
五、 标准化、信息化和知识产权基础知识 🛠️
📜 题目12:知识产权 - 委托开发软件的著作权归属
以下关于某委托开发软件的著作权归属的叙述中,正确的是 (12) 。
(12)
A. 该软件的著作权归属仅依据委托人与受托人在书面合同中的约定来确定
B. 无论是否有合同约定,该软件的著作权都由委托人和受托人共同享有
C. 若无书面合同或合同中未明确约定,则该软件的著作权由受托人享有 ✅
D. 若无书面合同或合同中未明确约定,则该软件的著作权由委托人享有
📌 正确答案:C
🔍 详细解析
-
法律依据(《计算机软件保护条例》第11条)
-
有合同约定:著作权归属按合同约定执行(优先尊重双方意思自治)。
-
无合同或约定不明:著作权默认归属 受托人(实际开发者)。
-
-
选项逐项分析
选项 正误 说明 A ❌ "仅依据合同"错误,合同未约定时依法定规则(归受托人)。 B ❌ 共同享有需明确约定,非法定默认情况。 C ✅ 完全符合法律规定,是默认情形。 D ❌ 委托人仅享有使用权,非著作权(除非合同明确转让)。
💡 关键结论
-
委托开发 ≠ 职务开发:
- 职务作品著作权默认归单位,但委托作品默认归受托方。
-
委托人权利:
- 可免费使用软件(除非合同限制),但不能未经许可修改或转售。
📌 实际应用案例
-
场景1:甲方委托乙方开发APP但未签合同 → 乙方保留著作权,甲方需获授权使用。
-
场景2:合同约定“著作权归甲方” → 需明确转让条款,乙方后续无权主张权利。
📜 题目13:知识产权 - 软件著作权中的翻译权定义
《计算机软件保护条例》第八条第一款第八项规定的软件著作权中的翻译权是将原软件由 (13) 的权利。
(13)
A. 源程序语言转换成目标程序语言
B. 一种程序设计语言转换成另一种程序设计语言
C. 一种汇编语言转换成一种自然语言
D. 一种自然语言文字转换成另一种自然语言文字 ✅
📌 正确答案:D
🔍 详细解析
-
法律条文依据
根据《计算机软件保护条例》第八条:软件著作权人享有下列各项权利:
……
(八)翻译权,即将原软件从一种自然语言文字转换成另一种自然语言文字的权利。 -
翻译权的核心定义
-
仅适用于自然语言:如将英文用户手册翻译为中文,或将日文注释转换为法文。
-
不涵盖编程语言转换:
-
源程序→目标程序(选项A)属于编译过程,非著作权法意义的翻译。
-
编程语言间的转换(如Python→C,选项B)属于代码重写或移植。
-
-
-
排除其他选项的理由
选项 错误原因 A 描述的是编译器功能(如C→机器码),与著作权无关。 B 编程语言转换可能涉及重新创作,但非《条例》定义的翻译权范畴。 C 汇编语言→自然语言属于反汇编或注释行为,非翻译权覆盖内容。
💡 实际应用场景
-
合法行为:将软件的英文说明书翻译为德文需著作权人授权。
-
侵权行为:未经许可将中文UI界面文字翻译为俄文并发布。
📜 题目14:知识产权 - 知识产权权利辨析
M 公司将其开发的某软件产品注册商标为 S,为确保公司在市场竞争中占据优势地位,M 公司对员工进行了保密约束,此情形下,该公司不享有 (14) 。
(14)
A. 软件著作权
B. 专利权 ✅
C. 商业秘密权
D. 商标权
📌 正确答案:B
🔍 详细解析
-
题目情境分析
-
注册商标:说明公司拥有商标权(选项D)。
-
保密约束:表明公司主张商业秘密权(选项C)。
-
开发软件:默认享有软件著作权(选项A)。
-
未提及:专利申请或技术方案公开(影响专利权)。
-
-
专利权缺失的原因
-
需主动申请:专利权必须向国家知识产权局申请,经审查授权后方可获得。
-
题目未体现:
-
未描述软件包含技术创新(如算法专利)。
-
保密措施可能阻碍专利授权(专利需公开技术方案)。
-
-
-
其他权利明确归属
权利 获得方式 题目依据 软件著作权 自动产生(开发完成即享有) “开发的某软件产品” 商标权 注册核准 “注册商标为 S” 商业秘密权 保密措施+商业价值 “对员工进行保密约束”
六、 计算机英语 🐧
🐧题目71-75:计算机英语
We initially described SOA without mentioning Web services, and vice versa. This is because they are orthogonal: service-orientation is an architectural (71) , while Web services are an implementation (72) . The two can be used together, and they frequently are, but they are not mutually dependent.
For example, although it is widely considered to be a distributed-computing solution, SOA can be applied to advantage in a single system, where services might be individual processes with welldefined (73) that communicate using local channels, or in self-contained cluster, where they might communicate across a high-speed interconnect.
Similarly, while Web services are (74) asthe basisfor a service-oriented environment, there is nothing in their definition that requires them to embody the SOA principles. While (75) is often held up as a key characteristic of Web services, there is no technical reason that they should be stateless—that would be a design choice of the developer, which may be dictated by the architectural style of the environment in which the service is intended to participate.
(71)
A. design
B. style ✅
C. technology
D. structure
(72)
A. structure
B. style
C. technology ✅
D. method
(73)
A. interfaces ✅
B. functions
C. logiccs
D. formats
(74)
A. regarded
B. well-suited ✅
C. worked
D. used
(75)
A. distribution
B. interconnection
C. dependence
D. statelessness✅
📌 正确答案:(71)B,(72)C,(73)A,(74)B,(75)D
参考译文:
我们最初描述 SOA 时没有提到 Web 服务,反之亦然。这是因为它们是正交的:面向服务是一种架构风格,而 Web 服务是一种实现技术。两者可以一起使用,而且它们经常是,但它们并不相互依赖。
例如,尽管 SOA 被广泛认为是一种分布式计算解决方案,但它可以应用于单个系统中,其中服务可能是具有明确定义的接口的单个进程,使用本地通道进行通信,或者在自包含集群中,它们可能通过高速互连进行通信。
类似地,尽管 Web 服务非常适合作为面向服务的环境的基础,但它们的定义中没有任何东西要求它们体现 SOA 原则。虽然无状态通常被认为是 Web 服务的一个关键特征,但从技术上讲,它们没有理由应该是无状态的——这将是开发人员的设计选择,这可能由服务打算参与的环境的架构风格决定。

码字不易,写完发现4万多字。如果有收获不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️


















 2638
2638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









