







ShardingSphere保姆级教程
前言
最近公司项目中,有些日志表,操作表等数据量比较大,接入shardingsphere来实现了分库分表,并且在线上顺利运行一段时间了。项目在接入shardingsphere以后,对shardingsphere的源码有些兴趣,在工作之余花了一些时间去阅读shardingsphere官网的文档,并且根据文档进行了shardingsphere源码的阅读。该文章基于5.1.1的版本的shardingsphere。
前期准备:
在读这篇文章之前,首先可以学习一下shardingsphere的官方文档:
https://shardingsphere.apache.org/document/5.1.1/cn/shardingsphere_docs_cn.pdf
shardingsphere的源码,可以fork到自己本地仓库进行学习:
https://github.com/apache/shardingsphere
第一章节demo代码及数据库SQL脚本在:GitHub
第二章节源码所有的注释在:GitHub
肝了五天,近十万字,终于写完了,有错误欢迎交流!
一、ShardingSphere怎么用?
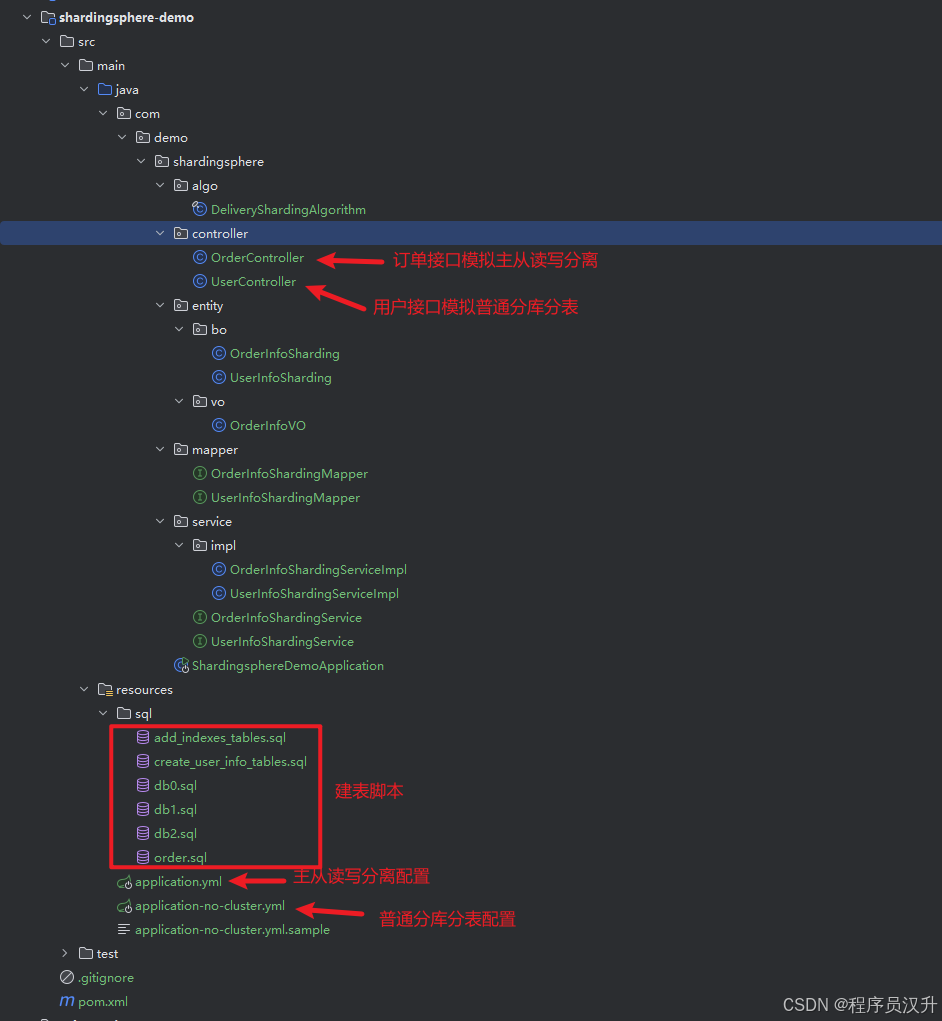
demo的目录结构:
首先,我们先接入ShardingSphere,在pom文件导入下面依赖,ShardingSphere版本使用5.1.1,连接池的版本需要在8.x以上
<dependencies>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
</dependency>
<!--访问mysql-->
<!--JDBC-->
<!-- MySql 8.0 Connector -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<!-- shardingSphere-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
</dependencies>
1.1 ShardingSphere普通用法
1.1.1 applicaiton.yml配置文件解读
接下来我们看看普通用法的核心配置文件:
server:
port: 25000
spring:
# sharding-jdbc配置
shardingsphere:
# 是否开启SQL显示
props:
sql:
show: true
# ====================== 数据源配置 ======================
datasource:
names: db0,db1,db2
db0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db0?serverTimezone=Asia/Shanghai&useSSL=false&zeroDateTimeBehavior=convertToNull&characterEncoding=utf-8
username: root
password: 123456
maximum-pool-size: 3
minimum-idle: 1
db1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db1?serverTimezone=Asia/Shanghai&useSSL=false&zeroDateTimeBehavior=convertToNull&characterEncoding=utf-8
username: root
password: 123456
maximum-pool-size: 3
minimum-idle: 1
db2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db2?serverTimezone=Asia/Shanghai&useSSL=false&zeroDateTimeBehavior=convertToNull&characterEncoding=utf-8
username: root
password: 123456
maximum-pool-size: 3
minimum-idle: 1
rules:
sharding:
tables:
# 分表规则:在使用 ShardingSphere 时,
# t_user_info 是一个逻辑表(logical table),它本身并不真实存在于某一个数据库中,而是由多张 实际表(physical table) 组成。
# ShardingSphere 会帮你把对逻辑表的操作自动映射到实际表上。
# 比如将t_user_info数据映射到下面表中:
# db0.user_info_0 ~ db0.user_info_19
# db1.user_info_0 ~ db1.user_info_19
# db2.user_info_0 ~ db2.user_info_19
t_user_info:
actual-data-nodes: db$->{0..2}.user_info_$->{0..19}
# 分库规则:根据 user_id 的值,将数据存储到不同的数据库中
database-strategy:
standard:
sharding-column: user_id
# 分库算法
sharding-algorithm-name: database-inline-user-id
# 分表规则:根据 user_id 的值,将数据存储到不同的表中
table-strategy:
standard:
sharding-column: user_id
# 分表算法
sharding-algorithm-name: t-inline
# 主键生成策略:根据 id 的值,生成主键,默认使用雪花算法
key-generate-strategy:
column: id
sharding-algorithms:
# 分库算法
database-inline-user-id:
type: INLINE
props:
algorithm-expression: db$->{user_id % 3}
# 分表算法
t-inline:
type: INLINE
props:
algorithm-expression: user_info_$->{user_id % 20}
上面application.yml配置文件中,主要配置了数据源,库表的分片键,分片策略等规则,下面来详细说说:
-
🛠 基础配置
server: port: 25000📌 启动端口设置为 25000,是整个应用的入口监听端口。
-
🌱 Spring ShardingSphere 配置总览
spring: shardingsphere: props: sql: show: truesql.show: true表示开启 SQL 打印,用于在控制台中输出最终执行的 SQL,便于调试。
-
💾 数据源配置(三个库)
spring: shardingsphere: datasource: names: db0,db1,db2ShardingSphere 支持多个数据源,这里声明了三个数据源名称:
-
db0
-
db1
-
db2
每个数据源的配置如下:
db0: type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.cj.jdbc.Driver jdbc-url: jdbc:mysql://localhost:3306/db0... username: root password: 123456 maximum-pool-size: 3 minimum-idle: 1使用 HikariCP 作为连接池,轻量高效,适用于高并发场景。每个库连接池最大连接数为 3,最小空闲连接数为 1。
-
-
🧩 分库分表配置规则
rules: sharding: tables: t_user_info: actual-data-nodes: db$->{0..2}.user_info_$->{0..19}🎯 逻辑表定义
t_user_info是一个逻辑表,实际映射到了如下数据节点上:-
db0.user_info_0 ~ db0.user_info_19
-
db1.user_info_0 ~ db1.user_info_19
-
db2.user_info_0 ~ db2.user_info_19
共计:3 库 × 20 表 = 60 张实际表
-
-
🧭 分库策略(Database Strategy)
database-strategy: standard: sharding-column: user_id sharding-algorithm-name: database-inline-user-id按照
user_id字段取模进行分库。分库算法如下:sharding-algorithms: database-inline-user-id: type: INLINE props: algorithm-expression: db$->{user_id % 3}user_id % 3的结果分别为0, 1, 2,分别对应db0, db1, db2
-
🧱 分表策略(Table Strategy)
table-strategy: standard: sharding-column: user_id sharding-algorithm-name: t-inline同样根据
user_id进行分表,分表算法如下:sharding-algorithms: t-inline: type: INLINE props: algorithm-expression: user_info_$->{user_id % 20}- 将数据分散到
user_info_0 ~ user_info_19共 20 张表中
- 将数据分散到
-
🔑 主键生成策略
key-generate-strategy: column: id默认采用 雪花算法(Snowflake) 自动生成全局唯一 ID,无需依赖数据库自增,适合分布式环境。
-
✅ 总结
类型 策略说明 分库 根据 user_id % 3,映射到db0~db2分表 根据 user_id % 20,映射到user_info_0~user_info_19主键 自动生成,雪花算法 SQL 显示 开启,便于调试和观察执行 SQL
1.1.2 实体类及建表语句
-
实体类如下:
@Data @TableName("t_user_info") public class UserInfoSharding { /** * 主键id */ @TableId(value = "id", type = IdType.AUTO) private Long id; /** * 用户id */ private Long userId; /** * 用户名 */ private String userName; /** * 用户年龄 */ private Integer userAge; /** * 用户性别 */ private String userSex; /** * 用户手机号 */ private String userPhone; /** * 用户邮箱 */ private String userEmail; /** * 用户地址 */ private String userAddress; /** * 最后查看时间 */ @TableField("view_time") private LocalDateTime viewTime; /** * 创建时间 */ private LocalDateTime createTime; /** * 更新时间 */ private LocalDateTime updateTime; }本demo采用的是mybatisplus进行数据库操作,
@TableName("t_user_info")映射的是逻辑表,ShardingSphere 会帮你把对逻辑表的操作自动映射到实际表上。 -
sql脚本
-- 切换到 db0 USE db0; -- 创建表 user_info_0 到 user_info_19 DELIMITER $$ BEGIN DECLARE i INT DEFAULT 0; WHILE i < 20 DO SET @sql = CONCAT('CREATE TABLE IF NOT EXISTS user_info_', i, ' ( id BIGINT NOT NULL AUTO_INCREMENT COMMENT ''主键id'', user_id BIGINT DEFAULT NULL COMMENT ''用户id'', user_name VARCHAR(100) DEFAULT NULL COMMENT ''用户名'', user_age INT DEFAULT NULL COMMENT ''用户年龄'', user_sex VARCHAR(10) DEFAULT NULL COMMENT ''用户性别'', user_phone VARCHAR(20) DEFAULT NULL COMMENT ''用户手机号'', user_email VARCHAR(100) DEFAULT NULL COMMENT ''用户邮箱'', user_address VARCHAR(255) DEFAULT NULL COMMENT ''用户地址'', view_time DATETIME DEFAULT NULL COMMENT ''最后查看时间'', create_time DATETIME DEFAULT NULL COMMENT ''创建时间'', update_time DATETIME DEFAULT NULL COMMENT ''更新时间'', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT=''用户信息分表'''); PREPARE stmt FROM @sql; EXECUTE stmt; DEALLOCATE PREPARE stmt; SET i = i + 1; END WHILE; END$$ DELIMITER ; db1.sql-- 切换到 db1 USE db1; -- 创建表 user_info_0 到 user_info_19 DELIMITER $$ BEGIN DECLARE i INT DEFAULT 0; WHILE i < 20 DO SET @sql = CONCAT('CREATE TABLE IF NOT EXISTS user_info_', i, ' ( id BIGINT NOT NULL AUTO_INCREMENT COMMENT ''主键id'', user_id BIGINT DEFAULT NULL COMMENT ''用户id'', user_name VARCHAR(100) DEFAULT NULL COMMENT ''用户名'', user_age INT DEFAULT NULL COMMENT ''用户年龄'', user_sex VARCHAR(10) DEFAULT NULL COMMENT ''用户性别'', user_phone VARCHAR(20) DEFAULT NULL COMMENT ''用户手机号'', user_email VARCHAR(100) DEFAULT NULL COMMENT ''用户邮箱'', user_address VARCHAR(255) DEFAULT NULL COMMENT ''用户地址'', view_time DATETIME DEFAULT NULL COMMENT ''最后查看时间'', create_time DATETIME DEFAULT NULL COMMENT ''创建时间'', update_time DATETIME DEFAULT NULL COMMENT ''更新时间'', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT=''用户信息分表'''); PREPARE stmt FROM @sql; EXECUTE stmt; DEALLOCATE PREPARE stmt; SET i = i + 1; END WHILE; END$$ DELIMITER ; -- 切换到 db2 USE db2; -- 创建表 user_info_0 到 user_info_19 DELIMITER $$ BEGIN DECLARE i INT DEFAULT 0; WHILE i < 20 DO SET @sql = CONCAT('CREATE TABLE IF NOT EXISTS user_info_', i, ' ( id BIGINT NOT NULL AUTO_INCREMENT COMMENT ''主键id'', user_id BIGINT DEFAULT NULL COMMENT ''用户id'', user_name VARCHAR(100) DEFAULT NULL COMMENT ''用户名'', user_age INT DEFAULT NULL COMMENT ''用户年龄'', user_sex VARCHAR(10) DEFAULT NULL COMMENT ''用户性别'', user_phone VARCHAR(20) DEFAULT NULL COMMENT ''用户手机号'', user_email VARCHAR(100) DEFAULT NULL COMMENT ''用户邮箱'', user_address VARCHAR(255) DEFAULT NULL COMMENT ''用户地址'', view_time DATETIME DEFAULT NULL COMMENT ''最后查看时间'', create_time DATETIME DEFAULT NULL COMMENT ''创建时间'', update_time DATETIME DEFAULT NULL COMMENT ''更新时间'', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT=''用户信息分表'''); PREPARE stmt FROM @sql; EXECUTE stmt; DEALLOCATE PREPARE stmt; SET i = i + 1; END WHILE; END$$ DELIMITER ; -
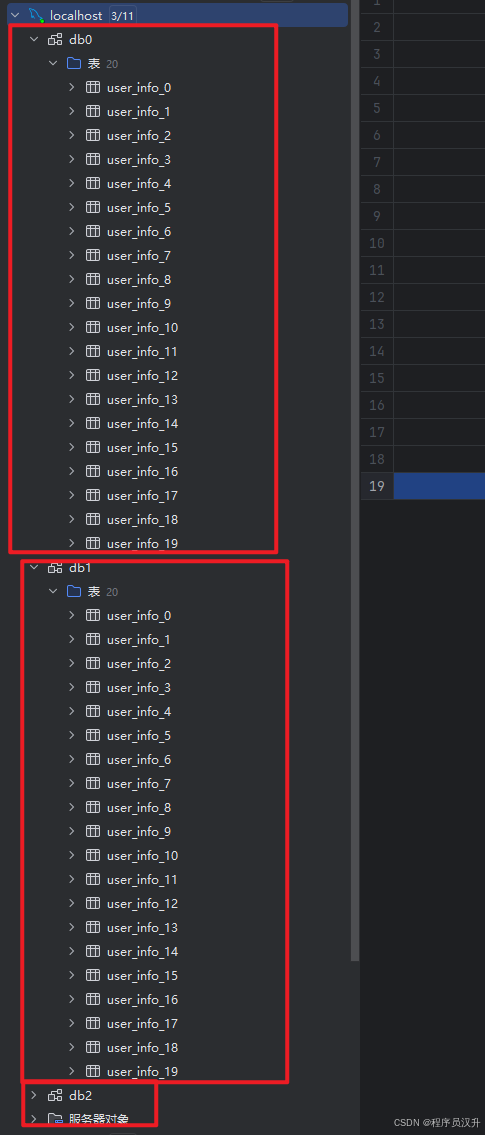
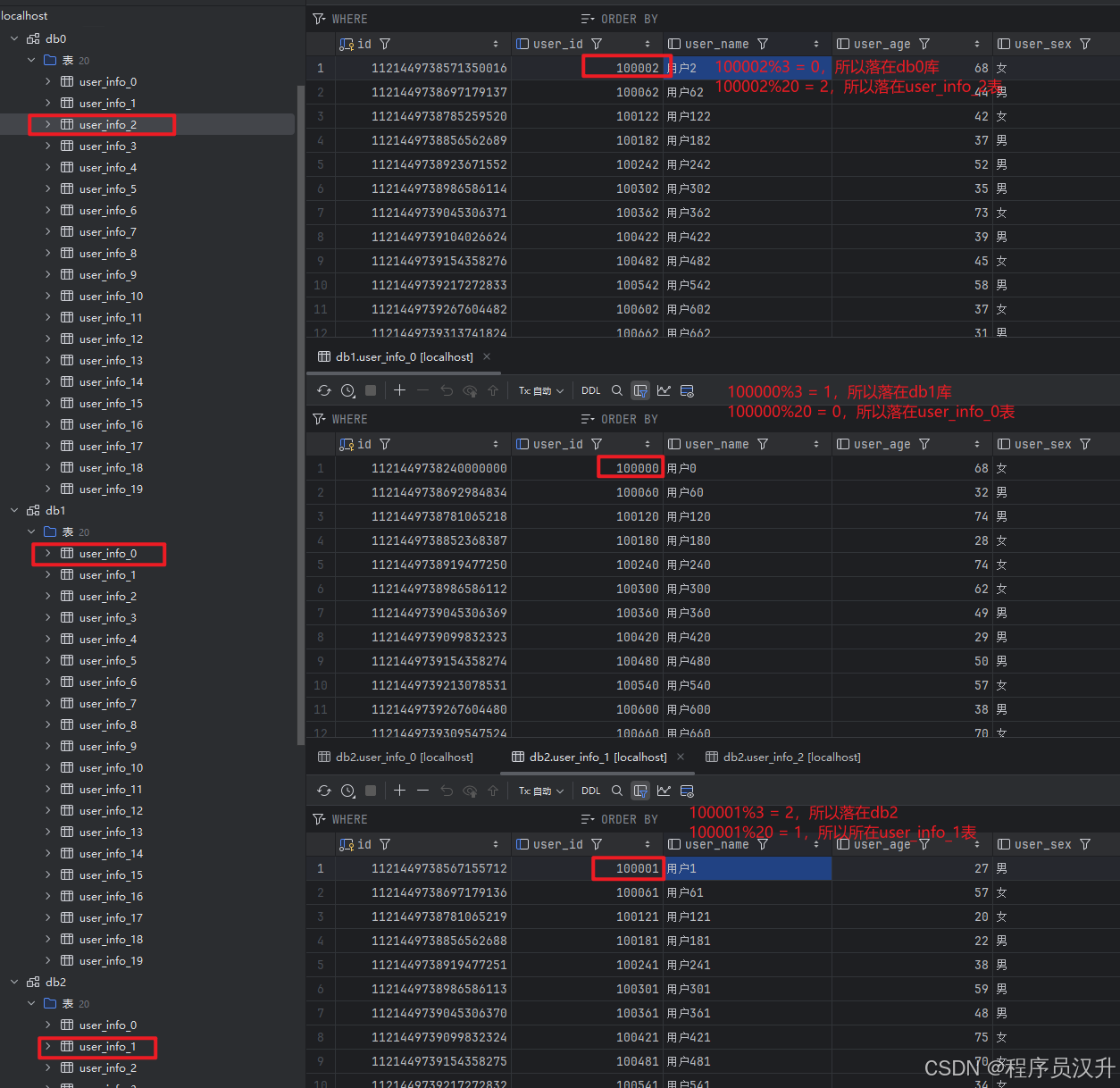
表目录如下图片:
1.1.3 随机生成1000条模拟数据
/**
* 随机生成1000条数据 插入表中
* @return 随机生成1000条数据
*/
@Override
public List<UserInfoSharding> randomAddUser() {
List<UserInfoSharding> userList = new ArrayList<>();
Random random = new Random();
LocalDateTime now = LocalDateTime.now();
for (int i = 0; i < 1000; i++) {
UserInfoSharding user = new UserInfoSharding();
user.setUserId((long) (100000 + i)); // 模拟userId
user.setUserName("用户" + i);
user.setUserAge(random.nextInt(60) + 18); // 18 - 77
user.setUserSex(random.nextBoolean() ? "男" : "女");
user.setUserPhone("138" + String.format("%08d", random.nextInt(100000000)));
user.setUserEmail("user" + i + "@example.com");
user.setUserAddress("地址_" + random.nextInt(1000));
user.setViewTime(now.minusDays(random.nextInt(30)));
// createTime 增加更多随机性
user.setCreateTime(
now
.minusDays(random.nextInt(30))
.minusHours(random.nextInt(24))
.minusMinutes(random.nextInt(60))
);
user.setUpdateTime(now);
userList.add(user);
}
// 批量插入数据库(假设你有 mapper 层)
this.saveBatch(userList);
return userList;
}
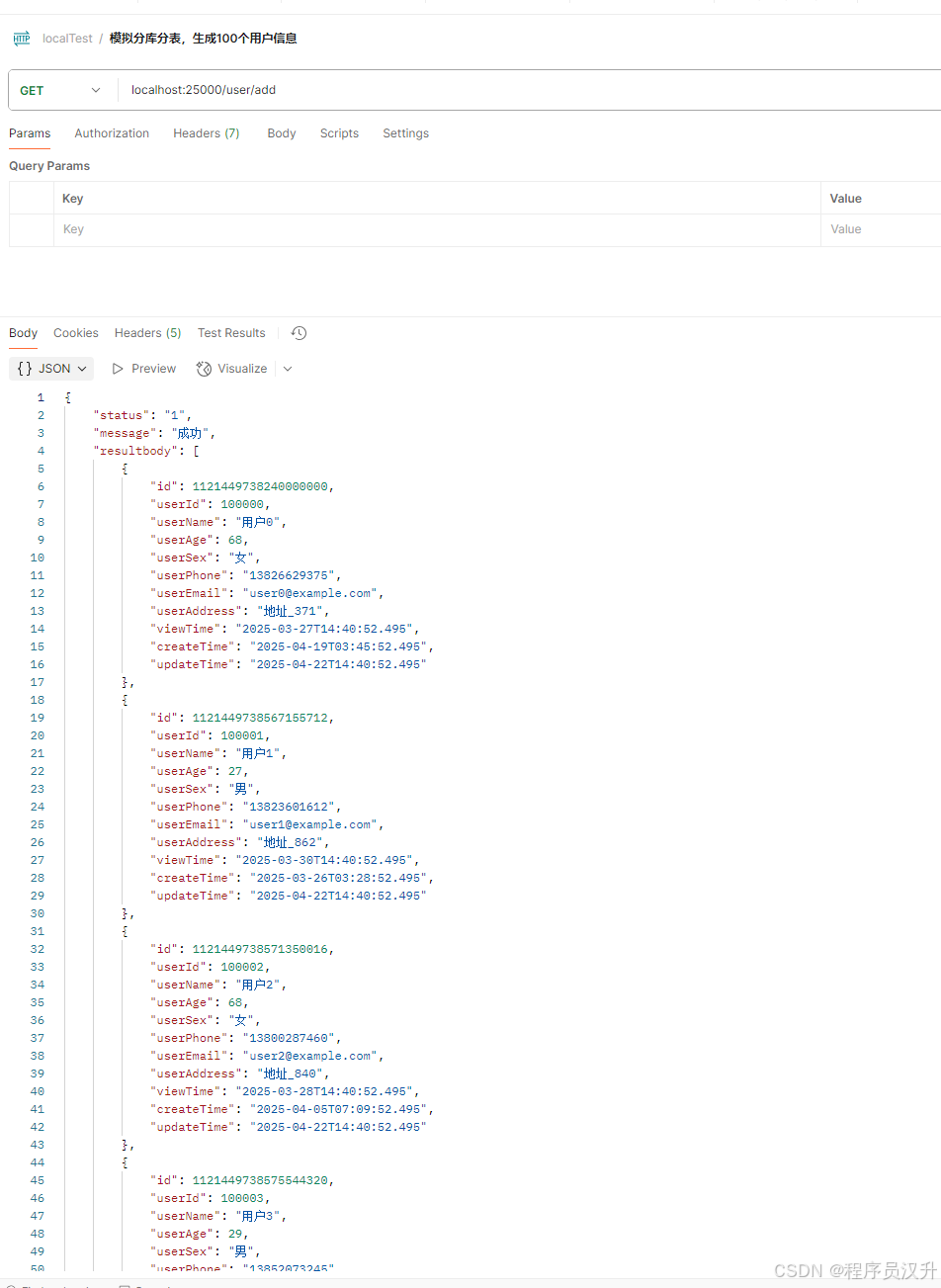
-
新增结果
1.2 ShardingSphere主从读写分离用法
1.2.1 applicaiton.yml配置文件解读
先看主从读写分离用法配置文件:
server:
port: 25001
spring:
# sharding-jdbc配置
shardingsphere:
# 是否开启SQL显示
props:
sql:
show: true
# ====================== 数据源配置 ======================
datasource:
names: order_master_0,order_slave_0,order_master_1,order_slave_1
# ====================== 配置第1个主从库 ======================
# 主库0
order_master_0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/order?serverTimezone=Asia/Shanghai&useSSL=false&zeroDateTimeBehavior=convertToNull&characterEncoding=utf-8
username: root
password: 123456
# 从库0
order_slave_0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/order?serverTimezone=Asia/Shanghai&useSSL=false&zeroDateTimeBehavior=convertToNull&characterEncoding=utf-8
username: root
password: 123456
# ====================== 配置第2个主从库 ======================
# 主库1
order_master_1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/order?serverTimezone=Asia/Shanghai&useSSL=false&zeroDateTimeBehavior=convertToNull&characterEncoding=utf-8
username: root
password: 123456
# 从库1
order_slave_1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/order?serverTimezone=Asia/Shanghai&useSSL=false&zeroDateTimeBehavior=convertToNull&characterEncoding=utf-8
username: root
password: 123456
rules:
# ====================== 读写分离配置 ======================
readwrite-splitting:
data-sources:
order_0:
props:
# 主库
write-data-source-name: order_master_0
# 从库
read-data-source-names: order_slave_0
# 从库查询数据的负载均衡算法 目前有2种算法 round_robin(轮询)和 random(随机)
# 算法接口 {@link org.apache.shardingsphere.spi.masterslave.MasterSlaveLoadBalanceAlgorithm}
# 实现类 RandomMasterSlaveLoadBalanceAlgorithm 和 RoundRobinMasterSlaveLoadBalanceAlgorithm
load-balancer-name: RANDOM
type: Static
order_1:
props:
write-data-source-name: order_master_1
read-data-source-names: order_slave_1
load-balancer-name: RANDOM
type: Static
load-balancers:
RANDOM:
type: RANDOM
# ====================== 分库分表配置 ======================
sharding:
tables:
# 分表规则:在使用 ShardingSphere 时,
t_order_info:
# 例如下面这个解释:
# 第一部分:order_${0..15}
# 表示生成 16个逻辑表(从0到15) 实际生成的表名会是: order_0 order_1 ... order_15
#
# 第二部分:t_order_info${(1..1000).collect{t ->t.toString().padLeft(4,'0')}}
# 更复杂的动态生成规则,分解如下:
# 1..1000:生成1到1000的数字序列
# .collect{t -> ... }:对每个数字进行格式化处理
# t.toString().padLeft(4,'0'):将数字转换为4位宽度,不足补零
# 实际生成的表后缀会是:t_order_info0001 t_order_info0002 ... t_order_info0999 t_order_info1000
#
# 组合后的完整含义
# 这个表达式会生成 16(前半部分) × 1000(后半部分) = 16,000个物理表,格式为:
# order_0.t_order_info0001 order_0.t_order_info0002 ... order_15.t_order_info0999 order_15.t_order_info1000
#
# actual-data-nodes: order_${0..15}.t_order_info${(1..1000).collect{t ->t.toString().padLeft(4,'0')}}
# 下面写一个简单的demo,两个数据库,每个数据库有10个表,共20个表
actual-data-nodes: order_${0..1}.t_order_info${(1..10).collect{t ->t.toString().padLeft(2,'0')}}
# 分库规则:根据 user_id 的值,将数据存储到不同的数据库中
database-strategy:
standard:
sharding-column: orderid
# 分库算法
sharding-algorithm-name: delivery
# 分表规则:根据 user_id 的值,将数据存储到不同的表中
table-strategy:
standard:
sharding-column: orderid
# 分表算法
sharding-algorithm-name: delivery
sharding-algorithms:
# 分库算法
delivery:
type: CLASS_BASED
props:
strategy: STANDARD
# 自定义分库算法实现类
algorithmClassName: com.demo.shardingsphere.algo.DeliveryShardingAlgorithm
-
🚪 1. 服务端口配置
server: port: 25001服务运行在 25001 端口。
-
🌱 2. 开启 SQL 显示
spring: shardingsphere: props: sql: show: true打印实际执行的 SQL,便于开发调试与排查问题。
-
🗃 3. 多数据源配置(主从库)
spring: shardingsphere: datasource: names: order_master_0, order_slave_0, order_master_1, order_slave_1- 📦 主从库详解
-
主库 & 从库 0
order_master_0: jdbc-url: jdbc:mysql://localhost:3306/order order_slave_0: jdbc-url: jdbc:mysql://localhost:3306/order -
主库 & 从库 1
order_master_1: jdbc-url: jdbc:mysql://localhost:3306/order order_slave_1: jdbc-url: jdbc:mysql://localhost:3306/order
两个主从组,每组一个主库和一个从库,数据库连接信息一致,但ShardingSphere 会负责读写路由的调度。 -
- 📦 主从库详解
-
🔄 4. 读写分离规则(ReadWrite Splitting)
readwrite-splitting: data-sources: order_0: write-data-source-name: order_master_0 read-data-source-names: order_slave_0 load-balancer-name: RANDOM order_1: write-data-source-name: order_master_1 read-data-source-names: order_slave_1 load-balancer-name: RANDOM load-balancers: RANDOM: type: RANDOM✨ 特点说明
-
主库写入:所有数据写操作路由到
order_master_X -
从库读取:查询类操作会分配给
order_slave_X,使用RANDOM负载均衡策略
-
-
🧩 5. 分库分表策略(Sharding Rules)
-
📑 分片逻辑表:
t_order_infoactual-data-nodes: order_${0..1}.t_order_info${(1..10).collect{t ->t.toString().padLeft(2,'0')}}这段配置生成了 2个库 × 每库10张表 = 共20张物理表,例如:
-
order_0.t_order_info01 ~ t_order_info10 -
order_1.t_order_info01 ~ t_order_info10
-
-
🧮 分库 + 分表策略
database-strategy: sharding-column: orderid sharding-algorithm-name: delivery table-strategy: sharding-column: orderid sharding-algorithm-name: delivery无论是 选库 还是 选表,都依据
orderid字段,使用同一个名为delivery的自定义分片算法。
-
-
🧠 6. 自定义分片算法
sharding-algorithms: delivery: type: CLASS_BASED props: strategy: STANDARD algorithmClassName: com.demo.shardingsphere.algo.DeliveryShardingAlgorithm通过继承
ShardingSphere的分片接口,可以实现更灵活的分片逻辑(如:哈希算法、范围分片等)。我这里采用自定义算法,后文详细讲解。 -
📌 总结
模块 功能说明 数据源配置 配置了两个主从对 读写分离 主写从读,负载均衡 分库分表 按照 orderid分片,生成 20 张表自定义算法 使用 Java 类实现灵活的分片逻辑
1.2.2 自定义分库分表算法
上面配置文件中导入了自定义分库分表算法algorithmClassName: com.demo.shardingsphere.algo.DeliveryShardingAlgorithm,下面是具体逻辑
-
分库算法
- 采用了
crc32算法对orderid订单id哈希计算,得到一个长整型a - 将长整型
a取模DB_TOTAL_COUNT(数据库总数),得到模数b即为数据库下标
- 采用了
-
分表算法
- 采用了
crc32算法对orderid订单id哈希计算,得到一个长整型a - 将长整型
a除以REAL_TABLE_TOTAL_COUNT(实际表总数),得到商b - 计算
b对REAL_TABLE_TOTAL_COUNT取模后+1,得到最终的分表编号c - 将
c格式化为两位数字符串并返回。
- 采用了
package com.demo.shardingsphere.algo;
import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.zip.CRC32;
/**
* @author hanson.huang
* @version V1.0
* @ClassName DeliveryShardingAlgorithm
* @Description 分片算法
* @date 2025/4/22 16:17
**/
@Component
public final class DeliveryShardingAlgorithm implements StandardShardingAlgorithm<String> {
private static final Logger log = LoggerFactory.getLogger(DeliveryShardingAlgorithm.class);
// private static final String REAL_TABLE_NAME_PREFIX = "t_order_info";
// private static final Long REAL_TABLE_TOTAL_COUNT = 1000L;
// private static final String DB_NAME_PREFIX = "order_";
// private static final Long DB_TOTAL_COUNT = 16L;
// 举个简单的例子
private static final String REAL_TABLE_NAME_PREFIX = "t_order_info";
private static final Long REAL_TABLE_TOTAL_COUNT = 10L;
private static final String DB_NAME_PREFIX = "order_";
private static final Long DB_TOTAL_COUNT = 2L;
public DeliveryShardingAlgorithm() {
}
public String dbAlgorithm(String orderId) {
Long a = crc32(orderId);
long b = a % DB_TOTAL_COUNT;
return Long.toString(b);
}
public String tableAlgorithm(String orderId) {
Long a = crc32(orderId);
Long b = a / REAL_TABLE_TOTAL_COUNT;
Long c = b % REAL_TABLE_TOTAL_COUNT + 1L;
return String.format("%02d", c);
}
private static Long crc32(String str) {
CRC32 crc32 = new CRC32();
crc32.update(str.getBytes());
return crc32.getValue();
}
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<String> preciseShardingValue) {
String orderId = String.valueOf(preciseShardingValue.getValue());
String databaseIndex;
String targetNode;
if (((String)tableNames.stream().findFirst().orElse("t_order_info")).startsWith(preciseShardingValue.getLogicTableName())) {
databaseIndex = this.tableAlgorithm(orderId);
targetNode = String.format("%s%s", "t_order_info", databaseIndex);
log.info("sharding table: {}", targetNode);
return targetNode;
} else {
databaseIndex = this.dbAlgorithm(orderId);
targetNode = String.format("%s%s", "order_", databaseIndex);
log.info("sharding database: {}", targetNode);
return targetNode;
}
}
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<String> rangeShardingValue) {
throw new UnsupportedOperationException("暂未支持区间查询");
}
@Override
public void init() {
}
@Override
public String getType() {
return "DELIVERY";
}
}
1.2.3 实体类及建表语句
-
实体类如下:
/** * @author hanson.huang * @version V1.0 * @ClassName OrderInfoShardingMapper * @Description 订单分库表 * @date 2025/4/22 16:36 **/ @Data @TableName("t_order_info") public class OrderInfoSharding implements Serializable { private static final long serialVersionUID = 1L; /** * 订单id */ @TableId("orderid") private Long orderId; /** * 用户id */ @TableField("userid") private Long userId; /** * 订单金额 */ @TableField("amount") private BigDecimal amount; /** * 订单状态 */ @TableField("status") private String status; /** * 订单创建时间 */ @TableField("create_time") private String createTime; /** * 订单更新时间 */ @TableField("update_time") private String updateTime; }实体类映射表为
t_order_info -
建表语句:
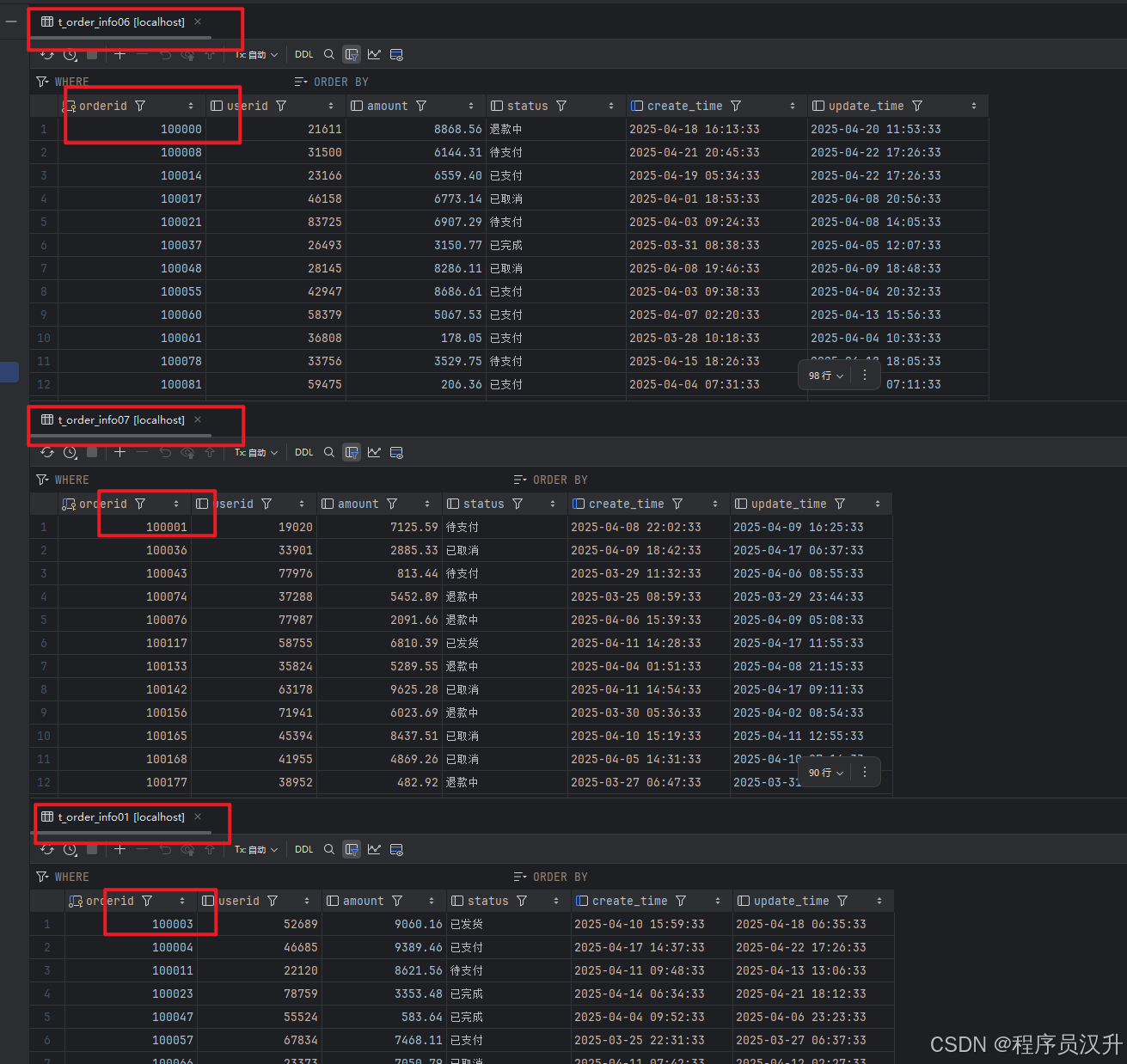
USE `order`; -- 循环创建 t_order_info01 到 t_order_info10 DELIMITER $$ CREATE PROCEDURE create_order_info_tables() BEGIN DECLARE i INT DEFAULT 1; DECLARE table_name VARCHAR(64); WHILE i <= 10 DO SET @table_name = CONCAT('t_order_info', LPAD(i, 2, '0')); SET @create_sql = CONCAT(' CREATE TABLE IF NOT EXISTS ', @table_name, ' ( orderid BIGINT NOT NULL, userid BIGINT, amount DECIMAL(18, 2), status VARCHAR(50), create_time VARCHAR(50), update_time VARCHAR(50), PRIMARY KEY (orderid), KEY idx_create_time (create_time) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; '); PREPARE stmt FROM @create_sql; EXECUTE stmt; DEALLOCATE PREPARE stmt; SET i = i + 1; END WHILE; END$$ DELIMITER ; -- 调用存储过程生成表 CALL create_order_info_tables(); -- 删除存储过程(可选) DROP PROCEDURE create_order_info_tables;
1.2.4 随机生成1000条模拟数据
/**
* 随机生成1000条数据 插入表中
* @return 随机生成1000条数据
*/
@Override
public List<OrderInfoSharding> randomAddOrder() {
List<OrderInfoSharding> orderList = new ArrayList<>();
Random random = new Random();
LocalDateTime now = LocalDateTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// 订单状态选项
String[] statuses = {"待支付", "已支付", "已发货", "已完成", "已取消", "退款中"};
for (int i = 0; i < 1000; i++) {
OrderInfoSharding order = new OrderInfoSharding();
// 订单ID (从100000开始递增)
order.setOrderId(100000L + i);
// 用户ID (随机10000-99999之间的用户)
order.setUserId(10000L + random.nextInt(90000));
// 订单金额 (100-9999.99之间的随机金额)
order.setAmount(new BigDecimal(100 + random.nextInt(9900))
.add(new BigDecimal(random.nextDouble()).setScale(2, BigDecimal.ROUND_HALF_UP)));
// 订单状态 (随机选择)
order.setStatus(statuses[random.nextInt(statuses.length)]);
// 创建时间 (过去30天内的随机时间)
LocalDateTime createTime = now.minusDays(random.nextInt(30))
.minusHours(random.nextInt(24))
.minusMinutes(random.nextInt(60));
order.setCreateTime(createTime.format(formatter));
// 更新时间 (在创建时间基础上随机增加0-7天)
LocalDateTime updateTime = createTime.plusDays(random.nextInt(8))
.plusHours(random.nextInt(24))
.plusMinutes(random.nextInt(60));
// 确保更新时间不超过当前时间
if (updateTime.isAfter(now)) {
updateTime = now;
}
order.setUpdateTime(updateTime.format(formatter));
orderList.add(order);
}
// 改为单条插入
for (OrderInfoSharding order : orderList) {
this.save(order);
}
return orderList;
}
二、ShardingSphere源码解析
第一节讲了分库分表的使用,这节讲讲底层实现原理(注:ShardingSphere版本迭代很快,需要注意源码版本,低版本可能与本文存在差异)
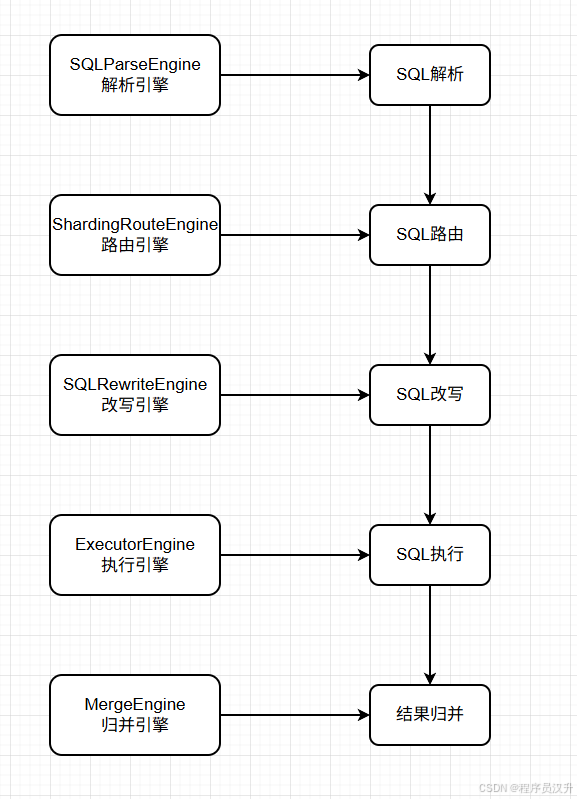
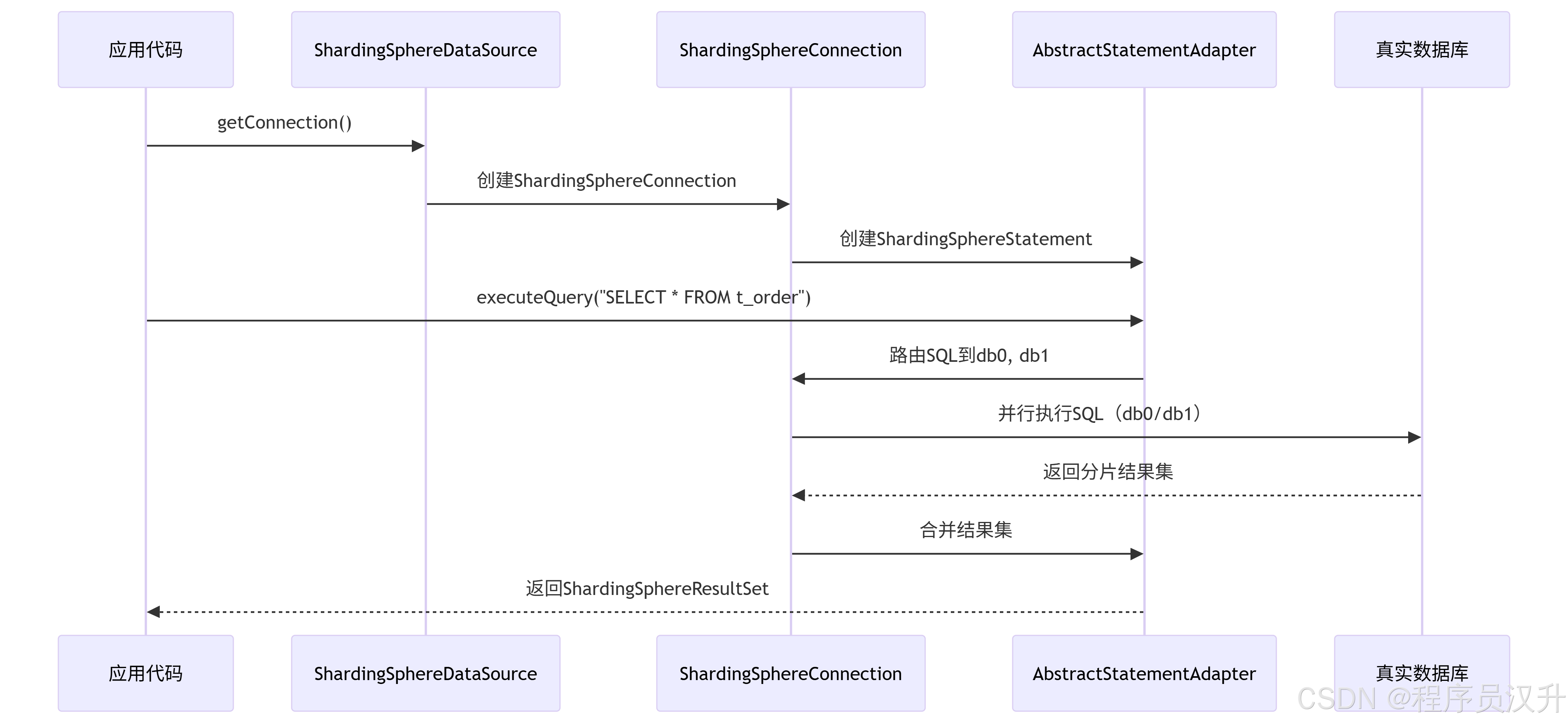
shardingsphere作为一款分库分表的中间件,分片是其的核心功能。分片流程包括SQL解析、SQL路由、SQL改写、SQL执行、结果归并。分片流程的这些流程都对应相应的引擎,如下图所示:
2.1 springboot接入sharding-jdbc的分析
前面通过maven引入了shardingsphere-jdbc-spring-boot-starter的jar,并且配置了数据源、分片策略以及算法,就实现了springboot接入shardingsphere-jdbc。那么shardingsphere-jdbc是如何通过简单配置就实现了springboot项目的分库分表功能呢?
shardingsphere-jdbc是兼容jdbc接口的,如果我们使用jdbc进行开发,代码可能如下:
// 创建池化的数据源
PooledDataSource dataSource = new PooledDataSource ();
// 设置MySQL Driver
dataSource.setDriver ("com.mysql.jdbc.Driver");
// 设置数据库URL、用户名和密码
dataSource.setUrl ("jdbc:mysql://localhost:3306/test");
dataSource.setUsername ("user");
dataSource.setPassword ("password");
// 获取连接
Connection connection = dataSource.getConnection();
// 执行查询
PreparedStatement statement = connection.prepareStatement ("select * from t_order");
// 获取查询结果应该处理
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
//省略读取数据
}
// 关闭资源
statement.close();
resultSet.close();
connection.close();
jdbc的主要类包括DataSource、Connection、Statement、ResultSet的等,sharding-jdbc同样实现这些接口,这样子才能无缝兼容jdbc。
有了这些概念以后,接下来看看shardingsphere-jdbc是如何通过简单配置就实现了springboot项目的分库分表功能。通过maven引入了shardingsphere-jdbc-spring-boot-starter,那些在这个包下源码肯定能找到程序的入口:
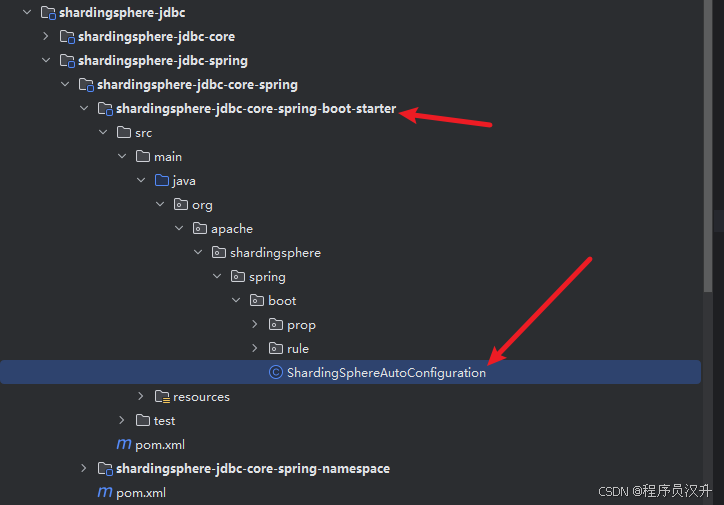
SpringBootConfiguration类就是springboot项目接入shardingsphere-jdbc的配置入口。
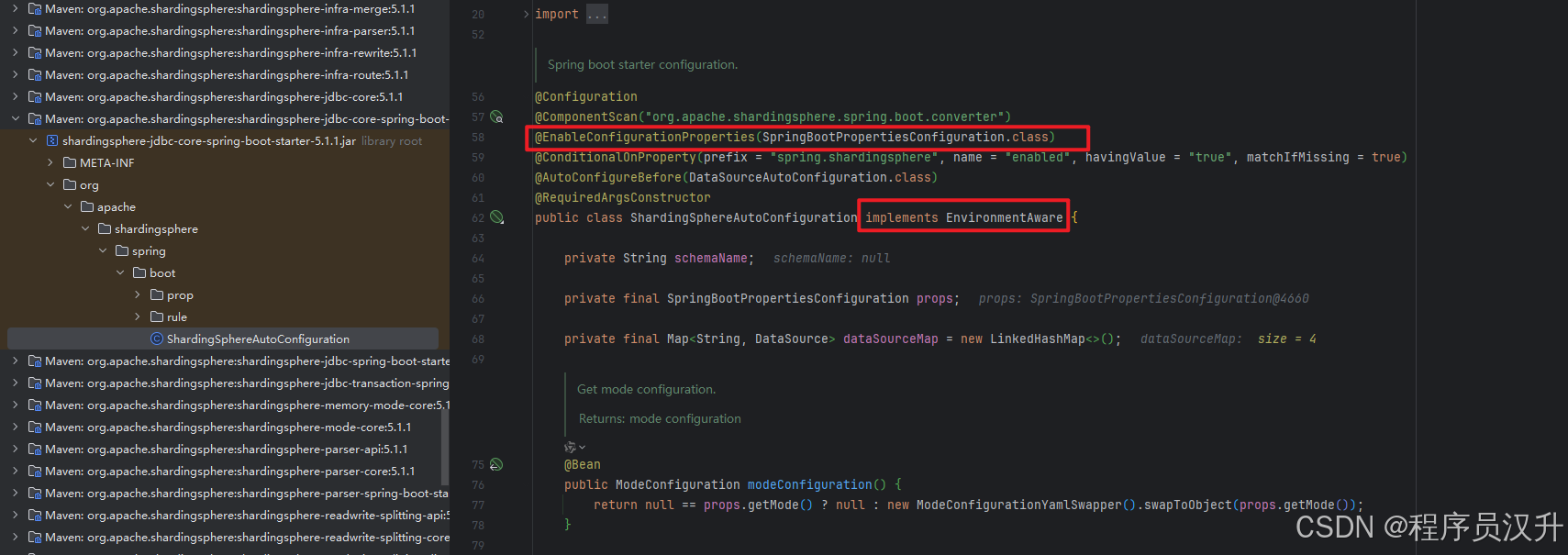
-
ShardingSphereAutoConfiguration类有@Configuration、@EnableConfigurationProperties以及@AutoConfigureBefore等注解。 -
@Configuration表示是spring的配置注解 -
@ConditionalOnProperty注解的prefix字段的值是spring.shardingsphere,表示会读取以spring.shardingsphere为前缀的配置。 -
@EnableConfigurationProperties注解将SpringBootPropertiesConfiguration类主动注入到ShardingSphereAutoConfiguration的props属性中。注意:这里老版本会存在多个配置类,例如:表示分库分表的配置类、表示读写分离的配置类、表示数据脱敏的配置类等,5.x版本之后全部统一用YAML驱动; -
@AutoConfigureBefore注解表示在DataSourceAutoConfiguration类初始化之前先进行初始化ShardingSphereAutoConfiguration类。
通过以上的配置,可以将数据源、分库分表的相关的配置就读取到ShardingSphereAutoConfiguration配置类中。分库分表的配置类为YamlShardingRuleConfiguration
**
* Sharding rule configuration for YAML.
*/
@Getter
@Setter
public final class YamlShardingRuleConfiguration implements YamlRuleConfiguration {
/**
* 分库分表的表规则配置(标准分片表)
* key 为逻辑表名,value 为对应的分片配置
*/
private Map<String, YamlTableRuleConfiguration> tables = new LinkedHashMap<>();
/**
* 自动分片表规则配置(使用 inline 或 hint 自动分片)
* key 为逻辑表名,value 为对应的自动分片配置
*/
private Map<String, YamlShardingAutoTableRuleConfiguration> autoTables = new LinkedHashMap<>();
/**
* 绑定表集合(多个逻辑表具有相同的分片策略并且可以联表查询)
*/
private Collection<String> bindingTables = new ArrayList<>();
/**
* 广播表集合(每个分片库中都存在完整一份,通常是字典表)
*/
private Collection<String> broadcastTables = new ArrayList<>();
/**
* 默认的分库策略(当逻辑表未指定时使用此策略)
*/
private YamlShardingStrategyConfiguration defaultDatabaseStrategy;
/**
* 默认的分表策略(当逻辑表未指定时使用此策略)
*/
private YamlShardingStrategyConfiguration defaultTableStrategy;
/**
* 默认的主键生成策略(当逻辑表未指定时使用此策略)
*/
private YamlKeyGenerateStrategyConfiguration defaultKeyGenerateStrategy;
/**
* 分片算法配置集合
* key 为算法名称,value 为算法的 YAML 配置
*/
private Map<String, YamlShardingSphereAlgorithmConfiguration> shardingAlgorithms = new LinkedHashMap<>();
/**
* 主键生成器配置集合
* key 为生成器名称,value 为生成器的 YAML 配置
*/
private Map<String, YamlShardingSphereAlgorithmConfiguration> keyGenerators = new LinkedHashMap<>();
/**
* 默认的分片列名称(用于配置不指定表时的默认分片列)
*/
private String defaultShardingColumn;
/**
* 数据扩容/收缩使用的任务名称
*/
private String scalingName;
/**
* 数据扩容/收缩相关的动作配置
* key 为逻辑表名,value 为规则变更后执行的操作
*/
private Map<String, YamlOnRuleAlteredActionConfiguration> scaling = new LinkedHashMap<>();
/**
* 返回 ShardingRuleConfiguration 类型,用于反序列化转换
*/
@Override
public Class<ShardingRuleConfiguration> getRuleConfigurationType() {
return ShardingRuleConfiguration.class;
}
}
ShardingSphereAutoConfiguration类还继承了spring的EnvironmentAware接口,EnvironmentAware接口有一个setEnvironment方法,在项目启动时可以获取到application.yml的配置文件配置的属性值。ShardingSphereAutoConfiguration类实现了setEnvironment方法:
@Override
public final void setEnvironment(final Environment environment) {
dataSourceMap.putAll(DataSourceMapSetter.getDataSourceMap(environment));
schemaName = SchemaNameSetter.getSchemaName(environment);
}
DataSourceMapSetter.getDataSourceMap方法:
/**
* 获取数据源映射表(逻辑库名 -> DataSource 实例)
*
* @param environment Spring Boot 的 Environment 环境对象
* @return 数据源名称与对应 DataSource 的映射
*/
public static Map<String, DataSource> getDataSourceMap(final Environment environment) {
Map<String, DataSource> result = new LinkedHashMap<>();
// 遍历所有配置的数据源名称,逐个构造 DataSource 并加入结果集
for (String each : getDataSourceNames(environment)) {
try {
result.put(each, getDataSource(environment, each));
} catch (final ReflectiveOperationException ex) {
throw new ShardingSphereException("Can't find data source type.", ex);
} catch (final NamingException ex) {
throw new ShardingSphereException("Can't find JNDI data source.", ex);
}
}
return result;
}
完整的关系图:
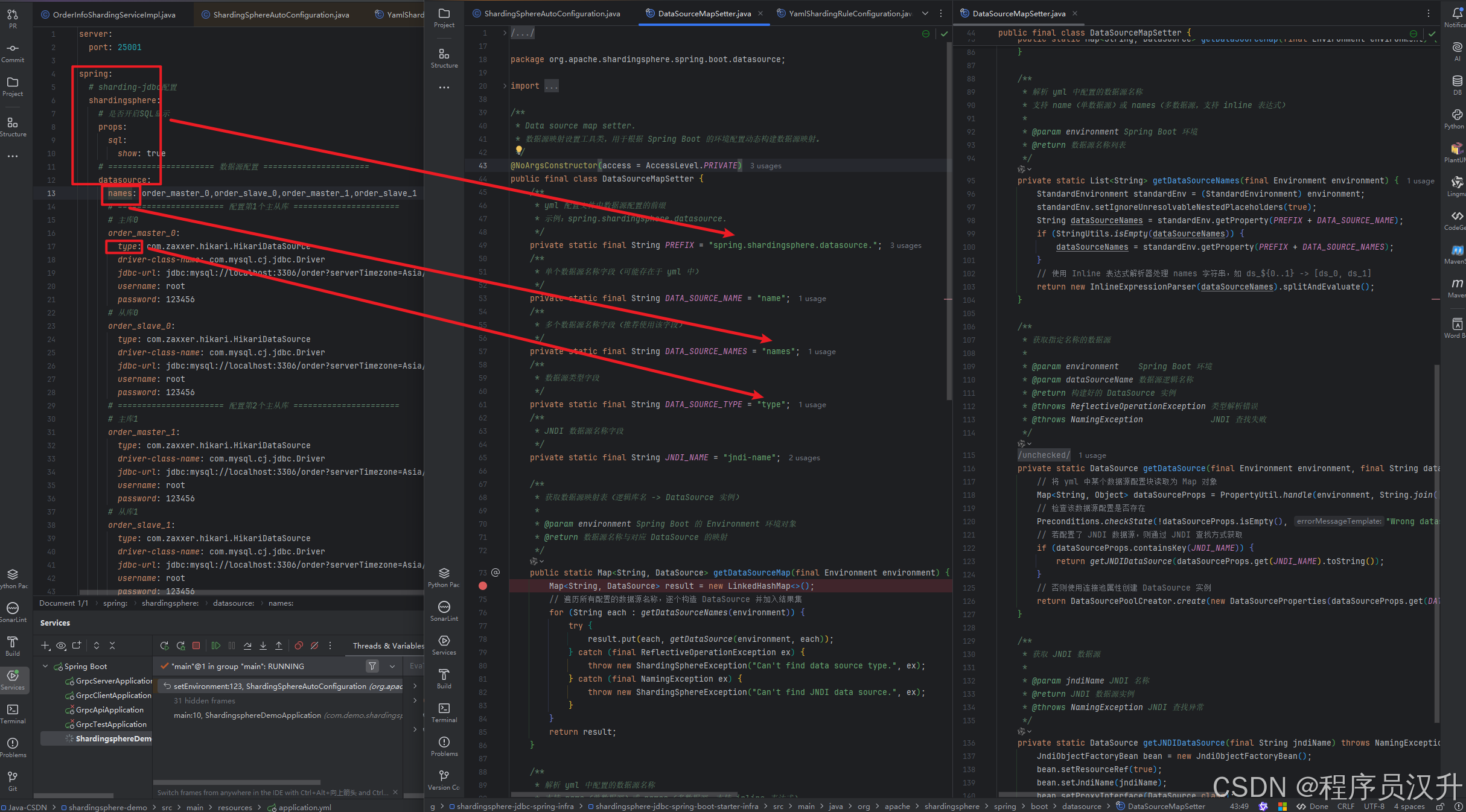
setEnvironment方法读取配置信息,从配置信息中找到spring.shardingsphere.datasource.names 或者spring.shardingsphere.datasource.name的配置,该配置是数据源的配置,遍历解析以后的数据源,并且通过配置生成DataSource缓存到dataSourceMap中。缓存在dataSourceMap的DataSource就是原生的jdbc的DataSource。
我们来Debug看一下:
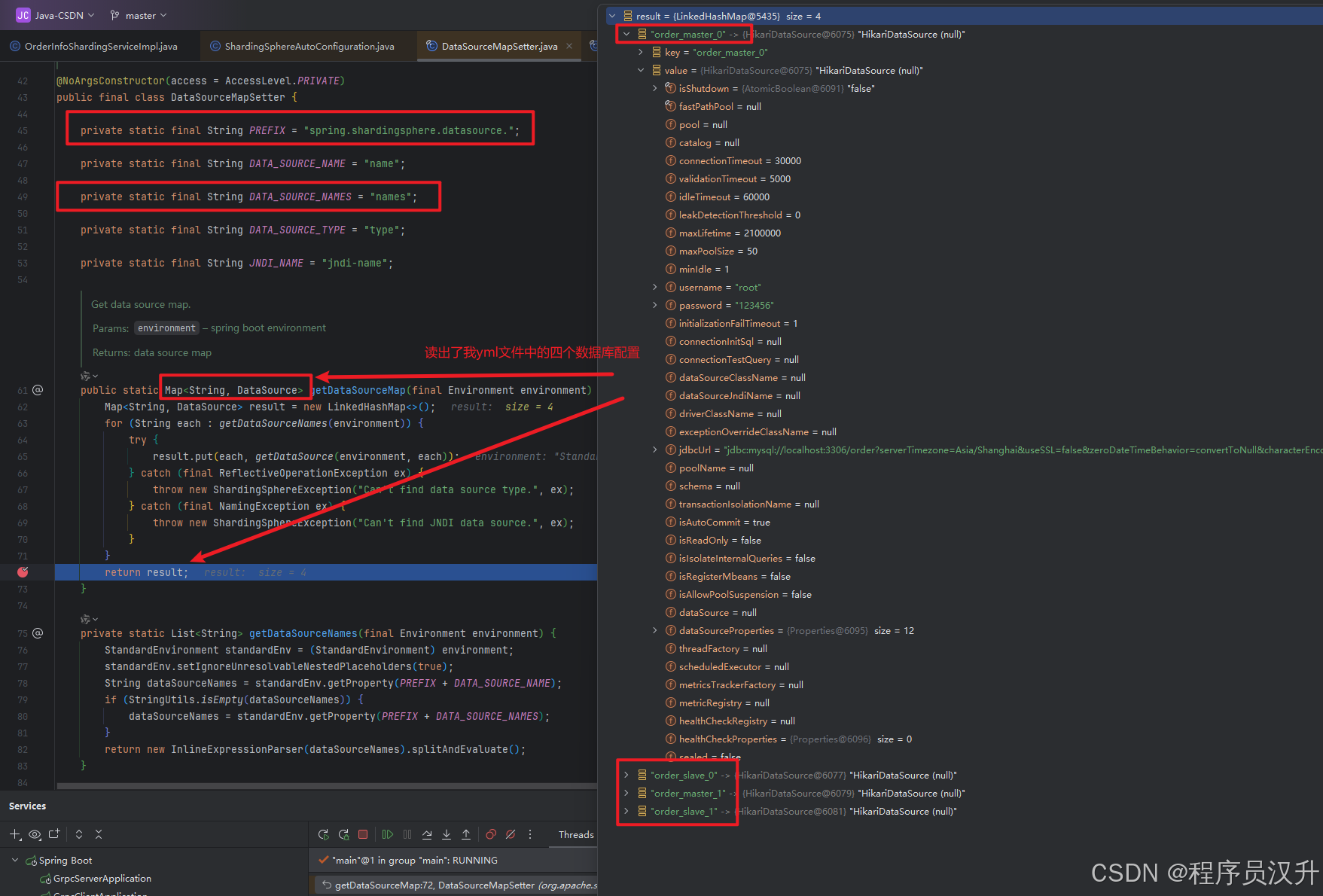
getDataSourceMap获取了yml配置文件中四个db记录,order_master_0、order_slave_0、order_master_1、order_slave_1
2.2 兼容jdbc规范
JDBC规范提供了一些接口,不同的数据库可以对这套规范进行实现,从而通过JDBC规范操作不同的不同数据库。shardingsphere兼容了JDBC规范,对JDBC规范提供的接口方法进行了重写。
JDBC规范提供了DataSource、Connection、Statement、ResultSet等接口,shardingsphere采用适配器模式对这些接口进行重写,保证兼容JDBC规范。shardingsphere对JDBC规范的这些接口抽象了一套基于适配器模式的实现方案,
举个例子 :
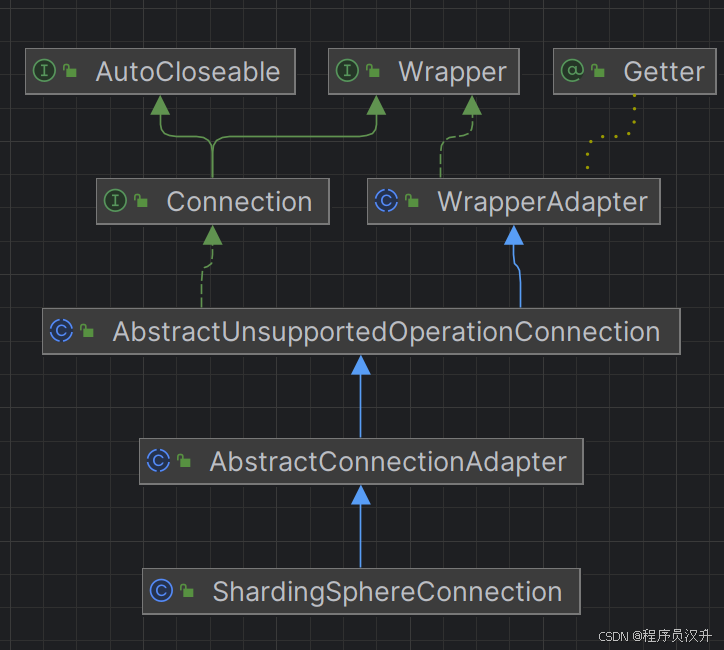
上述图中,ShardingSphere的JDBC连接类该类继承自AbstractConnectionAdapter,是 JDBC Connection 的包装实现。提供了连接管理、事务控制、Statement/PreparedStatement 创建等能力。
核心作用
提供与标准 JDBC 接口的兼容性适配,屏蔽底层分片逻辑对应用代码的侵入。
| 目录/类 | 功能说明 | 关键接口/类说明 |
|---|---|---|
①AbstractConnectionAdapter | 连接适配基类,管理多个真实数据库连接(如分库分表场景下的多个 PhysicalConnection) | 继承 java.sql.Connection,实现 Wrapper 接口 |
②AbstractDataSourceAdapter | 数据源适配基类,提供对 ShardingSphereDataSource 的包装 | 继承 javax.sql.DataSource |
③ AbstractStatementAdapter | Statement 适配基类,处理分片 SQL 的转发和执行 | 继承 java.sql.Statement |
④ AbstractResultSetAdapter | 结果集适配基类,合并多个分片结果集(如 UNION ALL) | 继承 java.sql.ResultSet |
每个适配器有具体的ShardingSphere实现类实现分库分表、读写分离、分布式事务等核心功能。
| 目录/类 | 功能说明 | 关键实现逻辑 |
|---|---|---|
| connection | 分片连接管理 | |
| ① ConnectionManager | 管理多个真实数据源的连接池(如 HikariCP、Druid) | 负责连接的获取、复用和销毁 |
② ShardingSphereConnection | 分片连接主类,入口所有分片操作 | 继承 AbstractConnectionAdapter,嵌入路由、执行引擎逻辑 |
| datasource | 数据源包装和元数据管理 | |
③ ShardingSphereDataSource | 应用直接接触的数据源对象,初始化分片规则 | 创建 ShardingSphereConnection |
| statement | 分片 SQL 执行逻辑 | |
④ ShardingSphereStatement | 普通 Statement 实现,解析静态 SQL 并分片执行 | 调用 SQLRouter 计算分片目标 |
⑤ ShardingSpherePreparedStatement | 预编译 Statement 实现,支持参数化分片 SQL | 优化批量操作性能 |
| resultset | 分片结果集处理 | |
⑥ ShardingSphereResultSet | 合并多个分片结果集,提供透明访问 | 支持内存排序、聚合计算(如 MAX/MIN) |
⑦ DatabaseMetaDataResultSet | 分片场景下的元数据结果集(如 getTables()) | 合并多个真实库的元数据 |
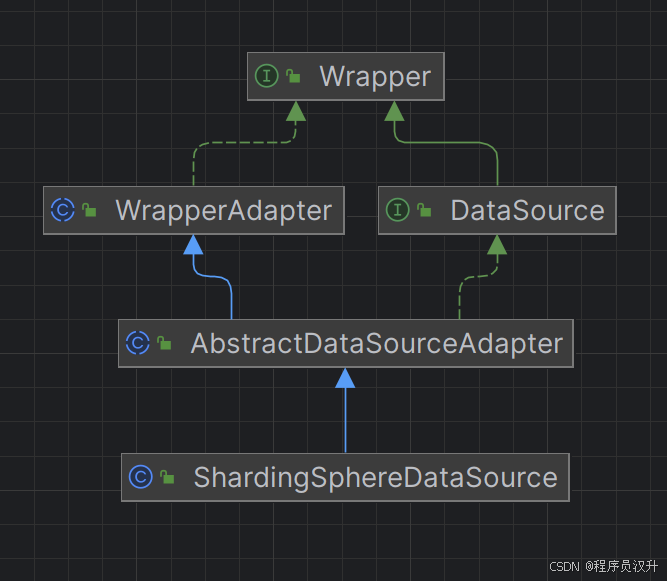
接下来用ShardingSphereDataSource来作为介绍shardingsphere对Jdbc规范的接口进行重写的案列。
ShardingSphereDataSource类图如下:
springboot采用工厂方法创建了分库分表的数据源ShardingSphereDataSource对象。代码如下:
/**
* ShardingSphere 数据源工厂类。
* 提供多种方式创建支持分片、读写分离等功能的 ShardingSphere 数据源。
*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class ShardingSphereDataSourceFactory {
/**
* 根据 schema 名称和模式配置创建数据源。
*
* @param schemaName 数据库逻辑名称(可为空)
* @param modeConfig 模式配置(Standalone, Cluster, Memory 等)
* @return ShardingSphere 数据源
* @throws SQLException SQL 异常
*/
public static DataSource createDataSource(final String schemaName, final ModeConfiguration modeConfig) throws SQLException {
return new ShardingSphereDataSource(Strings.isNullOrEmpty(schemaName) ? DefaultSchema.LOGIC_NAME : schemaName, modeConfig);
}
/**
* 创建包含分片规则等配置的数据源。
*
* @param schemaName 数据库逻辑名称
* @param modeConfig 模式配置
* @param dataSourceMap 数据源映射(key 为数据源名称)
* @param configs 规则配置集合(如分片、读写分离、影子库等)
* @param props 配置属性(用于自定义行为)
* @return ShardingSphere 数据源
* @throws SQLException SQL 异常
*/
public static DataSource createDataSource(final String schemaName, final ModeConfiguration modeConfig,
final Map<String, DataSource> dataSourceMap, final Collection<RuleConfiguration> configs, final Properties props) throws SQLException {
return new ShardingSphereDataSource(Strings.isNullOrEmpty(schemaName) ? DefaultSchema.LOGIC_NAME : schemaName, modeConfig, dataSourceMap, configs, props);
}
}
ShardingSphereDataSourceFactory类采用createDataSource方法创建ShardingSphereDataSource对象,将数据源dataSourceMap和RuleConfiguration以及Properties作为参数new了一个ShardingSphereDataSource对象。ShardingSphereDataSource类如下:
/**
* ShardingSphere 数据源实现类,用于支持分库分表、读写分离、分布式事务等功能。
* 是 JDBC 应用连接 ShardingSphere 的统一入口,底层使用 ContextManager 进行全局管理。
*/
@Getter
public final class ShardingSphereDataSource extends AbstractDataSourceAdapter implements AutoCloseable {
/**
* 当前数据源所属逻辑 schema 名称(逻辑数据库名)。
*/
private final String schemaName;
/**
* 分库分表运行时上下文对象,内部包含元数据管理、规则引擎、事务控制等核心功能。
*/
private final ContextManager contextManager;
/**
* 构造函数 - 仅传入 schema 名称和模式配置,使用空的数据源和规则集合进行初始化。
*
* @param schemaName 当前逻辑库名称
* @param modeConfig 模式配置,包含本地模式、集群模式等配置内容
* @throws SQLException 初始化失败时抛出
*/
public ShardingSphereDataSource(final String schemaName, final ModeConfiguration modeConfig) throws SQLException {
this.schemaName = schemaName;
// 初始化上下文管理器(使用空数据源和空规则)
contextManager = createContextManager(schemaName, modeConfig, new HashMap<>(), new LinkedList<>(), new Properties());
}
/**
* 构造函数 - 传入完整配置:数据源、规则、属性
*
* @param schemaName 当前逻辑库名称
* @param modeConfig 模式配置
* @param dataSourceMap 数据源映射(key 是数据源逻辑名称,value 是对应的 DataSource 对象)
* @param ruleConfigs 分库分表、读写分离等规则配置集合
* @param props 其他属性配置,如 SQL 显示、执行引擎线程池等
* @throws SQLException 初始化失败时抛出
*/
public ShardingSphereDataSource(final String schemaName, final ModeConfiguration modeConfig, final Map<String, DataSource> dataSourceMap,
final Collection<RuleConfiguration> ruleConfigs, final Properties props) throws SQLException {
// 检查规则合法性(比如表路由规则、分片算法是否正确)
checkRuleConfiguration(schemaName, ruleConfigs);
this.schemaName = schemaName;
// 初始化上下文管理器
contextManager = createContextManager(schemaName, modeConfig, dataSourceMap, ruleConfigs, null == props ? new Properties() : props);
}
/**
* 检查规则配置是否合法。
* 每个规则(如 ShardingRuleConfiguration、ReadwriteSplittingRuleConfiguration)都应有对应的 Checker 实现。
*
* @param schemaName 当前逻辑库名称
* @param ruleConfigs 配置集合
*/
@SuppressWarnings("unchecked")
private void checkRuleConfiguration(final String schemaName, final Collection<RuleConfiguration> ruleConfigs) {
ruleConfigs.forEach(each -> RuleConfigurationCheckerFactory.newInstance(each).ifPresent(optional -> optional.check(schemaName, each)));
}
/**
* 创建上下文管理器 ContextManager,是整个 ShardingSphere 的核心运行容器。
*
* @param schemaName 当前逻辑库名称
* @param modeConfig 模式配置
* @param dataSourceMap 数据源集合
* @param ruleConfigs 分片规则
* @param props 属性参数
* @return ContextManager 上下文对象
* @throws SQLException 初始化失败时抛出
*/
private ContextManager createContextManager(final String schemaName, final ModeConfiguration modeConfig, final Map<String, DataSource> dataSourceMap,
final Collection<RuleConfiguration> ruleConfigs, final Properties props) throws SQLException {
// 过滤出全局规则(如权限、系统变量等)
Collection<RuleConfiguration> globalRuleConfigs = ruleConfigs.stream().filter(each -> each instanceof GlobalRuleConfiguration).collect(Collectors.toList());
// 构建上下文参数对象,用于传递给 ContextManagerBuilder
ContextManagerBuilderParameter parameter = ContextManagerBuilderParameter.builder()
.modeConfig(modeConfig) // 模式配置,如 Standalone、Cluster 等
.schemaConfigs(Collections.singletonMap(schemaName, new DataSourceProvidedSchemaConfiguration(dataSourceMap, ruleConfigs))) // 指定 schema 的数据源和规则配置
.globalRuleConfigs(globalRuleConfigs)// 全局规则配置
.props(props)// 属性配置
.instanceDefinition(new InstanceDefinition(InstanceType.JDBC)).build();
// 构建上下文管理器
return ContextManagerBuilderFactory.newInstance(modeConfig).build(parameter);
}
}
ShardingSphereDataSource类有一个contextManager属性,该属性是保存分库分表运行时的上下文。ShardingSphereDataSource的构造器就是对contextManager进行初始化,将数据源dataSourceMap、分库分表规则RuleConfiguration等保存在contextManager中。另外ShardingSphereDataSource还有一个方法用来获取Connection对象。在初始化ShardingSphereDataSource时,还会执行静态代码块,静态代码块采用SPI机制加载注册了路由装饰器类、SQL重写装饰器类、结果出来引擎类,主要是对这些类进行初始化,等需要用到的时候直接拿来用。
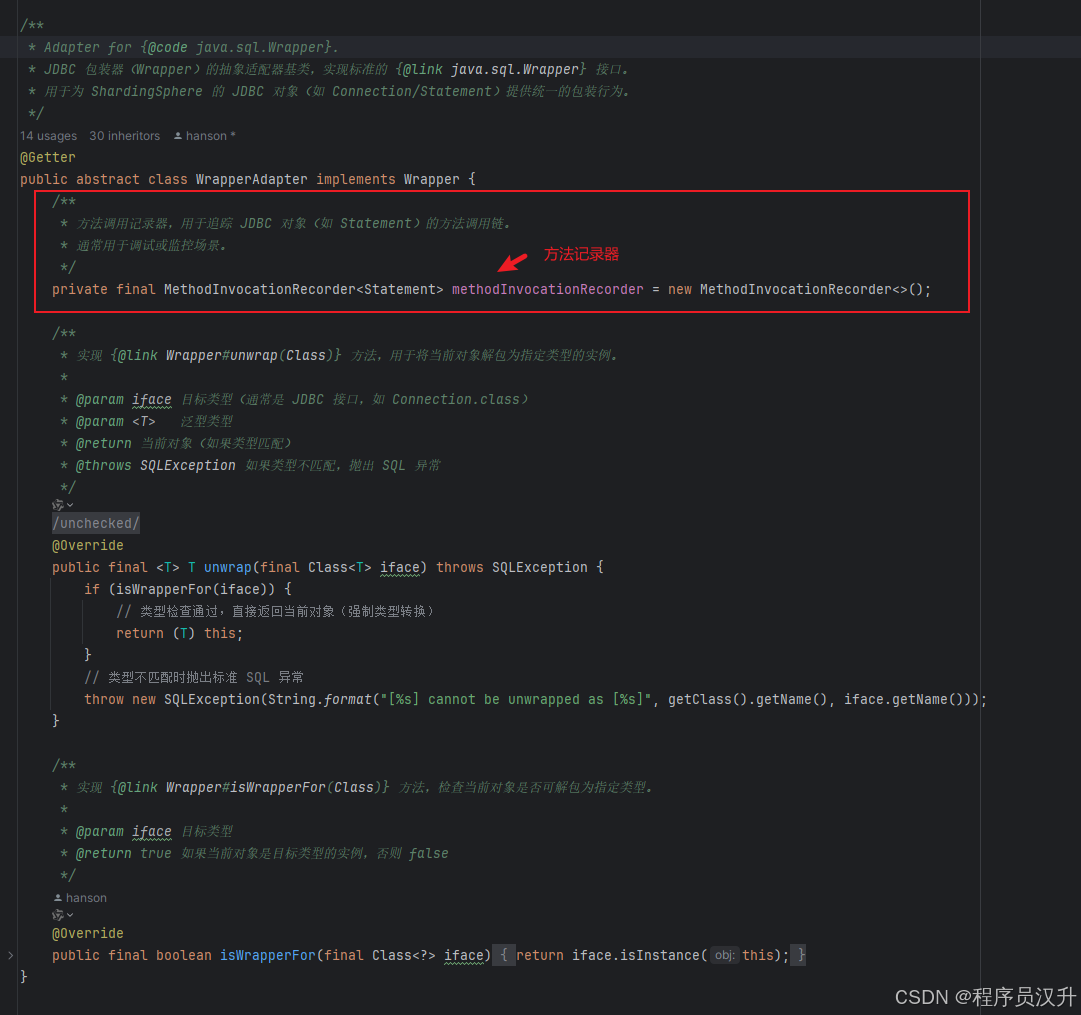
shardingsphere为Wrapper 接口实现了一个子类WrapperAdapter,WrapperAdapter类是Wrapper接口的适配器,WrapperAdapter类有一个重要的属性methodInvocationRecorder,如下:
进入到MethodInvocationRecorder类中:
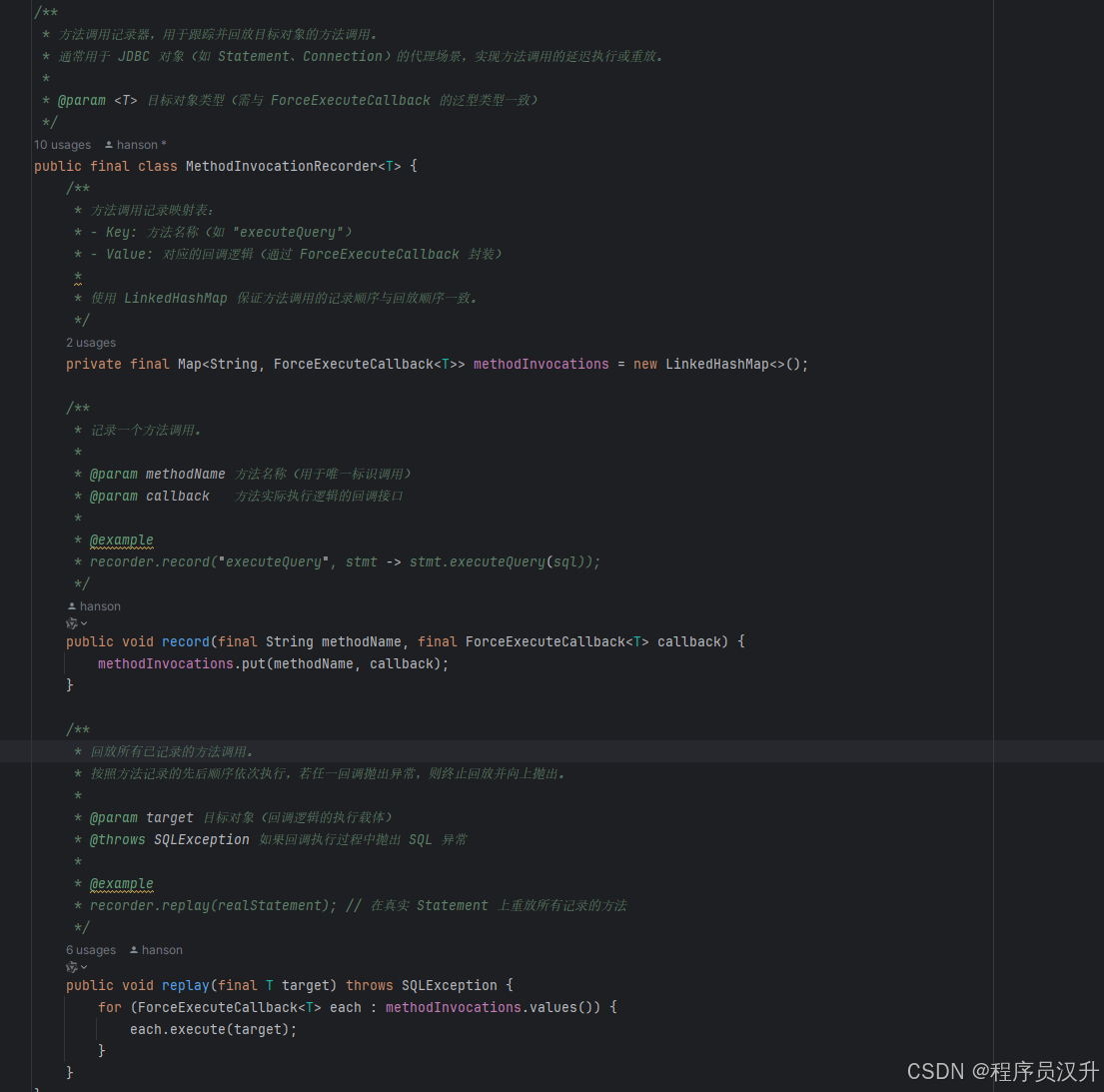
record方法是将方法的调用相关信息保存在methodInvocationsMap中,而replay方法是遍历methodInvocations,将保存在methodInvocations中的方法进行调用。
接下来在看看ShardingSphereResource类,ShardingSphereResource类拥有四个重要的属性(4.x之前的版本在AbstractDataSourceAdapter类中只有):
/**
* 数据源集合(Key为数据源名称,Value为物理数据源对象dataSources和databaseType)
* 示例:
* {
* "ds_0": HikariDataSource@1234,
* "ds_1": DruidDataSource@5678
* }
*/
private final Map<String, DataSource> dataSources;
/**
* 数据源元数据,包含:
* - 数据源URL、用户名等连接信息
* - 实例分组(如主从库的读写分离组)
*/
private final DataSourcesMetaData dataSourcesMetaData;
/**
* 缓存的数据库元数据,避免频繁访问数据库系统表:
* - 表结构信息
* - 索引信息
* - 约束信息
*/
private final CachedDatabaseMetaData cachedDatabaseMetaData;
/**
* 数据库类型(MySQL/Oracle/PostgreSQL等),用于:
* - SQL方言适配
* - 分页语法生成
* - DDL语句转换
*/
private final DatabaseType databaseType;
分析到这里就可以了解到,shardingsphere兼容JDBC规范的是采用基于适配器模式的方式对JDBC规范的提供的接口进行重新重写。使用shading-jdbc和使用原生的jdbc没有什么区别,都是使用jdbc规范提供的接口进行操作数据库的。这里只分析了ShardingSphereDataSource,ShardingSphereConnection、ShardingSphereStatement、ShardingSpherePreparedStatement等对象也是使用基于适配器模式的方式进行重写JDBC规范提供Connection、Statement、PreparedStatement等接口。
2.3 全局上下文管理者分析
在ShardingSphere 4.x版本之前,存在一套较复杂的运行时上下文体系,主要用于区分不同模式(如单数据源、多数据源、脱敏、影子库等),使用RuntimeContext、MultipleDataSourcesRuntimeContext、ShardingRuntimeContext 等来进行上下文管理:
-
顶层接口:RuntimeContext
-
抽象类:AbstractRuntimeContext
-
单数据源:SingleDataSourceRuntimeContext
-
EncryptRuntimeContext -
ShadowRuntimeContext
-
-
多数据源:MultipleDataSourcesRuntimeContext
-
MasterSlaveRuntimeContext -
ShardingRuntimeContext
-
-
-
在5.x版本后被重构成ContextManager + MetaDataContexts
[4.x] [5.x]
RuntimeContext ContextManager
├─ SingleDataSourceRuntimeContext ├─ MetaDataContexts
│ ├─ EncryptRuntimeContext │ └─ Map<String, ShardingSphereDatabase>
│ └─ ShadowRuntimeContext │ └─ ShardingSphereRuleMetaData(EncryptRule/ShadowRule...)
└─ MultipleDataSourcesRuntimeContext └─ InstanceContext
├─ MasterSlaveRuntimeContext
└─ ShardingRuntimeContext
我们以5.x版本为例
-
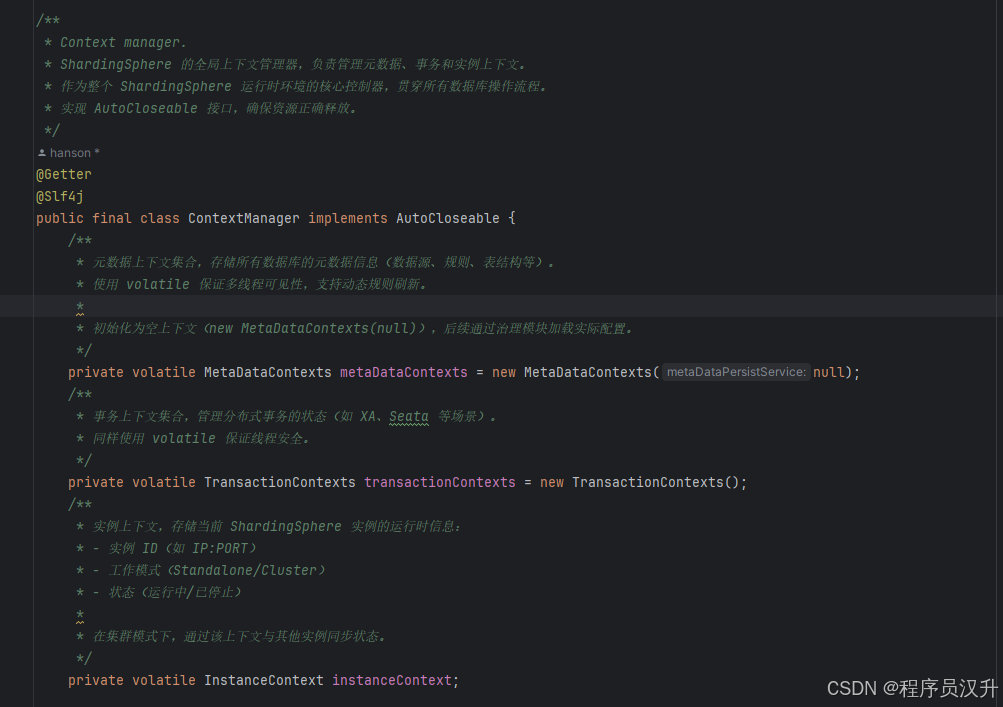
首先看
ContextManager类/** * Context manager. * ShardingSphere 的全局上下文管理器,负责管理元数据、事务和实例上下文。 * 作为整个 ShardingSphere 运行时环境的核心控制器,贯穿所有数据库操作流程。 * 实现 AutoCloseable 接口,确保资源正确释放。 */ @Getter @Slf4j public final class ContextManager implements AutoCloseable { /** * 元数据上下文集合,存储所有数据库的元数据信息(数据源、规则、表结构等)。 * 使用 volatile 保证多线程可见性,支持动态规则刷新。 * * 初始化为空上下文(new MetaDataContexts(null)),后续通过治理模块加载实际配置。 */ private volatile MetaDataContexts metaDataContexts = new MetaDataContexts(null); /** * 事务上下文集合,管理分布式事务的状态(如 XA、Seata 等场景)。 * 同样使用 volatile 保证线程安全。 */ private volatile TransactionContexts transactionContexts = new TransactionContexts(); /** * 实例上下文,存储当前 ShardingSphere 实例的运行时信息: * - 实例 ID(如 IP:PORT) * - 工作模式(Standalone/Cluster) * - 状态(运行中/已停止) * * 在集群模式下,通过该上下文与其他实例同步状态。 */ private volatile InstanceContext instanceContext; //...剩下代码 }ContextManager中三个重要的属性,metaDataContexts用于存储所有数据库的元数据信息,这是个非常非常核心的属性,transactionContexts用于管理分布式事务,instanceContext用于储存实例。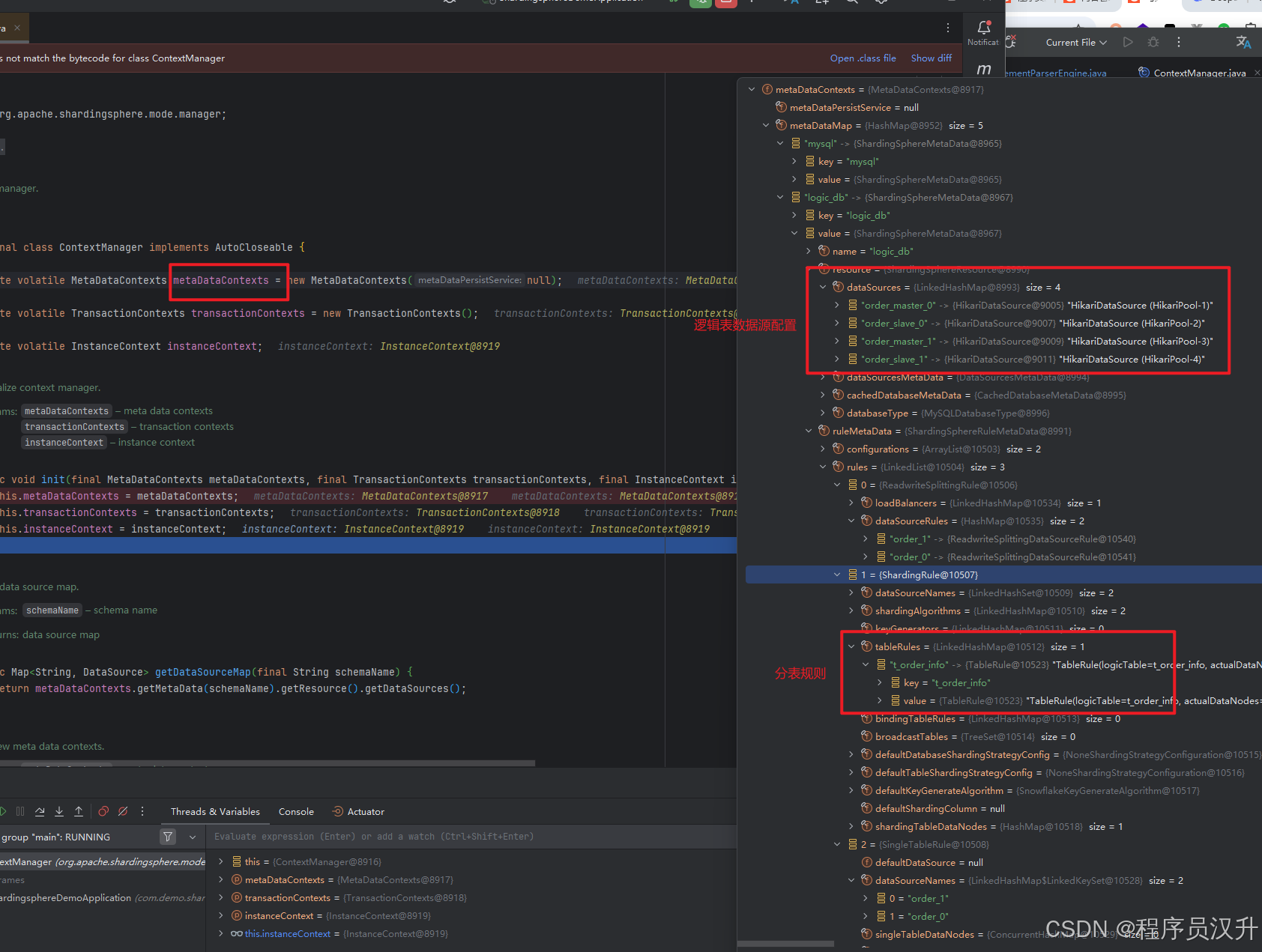
-
再深挖一下
MetaDataContexts类/** * 元数据上下文容器类,包含ShardingSphere的所有元数据上下文信息。 * 实现了AutoCloseable接口,用于在关闭时释放资源。 */ @RequiredArgsConstructor// Lombok注解,自动生成包含所有final字段的构造函数 @Getter// Lombok注解,自动生成所有字段的getter方法 public final class MetaDataContexts implements AutoCloseable { // 元数据持久化服务,负责元数据的存储和读取 private final MetaDataPersistService metaDataPersistService; // 存储所有schema的元数据,key为schema名称,value为对应的元数据 private final Map<String, ShardingSphereMetaData> metaDataMap; // 全局规则元数据,适用于所有schema的规则 private final ShardingSphereRuleMetaData globalRuleMetaData; // 执行引擎,用于任务执行 private final ExecutorEngine executorEngine; // 优化器上下文,包含SQL优化相关的信息 private final OptimizerContext optimizerContext; // 配置属性,包含ShardingSphere实例的所有配置项 private final ConfigurationProperties props; //...剩下代码 }metaDataPersistService负责元数据的存储和读取,metaDataMap存储数据库的相关元数据,globalRuleMetaData用来定义规则,executorEngine是执行引擎,optimizerContext是sql的优化引擎,props表示实例的配置项 -
ShardingSphereMetaData元数据类/** * ShardingSphere 元数据类。 * 该类封装了某个逻辑数据库(逻辑库)的资源、规则、模式(schema)等元信息, * 用于支持分库分表、读写分离、数据加密等功能。 */ @RequiredArgsConstructor @Getter public final class ShardingSphereMetaData { /** * 逻辑数据库名称,对应 ShardingSphere 配置的逻辑库名。 */ private final String name; /** * 数据源及元数据资源封装类,包含了数据源、数据源元数据、数据库类型等。 */ private final ShardingSphereResource resource; /** * ShardingSphere 中的规则元数据(例如:分片规则、加密规则、读写分离规则等) */ private final ShardingSphereRuleMetaData ruleMetaData; /** * 所有 schema 的映射,key 是 schema 名称,value 是对应的 ShardingSphereSchema 对象。 */ private final Map<String, ShardingSphereSchema> schemas; //...剩下代码 }ShardingSphereMetaData装了某个逻辑数据库(逻辑库)的资源、规则、模式(schema)等元信息,用于支持分库分表、读写分离、数据加密等功能。
-
ShardingSphereResource类/** * ShardingSphere 物理数据源资源管理器,统一管理所有底层数据库连接池及其元数据。 * 1. 维护数据源的生命周期(创建、销毁) * 2. 提供数据库类型和元数据的快速访问 * 3. 支持多实例模式(如读写分离的主从库) */ @RequiredArgsConstructor @Getter public final class ShardingSphereResource { /** * 数据源集合(Key为数据源名称,Value为物理数据源对象) * 示例: * { * "ds_0": HikariDataSource@1234, * "ds_1": DruidDataSource@5678 * } */ private final Map<String, DataSource> dataSources; /** * 数据源元数据,包含: * - 数据源URL、用户名等连接信息 * - 实例分组(如主从库的读写分离组) */ private final DataSourcesMetaData dataSourcesMetaData; /** * 缓存的数据库元数据,避免频繁访问数据库系统表: * - 表结构信息 * - 索引信息 * - 约束信息 */ private final CachedDatabaseMetaData cachedDatabaseMetaData; /** * 数据库类型(MySQL/Oracle/PostgreSQL等),用于: * - SQL方言适配 * - 分页语法生成 * - DDL语句转换 */ private final DatabaseType databaseType; //...剩下代码 } -
SQLStatementParserEngineFactory解析引擎工厂类/** * SQL 语句解析引擎工厂类。 * * 该类用于为指定数据库类型创建或获取一个 SQL 语句解析器(SQLStatementParserEngine)。 * 它采用缓存池的方式复用解析器实例,避免重复创建,提高性能。 * * 此类为工具类,禁止实例化,因此使用了私有构造器。 */ @NoArgsConstructor(access = AccessLevel.PRIVATE) // 私有构造器,禁止外部实例化 public final class SQLStatementParserEngineFactory { /** * 缓存不同数据库类型对应的 SQL 语句解析器。 * * key:数据库类型(如 "MySQL"、"PostgreSQL") * value:对应的 SQLStatementParserEngine 实例 * * 使用 ConcurrentHashMap 保证线程安全,适用于并发场景。 */ private static final Map<String, SQLStatementParserEngine> ENGINES = new ConcurrentHashMap<>(); /** * 获取指定数据库类型的 SQL 语句解析引擎。 * * 如果缓存中已存在对应类型的解析器,则直接返回; * 如果不存在,则使用提供的缓存选项和是否解析注释的配置创建一个新的解析器并缓存。 * * @param databaseType 数据库类型(如 MySQL、PostgreSQL 等) * @param sqlStatementCacheOption SQL 语句缓存选项,用于缓存 SQL 语句解析结果 * @param parseTreeCacheOption 解析树缓存选项,用于缓存 SQL 的语法树 * @param isParseComment 是否解析 SQL 中的注释(true 表示解析,false 表示忽略注释) * @return SQL 语句解析引擎 */ public static SQLStatementParserEngine getSQLStatementParserEngine( final String databaseType, final CacheOption sqlStatementCacheOption, final CacheOption parseTreeCacheOption, final boolean isParseComment) { // 先尝试从缓存中获取对应数据库类型的解析器 SQLStatementParserEngine result = ENGINES.get(databaseType); // 如果缓存中没有,则创建新的解析器并放入缓存(使用 computeIfAbsent 保证线程安全且只初始化一次) if (null == result) { result = ENGINES.computeIfAbsent(databaseType, key -> new SQLStatementParserEngine(key, sqlStatementCacheOption, parseTreeCacheOption, isParseComment) ); } // 返回解析器 return result; } }-
CacheOption是 ShardingSphere 用于控制缓存策略(大小、过期时间等)的配置类; -
isParseComment可用于判断是否对注释中的内容做语法分析,这对一些场景如 SQL Hint(例如 MySQL 的/*+ HINT */)非常重要; -
此类为典型的 懒汉式单例 + 缓存工厂,避免重复初始化同类型对象;
-
computeIfAbsent保证了线程安全的同时只会执行一次对象构造。
-
-
ShardingSphereSQLParserEngineSQL 解析引擎/** * ShardingSphere SQL 解析引擎。 * * 该类统一封装了标准 SQL 和 DistSQL 的解析能力。 * 对于标准 SQL,使用 SQLStatementParserEngine 进行解析; * 对于 DistSQL(ShardingSphere 自定义的分布式 SQL),使用 DistSQLStatementParserEngine。 * * 支持使用缓存以提高解析性能,并在遇到解析异常时,尝试使用 DistSQL 解析作为兜底策略。 */ public final class ShardingSphereSQLParserEngine { /** * 标准 SQL 解析引擎。 * 该解析器支持对 MySQL、PostgreSQL、Oracle 等数据库类型的标准 SQL 语法进行解析。 */ private final SQLStatementParserEngine sqlStatementParserEngine; /** * DistSQL 解析引擎。 * 用于解析 ShardingSphere 提供的自定义 SQL(如资源管理、规则定义等)。 */ private final DistSQLStatementParserEngine distSQLStatementParserEngine; /** * 构造方法。 * * @param databaseTypeName 数据库类型名称(如 "MySQL"、"PostgreSQL") * @param config 解析器配置,包括缓存选项、是否解析注释等 */ public ShardingSphereSQLParserEngine(final String databaseTypeName, final ParserConfiguration config) { // 获取标准 SQL 的解析引擎,使用工厂方法并带有缓存选项 sqlStatementParserEngine = SQLStatementParserEngineFactory.getSQLStatementParserEngine( databaseTypeName, config.getSqlStatementCacheOption(), config.getParseTreeCacheOption(), config.isParseComment()); // 初始化 DistSQL 解析引擎(不区分数据库类型) distSQLStatementParserEngine = new DistSQLStatementParserEngine(); } /* * SkyWalking 监控系统相关提示: * 如果将来该类的 API 被修改,需要同步为 SkyWalking 提供新的插件适配。 * * 详见插件开发文档: * https://github.com/apache/skywalking/blob/master/docs/en/guides/Java-Plugin-Development-Guide.md */ /** * 解析 SQL 语句。 * * 优先使用标准 SQL 解析器进行解析;如果解析失败(抛出异常), * 将尝试使用 DistSQL 解析器对去除注释后的 SQL 再次进行解析; * 若仍失败,则抛出最初的异常。 * * @param sql 待解析的 SQL 字符串 * @param useCache 是否使用解析缓存(true 表示启用缓存,false 表示每次都解析) * @return SQLStatement 对象,表示解析后的 SQL 抽象语法树(AST) */ public SQLStatement parse(final String sql, final boolean useCache) { try { // 尝试使用标准 SQL 解析器进行解析 return sqlStatementParserEngine.parse(sql, useCache); } catch (final SQLParsingException | ParseCancellationException | UncheckedExecutionException originalEx) { try { // 如果标准 SQL 解析失败,尝试使用 DistSQL 解析器解析去除注释后的 SQL String trimSQL = SQLUtil.trimComment(sql); return distSQLStatementParserEngine.parse(trimSQL); } catch (final SQLParsingException ignored) { // DistSQL 解析仍然失败,则抛出原始异常 throw originalEx; } } } }-
sqlStatementParserEngine.parse()失败后并没有立即抛出,而是用SQLUtil.trimComment(sql)去除注释,再使用distSQLStatementParserEngine尝试解析; -
useCache是为了优化性能,如果设置为 true,将使用语法解析结果的缓存; -
UncheckedExecutionException是缓存执行中抛出的包装异常,常见于 Guava 缓存逻辑; -
如果两个解析器都失败,最终仍抛出原始异常,便于上层保留调试信息。
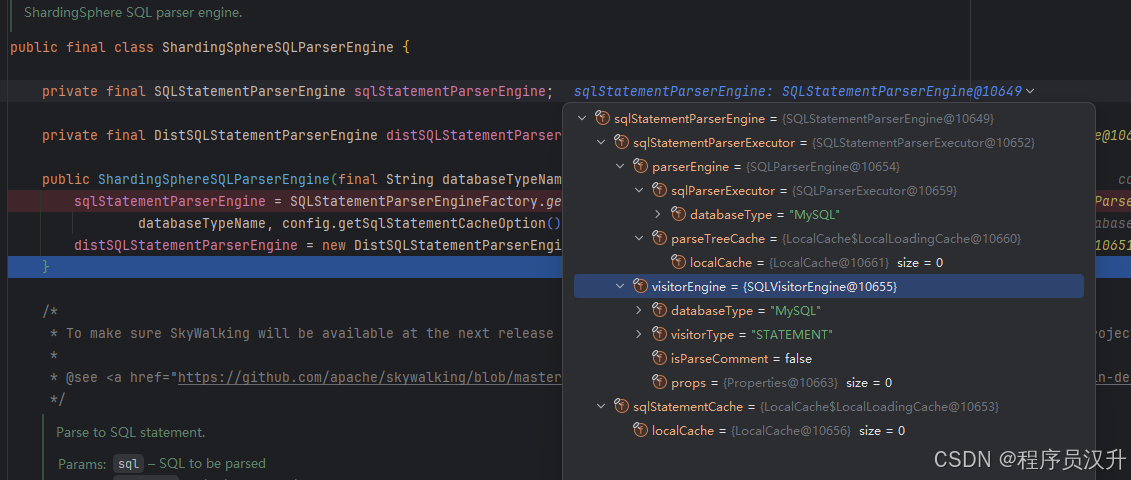
-
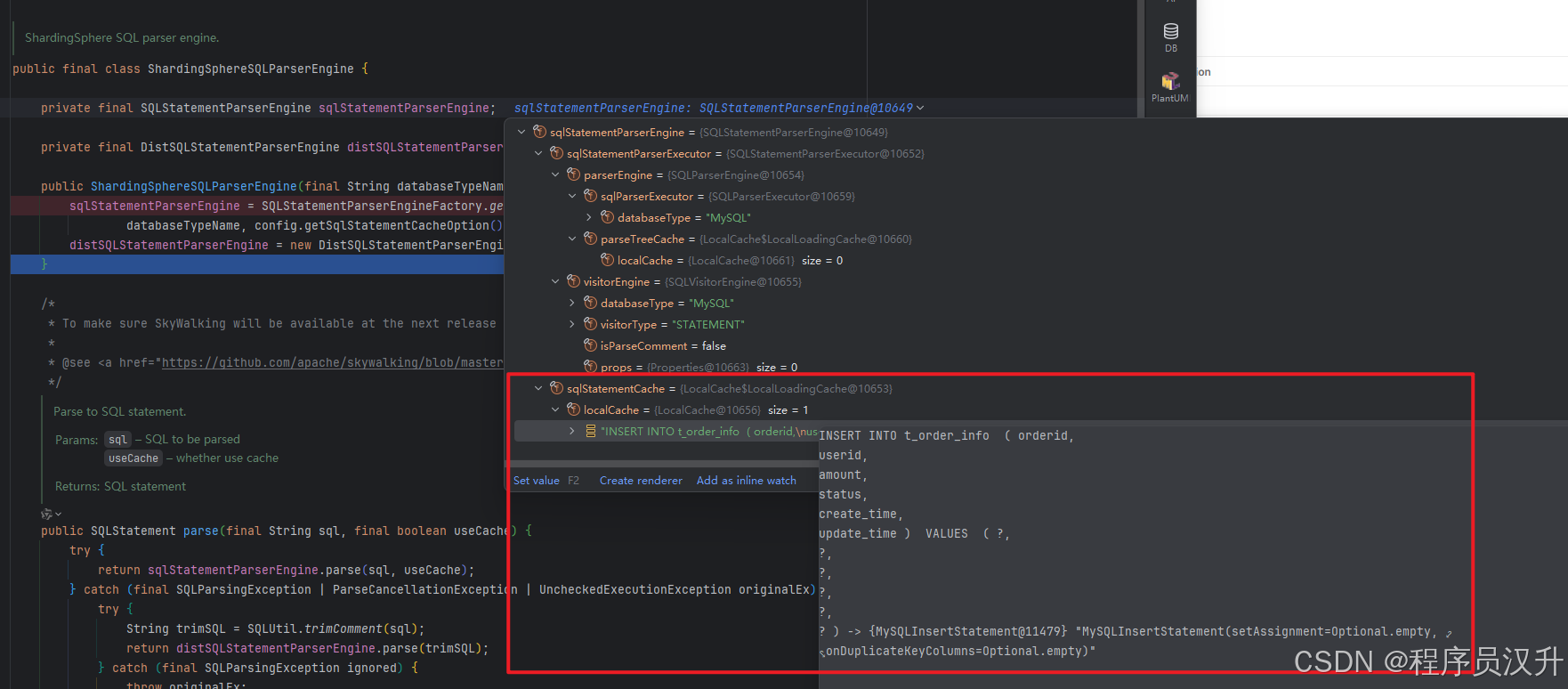
添加完数据,缓存中会存在记录
-
再执行一次查询
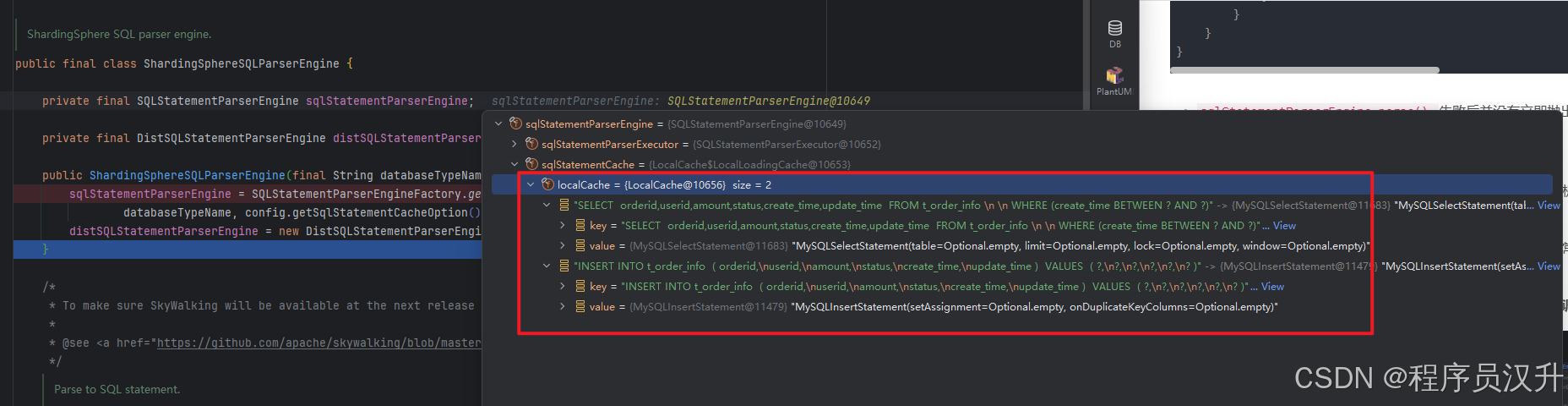
-
-
上述
ShardingSphereMetaData封装了某个逻辑数据库(逻辑库)的资源、规则、模式(schema)等元信息,用于支持分库分表、读写分离、数据加密等功能。其中有一个schemas属性存储了所有 schema 的映射,key 是 schema 名称,value 是对应的ShardingSphereSchema对象。接下来详细看看这个类/** * ShardingSphere 的逻辑 Schema 对象,封装了当前逻辑库中所有表的元数据信息。 */ @Getter public final class ShardingSphereSchema { // 存储表名与其对应的元数据信息(键为小写表名) private final Map<String, TableMetaData> tables; /** * 默认构造函数,初始化空的表结构集合。 */ @SuppressWarnings("CollectionWithoutInitialCapacity") public ShardingSphereSchema() { tables = new ConcurrentHashMap<>(); } /** * 通过已有表结构 Map 构造 Schema。 * 会将所有表名转换为小写,以便忽略大小写敏感。 * * @param tables 表结构信息映射 */ public ShardingSphereSchema(final Map<String, TableMetaData> tables) { this.tables = new ConcurrentHashMap<>(tables.size(), 1); tables.forEach((key, value) -> this.tables.put(key.toLowerCase(), value)); } //...剩下代码 }tables属性是一个map,保存了表的相关的元数据,
ShardingSphereSchema的其他方法都有关于这个tables属性的,如从tables获取某个表的元数据,删除某个表的元数据、获取所有的表的表名等方法。TableMetaData类是具体保存表相关元数据的类,TableMetaData类如下几个重要的数据:/** * TableMetaData 表示一张逻辑表的元数据信息。 * 包含字段(columns)、索引(indexes)、约束(constraints)等结构信息。 */ @Getter @EqualsAndHashCode @ToString public final class TableMetaData { // 表名 private final String name; // 列信息,key 为列名(小写),value 为 ColumnMetaData 对象 private final Map<String, ColumnMetaData> columns; // 索引信息,key 为索引名(小写),value 为 IndexMetaData 对象 private final Map<String, IndexMetaData> indexes; // 表约束信息(如主键、唯一约束等),key 为约束名(小写),value 为 ConstraintMetaData 对象 private final Map<String, ConstraintMetaData> constrains; // 按顺序记录所有列的名称(原始大小写) private final List<String> columnNames = new ArrayList<>(); // 主键列名称列表(小写) private final List<String> primaryKeyColumns = new ArrayList<>(); /** * 默认构造函数,构造一个空表结构。 */ public TableMetaData() { this("", Collections.emptyList(), Collections.emptyList(), Collections.emptyList()); } /** * 构造函数,创建表结构元数据。 * * @param name 表名 * @param columnMetaDataList 列元数据集合 * @param indexMetaDataList 索引元数据集合 * @param constraintMetaDataList 约束元数据集合 */ public TableMetaData(final String name, final Collection<ColumnMetaData> columnMetaDataList, final Collection<IndexMetaData> indexMetaDataList, final Collection<ConstraintMetaData> constraintMetaDataList) { this.name = name; columns = getColumns(columnMetaDataList); indexes = getIndexes(indexMetaDataList); constrains = getConstrains(constraintMetaDataList); } /** * 将列集合转换为 Map,记录列元数据,并填充 columnNames 和 primaryKeyColumns。 * * @param columnMetaDataList 列元数据集合 * @return 列名到列元数据的映射 */ private Map<String, ColumnMetaData> getColumns(final Collection<ColumnMetaData> columnMetaDataList) { Map<String, ColumnMetaData> result = new LinkedHashMap<>(columnMetaDataList.size(), 1); for (ColumnMetaData each : columnMetaDataList) { String lowerColumnName = each.getName().toLowerCase(); result.put(lowerColumnName, each); columnNames.add(each.getName()); if (each.isPrimaryKey()) { primaryKeyColumns.add(lowerColumnName); } } return result; } /** * 将索引集合转换为 Map。 * * @param indexMetaDataList 索引元数据集合 * @return 索引名到索引元数据的映射 */ private Map<String, IndexMetaData> getIndexes(final Collection<IndexMetaData> indexMetaDataList) { Map<String, IndexMetaData> result = new LinkedHashMap<>(indexMetaDataList.size(), 1); for (IndexMetaData each : indexMetaDataList) { result.put(each.getName().toLowerCase(), each); } return result; } /** * 将约束集合转换为 Map。 * * @param constraintMetaDataList 约束元数据集合 * @return 约束名到约束元数据的映射 */ private Map<String, ConstraintMetaData> getConstrains(final Collection<ConstraintMetaData> constraintMetaDataList) { Map<String, ConstraintMetaData> result = new LinkedHashMap<>(constraintMetaDataList.size(), 1); for (ConstraintMetaData each : constraintMetaDataList) { result.put(each.getName().toLowerCase(), each); } return result; } } /** * 字段元数据 */ @RequiredArgsConstructor @Getter @EqualsAndHashCode @ToString public final class ColumnMetaData { private final String name; private final int dataType; private final boolean primaryKey; private final boolean generated; private final boolean caseSensitive; } /** * 索引元数据 */ @RequiredArgsConstructor @Getter @EqualsAndHashCode @ToString public final class IndexMetaData { private final String name; }columns属性保存的是表所有的字段相关的元数据,indexes属性保存是所有的索引的元数据,columnNames属性保存了所有的字段名称,primaryKeyColumns属性保存了所有的主键。ColumnMetaData类是表字段元数据类,该类包括了字段的名称、字段的类型、字段的类型名称、是否是主键、是否是自动生成的、是否区分大小写敏感这些属性。IndexMetaData是索引字段元数据类,只有一个名称属性。TableMetaData类的构造方法,对name、indexes、columns和constrains属性进行初始化,该构造方法的入参为columnMetaDataList和indexMetaDataList,columnMetaDataList是保存了ColumnMetaData对象的集合,indexMetaDataList是保存了IndexMetaData集合,TableMetaData类的构造方法如下:/** * 构造函数,创建表结构元数据。 * * @param name 表名 * @param columnMetaDataList 列元数据集合 * @param indexMetaDataList 索引元数据集合 * @param constraintMetaDataList 约束元数据集合 */ public TableMetaData(final String name, final Collection<ColumnMetaData> columnMetaDataList, final Collection<IndexMetaData> indexMetaDataList, final Collection<ConstraintMetaData> constraintMetaDataList) { this.name = name; columns = getColumns(columnMetaDataList); indexes = getIndexes(indexMetaDataList); constrains = getConstrains(constraintMetaDataList); } /** * 将列集合转换为 Map,记录列元数据,并填充 columnNames 和 primaryKeyColumns。 * * @param columnMetaDataList 列元数据集合 * @return 列名到列元数据的映射 */ private Map<String, ColumnMetaData> getColumns(final Collection<ColumnMetaData> columnMetaDataList) { Map<String, ColumnMetaData> result = new LinkedHashMap<>(columnMetaDataList.size(), 1); for (ColumnMetaData each : columnMetaDataList) { String lowerColumnName = each.getName().toLowerCase(); result.put(lowerColumnName, each); columnNames.add(each.getName()); if (each.isPrimaryKey()) { primaryKeyColumns.add(lowerColumnName); } } return result; } /** * 将索引集合转换为 Map。 * * @param indexMetaDataList 索引元数据集合 * @return 索引名到索引元数据的映射 */ private Map<String, IndexMetaData> getIndexes(final Collection<IndexMetaData> indexMetaDataList) { Map<String, IndexMetaData> result = new LinkedHashMap<>(indexMetaDataList.size(), 1); for (IndexMetaData each : indexMetaDataList) { result.put(each.getName().toLowerCase(), each); } return result; } /** * 将约束集合转换为 Map。 * * @param constraintMetaDataList 约束元数据集合 * @return 约束名到约束元数据的映射 */ private Map<String, ConstraintMetaData> getConstrains(final Collection<ConstraintMetaData> constraintMetaDataList) { Map<String, ConstraintMetaData> result = new LinkedHashMap<>(constraintMetaDataList.size(), 1); for (ConstraintMetaData each : constraintMetaDataList) { result.put(each.getName().toLowerCase(), each); } return result; }getColumns方法是将columnMetaDataList集合转换为Map<String, ColumnMetaData>将ColumnMetaData元数据缓存起来,getIndexes方法是将indexMetaDataList集合转换为Map<String, IndexMetaData>进行IndexMetaData元数据缓存起来。分析完
TableMetaData,接下来分析下ShardingSphereResource中的cachedDatabaseMetaData属性,如下:/** * 缓存的数据库元数据,避免频繁访问数据库系统表: * - 表结构信息 * - 索引信息 * - 约束信息 */ private final CachedDatabaseMetaData cachedDatabaseMetaData;一些数据库的连接配置
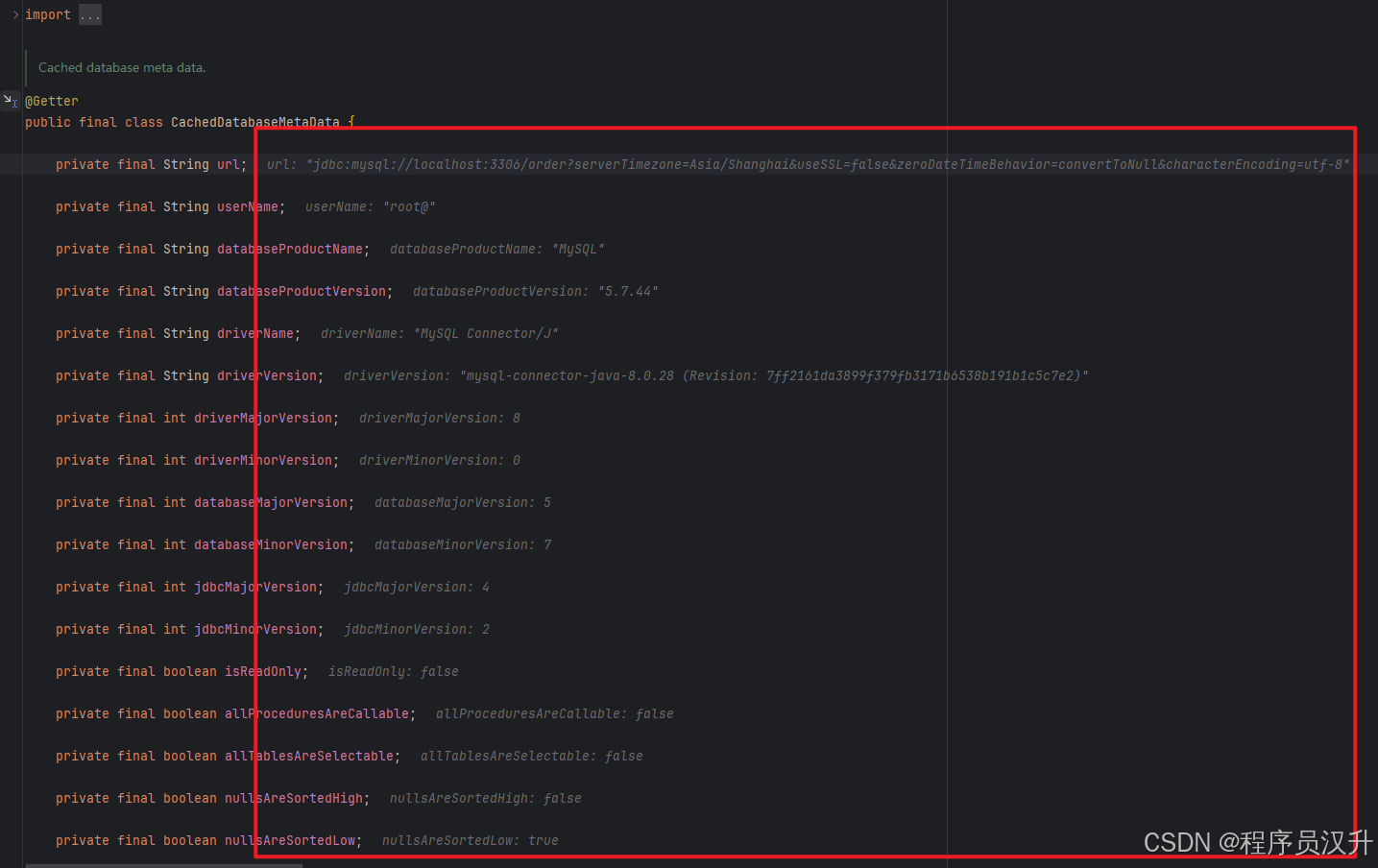
-
接下来看表信息加载过程,
TableMetaDataLoader类/** * 表元数据加载器。 * 提供静态方法用于从数据源中加载某个表的结构信息(字段、索引等)。 */ @NoArgsConstructor(access = AccessLevel.PRIVATE) public final class TableMetaDataLoader { /** * 加载指定表的元数据信息。 * * @param dataSource 数据源(一般是实际数据库连接池) * @param tableNamePattern 表名或匹配模式(如支持大小写或通配符) * @param databaseType 数据库类型(如 MySQL、PostgreSQL,用于适配差异) * @return 表元数据,如果表不存在则返回 Optional.empty() * @throws SQLException SQL 异常 */ public static Optional<TableMetaData> load(final DataSource dataSource, final String tableNamePattern, final DatabaseType databaseType) throws SQLException { // 使用 MetaDataLoaderConnectionAdapter 包装 JDBC Connection,屏蔽不同数据库差异 try (MetaDataLoaderConnectionAdapter connectionAdapter = new MetaDataLoaderConnectionAdapter(databaseType, dataSource.getConnection())) { // 根据数据库类型格式化表名(比如大小写敏感问题) String formattedTableNamePattern = databaseType.formatTableNamePattern(tableNamePattern); // 判断表是否存在,存在则加载元数据 return isTableExist(connectionAdapter, formattedTableNamePattern) ? Optional.of(new TableMetaData(tableNamePattern, ColumnMetaDataLoader.load( connectionAdapter, formattedTableNamePattern, databaseType), IndexMetaDataLoader.load(connectionAdapter, formattedTableNamePattern), Collections.emptyList())) : Optional.empty(); } } /** * 判断指定表是否存在于当前连接的数据库中。 * * @param connection JDBC 连接 * @param tableNamePattern 表名或匹配模式 * @return true 表存在;false 表不存在 * @throws SQLException SQL 异常 */ private static boolean isTableExist(final Connection connection, final String tableNamePattern) throws SQLException { // 使用 JDBC 元数据接口获取当前库中是否有匹配表 try (ResultSet resultSet = connection.getMetaData().getTables(connection.getCatalog(), connection.getSchema(), tableNamePattern, null)) { return resultSet.next(); // 有记录表示表存在 } } }TableMetaDataLoader类只有一个
load加载方法,该方法首先从DataSource获取到数据库连接Connection,然后使用ColumnMetaDataLoader加载器加载表字段元数据ColumnMetaData的集合,使用IndexMetaDataLoader加载器加载索引元数据IndexMetaData的集合,并把表字段元数据ColumnMetaData的集合和索引元数据IndexMetaData的集合作为创建TableMetaData的参数。ColumnMetaDataLoader加载方法如下:/** * 加载表的所有字段元数据。 * * @param connection JDBC 连接 * @param tableNamePattern 表名(完全匹配) * @param databaseType 数据库类型(用于适配不同 SQL 方言) * @return 字段元数据集合 * @throws SQLException SQL 异常 */ public static Collection<ColumnMetaData> load(final Connection connection, final String tableNamePattern, final DatabaseType databaseType) throws SQLException { Collection<ColumnMetaData> result = new LinkedList<>(); // 加载主键字段名 Collection<String> primaryKeys = loadPrimaryKeys(connection, tableNamePattern); //字段名称集合 List<String> columnNames = new ArrayList<>(); //字段类型集合 List<Integer> columnTypes = new ArrayList<>(); //是否是主键集合 List<Boolean> isPrimaryKeys = new ArrayList<>(); //字段是否是大小写敏感 List<Boolean> isCaseSensitives = new ArrayList<>(); //使用原生的jdbc的connection获取字段元数据,并且对字段元数据进行遍历 try (ResultSet resultSet = connection.getMetaData().getColumns(connection.getCatalog(), connection.getSchema(), tableNamePattern, "%")) { while (resultSet.next()) { //字段名称 String tableName = resultSet.getString(TABLE_NAME); if (Objects.equals(tableNamePattern, tableName)) { String columnName = resultSet.getString(COLUMN_NAME); //字段类型 columnTypes.add(resultSet.getInt(DATA_TYPE)); //是否是主键 isPrimaryKeys.add(primaryKeys.contains(columnName)); columnNames.add(columnName); } } } //判断表字段是否大小写敏感 try (Statement statement = connection.createStatement(); ResultSet resultSet = statement.executeQuery(generateEmptyResultSQL(tableNamePattern, databaseType))) { for (int i = 0; i < columnNames.size(); i++) { boolean generated = resultSet.getMetaData().isAutoIncrement(i + 1); isCaseSensitives.add(resultSet.getMetaData().isCaseSensitive(resultSet.findColumn(columnNames.get(i)))); result.add(new ColumnMetaData(columnNames.get(i), columnTypes.get(i), isPrimaryKeys.get(i), generated, isCaseSensitives.get(i))); } } return result; }ColumnMetaDataLoader的load方法使用原生JDBC的Connection对象获取表相关的元数据,并将表的字段名称、字段类型、是否是主键以及是否大小写敏感作为参数创建ColumnMetaData。IndexMetaDataLoader的load方法也是使用原生的JDBC对象获取字段索引的信息,并且将获取的字段索引信息构建IndexMetaData。load的方法如下:/** * 索引元数据加载器,用于从数据库加载指定表的索引信息。 */ @NoArgsConstructor(access = AccessLevel.PRIVATE) public final class IndexMetaDataLoader { // 索引名称字段,ResultSet中列名,通常是 getIndexInfo 查询返回的字段之一 private static final String INDEX_NAME = "INDEX_NAME"; // Oracle 特殊错误码,如果在视图上调用 getIndexInfo,会抛出该错误码的 SQLException private static final int ORACLE_VIEW_NOT_APPROPRIATE_VENDOR_CODE = 1702; /** * 加载表的索引元数据列表。 * * 注意:在某些 JDBC 实现中(如 Oracle),getIndexInfo 返回的结果中可能包含不是索引的统计信息,这些记录的 INDEX_NAME 为 null,应当跳过。 * * @param connection JDBC 连接对象 * @param table 表名 * @return 索引元数据集合 * @throws SQLException 如果数据库操作失败,则抛出异常 */ @SuppressWarnings("CollectionWithoutInitialCapacity") public static Collection<IndexMetaData> load(final Connection connection, final String table) throws SQLException { // 用于存放返回的索引元数据,使用 HashSet 自动去重 Collection<IndexMetaData> result = new HashSet<>(); try ( // 调用 JDBC 的元数据接口获取指定表的索引信息 ResultSet resultSet = connection.getMetaData().getIndexInfo( connection.getCatalog(), // 当前 catalog(一般可为 null) connection.getSchema(), // 当前 schema(根据数据库类型决定是否生效) table, // 表名 false, // unique: 是否只返回唯一索引(false 表示全部索引) false // approximate: 是否允许返回近似结果(false 表示精确结果) ) ) { while (resultSet.next()) { // 获取索引名字段 String indexName = resultSet.getString(INDEX_NAME); // Oracle 等数据库中可能会返回一些统计信息,它们的 INDEX_NAME 为 null,应当跳过 if (null != indexName) { result.add(new IndexMetaData(indexName)); } } } catch (final SQLException ex) { // 如果是 Oracle 数据库中视图引起的 1702 错误,不抛出,表示忽略该异常(可能是非表结构) if (ORACLE_VIEW_NOT_APPROPRIATE_VENDOR_CODE != ex.getErrorCode()) { throw ex; } } return result; } }从上面源码分析可知,
ShardingSphereSchema包含了TableMetaData,TableMetaData包含了ColumnMetaData和IndexMetaData,获取这些元数据,是通过原生JDBC来获取数据库表相关元数据信息。还会采用ShardingTableMetaDataBuilder建造器对TableMetaData进行构建。ShardingTableMetaDataBuilder类如下:/** * ShardingTableMetaDataBuilder 类用于构建分片表的元数据,结合 ShardingRule 和表的元数据加载。 * 该类实现了 RuleBasedTableMetaDataBuilder 接口,用于构建、修饰和验证表的元数据。 */ public final class ShardingTableMetaDataBuilder implements RuleBasedTableMetaDataBuilder<ShardingRule> { @Override public Map<String, TableMetaData> load(final Collection<String> tableNames, final ShardingRule rule, final SchemaBuilderMaterials materials) throws SQLException { // 筛选出需要加载的表名,包含 ShardingRule 中的表规则或者广播表 Collection<String> needLoadTables = tableNames.stream().filter(each -> rule.findTableRule(each).isPresent() || rule.isBroadcastTable(each)).collect(Collectors.toList()); // 如果没有需要加载的表,直接返回空的 Map if (needLoadTables.isEmpty()) { return Collections.emptyMap(); } // 判断是否启用表元数据检查 boolean isCheckingMetaData = materials.getProps().getValue(ConfigurationPropertyKey.CHECK_TABLE_METADATA_ENABLED); // 获取加载表元数据的材料集合 Collection<TableMetaDataLoaderMaterial> tableMetaDataLoaderMaterials = TableMetaDataUtil.getTableMetaDataLoadMaterial(needLoadTables, materials, isCheckingMetaData); // 如果没有需要加载的元数据材料,返回空 Map if (tableMetaDataLoaderMaterials.isEmpty()) { return Collections.emptyMap(); } // 加载所有表的元数据 Collection<TableMetaData> tableMetaDataList = TableMetaDataLoaderEngine.load(tableMetaDataLoaderMaterials, materials.getDatabaseType()); // 如果启用了元数据检查,进行检查 if (isCheckingMetaData) { checkTableMetaData(tableMetaDataList, rule); } // 返回表名与表元数据的映射 return getTableMetaDataMap(tableMetaDataList, rule); } @Override public Map<String, TableMetaData> decorate(final Map<String, TableMetaData> tableMetaDataMap, final ShardingRule rule, final SchemaBuilderMaterials materials) { // 对每个表元数据进行修饰,返回修饰后的元数据映射 Map<String, TableMetaData> result = new LinkedHashMap<>(); for (Entry<String, TableMetaData> entry : tableMetaDataMap.entrySet()) { result.put(entry.getKey(), decorate(entry.getKey(), entry.getValue(), rule)); } return result; } /** * 对表元数据进行修饰,结合分片规则修饰表的列、索引和约束信息 * * @param tableName 表名 * @param tableMetaData 表元数据 * @param shardingRule 分片规则 * @return 修饰后的表元数据 */ private TableMetaData decorate(final String tableName, final TableMetaData tableMetaData, final ShardingRule shardingRule) { // 如果找到了该表的分片规则,进行修饰;否则返回原始表元数据 return shardingRule.findTableRule(tableName).map(tableRule -> new TableMetaData(tableName, getColumnMetaDataList(tableMetaData, tableRule), getIndexMetaDataList(tableMetaData, tableRule), getConstraintMetaDataList(tableMetaData, shardingRule, tableRule))).orElse(tableMetaData); } //...剩下代码 }ShardingTableMetaDataBuilder的
decorate方法对TableMetaData进行增强,实际上是对TableMetaData的ColumnMetaData和IndexMetaData进行增强,在对ColumnMetaData增强是,判断ColumnMetaData的字段的值是否是自动生成的,如果该字段的值是自动生成额,则重新创建ColumnMetaData对象,并将ColumnMetaData的generated属性设置为ture,否则不对ColumnMetaData进行增强。对IndexMetaData增强实际上是判断表字段是否具有索引并将索引名称进行返回。
ShardingSphereMetaData还有一个重要的属性cachedDatabaseMetaData,该属性保存了数据库元数据信息,在构造方法中获取该属性,方法如下:/** * 构造缓存的数据库元数据信息。 * * @param dataSources 数据源映射 * @return Optional 包装的 CachedDatabaseMetaData * @throws SQLException 获取连接或元数据失败 */ private static Optional<CachedDatabaseMetaData> createCachedDatabaseMetaData(final Map<String, DataSource> dataSources) throws SQLException { if (dataSources.isEmpty()) { return Optional.empty(); } // 取任意一个数据源的连接进行元数据获取 try (Connection connection = dataSources.values().iterator().next().getConnection()) { return Optional.of(new CachedDatabaseMetaData(connection.getMetaData())); } }createCachedDatabaseMetaData采用原生的JDBC的Connection获取数据库的元数据信息,CachedDatabaseMetaData元数据包括了数据库的账户名称、url、驱动名称、驱动版本等一些数据库的配置信息。到了这里,ShardingSphereMetaData的分析就完成了,ShardingSphereMetaData保存了数据库、表、字段、索引等的元数据信息,这些元数据信息,都是使用原生JDBC的获取得到的。另外,
MetaDataContexts类中还有两个重要的属性,ExecutorEngine执行引擎和OptimizerContext解析引擎,这两个引擎将在后面的文章将会分析到。
2.4 SQL解析引擎
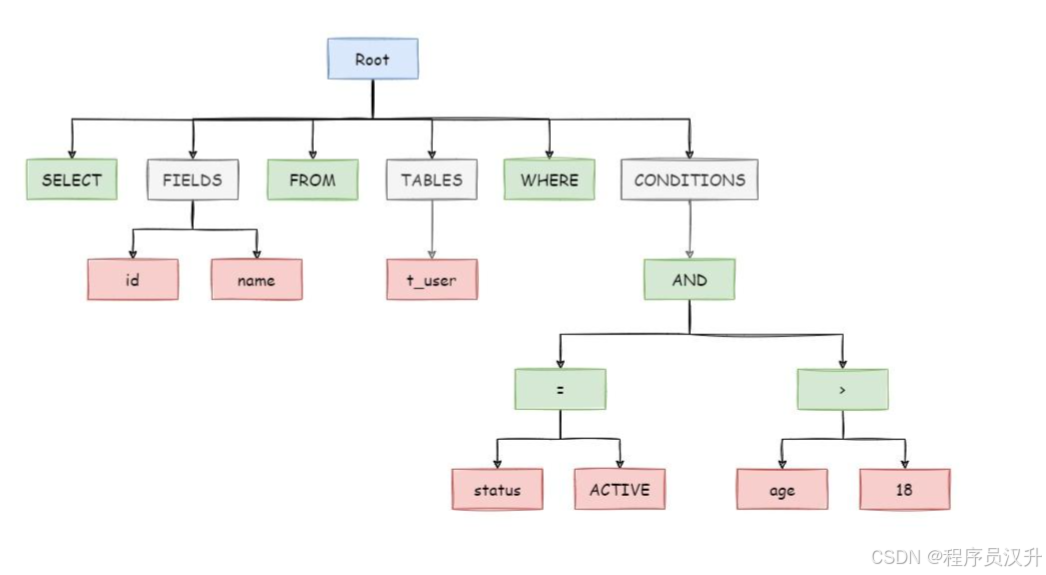
SQL解析是分片流程中的第一步,是由SQL解析引擎完成SQL解析的。SQL解析分为词法解析和语法解析,首先通过词法解析器将SQL语句解析为一个不可再分的单词,然后再使用语法解析器对SQL进行理解,提炼出解析上下文。解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。如下SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析之后的为抽象语法树见下图。
shardingsphere中SQL解析流程最终会将SQL语句解析为 SQLStatement 对象、SQLStatement 包括SQL 片段对象 SQLSegment ,SQLStatement 对象是解析好的SQL对象。如InsertStatement表示SQL插入语句被shardingsphereSQL解析后的对象,该类如下:
public abstract class InsertStatement extends AbstractSQLStatement implements DMLStatement {
// 表示插入的目标表
private SimpleTableSegment table;
// 表示插入语句中指定的列字段,如:INSERT INTO table (col1, col2)...
private InsertColumnsSegment insertColumns;
// 如果是 INSERT ... SELECT 语句,表示其 SELECT 子句部分
private SubquerySegment insertSelect;
// 表示 VALUES 部分,可以有多个 InsertValuesSegment(即插入的多行记录)
private final Collection<InsertValuesSegment> values = new LinkedList<>();
//省略代码
}
SQLSegment 对象包含了位置信息,如InsertColumnsSegment包含了插入字段在sql语句中开始位置和结束位置。如:
@RequiredArgsConstructor
@Getter
public final class InsertColumnsSegment implements SQLSegment {
private final int startIndex;
private final int stopIndex;
private final Collection<ColumnSegment> columns;
}
有了上述的了解,那么来看看SQL解析引擎SQLParserEngine的入口。在前面1ShardingSphereSQLParserEngine类的构造方法中,通过工厂方法获取了SQL的解析引擎
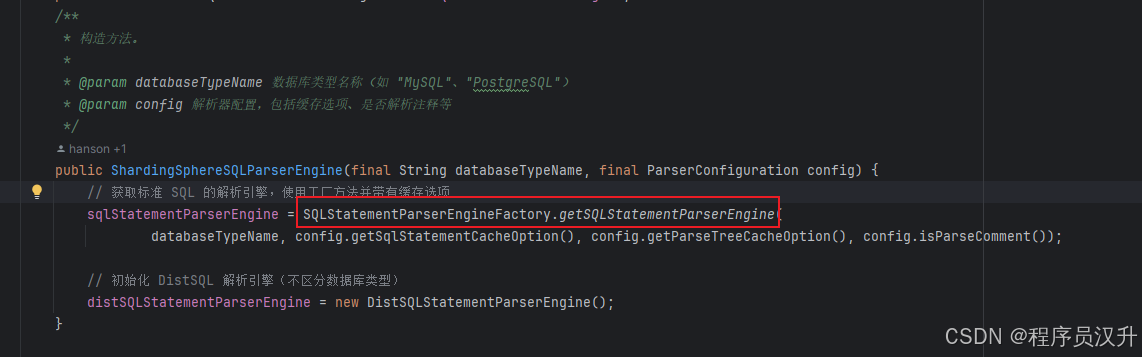
使用SQL引擎工程SQLStatementParserEngineFactory创建了SQLStatementParserEngine,SQLStatementParserEngineFactory类如下:
/**
* SQL 语句解析引擎工厂类。
*
* 该类用于为指定数据库类型创建或获取一个 SQL 语句解析器(SQLStatementParserEngine)。
* 它采用缓存池的方式复用解析器实例,避免重复创建,提高性能。
*
* 此类为工具类,禁止实例化,因此使用了私有构造器。
*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class SQLStatementParserEngineFactory {
/**
* 缓存不同数据库类型对应的 SQL 语句解析器。
*
* key:数据库类型(如 "MySQL"、"PostgreSQL")
* value:对应的 SQLStatementParserEngine 实例
*
* 使用 ConcurrentHashMap 保证线程安全,适用于并发场景。
*/
private static final Map<String, SQLStatementParserEngine> ENGINES = new ConcurrentHashMap<>();
/**
* 获取指定数据库类型的 SQL 语句解析引擎。
*
* 如果缓存中已存在对应类型的解析器,则直接返回;
* 如果不存在,则使用提供的缓存选项和是否解析注释的配置创建一个新的解析器并缓存。
*
* @param databaseType 数据库类型(如 MySQL、PostgreSQL 等)
* @param sqlStatementCacheOption SQL 语句缓存选项,用于缓存 SQL 语句解析结果
* @param parseTreeCacheOption 解析树缓存选项,用于缓存 SQL 的语法树
* @param isParseComment 是否解析 SQL 中的注释(true 表示解析,false 表示忽略注释)
* @return SQL 语句解析引擎
*/
public static SQLStatementParserEngine getSQLStatementParserEngine(final String databaseType,
final CacheOption sqlStatementCacheOption, final CacheOption parseTreeCacheOption, final boolean isParseComment) {
// 先尝试从缓存中获取对应数据库类型的解析器
SQLStatementParserEngine result = ENGINES.get(databaseType);
// 如果缓存中没有,则创建新的解析器并放入缓存(使用 computeIfAbsent 保证线程安全且只初始化一次)
if (null == result) {
result = ENGINES.computeIfAbsent(databaseType, key -> new SQLStatementParserEngine(key, sqlStatementCacheOption, parseTreeCacheOption, isParseComment));
}
// 返回解析器
return result;
}
}
SQLStatementParserEngineFactory类有一个ENGINES属性,保存着不同数据库类型的SQL解析引擎。getSQLStatementParserEngine方法获取SQL解析引擎。获取到SQLStatementParserEngine,就可以进行解析SQL了,SQLStatementParserEngine类如下:
/**
* SQL 语句解析引擎。
*
* 该类封装了 SQL 语句解析的核心逻辑,支持使用缓存提高解析效率,
* 并基于数据库类型、语法树缓存选项以及是否解析注释等配置初始化解析执行器。
*/
public final class SQLStatementParserEngine {
/**
* SQL 语句解析执行器。
* 用于实际执行 SQL 字符串的语法解析,生成 SQLStatement 抽象语法树(AST)。
*/
private final SQLStatementParserExecutor sqlStatementParserExecutor;
/**
* SQL 语句缓存(Guava 缓存)。
* Key:原始 SQL 字符串;
* Value:对应的解析结果 SQLStatement;
* 该缓存用于避免重复解析相同 SQL,提高系统性能。
*/
private final LoadingCache<String, SQLStatement> sqlStatementCache;
/**
* 构造方法。
*
* @param databaseType 数据库类型名称(如 "MySQL", "PostgreSQL" 等)
* @param sqlStatementCacheOption SQL 语句级缓存配置(影响是否缓存解析结果)
* @param parseTreeCacheOption 语法树缓存配置(影响解析器行为)
* @param isParseComment 是否解析 SQL 中的注释(true 表示保留注释)
*/
public SQLStatementParserEngine(final String databaseType, final CacheOption sqlStatementCacheOption, final CacheOption parseTreeCacheOption, final boolean isParseComment) {
// 初始化 SQL 解析执行器,主要负责语法分析、语法树构建等底层操作
sqlStatementParserExecutor = new SQLStatementParserExecutor(databaseType, parseTreeCacheOption, isParseComment);
// 初始化 SQL 解析执行器,主要负责语法分析、语法树构建等底层操作
sqlStatementCache = SQLStatementCacheBuilder.build(databaseType, sqlStatementCacheOption, parseTreeCacheOption, isParseComment);
}
/**
* 解析 SQL 字符串为 SQLStatement 抽象语法树对象。
*
* @param sql 待解析的 SQL 语句
* @param useCache 是否启用缓存:
* true - 优先从缓存中获取解析结果;
* false - 每次都重新解析 SQL,忽略缓存。
* @return SQLStatement 抽象语法树对象,表示该 SQL 的结构化表达
*/
public SQLStatement parse(final String sql, final boolean useCache) {// 使用缓存(如果没有就会自动解析并放入缓存)
return useCache ? sqlStatementCache.getUnchecked(sql) : sqlStatementParserExecutor.parse(sql);// 不使用缓存,直接执行解析
}
}
SQLStatementParserEngine类构造方法先创建了SQL的解析器,然后SQL语句的缓存(可以看2.3截图,第一次插入语句和第二次查询语句后面都进了缓存中),parse()用于解析SQL字符串为 SQLStatement 抽象语法树对象,可以优先取缓存;SQLStatementParserExecutor SQL语句解析执行器代码如下:
public final class SQLStatementParserExecutor {
// SQL 解析器引擎,负责将 SQL 文本解析为抽象语法树(AST)
private final SQLParserEngine parserEngine;
// SQL 访问器引擎,负责将解析树(ParseTree)转换为 SQLStatement 对象
private final SQLVisitorEngine visitorEngine;
/**
* 构造函数,初始化解析器引擎和访问器引擎。
*
* @param databaseType 数据库类型,例如:MySQL、PostgreSQL、Oracle等
* @param parseTreeCacheOption ParseTree 缓存配置,用于提升性能
* @param isParseComment 是否解析 SQL 注释
*/
public SQLStatementParserExecutor(final String databaseType, final CacheOption parseTreeCacheOption, final boolean isParseComment) {
// 初始化 SQL 解析器引擎
parserEngine = new SQLParserEngine(databaseType, parseTreeCacheOption);
// 初始化 SQL 访问器引擎,STATEMENT 模式代表将 ParseTree 转换为 SQLStatement
visitorEngine = new SQLVisitorEngine(databaseType, "STATEMENT", isParseComment, new Properties());
}
/**
* 解析 SQL 字符串为 SQLStatement 对象。
*
* @param sql 要解析的 SQL 字符串
* @return SQLStatement 抽象语法树结果
*/
public SQLStatement parse(final String sql) {
// 先通过 parserEngine 解析为 ParseTree,然后通过 visitorEngine 转换为 SQLStatement
return visitorEngine.visit(parserEngine.parse(sql, false));
}
}
SQLStatementParserExecutor SQL语句解析执行器主要有两个引擎,一个是SQLParserEngine 解析器引擎 ,一个是SQLVisitorEngine 访问器引擎,在parse()方法执行时,先将sql字符串通过SQLParserEngine 解析器引擎转换成抽象语法树(AST),然后通过SQLVisitorEngine 访问器引擎将抽样语法树转换成SQLStatement,接下来看看SQLParserEngine 解析器引擎 :
/**
* SQL解析引擎,用于将原始SQL字符串解析为抽象语法树(AST)节点。
* 这是 ShardingSphere 5.x 中封装的核心SQL解析组件。
*/
public final class SQLParserEngine {
// 实际执行SQL解析任务的执行器,负责调用 ANTLR 解析器生成语法树
private final SQLParserExecutor sqlParserExecutor;
// 缓存解析结果,避免重复解析相同SQL。key 是 SQL 字符串,value 是对应的 AST 节点
private final LoadingCache<String, ParseASTNode> parseTreeCache;
/**
* 构造函数,根据数据库类型创建解析执行器,并初始化解析结果缓存。
*
* @param databaseType 数据库类型,如 MySQL、PostgreSQL 等
* @param cacheOption 缓存选项,用于配置缓存的大小、过期时间等
*/
public SQLParserEngine(final String databaseType, final CacheOption cacheOption) {
// 初始化解析执行器,根据数据库类型加载对应的 ANTLR 语法解析器
sqlParserExecutor = new SQLParserExecutor(databaseType);
// 创建解析缓存,缓存解析后的 AST 结果,提升性能
parseTreeCache = ParseTreeCacheBuilder.build(cacheOption, databaseType);
}
/**
* 解析 SQL 为抽象语法树(AST)。
*
* @param sql 要解析的 SQL 字符串
* @param useCache 是否使用缓存(true 表示先查缓存,否则直接解析)
* @return 解析得到的 AST 根节点(ParseASTNode)
*/
public ParseASTNode parse(final String sql, final boolean useCache) {
// 如果使用缓存,尝试从缓存中获取解析结果
// 若缓存未命中,则自动调用 SQLParserExecutor 进行解析,并写入缓存
return useCache ? parseTreeCache.getUnchecked(sql) : sqlParserExecutor.parse(sql);
}
}
SQLVisitorEngine 访问器引擎源码如下:
/**
* SQLVisitorEngine 是 SQL 解析的访问器,用于将解析出的 AST(抽象语法树)转换为具体的 SQLStatement 对象。
* 它基于 Visitor 模式实现,通过解析器访问器规则来还原 SQL 的语义结构。
*/
@RequiredArgsConstructor
public final class SQLVisitorEngine {
// 数据库类型(如 MySQL、PostgreSQL、Oracle 等)
private final String databaseType;
// 访问器类型,通常是 "STATEMENT",表示将 AST 转换为 SQLStatement
private final String visitorType;
// 是否解析注释(如 /* 注释内容 */ 或 -- 单行注释)
private final boolean isParseComment;
// 附加属性,可供访问器扩展使用
private final Properties props;
/**
* 将解析后的 AST 节点转化为具体的 SQLStatement 对象(或其他类型 T)。
*
* @param parseASTNode SQL 的抽象语法树节点(ParseTree 的包装)
* @param <T> SQL 访问器返回的结果类型
* @return AST 转换后的 SQLStatement 或其他结构化对象
*/
public <T> T visit(final ParseASTNode parseASTNode) {
// 根据解析树根节点的类型,构造对应的访问器
ParseTreeVisitor<T> visitor = SQLVisitorFactory.newInstance(
databaseType, // 数据库类型
visitorType, // 访问器类型(一般为 "STATEMENT")
SQLVisitorRule.valueOf(parseASTNode.getRootNode().getClass()), // 访问器规则
props // 属性参数
);
// 使用访问器访问 AST 的根节点,生成语义化 SQLStatement 对象
T result = parseASTNode.getRootNode().accept(visitor);
// 如果开启了解析注释,则提取 SQL 中的注释并附加到 SQLStatement 中
if (isParseComment) {
appendSQLComments(parseASTNode, result);
}
return result;
}
/**
* 将 AST 中提取出的注释追加到 SQLStatement 对象中。
*
* @param parseASTNode 解析后的 AST 节点
* @param visitResult 访问器返回的结果对象(需为 AbstractSQLStatement 类型)
* @param <T> 泛型参数
*/
private <T> void appendSQLComments(final ParseASTNode parseASTNode, final T visitResult) {
// 判断访问结果是否为 AbstractSQLStatement 类型
if (visitResult instanceof AbstractSQLStatement) {
// 遍历隐藏 token(注释),将其转换为 CommentSegment,并加入 SQLStatement 中
Collection<CommentSegment> commentSegments = parseASTNode.getHiddenTokens().stream().map(
each -> new CommentSegment(each.getText(), each.getStartIndex(), each.getStopIndex())).collect(Collectors.toList());
// 将注释段加入 SQLStatement 对象中
((AbstractSQLStatement) visitResult).getCommentSegments().addAll(commentSegments);
}
}
}
SQLParserExecutor类将SQL解析为抽象语法树,代码如下:
/**
* SQL 解析执行器(SQLParserExecutor)。
*
* 作用:
* - 使用 ANTLR 执行 SQL 的词法和语法解析。
* - 使用两阶段解析(SLL → LL)提升性能和容错能力。
* - 解析结果为 ParseASTNode(抽象语法树)。
*/
@RequiredArgsConstructor
public final class SQLParserExecutor {
// 当前数据库类型(如 MySQL、PostgreSQL、Oracle 等)
private final String databaseType;
/**
* 执行 SQL 的解析过程,返回 AST 节点。
*
* @param sql 要解析的 SQL 语句
* @return SQL 解析结果(AST)
*/
public ParseASTNode parse(final String sql) {
// 两阶段解析
ParseASTNode result = twoPhaseParse(sql);
// 如果解析结果的根节点是错误节点,则抛出异常
if (result.getRootNode() instanceof ErrorNode) {
throw new SQLParsingException("Unsupported SQL of `%s`", sql);
}
return result;
}
/**
* 两阶段 SQL 解析策略(SLL -> LL)。
*
* 原理:
* - 首先使用 SLL 模式解析,速度快,但对语法容错能力弱。
* - 如果 SLL 模式失败(ParseCancellationException),则回退使用 LL 模式,容错强但速度慢。
*
* @param sql SQL 语句
* @return 解析得到的 AST 节点
*/
private ParseASTNode twoPhaseParse(final String sql) {
// 从 SPI 注册表中根据数据库类型获取解析器门面类(包括词法和语法类)
DatabaseTypedSQLParserFacade sqlParserFacade = DatabaseTypedSQLParserFacadeRegistry.getFacade(databaseType);
// 创建具体的 ANTLR SQL 解析器
SQLParser sqlParser = SQLParserFactory.newInstance(
sql,
sqlParserFacade.getLexerClass(), // 获取词法分析器类
sqlParserFacade.getParserClass() // 获取语法分析器类
);
try {
// 第一次尝试使用 SLL(单向预测)模式,效率更高
((Parser) sqlParser).getInterpreter().setPredictionMode(PredictionMode.SLL);
return (ParseASTNode) sqlParser.parse();
} catch (final ParseCancellationException ex) {
// SLL 失败后,回退为 LL(上下文无关文法)模式,提高容错能力
((Parser) sqlParser).reset();
((Parser) sqlParser).getInterpreter().setPredictionMode(PredictionMode.LL);
try {
return (ParseASTNode) sqlParser.parse();
} catch (final ParseCancellationException e) {
// LL 模式也失败,说明 SQL 语法非法,抛出解析异常
throw new SQLParsingException("You have an error in your SQL syntax");
}
}
}
}
SQLParserExecutor类采用工厂模式很快数据库类型和sql得到不同数据库的SQL解析器。SQLParserFactory类通过SQLParserFactory.newInstance获取SQL解析器:
/**
* SQL 解析器工厂类(用于动态创建 ANTLR SQL 解析器对象)。
*
* 特点:
* - 禁止实例化(私有构造器)
* - 使用反射机制创建 Lexer 和 Parser
*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class SQLParserFactory {
/**
* 创建 SQL 解析器实例(组合词法分析器和语法分析器)。
*
* @param sql SQL 原始文本
* @param lexerClass 词法分析器类(ANTLR 生成)
* @param parserClass 语法分析器类(ANTLR 生成)
* @return SQL 解析器实例(Parser)
*/
public static SQLParser newInstance(final String sql, final Class<? extends SQLLexer> lexerClass, final Class<? extends SQLParser> parserClass) {
// 创建 TokenStream 并构造 SQLParser
return createSQLParser(createTokenStream(sql, lexerClass), parserClass);
}
/**
* 反射创建 SQL 语法分析器(Parser)。
*
* @param tokenStream 词法分析器输出的 Token 流
* @param parserClass 语法分析器类
* @return SQLParser 实例
*/
@SneakyThrows(ReflectiveOperationException.class)
private static SQLParser createSQLParser(final TokenStream tokenStream, final Class<? extends SQLParser> parserClass) {
// 使用 TokenStream 构造语法分析器
SQLParser result = parserClass.getConstructor(TokenStream.class).newInstance(tokenStream);
// 设置错误处理策略为 BailErrorStrategy,遇错立即抛异常(性能更高,便于回退 LL 模式)
((Parser) result).setErrorHandler(new BailErrorStrategy());
// 移除默认控制台错误监听器,避免控制台输出干扰
((Parser) result).removeErrorListener(ConsoleErrorListener.INSTANCE);
return result;
}
/**
* 创建 ANTLR 所需的 TokenStream。
*
* @param sql SQL 文本
* @param lexerClass 词法分析器类
* @return Token 流对象
*/
@SneakyThrows(ReflectiveOperationException.class)
private static TokenStream createTokenStream(final String sql, final Class<? extends SQLLexer> lexerClass) {
// 构造词法分析器(Lexer)
Lexer lexer = (Lexer) lexerClass.getConstructor(CharStream.class).newInstance(getSQLCharStream(sql));
// 同样移除默认的 ConsoleErrorListener
lexer.removeErrorListener(ConsoleErrorListener.INSTANCE);
// 将词法分析器输出的词元封装为 TokenStream,供语法分析器使用
return new CommonTokenStream(lexer);
}
/**
* 将字符串 SQL 转换为 ANTLR 所需的 CharStream。
*
* @param sql SQL 文本
* @return 字符流
*/
private static CharStream getSQLCharStream(final String sql) {
// 创建 ANTLR 兼容的字符缓冲区
CodePointBuffer buffer = CodePointBuffer.withChars(CharBuffer.wrap(sql.toCharArray()));
// 基于缓冲区构造字符流
return CodePointCharStream.fromBuffer(buffer);
}
}
sql(文本字符串) => CharStream(字符流) => createTokenStream(词法分析器) => createSQLParser(语法分析器) => SQLParser解析器实例
SQLVisitorFactory类源码如下:
/**
* SQL 访问器工厂类。
*
* 作用:根据数据库类型、访问器类型、SQL 类型规则,动态创建对应的 ParseTreeVisitor。
* 使用反射机制,支持多种 SQL 类型(如 DML/DDL/TCL 等)。
*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class SQLVisitorFactory {
/**
* 创建 SQL Parse Tree 访问器实例。
*
* @param databaseType 数据库类型,如 MySQL、PostgreSQL
* @param visitorType 访问器类型,如 STATEMENT
* @param visitorRule 访问规则(封装了 SQL 类型)
* @param props 访问器配置属性
* @param <T> 返回结果类型
* @return ParseTreeVisitor 解析器
*/
public static <T> ParseTreeVisitor<T> newInstance(final String databaseType, final String visitorType, final SQLVisitorRule visitorRule, final Properties props) {
// 获取数据库 + 访问器类型 对应的访问器外观类(Facade)
SQLVisitorFacade facade = SQLVisitorFacadeRegistry.getInstance().getSQLVisitorFacade(databaseType, visitorType);
// 根据 SQL 类型创建具体访问器
return createParseTreeVisitor(facade, visitorRule.getType(), props);
}
/**
* 根据 SQL 类型,创建对应的 ParseTreeVisitor。
*
* @param visitorFacade SQLVisitor 外观类
* @param type SQL 类型(如 DML/DDL)
* @param props 配置参数
* @param <T> 返回类型
* @return SQL 树访问器
*/
@SuppressWarnings("unchecked")
@SneakyThrows(ReflectiveOperationException.class)
private static <T> ParseTreeVisitor<T> createParseTreeVisitor(final SQLVisitorFacade visitorFacade, final SQLStatementType type, final Properties props) {
switch (type) {
case DML:
// 创建 DML(增删改)类型访问器
return (ParseTreeVisitor<T>) visitorFacade.getDMLVisitorClass().getConstructor(Properties.class).newInstance(props);
case DDL:
// 创建 DDL(建表、修改表等)访问器
return (ParseTreeVisitor<T>) visitorFacade.getDDLVisitorClass().getConstructor(Properties.class).newInstance(props);
case TCL:
// 创建 TCL(事务控制,如 COMMIT)访问器
return (ParseTreeVisitor<T>) visitorFacade.getTCLVisitorClass().getConstructor(Properties.class).newInstance(props);
case DCL:
// 创建 DCL(权限控制)访问器
return (ParseTreeVisitor<T>) visitorFacade.getDCLVisitorClass().getConstructor(Properties.class).newInstance(props);
case DAL:
// 创建 DAL(数据查询/操作,如 SHOW TABLES)访问器
return (ParseTreeVisitor<T>) visitorFacade.getDALVisitorClass().getConstructor(Properties.class).newInstance(props);
case RL:
// 创建 RL(资源管理)访问器(如 RULE、RESOURCE 等)
return (ParseTreeVisitor<T>) visitorFacade.getRLVisitorClass().getConstructor(Properties.class).newInstance(props);
default:
throw new SQLParsingException("Can not support SQL statement type: `%s`", type);
}
}
}
SQLParserFactory类根据不同的SQL解析器配置获取不同数据库的SQL解析器,最终获取到ANTLR的SQL解析器Lexer。通过SQLParserExecutor获取到ParseTree,就可以通过SQLVisitorFactory类获取不同的SQLStatement了,到这里SQLParserEngine解析就分析完了。
2.5 SQL路由
上面讲完sql的解析,这节讲一下SQL上下文中SQL路由
/**
* KernelProcessor 是核心处理器类,用于生成 SQL 的 ExecutionContext。
* ExecutionContext 包含了执行 SQL 所需的所有上下文信息,如路由信息、改写后的 SQL、参数等。
*/
public final class KernelProcessor {
/**
* 生成执行上下文。
*
* @param logicSQL 逻辑 SQL 对象(包含原始 SQL、参数、SQL 上下文)
* @param metaData 数据库的元数据(包括表结构、分片规则等)
* @param props 配置属性(如是否显示 SQL 日志等)
* @return SQL 执行上下文 ExecutionContext
*/
public ExecutionContext generateExecutionContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props) {
// 第一步:执行路由,根据逻辑 SQL 和规则决定该 SQL 应该在哪些数据源、表上执行
RouteContext routeContext = route(logicSQL, metaData, props);
// 第二步:SQL 改写,例如添加真实表名、绑定参数等
SQLRewriteResult rewriteResult = rewrite(logicSQL, metaData, props, routeContext);
// 第三步:构造最终的执行上下文,包括执行单元(SQLUnit)和路由信息
ExecutionContext result = createExecutionContext(logicSQL, metaData, routeContext, rewriteResult);
// 第四步(可选):如果开启了 SQL 显示功能,则打印 SQL 日志
logSQL(logicSQL, props, result);
return result;
}
// 其他代码
}
KernelProcessor 核心类有generateExecutionContext方法来实现LogicSQL 转换成可执行的上下文,其中包括SQL路由、SQL改写、构造上下文等,现在重点看一下route()方法
/**
* 路由逻辑 SQL,生成 RouteContext。
*
* @param logicSQL 逻辑 SQL
* @param metaData 元数据
* @param props 配置属性
* @return 路由上下文(包含路由结果)
*/
private RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props) {
// 使用 SQLRouteEngine 路由引擎进行路由计算
return new SQLRouteEngine(metaData.getRuleMetaData().getRules(), props).route(logicSQL, metaData);
}
route()是用的执行引擎SQLRouteEngine来计算,SQLRouteEngine代码如下:
/**
* SQL 路由引擎。
* 该类是 ShardingSphere 中进行 SQL 路由(Routing)的核心入口。
* 根据 SQL 类型和当前规则环境,选择合适的路由执行器(Executor)进行 SQL 路由。
*/
@RequiredArgsConstructor
public final class SQLRouteEngine {
// 当前生效的所有 ShardingSphere 规则(例如分片规则、读写分离规则等)
private final Collection<ShardingSphereRule> rules;
// 配置属性(来自配置文件中的 props 配置)
private final ConfigurationProperties props;
/**
* 对逻辑 SQL 进行路由,返回路由上下文信息(RouteContext)。
*
* @param logicSQL 表示经过解析、改写封装后的 LogicSQL 对象,包含 SQLStatement、参数、原始 SQL 等
* @param metaData 当前数据库的元数据(包含各个逻辑库/表结构信息)
* @return 路由上下文(包含每条实际 SQL 应该发往哪个数据源、目标表等信息)
*/
public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) {
// 判断是否需要对所有 schema 进行处理(如 SHOW TABLES 这类广播语句)
SQLRouteExecutor executor = isNeedAllSchemas(logicSQL.getSqlStatementContext().getSqlStatement()) ? new AllSQLRouteExecutor() : new PartialSQLRouteExecutor(rules, props);
return executor.route(logicSQL, metaData);
}
/**
* 判断当前 SQL 是否需要对所有 schema 进行广播路由。
* 通常用于 MySQL 的 SHOW TABLES 等语句,因为它们不指定具体 schema。
*
* TODO: 后续考虑通过动态配置来判断未配置 schema 的行为(UnconfiguredSchema)
*
* @param sqlStatement SQL 语句
* @return true 则对所有 schema 进行路由;false 仅路由部分 schema
*/
private boolean isNeedAllSchemas(final SQLStatement sqlStatement) {
return sqlStatement instanceof MySQLShowTablesStatement || sqlStatement instanceof MySQLShowTableStatusStatement;
}
}
SQLRouteEngine 是 SQL 路由的总入口。它会判断 SQL 类型是否需要对所有逻辑库/Schema 做路由(比如 SHOW TABLES)。根据不同情况使用 AllSQLRouteExecutor 或 PartialSQLRouteExecutor:
-
AllSQLRouteExecutor:广播查询所有逻辑库。 -
PartialSQLRouteExecutor:根据规则判断发往哪个库/表。
返回的 RouteContext 会在后续构造 ExecutionUnit 和执行计划中使用。
我们先来看看广播查询AllSQLRouteExecutor源码如下:
/**
* 全量 SQL 路由执行器。
*
* 该类的作用是将一条 SQL 请求路由到所有数据源(dataSource)上,常用于广播类 SQL,
* 比如:建表语句、全量查询等需要在所有数据源上执行的情况。
*/
public final class AllSQLRouteExecutor implements SQLRouteExecutor {
/**
* 执行路由逻辑,生成包含所有数据源的 RouteContext。
*
* @param logicSQL 逻辑 SQL 对象(已绑定参数及上下文)
* @param metaData 当前逻辑库的元数据,包括数据源信息等
* @return 路由上下文,包含所有数据源的 RouteUnit
*/
@Override
public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) {
// 创建空的路由上下文容器
RouteContext result = new RouteContext();
// 遍历所有数据源(通常是多个物理库的别名,如 ds0, ds1)
for (String each : metaData.getResource().getDataSources().keySet()) {
// 将每个数据源都添加为一个 RouteUnit
// RouteMapper(sourceName, actualName) 表示逻辑与实际数据源之间的映射(此处一一对应)
result.getRouteUnits().add(new RouteUnit(new RouteMapper(each, each), Collections.emptyList()));
}
return result;
}
}
再看看PartialSQLRouteExecutor源码
/**
* Partial SQL 路由执行器。
*
* 此执行器用于在部分 schema(或数据库实例)中选择路由目标。
* 与 AllSQLRouteExecutor(广播路由)不同,此类会根据配置规则精确选择目标数据源。
*/
public final class PartialSQLRouteExecutor implements SQLRouteExecutor {
// 静态块:注册 SQLRouter SPI 实现类(用于后续按需加载)
static {
ShardingSphereServiceLoader.register(SQLRouter.class);
}
private final ConfigurationProperties props;
/**
* 每个规则(ShardingSphereRule)对应一个 SQLRouter 实例。
* SQLRouter 是实际执行路由逻辑的策略接口。
*/
@SuppressWarnings("rawtypes")
private final Map<ShardingSphereRule, SQLRouter> routers;
/**
* 构造函数,初始化属性和注册的路由器。
*
* @param rules 路由规则集合(分片、读写分离、影子库等)
* @param props 配置属性
*/
public PartialSQLRouteExecutor(final Collection<ShardingSphereRule> rules, final ConfigurationProperties props) {
this.props = props;
routers = OrderedSPIRegistry.getRegisteredServices(SQLRouter.class, rules);
}
/**
* 执行路由逻辑,生成 RouteContext。
*
* @param logicSQL 解析后的逻辑 SQL
* @param metaData 当前数据库的元数据
* @return 路由上下文
*/
@Override
@SuppressWarnings({"unchecked", "rawtypes"})
public RouteContext route(final LogicSQL logicSQL, final ShardingSphereMetaData metaData) {
// 初始化空的 RouteContext,用于收集路由单元
RouteContext result = new RouteContext();
// 1. 优先判断 Hint 强制指定的数据源(如 HintManager.setDataSourceName)
Optional<String> dataSourceName = findDataSourceByHint(logicSQL.getSqlStatementContext(), metaData.getResource().getDataSources());
if (dataSourceName.isPresent()) {
// 如果通过 Hint 指定了数据源,直接构造 RouteUnit 返回
result.getRouteUnits().add(new RouteUnit(new RouteMapper(dataSourceName.get(), dataSourceName.get()), Collections.emptyList()));
return result;
}
// 2. 根据配置规则迭代执行每个 SQLRouter
for (Entry<ShardingSphereRule, SQLRouter> entry : routers.entrySet()) {
if (result.getRouteUnits().isEmpty()) {
// 第一个路由器执行 createRouteContext
result = entry.getValue().createRouteContext(logicSQL, metaData, entry.getKey(), props);
} else {
// 后续路由器执行 decorateRouteContext 进行补充或装饰
entry.getValue().decorateRouteContext(result, logicSQL, metaData, entry.getKey(), props);
}
}
// 3. 如果所有路由器都没匹配上,并且系统只配置了一个数据源,则默认选这个数据源
if (result.getRouteUnits().isEmpty() && 1 == metaData.getResource().getDataSources().size()) {
String singleDataSourceName = metaData.getResource().getDataSources().keySet().iterator().next();
result.getRouteUnits().add(new RouteUnit(new RouteMapper(singleDataSourceName, singleDataSourceName), Collections.emptyList()));
}
return result;
}
/**
* 尝试从 Hint 中获取用户强制指定的数据源。
* 如果存在 Hint 并有效(即在当前资源中存在对应的 datasource),则返回。
* 否则抛出异常或返回空。
*
* @param sqlStatementContext SQL 上下文
* @param dataSources 当前所有的数据源
* @return Optional 类型的数据源名
*/
private Optional<String> findDataSourceByHint(final SQLStatementContext<?> sqlStatementContext, final Map<String, DataSource> dataSources) {
Optional<String> result;
// 1. 先判断是否通过 HintManager 显式指定数据源
if (HintManager.isInstantiated() && HintManager.getDataSourceName().isPresent()) {
result = HintManager.getDataSourceName();
} else {
// 2. 如果 HintManager 没有指定,则尝试从 SQL 语句上下文中找(如 SQL 注释中含有 Hint)
result = ((CommonSQLStatementContext<?>) sqlStatementContext).findHintDataSourceName();
}
// 3. 校验该数据源是否真实存在于当前数据源中
if (result.isPresent() && !dataSources.containsKey(result.get())) {
throw new ShardingSphereException("Hint datasource: %s is not exist!", result.get());
}
return result;
}
}
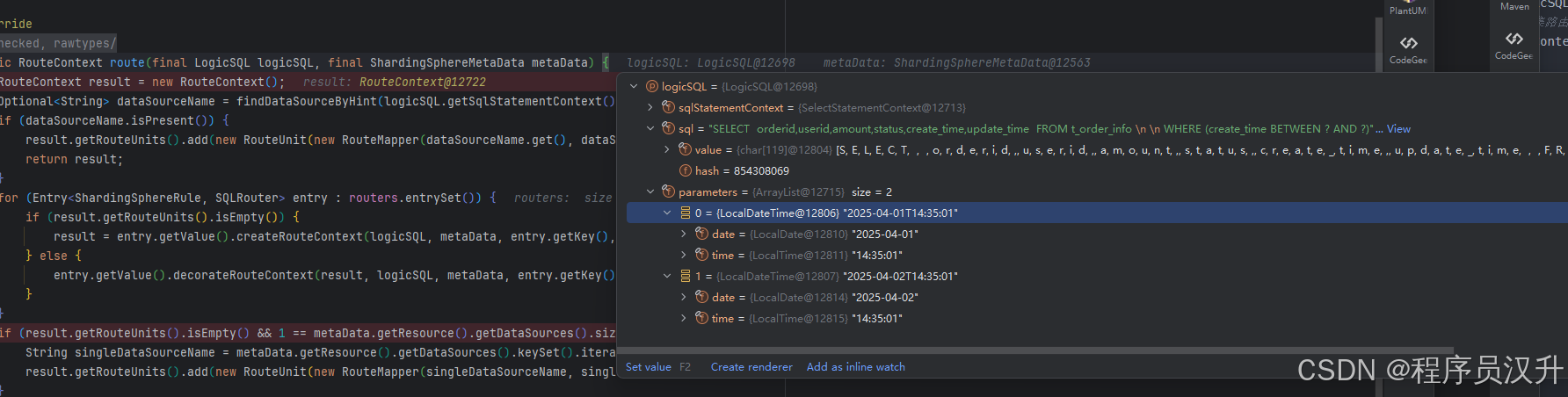
加载配置
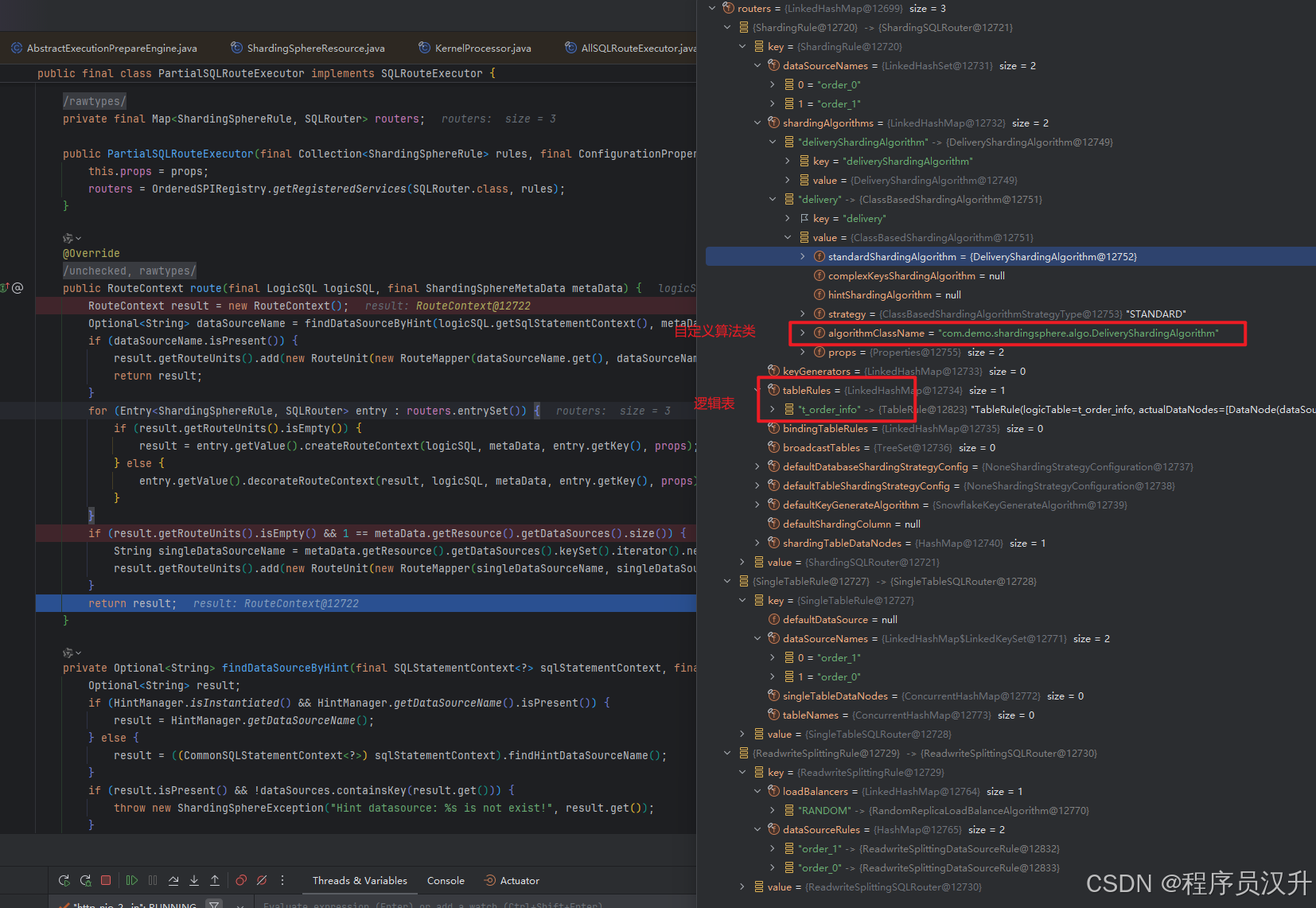
我的一条查询语句,路由成
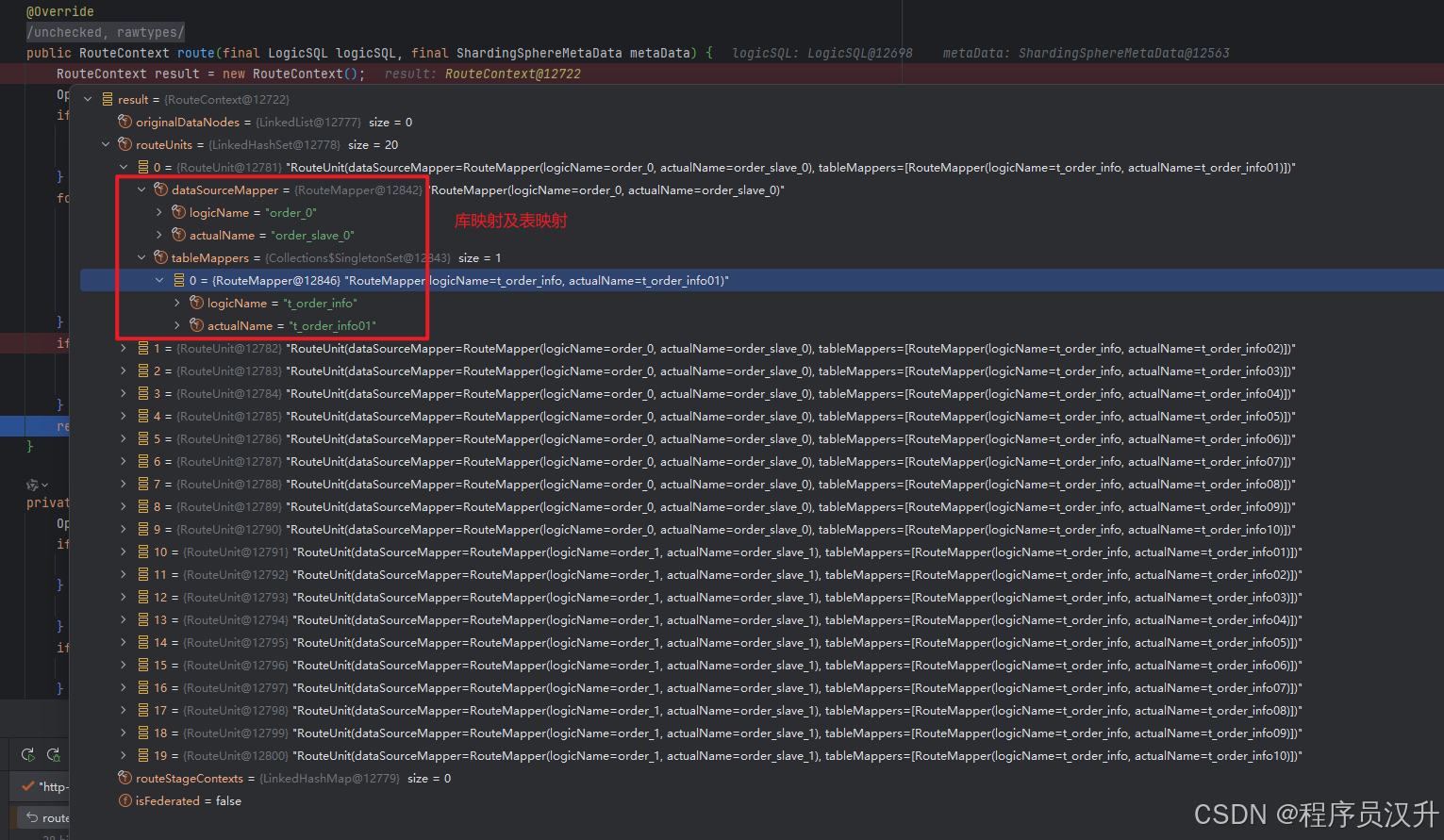
再进入SQLRouter接口中
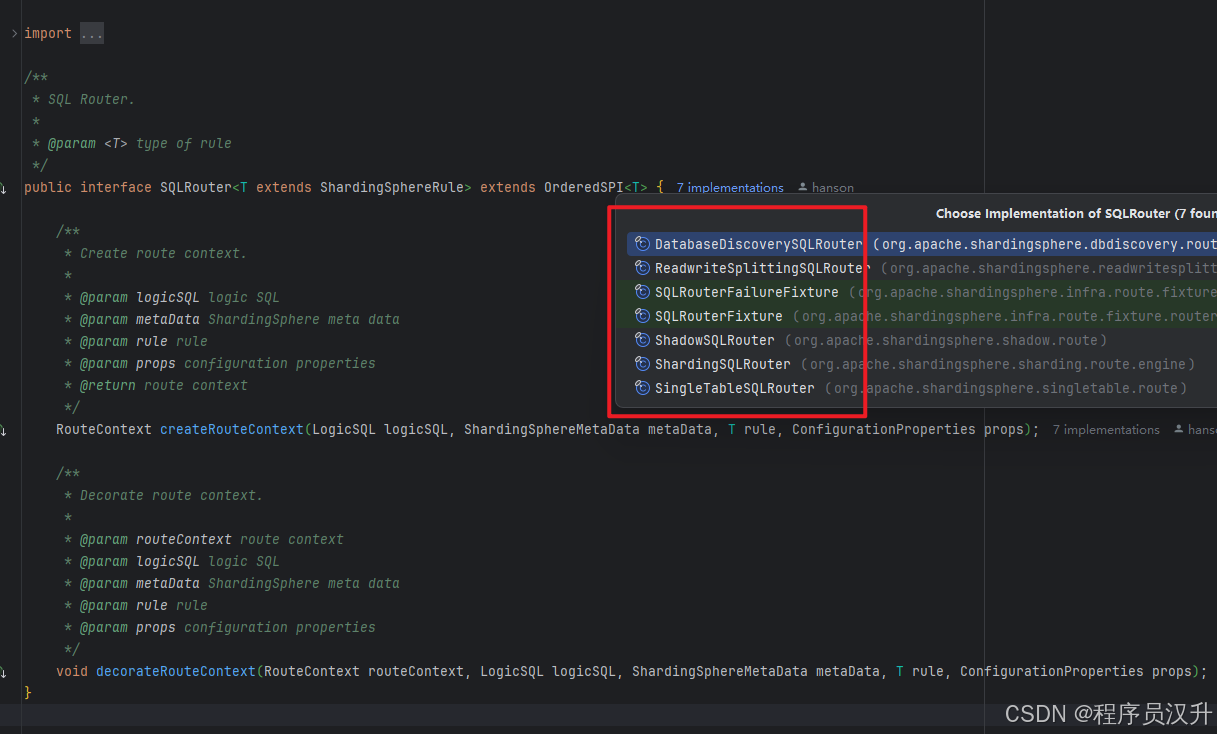
SQLRouter接口有七个实现类,在 PartialSQLRouteExecutor 中,这些路由器是按顺序协同工作的:
-
初始化时由
OrderedSPIRegistry.getRegisteredServices()加载; -
按优先级(
getOrder())依次调用:-
第一个调用
createRouteContext(); -
后续调用
decorateRouteContext()来进一步补充或修改结果;
-
-
每个 Router 可以决定是否处理当前 SQL;
-
最终形成完整的
RouteContext。
| 实现类 | 所属模块 | 说明 |
|---|---|---|
DatabaseDiscoverySQLRouter | Database Discovery(数据库发现) | 适用于自动主从发现的场景,会根据数据库探测机制选择可用的数据源(比如心跳检测判断主库存活与否)。 |
ReadwriteSplittingSQLRouter | 读写分离 | 根据读写标识将 SQL 路由到主库或从库。例如,SELECT 路由到从库,INSERT 路由到主库。 |
ShadowSQLRouter | 影子库(灰度) | 用于灰度发布场景,支持将特定 SQL 路由到影子库,以实现线上灰度流量隔离。 |
ShardingSQLRouter | 分片路由 | 根据分片键(如 user_id)将 SQL 精确路由到对应的分片库或分片表上,是核心的分库分表路由逻辑。 |
SingleTableSQLRouter | 单表路由 | 用于未分片的普通表,在多数据源场景中,仍需确定该表在哪个库中,避免广播查询。 |
详细说说读写分离ReadwriteSplittingSQLRouter和分片路由ShardingSQLRouter
ReadwriteSplittingSQLRouter
/**
* 读写分离 SQL 路由器,负责根据 SQL 类型(读/写)路由到主库或从库。
* 实现 SQLRouter 接口,专用于 ReadwriteSplittingRule 规则。
*/
public final class ReadwriteSplittingSQLRouter implements SQLRouter<ReadwriteSplittingRule> {
/**
* 创建初始路由上下文,确定逻辑数据源对应的物理数据源(主库或从库)。
*
* @param logicSQL 逻辑SQL对象,包含SQL语句、参数和解析后的SQLStatementContext
* @param metaData ShardingSphere元数据(如库表结构、规则配置)
* @param rule 当前读写分离规则(如主从库配置)
* @param props 全局配置属性
* @return RouteContext 初始路由上下文,包含数据源映射关系
*/
@Override
public RouteContext createRouteContext(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ReadwriteSplittingRule rule, final ConfigurationProperties props) {
RouteContext result = new RouteContext();
// 使用读写分离数据源路由器选择主库或从库(根据SQL类型自动判断)
String dataSourceName = new ReadwriteSplittingDataSourceRouter(rule.getSingleDataSourceRule()).route(logicSQL.getSqlStatementContext());
// 构建路由单元:逻辑库名 -> 实际数据源名(如 logic_db -> master_db 或 slave_db)
result.getRouteUnits().add(new RouteUnit(new RouteMapper(DefaultSchema.LOGIC_NAME, dataSourceName), Collections.emptyList()));
return result;
}
/**
* 装饰(修正)已有的路由上下文,处理动态主从切换场景。
* 例如:当路由结果中的主库因故障切换时,需替换为新的主库。
*
* @param routeContext 已存在的路由上下文
* @param logicSQL 逻辑SQL对象
* @param metaData 元数据
* @param rule 读写分离规则
* @param props 配置属性
*/
@Override
public void decorateRouteContext(final RouteContext routeContext,
final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ReadwriteSplittingRule rule, final ConfigurationProperties props) {
Collection<RouteUnit> toBeRemoved = new LinkedList<>();
Collection<RouteUnit> toBeAdded = new LinkedList<>();
// 遍历现有路由单元,检查是否需要更新数据源映射
for (RouteUnit each : routeContext.getRouteUnits()) {
String dataSourceName = each.getDataSourceMapper().getLogicName();
// 查找对应的读写分离规则配置
Optional<ReadwriteSplittingDataSourceRule> dataSourceRule = rule.findDataSourceRule(dataSourceName);
// 如果规则存在且当前实际数据源名与规则名一致
if (dataSourceRule.isPresent() && dataSourceRule.get().getName().equalsIgnoreCase(each.getDataSourceMapper().getActualName())) {
toBeRemoved.add(each);// 标记待移除
// 重新路由获取最新数据源(如主库切换后返回新主库名)
String actualDataSourceName = new ReadwriteSplittingDataSourceRouter(dataSourceRule.get()).route(logicSQL.getSqlStatementContext());
// 创建新路由单元(保留原逻辑名和表映射)
toBeAdded.add(new RouteUnit(new RouteMapper(each.getDataSourceMapper().getLogicName(), actualDataSourceName), each.getTableMappers()));
}
}
// 批量更新路由上下文
routeContext.getRouteUnits().removeAll(toBeRemoved);
routeContext.getRouteUnits().addAll(toBeAdded);
}
@Override
public int getOrder() {
return ReadwriteSplittingOrder.ORDER;
}
@Override
public Class<ReadwriteSplittingRule> getTypeClass() {
return ReadwriteSplittingRule.class;
}
}
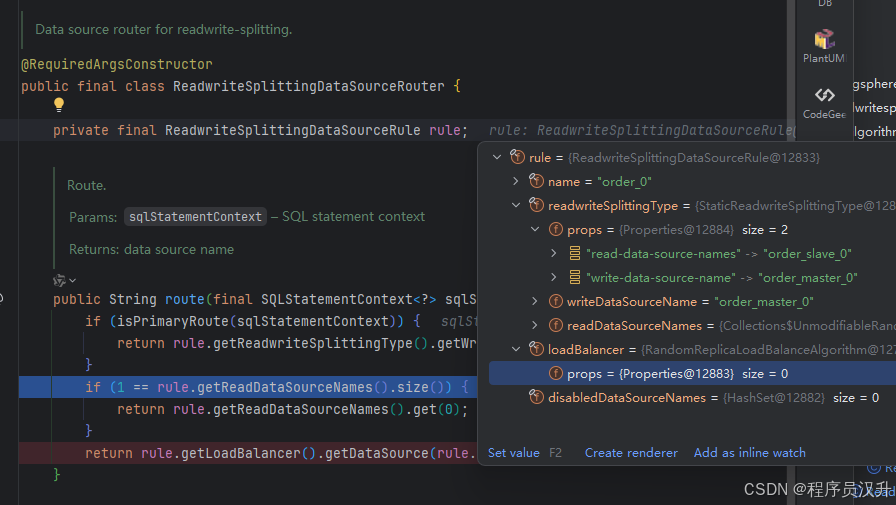
ShardingSQLRouter
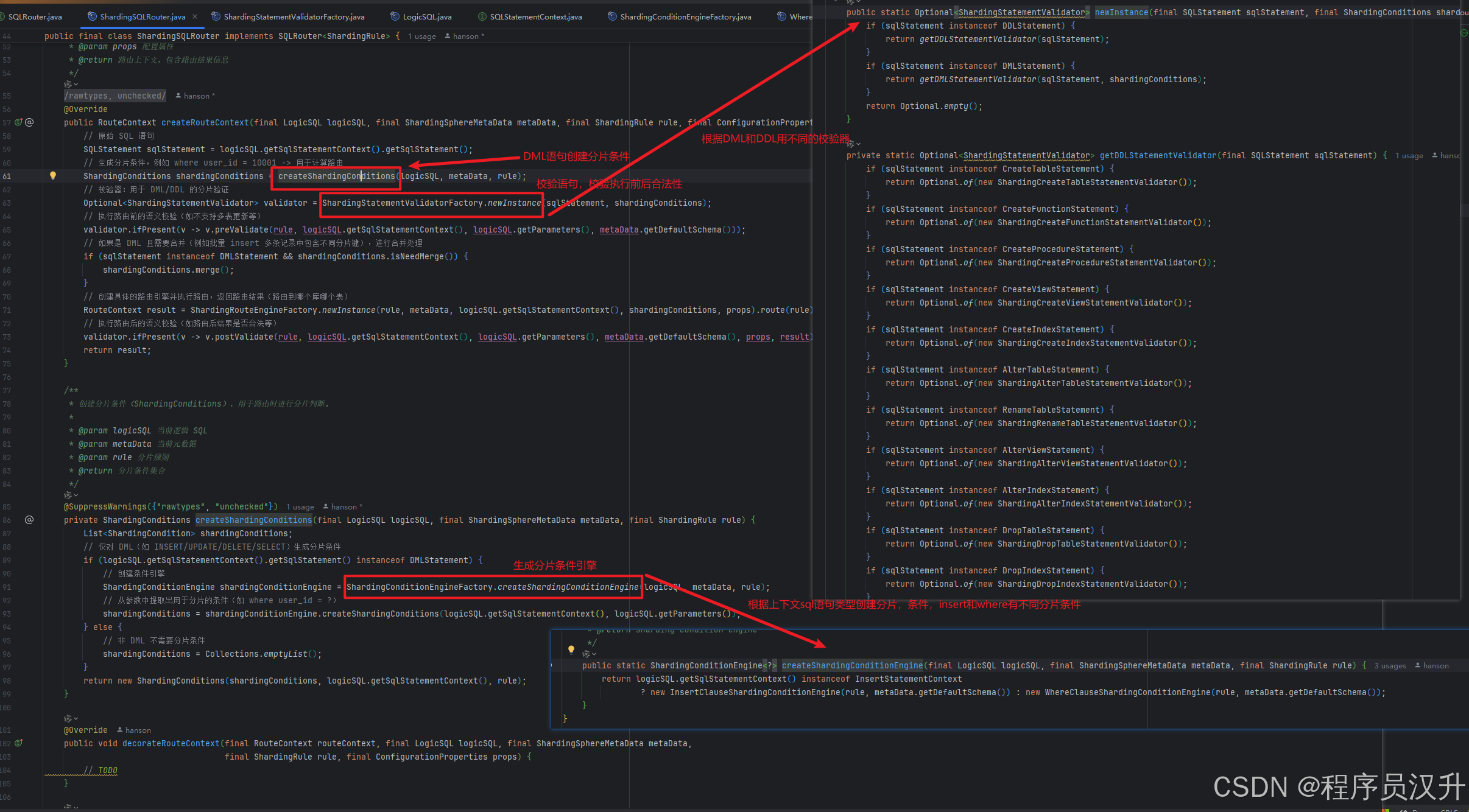
2.6 SQL改写
什么是sql改写?为什么要sql改写
在分库分表或者读写分离的场景中,我们面对的是逻辑 SQL —— 即业务层写的是“统一视角下”的 SQL:
SELECT * FROM user WHERE user_id = 123;
而数据库实际结构是:
-
user_0, user_1 两张表(垂直/水平分表)
-
或者 user 表在 ds_0、ds_1 两个数据库中各存在一份
因此,逻辑 SQL 不能直接执行在真实数据库中,必须进行改写,变成物理 SQL,发往真正的目标库表。
KernelProcessor核心类generateExecutionContext()方法中第一步是将logicSQL路由成上下文格式,第二步SQL改写
/**
* 对 SQL 进行改写。
*
* @param logicSQL 逻辑 SQL
* @param metaData 元数据
* @param props 配置属性
* @param routeContext 路由上下文
* @return SQLRewriteResult 改写后的 SQL 结果
*/
private SQLRewriteResult rewrite(final LogicSQL logicSQL, final ShardingSphereMetaData metaData, final ConfigurationProperties props, final RouteContext routeContext) {
// 创建 SQL 改写引擎,并执行 SQL 改写逻辑
SQLRewriteEntry sqlRewriteEntry = new SQLRewriteEntry(metaData.getName(), metaData.getDefaultSchema(), props, metaData.getRuleMetaData().getRules());
return sqlRewriteEntry.rewrite(logicSQL.getSql(), logicSQL.getParameters(), logicSQL.getSqlStatementContext(), routeContext);
}
KernelProcessor核心类rewrite()调用SQLRewriteEntry 类中rewrite()方法
/**
* 执行SQL改写。
*
* @param sql 原始SQL
* @param parameters SQL参数
* @param sqlStatementContext SQL语句上下文(已解析的语法树)
* @param routeContext 路由上下文(包含数据源和表路由信息)
* @return SQL改写结果(可能包含多个路由单元的改写SQL)
*/
public SQLRewriteResult rewrite(final String sql, final List<Object> parameters, final SQLStatementContext<?> sqlStatementContext, final RouteContext routeContext) {
// 1. 创建改写上下文
SQLRewriteContext sqlRewriteContext = createSQLRewriteContext(sql, parameters, sqlStatementContext, routeContext);
// 2. 根据路由情况选择改写引擎
return routeContext.getRouteUnits().isEmpty()// 无路由:通用改写
? new GenericSQLRewriteEngine().rewrite(sqlRewriteContext) : new RouteSQLRewriteEngine().rewrite(sqlRewriteContext, routeContext);// 有路由:基于路由单元改写
}
两种改写模式:
-
通用改写 (
GenericSQLRewriteEngine):当没有路由信息时(如全库广播),生成统一的改写SQL。 -
路由改写 (
RouteSQLRewriteEngine):针对每个路由单元(RouteUnit)生成不同的SQL(如分片键值替换)。
通用改写 (GenericSQLRewriteEngine)源码:
路由改写 (RouteSQLRewriteEngine)
/**
* 基于路由单元的 SQL 改写引擎,处理需要分片执行的 SQL 改写。
* 核心功能:
* 1. 根据路由单元(RouteUnit)生成分片SQL
* 2. 支持两种改写模式:单路由单元独立改写 vs 多路由单元聚合改写(UNION ALL)
* 3. 处理参数与路由单元的匹配关系
*/
public final class RouteSQLRewriteEngine {
/**
* 执行 SQL 和参数改写。
*
* @param sqlRewriteContext SQL 改写上下文(包含原始SQL、参数、SQLToken等)
* @param routeContext 路由上下文(包含所有路由单元信息)
* @return 路由SQL改写结果(包含每个路由单元对应的改写SQL和参数)
*/
public RouteSQLRewriteResult rewrite(final SQLRewriteContext sqlRewriteContext, final RouteContext routeContext) {
// 结果映射:RouteUnit -> 改写后的SQL和参数
Map<RouteUnit, SQLRewriteUnit> result = new LinkedHashMap<>(routeContext.getRouteUnits().size(), 1);
// 按数据源分组路由单元(相同数据源的路由单元可能合并执行)
for (Entry<String, Collection<RouteUnit>> entry : aggregateRouteUnitGroups(routeContext.getRouteUnits()).entrySet()) {
Collection<RouteUnit> routeUnits = entry.getValue();
// 判断是否需要聚合改写(将多个路由单元合并为UNION ALL查询)
if (isNeedAggregateRewrite(sqlRewriteContext.getSqlStatementContext(), routeUnits)) {
// 聚合模式:多个路由单元合并为一个SQLRewriteUnit
result.put(routeUnits.iterator().next(), createSQLRewriteUnit(sqlRewriteContext, routeContext, routeUnits));
} else {
// 独立模式:每个路由单元生成独立的SQLRewriteUnit
addSQLRewriteUnits(result, sqlRewriteContext, routeContext, routeUnits);
}
}
return new RouteSQLRewriteResult(result);
}
/**
* 创建聚合改写单元(UNION ALL 模式)。
* 适用场景:简单SELECT查询跨多个分片表,无子查询/JOIN/ORDER BY/LOCK等复杂语法。
*/
private SQLRewriteUnit createSQLRewriteUnit(final SQLRewriteContext sqlRewriteContext,
final RouteContext routeContext,
final Collection<RouteUnit> routeUnits) {
Collection<String> sql = new LinkedList<>();
List<Object> parameters = new LinkedList<>();
// 特殊处理包含$参数的SELECT语句(如PostgreSQL的$1占位符)
boolean containsDollarMarker = sqlRewriteContext.getSqlStatementContext() instanceof SelectStatementContext
&& ((SelectStatementContext) sqlRewriteContext.getSqlStatementContext()).isContainsDollarParameterMarker();
for (RouteUnit each : routeUnits) {
// 生成单路由单元SQL并去除末尾分号
sql.add(SQLUtil.trimSemicolon(new RouteSQLBuilder(sqlRewriteContext, each).toSQL()));
// 如果包含$参数且参数已填充,则跳过重复添加
if (containsDollarMarker && !parameters.isEmpty()) {
continue;
}
parameters.addAll(getParameters(sqlRewriteContext.getParameterBuilder(), routeContext, each));
}
// 合并为UNION ALL查询
return new SQLRewriteUnit(String.join(" UNION ALL ", sql), parameters);
}
/**
* 添加独立路由单元改写结果。
*/
private void addSQLRewriteUnits(final Map<RouteUnit, SQLRewriteUnit> sqlRewriteUnits,
final SQLRewriteContext sqlRewriteContext,
final RouteContext routeContext,
final Collection<RouteUnit> routeUnits) {
for (RouteUnit each : routeUnits) {
sqlRewriteUnits.put(each,
new SQLRewriteUnit(
new RouteSQLBuilder(sqlRewriteContext, each).toSQL(),
getParameters(sqlRewriteContext.getParameterBuilder(), routeContext, each)
));
}
}
/**
* 判断是否需要聚合改写(UNION ALL模式)。
* 满足以下所有条件时启用:
* 1. 必须是SELECT语句
* 2. 多个路由单元
* 3. 不包含子查询/JOIN查询
* 4. 不包含ORDER BY/LIMIT子句
* 5. 不包含锁语句(如FOR UPDATE)
*/
private boolean isNeedAggregateRewrite(final SQLStatementContext<?> sqlStatementContext,
final Collection<RouteUnit> routeUnits) {
if (!(sqlStatementContext instanceof SelectStatementContext) || routeUnits.size() == 1) {
return false;
}
SelectStatementContext statementContext = (SelectStatementContext) sqlStatementContext;
boolean containsComplexQuery = statementContext.isContainsSubquery() || statementContext.isContainsJoinQuery();
boolean containsOrderByLimit = !statementContext.getOrderByContext().getItems().isEmpty()
|| statementContext.getPaginationContext().isHasPagination();
boolean containsLock = SelectStatementHandler.getLockSegment(statementContext.getSqlStatement()).isPresent();
boolean needAggregate = !containsComplexQuery && !containsOrderByLimit && !containsLock;
statementContext.setNeedAggregateRewrite(needAggregate); // 标记改写状态供后续使用
return needAggregate;
}
/**
* 按数据源名称分组路由单元。
*/
private Map<String, Collection<RouteUnit>> aggregateRouteUnitGroups(final Collection<RouteUnit> routeUnits) {
Map<String, Collection<RouteUnit>> result = new LinkedHashMap<>(routeUnits.size(), 1);
for (RouteUnit each : routeUnits) {
String dataSourceName = each.getDataSourceMapper().getActualName();
result.computeIfAbsent(dataSourceName, unused -> new LinkedList<>()).add(each);
}
return result;
}
/**
* 获取路由单元对应的参数列表。
*/
private List<Object> getParameters(final ParameterBuilder parameterBuilder,
final RouteContext routeContext,
final RouteUnit routeUnit) {
// 标准参数构建器直接返回全局参数
if (parameterBuilder instanceof StandardParameterBuilder) {
return parameterBuilder.getParameters();
}
// 分组参数构建器需匹配参数与数据节点关系
return routeContext.getOriginalDataNodes().isEmpty()
? ((GroupedParameterBuilder) parameterBuilder).getParameters()
: buildRouteParameters((GroupedParameterBuilder) parameterBuilder, routeContext, routeUnit);
}
/**
* 构建路由单元专属参数列表(用于批量插入等场景)。
*/
private List<Object> buildRouteParameters(final GroupedParameterBuilder parameterBuilder,
final RouteContext routeContext,
final RouteUnit routeUnit) {
List<Object> result = new LinkedList<>();
int count = 0;
// 遍历原始数据节点,匹配当前路由单元
for (Collection<DataNode> each : routeContext.getOriginalDataNodes()) {
if (isInSameDataNode(each, routeUnit)) {
result.addAll(parameterBuilder.getParameters(count));
}
count++;
}
// 添加通用参数(不绑定到特定分片)
result.addAll(parameterBuilder.getGenericParameterBuilder().getParameters());
return result;
}
/**
* 判断数据节点是否属于当前路由单元。
*/
private boolean isInSameDataNode(final Collection<DataNode> dataNodes, final RouteUnit routeUnit) {
if (dataNodes.isEmpty()) {
return true;
}
for (DataNode each : dataNodes) {
if (routeUnit.findTableMapper(each.getDataSourceName(), each.getTableName()).isPresent()) {
return true;
}
}
return false;
}
}
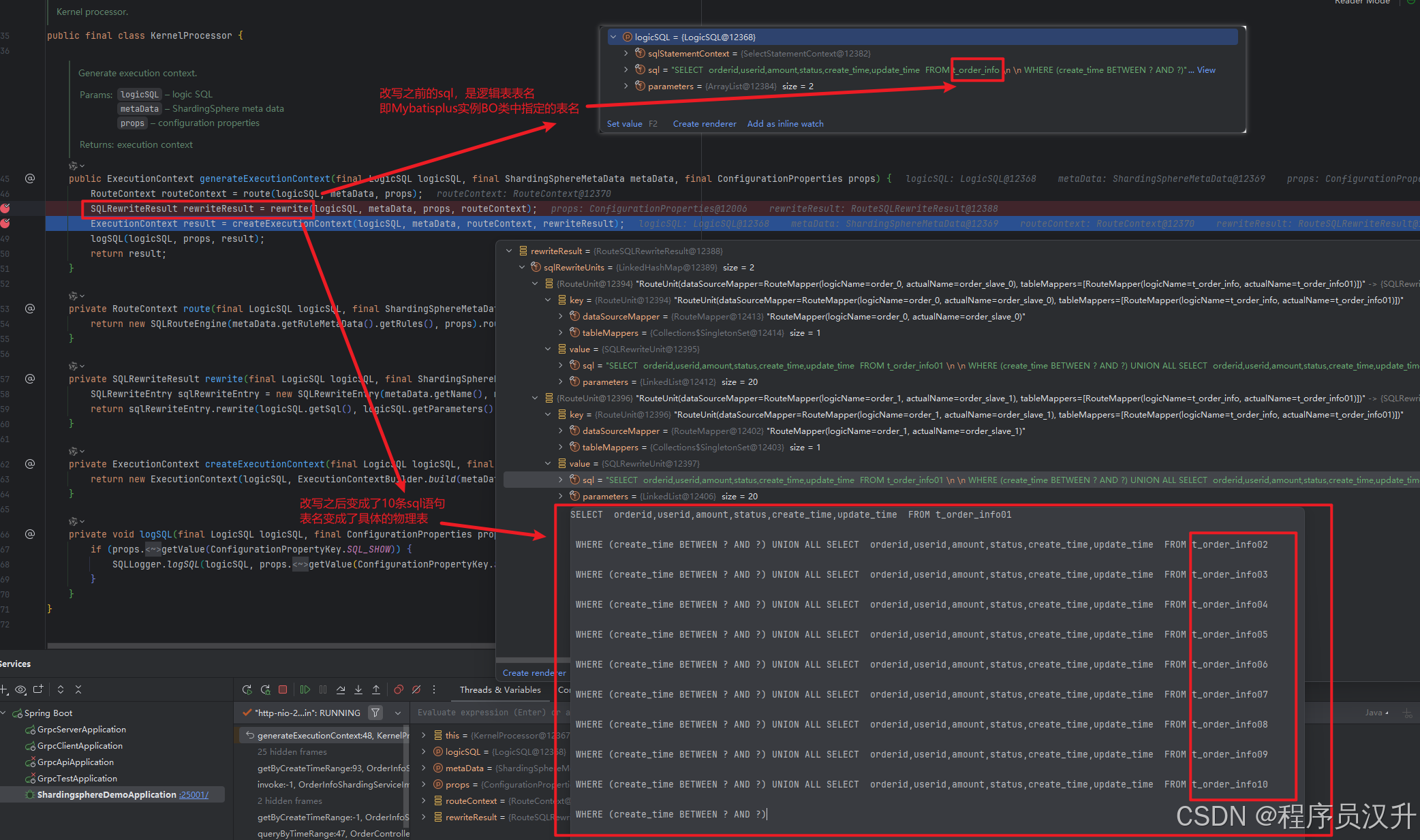
2.5 SQL执行
在KernelProcessor核心类的generateExecutionContext()方法中第三步就是创建可执行的上下文
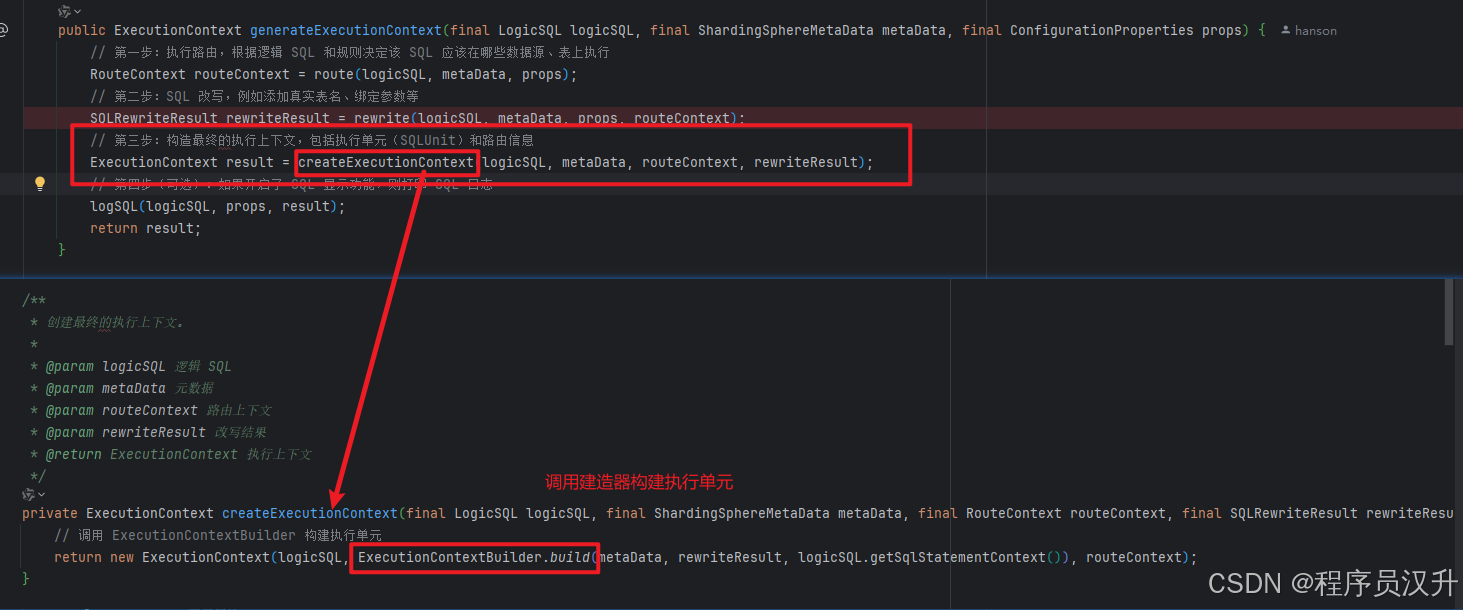
SQL的执行器ExecutionContextBuilder源码
/**
* Execution context builder.
* 执行上下文构建器,用于根据 SQL 改写结果生成最终的 SQL 执行单元(ExecutionUnit)。
*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class ExecutionContextBuilder {
/**
* 构建 SQL 执行单元集合。
*
* @param metaData ShardingSphere 元数据
* @param sqlRewriteResult SQL 改写结果,可能是单路由或多路由
* @param sqlStatementContext SQL 语句上下文(包含表、参数等绑定信息)
* @return SQL 执行单元(ExecutionUnit)集合
*/
public static Collection<ExecutionUnit> build(final ShardingSphereMetaData metaData, final SQLRewriteResult sqlRewriteResult, final SQLStatementContext<?> sqlStatementContext) {
// 判断 SQL 是否为通用改写结果(即不依赖具体数据节点的情况,如广播表、无表 DML 等)
return sqlRewriteResult instanceof GenericSQLRewriteResult
? build(metaData, (GenericSQLRewriteResult) sqlRewriteResult, sqlStatementContext) :
build((RouteSQLRewriteResult) sqlRewriteResult);// 否则为路由相关改写结果
}
/**
* 构建通用 SQL 改写结果的执行单元(仅涉及单数据源场景)。
*/
private static Collection<ExecutionUnit> build(final ShardingSphereMetaData metaData, final GenericSQLRewriteResult sqlRewriteResult, final SQLStatementContext<?> sqlStatementContext) {
Collection<String> instanceDataSourceNames = metaData.getResource().getDataSourcesMetaData().getAllInstanceDataSourceNames();
if (instanceDataSourceNames.isEmpty()) {
return Collections.emptyList();
}
// 通用 SQL 情况下,只需要取出任意一个数据源执行即可
return Collections.singletonList(new ExecutionUnit(instanceDataSourceNames.iterator().next(),
new SQLUnit(sqlRewriteResult.getSqlRewriteUnit().getSql(), sqlRewriteResult.getSqlRewriteUnit().getParameters(), getGenericTableRouteMappers(sqlStatementContext))));
}
/**
* 构建包含具体路由信息的 SQL 执行单元。
*/
private static Collection<ExecutionUnit> build(final RouteSQLRewriteResult sqlRewriteResult) {
Collection<ExecutionUnit> result = new LinkedHashSet<>(sqlRewriteResult.getSqlRewriteUnits().size(), 1f);
for (Entry<RouteUnit, SQLRewriteUnit> entry : sqlRewriteResult.getSqlRewriteUnits().entrySet()) {
result.add(new ExecutionUnit(
// 路由到的实际数据源名称
entry.getKey().getDataSourceMapper().getActualName(),
new SQLUnit(
entry.getValue().getSql(),
entry.getValue().getParameters(),
getRouteTableRouteMappers(entry.getKey().getTableMappers())
)));
}
return result;
}
/**
* 获取路由改写时使用的逻辑表到真实表的映射关系。
*/
private static List<RouteMapper> getRouteTableRouteMappers(final Collection<RouteMapper> tableMappers) {
if (null == tableMappers) {
return Collections.emptyList();
}
List<RouteMapper> result = new ArrayList<>(tableMappers.size());
for (RouteMapper each : tableMappers) {
// 将路由后的逻辑表名和实际表名封装为 RouteMapper 对象
result.add(new RouteMapper(each.getLogicName(), each.getActualName()));
}
return result;
}
/**
* 获取通用改写的逻辑表名映射(实际表名与逻辑表名相同)。
*/
private static List<RouteMapper> getGenericTableRouteMappers(final SQLStatementContext<?> sqlStatementContext) {
TablesContext tablesContext = null;
if (null != sqlStatementContext) {
tablesContext = sqlStatementContext.getTablesContext();
}
// 对所有逻辑表名生成“逻辑 = 实际” 的 RouteMapper
return null == tablesContext
? Collections.emptyList()
: tablesContext.getTableNames().stream()
.map(tableName -> new RouteMapper(tableName, tableName))
.collect(Collectors.toList());
}
}
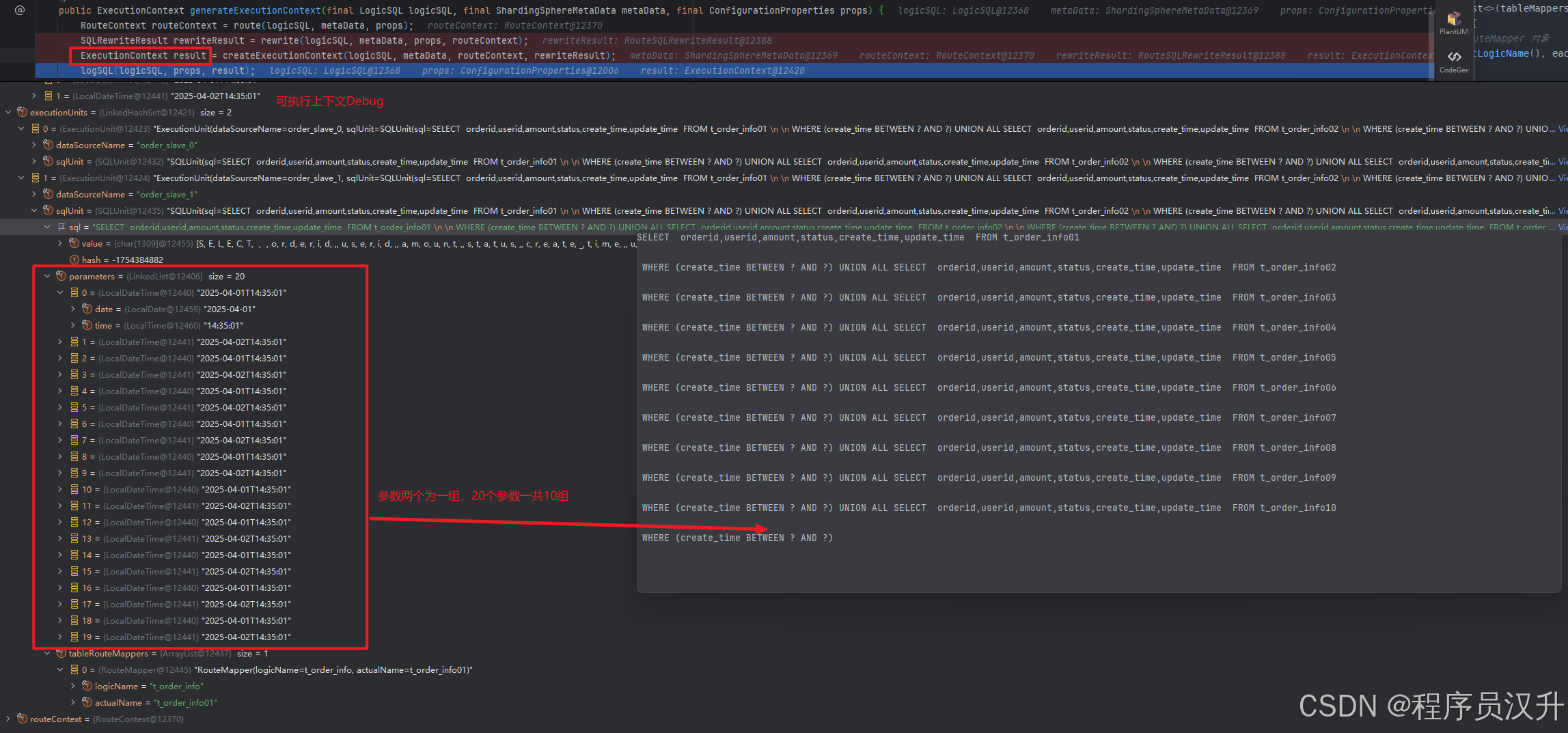
延迟执行:ExecutionUnit 只是 执行任务的描述,实际执行由后续的 ExecutorEngine 处理。
/**
* 执行器引擎(ExecutorEngine)。
*
* 这个类用于管理 SQL 执行的并发线程池,并封装了串行或并行执行任务的流程逻辑。
* 它是整个 SQL 执行调度的核心,可以根据配置决定是串行还是并行执行。
*/
@Getter
public final class ExecutorEngine implements AutoCloseable {
// 管理线程池的工具类,用于获取线程池对象SQLStatementParserEngineFactory
private final ExecutorServiceManager executorServiceManager;
/**
* 构造方法。
*
* @param executorSize 线程池的线程数
*/
public ExecutorEngine(final int executorSize) {
executorServiceManager = new ExecutorServiceManager(executorSize);
}
/**
* 执行入口方法(简化版本,默认并行执行)。
*
* @param executionGroupContext 执行分组上下文
* @param callback 每组执行的回调
* @param <I> 输入数据类型
* @param <O> 输出结果类型
* @return 执行结果列表
* @throws SQLException 如果执行失败
*/
public <I, O> List<O> execute(final ExecutionGroupContext<I> executionGroupContext, final ExecutorCallback<I, O> callback) throws SQLException {
return execute(executionGroupContext, null, callback, false);
}
/**
* 执行主方法(支持串行或并行、支持设置首次回调)。
*
* @param executionGroupContext 执行组上下文
* @param firstCallback 第一个执行组使用的回调(可选)
* @param callback 其余执行组使用的回调
* @param serial 是否串行执行
* @param <I> 输入类型
* @param <O> 输出类型
* @return 执行结果集合
* @throws SQLException 执行失败时抛出
*/
public <I, O> List<O> execute(final ExecutionGroupContext<I> executionGroupContext,
final ExecutorCallback<I, O> firstCallback, final ExecutorCallback<I, O> callback, final boolean serial) throws SQLException {
if (executionGroupContext.getInputGroups().isEmpty()) {
return Collections.emptyList();
}
return serial ? serialExecute(executionGroupContext.getInputGroups().iterator(), firstCallback, callback)
: parallelExecute(executionGroupContext.getInputGroups().iterator(), firstCallback, callback);
}
// 串行执行所有任务组
private <I, O> List<O> serialExecute(final Iterator<ExecutionGroup<I>> executionGroups, final ExecutorCallback<I, O> firstCallback, final ExecutorCallback<I, O> callback) throws SQLException {
ExecutionGroup<I> firstInputs = executionGroups.next();
// 执行第一个任务组(可以使用专属回调)
List<O> result = new LinkedList<>(syncExecute(firstInputs, null == firstCallback ? callback : firstCallback));
// 其余任务组用统一回调串行执行
while (executionGroups.hasNext()) {
result.addAll(syncExecute(executionGroups.next(), callback));
}
return result;
}
// 并行执行剩余任务组,第一个任务组同步执行
private <I, O> List<O> parallelExecute(final Iterator<ExecutionGroup<I>> executionGroups, final ExecutorCallback<I, O> firstCallback, final ExecutorCallback<I, O> callback) throws SQLException {
ExecutionGroup<I> firstInputs = executionGroups.next();
Collection<ListenableFuture<Collection<O>>> restResultFutures = asyncExecute(executionGroups, callback);
return getGroupResults(syncExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures);
}
// 同步执行某一个 ExecutionGroup
private <I, O> Collection<O> syncExecute(final ExecutionGroup<I> executionGroup, final ExecutorCallback<I, O> callback) throws SQLException {
return callback.execute(executionGroup.getInputs(), true, ExecutorDataMap.getValue());
}
// 异步执行所有剩余 ExecutionGroup
private <I, O> Collection<ListenableFuture<Collection<O>>> asyncExecute(final Iterator<ExecutionGroup<I>> executionGroups, final ExecutorCallback<I, O> callback) {
Collection<ListenableFuture<Collection<O>>> result = new LinkedList<>();
while (executionGroups.hasNext()) {
result.add(asyncExecute(executionGroups.next(), callback));
}
return result;
}
// 异步提交单个任务组到线程池
private <I, O> ListenableFuture<Collection<O>> asyncExecute(final ExecutionGroup<I> executionGroup, final ExecutorCallback<I, O> callback) {
Map<String, Object> dataMap = ExecutorDataMap.getValue();
return executorServiceManager.getExecutorService().submit(() -> callback.execute(executionGroup.getInputs(), false, dataMap));
}
// 获取所有执行结果(同步结果 + 异步 future 结果)
private <O> List<O> getGroupResults(final Collection<O> firstResults, final Collection<ListenableFuture<Collection<O>>> restFutures) throws SQLException {
List<O> result = new LinkedList<>(firstResults);
for (ListenableFuture<Collection<O>> each : restFutures) {
try {
result.addAll(each.get());
} catch (final InterruptedException | ExecutionException ex) {
return throwException(ex);
}
}
return result;
}
// 处理异常抛出
private <O> List<O> throwException(final Exception exception) throws SQLException {
if (exception.getCause() instanceof SQLException) {
throw (SQLException) exception.getCause();
}
throw new ShardingSphereException(exception);
}
// 优雅关闭线程池
@Override
public void close() {
executorServiceManager.close();
}
}
支持通过串行或并行来执行主方法,然后通过JDBCExecutor、DriverJDBCExecutor和ShardingSpherePreparedStatement直接调用原生JDBC方法
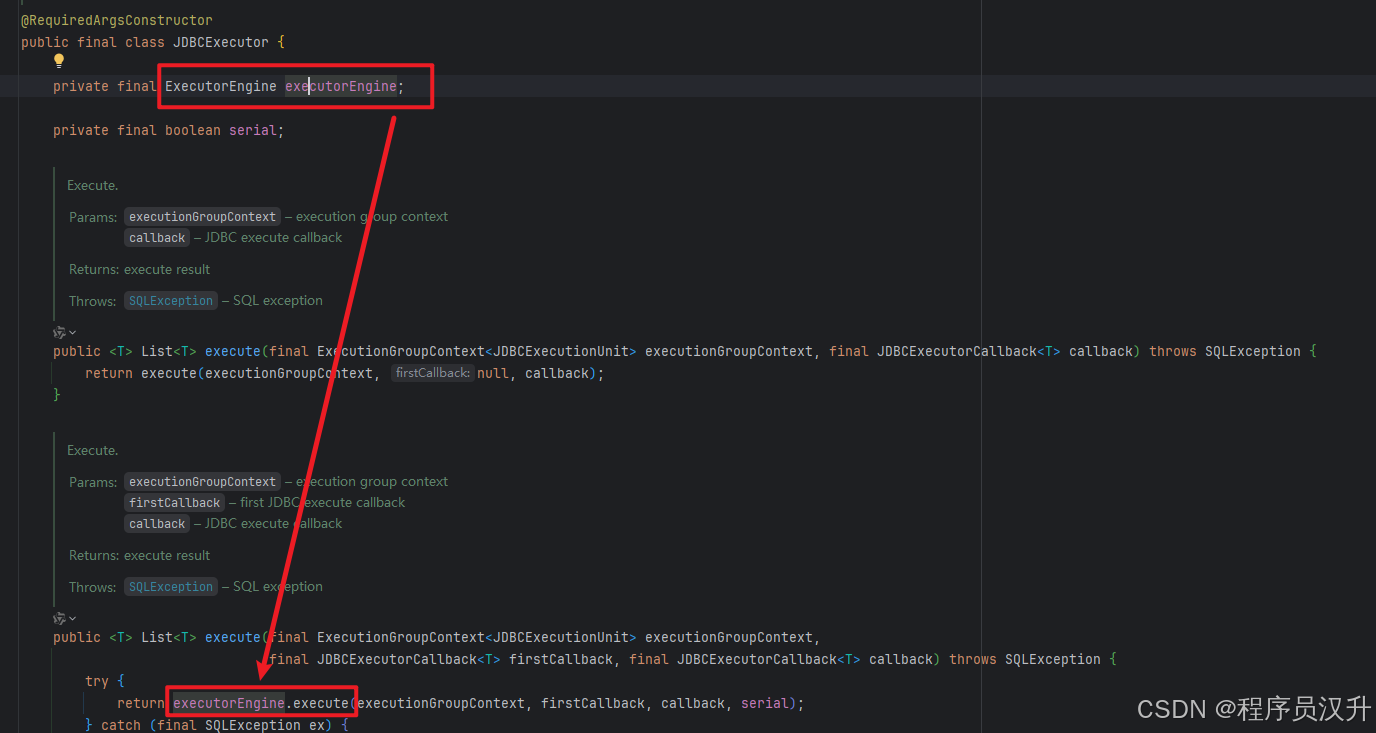

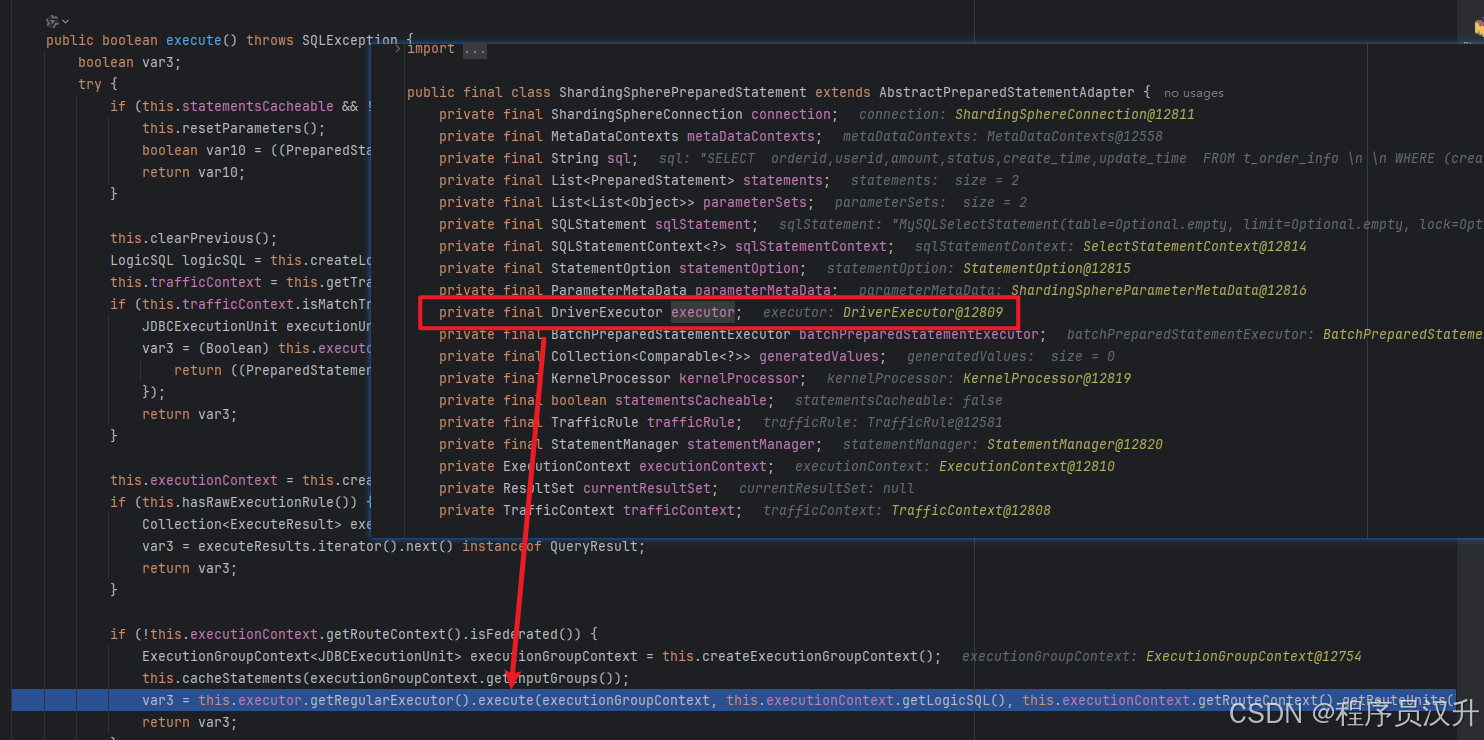
调用原生增删查改接口,且查询语句占位符数据已被替换
最后查出结果集
总结
完整流程图如下:
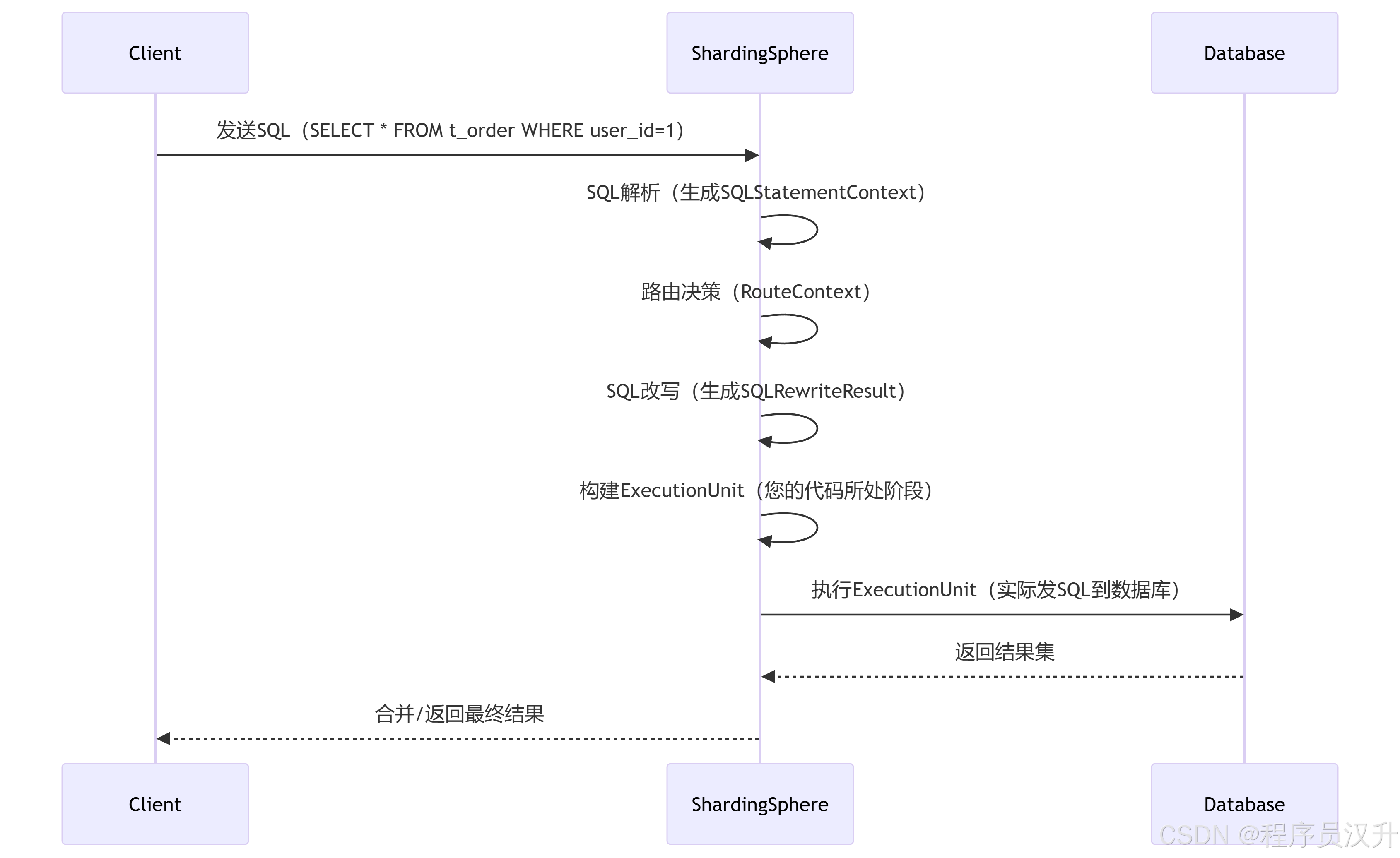
码字不易。如果有收获不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









