







mAP:mean Average Precision,平均精度均值,即AP(Average Precision)的平均值,它是目标检测算法的主要评估指标。目标检测模型通常会用速度和精度(mAP)指标描述优劣,mAP值越高,表明该目标检测模型在给定的数据集上的检测效果越好。
既然mAP是AP(Average Precision)的平均值,那么首先要了解AP的定义和计算方法。要了解AP的定义,首先需要区别什么是精(Precision),什么是准(Accuracy)?
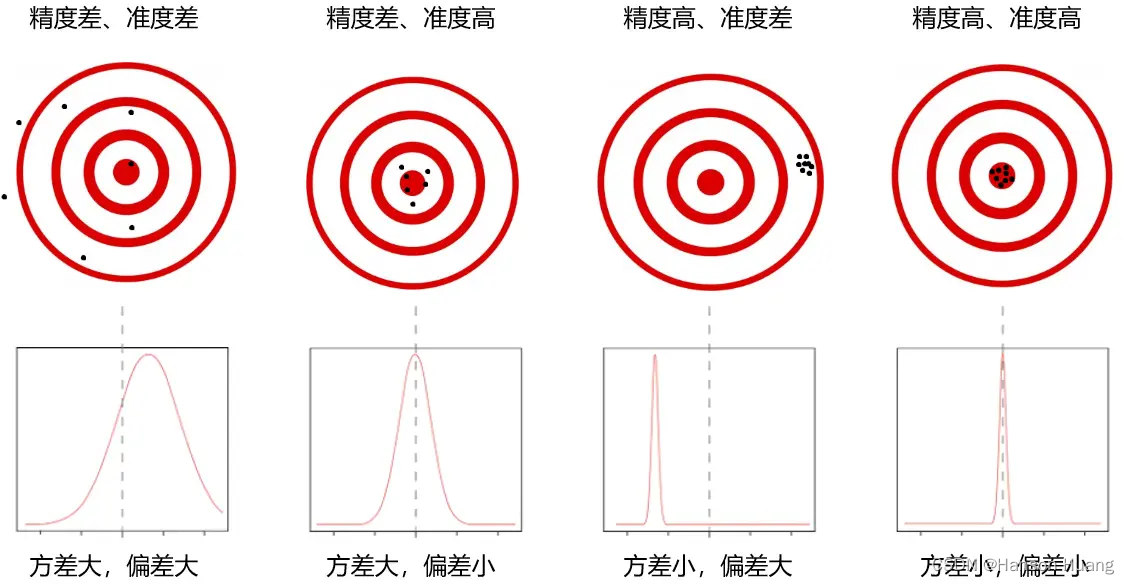
Precision指精度,意味着随机误差(Random Error)小,即方差(Variance)小,描述了实际值的扰动情况。
Accuracy指准度,意味着系统误差(System Error)小,即偏差(Bias) 小,描述了的实际值与真实结果的偏离程度
准确度高,意味着误差(Error)小,Error = Bias + Variance
在机器学习中,可以将预测分为四种情况
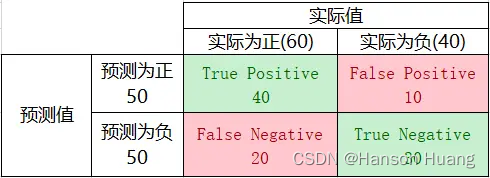
True Positive(TP): 预测为正,实际为正,预测对了
False Negative(FN): 预测为负,实际为正,预测错了
False Positive(FP): 预测为正,实际为负,预测错了
True Negative(TN): 预测为负,实际为负,预测对了
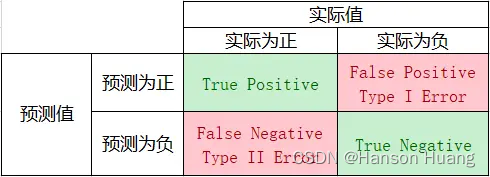
例如,有60个正样本,40个负样本,系统预测了50个正样本,其中40个是预测正确的正样本;预测了50个负样本,其中30个是预测正确的负样本。TP=40,FP=10;FN=20,TN=30。
定义:

可得上例中:
Precision(精确度) = 40/(40+10)=80%
Recall(召回率) = 40/(40+20)=66.7%;
Accuracy(准确度) = (40+30)/(40+10+30+20) = 70%
F1 Score = 240/(240+10+20) = 72.7%
由此可见:
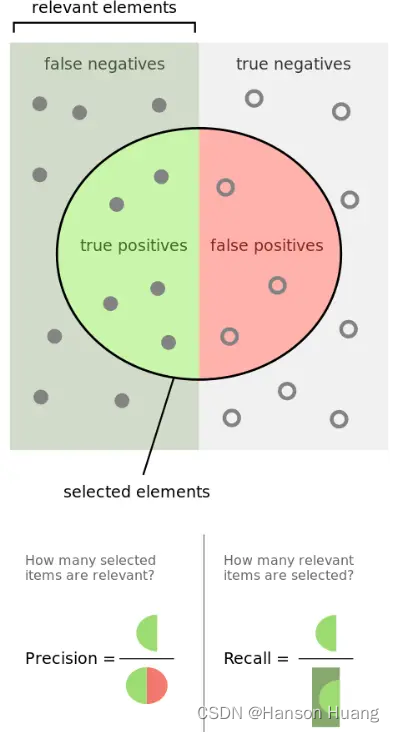
Precision是预测为正实际为正占预测为正的比例,Precision可以视作是模型找出来的数据的正确能力,Precision=1表示模型找一个对一个,Presicion=0.5表示模型找出2个,能对1个。
Recall是预测为正实际为正占总体正样本的比例,Recall可以视作是模型在数据集中,检测出目标类型数据的能力,即是否把想找出来的都找出来了,Recall=1表示已经把想找出来的数据全部找出来了。
Accuracy是预测为正实际为正和预测为负实际负占总样本的比例。
F1 Score是Precision与Recall的调和平均(harmonic mean),是综合Precision与Recall的评估指标,避免Precision或Recall的单一极大值,用于综合反映整体的指标。
一图以蔽之
对于目标检测(Object Detection)算法来说,Precision 和 Recall与上述的定义略有不同。
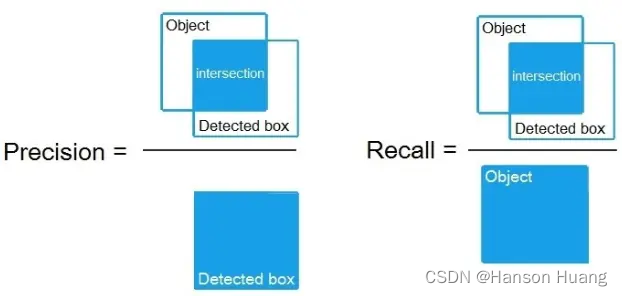
Precision与Recall曲线:把每次预测结果的Precision和Recall计算出来,并按照关系画出曲线,就是P-R曲线。
把所有样本预测为正,则Recall=1,表示模型把所有该识别的样本都识别出来了,但此时Precision很差。由此可见,优化模式的检测能力,本质是Precision和Recall的Tradeoff的过程。
F1 Score是Precision与Recall的调和平均(harmonic mean),表征模型的综合能力,避免Precision或Recall的单一极大值。Precision很大、Recall很小;或Precision很小,Recall很大,都不是好的检测能力,如下图所示。
了解了什么是precison-recall-f1后,还需要了解目标检测中的两个基本概念:Confidence Score和IoU。
Confidence Score 置信度分数是一个分类器(Classifier)预测一个锚框(Anchor Box)中包含某个对象的概率(Probability)。通过设置Confidence Threshold置信度阈值可以过滤掉(不显示)小于threshold的预测对象。
IoU详情见文章《NMS及IOU原理讲解和代码解析》
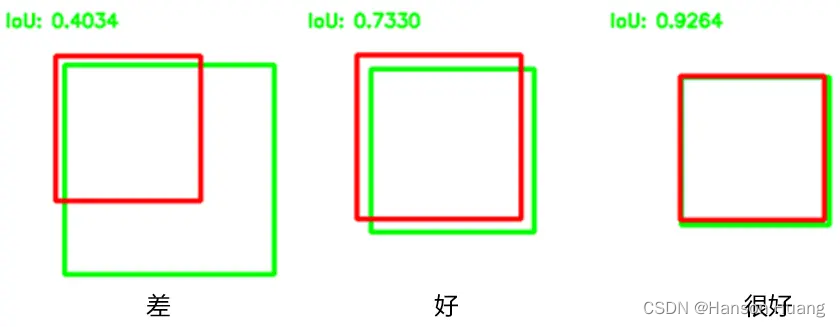
IoU (Intersection over union)交并比,预测框(Prediction)与原标记框(Ground truth)之间的重叠度(Overlap),最理想情况是完全重叠,即比值为1。IoU用于衡量预测框的准确度。

一般来说,IoU≥ 0.5 就可以被认为一个不错的结果了。
Confidence Score和IoU共同决定一个检测结果(detection)是Ture Positive还是False Positive,伪代码如下:

在目标检测算法中,当一个检测结果(detection)被认为是True Positive时,需要同时满足下面三个条件:
- Confidence Score > Confidence Threshold
- 预测类别匹配(match)真实值(Ground truth)的类别
- 预测边界框(Bounding box)的IoU大于设定阈值,如0.5
不满足条件2或条件3,则认为是False Positive。
当对应同一个真值有多个预测结果时(In case multiple predictions correspond to the same ground-truth),只有最高置信度分数的预测结果被认为是True Positive,其余被认为是False Positive。
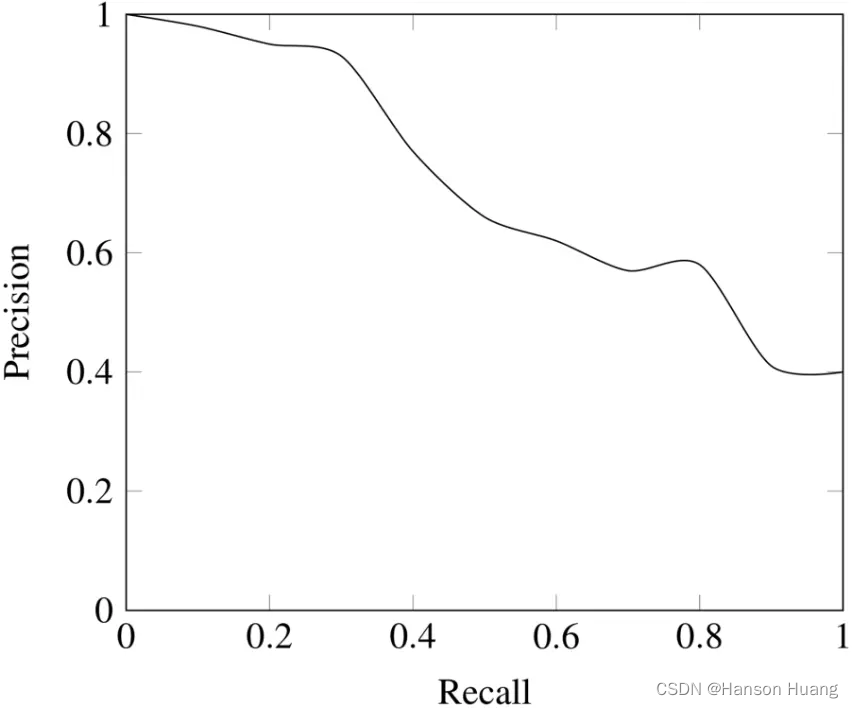
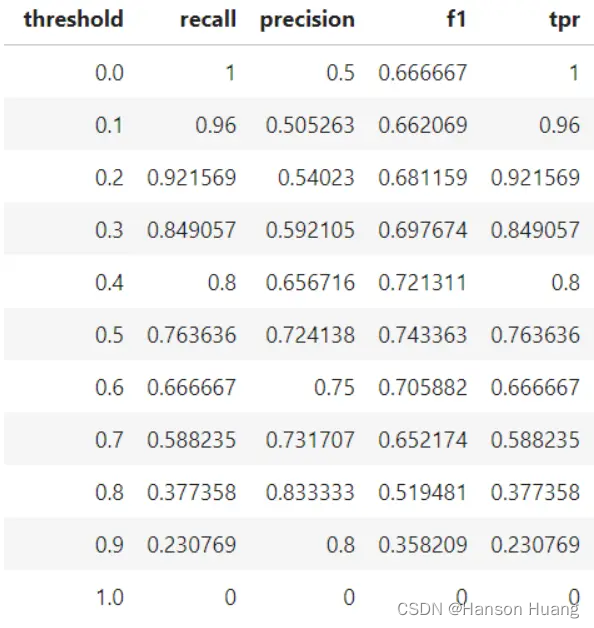
改变不同的置信度阈值,可以获得多对Precision和Recall值,Recall值放X轴,Precision值放Y轴,可以画出一个Precision-Recall曲线,简称P-R曲线。

如上图所示,当Threshold单调下降的时候,recall是单调上升的;而Precision总体趋势是下降的,局部趋势可能上升,也可能下降,走的所谓“zigzag”形状。
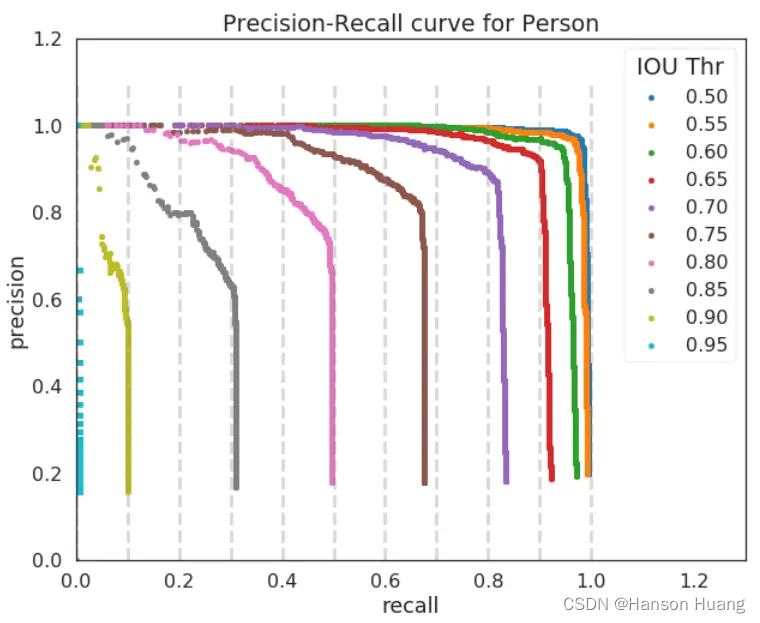
改变IoU的阈值,绘制recall和IoU关系曲线。当IoU≥0.5,检测结果才被认为是True Positive,所以绘制曲线的时候,IoU取值 0.5≤IoU≤1.0。
改变IoU的阈值,绘制recall和IoU关系曲线。当IoU≥0.5,检测结果才被认为是True Positive,所以绘制曲线的时候,IoU取值 0.5≤IoU≤1.0。

从Recall-IoU曲线可以看出,Recall跟IoU是单调递减关系,即IoU增加,Recall减少。
了解Confidence Score、IoU、Precision-Recall曲线以及Recall-IoU曲线后,下面本文将介绍目标检测的关键性能评估指标:AP(Average Precision),mAP(mean Average Precision)
单类别AP(Average Precision)的计算
物体检测中的每一个预测结果包含两部分,预测框(bounding box)和置信概率(Pc)。bounding box通常以矩形预测框的左上角和右下角的坐标表示,即x_min, y_min, x_max, y_max,如下图。置信概率Pc有两层意思,一是所预测bounding box的类别,二是这个类别的置信概率,如下图中的P_dog=0.88,代表预测绿色框为dog,并且置信概率为88%。

那么,怎么才叫预测正确呢?显而易见的,必须满足两个条件:
类别正确且置信度大于一定阀值(P_threshold)
预测框与真实框(ground truth)的IoU大于一定阀值(IoU_threshold)
如下图,假如P_threshold=0.6,IoU_threshold=0.5,则绿色框预测正确,记为True Positive。

而在衡量模型性能时,IoU_threshold先取一个定值,然后综合考虑各种P_threshold取值时的性能,进而得到一个与P_threshold选定无关的模型性能衡量标准。
AP是计算单类别的模型平均准确度。
Precision-Recall曲线可以衡量目标检测模型的好坏,但不便于模型和模型之间比较。在Precision-Recall曲线基础上,通过计算每一个recall值对应的Precision值的平均值,可以获得一个数值形式(numerical metric)的评估指标:AP(Average Precision),用于衡量的是训练出来的模型在感兴趣的类别上的检测能力的好坏。
在计算AP前,为了平滑P-R曲线,减少曲线抖动的影响,首先对P-R曲线进行插值(interpolation)。给定某个recall值r,用于插值的P_interp为下一个recall值r’,与当前r值之间的最大的Precision值。
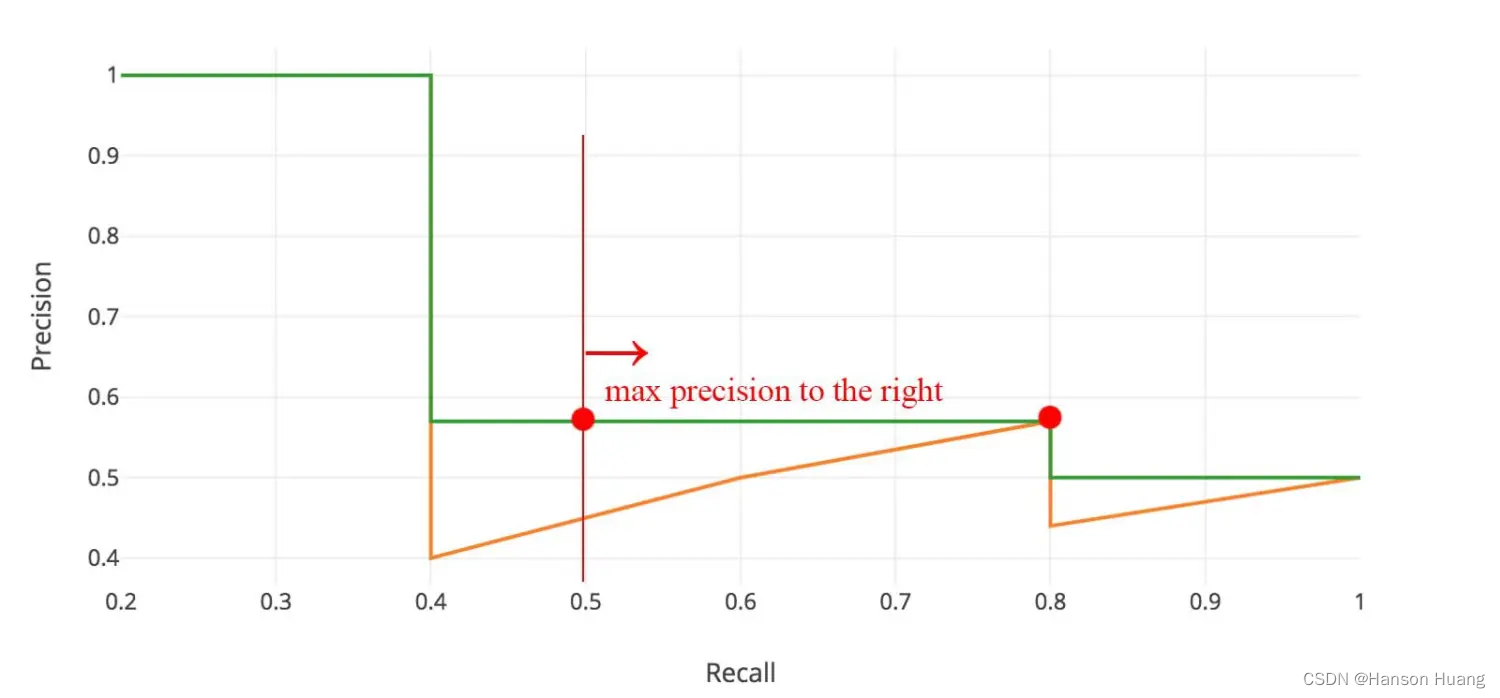
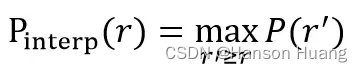
PASCAL VOC挑战赛计算AP的老标准VOC07是:等间距选取11个recall点,[0.0,0.1,0.2…0.8,0.9,1.0],然后取这11个recall点对应的Precision值做平均。
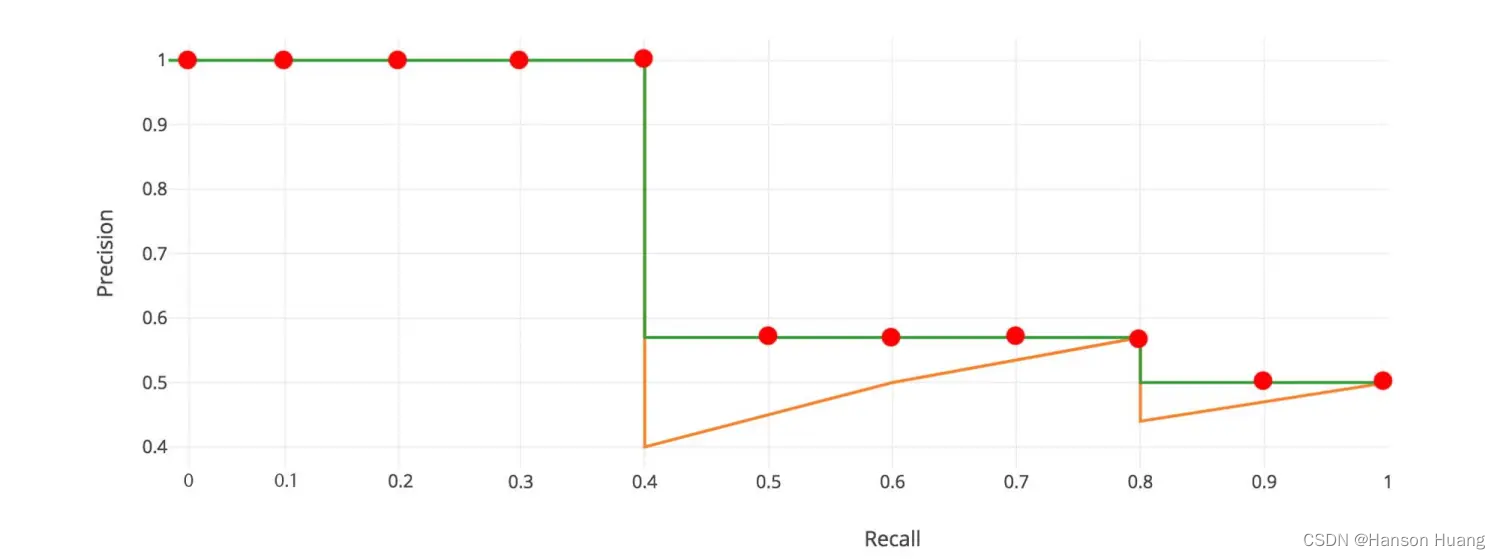
以上图为例,AP的计算过程为

2010年后的新标准是取所有不同的recall点对应的Precision值做平均,如下图所示。新标准算出的AP更准。

根据新标准,AP计算可以定义为经过插值的precision-recall曲线与X轴包络的面积。这种方式称为:AUC (Area under curve)
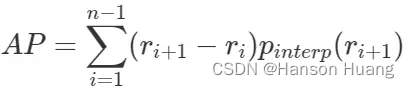
r1,r2,…,rn是按升序排列的Precision插值段第一个插值处对应的recall值。
AP计算的Python代码实现voc_eval.py,如下所示。

AP值计算仅仅是针对一个类别,得到AP后mAP的计算就变得很简单了,就是计算所有类别的AP,然后取平均值。mAP衡量的是训练出来的模型在所有类别上的检测能力的好坏。
假设有K种类别,K>1,那么mAP的计算公式为:
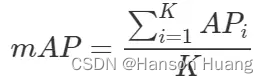
当K=1时,mAP = AP。
Pascal VOC新标准定义的mAP计算方式可以认为是mAP的标准计算方式。
COCO挑战赛定义了12种mAP计算方式,典型的有:
mAP(IoU@0.5),跟Pascal VOC mAP标准计算方式一致;
mAP(IoU@[0.5:0.05:0.95]),需要计算10个IoU阈值下的mAP,然后计算平均值。这个评估指标比仅考虑通用IoU阈值(0.5)评估指标更能体现出模型的精度。
mAP(IoU@0.75),这是一个对检测能力要求更高的标准。
除了根据不同的IoU阈值来计算mAP外,还可以根据检测目标的大小来计算。
mAP@small,检测目标的面积 ≤ 32x32
mAP@medium,32x32 < 检测目标的面积 ≤ 96x96
mAP@Large,96x96 < 检测目标的面积
TensorFlow Object Detection API框架给出了支持的目标检测能力评估协议,通过配置参数,可以让TensorFlow Object Detection API框架采用不同的mAP计算方式。
Metrics for object detection这个开源项目给出了PASCAL VOC、COCO、Open Images Dataset V4和ImageNet Object Localization(AUC方法)四大比赛的评估指标计算方法的代码实现。
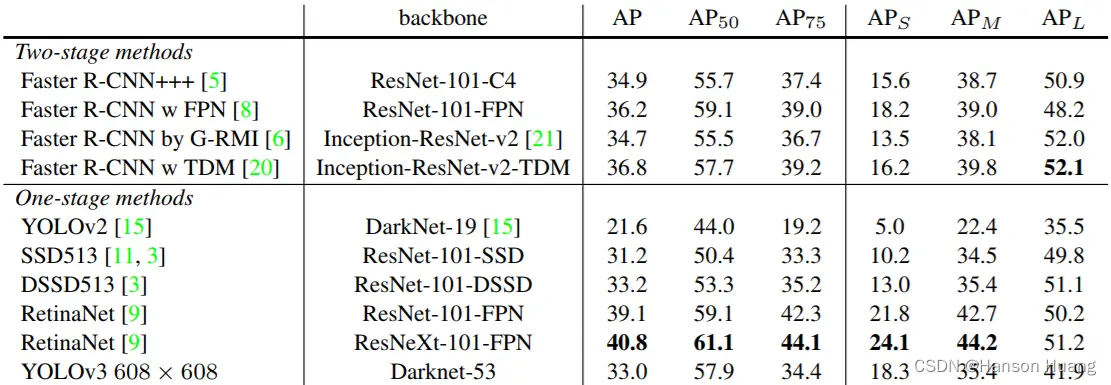
YOLOv3的评估指标,如下
总结
查准率其实就是精确度,当Precision=1的时候就意味着我找一个对一个,Precision=0.1的时候意味着我找了十个检测框才对了一个,所以我们需要这个值越大越好,but要是只限制这一个指标的时候,然而这就会出现找不全的情况。即一共十个目标,我只找了一个检测框,这个检测框是对的,这时候我的precision也是1,所以为了避免这种情况的出现,就加了另外一个定义:查全率–召回率。Recall是预测为正实际为正占总体正样本的比例,Recall可以视作是模型在数据集中,检测出目标类型数据的能力,即是否把想找出来的都找出来了,Recall=1表示已经把想找出来的数据全部找出来了。所以就加了这个限制,也是为什么在这两个坐标轴下呈现下降的情况,所以我们需要的最好的情况就是precision=1 AND Recall=1而在这种情况下AUC就是最容易计算的一种方式。

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









