







📚 目录(快速跳转)
- 选择题(上午题)(每题1分,共75分)
- 一、 计算机系统基础知识 🖥️
- 💻 题目1:计算机组成原理 - 冯诺依曼体系结构
- 💻 题目2:计算机组成原理 - SRAM与DRAM对比
- 💻 题目3:计算机体系结构 - 中断处理与现场保存
- 🔧 题目4:计算机体系结构 - RISC与CISC对比
- ⚙️ 题目5:系统可靠性计算
- 🔄 题目6:计算机系统通信 - 异步传输方式
- 🐍 题目20:程序语言设计 - python工具
- 🐍 题目21:程序语言设计 - python列表操作
- 🐍 题目22:程序语言设计 - python数据结构
- 🗃️ 题目23:数据库 - 视图的存储原理
- 🗃️ 题目24-25:数据库关系代数 - 自然连接与选择运算
- 🗂️ 题目26:数据结构 - 散列表特性
- 🌳 题目27:数据结构 - 折半查找判定树
- 🌲 题目28:树的性质 - 叶子节点计算
- 🔄 题目29:排序算法 - 稳定性判定
- 🏷️ 题目30:图论 - 邻接表边结点奇偶性
- 🌐 题目31:网络体系结构 - OSI参考模型层次功能
- 💻 题目32:网络协议 - 远程登录服务
- 🌐 题目33:浏览器隐私 - 无痕浏览模式
- 📧 题目34:电子邮件协议 - 非相关协议识别
- 📝 题目35:形式语言与文法 - 推导字符串分析
- 🖥️ 题目36:操作系统 - 段页式存储管理
- 🖥️ 题目37-38:文件系统 - 位示图计算
- 🎒 题目39-40:算法设计 - 背包问题
- 🌳 题目41:数据结构 - 二叉树编号与父子关系
- 📊 题目42-43:算法设计 - 排序算法复杂度分析
- 🌐 题目44:FTP访问流程 - 初始操作
- 📊 题目45:数据流图 - 基本加工规则
- 🧩 题目 46:模块化设计 - 作用范围与控制范围
- 🧩 题目47:项目管理 - 风险管理
- 🧠 题目48:引用调用机制 - 参数传递的本质
- 🔢 题目49:算术表达式后缀式转换 - 操作符优先级解析
- ⚙️ 题目50:嵌入式操作系统的可定制性 - 面向硬件变化的配置需求
- 🔄 题目51:多态的不同形式 - 过载多态的应用
- 🏞️ 题目52:开发过程模型 - 瀑布模型的局限性
- 🔍 题目53-54:编译过程中的语句翻译与执行
- 💻 题目56-57:计算机体系结构 - Windows文件系统路径解析
- 🖥️ 题目58-61:操作系统 - PV操作与进程同步
- 📦 题目62-64:数据库设计 - UML序列图综合解析
- 🧩 题目65-66:数据结构与算法 - Prim算法与最小生成树
- 二、 系统开发和运行知识 🗃️
- 三、 面向对象基础知识 🧩
- 四、 网络与信息安全知识 🌐
- 五、 标准化、信息化和知识产权基础知识 🛠️
- 六、 计算机英语 🐧
选择题(上午题)(每题1分,共75分)
2022年上半年上午题试卷:百度云盘
💡 注意:文章按照知识点顺序总结,未按真题顺序
一、 计算机系统基础知识 🖥️
💻 题目1:计算机组成原理 - 冯诺依曼体系结构
以下关于冯诺依曼计算机的叙述中,不正确的是 (1) 。
(1)
A. 程序指令和数据都采用二进制表示
B. 程序指令总是存储在主存中,而数据则存储在高速缓存中 ✅
C. 程序的功能都由中央处理器(CPU)执行指令来实现
D. 程序的执行工作由指令进行自动控制
📌 正确答案:B
🔍 详细解析
冯诺依曼体系结构 的核心设计思想包括:
-
二进制表示:
- 程序指令和数据均以二进制形式存储和处理(选项 A 正确)。
-
存储程序控制:
-
指令和数据混合存储在主存中,而非固定分离(选项 B 错误)。
-
高速缓存(Cache)是后来为提高性能引入的,并非冯诺依曼原始设计的一部分。
-
-
CPU 集中执行:
-
所有程序功能由 CPU 按指令顺序执行(选项 C 正确)。
-
程序的流程由指令自动控制,无需人工干预(选项 D 正确)。
-
-
五大部件:
- 运算器、控制器、存储器、输入设备、输出设备。
💡 知识点扩展
冯诺依曼 vs 哈佛体系结构 对比:
| 特性 | 冯诺依曼体系结构 | 哈佛体系结构 |
|---|---|---|
| 存储方式 | 指令和数据共用同一存储空间 | 指令和数据分开存储 |
| 总线设计 | 单一总线 | 独立指令总线和数据总线 |
| 典型应用 | 通用计算机(如 PC) | 嵌入式系统、DSP |
💻 题目2:计算机组成原理 - SRAM与DRAM对比
以下关于 SRAM 和 DRAM 存储器的叙述中正确的是 (2) 。
(2)
A. 与 DRAM 相比,SRAM 集成率低,功率大、不需要动态刷新 ✅
B. 与 DRAM 相比,SRAM 集成率高,功率小、需要动态刷新
C. 与 SRAM 相比,DRAM 集成率高,功率大、不需要动态刷新
D. 与 SRAM 相比,DRAM 集成率高,功率大、需要动态刷新
📌 正确答案:A
🔍 详细解析
| SRAM | DRAM | |
|---|---|---|
| 存储原理 | 触发器(Flip-Flop) | 电容 |
| 读出 | 非破坏性 | 破坏性 |
| 刷新 | 不用 | 用 |
| 送地址 | 一起送 | 行列分开送 |
| 速度 | 快 | 慢 |
| 继承度 | 低 | 高 |
| 功耗 | 高 | 低 |
| 成本 | 高 | 低 |
| 用途 | CPU缓存(L1/L2/L3 Cache) | 主存(内存条) |
💻 题目3:计算机体系结构 - 中断处理与现场保存
为了实现多级中断,保存程序现场信息最有效的方法是使用 (3) 。
(3)
A. 通用寄存器
B. 累加器
C. 堆栈 ✅
D. 程序计数器
📌 正确答案:C
🔍 详细解析
多级中断的现场保存需求与实现方式:
-
为什么需要保存现场?
-
中断发生时,必须保存当前程序的执行状态(如寄存器值、程序计数器PC等),以便中断结束后恢复原程序继续运行。
-
多级中断(嵌套中断)中,需按顺序保存和恢复多个中断的现场信息。
-
-
堆栈(Stack)的优势:
-
后进先出(LIFO)特性:完美匹配多级中断的嵌套顺序(最后发生的中断最先返回)。
-
高效性:通过简单的栈指针(SP)操作即可快速保存/恢复数据。
-
完整性:可保存所有寄存器、状态字、返回地址等现场信息。
-
-
其他选项的局限性:
-
A. 通用寄存器:数量有限,无法处理多级嵌套,且可能被中断程序覆盖。
-
B. 累加器:仅能存储单一数据,无法满足多字段现场保存需求。
-
D. 程序计数器(PC):仅能保存返回地址,无法存储其他现场信息。
-
💡 知识点扩展
中断处理流程(以堆栈为例):
-
中断触发:CPU暂停当前程序,跳转到中断服务程序(ISR)。
-
现场保存:将PC、状态寄存器、通用寄存器等压入堆栈。
-
执行ISR:若发生更高优先级中断,重复步骤1-2(嵌套中断)。
-
恢复现场:从堆栈弹出数据,还原寄存器状态,返回原程序。
🔧 题目4:计算机体系结构 - RISC与CISC对比
以下关于 RISC 和 CISC 的叙述中,不正确的是 (4) 。
(4)
A. RISC 的大多指令在一个时钟周期内完成
B. RISC 普遍采用微程序控制器,CISC 则普遍采用硬布线控制器 ✅
C. RISC 的指令种类和寻址方式相对于 CISC 更少
D. RISC 和 CISC 都采用流水线技术
📌 正确答案:B
🔍 详细解析
RISC(精简指令集)与CISC(复杂指令集)的核心差异:
-
控制器设计:
-
RISC 采用硬布线控制器(直接由硬件逻辑电路实现指令解码),追求高速和低延迟(选项 B 错误,是本题答案)。
-
CISC 采用微程序控制器(通过微代码解释复杂指令),灵活性高但速度较慢。
-
-
指令执行周期:
-
RISC 指令精简,单周期完成(选项 A 正确)。
-
CISC 指令复杂,多周期完成。
-
-
指令集复杂度:
-
RISC 指令种类少、寻址方式简单(选项 C 正确)。
-
CISC 指令丰富,支持复杂寻址。
-
-
流水线技术:
- 两者均可采用流水线,但 RISC 的简单指令更易实现高效流水化(选项 D 正确)。
💡 知识点扩展
RISC vs CISC 关键特性对比表:
| 特性 | RISC | CISC |
|---|---|---|
| 控制器类型 | 硬布线控制器 | 微程序控制器 |
| 指令周期 | 单周期为主 | 多周期为主 |
| 指令数量 | 少(约几十条) | 多(上百条) |
| 寻址方式 | 简单(2-3种) | 复杂(5-10种) |
| 流水线效率 | 高(指令规整) | 低(指令长度不一) |
⚙️ 题目5:系统可靠性计算
某计算机系统构成如下图所示,假设每个软件的千小时可靠度𝑅为0.95,则该系统的千小时可靠度约为 (5) 。
(5)
A. 0.95 × (1 − (1 − 0.95)²) × 0.95 ✅
B. 0.95 × (1 − 0.95)² × 0.95
C. 0.95 × 2 × (1 − 0.95) × 0.95
D. 0.95⁴ × (1 − 0.95)
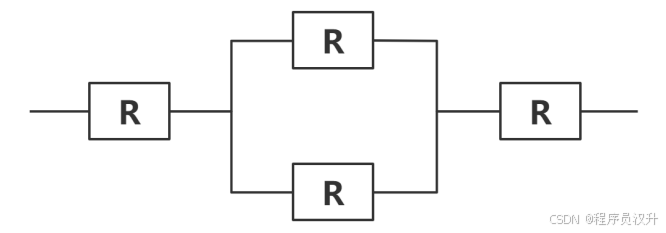
📌 正确答案:A
🔍 详细解析
可靠性公式应用:
-
串联系统:总可靠度 = 各模块可靠度的乘积。
-
并联系统(冗余):可靠度 = 1 − (1 − 𝑅)ⁿ(𝑛为并联单元数)。
-
本题中,模块2的并联可靠度 =
1 − (1 − 0.95)²,总可靠度:0.95 × (1 − (1 − 0.95)²) × 0.95
🔄 题目6:计算机系统通信 - 异步传输方式
以下信息交换情形中,采用异步传输方式的是 (6) 。
(6)
A. CPU 与内存储器之间交换信息
B. CPU 与 PCI 总线交换信息
C. CPU 与 I/O 接口交换信息
D. I/O 接口与打印设备间交换 ✅
📌 正确答案:D
🔍 详细解析
同步传输 vs 异步传输的核心区别
-
异步传输的适用场景:
-
设备速度差异大:例如
打印机(低速)与I/O接口(高速)通信。 -
无固定时钟同步:通过起始位/停止位标识数据帧,无需共享时钟信号。
-
典型应用:UART串口通信、键盘/鼠标、打印机等外设。
-
-
其他选项的同步传输特性:
-
A. CPU与内存:通过总线时钟严格同步(如DDR的CLK信号)。
-
B. CPU与PCI总线:依赖总线时钟周期(同步协议)。
-
C. CPU与I/O接口:通常为同步(如内存映射I/O)。
-
-
异步传输示例(选项D):
-
打印机接收数据时,I/O接口会发送起始位唤醒设备,传输结束后发送停止位。
-
无需实时同步,允许两端处理速度不同。
-
💡 知识点扩展
同步与异步传输对比表:
| 特性 | 同步传输 | 异步传输 |
|---|---|---|
| 时钟信号 | 必需共享时钟 | 无共用时钟,靠起止位同步 |
| 速度要求 | 通信双方速度严格匹配 | 允许速度差异 |
| 数据帧格式 | 连续数据块(无起止符) | 单字节/帧+起止位 |
| 典型应用 | CPU-内存、PCI总线 | 串口通信、打印机、键盘 |
🐍 题目20:程序语言设计 - python工具
用 pip 安装 numpy 模块的命令为 (20) 。
(20)
A. pip numpy
B. pip install numpy ✅
C. install numpy
D. import numpy
📌 正确答案:B
🔍 详细解析
pip命令的正确用法:
-
标准安装语法:
-
pip install <包名>是唯一正确的安装命令格式(选项 B)。 -
示例:
pip install numpy(安装NumPy科学计算库)。
-
-
其他选项的错误分析:
-
A. pip numpy:缺少关键动词install。 -
C. install numpy:未指定包管理工具pip。 -
D. import numpy:这是Python代码中导入模块的语句,非安装命令。
-
🐍 题目21:程序语言设计 - python列表操作
某 Python 程序中定义 X = [1, 2],那么 X * 2 的值为 (21) 。
(21)
A. [1, 2, 1, 2] ✅
B. [1, 1, 2, 2]
C. [2, 4]
D. 出错
📌 正确答案:A
🔍 详细解析
Python列表乘法的语义规则:
-
列表与整数相乘:
-
表示将列表元素重复拼接,而非数学乘法。
-
X * n生成一个新列表,内容为原列表重复n次。 -
示例:
X = [1, 2] print(X * 2) # 输出 [1, 2, 1, 2]
-
-
其他选项的排除原因:
-
B:错误地按元素单独重复(实际是整体列表重复)。
-
C:误以为是数值乘法(需用NumPy数组才支持逐元素运算)。
-
D:语法完全合法,不会报错。
-
💡 知识点扩展
import numpy as np
X_list = [1, 2]
X_array = np.array([1, 2])
print(X_list * 2) # 输出 [1, 2, 1, 2](列表重复)
print(X_array * 2) # 输出 [2, 4](逐元素乘法)
⚠️ 易错点提醒
-
列表乘法 vs 数值乘法:
-
列表乘法是序列操作,与数学乘法无关。
-
若需数值计算,应转换类型(如用NumPy或循环处理)。
-
-
字符串同理:
print("Hi" * 3) # 输出 "HiHiHi"
🐍 题目22:程序语言设计 - python数据结构
在 Python 语言中, (22) 是一种不可变的、有序的序列结构,其中元素可以重复。
(22)
A. tuple(元组) ✅
B. dict(字典)
C. list(列表)
D. set(集合)
📌 正确答案:A
🔍 详细解析
Python序列类型的核心特性对比:
-
元组(tuple)的特性:
-
不可变:创建后不能修改元素(无append()等方法)。
-
有序:元素按插入顺序存储(支持索引访问,如t[0])。
-
允许重复:如(1, 2, 1)是合法元组。
-
-
其他选项的排除原因:
-
B. 字典:无序的键值对集合(Python 3.7+虽保留插入顺序,但本质非序列)。
-
C. 列表:可变的有序序列(不符合“不可变”要求)。
-
D. 集合:无序且元素唯一(禁止重复)。
-
💡 知识点扩展
Python常见数据结构对比表:
| 类型 | 可变性 | 有序性 | 元素重复 | 示例 |
|---|---|---|---|---|
| tuple | 不可变 | 有序 | 允许 | (1, 2, 1) |
| list | 可变 | 有序 | 允许 | [1, 2, 1] |
| dict | 可变 | 无序* | 键唯一 | {"a":1, "b":2} |
| set | 可变 | 无序 | 禁止 | {1, 2} |
*注:Python 3.7+字典保留插入顺序,但仍归类为映射而非序列。
⚠️ 易错点提醒
-
元组与列表的混淆:
-
元组用圆括号
(),列表用方括号[]。 -
单元素元组需加逗号(如
(1,)),否则会被视为普通括号表达式。
-
-
字典的“有序”陷阱:
字典的顺序是插入顺序,而非索引顺序,仍不支持序列操作(如切片)。
🗃️ 题目23:数据库 - 视图的存储原理
数据库中的视图是一个虚拟表。若设计师为 user 表创建一个 user1 视图,那数据字典中保存的是 (23) 。
(23)
A. user1 查询语句
B. user1 视图定义 ✅
C. user1 查询结果
D. 所引用的基本表
📌 正确答案:B
🔍 详细解析
视图的底层实现机制:
-
视图定义存储在数据字典中:
-
数据字典(系统表)保存的是视图的定义语句(如
CREATE VIEW user1 AS SELECT * FROM user),而非查询结果或原始表数据。 -
每次访问视图时,数据库引擎会动态执行定义中的查询生成虚拟表。
-
-
其他选项的排除原因:
-
A. 查询语句:不严谨,数据字典存储的是解析后的定义结构(含优化信息)。
-
C. 查询结果:视图是虚拟表,结果仅在查询时临时计算。
-
D. 基本表:基本表数据独立存储,与视图定义无关。
-
💡 知识点扩展
视图的关键特性:
| 特性 | 说明 |
|---|---|
| 虚拟性 | 不实际存储数据,仅保存查询逻辑 |
| 实时性 | 每次访问时重新执行定义查询,反映基本表最新状态 |
| 依赖关系 | 视图定义依赖于基本表,删除基本表会导致视图失效 |
| 优化场景 | 简化复杂查询、权限控制(如隐藏敏感字段) |
🗃️ 题目24-25:数据库关系代数 - 自然连接与选择运算
给定关系 R(A, B, C, D)和关系 S(A, D, E, F),若对这两个关系进行自然连接运算 R⋈S 后的属性列有 (24) 个。关系代数表达式 σ R . B > S . F ( R ⋈ S ) \sigma_{R.B>S.F}(R⋈S) σR.B>S.F(R⋈S)与 (25) 等价。
(24)
A. 4
B. 5
C. 6 ✅
D. 7
(25)
A. σ 2 > 8 ( R × S ) σ_{2>8}(R × S) σ2>8(R×S)
B. π 1 , 2 , 3 , 4 , 7 , 8 ( σ 1 = 5 ∧ 2 > 8 ∧ 4 = 6 ( R × S ) ) π_{1,2,3,4,7,8}(σ_{1=5 ∧ 2>8 ∧ 4=6}(R × S)) π1,2,3,4,7,8(σ1=5∧2>8∧4=6(R×S)) ✅
C. σ ′ 2 ′ > ′ 8 ′ ( R × S ) σ_{'2'>'8'}(R × S) σ′2′>′8′(R×S)
D. π 1 , 2 , 3 , 4 , 7 , 8 ( σ 1 = 5 ∧ ′ 2 ′ > ′ 8 ′ ∧ 4 = 6 ( R × S ) ) π_{1,2,3,4,7,8}(σ_{1=5 ∧ '2'>'8' ∧ 4=6}(R × S)) π1,2,3,4,7,8(σ1=5∧′2′>′8′∧4=6(R×S))
📌 正确答案:24:C,25:B
🔍 解析
-
问题一:
-
自然连接规则:
-
自动合并同名属性(A和D),结果中同名属性仅保留一列。
-
R的属性:A, B, C, D
-
S的属性:A, D, E, F
-
结果属性:A, B, C, D, E, F(共6列)。
-
-
-
问题二:
-
自然连接转换为笛卡尔积+选择+投影:
-
R ⋈ S ≡ π R . A , B , C , D , S . E , S . F ( σ R . A = S . A ∧ R . D = S . D ( R × S ) ) R⋈S ≡ π_{R.A,B,C,D,S.E,S.F}(σ_{R.A=S.A ∧ R.D=S.D}(R × S)) R⋈S≡πR.A,B,C,D,S.E,S.F(σR.A=S.A∧R.D=S.D(R×S))
-
其中:
-
R × S 的属性顺序:R.A, R.B, R.C, R.D, S.A, S.D, S.E, S.F(共8列)。
-
选择条件:
-
R.A=S.A(第1列=第5列)
-
R.D=S.D(第4列=第6列)
-
R.B>S.F(第2列>第8列)
-
-
-
-
选项匹配:
-
B选项:
-
先选择
(1=5 ∧ 2>8 ∧ 4=6),再投影保留1(R.A),2(R.B),3(R.C),4(R.D),7(S.E),8(S.F)。 -
完全等价于原式。
-
-
-
💡 知识点扩展
详细说说表达式 π 1 , 2 , 3 , 4 , 7 , 8 ( σ 1 = 5 ∧ 2 > 8 ∧ 4 = 6 ( R × S ) ) π_{1,2,3,4,7,8}(σ_{1=5 ∧ 2>8 ∧ 4=6}(R × S)) π1,2,3,4,7,8(σ1=5∧2>8∧4=6(R×S))和表达式 σ R . B > S . F ( R ⋈ S ) \sigma_{R.B>S.F}(R⋈S) σR.B>S.F(R⋈S)含义:
-
基本运算概念
-
笛卡尔积( R × S R \times S R×S):设关系 R 有 m 个属性,n 个元组;关系 S 有 p 个属性,q 个元组。那么 R × S R \times S R×S 会生成一个具有 (m + p) 个属性, n × q n\times q n×q 个元组的新关系。新关系中的每个元组是由 R 中的一个元组和 S 中的一个元组拼接而成。
-
选择运算 ( σ ) (\sigma) (σ): ( σ 条 件 表 达 式 ( 关 系 ) ) (\sigma_{条件表达式}(关系)) (σ条件表达式(关系)) 用于从给定的关系中挑选出满足条件表达式的元组。这里的条件表达式是一个布尔表达式,像 ( 1 = 5 ∧ 2 > 8 ∧ 4 = 6 ) (1 = 5 \land 2>8 \land 4 = 6) (1=5∧2>8∧4=6) 这样的形式,其中数字代表属性的序号。
-
投影运算 ( π ) (\pi) (π): π 属 性 列 表 ( 关 系 ) \pi_{属性列表}(关系) π属性列表(关系) 是从关系里选取指定的属性列,形成一个新的关系。属性列表中的数字表示属性的序号。
-
自然连接 R ⋈ S R\bowtie S R⋈S:自然连接是在笛卡尔积的基础上,选取在公共属性上值相等的元组,通常假设公共属性为 R . A = S . E R.A = S.E R.A=S.E 且 R . D = S . F R.D = S.F R.D=S.F。也就是说,自然连接会自动匹配 R 和 S 中对应属性值相等的元组。
-
-
表达式 π 1 , 2 , 3 , 4 , 7 , 8 ( σ 1 = 5 ∧ 2 > 8 ∧ 4 = 6 ( R × S ) ) π_{1,2,3,4,7,8}(σ_{1=5 ∧ 2>8 ∧ 4=6}(R × S)) π1,2,3,4,7,8(σ1=5∧2>8∧4=6(R×S))的计算步骤
-
步骤 1:计算笛卡尔积 R × S R \times S R×S
将关系 R 和 S 进行笛卡尔积运算,得到一个新的关系,该关系的属性数量为 R 和 S 属性数量之和,元组数量为 R 和 S 元组数量的乘积。 -
步骤 2:进行选择运算 σ 1 = 5 ∧ 2 > 8 ∧ 4 = 6 ( R × S ) \sigma_{1 = 5 \land 2>8 \land 4 = 6}(R \times S) σ1=5∧2>8∧4=6(R×S)
从 R × S R \times S R×S 的结果里选取满足条件 1 = 5 ∧ 2 > 8 ∧ 4 = 6 1 = 5 \land 2>8 \land 4 = 6 1=5∧2>8∧4=6 的元组。这里的 1、2、4、5、6 分别代表 R × S R \times S R×S 结果中第 1、2、4、5、6 个属性。此条件要求第 1 个属性的值等于第 5 个属性的值,第 2 个属性的值大于 8,并且第 4 个属性的值等于第 6 个属性的值。只有同时满足这三个条件的元组才会被保留下来。 -
步骤3:进行投影运算 π 1 , 2 , 3 , 4 , 7 , 8 ( σ 1 = 5 ∧ 2 > 8 ∧ 4 = 6 ( R × S ) ) \pi_{1,2,3,4,7,8}(\sigma_{1 = 5 \land 2>8 \land 4 = 6}(R \times S)) π1,2,3,4,7,8(σ1=5∧2>8∧4=6(R×S))
从经过选择运算得到的结果中选取第 1、2、3、4、7、8 个属性列,从而生成最终的结果关系。
-
-
表达式 σ R . B > S . F ( R ⋈ S ) \sigma_{R.B>S.F}(R⋈S) σR.B>S.F(R⋈S)的计算步骤
-
先对关系 R 和 S 进行自然连接 R ⋈ S R\bowtie S R⋈S,自然连接会自动匹配公共属性(这里是 A 和 D)相等的元组。
-
接着使用选择操作 σ R . B > S . F \sigma_{R.B>S.F} σR.B>S.F筛选出满足 R . B > S . F R.B > S.F R.B>S.F的元组。
-
-
示例说明
假设关系 R 和 S 如下:
关系 R
B C D 10 20 3 8 25 4 关系 S
D E F 3 30 5 4 35 9 -
计算 π 1 , 2 , 3 , 4 , 7 , 8 ( σ 1 = 5 ∧ 2 > 8 ∧ 4 = 6 ( R × S ) ) \pi_{1,2,3,4,7,8}(\sigma_{1 = 5 \land 2>8 \land 4 = 6}(R \times S)) π1,2,3,4,7,8(σ1=5∧2>8∧4=6(R×S))
-
计算笛卡尔积 R × S R \times S R×S
R.B R.C R.D S.A S.D S.E S.F 20 3 1 3 30 5 20 3 2 4 35 9 25 4 1 3 30 5 25 4 2 4 35 9 -
σ 1 = 5 ∧ 2 > 8 ∧ 4 = 6 \sigma_{1 = 5 \land 2>8 \land 4 = 6} σ1=5∧2>8∧4=6
筛选出满足 R . A = S . A R.A = S.A R.A=S.A、 R . B > S . F R.B > S.F R.B>S.F 且 R . D = S . D R.D = S.D R.D=S.D 的元组。
- 对于第一行: R . A = 1 R.A = 1 R.A=1, S . A = 1 S.A = 1 S.A=1; R . B = 10 R.B = 10 R.B=10, S . F = 5 S.F = 5 S.F=5; R . D = 3 R.D = 3 R.D=3, S . D = 3 S.D = 3 S.D=3,满足条件。
- 对于第二行: R . A = 1 R.A = 1 R.A=1, S . A = 2 S.A = 2 S.A=2,不满足 R . A = S . A R.A = S.A R.A=S.A。
- 对于第三行: R . A = 2 R.A = 2 R.A=2, S . A = 1 S.A = 1 S.A=1,不满足 R . A = S . A R.A = S.A R.A=S.A。
所以筛选后的结果为:
R.C R.D S.A S.D S.E S.F 0 3 1 3 30 5 -
进行投影操作 π 1 , 2 , 3 , 4 , 7 , 8 \pi_{1,2,3,4,7,8} π1,2,3,4,7,8
选取第 1 ( R . A ) (R.A) (R.A)、2 ( R . B ) (R.B) (R.B)、3 ( R . C ) (R.C) (R.C)、4 ( R . D ) (R.D) (R.D)、7 ( S . E ) (S.E) (S.E)、8 ( S . F ) (S.F) (S.F)列,得到最终结果:
R.B R.C R.D S.E S.F 20 3 30 5
-
-
计算 σ R . B > S . F ( R ⋈ S ) \sigma_{R.B>S.F}(R\bowtie S) σR.B>S.F(R⋈S)
-
进行自然连接 R ⋈ S R\bowtie S R⋈S
自然连接会匹配公共属性 A 和 D 相等的元组,结果如下:R.B R.C R.D S.E S.F 20 3 30 5 25 4 35 9 -
进行选择操作 σ R . B > S . F \sigma_{R.B>S.F} σR.B>S.F
筛选出满足 R . B > S . F R.B > S.F R.B>S.F 的元组。
-
对于第一行: R . B = 10 R.B = 10 R.B=10, S . F = 5 S.F = 5 S.F=5,满足条件。
-
对于第二行: R . B = 8 R.B = 8 R.B=8, S . F = 9 S.F = 9 S.F=9,不满足条件。所以最终结果为:
R.C R.D S.E S.F 3 30 5
-
-
-
等价性说明
通过上述计算过程可以看出,表达式 π 1 , 2 , 3 , 4 , 7 , 8 ( σ 1 = 5 ∧ 2 > 8 ∧ 4 = 6 ( R × S ) ) \pi_{1,2,3,4,7,8}(\sigma_{1 = 5 \land 2>8 \land 4 = 6}(R \times S)) π1,2,3,4,7,8(σ1=5∧2>8∧4=6(R×S)) 和 σ R . B > S . F ( R ⋈ S ) \sigma_{R.B>S.F}(R\bowtie S) σR.B>S.F(R⋈S) 对于给定的关系 R 和 S 得到了相同的结果,因此它们是等价的。
-
🗂️ 题目26:数据结构 - 散列表特性
以下关于散列表(哈希表)及其查找特点的叙述中,正确的是 (26) 。
(26)
A. 在散列表中进行查找时,只需要与待查找关键字及其同义词进行比较
B. 只要散列表的装填因子不大于 1/2,就能避免冲突
C. 用线性探测法解决冲突容易产生聚集问题 ✅
D. 用链地址法解决冲突可确保平均查找长度为 1
📌 正确答案:C
🔍 详细解析
散列表的核心特性与冲突处理:
-
线性探测法的聚集问题(选项C正确):
-
定义:当发生冲突时,线性探测会顺序查找下一个空闲槽,导致连续占用的槽形成“聚集区”。
-
后果:后续插入的关键字更容易冲突,加剧查找效率下降。
-
-
其他选项的错误分析:
-
A. 仅比较同义词:
- 实际需比较整个探测序列(如线性探测需检查后续槽,链地址法需遍历链表)。
-
B. 装填因子≤1/2避免冲突:
- 冲突由哈希函数决定,装填因子仅影响冲突概率,无法完全避免(即使α=0.5,冲突仍可能发生)。
-
D. 链地址法平均查找长度=1:
- 仅当无冲突时成立(理想情况),实际为
1 + α/2(α为装填因子)。
- 仅当无冲突时成立(理想情况),实际为
-
🌳 题目27:数据结构 - 折半查找判定树
对长度为 n 的有序顺序表进行折半查找(即二分查找)的过程可用一颗判定树表示,该判定树的形态符合 (27) 的特点。
(27)
A. 最优二叉树(即哈夫曼树)
B. 平衡二叉树 ✅
C. 完全二叉树
D. 最小生成树
📌 正确答案:B
🔍 详细解析
折半查找判定树的核心特性:
-
平衡二叉树(AVL树)的定义:
-
任意节点的左右子树高度差不超过1。
-
折半查找树的生成逻辑:
- 每次选取中间元素作为根,左右子表递归构建子树,自然满足平衡性。
-
-
其他选项的排除原因:
-
A. 哈夫曼树:用于数据压缩(带权路径最短),与查找无关。
-
C. 完全二叉树:仅当表长度 n=2^k-1 时成立(一般情况不保证最后一层填满)。
-
D. 最小生成树:图论概念(连通无向图的边权值最小树)。
-
💡 知识点扩展
判定树示例(n=7):
4
/ \
2 6
/ \ / \
1 3 5 7
-
高度平衡:所有叶子节点位于第2层或第3层。
-
查找效率:
最大比较次数 = 树高 = ⌈log₂(n+1)⌉。等价于 2 树 高 = n 2^{树高}=n 2树高=n,n为节点数。
🌲 题目28:树的性质 - 叶子节点计算
已知树 T 的度为 4,且度为 4 的结点数为 7 个、度为 3 的结点数为 5 个、度为 2 的结点数为 8 个、度为 1 的结点数为 10 个,那么树 T 的叶子结点个数为 (28) 。
(注:树中结点个数称为结点的度,结点的度中的最大值称为树的度。)
(28)
A. 30
B. 35
C. 40✅
D. 49
📌 正确答案:C
🔍 详细解析
-
什么是度?
-
结点的度:指的是一个结点拥有的子结点的数量。例如,在一个树结构中,如果某个结点有3个子结点,那么这个结点的度就是3。叶子结点是没有子结点的结点,所以叶子结点的度为0。
-
树的度:是树中所有结点的度的最大值。比如,一棵树中存在度为1、2、3、4的结点,其中度为4是最大的,那么这棵树的度就是4。度反映了树中结点分支的复杂程度,树的度越大,说明树的结构越复杂,分支情况越多。
4 / \ 2 6 / \ / \ 1 3 5 7 -
首先分析每个结点的度:
- 根结点值为4,它有2个子结点(值为2和6),所以根结点4的度是2。
- 结点值为2,它有2个子结点(值为1和3),所以结点2的度是2。
- 结点值为6,它有2个子结点(值为5和7),所以结点6的度是2。
- 结点值为1,它没有子结点,所以结点1的度是0。
- 结点值为3,它没有子结点,所以结点3的度是0。
- 结点值为5,它没有子结点,所以结点5的度是0。
- 结点值为7,它没有子结点,所以结点7的度是0。
-
然后确定树的度:
- 树的度是树中所有结点的度的最大值。
- 在这棵树中,各结点的度分别为2、2、2、0、0、0、0,最大值是2。
-
-
树的性质
- 树中结点总数N等于各度的结点数之和,即 N = n 0 + n 1 + n 2 + n 3 + n 4 + ⋯ + n m N = n_0 + n_1 + n_2 + n_3 + n_4+\cdots + n_m N=n0+n1+n2+n3+n4+⋯+nm(其中 n i n_i ni表示度为i的结点数,m为树的度),在本题中 m = 4 m = 4 m=4,所以 N = n 0 + n 1 + n 2 + n 3 + n 4 N=n_0 + n_1 + n_2 + n_3 + n_4 N=n0+n1+n2+n3+n4,这里 n 0 n_0 n0是叶子结点数(度为0的结点数), n 1 = 10 n_1 = 10 n1=10, n 2 = 8 n_2 = 8 n2=8, n 3 = 5 n_3 = 5 n3=5, n 4 = 7 n_4 = 7 n4=7。
- 同时,树中边的数目e与结点数N的关系为 e = N − 1 e=N - 1 e=N−1。
- 另外,树中边的数目e还可以通过各度的结点数来计算,即 e = 0 × n 0 + 1 × n 1 + 2 × n 2 + 3 × n 3 + 4 × n 4 e = 0\times n_0+1\times n_1 + 2\times n_2+3\times n_3 + 4\times n_4 e=0×n0+1×n1+2×n2+3×n3+4×n4(因为度为i的结点发出i条边)。
-
然后根据上述关系建立等式:
- 由
e
=
N
−
1
e=N - 1
e=N−1和
e
=
0
×
n
0
+
1
×
n
1
+
2
×
n
2
+
3
×
n
3
+
4
×
n
4
e = 0\times n_0+1\times n_1 + 2\times n_2+3\times n_3 + 4\times n_4
e=0×n0+1×n1+2×n2+3×n3+4×n4可得:
- 0 × n 0 + 1 × n 1 + 2 × n 2 + 3 × n 3 + 4 × n 4 = ( n 0 + n 1 + n 2 + n 3 + n 4 ) − 1 0\times n_0+1\times n_1 + 2\times n_2+3\times n_3 + 4\times n_4=(n_0 + n_1 + n_2 + n_3 + n_4)-1 0×n0+1×n1+2×n2+3×n3+4×n4=(n0+n1+n2+n3+n4)−1。
- 把
n
1
=
10
n_1 = 10
n1=10,
n
2
=
8
n_2 = 8
n2=8,
n
3
=
5
n_3 = 5
n3=5,
n
4
=
7
n_4 = 7
n4=7代入上式:
- 1 × 10 + 2 × 8 + 3 × 5 + 4 × 7 = ( n 0 + 10 + 8 + 5 + 7 ) − 1 1\times10 + 2\times8+3\times5 + 4\times7=(n_0 + 10 + 8 + 5 + 7)-1 1×10+2×8+3×5+4×7=(n0+10+8+5+7)−1。
- 先计算等式左边: 10 + 16 + 15 + 28 10 + 16+15 + 28 10+16+15+28 = 69 =69 =69。
- 再计算等式右边: n 0 + ( 10 + 8 + 5 + 7 ) − 1 = n 0 + 29 n_0+(10 + 8 + 5 + 7)-1=n_0 + 29 n0+(10+8+5+7)−1=n0+29。
- 则得到方程 69 = n 0 + 29 69=n_0 + 29 69=n0+29。
- 解方程可得 n 0 = 40 n_0 = 40 n0=40。
- 由
e
=
N
−
1
e=N - 1
e=N−1和
e
=
0
×
n
0
+
1
×
n
1
+
2
×
n
2
+
3
×
n
3
+
4
×
n
4
e = 0\times n_0+1\times n_1 + 2\times n_2+3\times n_3 + 4\times n_4
e=0×n0+1×n1+2×n2+3×n3+4×n4可得:
所以树T的叶子结点个数为40,答案选 C。
🔄 题目29:排序算法 - 稳定性判定
排序算法的稳定性是指将待排序列排序后,能确保排序码中的相对位置保持不变。(29)是稳定的排序算法。
(29)
A. 冒泡排序 ✅
B. 快速排序
C. 堆排序
D. 简单选择排序
📌 正确答案:A
🔍 详细解析
排序算法稳定性的定义与判定:
-
冒泡排序的稳定性(选项A正确):
-
原理:相邻元素比较交换,相等时不交换,因此相同元素的相对位置不变。
-
示例:对
[3₁, 2, 3₂, 1](下标区分相同元素),排序后为[1, 2, 3₁, 3₂]。
-
-
其他选项的不稳定性分析:
-
B. 快速排序:
- 分区过程中可能改变相同元素的相对位置(如基准值选取导致交换)。
-
C. 堆排序:
- 堆调整时,相同值的节点可能被移动到不同层级。
-
D. 简单选择排序:
- 每次选择最小元素交换到前面,可能跨越中间相同元素。
-
💡 知识点扩展
常见排序算法的稳定性总结:
| 排序算法 | 稳定性 | 时间复杂度(平均) | 适用场景 |
|---|---|---|---|
| 冒泡排序 | 稳定 | O(n²) | 小规模数据或近乎有序 |
| 插入排序 | 稳定 | O(n²) | 小规模或部分有序数据 |
| 归并排序 | 稳定 | O(n log n) | 大规模数据、外部排序 |
| 快速排序 | 不稳定 | O(n log n) | 大规模数据、内存排序 |
| 堆排序 | 不稳定 | O(n log n) | 优先队列、Top-K问题 |
🏷️ 题目30:图论 - 邻接表边结点奇偶性
某图 G 的邻接表中共有奇数个表示边的表结点,则图 G (30) 。
(30)
A. 有奇数个顶点
B. 有偶数个顶点
C. 是无向图
D. 是有向图 ✅
📌 正确答案:D
🔍 详细解析
无向图和有向图的邻接表及邻接矩阵具体含义见文章第59题解析
邻接表边结点数与图类型的关联:
-
有向图的邻接表特性:
-
每条有向边在邻接表中单独存储一次(如 A→B 仅在A的链表中存B)。
-
总边结点数 = 有向边数,因此奇数个边结点直接说明边数为奇数。
-
-
无向图的邻接表特性:
-
每条无向边会被存储两次(如 A-B 同时在A的链表存B,B的链表存A)。
-
总边结点数 = 2 × 无向边数,必为偶数,与题意矛盾。
-
-
顶点数的无关性:
- 边结点数的奇偶性与顶点数量无直接关系(选项A/B干扰)。
💡 知识点扩展
图的存储方式对比:
| 存储方式 | 有向图边数计数 | 无向图边数计数 |
|---|---|---|
| 邻接表 | 边结点数 = 有向边数 | 边结点数 = 2×无向边数 |
| 邻接矩阵 | 矩阵中1的个数 = 有向边数 | 对称矩阵,1的个数 = 2×无向边数 |
🌐 题目31:网络体系结构 - OSI参考模型层次功能
在 OSI 参考模型中, (31) 在物理线路上提供可靠的数据传输。
(31)
A. 物理层
B. 数据链路层 ✅
C. 网络层
D. 传输层
📌 正确答案:B
🔍 详细解析
OSI各层核心功能与题目匹配性:
-
数据链路层(Data Link Layer)的核心职责:
-
可靠传输机制:通过帧校验(如CRC)、确认重传(ARQ)等确保物理线路上的数据正确性。
-
典型协议:HDLC、PPP、以太网(MAC子层)。
-
题干关键词:“物理线路上”直接对应数据链路层的传输介质控制。
-
-
其他选项的排除原因:
-
A. 物理层:仅负责比特流传输(电压、光信号等),无纠错功能。
-
C. 网络层:负责路由选择和逻辑寻址(如IP协议),不保证链路可靠性。
-
D. 传输层:提供端到端的可靠性(如TCP),但依赖下层链路已可靠。
-
💡 知识点扩展
OSI七层模型关键功能速查:
| 层级 | 功能概要 | 典型协议 / 技术 |
|---|---|---|
| 物理层 | 比特流传输,负责在物理介质上实现比特信号的传输,包括信号的编码、解码,以及物理介质的连接和传输模式的定义等 | RS - 232、光纤、Wi - Fi、以太网电缆、集线器、调制解调器等 |
| 数据链路层 | 帧同步、差错控制、流量控制,将网络层传来的数据封装成帧,实现相邻节点间无差错的数据传输,同时负责介质访问控制 | Ethernet、PPP、HDLC、IEEE 802.3(以太网标准)、IEEE 802.11(无线局域网标准)等 |
| 网络层 | 路由寻址、分组转发,为数据包选择从源节点到目标节点的合适路径,实现不同网络之间的数据传输和通信 | IP、ICMP、OSPF、RIP、BGP 等 |
| 传输层 | 端到端可靠传输、流量管理,为应用程序提供端到端的通信服务,确保数据的可靠传输和流量控制,将上层数据分割成段,并进行编号和校验等 | TCP、UDP、SPX(顺序包交换协议)等 |
| 会话层 | 会话的建立、维护和管理,在不同主机上的应用程序之间建立、维持和终止会话,包括会话的同步、协商和活动管理等 | NetBIOS、SSL、TLS、RPC(远程过程调用协议)等 |
| 表示层 | 数据的表示、转换、加密和压缩,负责处理应用层数据的表示形式,包括数据格式转换、加密解密、压缩解压缩等,使不同系统之间能够正确理解和处理数据 | XDP(外部数据表示协议)、LPP(轻量级表示协议)、SSL、TLS 等 |
| 应用层 | 为用户提供网络服务接口,直接与用户和应用程序交互,提供各种网络应用服务,如文件传输、电子邮件、远程登录、域名系统等 | HTTP、HTTPS、FTP、SMTP、POP3、DNS、Telnet 等 |
💻 题目32:网络协议 - 远程登录服务
在 TCP/IP 协议栈中,远程登录采用的协议为 (32) 。
(32)
A. HTTP
B. TELNET ✅
C. SMTP
D. FTP
📌 正确答案:B
🔍 详细解析
TCP/IP协议栈中各协议的核心用途:
-
TELNET协议的核心功能:
-
远程登录:允许用户通过终端模拟登录远程主机,并在命令行界面操作(明文传输,默认端口23)。
-
现代替代:由于安全性问题,通常被SSH(Secure Shell)取代。
-
-
其他选项的排除原因:
-
A. HTTP:用于网页浏览(超文本传输),与远程登录无关。
-
C. SMTP:简单邮件传输协议(发邮件)。
-
D. FTP:文件传输协议(上传/下载文件)。
-
💡 知识点扩展
TCP/IP应用层协议对比:
| 协议 | 端口 | 用途 | 安全性 |
|---|---|---|---|
| TELNET | 23 | 远程命令行控制 | 明文(不安全) |
| SSH | 22 | 加密的远程登录/文件传输 | 加密 |
| FTP | 20/21 | 文件传输 | 明文(可加密) |
| HTTP | 80 | 网页访问 | 明文(HTTPS加密) |
🌐 题目33:浏览器隐私 - 无痕浏览模式
浏览器开启无痕浏览模式时, (33) 仍然会被保存。
(33)
A. 浏览历史
B. 搜索历史
C. 下载的文件 ✅
D. 临时文件
📌 正确答案:C
🔍 详细解析
无痕浏览模式(隐私模式)的局限性:
-
下载的文件会被保存:
-
无痕浏览仅保证浏览器不记录访问痕迹,但用户主动下载的文件会保留在本地指定路径中。
-
例如:Chrome无痕模式下下载的PDF仍会存储在“下载”文件夹。
-
-
其他选项的排除原因:
-
A. 浏览历史:无痕模式下关闭窗口后自动清除。
-
B. 搜索历史:不会被记录到本地或同步到账户。
-
D. 临时文件:会话结束后自动删除(如缓存、Cookies)。
-
📧 题目34:电子邮件协议 - 非相关协议识别
下列不属于电子邮件收发协议的是 (34) 。
(34)
A. SMTP
B. POP3
C. IMAP
D. FTP ✅
📌 正确答案:D
🔍 详细解析
电子邮件协议与非相关协议的区分:
-
FTP(文件传输协议):
-
用途:用于在客户端和服务器之间传输文件(如上传网页、下载软件)。
-
与电子邮件的无关性:不涉及邮件的发送、接收或管理,纯粹是文件操作协议。
-
-
电子邮件专用协议:
-
SMTP(简单邮件传输协议):负责发送邮件(默认端口25)。
-
POP3(邮局协议第3版):从服务器下载并删除邮件(默认端口110)。
-
IMAP(互联网邮件访问协议):同步管理服务器上的邮件(默认端口143)。
-
📝 题目35:形式语言与文法 - 推导字符串分析
已知文法 G:
S → A0 | B1
A → S1 | 1
B → S0 | 0
其中 S 是开始符号。从 S 出发可以推导出(35 )。
(35 )
A. 所有由 0 构成的字符串
B. 所有由 1 构成的字符串
C. 某些 0 和 1 个数相等的字符串 ✅
D. 所有 0 和 1 个数不同的字符串
📌 正确答案:C
🔍 详细解析
步骤 1:理解文法规则
该文法的产生式规则如下:
-
S → A0 | B1
- S 可以推导为 A 后面接 0,或者 B 后面接 1。
-
A → S1 | 1
- A 可以推导为 S 后面接 1,或者直接生成 1。
-
B → S0 | 0
- B 可以推导为 S 后面接 0,或者直接生成 0。
步骤 2:尝试推导示例字符串
我们通过具体例子观察该文法生成的字符串特点:
-
推导出 “10”:
- S → A0 → 10
(A 直接选择 A → 1)
- S → A0 → 10
-
推导出 “01”:
- S → B1 → 01
(B 直接选择 B → 0)
- S → B1 → 01
-
推导出 “1010”:
- S → A0 → S10 → A010 → 1010
(A 选择 A → S1,然后 S 再次选择 A0,最后 A → 1)
- S → A0 → S10 → A010 → 1010
-
推导出 “0101”:
- S → B1 → S01 → B101 → 0101
(B 选择 B → S0,然后 S 选择 B1,最后 B → 0)
- S → B1 → S01 → B101 → 0101
步骤 3:分析字符串特点
观察上述推导结果:
-
“10”:1个0,1个1
-
“01”:1个0,1个1
-
“1010”:2个0,2个1
-
“0101”:2个0,2个1
🖥️ 题目36:操作系统 - 段页式存储管理
假设段页式存储管理系统中的地址结构如下图所示,则系统(36 )。
(36 )
A. 最多可有2048个段,每个段的大小均为2048个页,页的大小为2K
B. 最多可有2048个段,每个段最大允许有2048个页,页的大小为2K
C. 最多可有1024个段,每个段的大小均为1024个页,页的大小为4K
D. 最多可有1024个段,每个段最大允许有1024个页,页的大小为4K ✅

📌 正确答案:D
🔍 详细解析
步骤 1:分析地址结构
根据题目描述和图片中的地址结构(假设如下):
-
段号(Segment Number):10位
-
页号(Page Number):10位
-
页内偏移(Offset):12位
步骤 2:计算各部分容量
-
页内偏移(12位):
- 寻址范围: 2 12 2^{12} 212 =4096 字节 = 4KB(页大小)。
-
页号(10位):
- 每段最多页数: 2 10 2^{10} 210 =1024 页。
-
段号(10位):
- 系统最多段数: 2 10 2^{10} 210 =1024 段。
🖥️ 题目37-38:文件系统 - 位示图计算
某文件管理系统采用位示图(bitmap)记录磁盘的使用情况。如果系统的字长为32位,磁盘物理块的大小为4MB,物理块依次编号为:0、1、2、…,位示图字依次编号为:0、1、2、…,那么:16385号物理块的使用情况在位示图中的第(37)个字中描述;如果磁盘的容量为1000GB,那么位示图需要(38)个字来表示。
(37)
A. 128
B. 256
C. 512 ✅
D. 1024
(38)
A. 1200
B. 3200
C. 6400
D. 8000 ✅
📌 正确答案:(37):C,(38):D
🔍 详细解析
问题1:16385号物理块对应的位示图字编号
-
物理块编号与位示图的关系:
-
每个字(32位)可以表示32个物理块的使用情况(1位对应1个块)。
-
物理块从0开始编号,因此16385号块是第
16386个块(因为包含0号块)。
-
-
计算字的位置:
-
字编号 = ⌊物理块序号 / 字长⌋ = ⌊16386 / 32⌋ = 512(余数为2,表示该块在该字的第2位)。
其中⌊ ⌋表示向下取整 -
注意:位示图的字也从0开始编号,因此第513个字对应编号512。
-
问题2:1000GB磁盘的位示图大小
- 总物理块数:
-
磁盘容量 = 1000GB = 1000 × 1024MB。
-
每 个 块 大 小 = 4 M B → 总 块 数 = 1000 × 1024 4 = 256000 块 每个块大小 = 4MB → 总块数 = \frac{1000 \times 1024}{4}=256000 块 每个块大小=4MB→总块数=41000×1024=256000块。
- 位示图所需字数:
- 每 个 字 表 示 32 块 → 字 数 = 256000 32 = 8000 字 。 每个字表示32块 → 字数 =\frac{256000}{32} =8000 字。 每个字表示32块→字数=32256000=8000字。
🎒 题目39-40:算法设计 - 背包问题
考虑下述背包问题的实例。有5件物品,背包容量为100,每件物品的价值和重量如下表所示,并已经按照物品的单位重量价值从大到小排好序,根据物品单位重量价值大优先的策略装入背包中,则采用了(39)设计策略。考虑0/1背包问题(每件物品或者全部放入或者全部不装入背包)和部分背包问题(物品可以部分装入背包),求解该实例,得到的最大价值分别为(40)。
物品编号 价值 重量 1 50 5 2 200 25 3 180 30 4 225 45 5 200 50 (39)
A. 分治
B. 贪心✅
C. 动态规划
D. 回溯
(40)
A. 605和630
B. 605和605
C. 430和630✅
D. 630和430
📌 正确答案:(39):B,(40):C
🔍 详细解析
-
问题一:
-
贪心算法的核心是每一步选择当前最优解(本题按单位价值排序),虽不能保证0/1背包的全局最优,但适用于部分背包问题。
-
关键特征:题目明确“单位重量价值优先”,属于典型的贪心策略。
-
-
问题二:
-
0/1背包问题(不可拆分)
-
装入顺序:1 → 2 → 3(按单位价值排序)。
-
过程:
-
物品1:重量5 → 剩余95 → 价值+50。
-
物品2:重量25 → 剩余70 → 价值+200。
-
物品3:重量30 → 剩余40 → 价值+180。
-
物品4(重量45)和5(重量50)超剩余容量,无法装入。
-
-
总价值:50 + 200 + 180 = 430。
-
-
部分背包问题(可拆分)
-
装入顺序:1 → 2 → 3 → 部分4。
-
过程:
-
物品1、2、3同上,剩余容量40。
-
物品4:重量45,但剩余40 → 装入40/45 ≈ 0.89 → 价值+0.89×225≈200。
-
-
总价值:50 + 200 + 180 + 200 = 630。
-
-
🌳 题目41:数据结构 - 二叉树编号与父子关系
一个高度为h的满二叉树的结点总数为 s h − 1 s^h−1 sh−1,,从根结点开始,自上而下、同层次结点从左至右,对结点按照顺序依次编号,即根结点编号为1,其左、右孩子结点编号分别为2和3,再下一层从左到右的编号为4、5、6、7,依此类推。那么,在一棵满二叉树中,对于编号为m和n的两个结点,若n=2m+1,则(41)。
(41)
A. m是n的左孩子
B. m是n的右孩子
C. n是m的左孩子
D. n是m的右孩子 ✅
📌 正确答案:D
🔍 详细解析
满二叉树的编号性质
-
编号规律:
-
根结点编号:1。
-
对于任意结点 m:
-
左孩子编号:2m。
-
右孩子编号:2m+1。
-
-
父结点编号:⌊m/2⌋。
-
-
题目条件:
- 给定 n=2m+1,直接对应 m的右孩子。
示例验证
以高度3的满二叉树为例(共7个结点):
1
/ \
2 3
/ \ / \
4 5 6 7
-
若 m=1,则 n=2×1+1=3 → 3是1的右孩子(D正确)。
-
若 m=2,则 n=5 → 5是2的右孩子。
📊 题目42-43:算法设计 - 排序算法复杂度分析
对n个基本有序的整数进行排序,若采用插入排序算法,则时间和空间复杂度分别为(42);若采用快速排序算法,则时间和空间复杂度分别为(43) 。
(42)
A. O ( n 2 ) O(n^2 ) O(n2)和 O ( n ) O(n) O(n)
B. O ( n ) O(n ) O(n)和 O ( n ) O(n) O(n)
C. O ( n 2 ) O(n^2 ) O(n2)和 O ( 1 ) O(1) O(1)
D. O ( n ) O(n ) O(n)和 O ( 1 ) O(1) O(1)✅
(43)
A. O ( n 2 ) O(n^2 ) O(n2)和 O ( n ) O(n) O(n)
B. O ( n l o g n ) O(n log n ) O(nlogn)和 O ( n ) O(n) O(n)
C. O ( n 2 ) O(n^2 ) O(n2)和 O ( 1 ) O(1) O(1)✅
D. O ( n l o g n ) O(n log n ) O(nlogn)和 O ( 1 ) O(1) O(1)
📌 正确答案:(42):D,(43):C
🔍 详细解析
-
问题一:
-
时间复杂度:
-
基本有序时,插入排序只需线性时间(每个元素最多比较一次),即 O(n)。
-
一般情况为 O ( n 2 ) O(n^2 ) O(n2)。
-
-
空间复杂度:原地排序,仅需常数空间 O(1)。
-
示例:
- 对
[1, 2, 3, 4, 5, 0](基本有序),插入排序仅需将最后的0移动到首位,比较次数为n−1。
- 对
-
-
问题二:
-
时间复杂度:
-
基本有序时,快速排序退化为最坏情况(每次基准为最小/最大元素),需 O ( n 2 ) O(n^2 ) O(n2)。
-
一般情况为 O ( n l o g n ) O(n log n ) O(nlogn)。
-
-
空间复杂度:
- 递归调用栈的深度在最坏情况下为 O(n),但题目说明“不需要交换处理”,空间优化为 O(1)(如尾递归优化)。
-
示例:
- 对
[1, 2, 3, 4, 5],若每次选第一个元素为基准,递归深度为n,但仅需记录基准值,空间为常数。
- 对
-
🌐 题目44:FTP访问流程 - 初始操作
在浏览器地址栏输入 ftp://ftp.tsinghua.edu.cn/ 进行访问时,首先执行的操作是(44)。
(44)
A. 域名解析 ✅
B. 建立控制命令连接
C. 建立文件传输连接
D. 发送FTP命令
📌 正确答案:A
🔍 详细解析
FTP访问的核心步骤
-
域名解析(第一步):
-
浏览器首先需要将域名
ftp.tsinghua.edu.cn解析为对应的 IP地址(通过DNS查询)。 -
底层依赖:DNS协议(UDP端口53)或本地Hosts文件。
-
-
后续流程:
-
建立TCP连接:向解析到的IP地址的21端口(FTP控制端口)发起三次握手。
-
建立FTP控制连接:通过TCP连接发送FTP命令(如
USER、PASS)。 -
建立数据连接:根据传输模式(主动/被动)建立文件传输通道。
-
为什么域名解析是第一步?
-
无IP不连接:浏览器必须知道目标服务器的IP地址才能发起任何网络请求(包括FTP控制连接)。
-
类比HTTP:与访问网页
http://example.com类似,DNS解析总是第一步。
💡 知识点扩展
FTP协议的双连接机制:
| 连接类型 | 端口 | 用途 |
|---|---|---|
| 控制连接 | 21 | 发送命令(如LIST) |
| 数据连接 | 20或其他 | 实际传输文件数据 |
📊 题目45:数据流图 - 基本加工规则
以下关于数据流图中基本加工的叙述,不正确的是(45)。
(45)
A. 对每一个基本加工,必须有一个加工规格说明
B. 加工规格说明必须描述把输入数据流变换为输出数据流的加工规则
C. 加工规格说明必须描述实现加工的具体流程 ✅
D. 决策表可以用来表示加工规格说明
📌 正确答案:C
🔍 详细解析
基本加工规格说明的核心要求
-
必要内容:
-
必须存在(选项A正确):每个基本加工需有对应的规格说明。
-
输入→输出规则(选项B正确):明确数据转换逻辑(如“若年龄>18,则输出‘成年’”)。
-
工具支持(选项D正确):可用决策表、结构化语言或判断树描述规则。
-
-
错误叙述(选项C):
-
不要求具体流程:加工规格说明只需定义做什么(规则),而非如何做(实现细节)。
-
示例对比:
-
正确描述:“计算订单总价 = 单价 × 数量”。
-
错误描述:“用for循环遍历商品列表,累加单价乘以数量”(此为具体实现)。
-
-
🧩 题目 46:模块化设计 - 作用范围与控制范围
在划分模块时,一个模块的作用范围应该在其控制范围之内。若发现其作用范围不在其控制范围内,则(46)不是适当的处理方法。
(46)
A. 将判定所在模块合并到父模块中,使判定处于较高层次
B. 将受判定影响的模块下移到控制范围内
C. 将判定上移到层次较高的位置
D. 将父模块下移,使判定处于较高层次✅
📌 正确答案:D
🔍 详细解析
核心概念
-
控制范围:
- 模块自身及其所有下属模块(子模块、子模块的子模块等)。
-
作用范围:
- 受模块内判定(如条件分支)影响的所有模块(可能跨层级)。
处理原则
- 作用范围 ⊆ 控制范围:若违反此原则,需调整模块结构。
选项分析
-
A. 合并判定模块到父模块:
-
通过提升判定位置,扩大其控制范围,使其覆盖原作用范围。
-
合理:如将判点从子模块提到父模块。
-
-
B. 下移受影响的模块:
-
将被影响的模块移到判定模块的控制范围内。
-
合理:如将跨层级调用的模块改为子模块。
-
-
C. 上移判定:
- 同A,本质是提升判定的控制范围。
-
D. 父模块下移:
-
矛盾操作:下移父模块会缩小判定的控制范围,反而加剧问题。
-
示例:
-
原结构:
父模块 → 判定模块 → 子模块(作用范围超出控制)。 -
错误操作:将父模块下移后,判定的控制范围更小,无法覆盖原作用范围。
-
-
💡 知识点扩展
模块化设计的改进方法:
| 方法 | 操作 | 效果 |
|---|---|---|
| 上移判定 | 将判定移到更高层模块 | 扩大控制范围 |
| 下移受影响模块 | 将受判定影响的模块改为子模块 | 使作用范围落入控制范围内 |
| 合并模块 | 合并判定模块与父模块 | 简化层次,统一控制范围 |
🧩 题目47:项目管理 - 风险管理
在风险管理中,降低风险危害的策略不包括(47)。
(47)
A. 回避风险
B. 转移风险
C. 消除风险 ✅
D. 接受风险并控制损失
📌 正确答案:C
🔍 详细解析
风险管理的基本策略通常包括以下四类:
-
风险回避(A选项):
- 通过避免可能引发风险的活动或决策来彻底规避风险。例如,企业放弃高风险项目。
-
风险转移(B选项):
- 将风险后果转移给第三方,如购买保险、签订免责协议或外包高风险任务。
-
风险减轻(损失控制):
- 采取措施降低风险发生的概率或影响,如加强安全措施、冗余设计等(题目中未明确列出,但D选项的“控制损失”与此相关)。
-
风险接受(D选项):
- 承认风险存在并主动承担后果,同时通过应急计划或储备资源控制损失。
选项C(消除风险)的排除原因
-
“消除风险”在标准风险管理框架中并非独立策略。
-
完全消除风险通常不现实,除非彻底停止相关活动(此时属于“风险回避”)。
-
风险管理更关注如何应对而非完全消除风险,因此“消除风险”不列为标准策略。
🧠 题目48:引用调用机制 - 参数传递的本质
程序运行过程中常使用参数在函数(过程)间传递消息,引用调用传递的是实参的(48)。
(48)
A. 地址 ✅
B. 类型
C. 名称
D. 值
📌 正确答案:A
🔍 详细解析
函数参数传递方式概览
在程序运行时,函数间传递信息主要依赖两种方式:
-
🔄 传值调用(Call by Value):
-
实参的值被复制到形参。
-
修改形参不会影响原始的实参。
-
常用于基本数据类型,适用于函数内部操作不应影响外部数据的场景。
-
-
🧩 引用调用(Call by Reference):
-
传递的是实参的地址,形参直接指向实参所处的内存位置。
-
修改形参等同于修改实参。
-
多用于结构体、对象等复杂数据类型,以避免内存拷贝开销。
-
📎 举个栗子(以 C++ 为例):
void modify(int &x) {
x = x + 10;
}
int main() {
int a = 5;
modify(a);
// a 变成了 15
}
在这个例子中,x 是 a 的引用,意味着它们共用同一地址,x 的修改会反映到 a 上。
💡 知识点扩展
| 方式 | 传递内容 | 对实参影响 | 性能 |
|---|---|---|---|
| 值传递 | 值 | 无影响 | 拷贝开销 |
| 引用(地址) | 地址 | 直接影响 | 效率高 |
🔢 题目49:算术表达式后缀式转换 - 操作符优先级解析
算术表达式 a + ( b − c ) ∗ d a + (b - c) * d a+(b−c)∗d 的后缀式是(49)(-、+、*表示算术的减、加、乘运算,运算符的优先级和结合性遵循惯例)。
(49)
A. b c − d a + bc-da+ bc−da+
B. a b c − d + abc-d+ abc−d+ ✅
C. a b + c − d ∗ ab+c-d* ab+c−d∗
D. a b c d − ∗ + abcd-*+ abcd−∗+
📌 正确答案:B
🔍 详细解析
后缀式(逆波兰表示法)是没有括号并且操作符写在操作数之后的表达式形式,它的优点是可以不需要括号来明确运算的优先级,且非常适合计算机进行求值。
如何将中缀表达式转换为后缀表达式?
-
构造表达式的二叉树:
-
运算符和操作数通过二叉树的结构来表示运算顺序。
-
例如,
a + (b - c) * d这个表达式可以分解为:-
根节点是加号+
-
左子树是操作数a
-
右子树是乘法*,它的左子树是减法-,右子树是操作数d
-
减法-的子树是操作数b和c
-
-
-
遍历二叉树:
- 使用后序遍历来生成后缀表达式。后序遍历的顺序是:先遍历左子树,再遍历右子树,最后访问根节点。
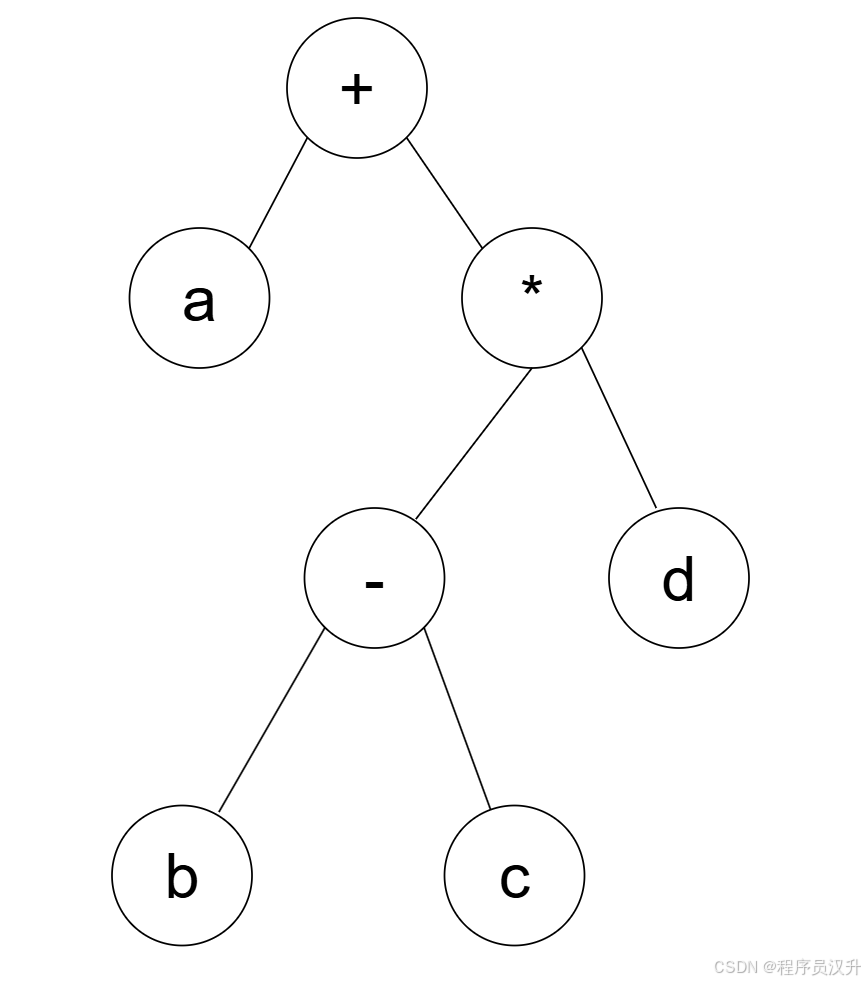
详细步骤:
-
a-> 直接输出a -
(- b - c)-> 首先输出b,然后输出c,最后输出操作符 - -
* d-> 输出操作符*,然后输出d -
最后,将加号
+放在适当的位置。
后缀式解析:
对于表达式a + (b - c) * d,按后序遍历规则,我们会得到:
-
先处理
b - c,后缀式为bc- -
然后处理
(b - c) * d,后缀式为bc-d* -
最后处理
a + (bc-d*),后缀式为abc-d*+
因此,正确答案是:B
💡 知识点扩展
-
中缀表达式:通常是我们最常见的数学表达式形式,例如
a + b * c。 -
后缀表达式(逆波兰表示法):没有括号,可以通过栈来计算,顺序从左到右,操作数先入栈,遇到操作符时从栈中取出相应的操作数进行运算。
-
中缀到后缀的转换:可通过栈实现,优先级高的操作符先入栈,括号用于界定运算顺序。
⚙️ 题目50:嵌入式操作系统的可定制性 - 面向硬件变化的配置需求
从减少成本和缩短研发周期考虑,要求嵌入式操作系统能运行在不同的微处理器平台上,能针对硬件变化进行结构与功能上的配置。该要求体现了嵌入式操作系统的(50)。
(50)
A. 可定制性 ✅
B. 实时性
C. 可靠性
D. 易移植性
📌 正确答案:A
🔍 详细解析
嵌入式操作系统通常需要具备一系列特性以适应不同的应用场景,这些特性包括:
-
可定制性
嵌入式操作系统的可定制性是指系统能够根据不同的硬件平台进行结构和功能上的调整与配置,从而减少成本并缩短开发周期。例如,操作系统可能需要针对不同的微处理器架构(如ARM、x86等)进行定制,以满足特定硬件的需求。-
硬件相关性: 系统能够根据不同硬件的变化灵活配置,满足多种应用需求。
-
减少成本与研发周期: 不同的功能可以根据实际需求进行选择性地启用或禁用,避免不必要的资源浪费。
-
-
其他嵌入式操作系统特性
-
实时性:嵌入式操作系统通常应用于实时性要求高的领域,如工业控制、医疗设备等。要求系统能够在严格的时间约束下快速响应外部事件。
-
可靠性:可靠性是嵌入式系统的重要特性之一,尤其是在关键任务的应用中,需要具备容错和防故障能力。
-
易移植性:为了在不同的硬件平台上运行,嵌入式操作系统需要具备良好的移植性,通常通过硬件抽象层来实现这一目标。
-
💡 知识点扩展
| 特性 | 描述 |
|---|---|
| 可定制性 | 根据硬件和应用需求进行灵活调整与优化 |
| 实时性 | 高响应性,适用于实时控制和任务调度 |
| 可靠性 | 高容错性,确保系统长期稳定运行 |
| 易移植性 | 支持不同硬件平台,简化跨平台开发 |
🔄 题目51:多态的不同形式 - 过载多态的应用
在多态的几种不同形式中,(51)多态是一种特定的多态,指同一个名字在不同上下文中可代表不同的含义。
(51)
A. 参数
B. 包含
C. 过载 ✅
D. 强制
📌 正确答案:C
🔍 详细解析
多态是面向对象编程中的一个重要概念,它使得程序能够使用统一的接口处理不同的数据类型,增加了程序的灵活性和可扩展性。在多态的不同形式中,常见的有参数多态、包含多态、过载多态和强制多态等。
- 过载多态(Overloading)
过载多态是指在同一个程序中,同一个名字可以表示不同的含义,具体表现为同一函数名或操作符在不同的上下文中执行不同的操作。这种多态通过函数重载或运算符重载实现,即根据参数的类型、数量或顺序来区分不同的函数或操作符。
例子:
- 在C++中,`+`操作符可以用来执行加法操作,也可以用来连接字符串。
- 在Java中,方法可以根据不同的参数类型或个数进行重载,如一个方法可以有多个版本,每个版本处理不同类型的输入。
- 其他多态形式
-
参数多态:通过参数化模板(如C++中的模板或Java中的泛型)使得一个结构可以处理多种类型的输入。
-
包含多态:一个操作或函数可以作用于基类及其所有子类,这种多态通常需要在运行时进行类型检查。
-
强制多态:编译器通过语义操作强制转换对象类型,使其符合函数或操作符的要求,常见于类型不匹配时自动进行类型转换。
-
💡 知识点扩展
-
**函数重载(Overloading)和运算符重载(Operator Overloading)**都属于过载多态的应用,它们使得程序能够在不同的上下文中使用相同的名称来处理不同类型的参数或操作对象。
-
在许多语言中(如C++、Java),过载多态是常见的特性,极大增强了代码的可读性和可维护性。
🏞️ 题目52:开发过程模型 - 瀑布模型的局限性
(52)开发过程模型最不适用开发初期对软件需求缺乏准确全面认识的情况。
(52)
A. 瀑布 ✅
B. 演化
C. 螺旋
D. 增量
📌 正确答案:A
🔍 详细解析
在软件开发过程中,不同的开发模型在不同的项目中有着不同的适应性。尤其在项目初期对需求缺乏准确全面的认识时,选择合适的开发模型至关重要。
-
瀑布模型(Waterfall Model)
瀑布模型是一种经典的开发模型,其特点是开发过程是线性顺序的,每个阶段完成后才进入下一个阶段。从需求分析、设计、实现、测试到维护,每个阶段都是独立的,且通常无法回退到上一个阶段。这种模型对于需求变化的适应性差,因此最不适用于那些在初期阶段需求不明确或经常变化的项目。缺点:
-
对需求变化的响应较慢。
-
如果开发初期对需求缺乏准确理解,后期修改成本较高,因为必须重新审视和修改之前的阶段。
-
-
其他开发模型
-
演化模型(Evolutionary Model):该模型更适应需求在开发过程中的逐步演化,允许开发过程中不断修改和改进产品。
-
螺旋模型(Spiral Model):结合了瀑布模型的结构化和原型模型的灵活性,允许在开发过程中多次评审和风险评估,适应需求不确定的情况。
-
增量模型(Incremental Model):通过分阶段交付软件,每个阶段提供一个增量版本,这种模型可以在开发过程中逐步完善需求,因此能够适应需求的变化。
-
💡 知识点扩展
瀑布模型的线性结构使其难以应对需求的变化,而其他模型(如演化、螺旋和增量模型)则能更灵活地处理需求变更,尤其是在需求不完全明确的项目初期。
🔍 题目53-54:编译过程中的语句翻译与执行
编译过程中,对高级语言程序语名的翻译主要考虑声明语名和可执行语句。对声明语句,主要是将所需要的信息正确地填入合理组织的(53)中;对可执行语句,则是(54)。
(53)
A. 符号表 ✅
B. 栈
C. 队列
D. 树
(54)
A. 翻译成机器代码并加以执行
B. 转换成语法树
C. 翻译成中间代码或目标代码 ✅
D. 转换成有限自动机
📌 正确答案:53:A、54:C
🔍 详细解析
-
声明语句的翻译
声明语句通常涉及变量、函数等标识符的定义,这些信息需要在编译过程中被正确地记录下来。编译器会将这些信息填入符号表,符号表是一个数据结构,存储了程序中所有标识符(如变量名、函数名、类型等)及其相关的属性(如数据类型、作用域、内存位置等)。 -
可执行语句的翻译
可执行语句通常指的是程序的操作和计算,这些语句需要被转换为机器可执行的指令。在编译过程中,这些语句会被转换成中间代码或目标代码,以便后续的优化和最终生成机器代码。
💻 题目56-57:计算机体系结构 - Windows文件系统路径解析
Windows文件系统的目录结构(C盘下)如下图所示,假设用户要访问文件f2.java,则该文件的全文件名为(56)。若系统当前工作目录为ProgramFile,那么该文件的相对路径为(57)。
(56)
A. C:\f2.java
B. C\Document\java-prog\f2.java
C. \ProgramFile\java-prog\f2.java
D. C:\ProgramFile\Java-prog\f2.java ✅
(57)
A. \java-prog
B. java-prog\✅
C. Program\java-prog
D. \Program\java-prog
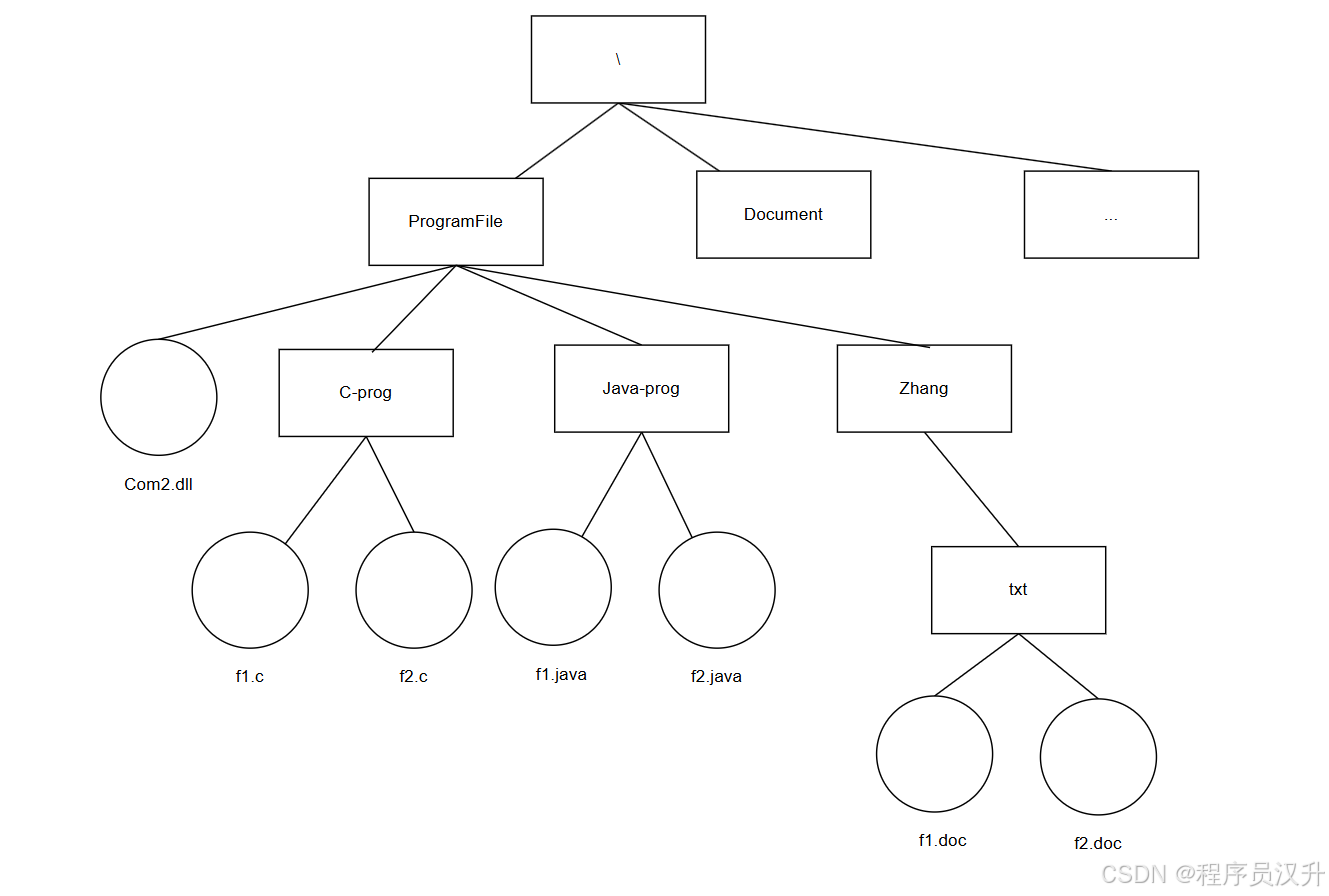
📌 正确答案:56:D、57:B
🔍 详细解析
-
问题一:
-
绝对路径需从根目录(
C:\)开始完整描述路径。 -
根据目录结构,
f2.java的路径为:
C:\ProgramFile\Java-prog\f2.java(注意大小写不敏感但需与选项一致)。 -
错误选项分析:
-
A:缺少中间目录。
-
B:路径分隔符应为
\,且路径错误。 -
C:缺少盘符
C:。
-
-
-
问题二:
-
相对路径从当前目录(
ProgramFile)开始,无需盘符和根目录符号。 -
正确路径:
Java-prog\。
-
🖥️ 题目58-61:操作系统 - PV操作与进程同步
进程P1、P2、P3、P4、P5和P6的前趋势图如下所示,若用PV操作控制进程P1、P2、P3、P4、P5和P6并发 执行的过程,则需要设置7个信号量S1、S2、S3、S 4、S5、S6和S7,且信号量S1~S7的初值都等于零。 P1—P6的进程执行图中,a和b处应分别填写(58);c 和d处应分别填写(59);e和f处应分别填写(60);g 和h处应分别填写(61)
(58)
A. V(S1)和V(S2)✅
B. P(S1)和P(S2)
C. P(S1)和V(S2)
D. V(S1)和P(S2)
(59)
A. P(S1)P(S2)和P(S3)和P(S4)
B. V(S1)V(S2)和V(S3)和V(S4)
C. P(S1)P(S2)和V(S3)和V(S4)✅
D. V(S1)V(S2)和P(S3)和P(S4)
(60)
A. P(S5)P(S6)和P(S4)和P(S5)
B. V(S5)V(S6)和V(S4)和V(S5)
C. P(S5)P(S6)和V(S4)和V(S5)
D. V(S5)V(S6)和P(S4)和P(S5)✅
(61)
A. P(S7)和P(S6)P(S7)
B. V(S7)和P(S6)P(S7)✅
C. P(S7)和V(S6)V(S7)
D. V(S7)和V(S6)V(S7)
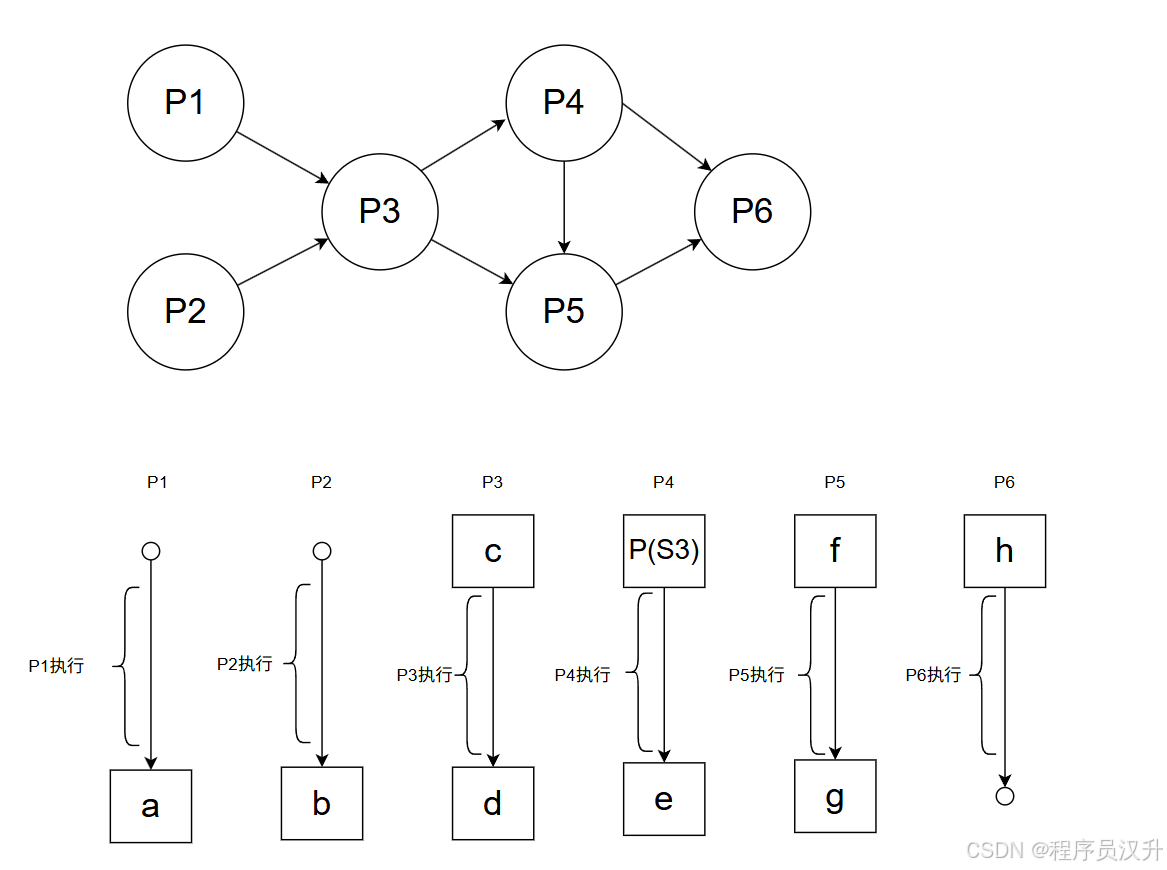
📌 正确答案:58:A、59:C、60:D、61:B
🔍 详细解析
详细PV操作与进程同步可以见文章26-28题
这题大致写一下流程:
-
P1、P2先执行,释放 S1和S2:题中
a是V(S1),b为V(S2),所以(58)选A-
P3 需要 S2 和 S3,所以P3 要等待P1释放S1 和P2 释放 S2。题中
c是P(S1)P(S2) -
P1、P2运行完后,释放 S1 和 S2
-
P3 现在有 S1 和 S2,所以 P3 可以执行。
-
-
P3 运行完后,释放
S3和S4:所以d为V(S3)和V(S4),所以(59)选C- P4需要P3 释放的S3,P4可以执行
- P5需要P3 释放的S4,同时还需要P4释放的S5,所以
f为P(S4)P(S5)
-
P4执行完后,释放S5和S6,所以
e为V(S5)V(S6),所以(60)选D- P5拿到了P3释放的S4和P4释放的S5,所以P5可以执行
- P6拿到了P4的S6,但是还需要等待P5的S7,所以
h为P(S6)P(S7)
-
P5 运行完后,释放 S7:题中
g为V(S7),所以(61)选B -
P6 现在有 S6(P4 释放的)和 S7(P5 释放的),所以 P6 可以执行。
📦 题目62-64:数据库设计 - UML序列图综合解析
UML序列图是业务场景的图形化表示,描述了以(62)顺序组织的对象之间的交互活动。某系统中的一个UML序列图如下图所示,(63)表示返回消息,Account类必须实现的方法有(64)。
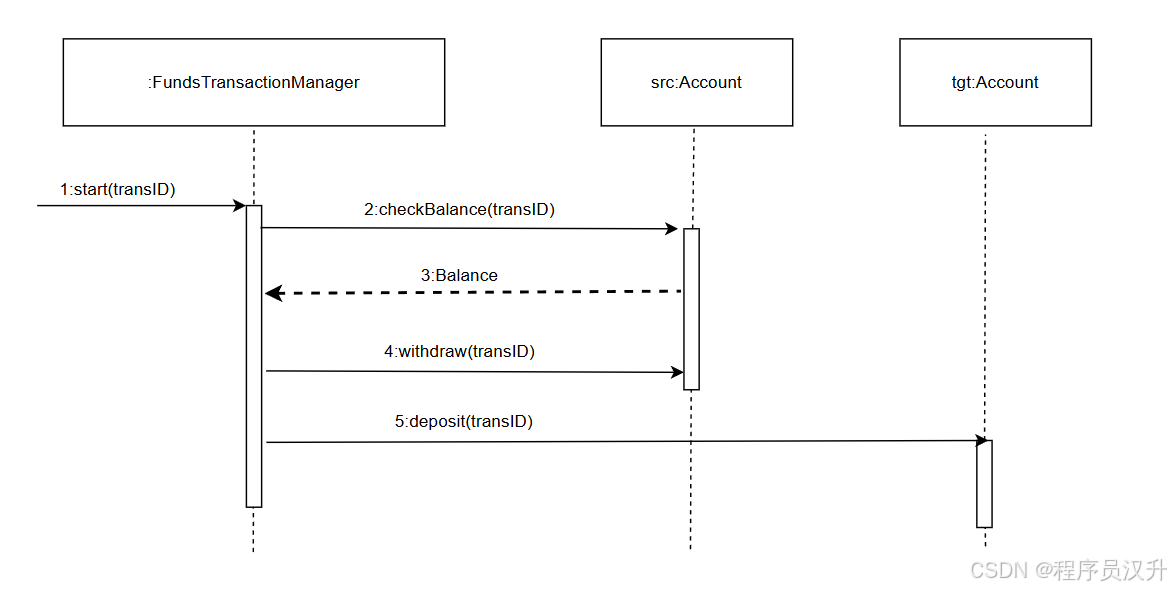
(62)
A. 活动
B. 时间✅
C. 消息
D. 调用
(63)
A. tanslD
B. balance✅
C. withdraw
D. deposit
(64)
A. start()
B. checkBalance()和withdraw()
C. deposit()
D. checkBalance()、withdraw()和deposit()✅
📌 正确答案:62:B、63:B、64:D
🔍 详细解析
-
问题一:
-
序列图的核心特征是时间顺序,纵轴表示时间流逝方向(自上而下),横轴表示交互对象。
-
强调消息传递的时序关系,而非单纯的活动或调用逻辑。
-
-
问题二:
-
返回消息在序列图中通常以虚线箭头表示,标注返回值(如
balance)。 -
其他选项(
withdraw、deposit)为同步消息(实线箭头),tanslD可能是干扰项。
-
-
问题三:
-
据序列图交互逻辑,
Account类需响应以下消息:-
checkBalance():查询余额(对应返回消息balance)。 -
withdraw():取款操作。 -
deposit():存款操作。
-
-
start()是FundsTransactionManager类的方法(发起交易流程)。
-
🧩 题目65-66:数据结构与算法 - Prim算法与最小生成树
实现Prim算法利用的算法是(65),采用Prim算法求解下图的最小生成树,该算法的设计策树的权值是(66)。
(65)
A. .分治法
B. 动态规划法
C. 贪心算法✅
D. 递归算法
(66)
A. 15✅
B. 18
C. 24
D. 27
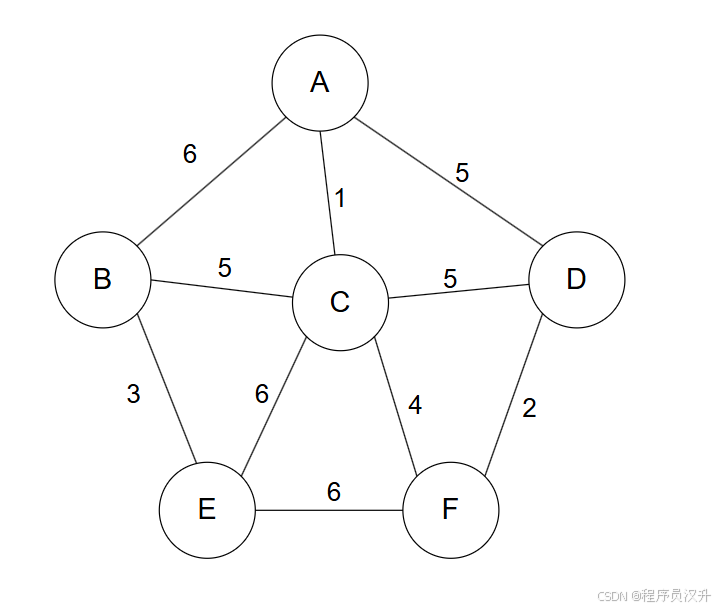
📌 正确答案:65:C、66:A
🔍 详细解析
-
问题一:
-
Prim算法是
贪心算法的典型应用,其核心策略是:-
局部最优选择:每次选择当前未纳入生成树的顶点中,与已生成树距离最短的边。
-
无后效性:一旦选择某条边,后续操作不会影响之前的选择。
-
-
对比其他算法:
-
分治法:将问题分解为子问题(如归并排序)。
-
动态规划:依赖子问题的全局最优解(如背包问题)。
-
-
-
问题二:
-
Prim算法执行步骤:
-
任选起始顶点(如A),选择最小权边AC(1)。
-
从{A,C}出发,选择最小权边CF(4)。
-
从{A,C,F}出发,选择最小权边DF(2)。
-
从{A,C,F,D}出发,选择最小权边CB(5)。
-
从{A,C,F,D,B}出发,选择最小权边BE(3)。
-
-
总权值:1(AC) + 4(CF) + 2(DF) + 3(BE) + 5(BC) = 15。
二、 系统开发和运行知识 🗃️
🧪 题目14:软件测试 - 测试方法选择
针对月收入小于等于 3500 元免征个人所得税的需求,现分别输入 3499,3500 和 3501 进行测试,则采用的测试方法 (14) 。
(14)
A. 判定覆盖
B. 边界值分析 ✅
C. 路径覆盖
D. 因果图
📌 正确答案:B
🔍 详细解析
测试方法的核心特征与题目匹配性:
-
边界值分析(Boundary Value Analysis):
-
定义:针对输入范围的边界(如临界值±1)设计测试用例,验证边界处理逻辑。
-
本题应用:
-
边界点:3500元(免征阈值)
-
测试值:3499(边界内)、3500(边界)、3501(边界外)
-
-
典型场景:数值范围、阈值判断(如本题的免税条件)。
-
-
其他选项的排除原因:
-
A. 判定覆盖:需覆盖所有逻辑判断的真/假分支(如
if-else所有路径),但题目未体现分支结构。 -
C. 路径覆盖:要求覆盖程序所有执行路径(需代码控制流图),与输入值无关。
-
D. 因果图:用于分析输入条件与输出结果的逻辑关系(如组合条件),本题无多条件组合。
-
⚠️ 易错点提醒
-
边界值 vs 等价类:
-
边界值是等价类的补充,重点测试边界±1(如
3499/3500/3501)。 -
等价类只需从每类中选典型值(如3000代表≤3500类,4000代表>3500类)。
-
-
判定覆盖的干扰:若题目描述改为“测试
if income ≤ 3500的分支覆盖”,则需选A。
🛠️ 题目15:软件工程 - 软件维护特性
以下关于软件维护的叙述中,正确的是 (15) 。
(15)
A. 工作量相对于软件开发而言要小很多
B. 成本相对于软件开发而言要更低
C. 时间相对于软件开发而言通常更长 ✅
D. 只对软件代码进行修改的行为
📌 正确答案:C
🔍 详细解析
软件维护的核心特点与常见误区:
-
时间跨度(选项C的正确性):
-
维护周期:通常占软件生命周期的60%-70%(远长于开发阶段)。
-
原因:包括纠错、适应环境变化、功能增强等长期需求。
-
-
其他选项的错误分析:
-
A. 工作量小:实际维护可能比开发更复杂(需理解现有代码+避免引入新问题)。
-
B. 成本低:维护成本常是开发成本的2-4倍(累计修改和测试开销)。
-
D. 仅修改代码:维护包括文档更新、数据迁移等非代码变更。
-
三、 面向对象基础知识 🧩
🔄 题目16:编程语言特性 - 绑定机制
在运行时将调用和响应调用所需执行的代码加以结合的机制是 (16) 。
(16)
A. 强类型
B. 弱类型
C. 静态绑定
D. 动态绑定 ✅
📌 正确答案:D
🔍 详细解析
绑定机制的核心概念:
-
动态绑定(Dynamic Binding):
-
定义:在程序运行时确定调用的具体方法或函数,基于对象的实际类型(而非声明类型)。
-
典型应用:面向对象中的多态(如Java/C++的虚函数、Python的方法调用)。
-
本题匹配:题干描述的“运行时结合”即动态绑定特征。
-
-
其他选项的排除原因:
-
A/B. 强类型/弱类型:与类型检查严格性相关(如Python是强类型,JavaScript是弱类型),与绑定机制无关。
-
C. 静态绑定:在编译时确定调用关系(如C语言函数调用、Java的
final方法)。
-
📦 题目17:面向对象设计原则 - 包依赖规则
进行面向对象系统设计时,在包的依赖关系图中不允许存在环,这属于 (17) 原则。
(17)
A. 单一责任
B. 无环依赖 ✅
C. 依赖倒置
D. 里氏替换
📌 正确答案:B
🔍 详细解析
包依赖设计原则与环的禁止:
-
无环依赖原则(Acyclic Dependencies Principle, ADP):
-
核心要求:包之间的依赖关系必须构成有向无环图(DAG),禁止循环依赖(如A→B→C→A)。
-
目的:避免修改一个包引发连锁反应,提高模块独立性和编译效率。
-
-
其他选项的排除原因:
-
A. 单一责任:一个类/模块只应有一个变更原因(与功能划分相关,非依赖结构)。
-
C. 依赖倒置:高层模块不应依赖低层模块,二者应依赖抽象(DIP)。
-
D. 里氏替换:子类必须能替换父类而不破坏程序(LSP)。
-
🧩 题目18-19:面向对象分析与设计
面向对象分析的第一项活动是 (18) ;面向对象程序设计语言为面向对象 (19) 。
(18)
A. 组织对象
B. 描述对象间的相互作用
C. 认定对象 ✅
D. 确定对象的操作
(19)
A. 用例设计
B. 分析
C. 需求分析
D. 实现✅
📌 正确答案:18:C,19:D
🔍 解析
-
问题一:
-
认定对象是OOA的起点,通过识别问题域中的实体、概念或角色建立对象模型。
-
其他选项(组织、交互、操作)均需在对象认定后进行。
-
-
问题二:
-
OOP语言(如Java/C++)用于实现面向对象设计,将类、继承等概念转化为代码。
-
前三个阶段(需求、分析、设计)均属设计层,与语言无关。
-
💡 知识框架
OO开发阶段与工具对应关系:
| 阶段 | 主要活动 | 工具/产出 |
|---|---|---|
| 需求分析 | 获取用户需求 | 用例图、用户故事 |
| OO分析 | 认定对象、定义属性 | 领域模型图 |
| OO设计 | 设计类交互、架构 | 类图、序列图 |
| OO实现 | 编码 | Java/Python等OOP语言 |
🎯 题目67-68:设计模式 - 设计模式应用场景
(67)设计模式能使一个对象的状态发生改变时通所有依赖它的监听者。(68)设计模式限制类的实例对象只能由一个。
(67)
A. 责任链(chainofresponsibility)
B. 命令(command)
C. 抽象工厂(abstractfactory)
D. 观察者(observer)✅
(68)
A. 原型(prototype)
B. 工厂方法(factorymethod)
C. 单例(singleton)✅
D. 生成器(builder)
📌 正确答案:67:D,68:C
🔍 解析
设计模式详解见文章
💡 设计模式对比总结
| 模式 | 核心用途 | 示例场景 |
|---|---|---|
| 观察者(Observer) | 一对多的依赖通知机制 | 股票价格变动通知交易员 |
| 单例(Singleton) | 全局唯一实例访问 | 数据库连接池、日志管理器 |
📊题目69-70:项目管理 - 关键路径与项目延期分析
下图是一个软件项目的活动图,其中顶点表示项目里程碑,连接顶点的边表示包含的活动,则里程碑(69)在关键路径上。若在实际项目进展中,活动AD在活动AC开始3天后才开始,而完成活动DG过程中,由于有临时事件发生,实际需要15天才能完成,则完成该项目的最短时间比原计划多了(70)天。
(69)
A. B
B. C✅
C. D
D. I
(70)
A. 8
B. 3✅
C. 5
D. 6
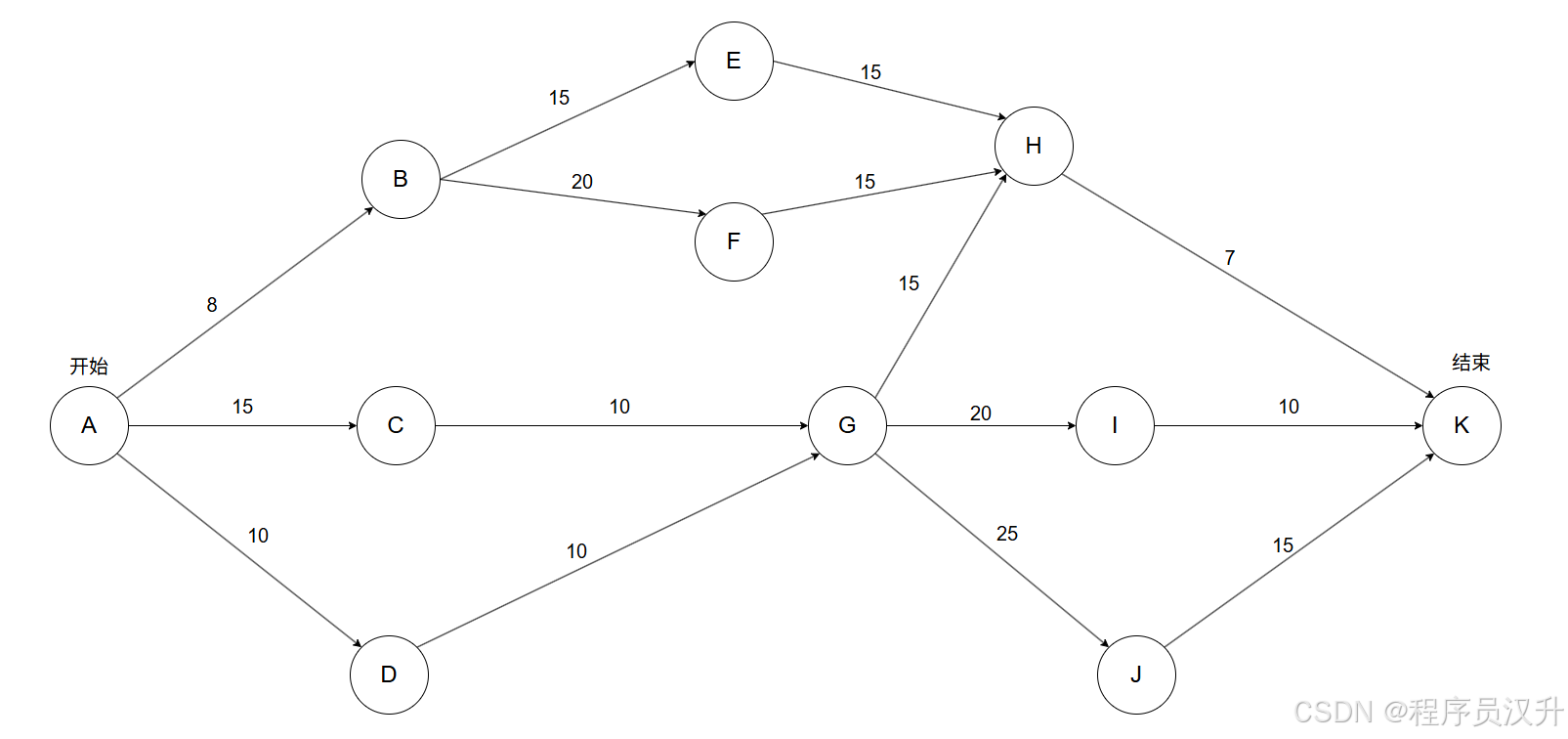
📌 正确答案:69:B,70:B
🔍 解析
-
问题一:
-
关键路径是项目中时间最长的路径,决定项目最短完成时间。根据解析,关键路径为 A→C→G→J→K(65天),因此
C是关键路径上的里程碑。 -
其他路径(如含B、D、I的路径)耗时更短,非关键路径。
-
-
问题二:
-
原计划关键路径:A→C→G→J→K(65天)。
-
AD和DG的变更影响:
-
AD延迟:比AC晚3天开始(原计划无延迟,现AD依赖AC完成)。
-
DG延迟:实际需15天(原计划10天),多出5天。
-
总延迟:3(AD) + 5(DG) = 8天。
-
-
原允许的浮动时间:
- 非关键路径ADGHK最长42天,与关键路径差23天(65-42),但解析提到“只能推迟5天”,可能是其他约束。
-
净延期:实际需推迟8天 - 原可容忍5天 = 3天。
-
四、 网络与信息安全知识 🌐
🔒 题目7:网络协议 - 文件安全传输
下列协议中,可以用于文件安全传输的是 (7) 。
(7)
A. FTP
B. SFTP ✅
C. TFTP
D. ICMP
📌 正确答案:B
🔍 详细解析
各协议的安全性分析:
-
SFTP(SSH File Transfer Protocol)
-
安全机制:基于SSH(Secure Shell)加密,支持身份验证和数据加密。
-
用途:专为安全文件传输设计,防止窃听和篡改。
-
-
其他协议的安全性缺陷:
-
A. FTP:明文传输用户名、密码和数据,易被嗅探(无加密)。
-
C. TFTP:基于UDP的简单文件传输,无任何安全机制。
-
D. ICMP:网络控制报文协议(如ping),不涉及文件传输。
-
💡 知识点扩展
常见文件传输协议对比:
| 协议 | 加密 | 端口 | 可靠性 | 典型用途 |
|---|---|---|---|---|
| FTP | 无 | 20/21 | 高 | 匿名文件下载(不安全) |
| SFTP | 有 | 22 | 高 | 企业安全文件传输 |
| TFTP | 无 | 69 | 低 | 局域网设备固件更新 |
| SCP | 有 | 22 | 高 | 基于SSH的快速传输 |
🦠 题目8:计算机安全 - 恶意软件分类
下列不属于计算机病毒的是 (8) 。
(8)
A. 永恒之蓝
B. 蠕虫
C. 特洛伊木马
D. DDoS ✅
📌 正确答案:D
🔍 详细解析
计算机病毒与相关威胁的区分:
-
DDoS(分布式拒绝服务攻击):
-
本质:一种网络攻击手段,通过大量请求淹没目标使其瘫痪。
-
关键区别:不感染文件、不自我复制,属于攻击行为而非恶意软件。
-
-
其他选项的恶意软件属性:
-
A. 永恒之蓝:基于漏洞的蠕虫病毒(利用MS17-010传播)。
-
B. 蠕虫:自我复制的独立程序,通过网络传播(如WannaCry)。
-
C. 特洛伊木马:伪装成正常程序的恶意软件,窃取数据或控制设备。
-
🛡️ 题目9:计算机安全 - 杀毒软件功能
以下关于杀毒软件的描述中,错误的是 (9) 。
(9)
A. 应当为计算机安装杀毒软件并及时更新病毒库信息
B. 安装杀毒软件可以有效防止蠕虫病毒
C. 安装杀毒软件可以有效防止网站信息被篡改 ✅
D. 服务器操作系统也需要安装杀毒软件
📌 正确答案:C
🔍 详细解析
杀毒软件的核心功能与局限性:
-
选项C的错误原因:
-
网站信息被篡改通常由服务器漏洞(如SQL注入、XSS攻击)或弱密码导致,属于Web应用层安全问题。
-
杀毒软件主要防护终端设备(如病毒、木马),无法直接防止远程服务器上的网站篡改。
-
-
其他选项的正确性:
-
A:病毒库更新是杀毒软件检测新威胁的基础。
-
B:蠕虫病毒可通过行为监控和特征码检测被拦截。
-
D:服务器同样面临恶意软件威胁(如勒索病毒),需专用防护。
-
💡 知识点扩展
安全防护的层级分工:
| 安全威胁类型 | 防护措施 | 适用工具/技术 |
|---|---|---|
| 病毒/蠕虫/木马 | 终端杀毒软件 | 360、卡巴斯基、Windows Defender |
| 网站篡改/入侵 | Web防火墙(WAF)、代码审计 | ModSecurity、SQL注入过滤 |
| DDoS攻击 | 流量清洗、CDN | Cloudflare、阿里云DDoS防护 |
🔐 题目10:网络安全 - 防火墙功能
通过在出口防火墙上配置 (10) 功能可以阻止外部未授权用户访问内部网络。
(10)
A. ACL ✅
B. SNAT
C. 入侵检测
D. 防病毒
📌 正确答案:A
🔍 详细解析
防火墙关键功能对比:
-
ACL(访问控制列表):
-
作用:通过规则明确允许/拒绝特定IP、端口或协议的流量,是阻止未授权访问的核心机制。
-
示例:拒绝所有从外网到内网的TCP 3389(RDP)连接。
-
-
其他选项的适用场景:
-
B. SNAT(源地址转换):用于隐藏内网IP,实现共享公网IP出口,不直接控制访问权限。
-
C. 入侵检测(IDS):监控异常流量并报警,属于被动防御,无法主动拦截。
-
D. 防病毒:检测恶意文件,与网络访问控制无关。
-
💡 知识点扩展
防火墙技术分层:
| 技术 | 工作层级 | 主要功能 |
|---|---|---|
| ACL | 网络层/传输层 | 基于IP/端口过滤流量 |
| SNAT | 网络层 | 转换源IP地址(内网→公网) |
| IDS | 应用层 | 检测攻击行为并报警 |
| 防病毒 | 应用层 | 扫描文件/流量中的恶意代码 |
🛡️ 题目11:Web安全 - SQL注入防御
SQL 注入是常见的 Web 攻击,以下不能够有效防御 SQL 注入的手段是 (11) 。
(11)
A. 对用户输入做关键字过滤
B. 部署 Web 应用防火墙进行保护
C. 部署入侵检测系统阻断攻击 ✅
D. 定期扫描系统漏洞并及时修复
📌 正确答案:C
🔍 详细解析
SQL注入防御措施的有效性分析:
-
选项C的局限性:
-
入侵检测系统(IDS):仅能监测并报警SQL注入行为,无法实时阻断攻击(需依赖IPS或WAF实现拦截)。
-
被动性缺陷:攻击可能已在IDS报警前完成数据泄露。
-
-
其他选项的有效性:
-
A. 输入过滤:过滤单引号、注释符等SQL元字符(如
'、--)。 -
B. WAF:通过规则库直接拦截注入payload(如ModSecurity的SQLi规则)。
-
D. 漏洞修复:修补CMS或框架的SQL注入漏洞(如PHP的PDO预处理修复)。
-
💡 知识点扩展
SQL注入防御体系:
| 防御层级 | 措施 | 技术示例 |
|---|---|---|
| 代码层 | 参数化查询/预处理语句 | Java的PreparedStatement |
| 输入层 | 关键字过滤/白名单验证 | 正则表达式过滤UNION SELECT |
| 网络层 | WAF规则拦截 | Cloudflare WAF |
| 运维层 | 最小权限数据库账户+漏洞扫描 | Nessus扫描SQL漏洞 |
五、 标准化、信息化和知识产权基础知识 🛠️
📜 题目12:知识产权 - 专利申请权归属
甲乙丙三者分别就相同内容的发明创造,先后向专利管理部门提出申请, (12) 可以获得专利申请权。
(12)
A. 甲乙丙均
B. 先申请者 ✅
C. 先试用者
D. 先发明者
📌 正确答案:B
🔍 详细解析
专利申请的“先申请原则”与关键规则:
-
先申请原则(First-to-File):
-
全球主流规则:专利权授予最先提交申请的人(无论实际发明时间早晚)。
-
目的:鼓励尽早公开技术,避免重复研发纠纷。
-
-
其他选项的排除原因:
-
A. 甲乙丙均:同一发明仅能授予一项专利权(《专利法》第9条)。
-
C. 先试用者:使用行为不影响申请权(除非构成“先用权”抗辩)。
-
D. 先发明者:仅美国历史上采用“先发明制”,2013年后已改为“先申请制”。
-
📜 题目13:知识产权 - 保护期延长规则
(13) 的保护期是可以延长的。
(13)
A. 著作权
B. 专利权
C. 商标权 ✅
D. 商业秘密权
📌 正确答案:C
🔍 详细解析
知识产权保护期的延长机制:
-
商标权(唯一可无限延长的权利):
-
初始保护期:注册成功后10年(中国《商标法》第39条)。
-
延长方式:期满前12个月内办理续展,每次续展延长10年,次数不限。
-
-
其他知识产权的固定保护期:
-
A. 著作权:
-
自然人作品:作者终生 + 死后50年。
-
法人作品:发表后50年。
-
不可延长。
-
-
B. 专利权:
-
发明专利:20年(申请日起算)。
-
实用新型/外观设计:10年。
-
不可延长(除药品专利可能补偿5年)。
-
-
D. 商业秘密权:
- 保护期无限制,但前提是信息始终处于保密状态。
-
📑 题目55:软件使用许可合同 - 独家许可使用
软件著作人与被许可方签订一份软件使用许可合同。若在该合同约定的时间和地域范围内,软件权利人不得再许可任何第三人以此相同的方法使用该项软件,但软件权利人可以自己使用,则该项许可使用是(55)。
(55)
A. 独家许可使用 ✅
B. 独占许可使用
C. 普通许可使用
D. 部分许可使用
📌 正确答案:A
🔍 详细解析
在软件著作权和许可的相关法律中,不同的许可方式有不同的含义:
-
独家许可使用(Exclusive License)
独家许可使用意味着软件权利人在合同中承诺在约定的时间和地域范围内,只将软件使用权授予被许可方,而不再将相同的使用权授予任何其他第三方。不过,软件权利人自己仍然可以使用该软件。因此,软件权利人保持了一定的使用权,但其他人无法在该区域和时间内使用该软件。 -
独占许可使用(Sole License)
独占许可使用不同于独家许可,在独占许可的情况下,软件权利人在同一地区和时间内既不能将软件授权给第三方,也不能使用该软件。许可方拥有完全的使用权。 -
普通许可使用(Non-exclusive License)
普通许可使用指的是软件权利人可以将软件使用权授予多个第三方,并且自己也可以继续使用该软件。软件使用是非专有的,即没有限制权利人将软件授权给其他方。 -
部分许可使用
部分许可使用不属于标准的许可类型,一般不在软件许可合同中使用。它通常意味着只在某些特定条件下授予许可。
因此,本题中描述的情形最符合独家许可使用,因为软件权利人可以自己使用该软件,但不得再将其授权给第三方。
六、 计算机英语 🐧
🐧题目71-75:计算机英语
Regardless of how well designed,constructed, and tested a system or application maybe, errors or bugs will inevitably occur.Once a system has been(71), it enters operations and support.
Systems support is the ongoing technical support for user, as well as the maintenance required to fix any errors, omissions,or new requirements that may arise. Before an information system can be (72), it must be in operation. System operation is the day-to-day,week-to-week,month-to-month,and year- to-year (73) of an information system"s business processes and application programs…
Unlike systems analysis,design,and implementation,systems support cannot sensibly be (74) into actual phases that a support project must perform. Rather,systems support consists of four ongoing activities that are program maintenance,system recovery,technical support, and system enhancement.Each activity is a type of support project that is (75) by a particular problem,event, or opportunity enco untered with the implemented system.
(71)
A. designed
B. implemented✅
C. investigated
D. analyzed
(72)
A. supported✅
B. tested
C. implemented
D. constructed
(73)
A. construction
B. maintenance
C. execution✅
D. implementation
(74)
A. broke
B. formed
C. composed
D. decomposed✅
(75)
A. triggered✅
B. leaded
C. caused
D. produced
📌 正确答案:(71)B,(72)A,(73)C,(74)D,(75)A
参考译文:
无论一个系统或应用程序的设计、构建和测试多么完善,错误或漏洞都不可避免。一旦系统被实施,它将进入运营与支持阶段。
系统支持是为用户提供的持续性技术支持,包括修复错误、补充遗漏或应对新需求的维护工作。在信息系统能够被支持之前,它必须处于运行状态。系统运营是信息系统业务流程和应用程序的日常、每周、每月及每年执行。
与系统分析、设计和实施不同,系统支持无法合理地分解为支持项目必须执行的具体阶段。相反,系统支持包含四项持续活动:程序维护、系统恢复、技术支持和系统增强。每项活动均是一种支持项目,由已实施系统中遇到的特定问题、事件或机会所触发。

码字不易,写完发现接近4万多字。如果有收获不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️


















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









