






import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler, MaxAbsScaler
# 设置随机种子以保证结果可复现
np.random.seed(42)
data = {
'年龄': np.random.randint(18, 70, 100), # 量级: 10-100
'年收入': np.random.randint(30000, 500000, 100), # 量级: 万-十万
'工作年限': np.random.randint(0, 40, 100), # 量级: 0-50
'信用评分': np.random.randint(300, 850, 100), # 量级: 百
'月消费': np.random.randint(1000, 15000, 100), # 量级: 千-万
}
df = pd.DataFrame(data)
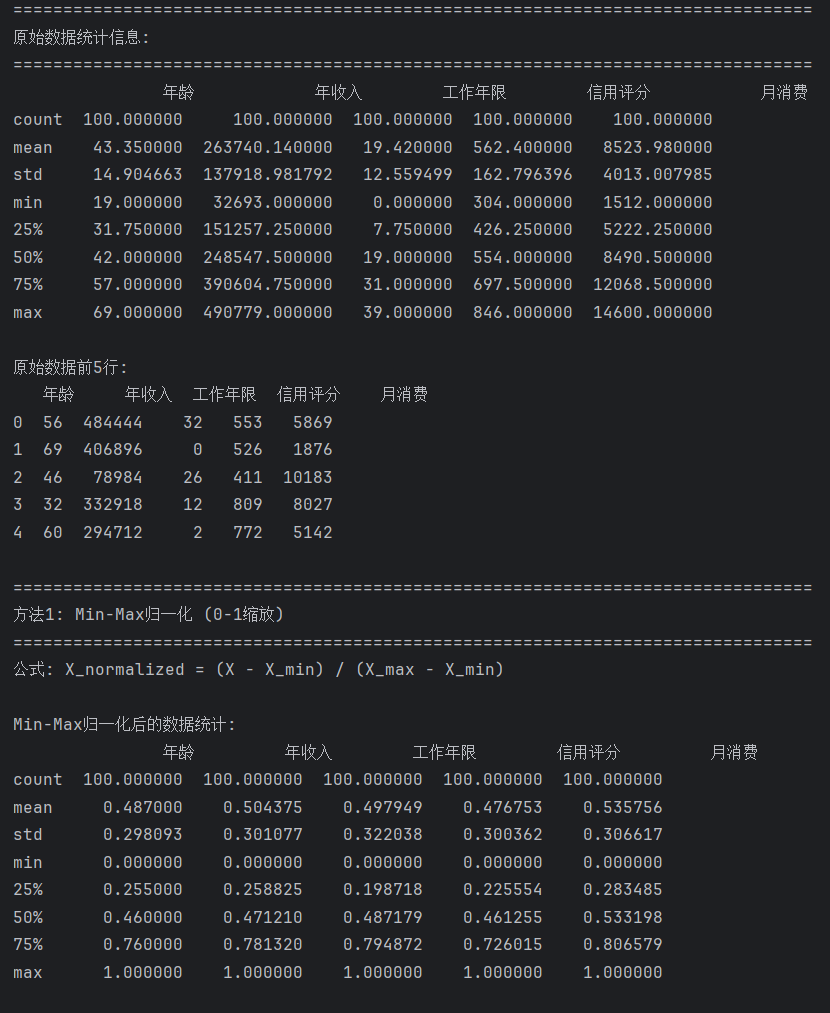
print("=" * 80)
print("原始数据统计信息:")
print("=" * 80)
print(df.describe())
print("\n原始数据前5行:")
print(df.head())
# ============================================================================
# 方法1: Min-Max归一化 (归一化到 [0, 1] 区间)
# ============================================================================
print("\n" + "=" * 80)
print("方法1: Min-Max归一化 (0-1缩放)")
print("=" * 80)
print("公式: X_normalized = (X - X_min) / (X_max - X_min)")
scaler_minmax = MinMaxScaler()
df_minmax = pd.DataFrame(
scaler_minmax.fit_transform(df),
columns=df.columns
)
print("\nMin-Max归一化后的数据统计:")
print(df_minmax.describe())
print("\nMin-Max归一化后的前5行:")
print(df_minmax.head())
# ============================================================================
# 方法2: Z-Score标准化 (标准化为均值0,标准差1)
# ============================================================================
print("\n" + "=" * 80)
print("方法2: Z-Score标准化 (标准正态分布)")
print("=" * 80)
print("公式: X_standardized = (X - mean) / std")
scaler_standard = StandardScaler()
df_standard = pd.DataFrame(
scaler_standard.fit_transform(df),
columns=df.columns
)
print("\nZ-Score标准化后的数据统计:")
print(df_standard.describe())
print("\nZ-Score标准化后的前5行:")
print(df_standard.head())
# ============================================================================
# 方法3: 最大绝对值归一化 (归一化到 [-1, 1] 区间)
# ============================================================================
print("\n" + "=" * 80)
print("方法3: 最大绝对值归一化 (-1到1缩放)")
print("=" * 80)
print("公式: X_normalized = X / max(|X|)")
scaler_maxabs = MaxAbsScaler()
df_maxabs = pd.DataFrame(
scaler_maxabs.fit_transform(df),
columns=df.columns
)
print("\n最大绝对值归一化后的数据统计:")
print(df_maxabs.describe())
print("\n最大绝对值归一化后的前5行:")
print(df_maxabs.head())
# ============================================================================
# 方法4: 鲁棒缩放 (使用中位数和四分位数,对异常值不敏感)
# ============================================================================
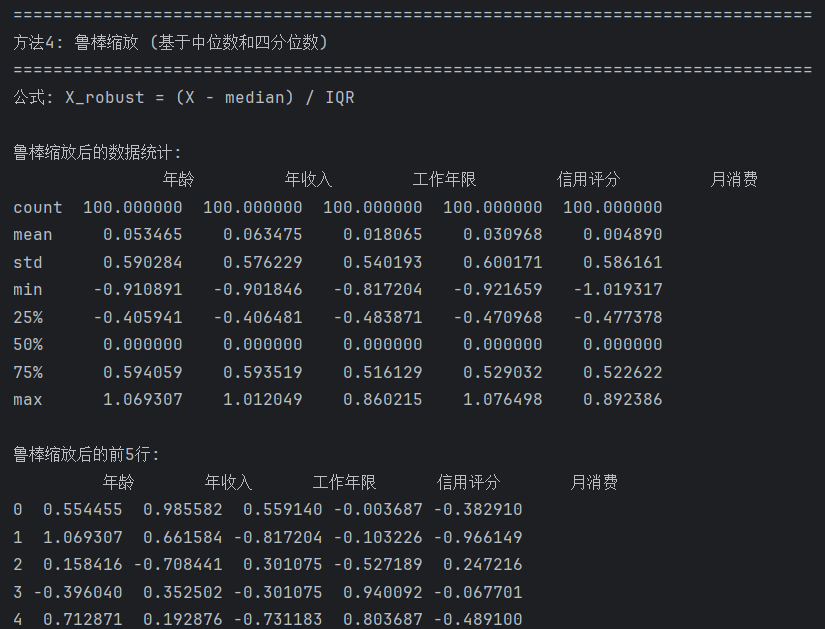
print("\n" + "=" * 80)
print("方法4: 鲁棒缩放 (基于中位数和四分位数)")
print("=" * 80)
print("公式: X_robust = (X - median) / IQR")
scaler_robust = RobustScaler()
df_robust = pd.DataFrame(
scaler_robust.fit_transform(df),
columns=df.columns
)
print("\n鲁棒缩放后的数据统计:")
print(df_robust.describe())
print("\n鲁棒缩放后的前5行:")
print(df_robust.head())
# ============================================================================
# 方法5: 使用pandas直接进行归一化(手动实现)
# ============================================================================
print("\n" + "=" * 80)
print("方法5: 使用Pandas手动实现Min-Max归一化")
print("=" * 80)
df_manual_minmax = (df - df.min()) / (df.max() - df.min())
print("\n手动Min-Max归一化后的前5行:")
print(df_manual_minmax.head())
# ============================================================================
# 方法6: 使用pandas直接进行标准化(手动实现)
# ============================================================================
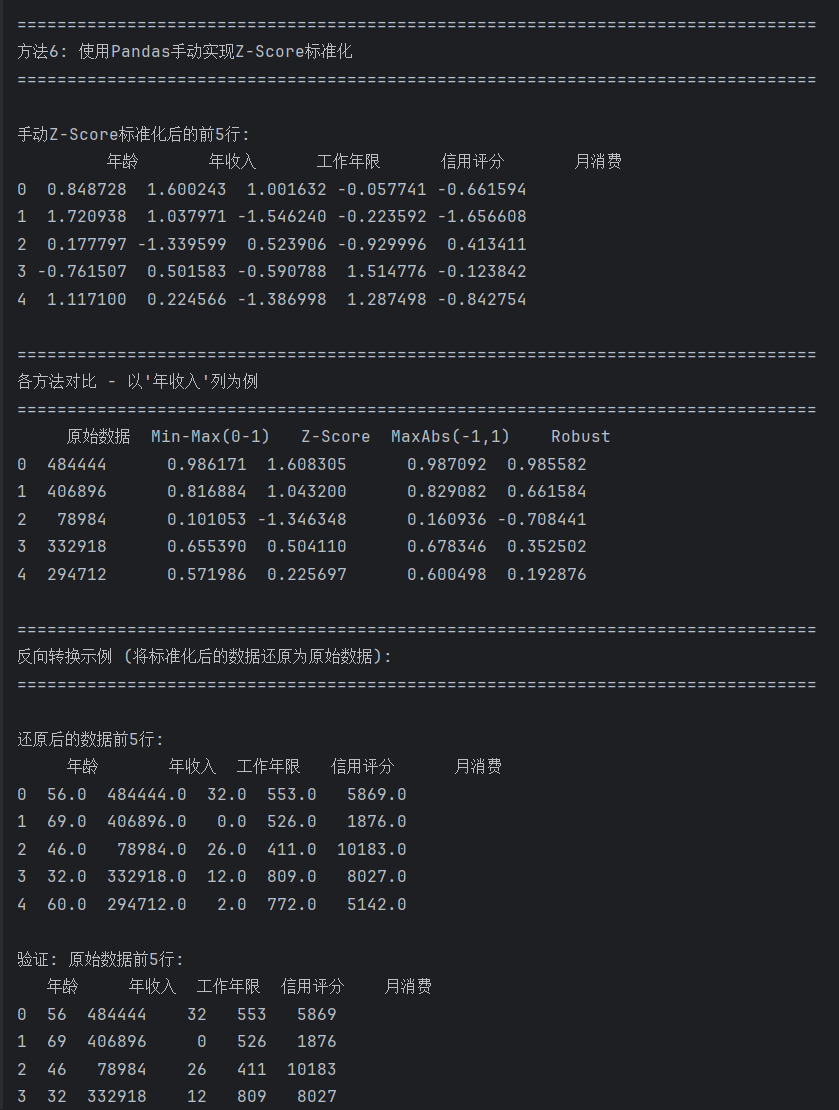
print("\n" + "=" * 80)
print("方法6: 使用Pandas手动实现Z-Score标准化")
print("=" * 80)
df_manual_standard = (df - df.mean()) / df.std()
print("\n手动Z-Score标准化后的前5行:")
print(df_manual_standard.head())
# ============================================================================
# 对比可视化准备
# ============================================================================
print("\n" + "=" * 80)
print("各方法对比 - 以'年收入'列为例")
print("=" * 80)
comparison = pd.DataFrame({
'原始数据': df['年收入'].head(),
'Min-Max(0-1)': df_minmax['年收入'].head(),
'Z-Score': df_standard['年收入'].head(),
'MaxAbs(-1,1)': df_maxabs['年收入'].head(),
'Robust': df_robust['年收入'].head()
})
print(comparison)
# ============================================================================
# 使用建议
# ============================================================================
print("\n" + "=" * 80)
print("各方法使用建议:")
print("=" * 80)
print("""
1. Min-Max归一化 (0-1缩放):
✓ 适合: 神经网络、图像处理、需要固定范围的算法
✗ 缺点: 对异常值敏感
2. Z-Score标准化:
✓ 适合: 机器学习算法(SVM、逻辑回归、KNN等)、数据呈正态分布
✗ 缺点: 对异常值敏感
3. 最大绝对值归一化:
✓ 适合: 稀疏数据、已经中心化的数据
✗ 缺点: 不改变稀疏性
4. 鲁棒缩放:
✓ 适合: 包含异常值的数据
✗ 缺点: 计算相对复杂
5. 手动实现:
✓ 适合: 简单场景、快速原型、理解原理
✗ 缺点: 功能有限、没有inverse_transform功能
""")
# ============================================================================
# 反向转换示例
# ============================================================================
print("\n" + "=" * 80)
print("反向转换示例 (将标准化后的数据还原为原始数据):")
print("=" * 80)
# 使用inverse_transform还原数据
df_restored = pd.DataFrame(
scaler_minmax.inverse_transform(df_minmax),
columns=df.columns
)
print("\n还原后的数据前5行:")
print(df_restored.head())
print("\n验证: 原始数据前5行:")
print(df.head())
print("\n是否完全一致:", df.head().equals(df_restored.head().astype(int)))

















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









