










论文地址:
https://arxiv.org/abs/1904.04971
主要思想:
卷积层是现代深度神经网络的基本构建块之一。其中一个基本假设是,数据集中的所有样本都应共享卷积核。而我们提出了一种有条件参数化的卷积(CondConv),它能针对每个样本学习专门的卷积核。将普通卷积替换为CondConv,我们可以在保持高效推理的同时,增加网络的大小和容量。我们证明,使用CondConv扩展网络可以改进多个现有卷积神经网络架构在分类和检测任务上的性能和推理成本权衡。在ImageNet分类中,我们的CondConv方法应用于EfficientNet-B0,以仅4.13亿次乘加运算实现了78.3%的准确率,达到了最先进的性能水平。
模块图: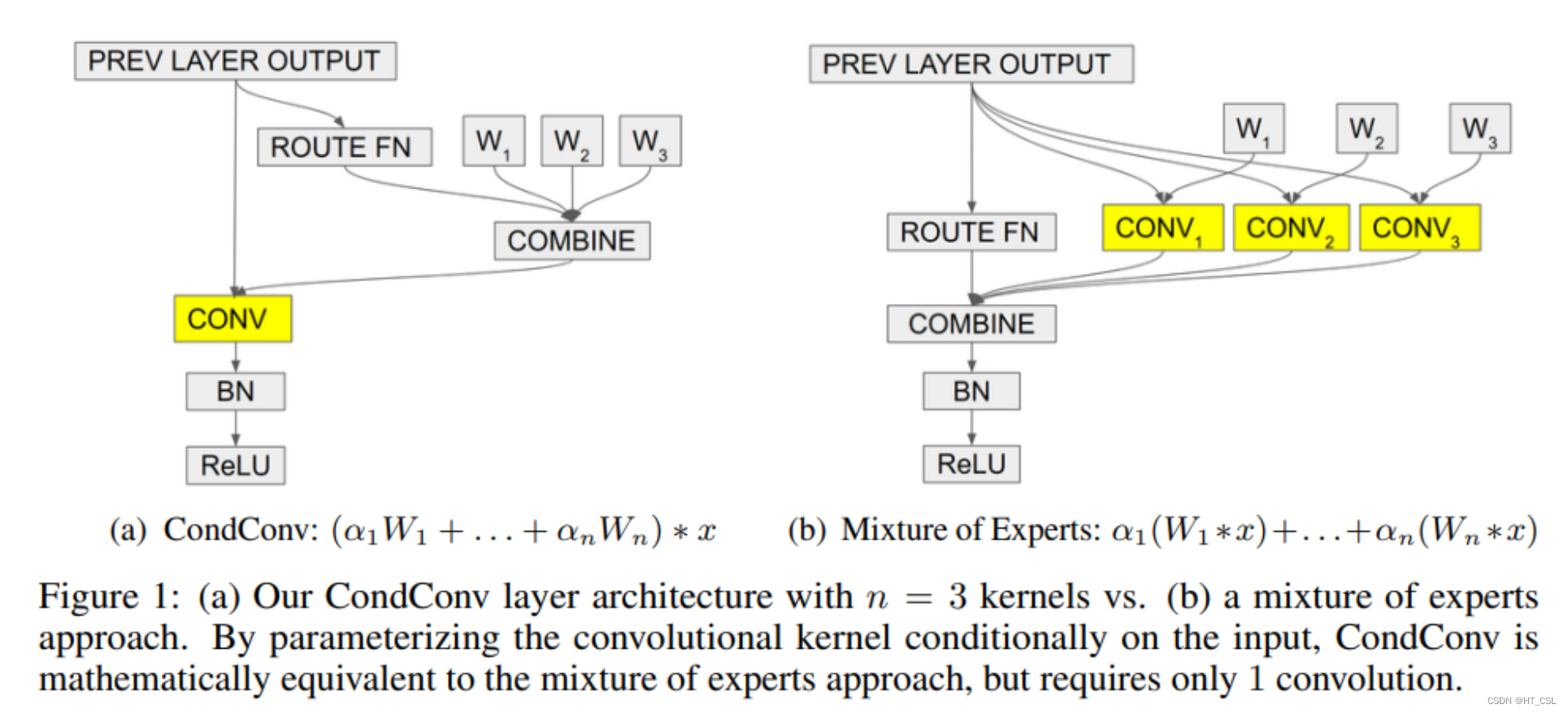
Pytorch源码:
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch.nn.modules.conv import _ConvNd
from torch.nn.modules.utils import _pair
from torch.nn.parameter import Parameter
import functools
class _routing(nn.Module):
def __init__(self, in_channels, num_experts, dropout_rate):
super(_routing, self).__init__()
# 定义路由网络中的 Dropout 层
self.dropout = nn.Dropout(dropout_rate)
# 定义路由网络中的全连接层
self.fc = nn.Linear(in_channels, num_experts)
def forward(self, x):
# 将输入张量展平
x = torch.flatten(x)
# 使用 Dropout 层进行随机失活
x = self.dropout(x)
# 通过全连接层得到路由权重
x = self.fc(x)
# 对路由权重进行 Sigmoid 激活
return torch.sigmoid(x)
class CondConv2D(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros',
num_experts=3, dropout_rate=0.2):
# 将参数转换为元组形式
kernel_size = _pair(kernel_size)
stride = _pair(stride)
padding = _pair(padding)
dilation = _pair(dilation)
super(CondConv2D, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias, padding_mode)
# 定义自适应平均池化函数
self._avg_pooling = functools.partial(F.adaptive_avg_pool2d, output_size=(1, 1))
# 初始化路由网络
self._routing_fn = _routing(in_channels, num_experts, dropout_rate)
# 定义条件卷积的权重
self.weight = Parameter(torch.Tensor(
num_experts, out_channels, in_channels // groups, *kernel_size))
# 初始化权重参数
self.reset_parameters()
def _conv_forward(self, input, weight):
if self.padding_mode != 'zeros':
return F.conv2d(F.pad(input, self._padding_repeated_twice, mode=self.padding_mode),
weight, self.bias, self.stride,
_pair(0), self.dilation, self.groups)
return F.conv2d(input, weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
def forward(self, inputs):
# 获取输入张量的批量大小
b, _, _, _ = inputs.size()
res = []
for input in inputs:
# 在输入张量的维度上增加一个维度
input = input.unsqueeze(0)
# 对输入张量进行自适应平均池化
pooled_inputs = self._avg_pooling(input)
# 使用路由网络得到路由权重
routing_weights = self._routing_fn(pooled_inputs)
# 计算加权后的卷积核
kernels = torch.sum(routing_weights[:, None, None, None, None] * self.weight, 0)
# 进行条件卷积操作
out = self._conv_forward(input, kernels)
res.append(out)
# 将结果拼接在一起并返回
return torch.cat(res, dim=0)
def test():
# 测试 CondConv2D 模块是否正常工作
cond_conv = CondConv2D(in_channels=3, out_channels=64, kernel_size=3, padding=1)
input_tensor = torch.randn(2, 3, 32, 32) # 输入张量的批量大小为 2,尺寸为 28x28
output_tensor = cond_conv(input_tensor)
print("Output tensor shape:", output_tensor.shape)
if __name__ == "__main__":
test()















 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









