










原文地址:[2403.01123] ELA: Efficient Local Attention for Deep Convolutional Neural Networks (arxiv.org)
与SE、CA注意力机制的区别:
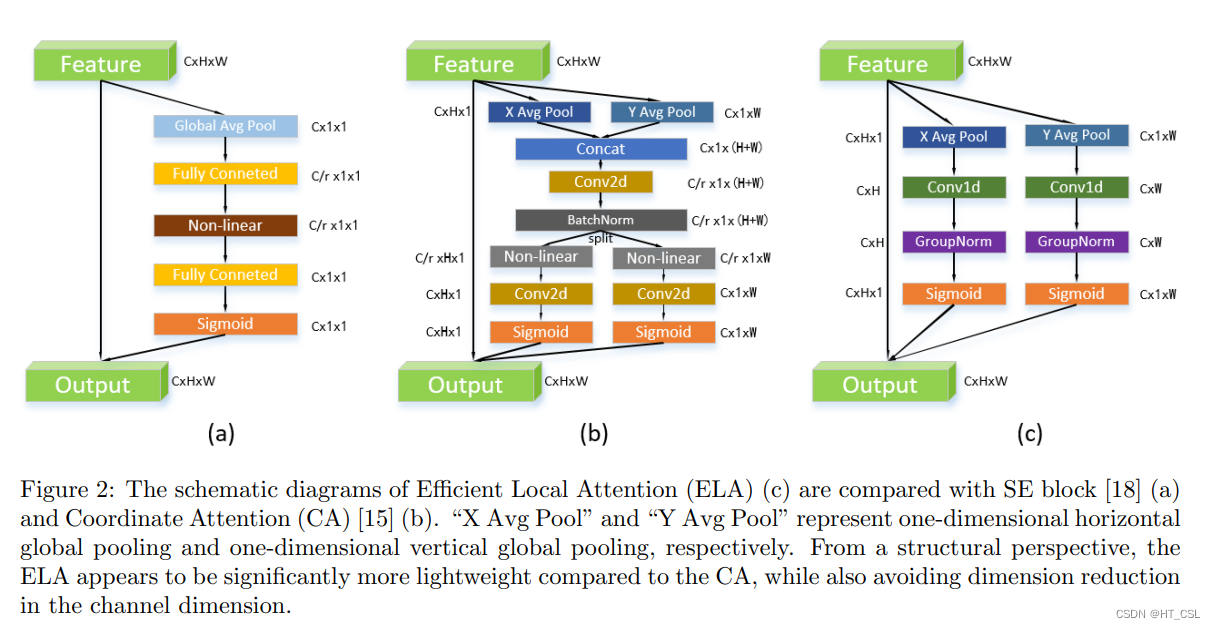
ELA通过在空间维度采用带状池化来提取水平和垂直方向的特征向量,维持细长的核形状以捕捉远距离的依赖关系,同时避免不相关区域对标签预测的干扰。这样做能够在每个方向上生成富有信息的目标位置特征。ELA独立处理这些方向的特征向量以进行注意力预测,随后通过乘积操作将它们整合,确保了感兴趣区域的精确位置信息。
代码模块:
import torch
import torch.nn as nn
class EfficientLocalizationAttention(nn.Module):
def __init__(self, channel, kernel_size=7):
super(EfficientLocalizationAttention, self).__init__()
self.pad = kernel_size // 2
self.conv = nn.Conv1d(channel, channel, kernel_size=kernel_size, padding=self.pad, groups=channel, bias=False)
self.gn = nn.GroupNorm(16, channel)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
# 处理高度维度
x_h = torch.mean(x, dim=3, keepdim=True).view(b, c, h)
x_h = self.sigmoid(self.gn(self.conv(x_h))).view(b, c, h, 1)
# 处理宽度维度
x_w = torch.mean(x, dim=2, keepdim=True).view(b, c, w)
x_w = self.sigmoid(self.gn(self.conv(x_w))).view(b, c, 1, w)
print(x_h.shape, x_w.shape)
# 在两个维度上应用注意力
return x * x_h * x_w
# 示例用法 ELABase(ELA-B)
if __name__ == "__main__":
# 创建一个形状为 [batch_size, channels, height, width] 的虚拟输入张量
dummy_input = torch.randn(2, 64, 32, 32)
# 初始化模块
ela = EfficientLocalizationAttention(channel=dummy_input.size(1), kernel_size=7)
# 前向传播
output = ela(dummy_input)
# 打印出输出张量的形状,它将与输入形状相匹配。
print(f"输出形状: {output.shape}")
"""
为了在考虑参数数量的同时优化ELA的性能,作者引入了四种方案: ELA-Tiny(ELA-T),ELABase(ELA-B),ELA-Smal(ELA-S)和ELA-Large(ELA-L)。
1.ELA-T的参数配置定义为 kernel size=5,groups =in channels, num group=32:
2.ELA-B的参数配置定义为 kernel size=7,groups =in_channels, num_group =16:
3.ELA-S的参数配置为 kernel size=5,groups=in_channels/8, num_group=16。
4.ELA-L的参数配置为 kernel_size=7,groups=in _channels /8,num_group=16 。
"""













 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









