







题目:CondConv: Conditionally Parameterized Convolutions for Efficient Inference
paper:paper
code:code
目录
前言
该文是谷歌大神
Quov V.Le出品,一种条件卷积,我更愿称之为动态卷积。 卷积是当前CNN网络的基本构成单元之一,它的一个基本假设是:卷积参数对所有样例共享。作者提出一种条件参数卷积,该卷积是一种即插即用的模块,它可以为每个样例学习一个特定的卷积核参数,通过替换标准卷积,CondConv可以提升模型的尺寸与容量,同时保持高效推理。作者证实:相比已有标准卷积网络,基于CondConv的网络在精度提升与推理耗时方面取得了均衡(即精度提升,但速度持平)。在ImageNet分类问题中,基于CondConv的EfficientNet-B0取得了78.3%的精度且仅有413M计算量。主要贡献:条件计算、集成技术、注意力机制三者间的巧妙结合。
CondConv是什么?
CondConv是一种条件参数卷积,或称为动态,该卷积是一种即插即用的模块,它可以为每个样例学习一个特定的卷积核参数,通过替换标准卷积,CondConv可以提升模型的尺寸与容量,同时保持高效推理。
CondConv解决了什么问题?
CNN在诸多计算机视觉任务中取得了前所未有的成功,但其性能的提升更多源自模型尺寸与容量的提升以及更大的数据集。模型的尺寸提升进一步加剧了计算量的提升,进一步加大优秀模型的部署难度。
现有CNN的一个基本假设:相同的卷积核用于数据集中的每一个实例(即卷积核是固定不变的)。这就导致:为提升模型的容量,就需要加大模型的参数、深度、通道数,进一步导致模型的计算量加大、部署难度提升。由于上述假设以及终端移动设备部署需求,当前高效网络往往具有较少的参数量。然而,越来越多的计算机视觉应用中(如终端视频处理、自动驾驶),对模型实时性要求高,且不受参数数量的限制,对参数量要求较低。这篇文章目标就是,设计出更好的服务于这些应用的模型。即延迟低。
CondConv做了怎样的工作?
作者提出一种条件参数卷积用于解决上述问题,它通过输入计算卷积核参数打破了传统的静态卷积特性。特别的,作者将CondConv中的卷积核参数化为多个专家知识的线性组合(其中,,...,
是通过梯度下降学习的加权系数):
![]() 。为更有效的提升模型容量,在网络设计过程中可以提升专家数量,这比提升卷积核尺寸更为高效,因为卷积核需要用于输入(比如一个feature map)中的许多不同位置,而专家知识只需要进行一次组合,这就可以在提升模型容量的同时保持高效推理。
。为更有效的提升模型容量,在网络设计过程中可以提升专家数量,这比提升卷积核尺寸更为高效,因为卷积核需要用于输入(比如一个feature map)中的许多不同位置,而专家知识只需要进行一次组合,这就可以在提升模型容量的同时保持高效推理。
用了怎样的方法?
在常规卷积中,其卷积核参数经训练确定且对所有输入样本“一视同仁”;而在CondConv中,卷积核参数参数通过对输入进行变换得到,通过下述公式得到kernal的参数:
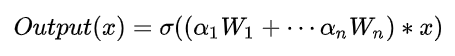
其中x为上一个layer的输出,n 表示这一层Condconv Layer有n 个expert(expert就是该层的卷积核W),表示激活函数,
一个样本依赖加权参数。在
CondConv中,每个卷积核具有与标准卷积核参数相同的维度。
常规卷积的容量提升依赖于卷积核尺寸与通道数的提升,将进一步提升的网络的整体计算;而CondConv则只需要在执行卷积计算之前通过多个专家对输入样本计算加权卷积核。关键的是,每个卷积核只需计算一次并作用于不同位置即可。这意味着:通过提升专家数据量达到提升网络容量的目的,而代码仅仅是很小的推理耗时:每个额外参数仅需一次乘加。
所以一个CondConv层的卷积核参数的由来,就是通过上述的线性组合公式。整个流程可以概括为:依赖于输入x ,在卷积操作之前,通过routing函数计算出每一个expert前面的系数
,再通过线性组合,得到CondConv层最终的kernal,最后与输入x 做卷积,并进行activation。在这里,routing weight的计算公式如下:
![]()
对于输入x xx,首先做GlobalAveragePooling,随后右乘一个矩阵R(该矩阵的目的是将维度映射到n个expert上面,以实现后续的线性组合),最后通过sigmoid将每一个维度上的权值规约到[0,1]区间。因此,根据输入x xx的不同,就会得到不同的routing weight向量,进而CondConv层的kernal也各有差异。
CondConv的流程如下图(a)所示:

上图(a)中所示的CondConv与图(b)都是将routing weight与expert做线性组合,但还是存在一些区别:CondConv只需要做一次卷积,而图(b)的方式要做n次(expert的数目)卷积。我们知道,直观上expert数目越多,模型的performace越好。因此图(a)的计算量会比图(b)少很多,计算开销大大减少,体现了CondConv这种设计的优越性。
所提CondConv可以对现有网络中的标准卷积进行替换,它同时适用于深度卷积与全连接层。
实验结果
作者在ImageNet分类任务上评估了所提CondConv的性能,相对性能对比见下表。
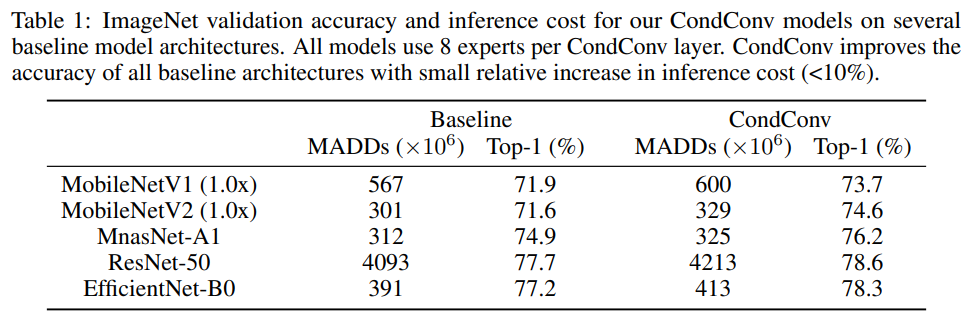
此外,作者还对比提升专家数量对模型性能的影响。

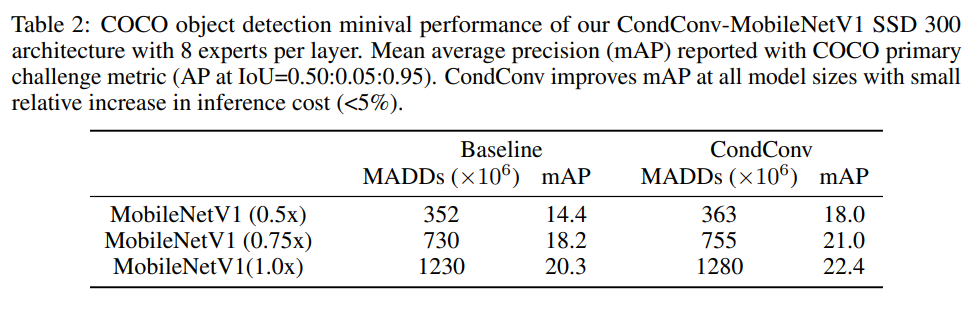
除了分类任务,作者还在COCO检测任务上对所提CondConv进行对比分析,见下图。
结论
总而言之,作者在静态卷积之外提出一种条件参数卷积:CondConv。它打破了静态卷积的假设:卷积核对所有输入“一视同仁”。这为提升模型容量同时保持高效推理打开了一个新的方向:提升卷积核生成函数的尺寸与复杂度。由于卷积核参数仅需计算一次,相比卷积计算,这些额外的计算量可以忽略。也就是说:提升卷积核生成的计算量要远比添加更多卷积或更多通道数高效。CondConv同样突出一个重要的研究问题:如何更好的覆盖、表达与利用样本的相关性以提升模型性能。
特别指出:
该模型虽然好用,但训起来稍微有些麻烦(麻烦指的是训练过程会比较慢,超参应该还是比较好调的),有两种训练方式——
- 使用batch_size=1的训练,每次前传都先组合权重再进行卷积
- 使用batch_size>1的训练,每次前传都直接分别卷积,最后在做组合
两种计算过程基本是等效的,但考虑到深度学习框架大多对大batch的训练过程有比较充分的优化,所以作者建议当experts数量不多余4时,采用方法2,超过4之后采用方法1.不过值得一提的是,BN层在batch_size比较小时是不利的,此时最好改用其他Normalization层。
要点总结(详细版)
以下内容摘自一名优秀博主的博客,内容很好,不忍改动,具体见博客。
CondConv解决的问题:在卷积网络中,使用常规卷积进行构建网络时候,有如下假设:所有的样本共享卷积网络中的卷积参数.因此,为了提升模型的容量,就需要增加网络的参数,深度,通道数,这将导致模型的计算量和参数量增加,模型部署难度大.然而,在某些计算机视觉应用中,要求模型的实时性高,这就需要模型拥有较低的参数量和计算量。
CondConv的思想:为了打破传统卷积的特性,作者将CondConv中卷积核参数化为多个专家知识的线性组合(其中,a1,a2,a3,...an是通过梯度下降法学习的权重系数):(a1W1+a2W2+...+anWn)*x,x是输入样本.可以通过提升专家的数量来提升模型的容量,这比提升卷积核的尺寸更有效,同时专家知识只需要一次线性组合,就可以提升模型容量的同时保持高效的推理。
CondConv结构
结构1,如下图,首先它采用更细粒度的集成方式,每一个卷积层都拥有多套权重,卷积层的输入分别经过不同的权重卷积之后组合输出,缺点是但这计算量依旧很大。

结构2,如图2,为了解决图1计算大问题,作者提出既然输入相同,卷积是一种线性计算,COMBINE也是一个线性计算(比如加权求和),作者将多套权重加权组合之后,只做一次卷积就能完成相当的效果!计算量相比上图,大大降低。

CondConv代码实现流程图(Tensorflow)

CondConv的Tensorflow具体实现流程如上图,首先输入是X,大小是(N,H,W,C),N表示数据Batch的大小,H和W表示输入图片的高和宽,C表示输入图片的通道数,之后有两条输出线,先介绍右边输出线,之后介绍左边输出线,最后对各自的输出进行整合.其中(h,w,cin,cout)表示卷积核大小,h和w分别表示卷积核的高和宽,cin,cout分别表示卷积核的输入和输出通道数.
右边线作用:计算输入样本对用的各自的卷积核的权重,具体流程如下:
- 对输入X,进行GAP操作(GlobalAveragePooling2D)操作,具体在维度(H,W),输出大小为(N,C);
- 之后经过FC层,学习不同输入样本对用num_experts个卷积的各自的权重系数,输出为(N,num_experts)
- 采用Sigmoid归一化到(0,1)之间,输出为(N,num_experts)
- 将3输出权重系数和num_experts个卷积核权重通过矩阵的相乘,赋予到相应的卷积上,输出各个样本对应加权后的卷积核权重,输出大小为:(N,h*w*cin,cout)
- 将4中的输出在N维度进行Split操作,得到各个样本对应加权后卷积核的权重
各个样本对应不同卷积权重:
self._avg_pooling = tf.keras.layers.GlobalAveragePooling2D(
data_format=self._global_params.data_format)
self._routing_fn = tf.layers.Dense(
self._condconv_num_experts, activation=tf.nn.sigmoid)
# (batch_size, channels)
pooled_inputs = self._avg_pooling(inputs)
# (batch_size,_condconv_num_experts)
routing_weights = self._routing_fn(pooled_inputs)左边线作用:对输入X依次通过对应加权输出的卷积核权重,完成CondConv:
- 将X在N维度进行split操作
- 将1中输出结果和右边线输出对应卷积权重进行卷积操作,之后进行Concat,完成CondConv操作
CondConv实现
class CondConv2D(tf.keras.layers.Conv2D):
"""2D conditional convolution layer (e.g. spatial convolution over images).
Attributes:
filters: Integer, the dimensionality of the output space (i.e. the number of
output filters in the convolution).
kernel_size: An integer or tuple/list of 2 integers, specifying the height
and width of the 2D convolution window. Can be a single integer to specify
the same value for all spatial dimensions.
num_experts: The number of expert kernels and biases in the CondConv layer.
strides: An integer or tuple/list of 2 integers, specifying the strides of
the convolution along the height and width. Can be a single integer to
specify the same value for all spatial dimensions. Specifying any stride
value != 1 is incompatible with specifying any `dilation_rate` value != 1.
padding: one of `"valid"` or `"same"` (case-insensitive).
data_format: A string, one of `channels_last` (default) or `channels_first`.
The ordering of the dimensions in the inputs. `channels_last` corresponds
to inputs with shape `(batch, height, width, channels)` while
`channels_first` corresponds to inputs with shape `(batch, channels,
height, width)`. It defaults to the `image_data_format` value found in
your Keras config file at `~/.keras/keras.json`. If you never set it, then
it will be "channels_last".
dilation_rate: an integer or tuple/list of 2 integers, specifying the
dilation rate to use for dilated convolution. Can be a single integer to
specify the same value for all spatial dimensions. Currently, specifying
any `dilation_rate` value != 1 is incompatible with specifying any stride
value != 1.
activation: Activation function to use. If you don't specify anything, no
activation is applied
(ie. "linear" activation: `a(x) = x`).
use_bias: Boolean, whether the layer uses a bias vector.
kernel_initializer: Initializer for the `kernel` weights matrix.
bias_initializer: Initializer for the bias vector.
kernel_regularizer: Regularizer function applied to the `kernel` weights
matrix.
bias_regularizer: Regularizer function applied to the bias vector.
activity_regularizer: Regularizer function applied to the output of the
layer (its "activation")..
kernel_constraint: Constraint function applied to the kernel matrix.
bias_constraint: Constraint function applied to the bias vector.
Input shape:
4D tensor with shape: `(samples, channels, rows, cols)` if
data_format='channels_first'
or 4D tensor with shape: `(samples, rows, cols, channels)` if
data_format='channels_last'.
Output shape:
4D tensor with shape: `(samples, filters, new_rows, new_cols)` if
data_format='channels_first'
or 4D tensor with shape: `(samples, new_rows, new_cols, filters)` if
data_format='channels_last'. `rows` and `cols` values might have changed
due to padding.
"""
def __init__(self,
filters,
kernel_size,
num_experts,
strides=(1, 1),
padding='valid',
data_format=None,
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
super(CondConv2D, self).__init__(
filters=filters,
kernel_size=kernel_size,
strides=strides,
padding=padding,
data_format=data_format,
dilation_rate=dilation_rate,
activation=activation,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=bias_regularizer,
activity_regularizer=activity_regularizer,
kernel_constraint=kernel_constraint,
bias_constraint=bias_constraint,
**kwargs)
if num_experts < 1:
raise ValueError('A CondConv layer must have at least one expert.')
self.num_experts = num_experts
if self.data_format == 'channels_first':
self.converted_data_format = 'NCHW'
else:
self.converted_data_format = 'NHWC'
def add_weight(self,
name,
shape,
dtype=None,
initializer=None,
regularizer=None,
trainable=True,
constraint=None):
"""Adds a weight variable to the layer.
# Arguments
name: String, the name for the weight variable.
shape: The shape tuple of the weight.
dtype: The dtype of the weight.
initializer: An Initializer instance (callable).
regularizer: An optional Regularizer instance.
trainable: A boolean, whether the weight should
be trained via backprop or not (assuming
that the layer itself is also trainable).
constraint: An optional Constraint instance.
# Returns
The created weight variable.
"""
initializer = initializers.get(initializer)
if dtype is None:
dtype = K.floatx()
weight = K.variable(initializer(shape), dtype=dtype, name=name)
if regularizer is not None:
self.add_loss(regularizer(weight))
if constraint is not None:
self.constraints[weight] = constraint
if trainable:
self._trainable_weights.append(weight)
else:
self._non_trainable_weights.append(weight)
return weight
def build(self, input_shape):
if len(input_shape) != 4:
raise ValueError(
'Inputs to `CondConv2D` should have rank 4. '
'Received input shape:', str(input_shape))
input_shape = tf.TensorShape(input_shape)
channel_axis = self._get_channel_axis()
if input_shape.dims[channel_axis].value is None:
raise ValueError('The channel dimension of the inputs '
'should be defined. Found `None`.')
input_dim = int(input_shape[channel_axis])
self.kernel_shape = self.kernel_size + (input_dim, self.filters)
kernel_num_params = 1
for kernel_dim in self.kernel_shape:
kernel_num_params *= kernel_dim
condconv_kernel_shape = (self.num_experts, kernel_num_params)
# output:(self.num_experts, kernel_num_params)
self.condconv_kernel = self.add_weight(
name='condconv_kernel',
shape=condconv_kernel_shape,
initializer=get_condconv_initializer(self.kernel_initializer,
self.num_experts,
self.kernel_shape),
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint,
trainable=True,
dtype=self.dtype)
if self.use_bias:
self.bias_shape = (self.filters,)
condconv_bias_shape = (self.num_experts, self.filters)
# output:(self.num_experts, self.filters)
self.condconv_bias = self.add_weight(
name='condconv_bias',
shape=condconv_bias_shape,
initializer=get_condconv_initializer(self.bias_initializer,
self.num_experts,
self.bias_shape),
regularizer=self.bias_regularizer,
constraint=self.bias_constraint,
trainable=True,
dtype=self.dtype)
else:
self.bias = None
self.input_spec = tf.layers.InputSpec(
ndim=self.rank + 2, axes={channel_axis: input_dim})
self.built = True
def call(self, inputs, routing_weights):
# Compute example dependent kernels
# self.condconv_kernel:(self.num_experts, kernel_num_params)
kernels = tf.matmul(routing_weights, self.condconv_kernel)
batch_size = inputs.shape[0].value
inputs = tf.split(inputs, batch_size, 0)
kernels = tf.split(kernels, batch_size, 0)
# Apply example-dependent convolution to each example in the batch
outputs_list = []
for input_tensor, kernel in zip(inputs, kernels):
kernel = tf.reshape(kernel, self.kernel_shape)
outputs_list.append(
tf.nn.convolution(
input_tensor,
kernel,
strides=self.strides,
padding=self._get_padding_op(),
dilations=self.dilation_rate,
data_format=self.converted_data_format))
outputs = tf.concat(outputs_list, 0)
if self.use_bias:
# Compute example-dependent biases
biases = tf.matmul(routing_weights, self.condconv_bias)
outputs = tf.split(outputs, batch_size, 0)
biases = tf.split(biases, batch_size, 0)
# Add example-dependent bias to each example in the batch
bias_outputs_list = []
for output, bias in zip(outputs, biases):
bias = tf.squeeze(bias, axis=0)
bias_outputs_list.append(
tf.nn.bias_add(output, bias,
data_format=self.converted_data_format))
outputs = tf.concat(bias_outputs_list, 0)
if self.activation is not None:
return self.activation(outputs)
return outputs
def get_config(self):
config = {'num_experts': self.num_experts}
base_config = super(CondConv2D, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def _get_channel_axis(self):
if self.data_format == 'channels_first':
return 1
else:
return -1
def _get_padding_op(self):
if self.padding == 'causal':
op_padding = 'valid'
else:
op_padding = self.padding
if not isinstance(op_padding, (list, tuple)):
op_padding = op_padding.upper()
return op_padding结论
CondConv打破了静态卷积的假设:卷积核对所有输入“一视同仁”。这为提升模型容量同时保持高效推理打开了一个新的方向:提升卷积核生成函数的尺寸与复杂度。由于卷积核参数仅需计算一次,相比卷积计算,这些额外的计算量可以忽略。也就是说:提升卷积核生成的计算量要远比添加更多卷积或更多通道数高效。



参考
动态卷积|CondConv - 知乎 (zhihu.com)















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









