







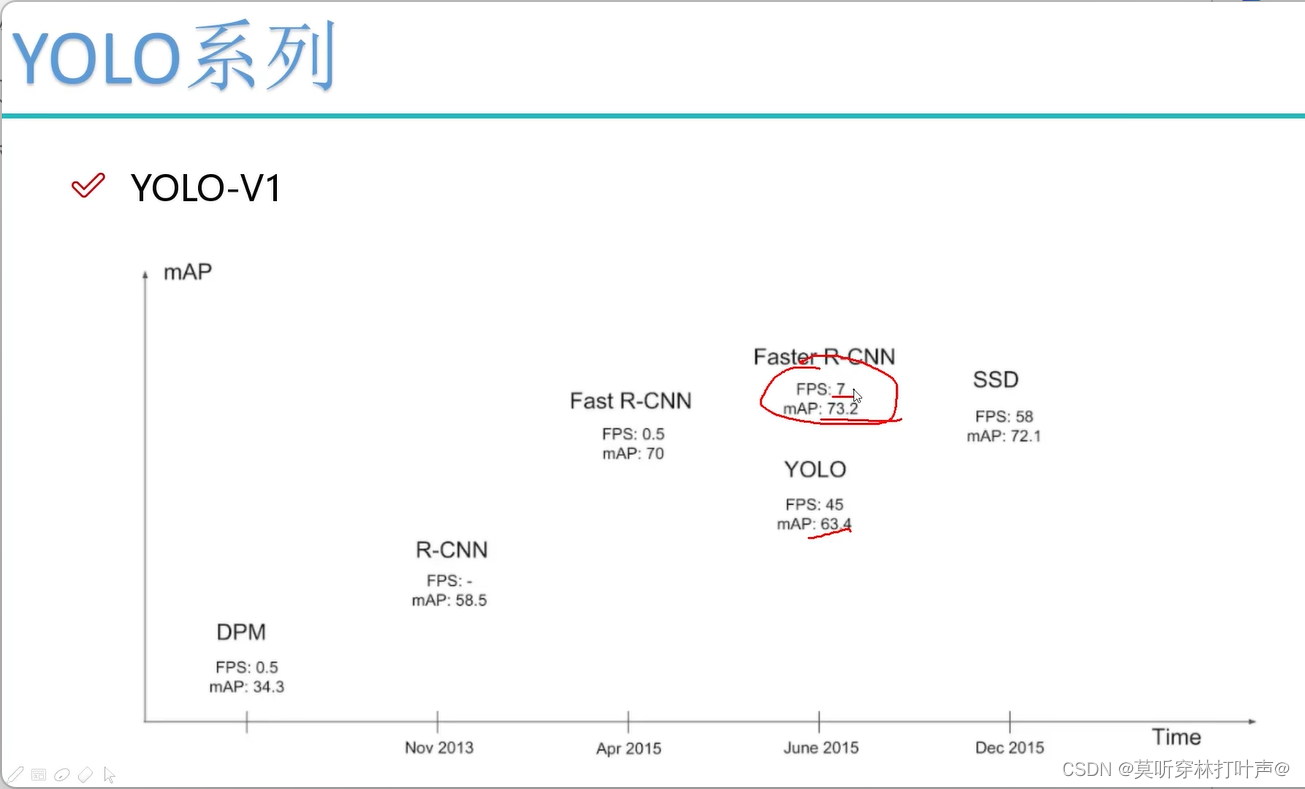
一、YOLO系列V1
- 经典的one-stage方法,You Only Look Once
- 将检测问题转化成回归问题,一个CNN搞定
- 可以对视频进行实时监测
YOLO系列的速度更快,我们检测的物体很简单,进行取舍,舍弃了一些精度。
V1核心思想
现在要预测一张图片中有哪些物体,左边的图像上有狗、自行车、面包车。
输入s×s的图片,假设7×7个格子,每个格子都负责预测落在自己位置上的是什么东西。格子上的中心点进行预测。
现在这个红色的点进行预测,它也不知道狗长什么样子,长宽是多少,所以先给一些经验值,就是图上黄色的两个框(h1,w1;h2,w2)。(YOLOV1给了两个)。经验值不准,但是也可以参考,将经验好的框进行微调,相当于一个回归任务,h怎么变,w怎么变。初始的点在哪(V1的版本初始点是中心点)。
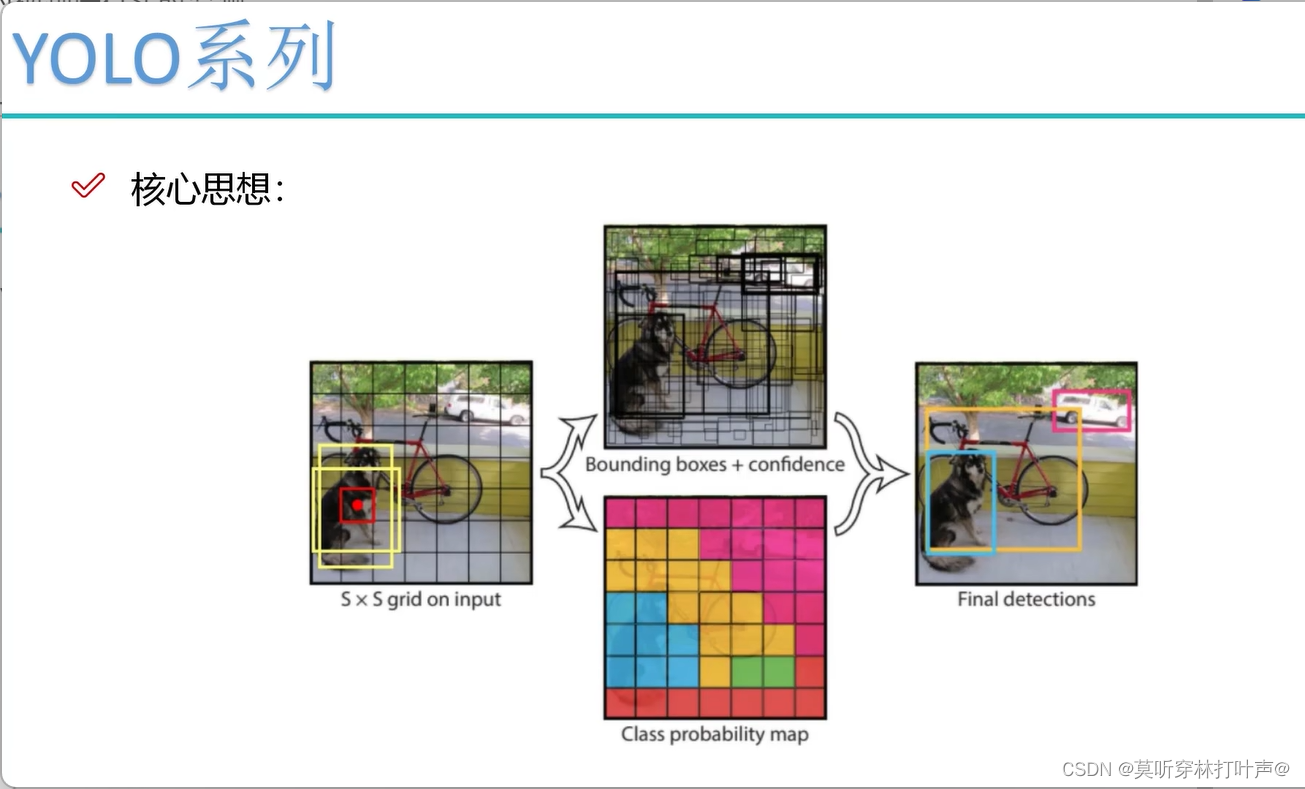
- 总结:有了输入数据,分成很多的小格子,每个小格子产生两种的候选框B值(V1版本),看看两种候选框和真实值匹配的怎么样,算IOU的值,哪个大,哪个候选框就好,就微调谁。会计算出来很多很多的候选框(因为每一个格子都要计算)。计算出bounding box和confidence,即为我们在预测的时候不仅要预测x,y,w,h,还要confidence(当前这个小格子预测出物体的概率)。置信度小的过滤掉。
- 输入s×s的图片
- 对置信度高的框、IOU高的框进行微调
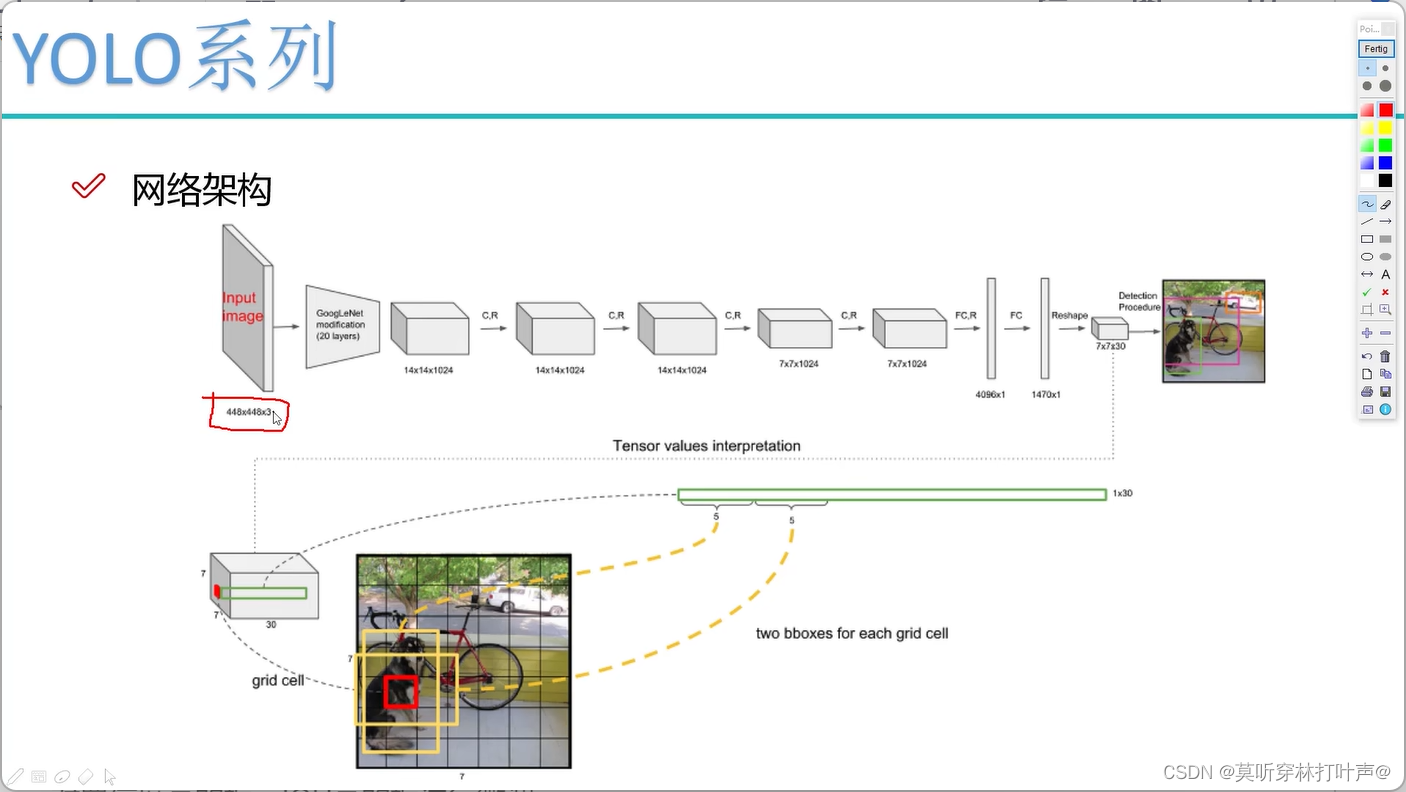
V1网络架构
卷积神经网络的输入图像是固定的,这个和卷积层没有关系,是因为全连接层是定死的。全连接层前面要固定好feature map的大小。
- 输入图像是固定值,是V1版本的局限
- 用一些卷积神经网络提取特征,V1版本用的是GoogLeNet,不关心,后面用效果更好的特征提取网络
- 得到一个7×7×1024的特征图
- 第一个全连接层,转化成4096×1
- 第二个全连接层,转化成1470×1
- reshape成7×7×30,是我们最后要的
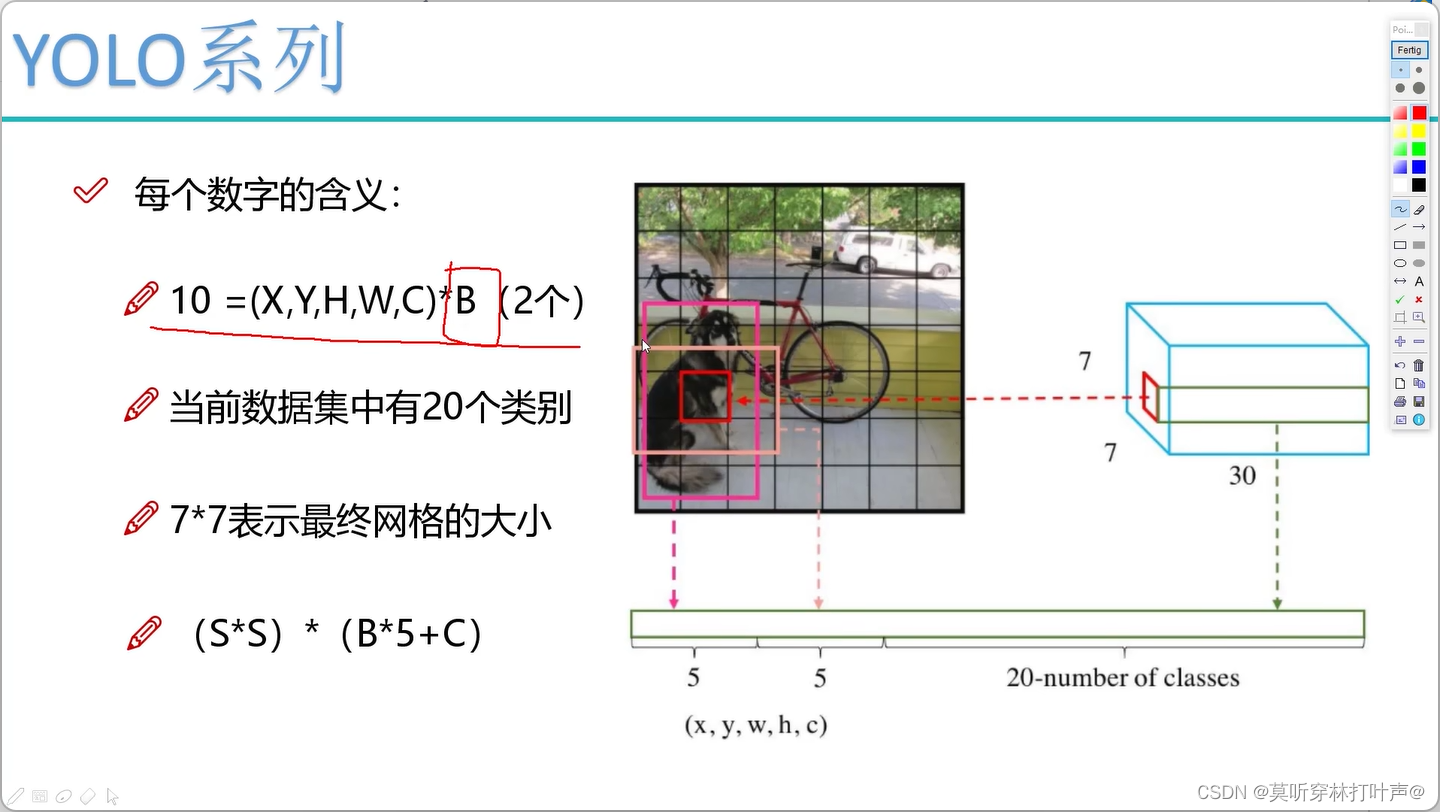
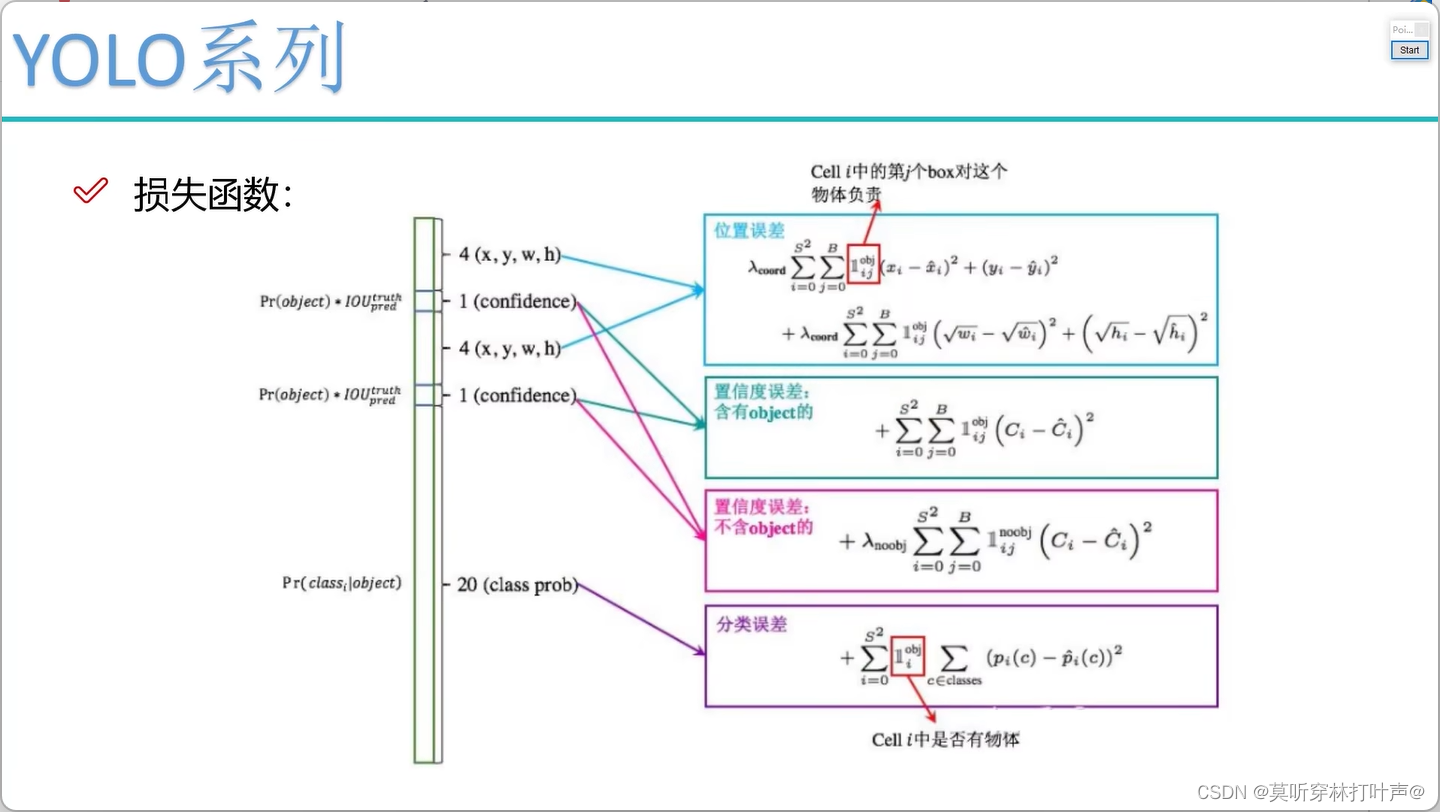
图片是7×7的格子,每个格子有30个值。
每个格子两种框,B1:x1,y1,w1,h1(归一化后的坐标值)B2:x2,y2,w2,h2
还有置信度,C1,C2
20个分类
加起来共30
求矩形框是回归任务,后面还有20分类任务

B是先验框的个数;C是类别。
损失函数
- 预测的值(回归):x,y,w,h,要让这几个的值和真实值的误差越小越好
- 使用位置误差
- confidence(预测是物体的):越接近1越好
- confidence(预测是背景的):越接近0越好,有权重项,因为背景多,给个0.1的权重,告诉网络背景不重要
- 分类:交叉熵损失函数
NMS非极大值抑制(测试时)
按照置信度排序,把最大的留下。

V1版本中的问题:
小物体检测不好
重合在一起的物体很难检测到
多标签效果不好

















 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











