







YOLO将物体检测作为一个回归问题进行求解,输入图像经过一次inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。
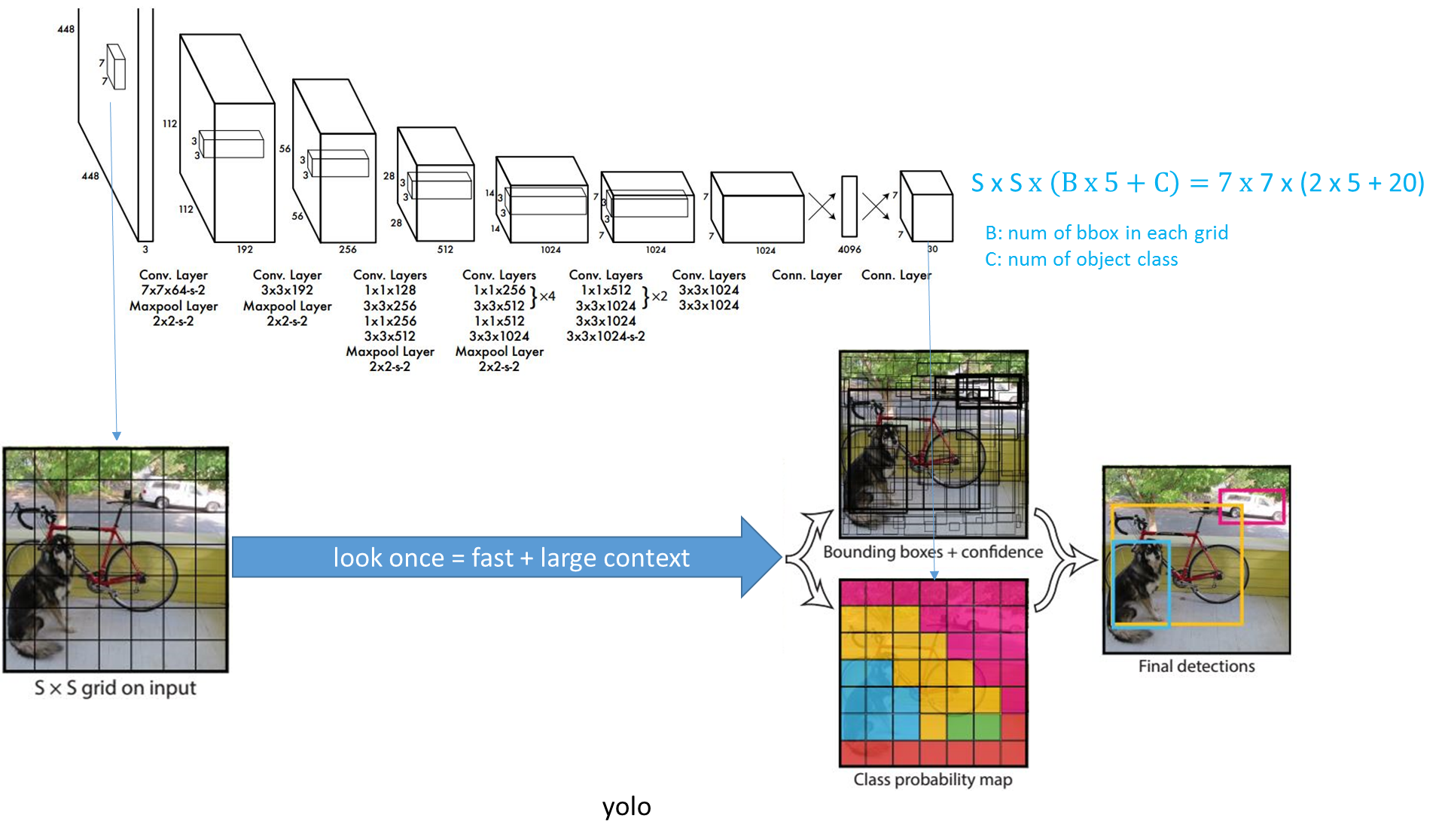
YOLO检测网络包括24个卷积层和2个全连接层,如下图所示。(YOLO网络借鉴了GoogLeNet分类网络结构,不同的是,YOLO未使用inception-module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+ 3x3卷积层简单替代。)

(1) 将原图划分为SxS的网格。如果一个目标的中心落入某个格子,这个格子就负责检测该目标。
(2) 每个网格要预测B个bounding boxes,以及C个类别概率Pr(classi|object)。
在YOLO中,每个格子只有一个C类别,即相当于忽略了B个bounding boxes,每个格子只判断一次类别,这样做非常简单粗暴。

(3) 每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有目标的置信度和这个bounding box预测的有多准两重信息:
![]()
如果有目标落中心在格子里Pr(Object)=1;否则Pr(Object)=0。 第二项是预测的bounding box和实际的ground truth之间的IOU.
每个bounding box都包含了5个预测量:(x, y, w, h, confidence),其中(x, y)代表预测box相对于格子的中心,(w, h)为预测box相对于图片的width和height比例,confidence就是上述置信度。需要说明,这里的x, y, w和h都是经过归一化的.
(4) 由于输入图像被分为SxS网格,每个网格包括5个预测量:(x, y, w, h, confidence)和一个C类,所以网络输出是SxSx(5xB+C)大小
训练:
Loss = λcoord * 坐标预测误差 +(含object的box confidence预测误差 + λnoobj * 不含object的box confidence预测误差)
+ 类别预测误差

(1) bounding box的(x, y, w, h)的坐标预测误差。
检测算法的实际使用中,一般都有这种经验:对不同大小的bounding box预测中,相比于大box大小预测偏一点,小box大小测偏一点肯定更不能被忍受。所以在Loss中同等对待大小不同的box是不合理的。为了解决这个问题,作者用了一个比较取巧的办法,即对w和h求平方根进行回归。从后续效果来看,这样做很有效,但是也没有完全解决问题。
(2) bounding box的confidence预测误差
由于绝大部分网格中不包含目标,导致绝大部分box的confidence=0,所以在设计confidence误差时同等对待包含目标和不包含目标的box也是不合理的,否则会导致模型不稳定。作者在不含object的box的confidence预测误差中乘以惩罚权重λnoobj=0.5。
除此之外,同等对待4个值(x, y, w, h)的坐标预测误差与1个值的conference预测误差也不合理,所以作者在坐标预测误差误差之前乘以权重λcoord=5
(3) 分类预测误差
缩进即每个box属于什么类别,需要注意一个网格只预测一次类别,即默认每个网格中的所有B个bounding box都是同一类。

(1) 对于bounding box的宽和高做如下normalization,使得输出宽高介于0~1:
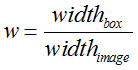
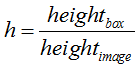
(2) 使用(row, col)网格的offset归一化bounding box的中心坐标:
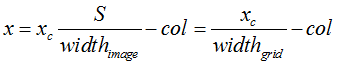
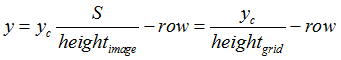
x,y为当前坐标相对于格子左上角点的坐标。
测试:
在检测目标的时候,每个网格预测的类别条件概率和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:
![]()
等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。

非极大值抑制(NMS)
- 将所有框的得分排序,选中最高分及其对应的框;
- 遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除;
- 从未处理的框中继续选一个得分最高的,重复上述过程。
优缺点
- 优点:
- 缺点:
参考:https://www.zybuluo.com/rianusr/note/1417734
原文:https://arxiv.org/abs/1506.02640















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}