







文章目录
一、vector容器
底层数据结构是动态开辟的数组,每次以原来空间大小的2倍进行扩容
使用前需要包含头文件:#include <vector>
容器中对象的构造析构,内存的开辟释放,是通过空间配置器allocator实现:allocate(内存开辟)、deallocate(内存释放)、construct(对象构造)、destroy(对象析构)
使用方法:
vector<int> vec;
增加:
vec.push_back(20);,在容器末尾增加一个元素,时间复杂度O(1),有可能会导致容器扩容vec.insert(it, 20);,在迭代器it指向的位置增加一个元素,时间复杂度O(n),有可能会导致容器扩容
删除:
vec.pop_back();,在容器末尾删除一个元素,时间复杂度O(1)vec.erase(it);,删除迭代器it指向的元素,时间复杂度O(n)
查询:
- 提供了
operator[]重载函数,数组下标的随机访问,例如vec[5],时间复杂度O(1) iterator,迭代器进行遍历,一定要考虑迭代器失效问题find,for_each等泛型算法- C++11提供的语法糖
foreach,其实就是通过迭代器来实现的
注意:对容器进行连续插入或者删除操作(insert/erase),一定要更新迭代器,否则第一次insert或者erase之后,迭代器就失效了,失效问题详见这里
常用方法:
size();,返回容器底层有效元素的个数empty();,判断容器是否为空reserve();,为vector预留空间,只给容器底层开辟指定大小空间并不添加新的元素resize();,扩容,不仅给容器底层开辟指定大小空间,还会添加新的元素swap();,两个容器进行元素交换
代码示例:元素遍历
vector<int> vec;
for (int i = 0; i < 20; ++i)
vec.push_back(i);
int size = vec.size();
for (int i = 0; i < size; ++i)
cout << vec[i] << " ";
cout << endl;
auto it1 = vec.begin();
for (; it1 != vec.end(); ++it1)
cout << *it1 << " ";
cout << endl;
运行结果:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
代码示例:删除所有偶数
vector<int> vec;
for (int i = 0; i < 20; ++i)
vec.push_back(i);
auto it = vec.begin();
while (it != vec.end())
{
if (*it % 2 == 0)
it = vec.erase(it);
else
++it;
}
int size = vec.size();
for (int i = 0; i < size; ++i)
cout << vec[i] << " ";
cout << endl;
运行结果:
1 3 5 7 9 11 13 15 17 19
代码示例:所有奇数前面加一个比其小1的数
vector<int> vec;
for (int i = 0; i < 20; ++i)
vec.push_back(i);
for (auto it = vec.begin(); it != vec.end(); ++it)
{
if (*it % 2 == 1)
{
it = vec.insert(it, *it - 1);
++it;
}
}
int size = vec.size();
for (int i = 0; i < size; ++i)
cout << vec[i] << " ";
cout << endl;
运行结果:
0 0 1 2 2 3 4 4 5 6 6 7 8 8 9 10 10 11 12 12 13 14 14 15 16 16 17 18 18 19
代码示例:reserve预留空间
reserve只是预留空间,只给容器底层开辟指定大小空间并不添加新的元素
默认定义的vector底层开辟空间为0,第一次push_back插入从0变更为1,再变为2,4,8,16,32…,一直进行二倍扩容,扩容频繁,效率太低,假如开始知道问题的数据量大小,即可使用reserve预留空间
vector<int> vec;
vec.reserve(20);
cout << vec.empty() << endl;
cout << vec.size() << endl;
for (int i = 0; i < 20; ++i)
vec.push_back(i);
cout << vec.empty() << endl;
cout << vec.size() << endl;
运行结果:
1
0
0
20
代码示例:resize扩容
resize扩容,不仅给容器底层开辟指定大小空间,还会添加新的元素,没有指定添加的元素值则为0
vector<int> vec;
vec.resize(10);
cout << vec.empty() << endl;
cout << vec.size() << endl;
for (int i = 0; i < 20; ++i)
vec.push_back(i);
cout << vec.empty() << endl;
cout << vec.size() << endl;
int size = vec.size();
for (int i = 0; i < size; ++i)
cout << vec[i] << " ";
cout << endl;
运行结果:
0
10
0
30
0 0 0 0 0 0 0 0 0 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
若改为vec.resize(10,3);,则运行结果为:
0
10
0
30
3 3 3 3 3 3 3 3 3 3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
二、deque和list容器
deque:使用前需要包含头文件:#include <deque>
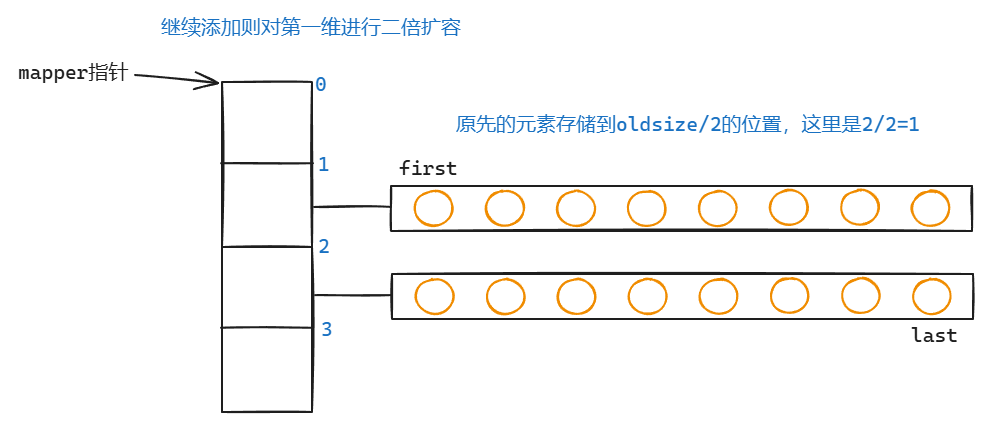
双端队列容器,底层数据结构为动态开辟的二维数组。 一维数组从2开始,以2倍的方式进行扩容,每次扩容后,原来第二维的数组,从新的第一维数组的下标oldsize/2开始存放(也就是扩容之后的中间),前后都预留相同的空行,方便支持双端的元素添加
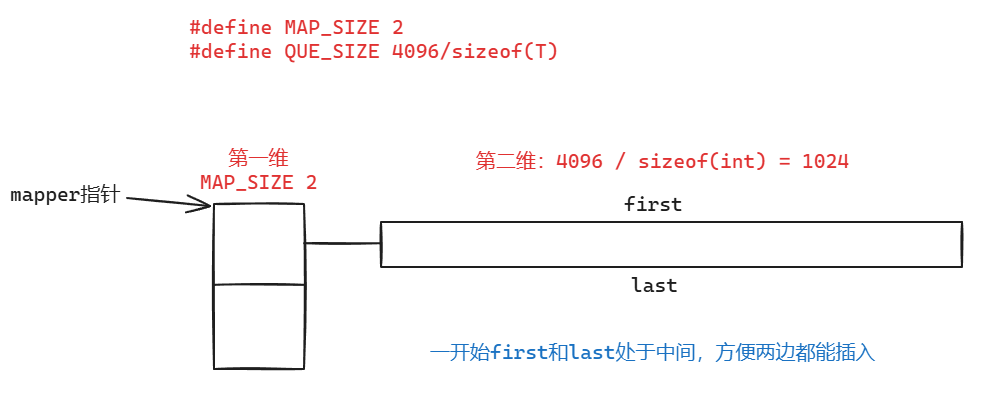
随着元素增加:
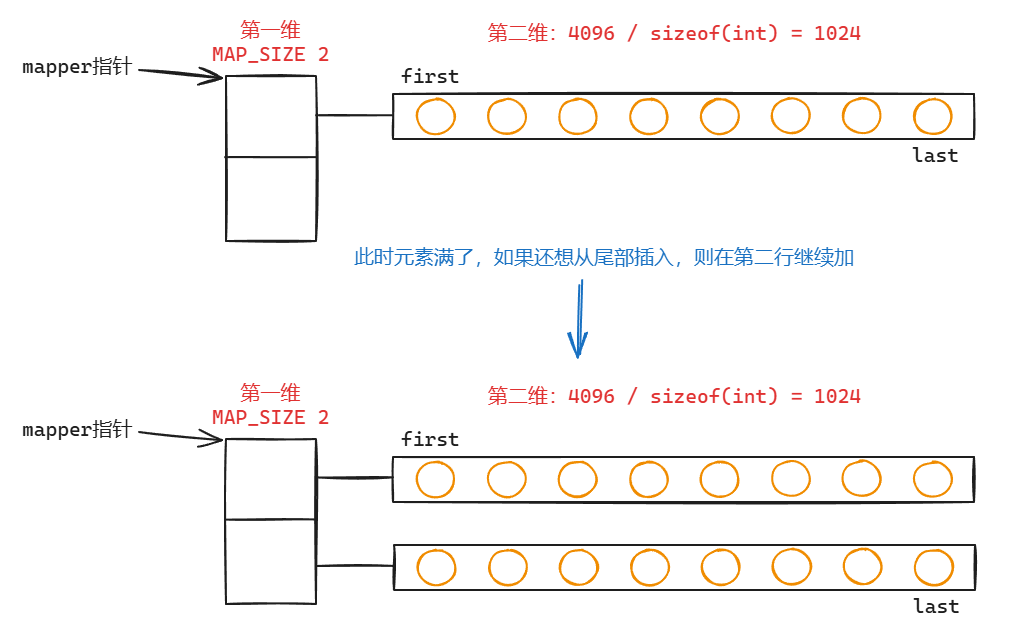
如果继续增加呢?会对第一维扩容
使用方法:
deque<int> deq;
增加:
deq.push_back(20);,从末尾添加元素,时间复杂度O(1),可能引起扩容deq.push_front(20);,从首部添加元素,时间复杂度O(1),可能引起扩容。vector中没有该方法,需要使用vec.insert(vec.begin(), 20),O(n)deq.insert(it, 20);,迭代器it指向的位置添加元素,时间复杂度O(n)
删除:
deq.pop_back();,从末尾删除元素,时间复杂度O(1)deq.pop_front();,从首部删除,时间复杂度O(1)deq.erase(it);,迭代器it指向的位置进行元素删除,时间复杂度O(n)
查询:
iterator,迭代器进行遍历,一定要考虑迭代器失效问题(连续的insert或erase)
常用方法:
size();,返回容器底层有效元素的个数empty();,判断容器是否为空resize();,扩容,不仅给容器底层开辟指定大小空间,还会添加新的元素swap();,两个容器进行元素交换
list:使用前需要包含头文件:#include <list>
底层数据结构为双向循环链表,结点中包括data、pre、next
与vector和deque不同,list允许高效地在任何位置插入和删除元素,但不支持随机访问
使用方法:
list<int> MyList;
增加:
MyList.push_back(20);,从末尾添加元素,时间复杂度O(1),可能引起扩容MyList.push_front(20);,从首部添加元素,时间复杂度O(1),可能引起扩容MyList.insert(it, 20);,迭代器it指向的位置添加元素,时间复杂度O(1),但是往往要考虑搜索到指定位置的时间
删除:
MyList.pop_back();,从末尾删除元素,时间复杂度O(1)MyList.pop_front();,从首部删除,时间复杂度O(1)MyList.erase(it);,迭代器it指向的位置进行元素删除,时间复杂度O(1),但是往往要考虑搜索到指定位置的时间
查询:
iterator,迭代器进行遍历,一定要考虑迭代器失效问题(连续的insert或erase)
常用方法:
size();,返回容器底层有效元素的个数empty();,判断容器是否为空resize();,扩容,不仅给容器底层开辟指定大小空间,还会添加新的元素swap();,两个容器进行元素交换
deque和list的使用实例与vector类似,这里就不再写了
三、vector、deque、list横向对比
vector特点:底层是动态开辟的数组,内存是连续的,以2倍的方式进行扩容。当我们默认定义一个vector时候vector<int> vec;,容器底层没有开辟空间,当添加元素时候才开始以0 -> 1 -> 2 -> 4 -> 8...这种方式进行扩容,用原来老内存上的对象在新内存的空间上进行拷贝构造,再析构老内存上的对象并释放老内存,扩容效率低下。我们可以用reserve函数预留空间,但注意reserve并未添加元素
deque特点:底层是动态开辟的二维数组空间,第二维是固定长度的数组空间,扩容时候(第一维的数组进行2倍扩容,原来的第二维的数组放入新扩容的数组中间,即oldsize/2的位置),前后插入删除操作的时间复杂度都是O(1)
那么,deque底层的内存是否是连续的呢?
并不是!deque的第二维都是独立new出来的,也就是说,每一个第二维是连续的,并不是所有的第二维连续,可以说是分段连续的
vector与deque之间的区别:
- 底层数据结构:看上面两者的特点
- 前后删除元素的时间复杂度:末尾插入删除都为O(1),但在最前面进行元素添加删除时候
deque为O(1),vector为O(n)。那么,如果现在需求是前后都能插入删除,就选择deque而不选择vector - 内存使用效率:
vector低,因为vector需要的内存空间必须是连续的;deque第二维内存空间分段连续就行,不用整片连续,可以分块进行数据存储,对内存使用效率更高 - 在中间进行
insert或者erase,vector与deque的效率:它们时间复杂度都为O(n),但vector内存完全连续,在中间进行插入删除元素的时候容易移动;但deque的第二维内存不完全连续,例如在删除一个元素之后,其他元素会一个一个往前挪动,会进行不同内存片段之间的挪动,元素移动更加麻烦一些,效率不如vector
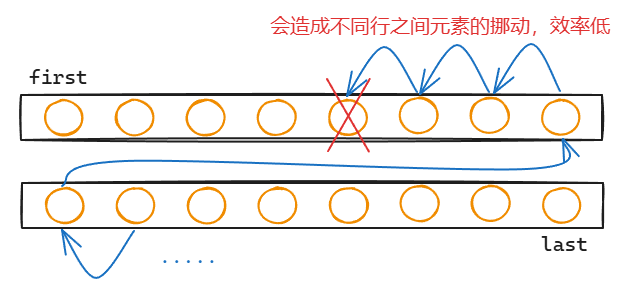
vector与list之间的区别:
- 底层数据结构:动态开辟的数组 vs 双向循环链表。那也就是在问数组和链表之间的区别
- 数组增加删除O(n),查找O(n),随机访问为O(1)
- 链表增加删除一个结点本身为O(1),但查找某元素的时间为O(n)
- 那么,如果增加删除使用多,优先使用
list;如果随机访问使用多,优先使用vector
四、详解容器适配器
C++容器适配器是一种特殊的容器,它们包装了其他容器(如std::vector、std::deque或std::list),并提供了一种不同的接口来访问和操作这些容器的内容。容器适配器并不存储自己的元素,而是将操作委托给它们所包含的容器。
容器适配器底层没有自己的数据结构,它是另外一个容器的封装,它的方法全部由底层依赖的容器进行实现的;它没有实现自己的迭代器,不能使用迭代器遍历
C++标准库提供了三种主要的容器适配器:
std::stack:栈是一种后进先出(LIFO)的数据结构,依赖dequestd::queue:队列是一种先进先出(FIFO)的数据结构,依赖dequestd::priority_queue:在C++中,std::priority_queue默认实现为一个大根堆,这意味着具有最高优先级的元素(即最大的元素)总是先出队,依赖vector
问题一:
stack与queue第二个模板类型参数依赖deque,为什么不依赖vector?而优先级队列为什么底层依赖vector?
vector的初始内存使用效率太低(需要 0 → \to → 1 → \to → 2 → \to → 4 → \to → 8 这样扩容),没有deque好(第二维默认就是4096/sizeof(T))- 对于
queue来说,需要支持尾部插入,头部删除,时间复杂度为 O(1) 效率好,deque恰好符合条件;若用vector那么从头部出队的效率很低 O(n)vector需要大片的连续内存,而deque只需要分段的内存,当存储大量数据时,显然deuqe对于内存的利用率更高更好一些
问题二:优先级队列为什么底层依赖
vector?
- 优先级队列底层默认把数据组成一个大根堆结构,将大根堆结构看作一棵树,如果将大根堆结构所有元素放入数组中,使用下标计算其结点。若从0号位开始存,根节点为
i,左孩子为2i+1,右孩子为2i+2;结点与左右孩子关系使用下标计算,就需要每一个元素内存必须是连续的,因此底层依赖vector;而deque的第二维不是连续的,不能使用
使用容器适配器还有一个好处是:可以在不改变现有代码的情况下更改底层容器的类型。例如,如果你最初使用std::deque作为std::stack的底层容器,但后来发现std::vector更适合你的需求,那么你可以简单地更改std::stack的模板参数,而无需修改任何使用std::stack的代码
看个简单例子:使用容器适配器来实现一个栈
template<typename T, typename Container = deque<T>>
class Stack
{
public:
void push(const T& val) { con.push_back(val); }
void pop() { con.pop_back(); }
T top() const { return con.back(); }
private:
Container con;
};
相当于栈将deque代理了,也称为代理模式。
push将底层容器的push_back代理了
pop将底层容器的pop_back代理了
top将底层容器的back代理了
stack
需要包含头文件#include <stack>
常用方法:
push();:入栈pop();:出栈top();:查看栈顶元素empty();:判断栈空size();:返回栈元素个数
简单使用案例:
stack<int> s1;
for (int i = 0; i < 20; ++i)
s1.push(i);
cout << "栈中元素个数:" << s1.size() << endl;
while (!s1.empty())
{
cout << s1.top() << " ";
s1.pop();
}
运行结果:
栈中元素个数:20
19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
queue
需要包含头文件#include <queue>
常用方法:
push();:入队pop();:出队front();:查看队头元素back();:产看队尾元素empty();:判断队空size();:返回队列元素个数
简单使用案例:
queue<int> que;
for (int i = 0; i < 20; ++i)
que.push(i);
cout << "队列中元素个数:" << que.size() << endl;
while (!que.empty())
{
cout << que.front() << " ";
que.pop();
}
运行结果:
队列中元素个数:20
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
priority_queue
需要包含头文件#include <queue>
常用方法:
push();:入优先级队列pop();:出优先级队列top();:查看队顶元素empty();:判断队空size();:返回元素个数
简单使用案例:
priority_queue<int> pque;
for (int i = 0; i < 20; ++i)
pque.push(i);
cout << "优先级队列中元素个数:" << pque.size() << endl;
while (!pque.empty())
{
cout << pque.top() << " ";
pque.pop();
}
运行结果:
优先级队列中元素个数:20
19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
五、关联容器
关联容器分为无序关联容器与有序关联容器
主要有两类:
set集合:存储关键字keymap映射表:存储键值对[key, value]
无序关联容器
无序关联容器底层为链式哈希表,里面元素无顺序,增删查O(1)
包含:
unordered_set:单重集合,不允许key重复unordered_multiset:多重集合,允许key重复unordered_map:单重映射表,不允许key重复unordered_multimap:多重映射表,允许key重复
头文件:
#include <unordered_set> // unordered_set、unordered_multiset
#include <unordered_map> // unordered_map、unordered_multimap
unordered_set与unordered_multiset常用方法:
- 插入:
insert(val);,注意vector/deque/list需要两个参数insert(it, val),对比区分开 - 遍历:
iterator搜索;调用find(val)成员方法 - 删除:
erase(key);、erase(it);,注意迭代器失效问题,要对迭代器更新 size();:返回容器中元素个数count(val);:返回key值为val的个数find(val);:在容器中查找值为val的key存在否,存在则返回所在位置迭代器,不存在则返回容器末尾迭代器set.end()
unordered_map与unordered_multimap和unordered_set与unordered_multiset的常用方法类似,只不过存储的是键值对
[key, value],底层有个pair结构体
struct pair
{
first; =>key
second; =>value
}
- 插入:
insert(make_pair(1000, "张三"));、insert({1010, "李四"});myMap[1010] = "李四2";:如果key不存在,则插入;若存在则更新值myMap[1010];:返回的是key对应的value值,如果key不存在,则插入[key, V()],value值为默认构造,如string()。如果key存在,则现在是查询操作
- 遍历:
iterator- 调用
find(val)成员方法,返回的是键值对的迭代器,需要用first和second访问
- 删除:
erase(key);、erase(it);,注意迭代器失效问题,要对迭代器更新 size();:返回容器中元素个数count(val);:返回key值为val的个数find(val);:在容器中查找值为val的key存在否,存在则返回所在位置迭代器,不存在则返回容器末尾迭代器set.end()
案例1:海量数据查重,一般使用map
const int ARR_LEN = 100;
int arr[ARR_LEN] = { 0 };
for (int i = 0; i < ARR_LEN; i++)
arr[i] = rand() % 20 + 1;
// 上面的100个整数中,统计哪些数字重复了,并且统计数字重复的次数
unordered_map<int, int> map1;
for (int k : arr)
{
/*auto it = map1.find(k);
if (it == map1.end()) // 数字没出现过
map1.insert(make_pair(k, 1));
else // 次数加一
it->second++;*/
map1[k]++; // 一句话解决,map1[k]返回的是对应的value,若没有则插入,返回的value是0
}
for (auto it = map1.begin(); it != map1.end(); ++it)
if (it->second > 1)
cout << "key:" << it->first << " value:" << it->second << endl;
// 另一种访问方式
for (pair<int, int> p : map1) // 用常引用const pair<int, int>& p : map1也行,这样foreach不会发生拷贝构造,提升了一些效率
if (p.second > 1)
cout << "key:" << p.first << " value:" << p.second << endl;
运行结果:
key:10 value:6
key:2 value:8
key:8 value:6
key:15 value:3
key:1 value:3
key:5 value:8
key:3 value:9
key:19 value:7
key:6 value:3
key:12 value:6
key:16 value:4
key:17 value:5
key:14 value:5
key:13 value:2
key:7 value:6
key:20 value:3
key:4 value:4
key:9 value:5
key:18 value:3
key:11 value:4
案例2:海量数据去重,一般使用set
const int ARR_LEN = 100;
int arr[ARR_LEN] = { 0 };
for (int i = 0; i < ARR_LEN; i++)
arr[i] = rand() % 20 + 1;
// 上面的整数中,将数字进行去重打印
unordered_set<int> set;
for (int k : arr)
set.insert(k);
for (int k : set)
cout << k << " ";
cout << endl;
运行结果:
10 2 8 15 1 5 3 19 6 12 16 17 14 13 7 20 4 9 18 11
有序关联容器
有序关联容器底层为红黑树,里面元素有序,增删查O(log2n)
包含:
set:单重集合,重复的只出现一次,从小到大元素有序排列(红黑树的中序遍历)multiset:多重集合,可以存储重复的元素,从小到大元素有序排列map:单重映射表,重复的只出现一次,从小到大元素有序排列multimap:多重映射表,可以存储重复的元素,从小到大元素有序排列
头文件:
#include <set> // set、multiset
#include <map> // map、multimap
常用方法和之前的无序关联容器基本一致,我们直接来看案例:
案例1:set
set<int> set1;
for (int i = 0; i < 20; ++i)
set1.insert(rand() % 20 + 1);
for (int v : set1)
cout << v << " ";
cout << endl;
运行结果:
1 2 3 5 6 8 10 12 15 16 17 19
可以看到去重并且从小到大排序了,这其实就是底层红黑树中序遍历的结果
案例2:set存放自定义类型
class Student
{
public:
Student(int id, string name)
:_id(id), _name(name) {}
// 需要重载小于号,才可以进行排序
bool operator<(const Student& stu) const { return _id < stu._id; }
private:
int _id;
string _name;
friend ostream& operator<<(ostream& out, const Student& stu);
};
ostream& operator<<(ostream& out, const Student& stu)
{
out << "id:" << stu._id << " name:" << stu._name;
return out;
}
int main()
{
set<Student> set1;
set1.insert(Student(1000, "张文"));
set1.insert(Student(1020, "李广"));
for (auto it = set1.begin(); it != set1.end(); ++it)
cout << *it << endl;;
}
运行结果:
id:1000 name:张文
id:1020 name:李广
案例3:map
class Student
{
public:
// 需要有默认构造,这里加上默认值就行
Student(int id = 0, string name = "") :_id(id), _name(name) {}
private:
int _id;
string _name;
friend ostream& operator<<(ostream& out, const Student& stu);
};
ostream& operator<<(ostream& out, const Student& stu)
{
out << "id:" << stu._id << " name:" << stu._name;
return out;
}
int main()
{
// map用key来排序的,不用重载小于号operator<
map<int, Student> stuMap;
stuMap.insert({ {3,Student(1010,"张文")},
{5,Student(1020,"李广")},
{1,Student(1030,"高阳")}
});
//stuMap.erase(it) stuMap.erase(1020)
//cout << stuMap[1050] << endl; //id:1050 name: 调用了默认构造
//auto it = stuMap.find(1020);
//if (it != stuMap.end())
// cout << it->second << endl; //id:1020 name:李广
for (auto it = stuMap.begin(); it != stuMap.end(); ++it)
cout << "key:" << it->first << " value:" << it->second << endl;
cout << endl;
}
运行结果:
key:1 value:id:1030 name:高阳
key:3 value:id:1010 name:张文
key:5 value:id:1020 name:李广
注意,如果是map<Student, int> stuMap;,那么此时根据Student进行红黑树的中序遍历,那么就需要operator<了
六、迭代器
const_iterator:常量的正向迭代器,只能读不能写iterator:普通的正向迭代器,可读可写const_reverse_iterator:常量的反向迭代器,只能读不能写reverse_iterator:普通的反向迭代器,可读可写
一般反向迭代器配合rbegin和rend进行使用
七、函数对象
函数对象类似C语言里面的函数指针,拥有operator()运算符重载函数的对象,称作函数对象,也叫仿函数
对比:

虽然看起来调用是一样的,但还是有区别:C语言中的sum(),函数名是一个地址;C++中的sum()是一个对象,相当于调用重载函数sum.operator()(10, 20);
接下来,那我们来看一下使用函数对象有什么好处呢?
template<typename T>
bool compare(T a, T b) { return a > b; }
int main()
{
cout << compare(10, 20) << endl; // 0
cout << compare('b', 'y') << endl; // 0
return 0;
}
现在的问题是,这个函数不够灵活!如果我们现在想比较小于,怎么办?改为return a < b;吗?每次来回改动,这样太麻烦
解决办法1:C语言中的函数指针
template<typename T>
bool myGreater(T a, T b) { return a > b; }
template<typename T>
bool myLess(T a, T b) { return a < b; }
// 现在,compare是C++的库函数模板
template<typename T, typename Compare>
bool compare(T a, T b, Compare comp) { return comp(a, b); }
int main()
{
cout << compare(10, 20, myGreater<int>) << endl;// 0
cout << compare(10, 20, myLess<int>) << endl; // 1
return 0;
}
可以看到,问题很好的解决了,我们只需要传入不同的第三个参数(函数指针),就可以得到想要的不同的结果
通过函数指针虽然解决了问题,但是,函数指针无法进行inline内联 (内联在编译阶段,编译的时候comp(a, b);根本不知道调用的是谁),有函数的调用开销,效率很低
解决办法2:C++中的函数对象
template<typename T>
class myGreater
{
public:
// 有两个参数,这叫二元函数对象
bool operator()(T a, T b) { return a > b; }
};
template<typename T>
class myLess
{
public:
// 有两个参数,这叫二元函数对象
bool operator()(T a, T b) { return a < b; }
};
// compare是C++的库函数模板
template<typename T, typename Compare>
bool compare(T a, T b, Compare comp) { return comp(a, b); }
int main()
{
// 注意对象是:类名+小括号
cout << compare(10, 20, myGreater<int>()) << endl; // 0
cout << compare(10, 20, myLess<int>()) << endl; // 1
return 0;
}
这回,comp(a, b);调用的是对象了,其实就是在调用对象的小括号重载函数,编译器在编译时就知道了仿函数的类型及其operator()方法,因此,它可以直接内联这个调用,因为类型和方法在编译时是明确的
虽然函数指针的方法在调用时指定了
myGreater<int>,但由于编译器处理函数指针和函数对象的方式不同,它不会在编译时内联函数指针指向的函数。函数对象(仿函数)因为其类型和实现的确定性,编译器可以在编译时内联其调用,从而提高性能。这也是函数对象(仿函数)在C++中更受欢迎的原因之一
- 通过函数对象调用
operator()运算符重载,可以省略函数的调用开销,比通过函数指针调用函数(不能inline内联调用)效率高- 因为函数对象是用类生成的,所以可以添加相关的成员变量用来记录函数对象使用时更多的信息,比如加入
count记录函数调用的次数
使用实例1:优先级队列
优先级队列底层依赖vector容器,默认是一个大根堆

默认用的less,改成greater,就可以实现小根堆输出了
// 大根堆
priority_queue<int> que1;
for (int i = 0; i < 10; ++i)
que1.push(i);
while (!que1.empty())
{
cout << que1.top() << " ";
que1.pop();
}
cout << endl;
// 改成小根堆
using MinHeap = priority_queue<int, vector<int>, greater<int>>;
MinHeap que2;
for (int i = 0; i < 10; ++i)
que2.push(i);
while (!que2.empty())
{
cout << que2.top() << " ";
que2.pop();
}
cout << endl;
运行结果:
9 8 7 6 5 4 3 2 1 0
0 1 2 3 4 5 6 7 8 9
使用实例2:set
set底层为红黑树,默认从小到大进行输出

默认用的less,改成greater,就可以实现大到小输出了
// 默认小到大
set<int> set1;
for (int i = 0; i < 10; ++i)
set1.insert(i);
for (int v : set1)
cout << v << " ";
cout << endl;
// 改编成大到小
set<int, greater<int>> set2;
for (int i = 0; i < 10; ++i)
set2.insert(i);
for (int v : set2)
cout << v << " ";
cout << endl;
运行结果:
0 1 2 3 4 5 6 7 8 9
9 8 7 6 5 4 3 2 1 0
八、泛型算法和绑定器
头文件:#include <algorithm>,包含了C++STL里面的泛型算法
泛型算法特点:
- 泛型算法的参数接受的都是迭代器
- 泛型算法的参数还可以接受函数对象(类似C函数指针)
泛型算法 = template模板 + 迭代器 + 函数对象
用模板实现的,接收的是容器的迭代器,还可以更改运算结果
实例1:sort
int arr[] = { 12, 4, 78, 9, 21, 43, 56, 52, 42, 31 };
vector<int> vec(arr, arr + sizeof(arr) / sizeof(arr[0]));
for (int v : vec)
cout << v << " ";
cout << endl;
// 小到大排序
sort(vec.begin(), vec.end());
for (int v : vec)
cout << v << " ";
cout << endl;
运行结果:
12 4 78 9 21 43 56 52 42 31
4 9 12 21 31 42 43 52 56 78
实例2:在上面得到的有序的容器中进行二分查找
if (binary_search(vec.begin(), vec.end(), 21)) // O(logn)
cout << "21存在" << endl;
// 也可以用find找,但效率是O(n)
auto it = find(vec.begin(), vec.end(), 21);
if (it != vec.end())
cout << "21存在" << endl;
实例3:改变sort排序方式
// 第三个参数传入一个临时的函数对象,就行了
sort(vec.begin(), vec.end(), greater<int>());
for (int v : vec)
cout << v << " ";
cout << endl;
运行结果:
78 56 52 43 42 31 21 12 9 4
实例4:find_if
find_if是 C++ 标准库中的一个算法,用于在范围内查找满足特定条件的第一个元素。它接受一个范围和一个谓词(即条件函数),返回指向找到的元素的迭代器,如果没有找到满足条件的元素,则返回指向范围末尾的迭代器
目标:在上面已经从大到小排序的容器中,按序插入48
那么此时,第三个参数需要的就是一元函数对象,因为要拿出一个数来和48进行比较
我们现在有的函数对象都是二元函数对象,那么怎么弄成一元函数对象呢,这就需要绑定器
绑定器 + 二元函数对象 → \to → 一元函数对象
bind1st:把二元函数对象operator()(a,b)第一个形参绑定起来,绑定为固定的值,只需要传入一个实参bind2nd:把二元函数对象operator()(a,b)第二个形参绑定起来,绑定为固定的值,只需要传入一个实参
使用绑定器需要包含头文件:#include <functional>
这里先学会用法,底层原理在之后的 《C++语言高级进阶课程》 中会讲
// 在78 56 52 43 42 31 21 12 9 4中插入48
// 目标是找第一个小于48的数字,需要的是一元函数对象,因此我们需要绑定器
// greater a(48) > b(从容器取的数)
// less a(从容器取的数) < b(48)
auto it = find_if(vec.begin(), vec.end(), bind1st(greater<int>(), 48));
vec.insert(it, 48);
for (int v : vec)
cout << v << " ";
cout << endl;
运行结果:
78 56 52 48 43 42 31 21 12 9 4
同效果的其他方法:
auto it = find_if(vec.begin(), vec.end(), bind2nd(less<int>(), 48));
// lambda表达式:绑定器的底层其实就是lambda表达式
auto it = find_if(vec.begin(), vec.end(), [](int val)->bool {return val < 48; });
实例4:for_each,将容器中所有偶数打印出来
for_each可以遍历容器的所有元素,可以自行添加合适的函数对象,对容器的元素进行过滤
for_each(vec.begin(), vec.end(),
[](int val)->void
{
if ((val & 1) == 0)
cout << val << " ";
});
cout << endl;
运行结果:
78 56 52 48 42 12 4
STL方面的总结,可以看看这篇文章:C++STL容器内容总结

















 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











