







K临近算法
1.什么是K临近算法?
所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
2.算法实例
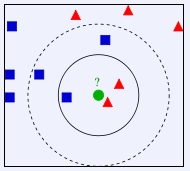
有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。我们要做的是给绿色的小圆分类。
如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。
3.算法特点
KNN 算法本身简单有效,分类器不需要使用训练集进行训练,训练时间复杂度为0。KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
4.算法流程
首先计算出已知类别的数据集当中所有点与当前点的距离
然后按照距离的大小按递增次序排列
之后选取与当前点距离最小的n个点
确定出那n个点所在类别出现的频率
最后返回n个点出现频率最高的类别作为当前点的预测分类
5.测试算法实现手写体识别
书中的k-临近算法,classify()函数有四个输入参数:用于分类的输入向量inX,输入的训练样本集为dataSet,标签向量为labele,最后的参数k表示用于选择最近邻居的数目,其中标签向量的元素数目和矩阵dataSet的行数相同。代码使用欧式距离公式来计算两个向量点之间的距离,计算完成之后对数据按照从小到大的次序排列。然后确定前k个距离最小元素所在额主要分类,将classCount字典分解为元组列表,然后使用程序第二行导入运算符模块的itemgetter方法,按照第二个元素的次序对元组进行逆序排列,最后返回发生频率最高的标签。
#书中的knn算法
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #取得样本的数量
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2 #求得不同维度上距离差值的平方
sqDistances = sqDiffMat.sum(axis=1) #将不同维度上的差值平方进行相加 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









