






采集某阁的盗版平台
采集流程:
1.输入小说名称查询到小说的链接
2.解析小说链接获取到每个章节的链接
3.解析章节链接获取内容
4.对内容进行排序保存
首先导入所需库:
1.输入小说名称查询到小说的链接
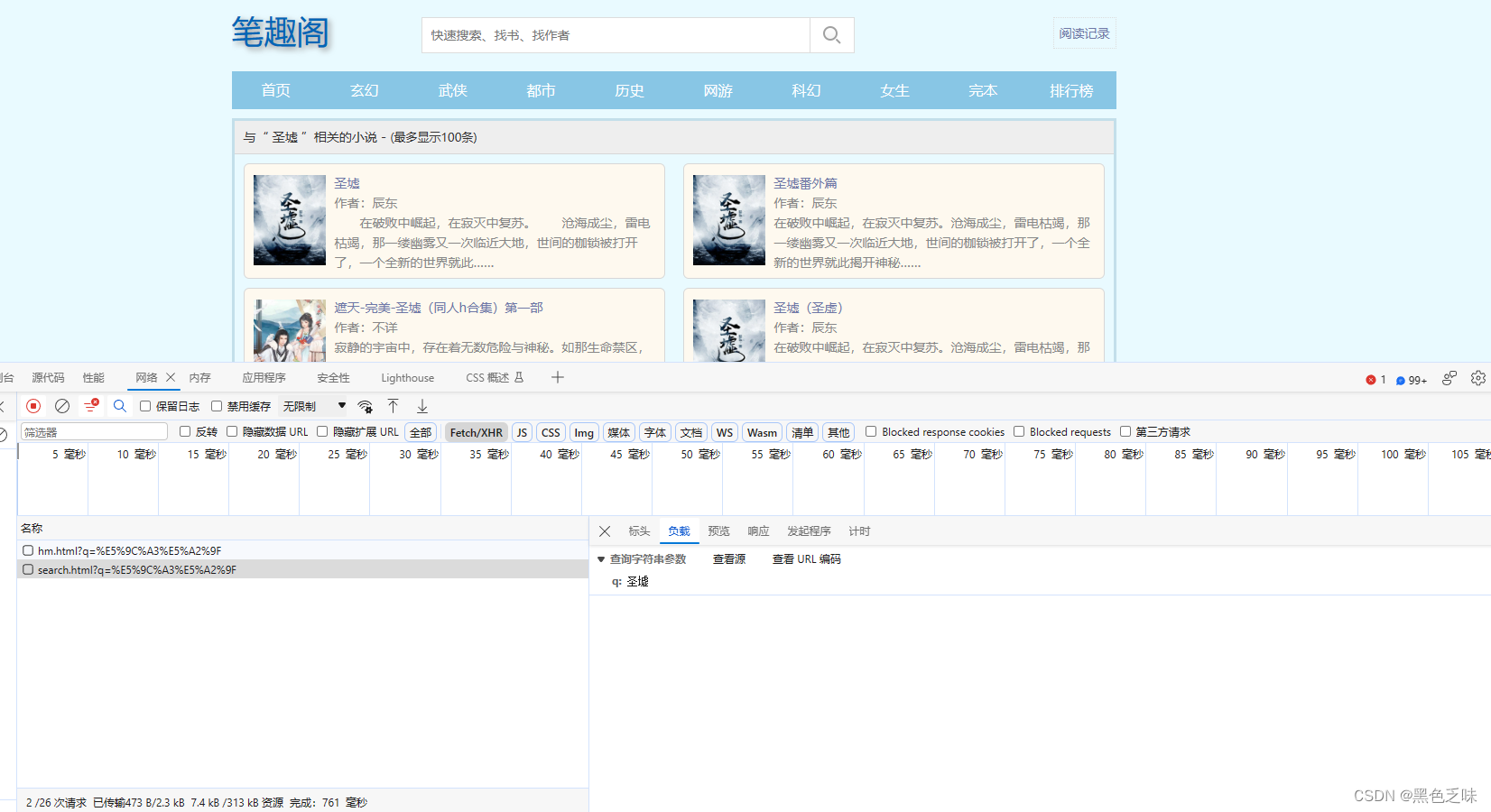
直接找调用接口,传参即为小说名称
直接上本模块功能代码:
def get_key(keys):
"""
查询要搜索的小说
:param keys: 小说名称
:return:
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43",
}
key_code = parse.quote(keys.encode('utf-8'))
url = f'https://www.biqg.cc/user/search.html?q={key_code}'
while True:
response = requests.get(url=url, headers=headers).text
if response == '1':
print(f'请求无效:{response}')
else:
response_json = json.loads(response)
novel_name = re.findall("'articlename': '(.*?)'", str(response_json))
novel_href = re.findall("'url_list': '(.*?)'", str(response_json))
info_zip = zip(novel_name, novel_href)
for zip_info in info_zip:
if keys == str(zip_info[0]):
url = f'https://www.biqg.cc{zip_info[1]}'
print(f'查询成功--->名称:{zip_info[0]}---链接:{url}')
return url
print(f'未查询到{keys}的信息')
return None运行示例:

2.解析小说链接获取到每个章节的链接
既然获取到小说链接了,就进入小说链接页面进行所有链接的采集
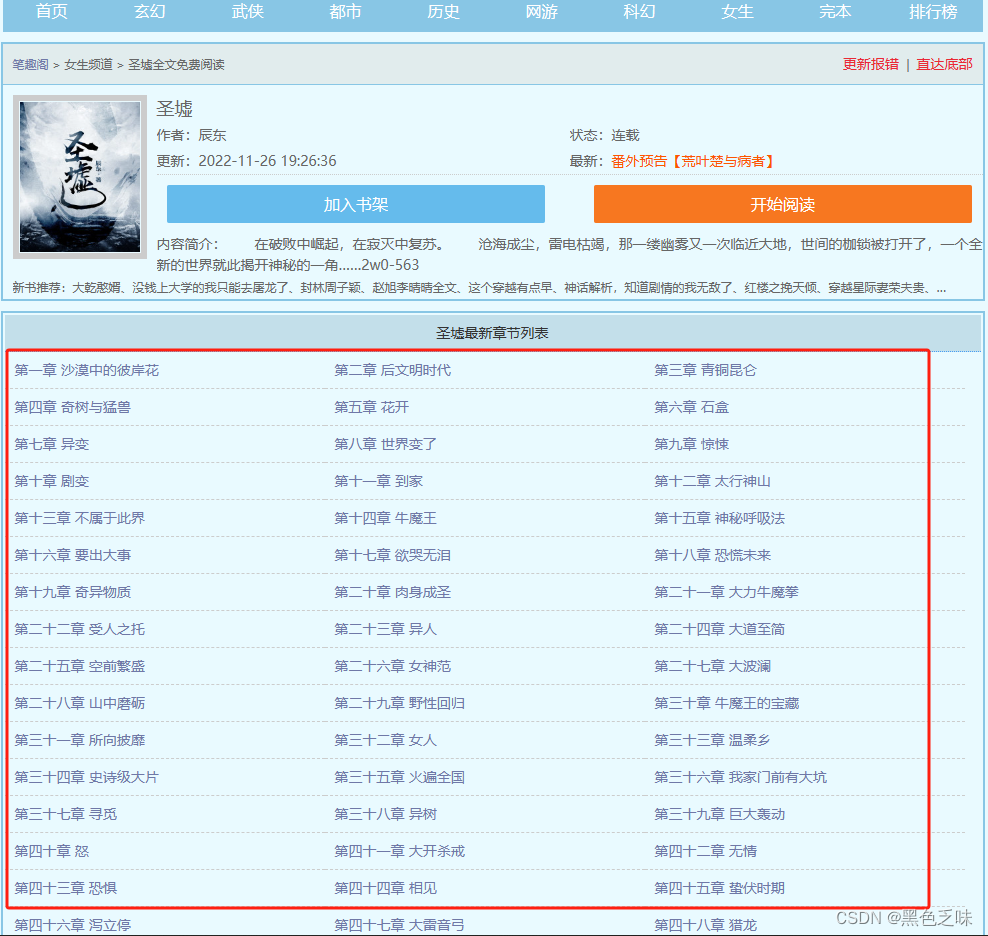
代码:
def get_urls(url):
"""
获取小说所有章节链接
:param url:
:return:
"""
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"cookie": "Hm_lvt_aee414c80f8428eae3eaab28dda30d0a=1702626463; cf_clearance=NOp519MdkLnQoGFfIPOofBJ_pD3k_pQn0.smF4oZcF0-1702626426-0-1-be1d63e.da1a60d5.5ce089de-0.2.1702626426; Hm_lpvt_aee414c80f8428eae3eaab28dda30d0a=1702626469",
"referer": "https://www.beqege.com/",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43"
}
for num in range(5):
try:
response = requests.get(url=url, headers=headers)
html = etree.HTML(response.text)
url_list = html.xpath('''//div[@class='listmain']//a/@href''')
if 'http' not in url_list:
url_list = ['https://www.biqg.cc'+u for u in url_list]
new_url_list = []
for new_url in url_list:
if ':dd_show()' in new_url:
continue
else:
new_url_list.append(new_url)
return new_url_list
except Exception as e:
print(f'采集第{num+1}次重试--->失败:{e}--->{url}')运行示例:
3.解析章节链接获取内容

代码:
async def parse_urls(url):
"""
异步解析每个url链接的文章
:return:
"""
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43",
}
for num in range(5):
try:
timeout = aiohttp.ClientTimeout(total=15)
async with aiohttp.ClientSession(timeout=timeout) as session:
async with session.get(url=url, headers=headers, timeout=timeout) as resp:
response = await resp.text()
html = etree.HTML(response)
title = html.xpath('''//h1[@class='wap_none']//text()''')[0]
content = html.xpath('''//div[@id='chaptercontent']//text()''')
return title, content
except Exception as e:
print(f'采集第{num+1}次重试--->失败:{e}--->{url}')异步请求所有链接,报错自动重试5次
4.对内容进行排序保存
本次排序逻辑为采集到的链接是有序的,只是异步解析的过程中导致章节错乱,应对方法很简单,我们在采集到所有链接的时候对每个链接进行分配一个id,到时候根据id进行判断。
def optimize_save_info(url_list):
"""
优化保存信息, 对需要保存的信息进行排序
:return:
"""
num_list = []
info_list = []
num = 0
for url in url_list:
num += 1
num_list.append(num)
info_list.append([num, url])
sort_num = sorted(num_list, reverse=False)
for nums in sort_num:
for info in info_list:
if info[0] == nums:
title = info[1][0]
content = info[1][1]
with open(f'./xs/{key}.txt', 'a', encoding='utf-8') as f:
f.write(title + '\n' * 2)
for con in content:
f.write(con + '\n')
f.write('\n' + '=' * 50 + '\n' * 2)
print(f'{title}--->保存成功')
break
def parse_main(url_list):
print(url_list)
loop = asyncio.get_event_loop()
task = [asyncio.ensure_future(parse_urls(u)) for u in url_list]
info_list = loop.run_until_complete(asyncio.gather(*task))
optimize_save_info(info_list)至此所有代码完毕
整体代码:
import aiohttp
import asyncio
import requests
import json
import re
import time
from lxml import etree
from urllib import parse
def get_key(keys):
"""
查询要搜索的小说
:param keys: 小说名称
:return:
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43",
}
key_code = parse.quote(keys.encode('utf-8'))
url = f'https://www.biqg.cc/user/search.html?q={key_code}'
while True:
response = requests.get(url=url, headers=headers).text
if response == '1':
print(f'请求无效:{response}')
else:
response_json = json.loads(response)
novel_name = re.findall("'articlename': '(.*?)'", str(response_json))
novel_href = re.findall("'url_list': '(.*?)'", str(response_json))
info_zip = zip(novel_name, novel_href)
for zip_info in info_zip:
if keys == str(zip_info[0]):
url = f'https://www.biqg.cc{zip_info[1]}'
print(f'查询成功--->名称:{zip_info[0]}---链接:{url}')
return url
print(f'未查询到{keys}的信息')
return None
def get_urls(url):
"""
获取小说所有章节链接
:param url:
:return:
"""
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"cookie": "Hm_lvt_aee414c80f8428eae3eaab28dda30d0a=1702626463; cf_clearance=NOp519MdkLnQoGFfIPOofBJ_pD3k_pQn0.smF4oZcF0-1702626426-0-1-be1d63e.da1a60d5.5ce089de-0.2.1702626426; Hm_lpvt_aee414c80f8428eae3eaab28dda30d0a=1702626469",
"referer": "https://www.beqege.com/",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43"
}
for num in range(5):
try:
response = requests.get(url=url, headers=headers)
html = etree.HTML(response.text)
url_list = html.xpath('''//div[@class='listmain']//a/@href''')
if 'http' not in url_list:
url_list = ['https://www.biqg.cc'+u for u in url_list]
new_url_list = []
for new_url in url_list:
if ':dd_show()' in new_url:
continue
else:
new_url_list.append(new_url)
return new_url_list
except Exception as e:
print(f'采集第{num+1}次重试--->失败:{e}--->{url}')
async def parse_urls(url):
"""
异步解析每个url链接的文章
:return:
"""
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43",
}
for num in range(5):
try:
timeout = aiohttp.ClientTimeout(total=15)
async with aiohttp.ClientSession(timeout=timeout) as session:
async with session.get(url=url, headers=headers, timeout=timeout) as resp:
response = await resp.text()
html = etree.HTML(response)
title = html.xpath('''//h1[@class='wap_none']//text()''')[0]
content = html.xpath('''//div[@id='chaptercontent']//text()''')
return title, content
except Exception as e:
print(f'采集第{num+1}次重试--->失败:{e}--->{url}')
def optimize_save_info(url_list):
"""
优化保存信息, 对需要保存的信息进行排序
:return:
"""
num_list = []
info_list = []
num = 0
for url in url_list:
num += 1
num_list.append(num)
info_list.append([num, url])
sort_num = sorted(num_list, reverse=False)
for nums in sort_num:
for info in info_list:
if info[0] == nums:
title = info[1][0]
content = info[1][1]
with open(f'./xs/{key}.txt', 'a', encoding='utf-8') as f:
f.write(title + '\n' * 2)
for con in content:
f.write(con + '\n')
f.write('\n' + '=' * 50 + '\n' * 2)
print(f'{title}--->保存成功')
break
def parse_main(url_list):
print(url_list)
loop = asyncio.get_event_loop()
task = [asyncio.ensure_future(parse_urls(u)) for u in url_list]
info_list = loop.run_until_complete(asyncio.gather(*task))
optimize_save_info(info_list)
if __name__ == '__main__':
'''https://www.biqg.cc/s?q=%E6%96%97%E7%A0%B4%E8%8B%8D%E7%A9%B9'''
start_time = time.time()
key = '斗破苍穹'
key_url = get_key(key)
if key_url:
urls_list = get_urls(key_url)
parse_main(urls_list)
print(f'采集完毕,用时{time.time()-start_time}秒')
我们来看一下采集过程:
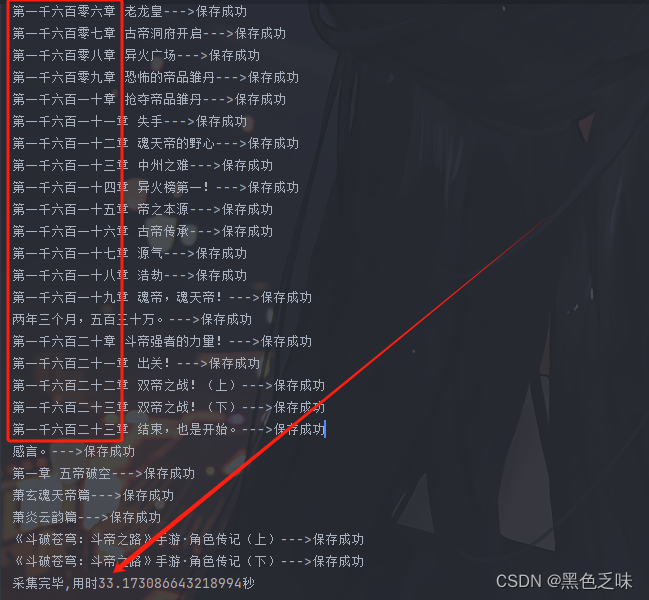

可以看到保存的顺序完全实现了有序化,并且采集1600章的信息用时仅33秒,异步采集效率也被展现的淋漓尽致。















 1122
1122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









