






本次爬取目标网址:长夜余火(爱潜水的乌贼)_长夜余火最新章节 - 笔趣阁
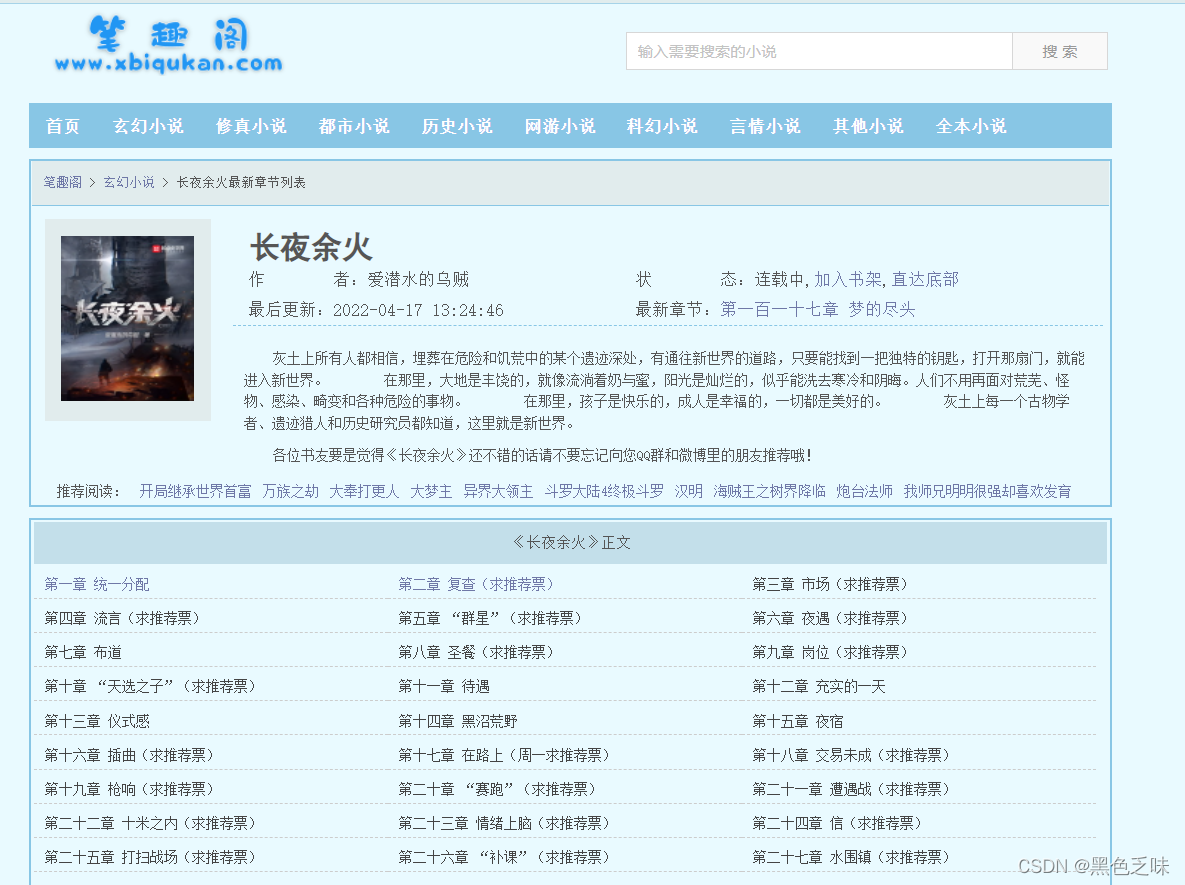
不难看出首页包含所有文章的链接,那么我们第一步就先获取说有章节的链接。
首先引入所需要的库:
import asyncio
import requests
import aiohttp
from lxml import etree
import csv然后创建一个获取链接的函数,刚获取到的链接是不完整的,所以需要拼接
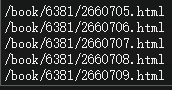
就这样我们创建好了一个获取所有章节链接的函数:
def get_url():
response = requests.get('https://www.xbiqukan.com/book/8885/')
response.encoding = 'gbk'
html = etree.HTML(response.text)
href = html.xpath('''//div[@id='list']//a/@href''')
url_list = ['https://www.xbiqukan.com' + url for url in href]
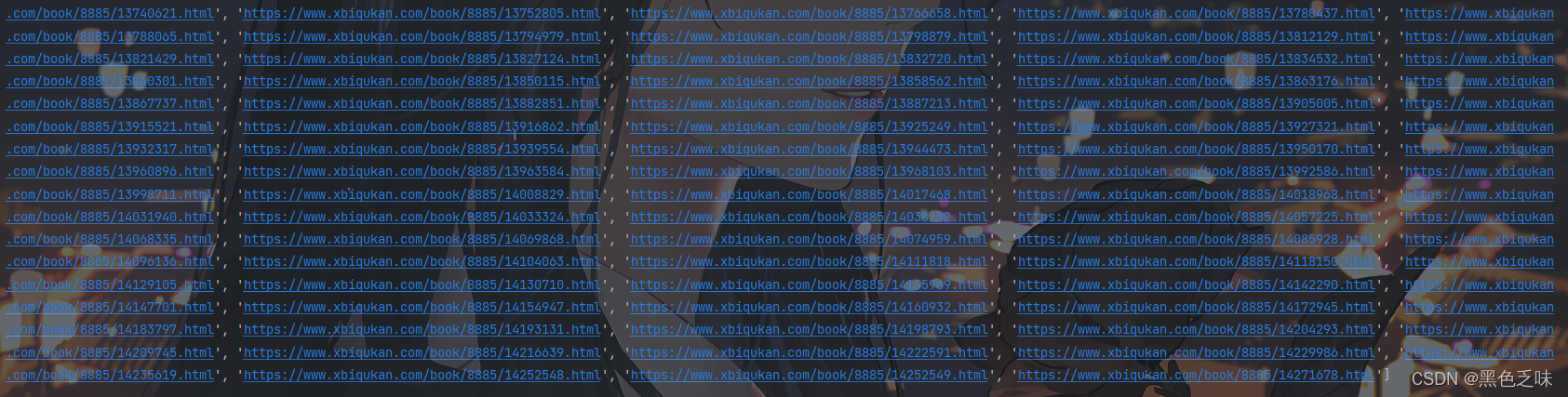
return url_list测试一下:
接下来创建异步解析函数,这样可以通过异步节省很多抓取时间:
async def parse(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
resp = await response.text()
html = etree.HTML(resp)
info = {}
info['标题'] = html.xpath('''//div[@class='bookname']/h1/text()''')[0]
title_bt = ['标题']
try:
with open('小说.csv', 'a',newline='', encoding='gbk') as fp:
zip_writer = csv.DictWriter(fp, title_bt)
zip_writer.writerow(info)
except Exception as e:
print(e)因为时间有限我就简单写一下,这里就先获取标题
最后把解析函数注册到事件循环中:
def main():
tasks = [asyncio.ensure_future(parse(urls)) for urls in get_url()]
loop = asyncio.get_event_loop()
tasks = asyncio.gather(*tasks)
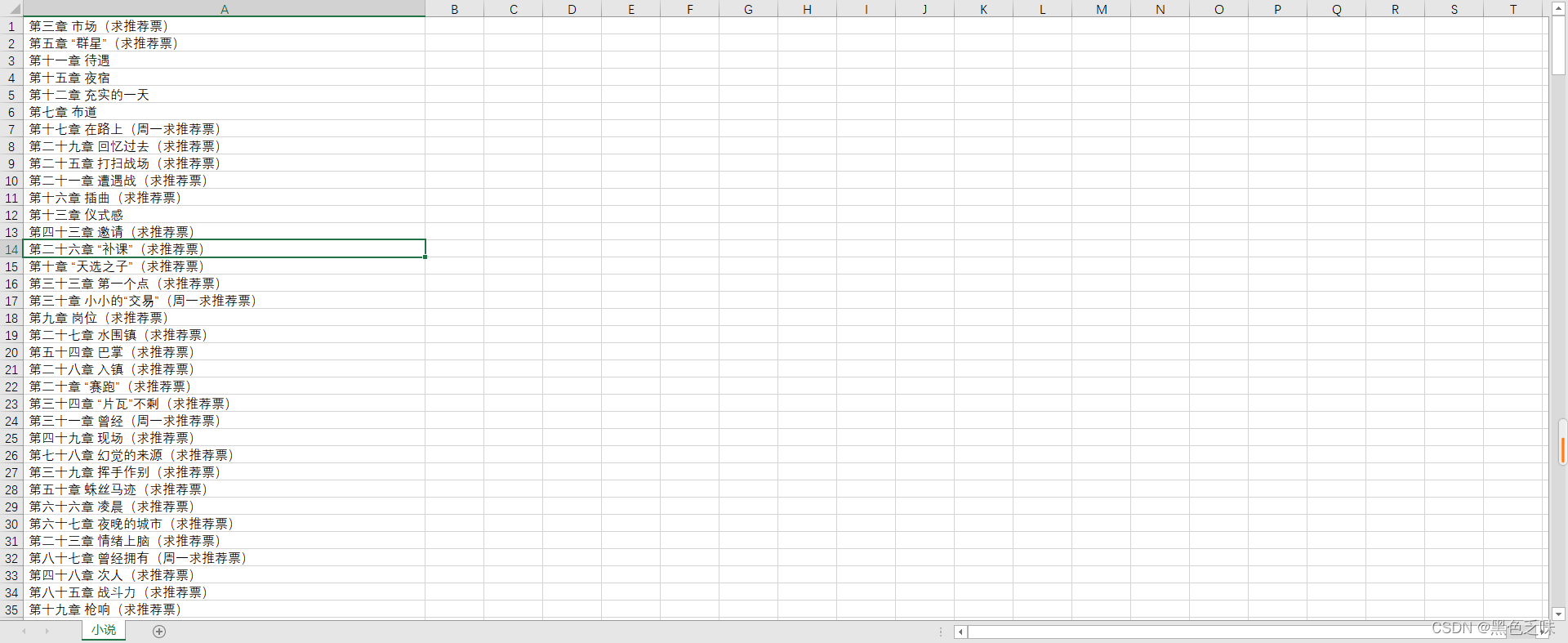
loop.run_until_complete(tasks)这是最后运行结果,但是章节是没有顺序的, 大家可以写爬虫的时候里面自己设置一下标题判断,这样爬出来就是有序的了
完整代码:
import asyncio
import requests
import aiohttp
from lxml import etree
import csv
def get_url():
response = requests.get('https://www.xbiqukan.com/book/8885/')
response.encoding = 'gbk'
html = etree.HTML(response.text)
href = html.xpath('''//div[@id='list']//a/@href''')
url_list = ['https://www.xbiqukan.com' + url for url in href]
return url_list
async def parse(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
resp = await response.text()
html = etree.HTML(resp)
info = {}
info['标题'] = html.xpath('''//div[@class='bookname']/h1/text()''')[0]
title_bt = ['标题']
try:
with open('小说.csv', 'a',newline='', encoding='gbk') as fp:
zip_writer = csv.DictWriter(fp, title_bt)
zip_writer.writerow(info)
except Exception as e:
print(e)
def main():
tasks = [asyncio.ensure_future(parse(urls)) for urls in get_url()]
loop = asyncio.get_event_loop()
tasks = asyncio.gather(*tasks)
loop.run_until_complete(tasks)
if __name__ == '__main__':
main()

















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









