







文章目录
11. 文件概述、文本、二进制文件区别
1.文件概述
1: 文件概述
c语言中输入输出的话都得用 函数
文件: 看成是字符序列(字符流), ”abcdefg“ 。把这个字符序列往磁盘存储形成文件。
根据数据组织形式,就我们人类而言将文件分成两种:
ASCII文件(文本文件),二进制文件。
而对于计算机来讲都是以二进制方式存储而不管什么ASCII。
从人类的角度理解:
a) ASCII文件(文本文件),每一个字节,存放一个ASCII🐎,代表一个字符,这种文件一般你打开就能看懂里面的类容。
b) 二进制文件,把内存中的数据按照其在内存中的存储形式原样输出到磁盘上存放。
对文本文件的理解:
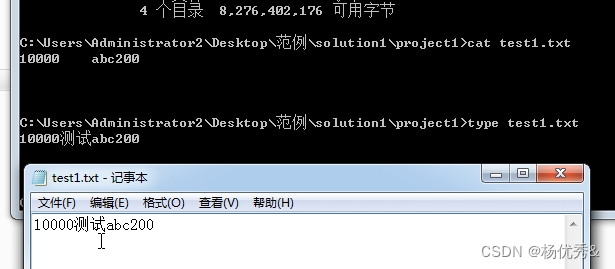
使用常规的打开方式都可以显示里面的内容,这些是人类可看懂的
对于计算机来说都是一堆二进制数据。
总结:
文件对于计算机来讲:一切都是二进制形式存储。
但是,你往文件中写入内容,你可以选择是以文本形式写入,还是
以二进制形式写入。
比如:使用记事本写入,系统就会认为是以文本形式写入的;
或则,打开文件往外读文件也一样,你可以选择以文本形式打开读或者
以二进制文件读。
双击打开这个文件,系统就会认为你是以文本形式打开来读。如果使用
程序代码,并且加一些二进制标记来读文本文件的话,系统就会认为
你是以二进制来读文本的。
一个字节存放一个字符
直接存放二进制省时间。
人类理解的二进制数据:
short int a; // 占2个字符
int ilen = sizeof(a); // 2个字节
a = 10000; //0x2710 , 10属于低位,27属于高位
**一个地址存放一个字节
// 所以0x0038F8D4 存放的是10 , 0x0038F8D5 存放的是27.
//也就是说:
//低位字节10存储到低地址0x0038F8D4,
//高位字节27存放到了高地址0x0038F8D5.**
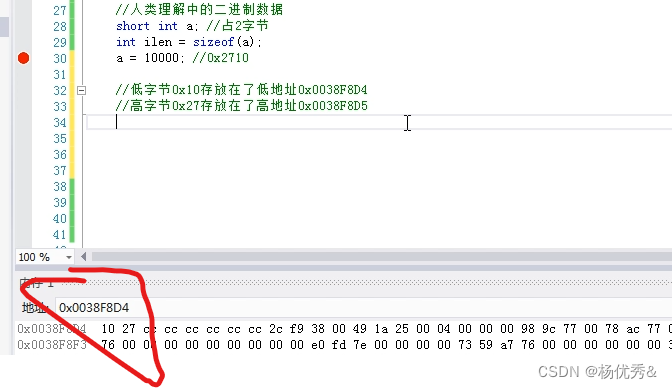
这就是 大端存储 和 小端存储。
大端存储: 低位地址存高地址里面,高位字节存在低地址里
小端存储: 低位字节存低地址,高位字节存高地址。
二进制编辑器编辑的时,如果你输入16进制的内容则转换成ASCII的字符。
结论:
文本文件和二进制区别:
- 不管什么文件对于计算机来讲,就是字节流,
- 计算机不区分文本文件或二进制文件
显示使用16进制或10进制,而存储是用的二进制。
2. 文本文件和二进制文件区别
- 能存储的数据类型不同
文本文件只能存储char型字符变量。二进制文件可以存储char/int/short/long/float/……各种变量值。 - 每条数据的长度
文本文件每条数据通常是固定长度的。以ASCII为例,每条数据(每个字符)都是1个字节。进制文件每条数据不固定。如short占两个字节,int占四个字节,float占8个字节…… - 读取的软件不同
文本文件编辑器就可以读写。比如记事本、NotePad++、Vim等。二进制文件需要特别的解码器。比如bmp文件需要图像查看器,rmvb需要播放器……
操作系统对换行符(‘\n’)的处理不同(不重要)
文本文件,操作系统会对’\n’进行一些隐式变换,因此文本文件直接跨平台使用会出问题。
在Windows下,写入’\n’时,操作系统会隐式的将’\n’转换为”\r\n”,再写入到文件中;读的时候,会把“\r\n”隐式转化为’\n’,再读到变量中。 - 在Linux下,写入’\n’时,操作系统不做隐式变换。
二进制文件,操作系统不会对’\n’进行隐式变换,很多二进制文件(如电影、图片等)可以跨平台使用。
从存储方式来说,文件在磁盘上的存储方式都是二进制形式,所以,文本文件其实也应该算二进制文件。先从他们的区别来说,虽然都是二进制文件,但是二进制代表的意思不一样。打个比方,一个人,我们可以叫他的大名,可以叫他的小名,但其实都是代表这个人。二进制读写是将内存里面的数据直接读写入文本中,而文本呢,则是将数据先转换成了字符串,再写入到文本中。
要弄明白二者的区别,需要知道文件的读写过程。以读文件为例,
实际上是磁盘 >> 文件缓冲区>>应用程序内存空间这两个转化过程。我们说“文本文件和二进制文件没有区别”,实际上针对的是第一个过程;既然没有区别,那么打开方式不同,为何显示内容就不同呢?这个区别实际上是第二个过程造成的。
文件实际上包括两部分,控制信息和内容信息。纯文本文件仅仅是没有控制格式信息罢了;
实际上也是一种特殊的二进制文件。所以,我们很难区分二者的不同,因为他们的概念上不是完全互斥的。我们说文本文件是特殊的二进制文件,是因为文本文件实际上的解释格式已经确定了:ASCII或者unicode编码。文本文件的一个缺点是,它的熵往往较低,也就是说,其实本可以用更小的存储空间记录这些信息。比如,文本文件中的一个数字65536,需要用5个字节来存储;但是用二进制格式,采用int存储,仅仅需要2个字节。而二进制文件elf和bmp等,都往往有一个head,告诉你文件信息和解释方式。
记事本支持文本文件而不支持二进制文件,所以如果你用记事本打开文本文件那么一切正常,如果打开的是二进制文件就会出现乱码。但也有不乱码的地方,你会注意到那些地方都是字符编码的,而对于int、double等类型所对应的值都是乱码的,这是由于记事本只能够识别字符类型,而无法识别其他类型。
1、二进制文件是把内存中的数据按其在内存中的存储形式原样输出到磁盘上存放,也就是说存放的是数据的原形式。
2、文本文件是把数据的终端形式的二进制数据输出到磁盘上存放,也就是说存放的是数据的终端形式。
字符数据本身在内存中就经过了编码,所以无论是二进制还是文本形式都是一样的,而对于非字符数据来说,例如inti=10;如果用二进制来进行存储的话为1010,但是如果需要用文本形式来进行存储的话就必须进行格式化编码(对1和0分别编码,即形式为‘1’和‘0’分别对应的码值)。
3. 大端模式和小端模式详解
1.假设变量x类型为int,位于地址0x512处,x = 0x01234567.地址范围为0x512~0x515的字节。则
| 地址 | 0x512 | 0x513 | 0x514 | 0x515 |
|---|---|---|---|---|
| 大端法 | 01 | 23 | 45 | 67 |
| 小端法 | 67 | 45 | 23 | 01 |
| 即大端为高位在前,小端为地位在前。 |
2.理论
所谓的大端模式,是指数据的低位(就是权值较小的后面那几位)保存在内存的高地址中,而数据的高位,保存在内存的低地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
所谓的小端模式,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
下面这段代码可以用来测试一下你的编译器是大端模式还是小端模式:
short int x;
char x0,x1;
x=0x1122;
x0=((char*)&x)[0]; //低地址单元
x1=((char*)&x)[1]; //高地址单元
若x0=0x11,则是大端; 若x0=0x22,则是小端…
上面的程序还可以看出,数据寻址时,用的是低位字节的地址
Keil C51是大端模式,WINAVR GCC是小端模式,x86也是小端模式
11.2 文件的开、关、读、写
1. 文件的打开
文件在读或者写之前,必须要打开,读写完之后,必须要关闭,否则会造成文件内容不完整
fopen: 文件打开函数,fopen函数的调用方式:
//FILE *fp; //FILE是个结构;fp是指向结构FILE的指针变量
//fp = fopen (文件名,使用的文件的方式); //文件名 和 使用文件的方式 都是字符串
//fp = fopen("a.txt","r"); //使用只读方式读取a.txt的文件
//我们通过fopen语句告诉系统三个信息;
- 我们需要打开的文件名;
- 使用文件的方式,
- 让哪个指针变量指向被打开的文件。 这里是fp这个指针变量;
使用文件的方式 :

文件有个位置指针 fgetc
fopen也有打开失败的时候
2.文件的关闭(重要)
fopen成功之后才有关闭
关闭文件的原因:
- 释放该文件占用的内存单元
- 资源用完及时释放的好习惯
- 防止往文件中写内容时文件内容写入不全
写数据,系统不会直接写如磁盘,会先写入缓冲区,快满的时候将内容写入磁盘,然后清空缓存,自此再次写入。 关闭文件动作会触发系统把缓冲区中的数据立即
写入到磁盘上。
一般形式:
**fclose(文件指针);|**
文件关闭举例:
FILE *fp;
fp = fopen("a.txt,"r");
if(fp != NULL)
{
fclose(fp); //fp就是fopen()的返回值
}
3.文件的读写
字符读取函数 fgetc
fgetc() 的用法为:
int fgetc (FILE *fp);
fp 为文件指针,fgetc() 读取成功时返回读取到的字符,读取到文件末尾或读取失败时返回EOF
EOF 是 end of file 的缩写,表示文件末尾,是在 stdio.h 中定义的宏,它的值是一个负数,往往是 -1。fgetc() 的返回值类型之所以为 int,就是为了容纳这个负数(char不能是负数)。
EOF 不绝对是 -1,也可以是其他负数,这要看编译器的实现。
fgetc() 的用法举例:
char ch;
FILE *fp = fopen("D:\\demo.txt", "r+");
ch = fgetc(fp);
表示从d:\demo.txt文件中读取一个字符,并保存到变量 ch 中。
在文件内部有一个位置指针,用来指向当前读写到的位置,也就是读写到第几个字节。在文件打开时,该指针总是指向文件的第一个字节。使用 fgetc() 函数后,该指针会向后移动一个字节,所以可以连续多次使用 fgetc() 读取多个字符。
注意:这个文件内部的位置指针与C语言中的指针不是一回事。位置指针仅仅是一个标志,表示文件读写到的位置,也就是读写到第几个字节,它不表示地址。文件每读写一次,位置指针就会移动一次,它不需要你在程序中定义和赋值,而是由系统自动设置,对用户是隐藏的。
【示例】在屏幕上显示 D:\demo.txt 文件的内容。
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//如果文件不存在,给出提示并退出
if( (fp=fopen("D:\\demo.txt","rt")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//每次读取一个字节,直到读取完毕
while( (ch=fgetc(fp)) != EOF ){
putchar(ch);
}
putchar('\n'); //输出换行符
fclose(fp);
return 0;
}
在D盘下创建 demo.txt 文件,输入任意内容并保存,运行程序,就会看到刚才输入的内容全部都显示在屏幕上。
该程序的功能是从文件中逐个读取字符,在屏幕上显示,直到读取完毕。
其中while循环的的条件为(ch=fgetc(fp)) != EOF。fget() 每次从位置指针所在的位置读取一个字符,并保存到变量 ch,位置指针向后移动一个字节。当文件指针移动到文件末尾时,fget() 就无法读取字符了,于是返回 EOF,表示文件读取结束了。
对 EOF 的说明
EOF 本来表示文件末尾,意味着读取结束,但是很多函数在读取出错时也返回 EOF,那么当返回 EOF 时,到底是文件读取完毕了还是读取出错了?我们可以借助 stdio.h 中的两个函数来判断,分别是 feof() 和 ferror()。
feof() 函数用来判断文件内部指针是否指向了文件末尾,它的原型是:
int feof ( FILE * fp );
当指向文件末尾时返回非零值,否则返回零值。
ferror() 函数用来判断文件操作是否出错,它的原型是:
int ferror ( FILE *fp );
出错时返回非零值,否则返回零值。
需要说明的是,文件出错是非常少见的情况,上面的示例基本能够保证将文件内的数据读取完毕。如果追求完美,也可以加上判断并给出提示:
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//如果文件不存在,给出提示并退出
if( (fp=fopen("D:\\demo.txt","rt")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//每次读取一个字节,直到读取完毕
while( (ch=fgetc(fp)) != EOF ){
putchar(ch);
}
putchar('\n'); //输出换行符
if(ferror(fp)){
puts("读取出错");
}else{
puts("读取成功");
}
fclose(fp);
return 0;
}
这样,不管是出错还是正常读取,都能够做到心中有数。
字符写入函数 fputc
fputc 是 file output char 的所以,意思是向指定的文件中写入一个字符。fputc() 的用法为:
int fputc ( int ch, FILE *fp );
ch 为要写入的字符,fp 为文件指针。fputc() 写入成功时返回写入的字符,失败时返回 EOF,返回值类型为 int 也是为了容纳这个负数。例如:
fputc('a', fp);
或者:
char ch = 'a';
fputc(ch, fp);
表示把字符 ‘a’ 写入fp所指向的文件中。
两点说明
-
被写入的文件可以用写、读写、追加方式打开,用写或读写方式打开一个已存在的文件时将清除原有的文件内容,并将写入的字符放在文件开头。如需保留原有文件内容,并把写入的字符放在文件末尾,就必须以追加方式打开文件。不管以何种方式打开,被写入的文件若不存在时则创建该文件。
-
每写入一个字符,文件内部位置指针向后移动一个字节。
【示例】从键盘输入一行字符,写入文件。
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//判断文件是否成功打开
if( (fp=fopen("D:\\demo.txt","wt+")) == NULL ){
puts("Fail to open file!");
exit(0);
}
printf("Input a string:\n");
//每次从键盘读取一个字符并写入文件
while ( (ch=getchar()) != '\n' ){
fputc(ch,fp);
}
fclose(fp);
return 0;
}
运行程序,输入一行字符并按回车键结束,打开D盘下的 demo.txt 文件,就可以看到刚才输入的内容。
程序每次从键盘读取一个字符并写入文件,直到按下回车键,while 条件不成立,结束读取。
fputc 将一个字符输出到磁盘文件上去,
**fputc() : 将一个字符输出到磁盘文件上去,**
应用:
fputc(写入的内容,返回的指针); // 如果fputc函数失败,会返回EOF(-1);
//如果成功则返回值就是写入文件的ascii码值
fgetc();
EOF(End of file) -1; 失败
#include <stdio.h>
#include "string.h"
FILE *fp;
int main(){
//FILE *fp; //FILE是个结构;fp是指向结构FILE的指针变量
//fp = fopen (文件名,使用的文件的方式); //文件名 和 使用文件的方式 都是字符串
//fp = fopen("a.txt","r"); //使用只读方式读取a.txt的文件
fp = fopen("file.txt","w");
//此处是w,才可以写,如果是r的话,则不能写
//fp = fopen("c:\\windows\\file.txt","w");
//这个就是在目录下创建
if(fp == NULL){
printf("EOF");
}
else{
char reco = fputc('a',fp);
if(reco == EOF){
//Error;
}
reco = fputc('d',fp);
reco = fputc('e',fp);
fclose(fp);
}
}
fgetc :从指定文件读入一个字符
调用形式:
char reco = fgetc(fp);
//执行成功: 返回读入的字符
//执行失败: 返回EOF
fp = fopen("flie.txt","r); //文件刚打开,文件位置位于文件头部
if(fp == NULL)
{
//文件打开失败
}
else {
//成功
char reco = fgetc(fp); //每读出一个字符,文件指针自东向下走一个字符;
**while(!feof(fp)) //文件读入是否结束
// while(recp != EOF) //对文本文件这样写**
{
putchar(reco); //往屏幕上输出一个字符
reco = fgetc(fp);
}
fclost(fp); //关闭文件
}
feof(fp)
文件是否读结束。如果文件结束的话,feof(fp)函数返回1(真)。
如果文件没结束,则返回0(假)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-49KrX0Jm-1667100932205)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/d99fd232-ce12-4a29-b746-f1429a886364/Untitled.png)]
4.文件读写实战
代码严谨,不能出现纰漏
#include <stdio.h>
#include <string.h>
int main()
{
FILE* fp = fopen( "file.txt", "r" );
if( !fp )
{
printf("文件打开失败");
}
else
{
char LineBuf[1024]; //足够一行长度
while(!feof(fp))
{
LineBuf[0]=0; //第一个字符给0;相当于给这个清理成0 ;
if(fgets(LineBuf,sizeof(LineBuf)-1,fp) == NULL) //读取一行,遇到换行符结束。我们发现文件中是\r\n,但是fgets读进来只读了\n(换行),\r他给舍弃了。
//我们可以这样认为,在fgets中,\n就同时具有\r\n的能力,所以fget在读一行时,遇到\r就舍弃,只保留\n
continue;
if(LineBuf[0] == '\0') //文本文件中应该不会出现这种情况,但作为商业代码,这种判断加上为好,防止出意外;
{
continue;
}
lblprocstring:
if(strlen(LineBuf) > 0)
{
if(LineBuf[strlen(LineBuf)-1] == 10 || LineBuf[strlen(LineBuf)-1] == 13 ) //如果行尾是换行,回车等都截取掉
{
LineBuf[strlen(LineBuf)-1] = 0; //把这个设置为字符串结束标记0;
goto lblprocstring;
}
}
if(strlen(LineBuf) <= 0) //如果一个空行则会出现这种情形
continue;
printf("%s\n",LineBuf);
}
fclose(fp);
}
}
11.3 将结构体写入二进制文件再读出
1. 将结构体写入二进制文件
fwrite :用于向文件中写入数据,
一般形式:
fwrite(buffer,size,count,fp);
// buffer 指针/地址,要写到文件中的去的数据
// size 要写入的文件的字节数
// count 要写入多少个size字节的数据项;
// fp 这个是文件指针
// 返回值:如果fwrite石板,则返回0.否则返回count值。
#include <stdio.h>
#include <stdio.h>
struct stu
{
char name[30];
int age;
double score;
};
int main(){
struct stu student[2]; //2个元素的结构体数组
strcpy(student[0].name,"张三abc");
student[0].age = 21;
student[0].score = 92.1f;
strcpy(student[1].name,"李四");
student[1].age = 25;
student[1].score = 70.1f;
FILE *fp;
fp = fopen("structfile.bin","wb");
if(fp==NULL){
//失败;
}
else{
//成功
int result = fwrite(student,sizeof(struct stu)*2,1,fp);
fclose(fp);
}
return 0;
}
注意:
往文件里写的结构体,不要出现指针类型变量;
结构体内存对齐问题: 和编译器有关,为了提高运行效率,在linux中可能是4字节对齐的。

同平台同打开方式可以保证字节对齐
- 不要开平台使用
2. 强制无论在什么平台,都 1字节对齐,也就是不对齐
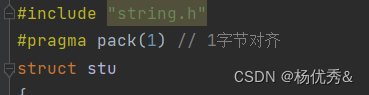
#include <stdio.h>
#include "string.h"
**#pragma pack(1) //按照一个字节来对齐**
struct stu
{
char name[30];
int age;
double score;
};
**#pragma pack() //不想对齐的时候用**
int main(){
int ilent = sizeof(struct stu); //48个字节,而不是42个字节
printf("%d\n",ilent);
struct stu student[2]; //2个元素的结构体数组
strcpy(student[0].name,"张三abc");
student[0].age = 21;
student[0].score = 92.1f;
strcpy(student[1].name,"李四");
student[1].age = 25;
student[1].score = 70.1f;
FILE *fp;
fp = fopen("structfile.bin","wb");
if(fp==NULL){
//失败;
}
else{
//成功
int result = fwrite(student,sizeof(struct stu)*2,1,fp);
fclose(fp);
}
return 0;
}
3. 从二进制文件中读出结构体数据
介绍一个新函数
fread
形式:
fread(buffer,size,count,fp)
// buffer 指针/地址,从文件中读出来的数据写到哪个地址去
// size 要读入的字节数
// count 要读入多少个size字节的数据项
// fp 文件指针
//返回值: 如果fread失败,则返回0. 否则返回count值。
#include <stdio.h>
#include "string.h"
#pragma pack(1)
struct stu
{
char name[30];
int age;
double score;
};
#pragma pack()
int main(){
struct stu
{
char name[30];
int age;
double score;
};
struct stu student[2];
strcpy(student[0].name,"张三abc");
student[0].age = 21;
student[0].score = 92.1f;
strcpy(student[1].name,"李四def");
student[1].age = 19;
student[1].score = 86.2f;
FILE *fp;
fp = fopen("structfile.bin","wb"); //文件名随意你就是写个structfile.txt也可以 ,这里注意,我们以wb方式打开文件,表示我们打开二进制文件
if(fp == NULL)
{
printf("文件打开失败");
}
else
{
int t = sizeof(stu);
//文件打开成功,向文件中写数据
int retresult = fwrite( &student, sizeof(struct stu), 2, fp ); //如果第二个参数写成sizeof(struct stu)*2 ,第三个参数写成1,也对
fclose(fp); //关闭文件
}
return 0;
}
















 2636
2636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











