



系列文章目录
用于时间序列预测的保形 PID 控制 NeurIPS 2023
1http://github.com/aangelopoulos/conformal-time-series
文章目录
摘要
我们研究时间序列预测的不确定性量化问题,目标是提供具有形式保证的易于使用的算法。 我们提出的算法建立在共形预测和控制理论的思想之上,能够在在线环境中前瞻性地对共形分数进行建模,并适应由于季节性、趋势和一般分布变化而出现的系统误差。 我们的理论既简化又加强了在线共形预测的现有分析。 对美国全州范围内的 COVID-19 死亡人数进行提前 4 周预测的实验表明,与 CDC 官方通信中使用的集合预报器相比,其覆盖范围有所改善。 我们还使用自回归、Theta、Prophet 和 Transformer 模型进行了预测电力需求、市场回报和温度的实验。 我们提供可扩展的代码库,用于测试我们的方法以及集成新算法、数据集和预测规则。1
http://github.com/aangelopoulos/conformal-time-series
提示:以下是本篇文章正文内容
**Conformal PID Control(共形PID控制)**是一种结合了传统PID控制和共形映射技术的先进控制方法。它旨在提高系统的鲁棒性和响应性能,特别适用于复杂和非线性系统。以下是对其原理和应用的详细解释:
1. PID控制器
PID控制器是工业控制中最常用的控制器之一,其基本形式包括三个部分:比例(P)、积分(I)和微分(D)。它们分别起到以下作用:
比例控制(P):根据当前误差进行调整,调节系统的输出以尽快减少误差。
积分控制(I):根据误差的累积进行调整,消除长期稳态误差。
微分控制(D):根据误差变化率进行调整,预测误差的趋势,从而减少过冲和振荡。
2. 共形映射
共形映射是一种数学变换,主要用于将一个复杂的几何形状转换为另一个简单的几何形状,同时保持角度和局部形状。这在控制系统中应用时,可以用于简化复杂的系统模型,使其更容易控制和分析。
3. Conformal PID Control的原理
Conformal PID Control将共形映射的概念引入PID控制,通过对系统的状态空间进行变换,使得复杂或非线性的系统行为在变换后的空间中变得更加线性和易于控制。其主要步骤包括:
系统建模:建立系统的数学模型,确定系统的非线性特性和动态行为。
共形映射设计:设计适当的共形映射,将原始系统状态空间转换为共形空间。在共形空间中,系统的非线性特性得到简化或线性化。
PID控制设计:在共形空间中设计传统的PID控制器。由于映射后的系统更加线性,PID控制器的设计和调节变得更加简单和有效。
逆映射应用:将控制器的输出通过逆共形映射转换回原始系统空间,驱动实际系统。
4. 应用及优势
Conformal PID Control在以下场景中具有显著优势:
复杂非线性系统:能够有效处理非线性系统,提高控制精度和响应速度。
鲁棒性需求高的系统:通过共形映射简化系统模型,提高系统的鲁棒性和稳定性。
多变量耦合系统:能够解耦系统的多个输入输出变量,提高控制效果。
5. 实际应用案例
机器人控制:在机器人运动控制中,Conformal PID Control可以处理复杂的运动学和动力学特性,提高机器人的定位精度和轨迹跟踪性能。
无人机控制:无人机的飞行控制涉及高度非线性的空气动力学模型,Conformal PID Control能够提高飞行稳定性和响应速度。
化工过程控制:在化工过程控制中,面对复杂的反应动力学和传质过程,Conformal PID Control可以提高过程控制的精度和稳定性。
总之,Conformal PID Control通过结合共形映射和PID控制的优点,提供了一种强大的工具来应对复杂和非线性系统的控制挑战。
一、引言
在生产系统中运行的机器学习模型经常会遇
到随时间变化的数据分布。 这可能是由于季节性和时间、上游机器学习模型的持续更新和再训练、用户行为的变化等因素造成的。 这些分布变化会降低模型的预测性能。 它们还使不确定性量化的标准技术失效,例如保形预测 [36, 35]。
为了解决分布变化的问题,我们考虑在对抗性在线环境中进行预测的任务,如[16]中所示。 在此问题设置中,我们观察到确定性协变量 x t ∈ X x_{t}\in\mathcal{X} xt∈X和响应 y t ∈ Y y_{t}\in\mathcal{Y} yt∈Y 的(潜在)对抗性时间序列,其中 t ∈ N = { 1 , 2 , 3 , … } {t\in\mathbb{N}}=\{1,2,3,\ldots\} t∈N={1,2,3,…}。 与标准共形预测一样,我们可以自由定义任何共形得分函数 s t s_{t} st: X × Y → R \mathcal{X}\times\mathcal{Y}\to\mathbb{R} X×Y→R,我们可以将其视为衡量时间 t 预测的准确性。 不失一般性,我们假设 st 是负向的(值越低意味着预测精度越高)。 例如,我们可以使用绝对误差 s t ( x , y ) = ∣ y − f t ( x ) ∣ , s_t(x,y)=|y-f_t(x)|, st(x,y)=∣y−ft(x)∣,其中 f t f_{t} ft 是根据截至时间 t 的数据(但不包括时间 t 的数据)进行训练的预测器。
顺序设置中的挑战如下。 我们寻求反转得分函数来构建共形预测集,
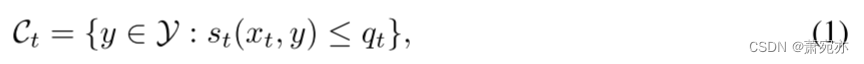
其中
q
t
q_{t}
qt 是时间 t 时得分
s
t
(
x
t
,
y
t
)
s_t(x_t,y_t)
st(xt,yt)分布的估计 1−α 分位数。 在标准保形预测中,我们将
q
t
q_{t}
qt视为
s
t
(
x
i
,
y
i
)
,
i
<
t
s_t(x_i,y_i),i<t
st(xi,yi),i<t 的 1 − α 级样本分位数(最多有限样本校正); 如果数据序列
(
x
i
,
y
i
)
,
i
∈
N
(x_i,y_i),i\in\mathbb{N}
(xi,yi),i∈N是 i.i.d. 或可交换,那么这将在每个时间 t 产生 1 − α 覆盖率 [35]。 然而,在不假设可交换性(或与此相关的数据的任何概率模型)的顺序设置中,选择(1)中的 qt 来产生覆盖范围是一项艰巨的任务。 事实上,如果我们不愿意对数据序列做出任何假设,那么只有使用简单的方法才能保证时间 t 的覆盖率,这些方法构造了无限大小的预测区间。
因此,我们的目标是及时实现长期覆盖。 也就是说,令
e
r
r
t
=
1
{
y
t
∉
C
t
}
,
\mathrm{err}_t=\mathbb{1}\left\{y_t\notin\mathcal{C}_t\right\},
errt=1{yt∈/Ct},我们希望实现,对于大整数 T,

在很少或没有假设的情况下,其中 o(1) 表示当 T →∞ 时趋向于零的量。 我们注意到,(2)根本不是概率性的,我们在本文中做出的每一个理论陈述都是确定性的。 此外,除了(2)之外,我们还寻求设计灵活的策略来产生可能的最清晰的预测集,该预测集不仅适应而且预测分布变化。
我们将我们提出的解决方案称为共形 PID 控制。 它将生成预测集的系统视为比例积分微分 (PID) 控制器。 在控制语言中,预测集采用控制变量
q
t
q_t
qt,然后生成过程变量
e
r
r
t
err_t
errt。 我们寻求将
e
r
r
t
err_t
errt锚定到设定点 α。 为此,我们根据输出误差 $g_{t}=\mathrm{err}_{t}-\alpha $对
q
t
q_t
qt进行修正。 通过用这种语言重新构建问题,我们能够构建具有更稳定覆盖范围的算法,同时也能够前瞻性地适应分数序列的变化,这与控制系统的风格非常相似。 参见图 1 中的示意图。
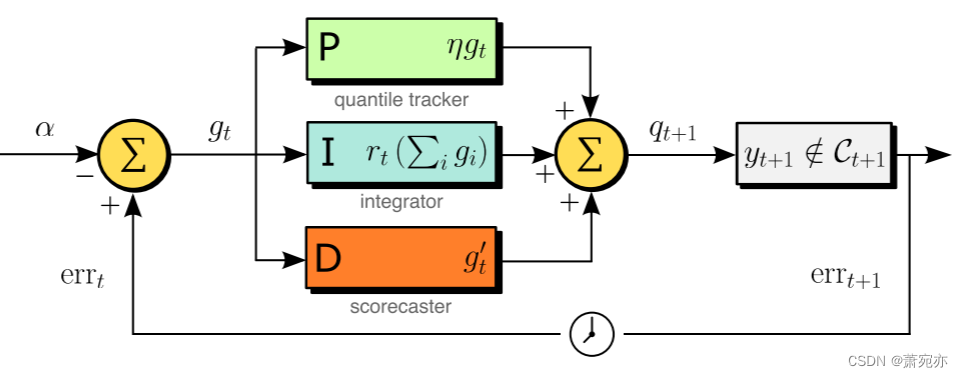
图 1:保形 PID 控制,以框图形式表示。
1.1 Peek at results: methods
我们的方法基于三个设计原则:
-
分位数跟踪(P 控制)。 对分位数损失(对所有过去的分数求和)运行在线梯度下降产生了一种我们称为分位数跟踪的方法,该方法在除了分数有界之外的任何假设下实现长期覆盖(2)。 该界限可能是未知的。 与自适应共形推理(ACI)[16]不同,分位数跟踪在一系列误覆盖事件之后不会返回无限集。 这可以看作等同于比例(P)控制。
-
误差积分(我控制)。 通过将覆盖误差的运行总和 ∑ i = 1 t ( e r r i − α ) \sum_{i=1}^t(\mathrm{err}_i-\alpha) ∑i=1t(erri−α)合并到在线分位数更新中,我们可以进一步稳定覆盖范围。 该误差积分方案在对分数没有任何假设的情况下实现了长期覆盖 (2)(它们可以是无界的)。 这可以看作等同于积分(I)控制。
-
计分(D 控制)。 为了解释分数的系统趋势(这可能是由于数据分布的各个方面(固定或变化)而导致的,这些方面是初始预测器未捕获的),我们训练第二个模型(分数预测器)来预测下一个分数的分位数 。 虽然分位数跟踪和误差积分仅仅是反应性的,但评分预测是前瞻性的。 它可以消除错误中的系统趋势,并在覆盖范围和效率(集合大小)方面带来实际优势。 这可以看作等同于微分(D)控制。 传统的控制理论建议使用线性近似 g t ′ = g t − g t − 1 g_{t}^{\prime}=g_{t}-g_{t-1} gt′=gt−gt−1,但在我们的问题中,我们通常会选择更先进的评分算法,这些算法远远超出了简单的差分方案。
这三个模块结合起来构成了我们的最终迭代,共形 PID 控制器:

在传统的 PID 控制中,人们将
r
t
(
x
)
r_{t}(x)
rt(x)视为 x 的线性函数。 这里,我们允许非线性并取 rt 为满足以下条件的饱和函数
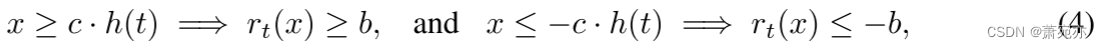 对于常数 b、c > 0 和次线性、非负、非递减函数 h,我们称满足这些条件的函数 h 为可接受的。 一个例子是正切积分器
r
t
(
x
)
=
K
I
tan
(
x
log
(
t
)
/
(
t
C
s
a
t
)
)
r_{t}(x)=K_{\mathrm{I}}\tan(x\operatorname{log}(t)/(tC_{\mathrm{sat}}))
rt(x)=KItan(xlog(t)/(tCsat)),其中我们设置
tan
(
x
)
=
s
i
g
n
(
x
)
⋅
∞
f
o
r
x
∉
[
−
π
/
2
,
π
/
2
]
\tan(x)=\mathrm{sign}(x)\cdot\infty\mathrm{for}x\notin[-\pi/2,\pi/2]
tan(x)=sign(x)⋅∞forx∈/[−π/2,π/2]是常数。 积分器
r
t
r_t
rt 的选择是用户的设计决策,记分器
g
t
′
g_t^{\prime}
gt′的选择也是如此。
对于常数 b、c > 0 和次线性、非负、非递减函数 h,我们称满足这些条件的函数 h 为可接受的。 一个例子是正切积分器
r
t
(
x
)
=
K
I
tan
(
x
log
(
t
)
/
(
t
C
s
a
t
)
)
r_{t}(x)=K_{\mathrm{I}}\tan(x\operatorname{log}(t)/(tC_{\mathrm{sat}}))
rt(x)=KItan(xlog(t)/(tCsat)),其中我们设置
tan
(
x
)
=
s
i
g
n
(
x
)
⋅
∞
f
o
r
x
∉
[
−
π
/
2
,
π
/
2
]
\tan(x)=\mathrm{sign}(x)\cdot\infty\mathrm{for}x\notin[-\pi/2,\pi/2]
tan(x)=sign(x)⋅∞forx∈/[−π/2,π/2]是常数。 积分器
r
t
r_t
rt 的选择是用户的设计决策,记分器
g
t
′
g_t^{\prime}
gt′的选择也是如此。
我们发现重新参数化 (3) 很方便,可以生成预测集 (1) 中使用的分位数估计
q
t
,
t
∈
N
q_t,t\in\mathbb{N}
qt,t∈N 序列,如下所示:
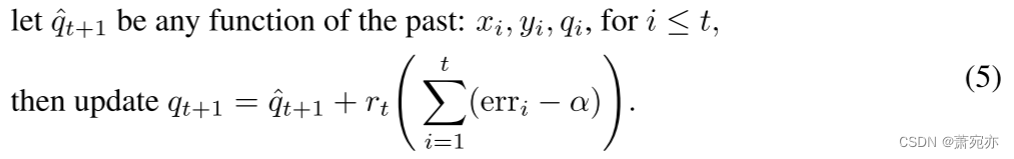
采用
q
^
t
+
1
=
η
g
t
+
g
t
′
\hat{q}_{t+1}=\eta g_{t}+g_{t}^{\prime}
q^t+1=ηgt+gt′可以恢复 (3),但我们发现考虑 (5) 中的公式通常很有用,这将是我们今后阐述的主要焦点。 现在我们将
q
^
t
+
1
\hat{q}_{t+1}
q^t+1 视为得分预测器,它使用过去的数据直接预测
q
t
+
1
{q}_{t+1}
qt+1。 本文的主要结果(其证明在附录 A 中给出)是,保形 PID 控制器 (5) 对于满足适当饱和条件的积分器
r
t
r_t
rt 和任何记分器
q
^
t
+
1
\hat{q}_{t+1}
q^t+1 的任何选择都产生长期覆盖。
定理 1. 令 { q ^ t } t ∈ N \{\hat{q}_{t}\}_{t\in\mathbb{N}} {q^t}t∈N 为 [−b/2, b/2] 中的任何数字序列,并令 { s t } t ∈ N \{s_{t}\}_{t\in\mathbb{N}} {st}t∈N 为输出为 [−b/2, b/] 中的任何得分函数序列 2]。 这里b>0,并且可能是无限的。 对于容许函数 h,假设 r t r_t rt 满足 (4)。 然后(5)中的迭代实现长期覆盖(2)。
强调一下,这个结果是确定性的,在数据 ( x t , y t ) (x_t,y_t) (xt,yt)、 t ∈ N t\in\mathbb{N} t∈N上没有概率模型。(因此,在序列是随机的情况下,结果适用于随机变量的所有实现。) 很快就会看到,这个定理可以看作是在线保形文献中现有结果的概括。
1.2 查看结果:实验
COVID-19 死亡预测。 为了在实践中证明适形 PID,我们考虑对 2020 年底到 2022 年底期间加利福尼亚州的 COVID-19 死亡人数进行提前 4 周的预测。我们使用的基本预测器 ft 是来自 COVID-19 预测中心的集成模型,该模型 是 CDC 关于 COVID-19 预测的官方沟通所使用的模型 [10, 29]。 在这个预测问题中,在每个时间 t,我们实际上试图预测在时间 t + 4 观察到的死亡人数 yt+4。
图 2 左侧面板显示了来自 Forecast Hub 集成模型的中央 80% 预测集,右侧面板显示了来自我们的共形 PID 方法的预测集。 我们使用分位数共形评分函数,如保形分位数回归[30],不对称地(即分别)应用于下分位数水平和上分位数水平)。 我们使用 tan 积分器,通过启发式选择常数(如附录 C 中所述),并使用 ℓ1 正则化分位数回归作为评分预测器,特别是,时间 t 的评分预测模型基于 t + 4 时间的分数预测分位数 美国所有 50 个州之前的所有预测、病例和死亡人数。 主要结论是,保形 PID 控制能够纠正 2020 年底/2021 年初冬季浪潮中持续低估的死亡人数。从图中我们可以看到,原始集合在 10 周内未能覆盖 8 次, 覆盖率达到 20%; 与此同时,保形 PID 在这段时间内只覆盖了 3 次,将覆盖率恢复到 70%(回想一下标称水平是 80%)。
这怎么可能? 该集合主要由成分预测者组成,为了简单性或计算的易处理性,这些预测者忽略了各州之间的地理依赖性[11]。 但新冠病毒感染和死亡表现出很强的时空依赖性,美国大多数州在相似的时间点经历了 2020 年底/2021 年初的冬季浪潮。 因此,记分员能够从美国其他州所犯的错误中吸取教训,以便前瞻性地调整整体对加利福尼亚州的预测。 其他州也可以看到类似的改进,我们在附录 F 中提供了纽约和德克萨斯州的实验示例,其中还提供了有关计分器和结果的更多详细信息。
电力需求预测。 接下来我们考虑新南威尔士州电力需求预测的数据集[18],其中包括1996年5月7日到1998年12月5日的半小时数据。对于基本预测器,我们使用 Transformer 模型[34],如 飞镖[19]。 仅每天重新训练,以批量预测一整天的需求; 由于计算成本较高,这是 Transformer 模型的标准方法。 对于保形分数,我们使用不对称(带符号)残差分数。 我们像以前一样使用 tan 积分器,并使用轻量级 Theta 模型 [2],在每个时间点(半小时)重新训练,作为记分器。
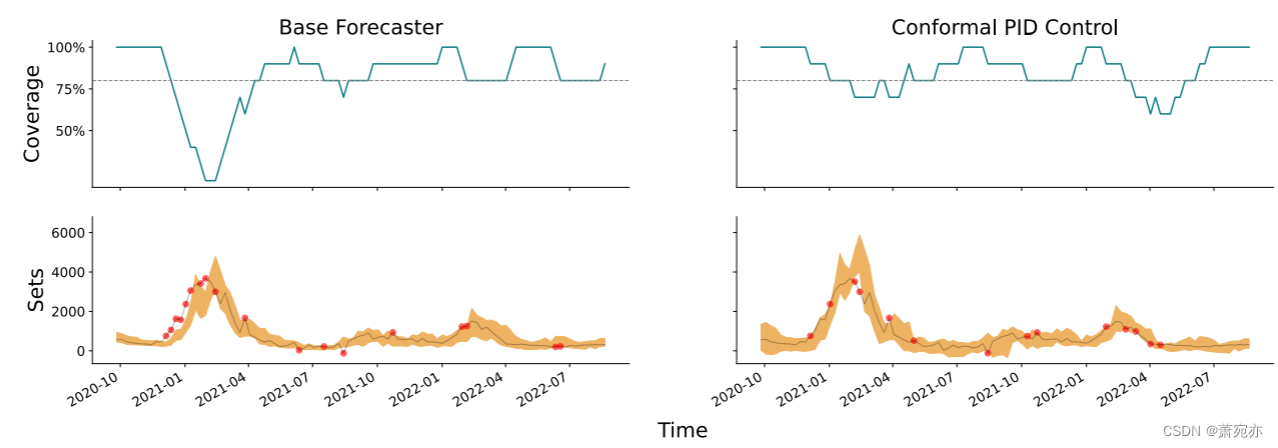 图 2:加利福尼亚州 4 周前的 COVID-19 死亡预测结果。 左列显示了 COVID-19 Forecast Hub 集成模型,右列显示了使用 tan 积分器的保形 PID 控制,以及由对所有 50 个州的所有过去预测、病例和死亡情况进行 ℓ1 惩罚分位数回归给出的记分器。 顶行绘制了 10 周跟踪窗口内的平均覆盖率。 标称覆盖水平为 1−α = 0.8,并用灰色虚线标记。 底行用金色绘制了预测集以及真实时间序列(死亡计数)。 误报事件用红点表示。 表 1 提供了覆盖率和平均集大小等汇总统计数据。
图 2:加利福尼亚州 4 周前的 COVID-19 死亡预测结果。 左列显示了 COVID-19 Forecast Hub 集成模型,右列显示了使用 tan 积分器的保形 PID 控制,以及由对所有 50 个州的所有过去预测、病例和死亡情况进行 ℓ1 惩罚分位数回归给出的记分器。 顶行绘制了 10 周跟踪窗口内的平均覆盖率。 标称覆盖水平为 1−α = 0.8,并用灰色虚线标记。 底行用金色绘制了预测集以及真实时间序列(死亡计数)。 误报事件用红点表示。 表 1 提供了覆盖率和平均集大小等汇总统计数据。
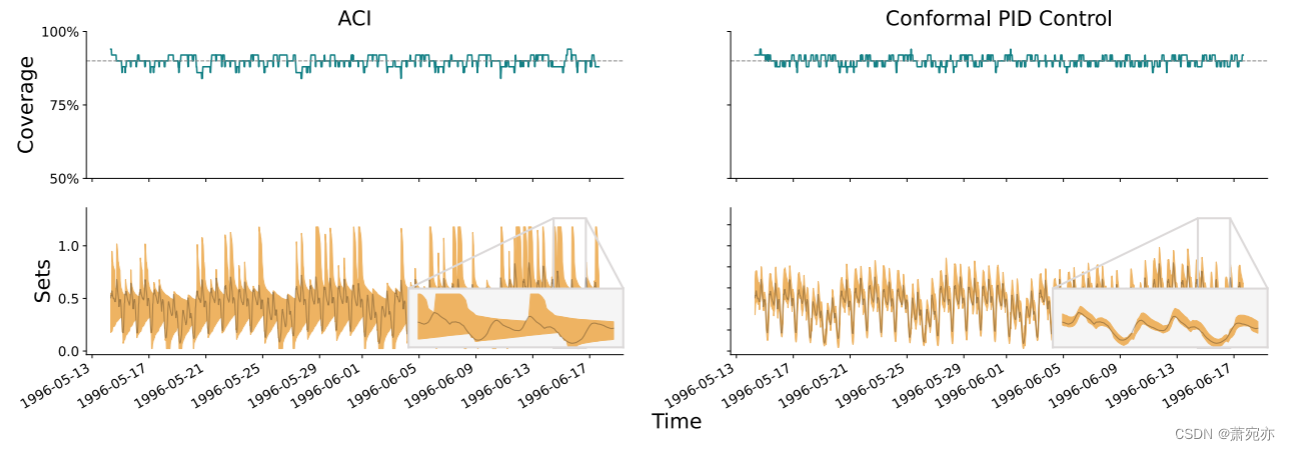
图 3:电力需求预测结果。 左列显示自适应共形推理 (ACI),右列显示共形 PID 控制。 基本预测器是 Transformer 模型,我们使用 tan 积分器和 Theta 计分器。 该图的格式遵循图 2 的格式,不同之处在于标称覆盖率现在为 1 − α = 0.9,并且覆盖率是在 50 个点的跟踪窗口上平均的(我们还省略了标记错误覆盖事件的红点)。 表 2 提供了汇总统计数据。
结果显示在图 3 的右图中,其中左图中还比较了自适应保形推理 (ACI) [16]。 简而言之,共形 PID 控制能够预测分数的日内变化,并生成紧密“拥抱”地面真实序列的集合; 它实现了紧密的覆盖,而不会生成过大或无限的集合。 改进的主要原因是记分器在其预测模型中内置了季节性成分; 一般来说,只有当基础预测器不完善时(就像这里的情况一样),才会出现如图 3 所示的大幅改进。
1.3 Related work
保形预测的对抗性在线观点是由 [16] 在首次介绍 ACI 的同一篇论文中首创的。 从那时起,人们在改进 ACI 方面开展了大量工作,主要是通过自适应地设置学习率 [17,40,7],并结合多重校准的思想来提高条件覆盖率 [5]。 值得注意的是,[7] 还观察到 ACI 迭代可以推广到跟踪分数序列的分位数,尽管他们的重点是自适应遗憾保证。 由于 ACI 和相关算法的自适应学习率主题已经被广泛研究,因此我们在当前论文中不考虑它。 任何这样的方法,例如[17, 7]中的方法,都应该与我们提出的算法结合起来很好地工作。
一项相关但独特的工作围绕对抗序列模型中的在线校准,其历史可以追溯到[14, 15],并以有趣的方式与博弈论和在线学习联系起来。 我们不会尝试对这些丰富而大量的文献进行全面的回顾,而只是强调[25,24,23]作为最近工作的一些有趣的例子。
最后,在在线环境之外,我们注意到一些研究人员对推广独立同分布之外的共形预测感兴趣。 (或可交换的)数据设置:包括[33,28,26,12,8],对于时间序列预测,特别是[9,31,38,39,3]。 所有这些论文的侧重点都截然不同,它们都依赖于对数据序列的概率假设来实现有效性; 我们在附录 B 中进行了进一步的讨论。
二、方法
我们从分位数跟踪器开始,一次一个地描述我们提案的主要组成部分。
2.1 分位数追踪
分位数跟踪的出发点是考虑以下优化问题:
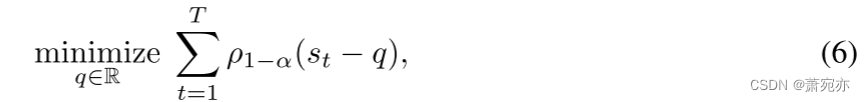
对于大 T,我们将测试点的得分缩写为
s
t
=
s
t
(
x
t
,
y
t
)
s_t=s_t(x_t,y_t)
st=st(xt,yt),
ρ
1
−
α
\rho_{1-\alpha}
ρ1−α表示第 1 − α 层的分位数损失,即
ρ
τ
(
z
)
=
τ
∣
z
∣
f
o
r
z
>
0
a
n
d
(
1
−
τ
)
∣
z
∣
f
o
r
z
≤
0.
\rho_{\tau}(z)=\tau|z|\mathrm{~for~}z>0\mathrm{~and~}(1-\tau)|z|\mathrm{~for~}z\leq0.
ρτ(z)=τ∣z∣ for z>0 and (1−τ)∣z∣ for z≤0.。后者是分位数回归中使用的标准损失 [22, 21]。 因此,问题 (6) 是一个简单的凸(线性)程序,用于跟踪分数序列 st, t ∈ N 的 1 − α 分位数。要了解这一点,请回想一下,对于连续分布的随机变量 Z,预期损失
E
[
ρ
1
−
α
(
Z
−
q
)
]
\mathbb{E}[\rho_{1-\alpha}(Z-q)]
E[ρ1−α(Z−q)]在 Z 分布的 1 − α 分位数水平上唯一最小化(在 q ∈ R 上)。
在顺序设置中,我们一次收到一个分数 st,一种自然而简单的方法是将在线梯度下降应用于 (6),并且学习率恒定 η > 0。这会导致更新:2
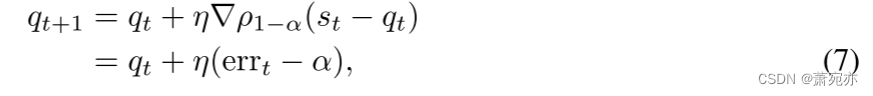
其中第二行如下:
∇
ρ
1
−
α
(
s
t
−
q
t
)
=
1
−
α
i
f
s
t
>
q
t
⟺
e
r
r
t
=
1
,
\nabla\rho_{1-\alpha}(s_{t}-q_{t})=1-\alpha\mathrm{if}s_{t}>q_{t}\iff\mathrm{err}_{t}=1,
∇ρ1−α(st−qt)=1−αifst>qt⟺errt=1,,并且
∇
ρ
1
−
α
(
s
t
−
q
t
)
=
−
α
i
f
s
t
≤
q
t
⟺
e
r
r
t
=
0.
\nabla\rho_{1-\alpha}(s_{t}-q_{t})=-\alpha\mathrm{if}s_{t}\leq q_{t}\iff\mathrm{err}_{t}=0.
∇ρ1−α(st−qt)=−αifst≤qt⟺errt=0. 请注意,(7) 中的更新非常直观:如果我们在最后一次迭代中错误覆盖(犯了错误),那么我们会增加分位数,而如果我们覆盖(没有犯错误),那么我们会减少分位数。
尽管非常简单,但分位数跟踪迭代(7)可以实现自己的长期覆盖,只要分数有界。
命题 1. 令 { s t } t ∈ N \{s_{t}\}_{t\in\mathbb{N}} {st}t∈N为 [−b, b] 中的任意数字序列,其中 0 < b < ∞ . 0<b<\infty. 0<b<∞.。 那么分位数跟踪迭代(7)满足
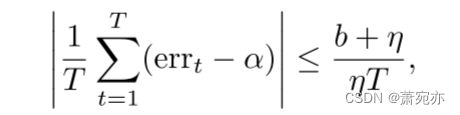
对于任何学习率 η > 0 且 T ≥ 1。特别是,(7) 产生如 (2) 中的长期覆盖率。
有几点评论是有必要的。 首先,虽然命题 1 假设分数有界,但我们不需要知道这个界限就可以运行 (7) 并获得长期覆盖率。 对于任何有限的 b,只要分数位于 [−b, b] 中,保证就会通过——显然,分位数跟踪器会以不可知的方式进行,并在任何情况下执行相同的更新。 值得注意的是,自适应共形推理算法可以表示为分位数跟踪器的特例; 详细信息参见附录B.1。
其次,对于学习率,在实践中,我们通常将 η 启发式设置为尾随窗口 B ^ t = max { s t − Δ + 1 , … , s t } . \hat{B}_{t}=\operatorname*{max}\{s_{t-\Delta+1},\ldots,s_{t}\}. B^t=max{st−Δ+1,…,st}.上最高得分的一部分。 在这个尺度上,设置 η = 0.1 B ^ t \eta=0.1\hat{B}_{t} η=0.1B^t通常会得到很好的结果,除非另有说明,我们在所有实验中都使用它(我们还将窗口长度 Δ 设置为与训练初始基础的老化期的长度相同) 预测者和评分者)。3 极高的学习率会导致集合不稳定,而极低的学习率可能无法跟上分数分布的快速变化。
2.2 误差积分
误差积分是迭代之后分位数跟踪的推广:
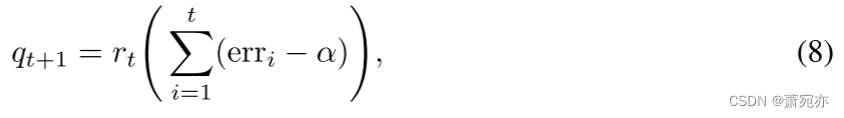
其中
r
t
r_t
rt 是饱和函数,对于容许函数 h 满足 (4) ; 回想一下,我们使用“可接受”来表示非负、非递减和次线性。 正如我们在(13)中看到的,分位数跟踪器使用恒定阈值函数 h,而现在允许 h 增长,只要它是次线性增长的,即
h
(
t
)
/
t
→
0
a
s
t
→
∞
h(t)/t\to0\mathrm{as}t\to\infty
h(t)/t→0ast→∞时。 非恒定阈值函数 h 可能是理想的,因为这意味着
r
t
r_t
rt 会“饱和”(将满足 (4) 中右侧的条件),因此对覆盖误差的修正将不那么频繁地发生,并且 从这个意义上说,沿着序列可以容忍更大程度的覆盖误差。
下一个命题,特别是它的证明,使 h 的作用更加精确。 重要的是,命题2足以证明定理1。
命题 2. 令
{
s
t
}
t
∈
N
\{s_t\}_{t\in\mathbb{N}}
{st}t∈N 为 [−b, b] 中的任意数字序列,其中 b > 0,并且可以是无限的。 对于容许函数 h,假设
r
t
r_t
rt 满足 (4)。 那么误差积分迭代(8)满足
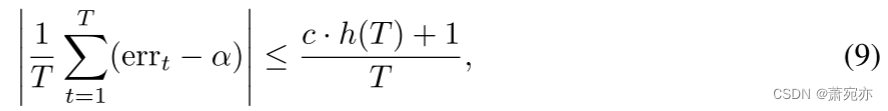
对于任何 T ≥ 1,其中 c 是 (4) 中的常数。 特别是,这意味着(8)产生长期覆盖率(2)。
饱和函数的选择本质上对应于自适应学习率的选择; 详细信息请参见附录 D。
2.3 Scorecasting
最后要讨论的是计分。 计分器尝试利用基础预测器未捕获的任何剩余信号直接预测 q t + 1 q_{t+1} qt+1。 这就是(5)中\hat{q}_{t+1}所扮演的角色。 当难以修改或重新训练基础预测器时,评分可能特别有用。 当基础预测器的训练计算成本很高时(例如,在 Transformer 模型中),就会发生这种情况; 或者它可能发生在复杂的操作预测管道中,在这些管道中频繁更新预测实施是不可行的。 计分可能有用的另一种情况是预测员和计分员可以访问不同级别的数据。 例如,如果公共卫生机构从外部团体收集流行病预测,并形成整体预测,那么该机构可能可以获得更细粒度的数据,用于重新校准整体的预测集(与数据粒度级别相比) 最初授予预报员)。
这就激发了将评分作为一个模块化层的需求,该层位于基础预测器的“顶部”,并消除了评分分布中的系统误差。 通过回顾,如上所述(遵循命题 2),这种直觉变得更加精确,如 (5) 中的评分与误差积分相结合只是误差积分 (8) 的重新参数化,其中 q t ′ = q t − q ^ t q_t'=q_t-\hat{q}_t qt′=qt−q^t 和 s t ′ = s t − q ^ t s_t^{\prime}=s_t-\hat{q}_t st′=st−q^t 分别是新的分位数和新的分数。 执行良好的记分器可以减少分数的变异性,使它们更具可交换性,从而产生更稳定的覆盖范围和更严格的预测集,如图 3 所示。另一方面,信号很少或没有信号的激进记分器实际上可能会造成伤害 通过向新的得分序列 s t ′ , s_t^{\prime}, st′,添加方差,这可能会导致更不稳定的覆盖范围和更大的集合。
我们可以为评分模型选择的内容没有限制。 我们可能希望使用一个可以同时纳入季节性、趋势和外生协变量的模型。 常见的选择是 SARIMA(季节性自回归综合移动平均)和 ETS(误差趋势季节性)模型,但还有许多其他可用的方法,例如 Theta 模型 [2]、Prophet 模型 [32] 和神经网络预测器; 请参阅[20]进行评论。
2.4 Putting it all together
简而言之,我们重新审视 PID 视角,回顾一下分位数跟踪、误差积分和评分预测如何相互配合和结合使用。 返回到 (3) 会有所帮助,我们在此再次复制该内容:
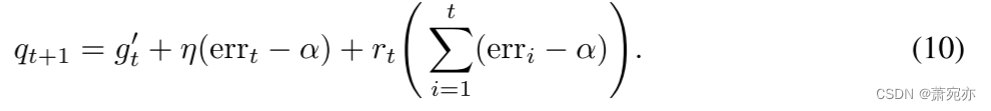
分位数跟踪是通过取
g
t
′
=
q
t
a
n
d
r
t
=
0
g_{t}^{\prime}=q_{t}\mathrm{~and~}r_{t}=0
gt′=qt and rt=0精确给出的。这可以看作等价于 P 控制:从 (10) 两边减去 qt 并将增量
u
t
+
1
=
q
t
+
1
−
q
t
u_{t+1}=q_{t+1}-q_{t}
ut+1=qt+1−qt视为 过程变量; 那么在这个修改后的系统中,分位数跟踪正是 P 控制。 因此,我们在接下来的实验中使用“共形 P 控制”来指代分位数跟踪器。 类似地,我们使用“共形 PI 控制”来指代选择
g
t
′
=
q
t
,
a
n
d
r
t
≠
0
g_{t}^{\prime}=q_{t},\mathrm{and}r_{t}\neq0
gt′=qt,andrt=0 作为通用积分器(对我们来说,tan 是默认值)。 最后,“保形PID控制”是指让
g
t
′
g_{t}^{\prime}
gt′为通用评分器,
r
t
≠
0
r_{t}\neq0
rt=0为通用积分器。
三、实验
除了引言中描述的全州范围内的 COVID-19 死亡预测实验之外,我们还对以下数据集和预测器的所有组合进行了实验。

在除 COVID-19 预测数据集之外的所有情况下,我们: 在每个时间点重新训练基础预测器; 使用不对称(有符号)残差分数构建预测集; 并使用 Theta 模型作为记分器。 对于 COVID-19 预测设置,我们: 使用给定的集成模型作为基础预测器(根本没有训练); 使用不对称分位数得分构建预测集; 并使用 ℓ1 惩罚分位数回归作为评分器,拟合从之前的预测、病例和死亡中得出的特征,如引言中所述。 最后,在所有情况下,我们都对积分器使用 tan 函数,并使用启发式选择的常数,如附录 C 中所述。
我们选择在下面的小节中显示的结果旨在说明关键概念点(方法之间的差异)。 其他结果显示在附录 G 中。我们的 GitHub 存储库 https://github.com/aangelopoulos/conformal-time-series 提供了全套评估。
3.1 ACI 与分位数跟踪
我们预测 2006 年至 2014 年亚马逊 (AMZN) 每日开盘股价。 我们在对数空间中进行此操作(因此预测股票的回报)。 图 4 比较了 ACI 和分位数跟踪器,每个跟踪器都有其默认学习率:ACI 为 η = 0.005,分位数跟踪为 η = 0.1 ˆBt。 我们看到每种方法的覆盖范围都不错,但在 1 − α = 0.9 的标称水平附近剧烈振荡(ACI 通常具有较大的振荡)。 因此,图 5 增加了每种方法的学习率:对于 ACI,η = 0.1,对于分位数跟踪器,η = 0.5 ˆBt。 我们现在看到两者都提供了非常严格的覆盖范围。 然而,ACI 通过频繁返回无限集来实现这一点; 与此同时,分位数跟踪器对集合所做的修正远没有那么激进。
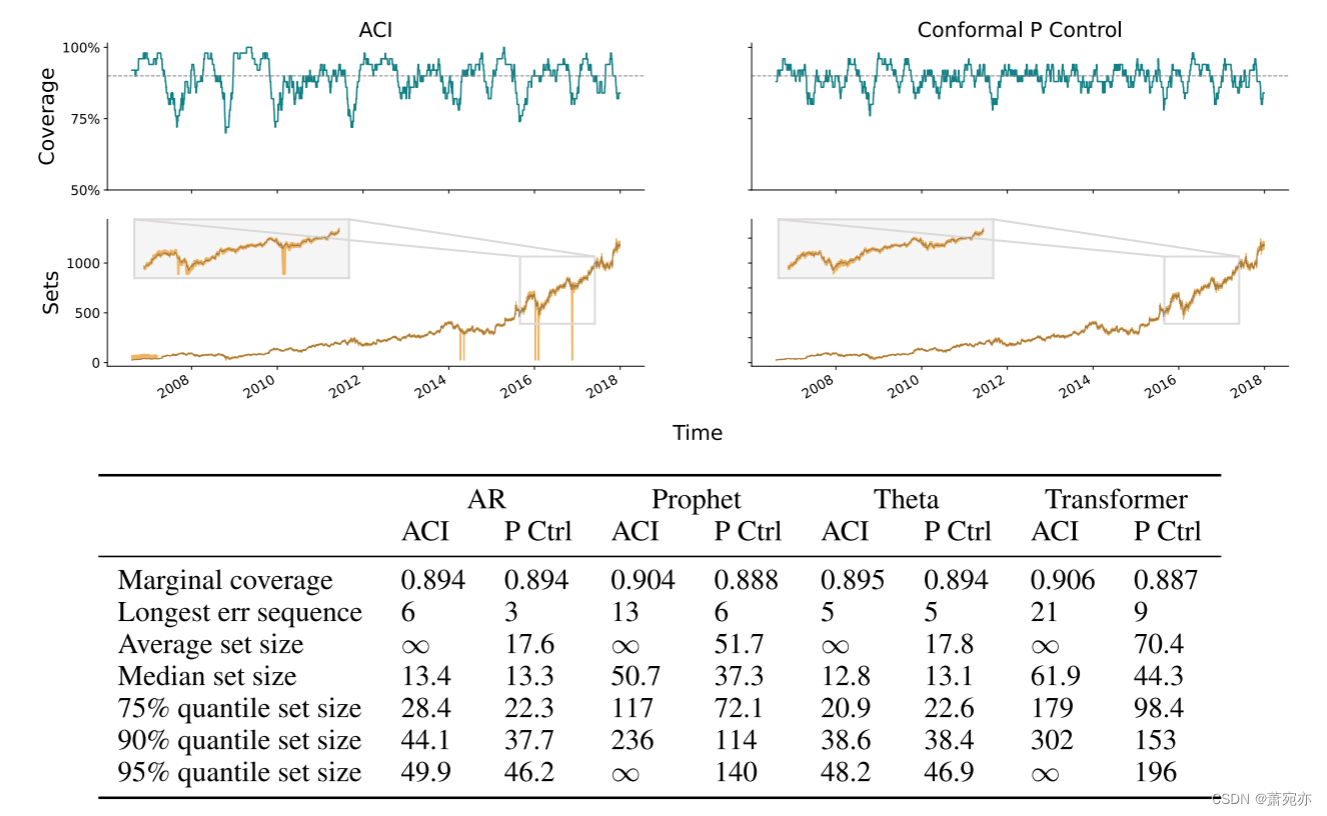
图 4:预测亚马逊股票回报的结果,比较 ACI 和分位数跟踪(P 控制)。 图中显示 AR 作为基础预测器; 该表总结了所有四个基本预测器的结果。 我们对 ACI 和分位数跟踪使用默认学习率:分别为 η = 0.005 和 η = 0.1 ˆBt。
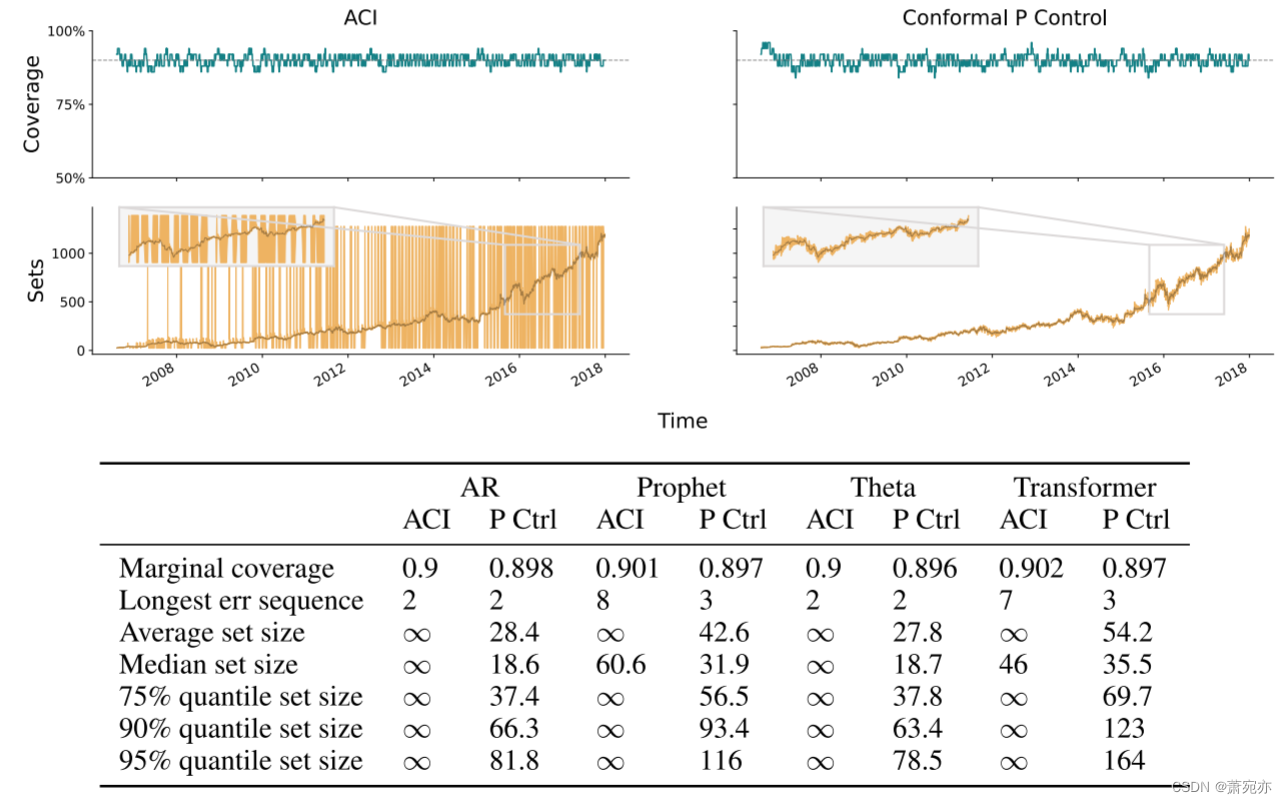
图 5:如图 4 所示,但 ACI 和分位数跟踪的学习率更大:分别为 η = 0.1 和 η = 0.5 ˆBt。
作为最后的比较,在附录 E 中,我们修改了 ACI,以不允许它们成为无限的方式来剪辑集合。 这种启发式方法可能会被想要防范无限集合的从业者使用,但它不再对有界或无界分数提供有效性保证。 附录中的结果表明分位数跟踪器具有与此过程类似的覆盖范围,并且通常具有较小的集合。
3.2 The effect of integration
接下来,我们预测 2006 年至 2014 年 Google (GOOGL) 每日开盘股价(同样在对数空间中进行)。 图 6 比较了有和没有附加积分器组件的分位数跟踪器(P 控制与 PI 控制)。 我们故意选择一个非常小的学习率, η = 0.01 ˆBt,以展示积分器如何稳定覆盖范围,它在大多数时间序列中都做得很好。 PI 控制的覆盖范围在接近序列末尾时开始更加振荡,我们至少部分地将其归因于积分器测量所有时间累积的覆盖范围误差这一事实,并且在长序列结束时,边际覆盖范围可以 即使局部覆盖范围偏差更大,仍然接近 1 −α。 这可以通过使用本地版本的积分器来解决,这是我们在讨论中返回的想法。
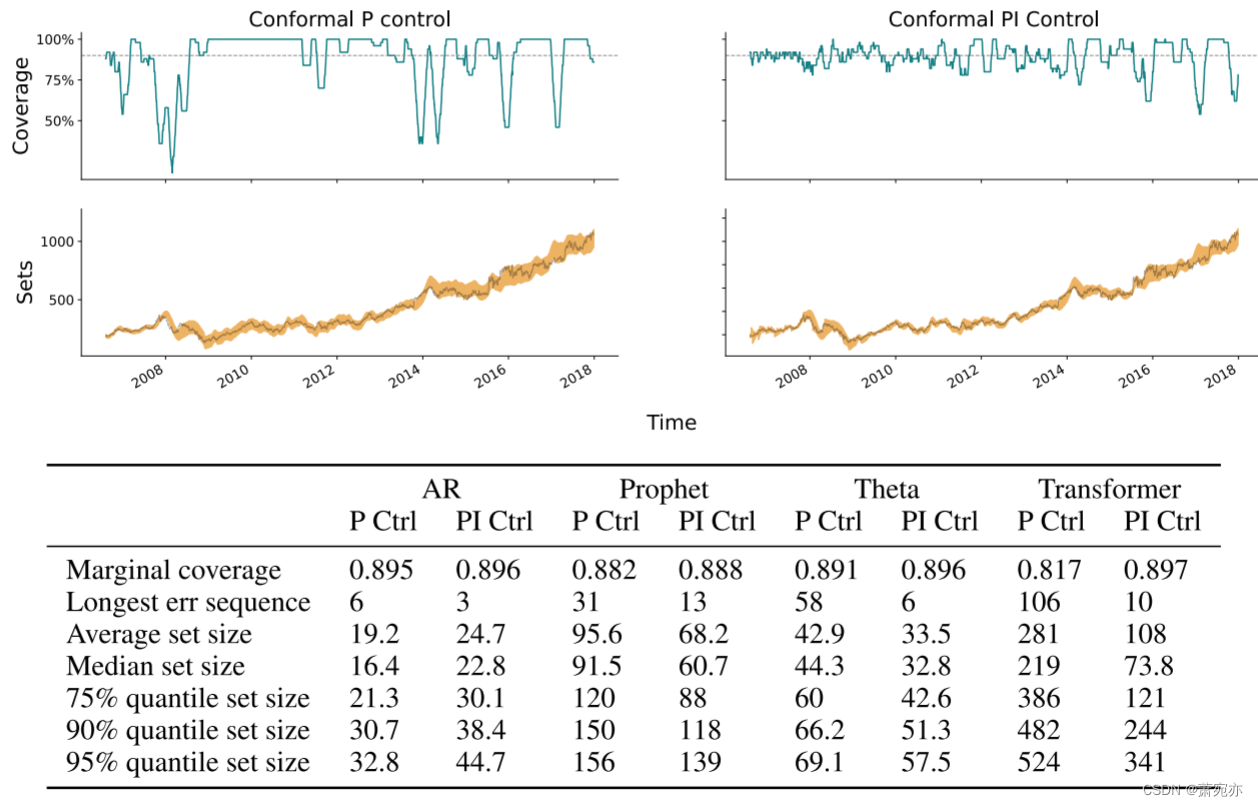
图 6:预测 Google 股票回报的结果,比较使用和不使用积分器的分位数跟踪(P 控制与 PI 控制)。 图中显示 Prophet 是基础预报员; 该表总结了所有四个基本预测器的结果。 我们特意使用非常小的学习率,η = 0.01 ^ Bt,以展示积分器如何稳定覆盖范围。
3.3 评分效果
图 2 和图 3 已经展示了计分播报在覆盖范围和集大小方面显着改进的示例。 回想一下,在这些设置中,基础预测器会产生具有可预测趋势的错误(分数)。 附录 F 中给出了 COVID-19 预测设置中的更多示例,这些示例显示出与评分类似的优势。
我们强调,记分并不总是有帮助。 在某些设置中,计分可能会在新的计分序列中引入足够的方差,从而导致覆盖范围或集合的稳定性降低。 (例如,如果我们在一系列独立同分布的分数上运行高度复杂的记分器,而没有任何趋势,就会发生这种情况。)在实践中,应该谨慎设计记分器,就像设计一个基础预测器一样; 使用“开箱即用”的计分技术不太可能足够强大,尤其是在高风险问题中。 附录 G 提供了一些示例,其中使用通用 Theta 模型在所有设置上运行的评分广播可能会造成损害(例如,它在亚马逊数据设置中的某些实例中增加了覆盖范围和设置的明显差异)。
四、讨论与扩展
讨论。 我们的工作提出了一个在时间序列中构建预测集的框架,该框架类似于(实际上在形式上等效)PID控制,包括分位数跟踪(P控制),它只是应用于分位数损失的在线梯度下降; 误差积分(我控制)以稳定覆盖范围; 和评分(D 控制)以消除评分中的系统趋势(基础预测员所犯的错误)。
我们发现,在我们的实验中,分位数跟踪和积分的结合始终能产生稳健且良好的性能。 如果分数中存在可预测的趋势(并且计分器设计良好),则计分器会提供额外的好处,就像我们的一些示例中的情况一样。 否则,评分可能会增加可变性,并使覆盖范围和预测集更加不稳定。 总体而言,设计记分器(包括甚至选择使用记分器)是一个重要的建模步骤,就像基本预测器的设计一样。
值得强调的是,除了 COVID-19 预测示例外,我们的实验旨在说明性,我们并不打算使用最先进的预测器,或包含任何和所有可能相关的特征 预言。 此外,虽然我们发现使用启发式方法设置常数(例如学习率 η 和 tan 积分器的常数
C
s
a
t
C_{sat}
Csat,
K
I
K_I
KI)效果很好,但我们相信更严格的技术,如 [17, 7], 可以用来以在线方式自适应地调整这些。
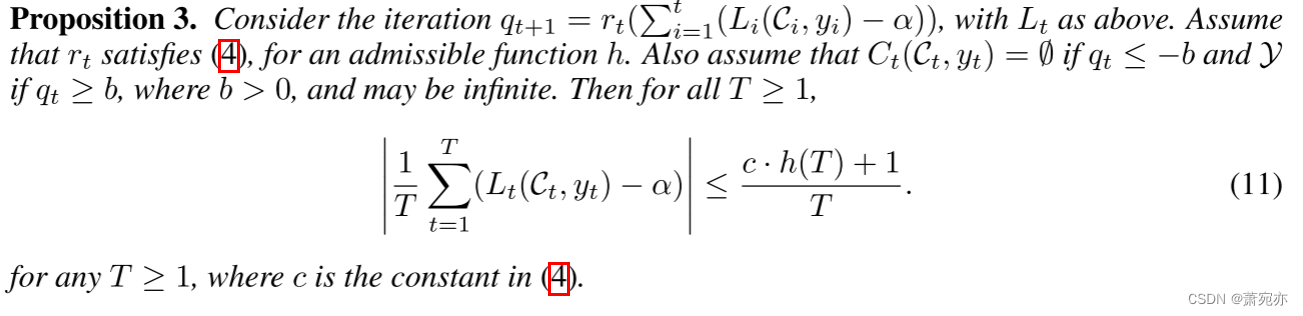
我们简短地总结说,我们相信许多其他扩展是可能的,特别是在积分器方面。 从广义上讲,我们可以选择以内核加权的方式进行集成,
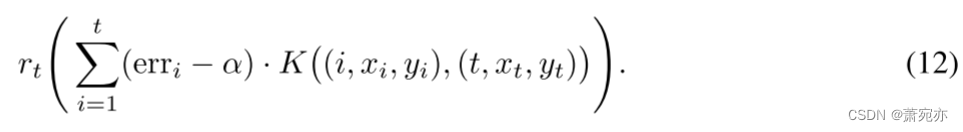
作为一种特殊情况,如果 t−i ≤ w,内核可以简单地分配权重 1,否则分配权重 0,这将导致积分器聚合长度为 w 的尾随窗口的覆盖范围。 这有助于在长序列中持续维持更好的局部覆盖。 作为另一个特殊情况,内核可以根据 xi 和 xt 是否位于 X 空间的某些预定义分箱中的同一个箱中来分配权重,这对于组结构问题(我们需要按组覆盖)可能很有用 。 内核的各种其他选择和形式也是可能的,并且考虑以多分辨率风格将多个这样的选择(12)组合在一起以实现最终的分位数更新将是很有趣的。

















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









