






作者:刘平,徐浩文,陈哲康,张圣林,杨家海,裴丹||清华大学,南开大学,鹏城实验室,北京国家信息科学技术研究中心
摘要:微服务调用链路(调用链)的异常通常表明基于微服务的大型软件服务的质量正在受到损害。然而,及时、准确地检测调用链异常非常具有挑战性,原因是:1)底层微服务数量众多,2)它们之间复杂的调用关系,3)响应时间和调用路径之间的相互依赖性。我们的核心思想是利用机器学习在周期性的离线训练中自动学习调用链的整体正常模式。在在线异常检测中,一个新的异常值较小的调用链(根据学习的正常模式计算)被认为是异常的。我们的无监督异常检测系统(名称:TraceAnomaly)利用我们新的链路表示和带后验流的深贝叶斯网络设计,能够准确、稳健地统一检测出链路异常。TraceAnomaly已经被部署在S公司的18项在线服务上。对包含数百个微服务的4个大型在线服务和包含41个微服务的测试平台进行了详细的评估,结果显示,追踪异常的召回率和精度均高于0.97,优于现有的方法(硬编码规则)19.6%和7.1%,和其他七个基线平均57.0%和41.6%。
关键词:调用链;异常检测;微服务
1 介绍
近年来,微服务[1]体系结构在基于web的大型服务中越来越流行,但它对保证服务的可靠性提出了新的挑战。这种体系结构将Web服务解耦为多个微服务。例如,本文在S公司(服务数千万用户的中国数字银行)研究的四项大型在线服务包含61 - 344项微服务(见表一)。图1的顶部显示了一个用S表示的服务。该服务由许多微服务组成,其中一些微服务可能调用其他外部服务(例如,银行的支付服务)。每个微服务都可以单独升级,从而支持更敏捷的软件开发和部署,但由于复杂的调用关系和大规模,使得故障排除更具挑战性。
故障诊断基于微服务的Web服务的一个重要步骤是检测异常(例如,意外响应时间或调用路径),当它们第一次出现在微服务调用链(由远程过程调用(RPC)链路框架(如谷歌Dapper[2])记录)时。如果检测到异常调用链,操作人员将通过调用链定位根本原因来分析微服务。图1显示了如何收集一个特定用户请求的简单真实调用链。当接收到用户请求时,Web服务将生成一个UUID(通用唯一标识符),唯一标识该用户请求的所有消息(如图1中的UUID-1)。当微服务m调用微服务n时,m向n发送一个调用消息(记为call(m→n))。n处理完成后,n向m发送响应消息(表示为response(n→m))。这两个消息都通过RPC框架在m和n之间路由,因此链路机制可以使用时间戳和uuid自然地记录这些消息。具有相同uuid的所有消息构成一个微服务调用链路(以下简称链路)。图1中的表显示了UUID1的真实链路。注意,对外部服务的调用消息不会通过RPC框架,因此不会受到监视。

图1:一个调用链案例。第一列是基于时间戳的消息顺序。第一次呼叫信息的发送时间(消息 )以及最后一次响应消息的接收时间(消息)没有采集,用“-”表示。
由于链路数据相对较新,就我们所知,业内部署的异常检测方法仍然是基于手工规则的。在调用结束后,每个微服务将返回反映微服务运行状态的代码。因此,操作人员根据这些返回码设计了一些固定的规则来检测踪迹异常。然而,Web服务可能包含数百个微服务(例如,S公司中的service -1包含344个微服务,请参见表I),而且这些微服务返回代码的值和意义可能会随着时间而变化,这使得基于规则的维护非常困难。
为了解决这些问题,我们提出了链路异常算法(TraceAnomaly),该算法可以自动学习复杂的轨迹模式,当异常轨迹的模式偏离正常轨迹的模式时,可以检测到异常轨迹。
A 相关工作
文章Multimodal LSTM[3]提出了一个多模态长短期记忆(LSTM)模型来学习正常链路中响应时间和调用的顺序性质。如果链路的模式偏离了习得的正常模式,那么链路就是异常的。然而,我们在§第五章中的评估表明,这种方法在以端到端方式学习响应时间和调用路径之间的关系方面存在困难,因此其性能会受到影响。此外,这种方法缺乏对异常链路的可解释性:即,哪些调用路径是异常的,或者哪些微服务的响应时间是异常的。文章AEVB[4]只关注道的响应时间异常。提出了一种无监督深度贝叶斯网络模型来检测链路数据的响应时间异常。但是,这种方法为每个微服务训练一个模型,如果其中一个组成微服务的响应时间被检测为异常,那么链路就被认为是异常的。因此,它的训练开销太高:如果一个大型服务包含数百个微服务(例如表I中的service -1),那么需要训练数百个模型。
由于在遗留软件服务中收集链路数据的困难(服务的框架需要更改),之前的一些工作[5]-[8]首先从系统日志文件中提取日志键,然后根据日志键构造链路。基于wfg基的[5]方法通过一个离线学习工作流图(WFG)来检测链路异常,WFG是一个有限状态自动机(FSA)模型。如果链路不能被WFG接受,则会出现执行路径异常。同时,基于wfg基的[5]方法使用3-sigma方法检测WFG中每个转变的时间消耗异常。基于CFGbased[6]方法通过一个离线学习控制流图来检测痕迹的异常。如果在预期的时间间隔内没有看到父节点的子节点,则链路是异常的。基于cpd的[7]方法通过检测不同线路控制流图之间的相似性来检测异常。相似度是根据下一个符号的条件概率分布来计算的。当链路的相似性太小时,链路就是异常的。DeepLog[8]采用基于LSTM的神经网络模型检测执行路径异常。它还为每个节点训练一个LSTM模型,以检测时间消耗异常。

图2: s公司一个小型在线服务无异常的痕迹响应时间分布。该服务仅包含三个微服务,三个轴分别表示三个微服务的响应时间。
B 挑战、核心理念和贡献
虽然上述相关工作[3]-[8]已经在文献中提出,但由于高开销和/或低精度,没有一个在现实中部署(详见 第五章),我们现在提出主要的挑战以及我们的核心思想和主要贡献。
挑战1和我们的核心思想:统一异常检测的响应时间和链路的调用路径。我们面临这样的挑战的原因是:
(1)微服务的响应时间可以在不异常的情况下发生显著变化。图2显示了一个小型在线服务在没有异常情况下的痕迹响应时间分布。尽管该服务中只有三个微服务,但响应时间差异很大。对于微服务,它的响应时间由自身和从入口微服务到它的调用路径决定。例如,图1中的微服务e以不同的响应时间(见图4)被调用了两次,这使得AEVB[4]中的微服务标准建模无效。这要求响应时间建模必须考虑从服务入口到微服务的调用路径。然而,个人路径的数量大(例如,数以百计的一个服务,还有数以百计的服务公司S)。这种规模使它不可行直接应用现有时间序列异常检测路径分别因为这些算法要么要求运营商手动为每个路径选择算法和优化参数[9]-[27],或需要一个专门的学习模式为每个路径[28],[29]。
(2)异常链路与正常链路可能具有相同的结构,只有响应时间的差异才能帮助区分它们(详细示例如图6所示)。
(3)当检测到异常链路时,需要快速定位链路的根本原因。因此,统一的方法必须可解释,以帮助操作符本地化根本原因,而多模态LSTM[3]无法做到这一点。
上述困难需要一种异常检测方法,该方法在链路级别统一链路的响应时间和调用路径,而不是单独的节点、边缘或路径级别。但是,以往大多数工作[4]-[8]、[30]都没有尝试统一的检测方法。虽然Multimodal LSTM[3]尝试了一种统一的检测方法,但它对异常链路缺乏可解释性,并且难以学习响应时间和调用路径之间的关系。
我们的核心思想是将服务的每个链路都视为一个训练样本,并使用机器学习来捕获服务链路的总体模式。因此,我们对每个服务都有一个模型,而不是AEVB[4]中的每个微服务都有一个模型。为此,我们将服务中链路的响应时间和调用路径编码为一个向量(以下简称服务链路向量机或STV),这是大多数成熟的深度学习算法所必需的。编码的信息不仅要表现出轨迹的整体模式,而且要易于被操作人员解释以进行根本原因定位。实际上,我们的可解释服务链路向量使我们能够开发一个简单但有效的根源定位算法。这就是为什么我们选择手工制作具有物理意义的服务链路向量设计,而不是使用网络/图表示学习(嵌入)[3]来自动学习不容易解释的向量。
挑战2和我们的核心理念:设计一个准确、健壮、无监督的学习架构,捕捉复杂的痕迹模式的特征,合理的训练开销。如挑战1中所述,微服务的响应时间与自身及其调用路径相关。对于包含许多微服务的单个服务,可能有数百条独立路径,因此需要了解数百条响应时间分布的调用路径。在如此复杂的情况下,需要一个高容量模型。此外,由于异常标签无法在如此复杂的背景下获取,且数据量庞大,我们不得不使用无监督算法。以上要求需要一个无监督的高容量模型,如深度贝叶斯网络。模型也应该是稳健的,因为它的性能是不敏感的超参数。我们解决这一挑战的核心思想是应用后流[31],它可以使用非线性映射来增加贝叶斯网络中潜在变量的复杂性,使模型能够以稳健、准确和无监督的方式捕获复杂模式。
我们的思路:(图3)我们提出的TraceAnomaly系统将每个链路作为一个整体处理,构建一个服务链路向量,对调用路径和响应时间进行编码(如图4中右表中的信息),然后在离线训练期间学习服务的总体正常链路模式。然后,在在线异常检测中,对于每一个新的链路,根据学习到的服务模型计算一个异常分数,得分小的链路视为异常。最后,采用基于服务链路向量的算法对异常链路的根本原因进行定位。
本文的贡献总结如下:
贡献1:我们提出一个新颖的方法来构造特征向量的链路服务,称为服务链路矢量(STV),既有效地编码的响应时间信息和调用路径信息链路、服务水平,使有效学习,准确的链路级别的异常检测,有效的定位在微服务级别。我们认为,除了本文提出的链路异常检测和定位算法外,STV还可以作为其他基于mlb的链路表示。
贡献2:我们提出了TraceAnomaly,这是一种无监督深度学习算法,可以学习服务中的复杂链路模式,并准确检测链路异常,利用我们的链路表示和我们设计的带后后流的深贝叶斯网络。TraceAnomaly已经部署在S公司的18项在线服务上,为数千万用户提供服务,据我们所知,这是第一个部署的基于机器学习的链路异常检测方法。
贡献3:详细评估包含数百个微服务和TrainTicket[32]实验包含41个微服务的四大在线服务,表明TraceAnomaly的查全率和查准率都高于0.97,优于现有的方法(硬编码规则)19.6%和7.1%,和其他七个基线平均57.0%和41.6%。此外,我们还开放了TraceAnomaly的原型[33],以帮助研究人员更好地理解我们的工作。
贡献4:我们提出了一种基于我们设计的服务链路向量的根源定位算法,该算法成功地在四个大型服务的所有73条异常链路上定位了正确的根源,在测试结果中,其定位精度比三个基线高出55%。

图3:TraceAnomaly构造。实线表示离线流,虚线表示在线流。
本文的其余部分组织如下。第二章给出了TraceAnomaly的总体设计,服务链路向量构造的细节和根源定位算法。第三节介绍了带后验流的深度贝叶斯网络的设计。第四章展示了部署的细节。第五章展示在四个大型在线服务和一个测试平台上评估TraceAnomaly。第六章评估和分析trace异常的内部机制。第七章总结了本文。
2 TraceAnomaly概述,服务链路向量构造和定位算法
本节首先介绍了TraceAnomaly的总体设计,然后介绍了如何为服务构造服务链路向量(STV)。最后,给出了STV设计的根源定位算法。
A TraceAnomaly总体架构
图3为示踪异常的结构。在对服务进行离线训练时,使用第二章-C中所示的方法,训练轨迹被编码为向量,用x表示。然后,这些向量被输入到我们设计的深度贝叶斯网络中,以学习分布p(x)(参见第三章),并生成一个模型。为适应潜在的服务升级,将定期对该模式进行再训练。
在在线检测过程中,每条新轨迹都被编码为一个矢量。如果一个链路包含一个以前看不见的调用路径(参见第二章-C), TraceAnomaly将其声明为一个异常。看不见的调用路径由白名单方法处理(参见第四章 -B)。如果没有看不见的调用路径,然后训练模型输出一个可能性,即logp(˜x)为每个向量,并使用它作为异常分数。如果一个链路的异常分数太小,就会被考虑为异常,定位算法可以定位出产生异常轨迹的根本原因。
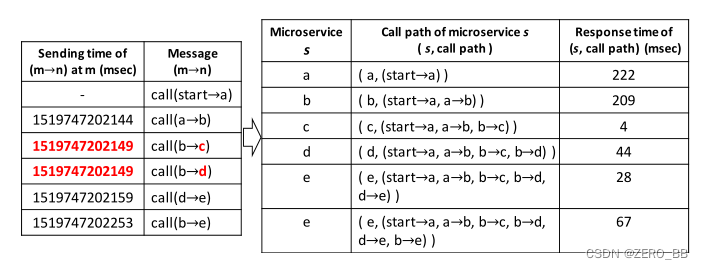
图4:调用路径提取示例(图1中的轨迹)。
B 从链路中提取调用路径和响应时间
为了解决挑战1,我们服务链路向量的设计目标是,可以从服务链路向量数据中了解给定服务链路的响应时间模式和调用路径模式。为了捕获链路中可能影响微服务响应时间的“发生了什么”,我们建议调用路径。
链路中微服务的调用路径,记为(s,callpath),是调用s之前的调用消息序列(按发送时间排序)。图4显示了在trace中提取每个微服务的调用路径的过程,其中一个调用消息表示为(m→n)。首先,所有的呼叫信息都按发送时间排序。如果两个调用消息具有相同的发送时间,则按照调用的id对它们进行排序(以确保顺序的唯一性)。如图4左半部分所示,调用(b→c)和调用(b→d)发送时间相同,然后按字母顺序对两种调用信息进行排序(c优先于d)。其次,对于一个“微服务”n,其呼叫消息序列从业务入口呼叫消息开始,到当前呼叫消息(m→n)结束,该消息表示被调用微服务n的调用路径。图4为从图1的轨迹中提取的呼叫路径。
(s,callpath)的响应时间rt可以计算为rt = srt−rct,其中rct为s的调用消息接收时间,srt为对应响应消息发送时间。例如,在图4中,微服务b的响应时间(209ms)是使用message 2 (图1中的1519747202146)和message11(图1中1519747202355)的发送时间注意,图4中右表的最后两行显示了微服务 e的两个不同调用路径可以有不同的响应时间。
C 服务链路(STV)架构
现在我们将介绍将调用链(trace)编码为服务链路向量(STV)的细节。我们选择基于我们关于trace的领域知识手工设计向量(参见第二章-B),而不是应用表示学习,因此得到的向量具有物理意义,因此是可解释的。我们认为,除了本文提出的链路异常检测和定位算法外,STV还可以作为其他基于mlb的链路表示。
在周期训练时间之前(如图3所示),通过第二章-B中所示方法提取服务的训练trace的所有调用路径。所有唯一调用路径的集合形成了服务的调用路径列表。考虑到大量的训练trace数据,我们假设所有现有的“正常”调用路径都被我们在训练期间构造的调用路径列表所覆盖。因为训练集是在周期性训练时更新的,所以调用路径列表也是周期性更新的。随着在线服务的发展,调用路径列表中的历史无效调用路径将消失,新的调用路径将出现。
一个特定链路的STV是用调用路径列表构造的。如图5所示,调用路径列表中的每个(s, callpath)都是STV的维度ID,每个维度的值为对应的响应时间(s, callpath)。如果调用路径列表中的a (s, call path)不包含在特定链路中,则将不包含的(s, callpath)对应的维数设为-1,表示特定链路的STV的无效维数;否则,其值不是-1的维是有效维。在在线检测期间,如果一个新链路的调用路径不在调用路径列表中,那么该调用路径是一个看不见的调用路径,由白名单方法处理(参见第四章-B)。
总之,通过调用路径,调用路径自然编码在STV的维度ID中,每个维度的值是特定链路中的响应时间。上述编码方法使TraceAnomaly能够统一调用路径模式和响应时间模式。请注意,对于相同的服务,两个trace可能具有相同的“结构”(即节点和边),只有响应时间的差异才能帮助区分正常trace和异常trace。如图6所示,trace t1和trace t2的结构相同,t1是正常的,因为它对该服务的业务逻辑需要这样的结构,t2是异常的,因为运行时微服务e出现了一些故障。图6中的表格显示了响应时间的差异。STV编码可以通过将t2声明为异常来自然地处理这个问题。

图5:STV构建过程。
D 根源定位
对于给定服务C中的异常调用链t,在我们的上下文中,其根本原因被定义为t的STV的维度ID,例如,元组(s, callpath),其中callpath为微服务s的调用路径,s是C中的一个有问题/失败的内部微服务,或者一个微服务(在C中)调用一个有问题的/失败的外部服务(没有直接监控)(例如,图1中的微服务e调用一个外部服务S2)。以上两种根本原因对操作人员都非常有帮助。根本原因可以由失败的微服务 s和相应的调用路径清楚地解释。一旦确定了根本原因,操作人员就可以只关注这个(s, callpath),进一步(可能手动)找出确切的根本原因(代码中的错误、错误配置等)。
我们的根本原因定位算法是由服务链路向量(STV)的明确物理意义启用的(每个维度ID是一个调用路径,每个维度的值是一个响应时间),在详细介绍算法之前,首先介绍了同构服务链路向量(STV)的概念。如果trace tx的STV与trace ty的STV具有相同的有效维度(参见§II-C),那么ty的STV就是tx的HSTV,反之亦然。图7显示了HSTV的示例。
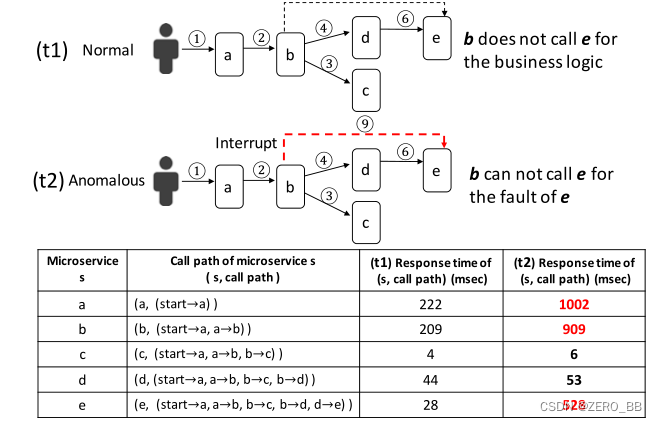
图6:trace t1与t2结构相同,但t1正常,t2异常。
当在线检测到异常调用链t时,TraceAnomaly检查训练集,找出所有的调用链,其STV都是t的STV的hstv。对于一个有效维数d (t),我们计算所有发现的HSTVs维d值的平均值和标准偏差(std)。如果t的STV中的d维值大于mean + 3∗std或小于mean - 3∗std,那么t的STV的d维是一个异常维。由于响应时间异常本质上是从调用方传播到调用方,因此根源的上游(直接或间接调用)的所有响应时间也会出现响应时间异常。因此,给定t, t的STV中会有多个异常维数,包括根源维数及其上游维数。在这些异常维数中,调用路径最长的维数自然地反映了响应时间的传播规律,因此我们的算法将其作为异常维数的根本原因。如图7所示,检测到三个异常维度(图7中的维度1、2、6),其中调用路径最长的维度为正确的根本原因,见维度6。如果没有找到HSTV,链路t可能有调用路径异常(例如,调用中断)。然后TraceAnomaly找到trace t的最长调用路径和调用路径列表中的所有调用路径之间的最长公共路径(参见第二章-C)。最长公共路径和最长公共路径的下一个称为微服务可能是根本原因。
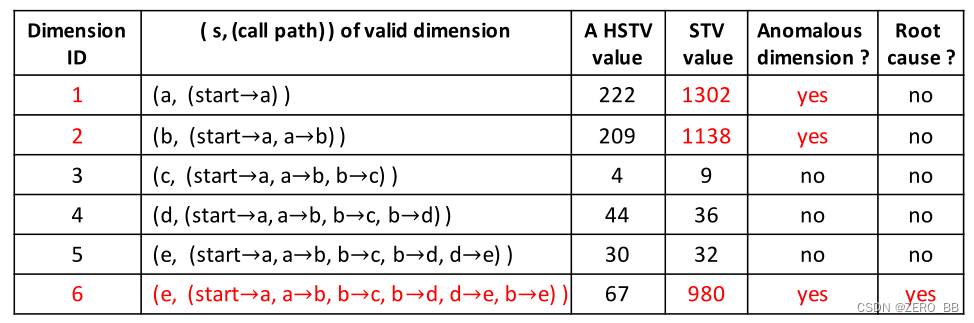
图7:从一个真正的异常轨迹定位根本原因的示例。根本原因是微服务b调用微服务e时微服务e的响应时间异常。
3 异常检测算法设计
本节介绍了训练和检测的设计,并解释了如何解决第一章-B中提到的挑战2。
A 学习数据的分布
可变自动编码器(VAE)是一个潜在概率模型[34]。通过引入一个辅助潜变量z和先验,VAE拟合p(x)的数据分布,式中θ为模型的参数。pθ(z)通常是单位高斯分布的N(0,I)。pθ(x|z)在文中是一个对角线高斯N(µθ(z),σ2θ(z)I),其中µθ(z) 和σθ(z)是神经网络学习的参数。
VAE通常是通过变分逼近技术来学习的,引入一种分离的变分后验分布qφ(z|x)来近似计算难解的真后验pθ(z|x)。然后通过最大化ELBO L(φ, θ)来训练VAE,logpθ(x)的下界:
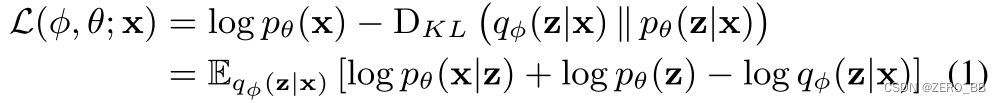
利用重要抽样[35]进行蒙特卡罗积分是计算pθ(x) 的一种常用方法。从qφ(z|x)中抽取Lz样本,记为z(l),则计算pθ(x)为:
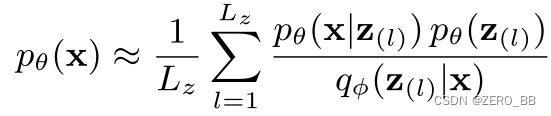
对qφ(z|x)来说,准确地估计 pθ(z|x)是至关重要的。qφ(z|x)越接近 pθ(z|x), L(φ, θ)越靠近下限(因此更好地训练logpθ(x)),更好的拟合pθ(x)[35],在VAE中qφ(z|x)选择成为对角高斯分布 N(µφ(x),σ2φ(x)I) 是不够的[31], [36],一种更好地近似pθ(z|x)的方法,是使用一个流变换后qφ(z|x),而不是使用对角高斯分布。通过在对角高斯函数q0φ(z|x) = N(µφ(x),σ2φ(x)I)上应用一个可逆映射 z0= fφ(z),可以得到一个更灵活的后侧qφ(z0|x) = qφ(z|x)|det(∂f(z)/∂z)|−1,从而有能力较好地近似pθ(z|x)[31]。
在本文中,我们选用了一种改进版的Glow’s flow[37]。
B 模型架构
我们的模型设计如图8所示。x为服务轨迹向量,z和z(k)为潜在变量。将业务轨迹向量x送入变分网中,通过隐含层 hφ(x)获取隐含特征。然后利用这些特征,得到z(0)的平均模组µz(0)和σz(0)的标准差:µz(0) = Wµz(0)hφ(x) + bµz(0),σz(0) = SoftPlus(Wσz(0)hφ(x) + bσz(0))+ ξ,其中SoftPlus(a) = log(1+exp(a)),应用于a的每个元素上,Wµz(0), bµz(0), Wσz(0)和 bσz(0)是需要学习的网络参数。ξ是一个小的常量向量,选择为σz(0)式中的最小值,可以避免训练中出现数值问题(见§III-C),[28]中采用的方法就是这样。z(0)是从N(µz(0),σ2z(0)I)的采样,然后通过长度为K的后验流,得到z(K)。
将输出z(K)作为潜在变量z,输入生成网,经过隐藏层 hθ(z),再次获得隐藏的特征。然后,使用这些特性来导出 x的平均值µx和标准偏差的σx,就像z(0)一样。重构后的x从N(µz(0),σ2z(0)I)取样。
重新参数化技巧[34]应用于初始z(0)。由于Glow’s flow[37]是连续的和确定性的映射,整个模型可以看作只有一个重新参数化的潜在变量:

这大大减少了我们推导第三章-C中的训练目标和第三章-D中的检测输出的付出。

图8:我们的模型架构
C 训练
用SGVB[34]直接训练我们的模型很简单,直接通过最大化训练数据上的ELBO L(φ, θ;x):
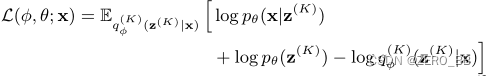
在实际部署中,训练数据是从大量的链路数据中获取的。我们的异常检测必须是无监督的,但是训练数据可能包含一些异常痕迹。然而,我们的观察和假设是,在轨迹中有一些异常。我们用随机梯度下降(SGD)训练我们的模型,它可以自然地容忍罕见的异常。它根据输入数据的小批样例更新模型参数,因此只捕获数据分布的最重要模式。
D 异常检测
为了检测一个服务链路向量是否异常,我们对模型使用其对数似然,即logpθ(x)。如第三章-A所述,通过重要性抽样可以计算出公式(3):

判断一条调用链异常的标准是该调用链的图形与正常调用链的图形有显著差异。这个标准可以量化为logpθ(x)的差值。
因此,如果调用链的logpθ(x)值明显小于正常调用链的 logpθ(x)值,调用链是异常的,我们使用核密度估计(KDE)[38]来学习正态痕迹的分布,而不是手动设置一个阈值来分割正态痕迹和异常痕迹。如果一个轨迹的 logpθ(x)不以高概率跟随学习分布,则该轨迹为异常轨迹。我们使用统计假设检验中广泛使用的 p值[39]来判断trace的l logpθ(x)是否遵循经过训练的KDE模型。我们设置p-value的显著性水平为0.001,这是一个常用的值。
4 实现和部署
A 在线服务部署
TraceAnomaly已经在S公司的18个真正的在线服务上部署了大约两个月,图9显示了部署中的数据管道。
1)数据采集模块从不同的数据中心采集RPC日志数据,然后将采集到的日志数据推送到Kafka[40]中,这是一个被广泛使用的开源分布式流媒体平台,用于构建实时数据管道和流处理应用。
2)批量聚合模块从Kafka获取日志数据,然后定期聚合,提取链路数据。
3)将原始的日志数据和trace数据存储到Ceph[41]数据库中,供离线训练模块使用(TraceAnomaly是无监督的,训练时不需要标注)。为适应可能出现的服务升级,根据最后一天的trace,每天00点对模型进行再训练。每天的训练时间平均为1.5小时。我们在S公司有3个特斯拉P40 gpu,因此模型最多可用于3种服务(每一种服务)并行训练。在训练一个新的模型之后,训练好的模型和调用路径列表(见第二章-C)被存储在Ceph中,然后在线检测模块被更新。
4)在线检测直接从Kafka获取日志数据,进行实时链路聚合,然后使用最新的模型对服务进行检测,检测服务中的异常,这些异常存储在MySQL数据库中。离线训练模块和在线检测模块可以插入不同的方法进行并行检测,以促进我们在§第五章 -B和§第六章-A中评估基线和替代方法。根据我们的评测,一个链路链的平均检测开销仅为0.004秒。对于一个每天有800,000次链路链的服务,每天的总检测开销只有3200秒,这对S公司来说是可以接受的。
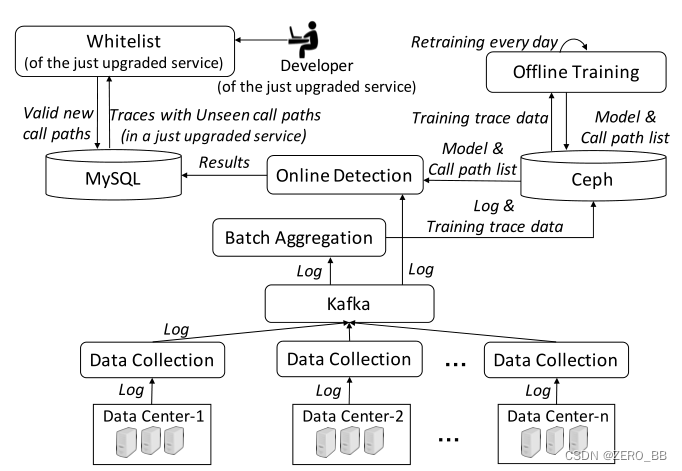
图9:S公司部署的数据管道
B 处理看不见的调用路径
现在,我们将介绍如何处理在服务升级后由于看不见的调用路径而引起的假警报。如果一个服务升级引入了以前未见过的调用路径,这些调用路径将在白天充分积累,并将在第二天被每日重新训练的模型自动视为“新常态”。需要解决的问题是,如何在日常再训练之前处理错误警报。我们使用一种简单的白名单方法解决这个问题,如图9左上角所示。升级服务的开发人员是发起升级的人,因此,他们被要求手动验证由TraceAnomaly检测到的以前看不见的调用路径。这些经过验证的新调用路径被存储在一个白名单中,这样在下次日常再训练之前就不会再为它们发出警报。请注意,对于开发人员来说,实际中手工验证的开销并不大,因为(1)是由开发人员编写代码来生成新的调用路径,(2)在我们的实践中,看不见的调用路径的数量非常少。实际上,在两个月的部署期间,我们观察到每天未见的调用路径的平均总数为约为4个服务。因此,验证开销是可以接受的。
5 评估
在本节中,我们将介绍来自S公司和一个试验台的四个大型在线服务(如表I所示)的评估。1)第五章 -A中介绍了我们的评估方法。2)第五章 -B描述了基线。3)评价结果见第五章-C。4)第五章 -D分析了对硬编码规则方法的改进。5)第五章 -E评估根本原因定位算法。6)第五章 -F总结了追溯异常对S公司故障排除的影响。

表一:S公司四大评估服务的详细情况
A 评价方法
为了评估目的,理想情况下,我们应该将每个trace标记为“异常”或“正常”,以获得真相。然而,手工标记在线服务trace数据(每个服务每天有数十万trace)是不可行的。因此,我们选择先构建一个测试平台,生成精确标记的trace进行评价,然后选择性能更好的方法进行大规模在线评价。
1)实验的评估:我们选择了一个基准测试微服务系统,即TrainTicket[32]作为我们的测试平台。TrainTicket是一种基于微服务架构的火车票订票系统,包含41个微服务。每个微服务都部署在Docker[43]容器上。
通过模拟随机访问TrainTicket不同功能的不同用户请求,生成用于评估的trace。我们模拟了一天的训练数据流量,包括40个高峰时段和大约38万个正常trace。图10显示了模拟流量中每1分钟的访问次数。请注意,虽然这些用于训练trace是在没有任何有意注入异常的情况下收集的,但是由于偶然的系统故障,仍然有少数链路是异常的。
为了获得测试集,我们用类似于训练集的模拟流量逐个向41个微服务注入异常。在现实中,异常更可能发生在高峰期,因此在模拟的高峰期注入异常以获得测试集。在高峰期间,首先系统正常运行,产生正常的测试traces。然后选择一个微服务,通过控制Docker容器的网卡延迟5分钟,首先向其注入响应时间异常。然后在不到30秒后,通过将微服务节点从TrainTicket系统中删除5分钟,将调用路径异常注入到该系统中。然后重新启动系统,让系统运行10分钟以恢复正常。然后,选择另一个微服务将异常注入其中。总的来说,上述异常注入过程运行了大约24小时,我们收集了30,356条正常trace、2,699条响应时间异常trace和2380条调用路径异常trace作为测试集。

图10:模拟流量中每分钟的访问量
2)获取在线trace标签:在线评估时,不可能对部署TraceAnomaly的18个服务(每个服务每天有数十万条trace)全部手工标注2个月。因此,我们得到ground truth如下。
如第四章 -A所述,图9中的离线训练模块和在线检测模块允许我们并行插入所有基线。将评估期内各基线检测到的所有异常trace的并集作为候选异常trace集,分别由两个经验丰富的操作人员手工验证。最后,将两个算子确认的异常trace都标记为异常trace,否则标记为正常trace。对于使用该ground truth集合的各种方法的评估,精度是准确的,但召回率可能都偏向于1,因为上述方法可能会遗漏一些异常trace,从而无法到达候选异常ground truth集合。
B 异常检测基线方法
我们首先介绍八种进行端到端调用链异常检测的基线方法。在(第一章-A)相关工作中介绍了多模态LSTM[3]、AEVB[4]、基于wfg[5]、基于cfg[6]、基于cpd[7]的。其余的基线方法有:
硬编码规则:S公司采用了基于微服务返回码的方法。这种方法是在TraceAnomaly部署之前,在S公司进行链路异常检测的实践。对于它服务的每一个调用,微服务都需要返回一个状态码来指示它在调用期间的状态(例如,响应时间是否超过了固定的阈值2000ms,或者发生了一些错误)。trace涉及的所有微服务的返回代码构成了链路的代码集,服务开发人员根据代码集手工设计一些固定规则,对每次trace进行异常检测。我们将这种检测方法称为硬编码规则。
OmniAnomaly [42]:它提出了一种用于多变量时间序列异常检测的随机递归神经网络。trace微服务的响应时间数据可以形成一个多元时间序列,因此可以利用多元时间序列异常检测来检测响应时间异常。
DeepLog* [8]:deeplog使用长短期内存(LSTM)模型检测执行路径异常。DeepLog为每个微服务训练一个LSTM模型,以检测响应时间异常,而TraceAnomaly为每个服务训练一个模型。如果我们使用LSTM来检测微服务的响应时间异常,则在我们的场景中必须训练数百个LSTM模型(例如,Service-1在表I中有344个微服务)。由于在线服务的资源限制,我们将响应时间异常检测替换为3-σ方法(与基于wgf的方法相同),并致力于改进方法DeepLog。
C 结果
表二显示了在包含41个微服务的试验台上各种方法的评价结果,表三显示了对包含数百个微服务的4个大型在线服务的各种方法的评价结果。不同方法的检测性能可以通过准确率和召回率来衡量。由于测试台上异常trace的ground truth情况是已知的,我们还计算了响应时间异常和调用路径异常的精度和召回率。

表二:对包含41项小额服务的TrainTicket试验台的不同方法的评价结果。测试集包含30,356条正常测试trace、2,699条响应时间异常trace和2380条调用路径异常trace

表三:对包含数百个微服务的四大在线服务不同方法的在线评价结果,统计数据见表一
基于cpd、基于cfg、AEVB和OmniAnomaly方法只检测调用路径异常或响应时间异常,因此,一些精度和召回率在表二中不能计算。TraceAnomaly和多模态 LSTM方法无法区分异常类型(响应时间异常或调用路径异常),所有无法计算响应时间异常和调用路径异常的精度。实际上,异常链路通常同时包含响应时间异常和调用路径异常。在试验台上进行区分只是为了评价目的。
普通微服务的响应时间可能会因调用路径的不同而发生显著变化。如图4所示,使用不同的响应时间调用了两次微服务 e。尽管基于wgf、DeepLog*、CFG、AEVB和OmniAnomaly也检测微服务级别响应时间异常,但它们没有考虑微服务的不同调用路径,这使得性能较差。基于cpd的仅检测调用路径异常。但是,仅分析调用路径并不适合检测链路异常。图6中的一个实际示例表明,异常trace和正常trace可以具有相同的调用路径。这些基线的性能证明了统一检测方法的价值。此外,由于轨迹结构的不同,微服务响应时间的时间序列数据中存在很多缺失数据点。这些缺失的数据点使得AEVB和OmniAnomaly的性能变差。尽管多模态LSTM尝试了一种统一的方法,但很难以端到端方式了解响应时间和调用路径之间的关系。由于AEVB、OmniAnomaly和Multimodal LSTM性能差,训练时间相对较长(6120分钟和530分钟),所以在在线评估中没有选择AEVB、OmniAnomaly和多模态 LSTM。TraceAnomaly需要大约90分钟来训练一天的测试和在线trace,而且这种训练开销在实践中是可以接受的。
硬编码的规则不如TraceAnomaly,尤其是在recall指标中(这是对∼0.2的改进)。由于在像我们这样的实际应用中,异常trace的数量远远少于正常trace,手动修复false negatives比false positives需要更多的努力。因此,召回度比精确度重要得多。根据这一点,我们得出结论,TraceAnomaly比硬编码规则好得多。
如A节里所述,使用近似ground truth的精度是准确的,但在表III中,所有方法的召回率可能都偏向于1。请注意,尽管TraceAnomaly在所有四个服务上的召回指标都是1.0,但实际上可能仍然有一些异常没有被成功检测到。但是,表三仍然很好地证明了TraceAnomaly的优越性,它可以检测到所有其他算法报告的异常,其精度高于所有基线。
D 对硬编码规则的改进
如B节中所述,硬编码规则是公司生产系统中使用最广泛的方法。因此,我们提供了它与TraceAnomaly之间的一些详细的比较。硬编码规则方法的一些误报是由于其规则设计不好所致。例如,一个开发人员在Service-1上设计了一个规则r1(参见表I)来检测异常trace:如果它的任何微服务返回一个“错误”返回代码,那么链路就是异常的。在我们的评估过程中,我们发现有些由r1检测到的痕迹没有被TraceAnomaly检测到。在与开发人员分析了详细的源代码后,我们发现r1错误地将以下正常情况声明为异常。Service1的微服务定期调用具有速率限制的外部API,超过速率限制会导致API的错误返回代码,但应用程序开发人员认为,相应的链路不应被认为是异常。TraceAnomaly成功地将这样的trace确定为正常,因为类似的trace并不少见,但是硬编码规则方法仅仅将带有错误返回代码的trace视为异常。
硬编码规则无法检测某些响应时间异常。例如,开发人员将微服务g的超时阈值设置为2秒。g的正常响应时间小于0.3秒。TraceAnomaly检测到了一些异常的trace,我们发现这些检测到的trace的微服务g的响应时间大于1秒,小于1.5秒。当我们通过TraceAnomaly呈现这些痕迹时,操作人员认为这些痕迹是异常的,需要被检测出来。
E 局部化根因
我们首先在测试台上比较了TraceAnomaly与三种基线方法的根本原因定位性能,这三种基线方法为:
MonitorRank [44] 利用节点间的邻接矩阵和时间序列相关性,生成个性化的pagerank向量,然后使用pagerank算法定位根源。
RCSF [45] 聚合从警告前端节点到错误后端节点的错误路径,挖掘从收集路径到定位根本原因的频繁序列模式。
MEPFL [46] 基于轨迹上定义的特征集,以监督的方式建立预测模型,对故障微服务进行定位。
表四显示了结果。Precision@K (top K的精度)是一个常用的排序度量,它表示一种方法给出的top K结果包含根本原因的概率。MonitorRank[44]、RCSF[45]和MEPFL[46]的本地化结果都是排名表,所以用Precision@K来衡量它们的性能。由于TraceAnomaly的定位结果不是排名列表,所以我们只对TraceAnomaly计算Precision@1。

表四:TrainTicket试验台根本原因定位方法的评价结果
MonitorRank[44]通过分析痕迹微服务的时间序列响应时间数据,定位根本原因。由于链路结构的多样性,微服务的响应时间数据中存在大量的不规则波动和数据点的缺失,使得算法的性能下降。RCSF[45]仅挖掘链路路径的频繁序列来定位根本原因,不足以处理各种链路结构和响应时间异常。MEPFL[46]所定义的特性不能反映调用路径异常,导致性能较差。因此,在在线评估中,我们只对TraceAnomaly定位进行评估。
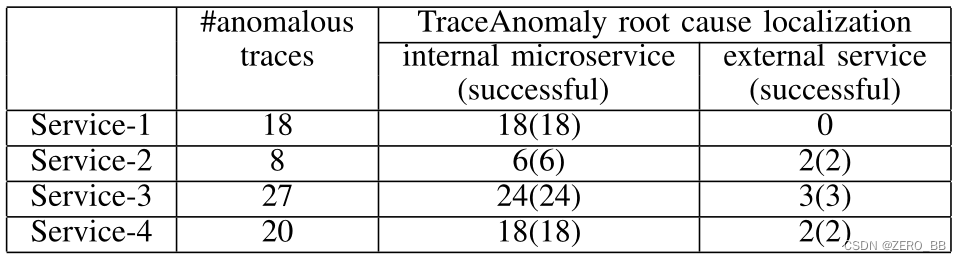
为了进行在线评估,我们收集了来自四家大型服务的73条异常踪迹,运营商对其进行了分析。如表5所示,这些链路的根本原因包括内部微服务和外部服务,TraceAnomaly成功地本地化了所有73个异常链路的根本原因。在未来,我们计划通过分析更多的信息来分析根本原因的确切原因,包括日志、配置、源代码等。
表五:在四个大型服务上定位根因的TraceAnomaly评估结果
F 影响
由于TraceAnomaly的良好性能,它已被用作S公司监控和故障排除系统的重要报警模块:
提前故障警告。有些错误在服务受到严重损害之前就会在链路中显示证据。例如,由于故障恶化,微服务的响应时间变得非常长,然后一些trace将立即异常。然而,恶化的故障可能需要几分钟到几小时才能影响服务的平均响应时间,因为由于有大量trace,平均响应时间变化非常缓慢。另一个例子是,少量的trace异常可能会揭示一些隐藏的错误,发现这些错误可以帮助开发人员在错误最终引发严重破坏之前修复它。
实时故障检测。如果一个服务出现故障,一批类似的异常trace可能会在短时间内出现(例如1分钟)。然后监控系统将立即报警,操作员可以迅速减轻和排除故障。
6 分析
回顾一下,我们的核心思想是通过无监督学习算法来学习服务链路向量(STVs)的分布p(x),并应用所学的模型来检测异常。一些无监督算法可以潜在地替代本文提出的贝叶斯网络:如高斯混合模型[47]、核密度估计[38]和Vanilla VAE[34]。在本节中,我们将在TraceAnomaly中使用这些替代方案替换贝叶斯网络,然后比较它们的性能,并分析为什么TraceAnomaly比其他替代方案更好。
A 探索替代方法
表六显示了所探讨方法的评价结果。首先,在我们探索的方法中,深度模型始终优于非深度模型(即KDE、GMM),这有力地证明了我们的猜想,即深度学习技术对于从复杂数据中学习p(x)是必要的。第二个结论是,TraceAnomaly始终比Vanilla VAE表现更好,正如我们在第三章-A中所预期的那样。这突出了在应用VAE进行痕迹异常检测时,需要一个强大的(即具有大建模能力的)后验qφ(z|x)。因此,我们得出结论,在所有学习的模型中,TraceAnomaly是最好的选择。
B 内部机制分析
为了分析第六章-A中算法的内部机制,我们绘制了一个二维数据集的密度图(图11a)和在该数据集上训练的模型的热点图(图11b到11e)。数据来自一个一天的在线服务,它的STV维数是2。我们选择这个数据集是因为高维数据集很难通过可视化分析。
数据集的密度(图11a)是通过直接绘制每个STV作为一个20%的透明点绘制的。训练模型的热图绘制如下。首先,沿x轴和y轴各取500个值,间隔相等,从x和y轴的笛卡尔积中得到250,000个点。这些点是模型的输入。然后我们计算每个模型对应的每个x的得分(logpθ(x)或对数密度)。最后,我们将这些分数绘制成图11中的热点图。
深度模型(图11b和11c)和非深度模型(图11d和11e)之间存在明显的对比。深度模型设法学习一个平滑的p(x),而非深度模型只能获得一个非平滑的p(x),在训练样本未覆盖的区域留下“空洞”。由于STVs的值是响应时间,因此有理由相信这些值本质上是连续的,因此具有平滑的p(x)应该有利于检测性能(确实是表6中的情况)。随着维度的增长,非深度模型将更难学习光滑的、瞬时的或真实的p(x)。这一事实有力地支持了我们在第三章-A中使用深层模型的偏向。
至于深层模型(图11b和11c),我们可以看到,VAE无法捕捉数据的细粒度模式。这是因为缺少良好的后验使得ELBO (Eqn(1))在训练中不能作为logpθ(x) 的紧下界,导致了次优模型,如第三章-A所述。因此,我们认为追踪异常可以有效地学习STVs的p(x)。

图11:(a)二维数据集的密度/热度图;(b)TraceAnomaly的logpθ(x);(c) VAE的logpθ(x);(d)KDE的对数密度;(e)GMM对数密度

表六:对四项大型服务和一个TrainTicket试验台所探讨的方法的评价结果
7 结论
本文提出了一种无监督异常检测方法TraceAnomaly,该方法可以自动学习服务轨迹的整体正常模式,并通过计算基于学习到的正常模式的可能性来检测异常。TraceAnomaly具有一种新的服务链路向量编码和后流深度变分贝叶斯网络。TraceAnomaly已经被部署在一家拥有数千万用户的公司S的18项大型在线服务上。对四个大型在线服务(包含61到344个微服务)和一个测试平台的详细评估表明,TraceAnomaly的召回率和精度都高于0.97,在S公司,比现有方法(硬编码规则)的表现分别高出19.6%和7.1%,比其他7个基线平均高出57.0%和41.6%。此外,TraceAnomaly在四个大型服务的所有73条异常链路上定位了正确的根本原因,在测试结果中,它的定位精度比三种基线方法高出55%。由于TraceAnomaly在两个月的部署期间表现良好,我们计划在S公司开发更多基于TraceAnomaly的监控和故障排除系统。
参考文献
[1] J. Thönes, “Microservices,” IEEE software, vol. 32, no. 1, pp. 116–116,2015.
[2] B. H. Sigelman, L. A. Barroso et al., “Dapper, a large-scale distributed systems tracing infrastructure,” Technical report, Google, Inc, Tech.Rep.,2010.
[3] S. Nedelkoski, J. Cardoso, and O. Kao, “Anomaly detection from system tracing data using multimodal deep learning,” in CLOUD’19. IEEE,2019.
[4] S. Nedelkoski, J. Cardoso et al., “Anomaly detection and classification using distributed tracing and deep learning,” 2018.
[5] Q. Fu, J.-G. Lou et al., “Execution anomaly detection in distributed systems through unstructured log analysis,” in Data Mining, 2009. ICDM’09.Ninth IEEE International Conference on. IEEE, 2009, pp. 149–158.
[6] A. Nandi, A. Mandal et al., “Anomaly detection using program control flow graph mining from execution logs,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016, pp. 215–224.
[7] L. Bao, Q. Li, P . Lu, J. Lu, T. Ruan, and K. Zhang, “Execution anomaly detection in large-scale systems through console log analysis,” Journal of Systems and Software, vol. 143, pp. 172–186, 2018.
[8] M. Du, F. Li et al., “Deeplog: Anomaly detection and diagnosis from system logs through deep learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM,2017, pp. 1285–1298.
[9] A. H. Yaacob, I. K. Tan et al., “Arima based network anomaly detection,” in Communication Software and Networks, 2010. ICCSN’10. Second International Conference on. IEEE, 2010, pp. 205–209.
[10] H. Yan, A. Flavel et al., “Argus: End-to-end service anomaly detection and localization from an ISP’s point of view,” in INFOCOM, 2012 Proceedings IEEE. IEEE, 2012, pp. 2756–2760.
[11] Y . Chen, R. Mahajan, B. Sridharan, and Z.-L. Zhang, “A provider-side view of web search response time,” ACM SIGCOMM Computer Communication Review, vol. 43, no. 4, 2013.
[12] S.-B. Lee, D. Pei et al., “Threshold compression for 3g scalable monitoring,” in INFOCOM, 2012 Proceedings IEEE. IEEE, 2012, pp.1350–1358.
[13] B. Krishnamurthy, S. Sen et al., “Sketch-based change detection: methods, evaluation, and applications,” in Proceedings of the 3rd ACM SIGCOMM conference on Internet measurement. ACM, 2003, pp. 234–247.
[14] B. Pincombe, “Anomaly detection in time series of graphs using arma processes,” Asor Bulletin, vol. 24, no. 4, p. 2, 2005.
[15] F. Knorn and D. J. Leith, “Adaptive kalman filtering for anomaly detection in software appliances,” in INFOCOM Workshops 2008, IEEE. IEEE, 2008, pp. 1–6.
[16] A. Mahimkar, Z. Ge et al., “Rapid detection of maintenance induced changes in service performance,” in Proceedings of the Seventh COn-
ference on emerging Networking EXperiments and Technologies. ACM,2011, p. 13.
[17] W. Lu and A. A. Ghorbani, “Network anomaly detection based on wavelet analysis,” EURASIP Journal on Advances in Signal Processing,vol. 2009,p. 4, 2009.
[18] A. A. Mahimkar, H. H. Song et al., “Detecting the performance impact of upgrades in large operational networks,” in SIGCOMM 2010.
[19] Y . Himura, K. Fukuda, K. Cho, and H. Esaki, “An automatic and dynamic parameter tuning of a statistics-based anomaly detection al-gorithm,” in Communications, 2009. ICC ’09. IEEE International Con-ference on.
[20] A. B. Ashfaq et al., “An information-theoretic combining method for multi-classifier anomaly detection systems,” in Communications (ICC),2010 IEEE international conference on.
[21] S. Shanbhag and T. Wolf, “Accurate anomaly detection through paral-lelism,” Network, IEEE, vol. 23, no. 1, pp. 22–28, 2009.
[22] A. Mahimkar, Z. Ge, J. Wang et al., “Rapid detection of maintenance induced changes in service performance,” in CoNEXT 2011.
[23] D. R. Choffnes, F. E. Bustamante, and Z. Ge, “Crowdsourcing service-level network event monitoring,” in SIGCOMM 2010.
[24] S.-B. Lee, D. Pei, M. Hajiaghayi et al., “Threshold compression for 3g scalable monitoring,” in INFOCOM 2012.
[25] A. Soule et al., “Combining filtering and statistical methods for anomaly detection,” in IMC 2005.
[26] Y . Zhang, Z. Ge, A. Greenberg, and M. Roughan, “Network anomogra-phy,” in IMC 2005.
[27] F. Silveira, C. Diot et al., “Astute: Detecting a different class of traffic anomalies,” in SIGCOMM 2010.
[28] H. Xu, W. Chen et al., “Unsupervised anomaly detection via variational auto-encoder for seasonal kpis in web applications,” in Proceedings of the 2018 World Wide Web Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2018, pp. 187–196.
[29] J. An and S. Cho, “V ariational autoencoder based anomaly detection using reconstruction probability,” SNU Data Mining Center, Tech. Rep.,2015.
[30] X. Y u, P . Joshi, J. Xu, G. Jin, H. Zhang, and G. Jiang, “Cloudseer:Workflow monitoring of cloud infrastructures via interleaved logs,” in ACM SIGPLAN Notices, vol. 51, no. 4. ACM, 2016, pp. 489–502.
[31] D. Rezende and S. Mohamed, “V ariational Inference with Normalizing Flows,” in Proceedings of the 32nd International Conference on Machine Learning (ICML-15), 2015, pp. 1530–1538.
[32] X. Zhou, X. Peng et al., “Fault analysis and debugging of microservice systems: Industrial survey, benchmark system, and empirical study,”TSE’18, 2018.
[33] “The traceanomaly project.” https://github.com/traceanomaly/anomalyDetection, June 7, 2020.
[34] D. P . Kingma and M. Welling, “Auto-Encoding V ariational Bayes,” in Proceedings of the International Conference on Learning Representa-tions,2014.
[35] C. P . Robert and G. Casella, Monte Carlo Statistical Methods (Springer Texts in Statistics). Secaucus, NJ, USA: Springer-V erlag New Y ork,Inc.,2005.
[36] D. P . Kingma, T. Salimans et al., “Improved variational inference with inverse autoregressive flow,” in Advances in Neural Information Processing Systems, pp. 4743–4751.
[37] D. P . Kingma and P . Dhariwal, “Glow: Generative flow with invertible 1x1 convolutions,” in Advances in Neural Information Processing Sys-tems 31, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., 2018, pp. 10 236–10 245.
[38] V . A. Epanechnikov, “Non-parametric estimation of a multivariate prob-ability density,” Theory of Probability & Its Applications, vol. 14, no. 1, pp. 153–158, 1969.
[39] Y . P . Chaubey, “Resampling-based multiple testing: Examples and methods for p-value adjustment,” 1993.
[40] J. Kreps, N. Narkhede, J. Rao et al., “Kafka: A distributed messaging system for log processing,” in Proceedings of the NetDB, 2011, pp. 1–7.
[41] S. A. Weil, S. A. Brandt et al., “Ceph: A scalable, high-performance distributed file system,” in Proceedings of the 7th symposium on Oper-ating systems design and implementation. USENIX Association, 2006,pp. 307–320.
[42] Y . Su, Y . Zhao et al., “Robust anomaly detection for multivariate time series through stochastic recurrent neural network,” in SIGKDD’19,2019.
[43] D. Merkel, “Docker: lightweight linux containers for consistent devel-opment and deployment,” Linux journal, vol. 2014, no. 239, 2014.
[44] M. Kim, R. Sumbaly, and S. Shah, “Root cause detection in a service-oriented architecture,” ACM SIGMETRICS Performance Evaluation Re-view,vol. 41, no. 1, 2013.
[45] K. Wang, C. Fung et al., “A methodology for root-cause analysis in component based systems,” in IWQoS’15. IEEE, 2015.
[46] X. Zhou, X. Peng, T. Xie, J. Sun, C. Ji, D. Liu, Q. Xiang, and C. He, “Latent error prediction and fault localization for microservice applications by learning from system trace logs,” 2019.
[47] D. Reynolds, “Gaussian mixture models,” Encyclopedia of biometrics,pp. 827–832, 2015.














 1399
1399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









