






摘要:日志是大规模服务管理最有价值的数据源之一。 日志表示将非结构化文本转换为结构化向量或矩阵,是实现自动化日志分析的第一步。 然而,当前的日志表示方法既不表示日志的特定领域语义信息,也不在运行时处理新类型日志的词汇表外词。 我们提出了Log2Vec,一个语义感知的日志分析表示框架。 Log2Vec结合了一种特定于日志的词嵌入方法来准确地提取日志的语义信息,并使用OOV字处理器在运行时将OOV词嵌入到向量中。 对OOV词的影响进行了分析,并对OOV词处理器的性能进行了评价。 在四个公共生产日志数据集上的评估实验表明,Log2Vec不仅修复了OOV词呈现的问题,而且显著提高了两个流行的基于日志的服务管理任务的性能,包括日志分类和异常检测。 我们已经将Log2Vec打包成一个开源工具包,并希望它能用于未来的研究。
关键词:日志分析,OOV词,AIOps
1 介绍
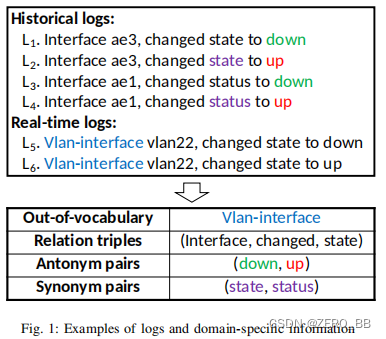
大型服务通常生成日志(见图1的上半部分。),它描述了它们观察到的大量事件,并记录服务运行时信息。 因此,它们对于服务管理[1]至关重要。 日志消息是由开发人员定义的日志语句(例如printf())打印的一行文本。 然而,大型服务通常由数百个开发人员/操作人员实现/维护。 通常,开发人员/操作员对整个服务有不完整的信息,而且他们都不熟悉服务生成的所有日志。 此外,日志的数量正在迅速增长,例如,以每小时约50千兆字节(约1.2∼2亿行)的速度[2]。 因此,在很大程度上依靠人工检查的传统日志分析方法已经成为一项劳动密集型和容易出错的任务。
自动日志分析方法被广泛应用于服务管理中。这些方法的设计是用于监测状态[3]、理解事件[4]、检测异常[1]、和预测故障[5]。上述大多数方法都需要结构化输入(例如向量或矩阵)[6]。然而,服务日志通常是非结构化的文本,需要正确地表示它们才能有效地使用[2]。因此,日志表示通常是自动化日志分析的第一步,因此对上述方法至关重要。以图1为例,在L1中,“ae3”是一个变量字段,而其余的,如“Interface ..., changed state to down”,是常量字段(模板)。将日志应用于管理的一种传统方法是从日志中学习模板,将日志映射到模板,并将其索引或嵌入到这些日志分析方法中(例如Deeplog[1]、Pre Fix[5]、LogAnomaly[7])。
在文献中,许多日志表示方法已经被提出[2],[8]。 Template2Vec是一项最先进的日志表示工作,它提出了提取的第一步通过将模板的单词嵌入到向量中,从日志中获取语义信息,这已经被证明比使用模板索引[7]获得了更好的性能。然而,从日志中提取语义信息用于日志表示面临两个尚未解决的挑战:(1)精确提取特定领域的语义信息。(2)将词汇外(OOV)词嵌入到向量中。
对于第一个挑战,目前的语义信息提取方法(例如template2Vec[7])基于分布假设将单词和模板嵌入到向量中,该假设假设具有相似上下文的单词往往具有相似的意义[9]。 然而,它们通常无法捕捉日志中许多单词的精确含义,因为一些对立对可能具有相似的上下文。 例如,图1中的“down”和“up”是反义词,但它们有相似的上下文。
对于第二个挑战,运营商不断地对服务进行软件/固件升级,以引入新功能、修复错误或改进性能[10]。 这些升级通常会生成带有OOV字样的新类型日志(例如,图1中的“Vlan-interface‘’)。 目前的单词嵌入方法不能嵌入这些OOV词,因为它们通常是基于历史日志的词汇表进行离线训练的,在运行时无法更新。
为了解决上述两个挑战,我们提出了Log2Vec,一个语义感知的在线日志分析表示框架。 服务日志的最初目标“日志是供用户阅读的”激励了我们的工作。 也就是说,日志由开发人员设计,“printf”由服务编辑。 此外,自然语言处理中的直觉和方法可以用于或改进日志表示。 具体来说,Log2Vec集成了一种特定于日志的词嵌入方法LSWE,用于提取特定于日志的语义信息,并在运行时使用OOV字处理器将OOV词嵌入到向量中。
本文的贡献如下:
1)我们提出了Log2Vec,一个将非结构化日志转换为具有日志特定信息的分布式表示的框架。
2)由于Log2Vec有一种生成OOV词嵌入的机制,当出现新类型的日志时,运算符不需要对原始词嵌入语料库进行冗余再训练。
3)对两个流行的基于日志的服务管理任务(包括日志分类和异常检测)的实验都证明了Log2Vec可以提取日志的关键特征,并显著提高基于日志的服务管理任务的性能。
4)我们有开源的Log2Vec,并希望它能用于未来的研究。
论文的其余部分组织如下:我们在第二节中讨论了相关的日志表示工作,并在第三节中提出了我们的方法。 评价见第四节。在第五节中,我们介绍了Log2Vec的案例研究。 最后,我们在第七节中总结我们的工作。
2 相关工作
服务日志在服务管理中起着重要的作用。 大多数基于日志的服务管理任务需要结构化输入(例如,事件/模板索引或matirx)。 因此,日志表示通常是走向自动化日志分析的第一步。
最流行的日志表示方法是自动模板提取。 它从日志中提取常量字段(模板),并将模板索引放入机器学习方法中。 模板提取方法[2]有很多类,如LogSig(一种基于集群的方法)[11],FT-tree(基于频繁项挖掘)[12],IPLoM(迭代划分)[13]和Spell(最长公共子序列)[8]。 然而,当只使用日志模板索引时,可能会丢失有价值的信息,因为它们[7]不能揭示日志的语义关系。
为了适用于机器学习算法,在检测异常日志时,使用包字模型将日志转换为向量[14]。 template2Vec2Vec[7]结合模板和Word2vec[15],用向量表示模板。 然而,基于语料库的方法(例如Word2Vec)通常无法捕捉到许多单词的特定领域含义。 例如,一些语义相关但不同的词可能有相似的上下文(例如同义词和反义词)。
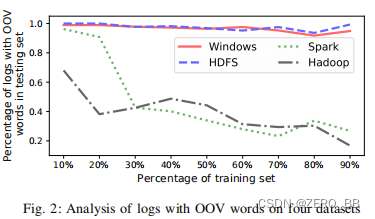
此外,服务可以在运行时生成新类型的日志[7]但是,现有的日志表示方法不能处理新日志中的词汇外词,这也会丢失语义信息。 例如,图2显示了包含OOV词的日志的百分比,因为培训数据的百分比从10%增加到90%(详细信息见第四-B节)。 我们观察到,OOV词在较小的日志样本上训练时有很大的百分比。
3 log2voc设计思路
A思路
我们设计Log2Vec来表示日志中的单词,基于以下思路:
1)日志是由开发人员使用“printf”函数预定义的。 它通常描述系统上发生的事件。 日志的文本表示事件的语义信息。
2)日志中的词汇表不断增长,因为软件/固件可以在服务上升级,因为引入了一些更改来添加新功能、修复错误或提高系统的性能。
3)日志包含许多特定于域的单词。 提取这些特定领域的单词的语义信息可能是困难的,但对于日志分析来说是至关重要的。
B Log2Vec概述
在这些观察的推动下,我们提出了Log2Vec(如图3所示),这是一种用于服务日志分析的新表示框架。 具体来说,我们提出了一种特定于日志的词嵌入方法LSWE,用于提取特定于日志的语义信息(第三-C节),并采用OOV字处理器在运行时嵌入OOV词(第三-D节)。 我们在本节进一步介绍Log2Vec的在线和离线阶段。
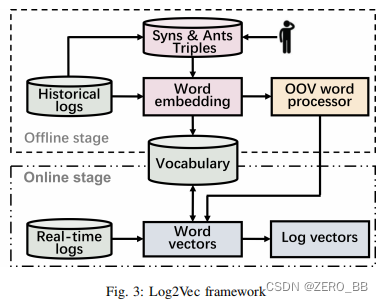
Log2Vec框架由离线阶段和在线阶段两部分组成。 在离线阶段,Log2Vec通过组合从日志中提取或由运算符提供的信息来构造特定于域的信息集(例如本文中的反义词和三元组。 接下来,Log2Vec表示具有特定领域语义的分布式单词。 由于服务将在运行时在新类型的日志中生成OOV词,Log2Vec在在线阶段为OOV词培训OOV词处理器。 在在线阶段,我们首先确定日志中的每个单词是否在词汇中。 如果是,则我们将现有单词转换为基于离线学习的单词向量。 否则,我们将通过OOV字处理器向OOV字分配一个新的嵌入向量。 最后,Log2Vec将日志中的所有单词转换为单词嵌入向量,并计算日志向量,这是其单词向量的加权平均值。
C 日志特定的词嵌入Word Embedding
日志的设计是为了方便用户的可读性;因此,服务设计者用自然语言定义了日志的常量部分。 以前的方法使用自然语言过程(NLP)方法(例如Word2vec[15])来表示文本中的单词。 然而,这些方法并不是专门为处理日志中的单词而设计的,这导致了几个缺点。 (1)例如,word2vec[15]使用上下文词来预测目标词,其中只考虑局部上下文信息。 因此,它不能表示同义词和反义词。 (2)Word2vec没有考虑相关信息,这也是日志的重要信息。
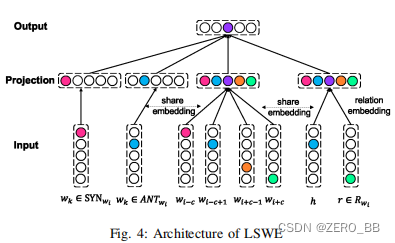
为了解决这些问题,我们提出了LSWE(Log特异性WordEmbedding),这是一种新的用于日志词的词向量表示,它将词汇对比集成到分布向量中,并增强特定于域的语义和关系信息,以确定词的相似性程度。 LSWE的体系结构如图4所示。 LSWE采用词汇信息词嵌入(L WE)[16]和语义词嵌入(SW E)[17]两种词嵌入方法。
给定与目标词对应的同义词和反义词集合,我们使用LWE预测目标词,使其向量表示的距离尽可能接近其同义词,并尽可能远离其反义词。 形式上,目标函数如下:
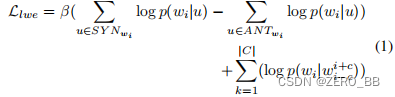
其中wi是目标词,u是反义词。 SYNwi和ANTwi分别表示wi的同义词和反义词集。 当反义词为u时,p(wi|u)是wi的概率。 第二部分是CBOW[18]的目标函数(Word2vec模型),C是训练语料库(logs)。 请注意,CBOW和LWE共享相同的单词向量。
一般来说,知识图中的信息是以关系三元组(h,r,t)的形式组织的)。 如SWE[17]中所使用的,我们构造了一个样本(h,r,wi),其中r表示各种不同的wi关联关系。 得到三元组后,有必要建立词语关系的表征。 跨E模型[19]是三元组最有效的表示方法。 对于三元组(h,r,t),如果三元组是事实信息,则(hr≈t)。 即hrr的对应向量应该更接近t.SWE[17],它结合了关系信息和CBOW,目标函数为:
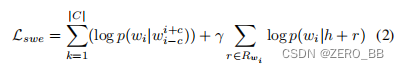
然后得到LSWE的目标函数如下:
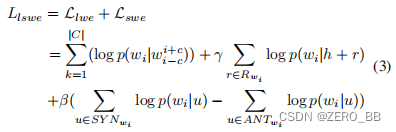
基于共现信息,LSWE学习上下文词。 此外,它还学习相应的语义和关系信息。 LSWE结合反义词集合和关系三元组来提高词向量的质量。 通用反义词可以在Word Net[20]中找到,它是英语的词汇数据库。 关系三元组可以使用依赖树[21]从处理的日志中提取,这是一种流行的语义解析方法。 然而,一些特定领域的反义词和关系必须由基于领域知识的运算符添加。
LSWE的显著优点是它能够推广到单词,这是通过将词汇和关系特征嵌入到低维欧几里得空间中来实现的。这些低维嵌入可以捕获分布相似性,因此信息可以在类似上下文中出现的单词之间共享。但是,不可能枚举所有日志的整个词汇,并且会错过出现在以后服务(OOV单词)中的单词。在下一节中,我们将介绍一种处理OOV单词的新技术。
D 词汇之外词处理器
为了在运行时处理OOV词,我们采用了MIMICK[22],一种通过学习从拼写到分布嵌入的函数来生成OOV词嵌入的方法。
MIMICK[22]将词汇外嵌入(OOV)问题视为生成问题:无论原始嵌入是如何创建的,MIMICK都假设有一个基于生成词形的协议来创建这些嵌入。 通过在现有词汇上训练一个模型,MIMICK以后可以使用该模型来预测一个看不见的单词的嵌入。 在这里,我们简要介绍了MIMICK的原理:给定一个语言L、一个大小为V的词汇V⊆L,以及一个预先训练的嵌入表∈RV×d,其中每个单词{w k}vk=1被分配一个维数d的向量ek。对MIMICK进行训练,以求函数f:L→RD,使投影函数f|v逼近ek的赋值f(Wk。 给定这样的模型,∈L\V∗的新单词wk现在可以分配嵌入ek∗=f(wk),如图3所示,我们在离线阶段使用MIMICK训练OOV处理器,并在在线阶段出现新单词时为未见单词分配新的嵌入向量。

4 实验部分
在本节中,我们报告了为评估所提出的日志2VEC的有效性而进行的所有实验。首先,我们描述了实验设置。接下来,我们提出了一项测量研究来强调OOV单词的挑战,并展示了日志2VOV处理器的性能。最后,为了证明日志2VEC的有效性,我们比较了三种流行的基于日志的服务管理任务(有/没有日志2VEC)的性能,包括日志分类和异常检测。
A 实验环境
1)数据集:我们从几个服务中对四个公共日志数据集进行实验,这些服务是Spark日志[2]、HDFS日志[2]、Windows日志[23]和Hadoop日志[24]。 这些数据集的详细信息列于表一。
2)实验设置:我们使用IntelXeon2.40G Hz CPU在Linux服务器上进行所有实验。 我们使用Python3.6实现Log2Vec,并将打开它的源代码。 至于MIMICK,我们在[22]中使用了一个流行的开源工具包。
B OOV词
1)OOV的测量:在这一节中,我们提出了一项大规模的测量研究,以突出处理OOV词的挑战。 我们生成原始数据集的百分比从10%到90%不等的训练集,并将剩余的日志视为测试集。
首先,我们评估了服务日志中OOV单词的数量。 图5显示了四个日志数据集上单词的百分比,因为训练数据的百分比从10%增加到90%。 结果表明,随着训练数据的增长,OOV词在测试集中的比例逐渐下降,特别是在Spark日志中。 当我们使用90%的Spark日志来训练模型时,我们在测试集中只找到2.48%的OOV单词。

接下来,我们评估包含OOV单词的日志数。图2显示了四个日志数据集上包含OOV词的日志的百分比,随着训练数据的百分比分别从10%增加到90。我们观察到,所有测试集都有OOV词的日志,即使它们是用90%的数据进行训练的,特别是Windows和HDFS日志。 无论使用何种比例的数据进行训练,总是有超过90%的日志由服务在线生成,其中包含OOV词。 此外,当我们基于10%的训练集训练模型时,服务生成的70%以上的日志将包含OOV词,这意味着当前的日志分析模型不能基于少量数据训练模型(如图 2所示)。 结果还表明,在分析日志时处理OOV词是至关重要的。
2)OOV字处理器的评估:如第三-D节所述,Log2Vec包含一个OOV处理器,用于在运行时处理OOV字。 在本节中,我们将评估OOV处理器的性能。 我们从四个数据集中的每一个随机选择10,000个日志作为地面真相。 然后,我们在每个日志中随机选择一个单词,并更改其中一个字母,使该单词成为OOV单词。 接下来,我们测试更改日志和原始日志之间的相似性(Cosine相似性)。
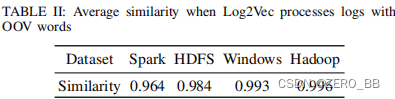
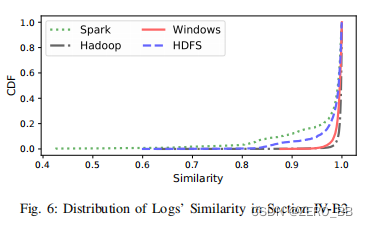
图6是上述实验的CDF,我们观察到,即使每一块日志都包含OOV词,Log2Vec也取得了优异的性能。 例如,99.8%的Windows日志与更改的日志具有0.9以上的相似性。 表二显示了Log2Vec处理修改后的日志时的平均相似性。 均达到较高的相似性。
C 任务1:日志分类
1)任务描述:通常,操作人员对单个日志进行分类,并将重点放在他们感兴趣的日志类别上,以监视服务的状态。 然而,现代服务的规模和复杂性不断增加,使得日志数量激增,在大规模服务中生成数千万个日志。 人工对原木进行分类存在着不灵活和劳动强度大的问题。 因此,日志自动分类也是日志分析中的一项重要任务。 为了评估在线日志分类的性能,我们将每个数据集划分为50%的训练集和50%的测试集。
2)基线:最流行的自动日志分类方法是基于规则的(例如,自动提取模板)。 它们将每个模板视为一个类别,并将在线日志与提取的模板匹配。 此外,template2Vec[7]在日志分析方面也取得了优异的性能,它们可以将每个日志表示为向量,并将日志聚类到某些类别。 在此任务中,我们选择LogSig[11],FT-tree[12],SPELL[8],template2Vec[7]作为基线。 [2]手动标记每个日志的类别(在表I中),这是分类的ground truth。
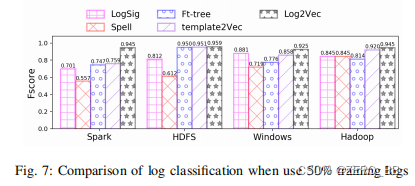
3)实验结果:图7显示了日志分类的实验结果。 我们观察到,使用模板提取方法(LogSig、FT-tree、Spell)进行分类的效果很差,因为测试集中有许多新类型的日志无法与现有模板匹配。 Template2Vec的性能优于模板方法,因为Template2Vec表示模板的语义。 然而,模板2Vec的输入是模板,它们也不能处理OOV词。 在四个数据集上,Log2Vec的性能稳定,Log2Vec的平均Fscore为0.944,说明Log2Vec能够比基线更准确地表示日志(平均Fscore为0.745)。
D 任务2:异常检测
1)任务描述:异常检测是构建安全可靠服务的关键步骤。 服务日志的主要目的是在各个关键点记录服务状态和重要事件,以帮助调试服务故障并执行根本原因分析。 因此,许多方法利用各种服务日志进行异常检测。 服务异常可以根据其日志序列推断,其中包含违反常规规则的多个日志。 我们在BGL日志[25]上进行这个实验,其中每个日志都被手动标记为正常或异常。
2)基线:Deeplog[1]是基于日志的顺序异常检测方法中最先进的一种。 然而,Deeplog的输入是日志模板索引,这已经意味着语义信息的丢失。 为了演示Log2Vec的性能,我们将模板索引(Deeplog的输入)更改为分布式表示。 当使用Log2Vec训练时,我们将Deeplog与自己进行比较。 这些方法的参数都是最精确的。
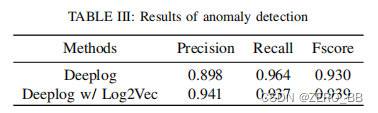
3)实验结果:如表三所示,Deeplog在BGL数据集(0.898)上的精度远低于Deeplog(w/)Log2Vec(0.941)。 一般来说,大型服务每天生产数千万根原木。 如果日志异常检测方法每天产生太多的错误警报,它将给操作人员增加大量不必要的工作。 因此,Log2Vec可以提高目前基于日志的异常检测方法的性能。 由于Log2Vec在分析日志时能够表示语义信息和处理OOV问题,所以Log2Vec获得了更好的性能。
5 实例分析
为了进一步评估Log2Vec的性能,我们展示了在线日志聚类的案例研究,其中日志是由部署在顶级云服务提供商的交换机在一个月内生成的。 日志聚类的目的是使类似的日志与表示给定空间中相同事件的日志更接近,其中同一类别中的日志具有相似的语义。 部署Log2Vec,template2Vec[7]和FT-tree[12]进行日志聚类。 Log2Vec生成775个类别,Template2Vec生成862个类别,FT-tree生成3212个类别。 经运营商确认,Log2Vec的聚类结果是最适合管理的。 大多数由FT-tree生成的类别过于细粒度。 属于同一事件的日志分为几类,因为FT-tree[12](和其他模板方法)不能将包含不同单词的两个日志放在一起,即使它们的语义相同。虽然Template2Vec可以表示日志的语义,但它不能处理OOV词,这将生成更多具有相似语义的类别。
例如,图8显示了来自上述案例研究的四个日志。 Log2Vec将它们分为两类({L1,L2},{L3,L4}),Template2Vec生成三个类别({L1,L2},{L3},{L4}),而FT-tree生成四个类别({L1},{L2},{L3},{L4})。 在L1和L2中,“状态”和“状态”是同义词。 在L4中,“mainIfname”是一个OOV词,但它类似于L3中的“mainName。 Log2Vec对它们进行了识别,并将它们分类为相同的类别。

6 讨论和未来工作展望
本文的目的是强调NLP驱动的日志方法的前景,并讨论在线日志分析场景中必须克服的挑战(例如,特定于日志的信息和OOV词),以实现这一愿景。 log2Vec是一个框架,操作人员可以替换任何模型或添加新的模型进行日志分析。
Log2Vec可以为下游的目的服务,我们在未来的工作中考虑到这一点。 我们将使用Log2Vec来改进基于日志的服务管理任务(例如,故障预测、根本原因分析。
7 总结
日志表示是自动化日志分析的第一步。 我们提出了一个语义感知的表示框架Log2Vec,以提高在线日志分析的性能。 在Log2Vec中,我们提出了OOV词的测量方法,并对OOV词处理器的性能进行了评价。 此外,我们还将Log2Vec应用于两个流行的基于日志的服务管理任务,包括日志分类和异常检测,这都表明Log2Vec可以提取日志的关键特征,并显著提高日志的性能。 传统的日志表示方法限制了许多日志分析应用程序,这些应用程序需要对任何日志都有表示。 Log2Vec能够在运行时为每个日志分配一个“soft”表示,以避免新类型日志引起的错误警报。
参考文献
[1] Min Du, Feifei Li, Guineng Zheng, and Vivek Srikumar. Deeplog:Anomaly detection and diagnosis from system logs through deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pages 1285–1298, 2017.
[2] Jieming Zhu, Shilin He, Jinyang Liu, Pinjia He, Qi Xie, Zibin Zheng,and Michael R Lyu. Tools and benchmarks for automated log parsing.In 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 121–130.IEEE, 2019.
[3] Subhendu Khatuya, Niloy Ganguly, Jayanta Basak, Madhumita Bharde,and Bivas Mitra. Adele: Anomaly detection from event log empiricism.In IEEE INFOCOM 2018-IEEE Conference on Computer Communications, pages 2114–2122. IEEE, 2018.
[4] Shilin He, Qingwei Lin, et al. Identifying impactful service system problems via log analysis. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 60–70. ACM, 2018.
[5] Shenglin Zhang, Ying Liu, Weibin Meng, Zhiling Luo, Jiahao Bu, SenYang, Peixian Liang, Dan Pei, Jun Xu, Yuzhi Zhang, et al. Prefifix: Switch failure prediction in datacenter networks. Proceedings of the ACM on Measurement and Analysis of Computing Systems, 2(1):1–29, 2018.
[6] Pinjia He, Jieming Zhu, Zibin Zheng, and Michael R Lyu. Drain:An online log parsing approach with fifixed depth tree. In 2017 IEEE International Conference on Web Services (ICWS), pages 33–40. IEEE,
[7] Weibin Meng, Ying Liu, Yichen Zhu, Shenglin Zhang, Dan Pei, YuqingLiu, Yihao Chen, Ruizhi Zhang, Shimin Tao, Pei Sun, et al. Loganomaly:Unsupervised detection of sequential and quantitative anomalies in unstructured logs. In Proceedings of the Twenty-Eighth International Joint Conference on Artifificial Intelligence, IJCAI-19. International Joint Conferences on Artifificial Intelligence Organization, volume 7, pages 4739–4745, 2019.
[8] Min Du and Feifei Li. Spell: Streaming parsing of system event logs.In 2016 IEEE 16th International Conference on Data Mining (ICDM),pages 859–864. IEEE, 2016.
[9] Michael Roth. Combining word patterns and discourse markers for paradigmatic relation classifification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics(ACL), pages 524–530, June 2014.
[10] Shenglin Zhang, Ying Liu, Dan Pei, Yu Chen, Xianping Qu, Shimin Tao, Zhi Zang, Xiaowei Jing, and Mei Feng. Funnel: Assessing software changes in web-based services. IEEE Transactions on Services Computing, 11(1):34–48, 2016.
[11] Liang Tang, Tao Li, and Chang-Shing Perng. Logsig: Generating system events from raw textual logs. In Proceedings of the 20th ACM international conference on Information and knowledge management,pages 785–794. ACM, 2011.
[12] Shenglin Zhang, Weibin Meng, Jiahao Bu, Sen Yang, Ying Liu, Dan Pei, Jun Xu, Yu Chen, Hui Dong, Xianping Qu, et al. Syslog processing for switch failure diagnosis and prediction in datacenter networks. In 2017 IEEE/ACM 25th International Symposium on Quality of Service (IWQoS), pages 1–10. IEEE, 2017.
[13] Adetokunbo AO Makanju, A Nur Zincir-Heywood, and Evangelos E Milios. Clustering event logs using iterative partitioning. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 1255–1264, 2009.
[14] Weibin Meng, Ying Liu, Shenglin Zhang, Dan Pei, Hui Dong, Lei Song, and Xulong Luo. Device-agnostic log anomaly classifification with partial labels. In 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), pages 1–6. IEEE, 2018.
[15] Kim Anh Nguyen, Sabine Schulte im Walde, and Ngoc Thang Vu. Integrating distributional lexical contrast into word embeddings for antonym-synonym distinction. arXiv preprint arXiv:1605.07766, 2016.
[16] Luchen Tan, Haotian Zhang, Charles Clarke, and Mark Smucker. Lexical comparison between wikipedia and twitter corpora by using word embeddings. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 657–661, 2015.
[17] Quan Liu, Hui Jiang, Si Wei, Zhen-Hua Ling, and Yu Hu. Learning semantic word embeddings based on ordinal knowledge constraints. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1501–1511, 2015.
[18] Tomas Mikolov, Quoc V Le, and Ilya Sutskever. Exploiting similarities among languages for machine translation. arXiv:1309.4168, 2013.
[19] Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. Knowledge graph and text jointly embedding. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1591–1601, 2014.
[20] George A Miller. Wordnet: a lexical database for english. Communications of the ACM, 38(11):39–41, 1995.
[21] Katrin Fundel, Robert K¨uffner, and Ralf Zimmer. Relex—relation extraction using dependency parse trees. Bioinformatics, 23(3):365–371,
[22] Yuval Pinter, Robert Guthrie, and Jacob Eisenstein. Mimicking word embeddings using subword rnns. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 102–112, 2017.
[23] Shilin He, Jieming Zhu, et al. Experience report: System log analysis for anomaly detection. In 2016 IEEE 27th International Symposium on Software Reliability Engineering (ISSRE), pages 207–218. IEEE, 2016.
[24] Qingwei Lin, Hongyu Zhang, Jian-Guang Lou, Yu Zhang, and Xuewei Chen. Log clustering based problem identifification for online service systems. In Proceedings of the 38th International Conference on Software Engineering Companion (ICSE), pages 102–111. ACM, 2016.
[25] Adam J. Oliner and Jon Stearley. What supercomputers say: A study of fifive system logs. IEEE International Conference on Dependable Systems and Networks (DSN’07), pages 575–584, 2007.

















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









