






苏亚,赵友建,夏文涛,刘蓉,卜家豪,朱静,曹元璞,李海滨,牛晨豪,张益银,王兆刚,裴丹* 清华大学,史蒂文斯理工学院,南开大学,国防科技大学,阿里巴巴集团,北京国家信息科学技术研究中心
摘要:互联网服务公司会监控大量的kpi(关键性能指标),以确保他们的服务质量稳定性和可靠性。通过指标波动来关联kpi可以揭示异常情况下kpi之间的交互,这对于服务的故障排除非常有用。然而,到目前为止,在互联网服务运营管理领域,对这种KPI指标关联的研究还很少。一个主要挑战是,对于大量kpi,如何自动准确地将具有不同结构特征(如周期性、趋势和平稳)的kpi中的波动与正常变化区分开来。在本文中,我们提出了CoFlux,一种无监督方法,自动(无需手动选择算法拟合和参数调整)确定两个kpi是否在波动上由相关性,以及它们以什么时间顺序波动,以及它们是否在同一方向上波动。CoFlux的鲁棒特征工程和鲁棒相关得分计算使其能够很好地应对不同的KPI特征。我们的大量实验表明,CoFlux在回答上述三个问题时,在来自一家顶级全球互联网公司的两个真实数据集中,分别获得了最佳的F1 Scores,分别为0.84(0.90)、0.92(0.95)、0.95(0.99)。此外,通过应用告警压缩、推荐Top N原因和构建波动传播链,我们证明了CoFlux在辅助服务的故障排除方面是有效的。
CCS的概念;
网络→网络监控;•社会和专业主题→软件维护。
关键词:
关键性能指标KPI、业务运营管理、时间序列、波动相关性、业务故障排除
1、介绍
大型互联网公司会通过成千上万的服务器来提供大量的服务和应用[1,2]。然而,由于网络中断、服务器宕机、恶意攻击等原因,服务中断是不可避免的[3,4]。为了保持竞争力,这些公司会尽力保持他们的服务稳定可靠。他们不断地监控kpi(关键性能指标),包含服务质量度量(如成功率和请求数量[5])的时间序列。某些事件可以触发某些kpi的波动,而波动可能传播到更相关的kpi,形成相互交织的波动,这使事件解决和根本原因分析复杂化[6]。在不了解它们之间的关系的情况下,操作人员很难对交织波动触发的告警进行优先排序,并识别可能的事故影响。
在本文中,我们重点分析KPI波动之间的相关性。波动是KPI与期望值的偏差。较大的波动可能是异常,经常表现为[3]指标值的突然峰值或下降。如果一个KPI的波动与另一个KPI的波动在一段时间内相互关联,则我们定义两个KPI是波动相关的(coflux-correlated)。请注意,波动相关性与KPI相关性不同,后者通常使用KPI的原始值进行计算。两个波动相关的kpi的原始值却可能是不相关的。例如,如图1(a)所示,k1和K2(或k1和K3)的原始值在算法计算上是不具有相关性的,如Pearson相关性计算[7]。然而,如图1(b)所示,这两个kpi的波动是高度相关的,因为它们经常同步或顺序发生。因此,波动相关性应该基于波动而不是原始的kpi值进行分析。
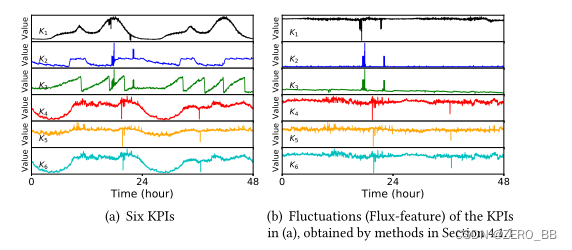
波动相关技术可以在许多方面帮助操作人员进行故障排除。基于internet的服务通常由部署在多台机器上的软件模块组成[1]。该服务由多个不同级别的kpi监控,为机器级和模块级[2]。当发生故障时,会从这些kpi生成过多且通常相关的告警。这些冗余的告警会吸引操作人员的注意力,分散他们对诊断的注意力。使用波动相关性,首先,我们可以基于告警压缩[8]的波动相关性结果对kpi进行聚类。如果两个或多个kpi与流量相关,则可以将它们分组到一个集群中,并根据整个集群而不是单个kpi发出告警,这将极大地减少操作人员的工作负担。例如,在图1(a)中,K1、k2、k3可以归为一个簇,而K4、k5、k6则归为另一个簇。其次,当KPI出现异常时,操作人员可以检查其Top N波动相关KPI的波动,以缩小其分析范围。第三,为了推断出根本原因,我们可以根据kpi波动的时间顺序构建一个波动传播链(例如,先K4,然后k5,最后K6,如图1(a)所示)。正如[6]所建议的,在服务中,具有最早异常更改的kpi可以更好地反映实际的根本原因。
波动相关的思想也吸引了其他领域的兴趣,如系统建模[9]和股票市场[10]。[9]旨在描述系统中kpi之间的异常交互,并构建影响结构图(SIG)。KPI的异常信号是通过滑动窗口中的数据分布与整个KPI分布之间的KL发散来计算的。因此,[9]关注的是异常值11,不能识别主要由部分历史数据判断的异常。我们开发了ARCH[10]、V ARMA[12]和CoIntegration[13]统计模型来分析股票价格变化的相关性,或研究股票市场的波动性等。然而,在我们的场景中,这些模型不能很好地解决波动相关性问题,因为它们不能准确地识别kpi的波动。另一个相关领域是原始时间序列之间的相关分析。Pearson[7]和Spearman Correlation分别关注原始kpi之间的线性和秩相关。它们不能很好地处理波动,特别是当两个kpi具有不同的模式时,例如周期性和相位转移。格兰杰因果关系[14]通过一个KPI是否有助于预测另一个KPI来确定两个KPI之间的相关性。然而,在我们的背景下,波动通常是由意外事故引起的,可能无法用回归来预测。因此,这些方法不能很好地解决我们的波动相关问题。
本文通过聚焦于KPI波动相关性分析来填补这一空白。主要挑战如下:
没有提取波动的通用机制。不同的kpi往往具有不同的时间序列特征(如周期性、平稳性和趋势性),需要特定的模型来捕捉其波动。在互联网公司中,通常存在1万到100万个kpi,手动为每个kpi搜索合适的波动提取模型既费时又不切实际。因此,设计一种针对不同KPI特征的健壮的通用波动(即流量特征)提取机制是具有挑战性的。
波动相关性不应基于异常检测。人们可能会对异常检测的二元结果应用J-measure[2]。然而,异常检测模型的选择和阈值的确定通常高度依赖于kpi的具体特征和用户的敏感性偏好[16]。因此,波动相关性不应以异常检测为基础。
两个波动相关的kpi可能呈现不同的交互模式。在实践中,kpi可能同步或按延迟顺序波动。而且,有时候,当一个KPI下降时,一些KPI会随之大幅下降,而其他KPI则会响应一个峰值。这些模式使波动相关分析复杂化。
在应对上述挑战时,我们在本文中作出了以下贡献:
就我们所知,本文是在互联网服务运营管理领域中对流量关联进行详细研究的首次尝试。我们提出了一种新的无监督算法CoFlux,以自动和准确地测量kpi之间的波动相关性,基于他们的波动特征,不需要异常检测。CoFlux可以回答三个问题,(1)两个kpi是波动相关的吗?如果波动相关,(2)它们以什么时间顺序波动?(3)它们是正相关还是负相关?
CoFlux包括一组从被广泛接受的时间序列模型的预测误差中提取的鲁棒波动特征。我们的直觉是,至少有一种波动特性能够足够准确地捕捉给定KPI的波动,尽管我们事先不知道是哪一种。这使得我们的特征提取对不同的KPI特征具有鲁棒性,并且可以在不需要算法拟合和参数调优的情况下处理大量KPI。
CoFlux利用两个kpi的不同波动特征之间的最佳互相关[17]得分计算两个kpi的波动相关得分。直观地说,如果两个kpi X和Y是波动相关的,那么来自X和Y的最佳波动特征也是相关的。不需要预先或手动识别这个最佳波动特征对,使CoFlux对不同的KPI特征具有鲁棒性。
我们的大量实验表明,CoFlux在回答波动相关分析的三个问题时,在来自一家顶级全球互联网公司的两个真实数据集中,分别获得了最佳f1 - score 0.84(0.90)、0.92(0.95)、0.95(0.99),显著优于基线算法及其他方法。此外,通过应用告警压缩、推荐Top N原因和构建波动传播链,我们证明了CoFlux在辅助服务故障排除方面是有效的。
2、问题陈述
在本节中,我们首先定义几个关键术语,包括kpi、波动特性、波动相关性和两个波动相关性模式,然后描述我们在本研究中的目标。
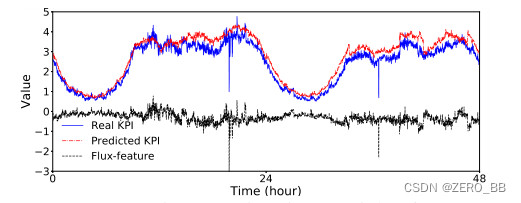
kpi和流量特性,KPI是在等距时间戳[2]上收集的一系列连续观测数据,表示为S = [s1, s2,…, sm],其中si 是对应于CoFlux:基于波动的服务故障诊断kpi的观测值,对于I∈1,2,…, m, m是KPI的长度。如果两个kpi有不同的采样间隔,在考虑它们的波动相关性时,我们使用它们的间隔的最小公倍数作为最终间隔对它们进行重新采样。我们将预测KPI定义为由时间序列预测模型产生的一系列预测值,表示为P = [p1, p2,…],其中pi为si的预测值。预测误差记为F = [f1, f2,… ] 其中fi= si−pi。虽然正常的观测值可以很好地预测,但波动经常产生预测误差。因此,预测误差在分析波动时非常有用。本文将预测误差视为波动特征,即波动特性。因此,用于预测的具有特定参数的时间序列模型是一种特征提取器。我们可以通过不同的时间序列预测模型为KPI创建许多波动特征。
图2显示了一个真实的KPI示例,它的预测值是Historical Average[18],以及相应的波动特征。由于波动特征是由时间序列预测模型生成的,因此模型的选择对波动特征提取至关重要。如果一个模型能准确地预测正常值,那么预测误差就能很好地捕捉波动。稍后我们将详细讨论模型的选择。
Flux-correlation,在本研究中,对于一个KPI对(X,Y),我们首先确定它们的波动是否相关,即波动相关。如果它们的波动特征是相关的,则用X∽Y表示。如果X和Y不是波动相关的,则用X≁Y表示。例如,图1显示了6个kpi及其流量特性。K1和K2的波动特征看起来高度相关,因此它们是波动相关的,即K1∽K2。而K1和K4没有波动相关,即K1≁K4。
当两个kpi是波动相关时,我们继续判断它们的时间顺序以及它们是否在同一方向上波动,如下所述。
波动相关的时间顺序,两个kpi的波动可能是同步的,也可能是以一定的时间间隔移动的。具体地说,我们用X→Y来表示X在Y之前波动的情况。如果两者的波动同时发生,我们表示这是X↔Y。由图1(a)可知,K2和K3的波动同时发生,即K2↔K3,而K1在K2和K3之前波动,即K1→K2, K1→K3。
flux-correlation的方向,当X和Y的波动是相关的,相关可以是正的,也可以是负的。当X的波动增大而Y的波动减小时,两者的波动相关性为负,表示为X−←→Y(或X−→Y)。另一方面,如果X的波动增加(或减少),对应的Y的波动也增加(或减少),它们的波动相关性为正,表示为X +←→Y(或X +→Y)。在图1(a)中,k2和K3的波动正相关,而k1与k2和K3的波动负相关。
根据这些定义,我们的目标是解决以下问题,记为问题Q1 ~ 3:
确定两个kpi之间是否存在波动相关性(Q1);
对波动相关kpi,了解其波动的时间顺序(Q2);
确定波动相关性的方向(Q3)。
3、核心理念
为了解决上述问题,我们设计了一种无监督的方法,称为CoFlux,如图3所示。CoFlux的输入是两个kpi。我们首先通过特征工程提取其波动特征,然后测量这些波动特征的相关性。最后,我们提供Q1 ~ Q3问题的答案。请注意,CoFlux的目标是在很长一段时间内确定kpi的波动相关性,因此它是一个离线模型,实时性不是我们的目标。此外,考虑到目前的数据,波动相关结果可以定期更新(例如,每周或每月更新一次)。

特征工程是该体系结构中的一个关键组成部分,即寻找合适的时间序列模型作为波动特征提取器。虽然已有许多模型被提出用于预测时间序列,如MA(移动平均)、TSD(时间序列分解)[19]等,但每个模型都只能很好地拟合时间序列的某些类型的特征。例如图1(a)所示的两个kpi, k4具有较强的周期性,而k5是稳定的。对于周期性kpi,像TSD和历史平均这样的模型可能是合适的。MA或加权MA可以更好地预测稳定的kpi,因为它们的预测主要依赖于最近的值[20]。当然,没有通用模型可以准确预测任何类型的kpi。如第1节所述,我们面临的挑战是拥有大量不同特征的kpi。人工为每一个预测模型寻找一个合适的预测模型是非常耗时和不切实际的。
因此,我们不能依靠单一的时间序列模型来提取波动特征。相反,为了使CoFlux尽可能多地通用,我们采用了几个普遍接受的模型和相应的参数作为波动特征提取器。本设计基于以下两个直观感受:
对于任何给定的KPI,如果我们调查广泛的模型,将会有一个或多个模型能够足够精确地预测其正常的观测结果,并产生一个接近真实的波动特征。
如果两个kpi X和Y是波动相关的,那么X的至少一个波动特征和Y的一个波动特征是相关的。
在第5.4节中,我们将使用大量的实验来验证这两种直觉。在提取波动特征的基础上,通过去噪和放大对其进行改进。
为了确定波动相关性,对于每一对kpi,我们通过互相关17计算其波动特征的成对相关性。然后,使用最大值来确定这两个kpi是否与波动相关。由于我们在CoFlux中加入了许多波动特征提取器,一些可能能够提取接近真实的波动特征,而另一些可能由于预测不准确而产生误导的波动特征。平均所有波动特征或多数投票决定将产生假阴性。当然,我们只考虑最大值的方法可能会导致潜在的假阳性。我们将使用第5.4.1节中的实验来说明,使用好的波动特征提取器,假阳性是非常少的。
4、设计
在本节中,我们将详细描述CoFlux的两个组成部分:特征工程和相关度量。我们从特征工程开始。
4.1 特征工程
4.4.1特征提取
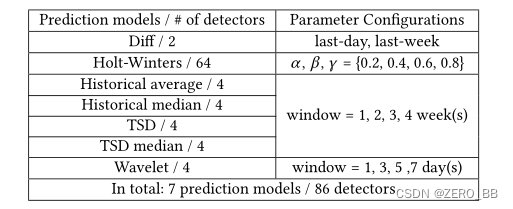
如前所述,kpi通常具有不同的形状和时间序列特征。为了理解它们的波动相关性,我们需要使用不同的合适的时间序列模型来生成波动特征。我们仔细挑选了7个应用广泛的模型,如表1所示。Diff[3]只是分别使用前一天或上周的值来预测当前的值。Holt-Winters[21]使用三个平滑方程(水平、趋势和周期成分)计算预测值,三个参数范围从0到1。历史平均值/中值[18]计算窗口内历史数据的平均值/中值作为一个预测。TSD(时间序列分解)[19]从KPI中提取四个成分:水平、趋势、周期性、噪声,然后使用前三个成分的总和进行预测。TSD Median与TSD相似,但在计算这三个分量时使用的是中值而不是均值。小波分解[22]可以覆盖KPI的整个频域,我们将高频部分设置为预测。
大多数时间序列模型都有一个或多个参数,它们的参数必须进行调整以适配KPI。然而,参数调优可能非常耗时,通常需要领域知识。在我们的研究中,我们的最终目标是确定波动相关性。只要模型能够做出足够准确的预测,使所获得的波动特征能够捕捉到真实的波动模式,就不需要努力寻找最佳的拟合参数。因此,在CoFlux中,对于每个模型参数,我们根据经验列举出可能的值。例如,小波的参数可以有几个可能的值。对于每一个参数配置(例如win=1天),小波模型可以产生一个预测的KPI,然后是一个波动特征。我们将具有特定参数配置的时间序列模型视为波动特征检测器。从表1所示的模型和参数配置中,我们总共得到86个检测器。相应地,对于每个KPI,它们都会产生86个波动特征。
当然,如果需要,我们在CoFlux中的波动特征提取模块可以配置其他模型或参数值。请注意,我们已经仔细评估了最广泛使用的时间序列模型。通过我们的实验,我们发现其中一些模型,如MA(移动平均)[20],WMA(加权MA)和指数WMA,在从我们的测试kpi中提取波动特征方面表现不佳,因为这些模型的预测主要依赖于近期数据,不能处理周期性的kpi。图4显示了一个例子,MA错误地将KPI的主要模式中的周期性捕获为波动特征,导致假阳性。
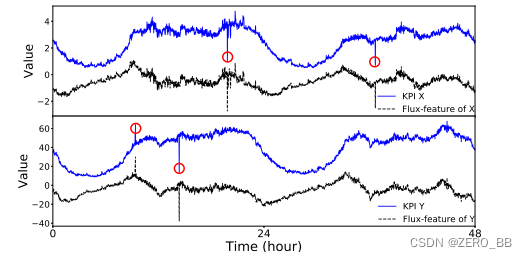
图4:两个非波动相关的kpi及其通过移动平均提取的波动特征;圆圈表示波动较大。
4.1.2 特征放大
在特征提取之后,每个KPI得到86个原始波动特征。不同kpi的原始波动特征通常具有不同规模和单位的值。我们应用z-score对每个波动特征进行归一化。在标准化波动特征中,一个值越接近于零,KPI波动就越小。
一般来说,KPI中的大多数值看起来相当正常,它们与预测值略有偏离,主要是由于噪声。为了减小噪声的影响,我们使用了修正的指数激活(Eq. 1)来增强大波动。Eq. 1放大明显偏离零的值,而对接近零的值影响很小。这种放大可以使波动特征更加清晰,有助于波动相关性的识别。在CoFlux中,我们设置α = 0.5(生长程度越大,生长速度越快)和β = 10(如果|x| > β, f值不会增长)。修正的指数激活的有效性将通过实验进行评估,并在后面的5.4.3节中讨论。
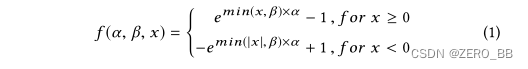
4.2相关性度量
互相关[17]作为一种时滞时间序列相似性度量方法,在信号和图像处理中得到了广泛的应用。互相关可以很好地确定两个时间序列的形状相似度,考虑了它们在振幅和畸变上的差异阶段,

适合对CoFlux中的三个问题进行判断。因此,我们选择互相关来衡量CoFlux中波动特征之间的相关性。两个放大flux-features G =(д1 , · · · , дl)和H = (h1 , · · · , 霍奇金淋巴瘤),考虑到G和H沿着时间轴之间的转变,互相关总是保持一个向量(例如,H)静态,让另一个(例如,G)幻灯片/ H为每个转变计算内积的G (s∈(−l, l),L为放大波动特性的长度)。Gs,即值s(特别是G0= G)发生位移的向量,可表示为:
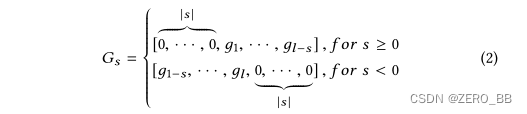
g和H的内积及其互相关值可计算为:
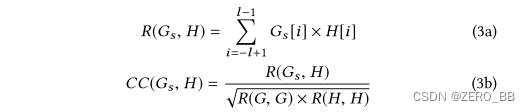
枚举s的所有可能值,我们可以得到一个长度为2l−1的互相关值向量。设向量的最小值为minCC,最大值为maxCC,分别对应移位后的值s1和s2。则G与H的最终互相关值为F CC: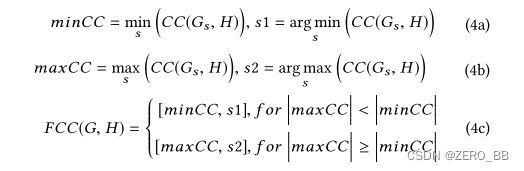
由式3可知,F CC∈[−1,1]。F CC越接近1或-1,G和h的相关性越强,且F CC为正表示方向一致,F CC为负表示一个波动特征增加,另一个波动特征减少,反之亦然。互相关的有效性可以在第5.4.4节中看到。
如算法1所示,通过放大波动特征,我们可以很容易地分析两个kpi的波动相关性。我们列举所有放大的波动特征对,计算它们的互相关值。其中,选择绝对值最大的值作为最终得分,并与阈值进行比较,以确定kpi之间是否存在波动相关性。这个阈值可以由实际需求决定,也可以由精度召回曲线决定,如第5.4.1节所述。如果最终得分的绝对值低于阈值,则X≁Y;否则X∽Y。由X∽Y确定的时间顺序和方向。时间顺序可由X的移位值决定。若为零(即无移位)则X↔Y;如果是负数(即X向左移动),则X→Y;否则,Y→X。这种波动相关性可以是正的,也可以是负的,正如最后的分数所表明的那样。
5、评估
在本节中,我们将使用两个真实的数据集来评估CoFlux的性能。
5.1数据集
我们从一家顶级的全球互联网公司收集了两个数据集,命名为数据集I和II。每个数据集包含许多kpi,它们的波动相关性已由领域专家标记,以便为我们提供评估的基本事实。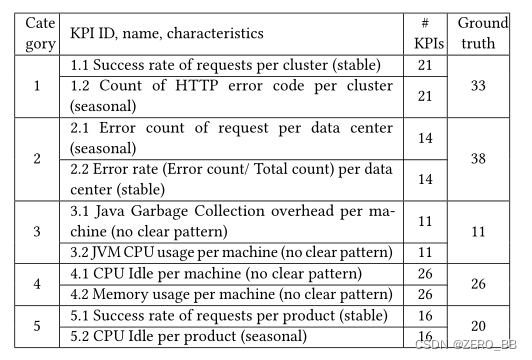
数据集I:具有不同时间序列特征的波动相关kpi。如表2所示,数据集I包含5个类别,每个类别有从不同的服务器集群、机器或产品收集的两种kpi。这两个波动相关的kpi往往具有不同的时间序列特征(如周期性、稳定性)。例如,在第一类中,“请求成功率”的波动往往伴随着“HTTP错误码数”的突然变化,即“请求成功率”−“HTTP错误码数”←→“HTTP错误码数”。
数据集II:具有同质时间序列特征的波动相关kpi。数据集II包含从10个软件模块使用的服务中收集的kpi,客户可以从这些服务中按需向提供商请求服务。具体情况见表3。所有kpi都受到客户请求数量的严重影响,因此它们都是周期性的。在每个模块中,服务在一个链中被调用,因此相应的kpi之间以时间顺序相互关联。例如,在模块1中,20个kpi中有9个与波动相关。当“#客户请求提供商”中出现波动时,一段时间后,波动传播到“#供应商接受和管理订单”,然后传播到“#客户支付订单”,等等。
表3:数据集II: 10个软件模块的kpi数据。所有kpi都是周期性的。“Ground truth”列列出了模块内波动相关的KPI对的数量。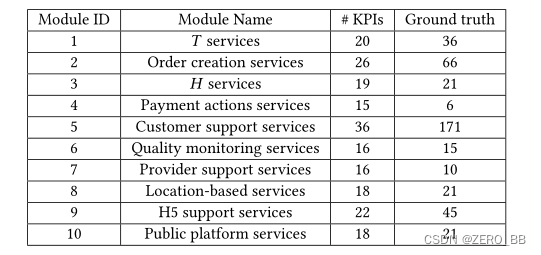
请注意,在我们的实验中只测量了类别内和模块内的波动相关性。例如,在数据集II中,模块1中的20个kpi之间进行了成对的波动相关性。
5.2基线算法
没有专门设计的方法来计算kpi的波动相关性。为了证明CoFlux的有效性,我们精心选择了7种基线算法。
5.2.1 J-measure。一种广泛使用的事件相关方法[2],该方法计算的相关性作为一个概率分类规则的平均信息内容。J-measure是为事件相关性而设计的,这里不能直接使用。因此,我们需要首先检测异常。回想一下,波动特征是预测误差。我们将异常定义为在波动特征中与均值相差2个标准差[18]以上的值,波动特征的选择将在稍后描述。结果,KPI被转换为二元序列。对于两个二元变量X - andY,如果J-Measure的相关性大于某一阈值,则X -∽Y。否则,X≁Y。这种方法既不能确定时间顺序,也不能确定相关方向。
为了公平比较,对于J-measure中的异常检测,我们枚举了表1中的所有检测器,并为每个数据集选择一个能提供最佳f1评分的检测器(见5.3节)。同样的方法也被用于为其他两个算法,Pearson 2和Granger 2选择性能最好的检测器。
5.2.2 SIG[9]。[9]利用KL散度计算时间序列的异常信号,然后利用互相关得到相关结果。但其异常信号为相对熵且非负,SIG无法判断相关方向。
5.2.3 Pearson相关性。[2]是研究两个变量(比如X和Y)之间相关性的一种流行技术。阈值为T H,如果ρ > T H,则X和Y呈正相关;如果ρ <−1∗T H,两个kpi是相关的,方向是负的。如果不是,X≁Y。该方法不考虑相关的时间顺序。在这里,我们计算每对原始kpi(记为Pearson 1〇)和每对放大流量特征(记为Pearson 2〇)的Pearson相关性,以进行公平比较。
5.2.4格兰杰因果关系。格兰杰因果关系[14]利用V AR(向量自回归)捕捉时间序列之间的线性相互依赖关系。具体来说,当且仅当Y的相应系数中至少有一个非零时,Y格兰杰导致X。如果Y格兰杰-导致X和X格兰杰-导致Y, 则X和Y同时发生。需要注意的是,格兰杰因果关系并不能表明相关性是正的还是负的。与Pearson 相关性类似,我们计算了原始kpi的格兰杰因果关系(记为格兰杰1〇)和流量特征的格兰杰因果关系(记为格兰杰2〇),以便进行公平比较。
5.2.5互相关。我们使用互相关(这也是CoFlux的一部分)来计算两个kpi之间的相关性,使用其原始值而不是波动特征。
5.3评价指标
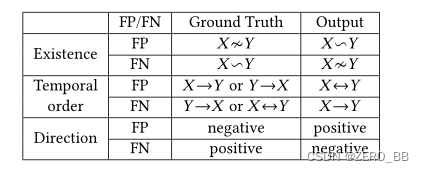
我们使用F1-Score来评估CoFlux和基线算法的有效性,定义为:F1-Score =2 × Precision × Recall / Precision + Recall , 精度= T P/T P + F P,召回=TP/ TP+ FN,表4描述了三个波动相关性问题的FP(假阳性)和FN(假阴性)。
由于J-measure、SIG、Pearson Correlation、Cross-correlation和CoFlux的阈值通常是根据精度和召回率的实际需求来确定的,因此我们使用PRC (precision recall Curve),通过将阈值从0变化到1来显示它们的性能。靠近右上方的PRC比靠近左下方的PRC具有更好的性能。此外,可以使用PRC选择最佳F1-Score。
5.4结果与观察
5.4.1 CoFlux vs基线算法。我们使用之前描述的两个数据集比较了CoFlux和七个算法。
表5列出了八种算法计算出的PRC的最佳F1-Scores。CoFlux算法在两个数据集上都显著优于其他7种算法。CoFlux对两个数据集的F1-Scores的总体最佳值分别在0.84、0.92和0.95以上(Q1 ~ 3)。此外,图5所示的prc表明,CoFlux在所有的精度和召回率组合上都有较好的整体表现。
表5:八种算法的最佳F1-Scores;对于J-measure,数据集I的最佳检测器是小波(win=1天),数据集II的最佳检测器是TSD(win=2周);对于Pearson ②,数据集I的最佳检测器是小波(win=1天),数据集II的最佳检测器是diff(win=1天);对于Granger②,数据集I的最佳检测器为小波(win=1天),数据集II的最佳检测器为TSD(win=2周)。(“N/A”表示没有结果)。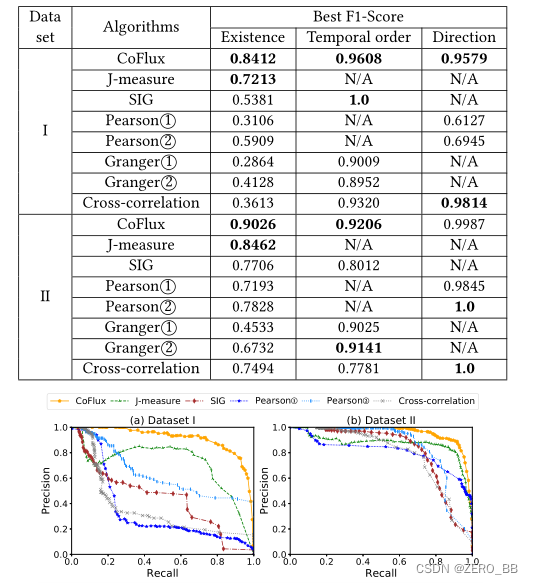
图5:CoFlux与五种基线算法之间存在波动相关性的prc。格兰杰因果关系在这里没有显示,因为它没有阈值,因此没有PRC。
另一个观察是,这些算法在数据集II中都比在数据集I中表现得更好,因为数据集II中的kpi在本质上是同质的(它们都是服务调用图的一部分,严重受客户请求模式的影响),而且波动遵循相同的模式,而数据集I中的数据则随时间序列特征而变化。因此,从数据集II提取波动相对容易。接下来,我们分析了每种算法在回答Q1 ~ 3时的性能。
对于Q1,我们的CoFlux在很多方面都优于其他算法。特别是,与数据集II相比,它在数据集I中的性能略有下降,而其他算法有更显著的变化。这表明CoFlux非常健壮,由于其丰富的检测器库,可以处理异构kpi。图6中f1得分最高的精确度和召回率提供了这些算法之间性能差异的更多细节。特别是CoFlux的精度高,在识别波动相关性时假阳性率小。这证明了用最大绝对互相关值来确定最终的波动相关是合适的,如第3节所述。
J-measure在我们的实验中获得了第二好的性能。根据F1-Score,对数据集I表现最好的检测器是小波(win=1天)。该检测器将KPI分解为一组层次结构系列[22]。然而,有些kpi没有很强的结构特征,很难预测。因此J-measure执行得比较好。对于数据集II, TSD(win=2 weeks)是最好的检测器,它非常适合该数据集kpi的周期性结构。SIG的异常信号是通过KL散度来计算的,与异常值的处理效果很好,不适合主要由部分历史数据判断的异常。因此,SIG在数据集I上的表现并不好,因为各种类型的kpi使得它的异常也很复杂。
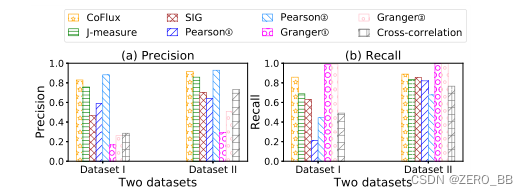
对于Pearson①,数据集I与数据集II相比,召回率显著下降,因为两个不同形状的波动相关kpi往往具有较弱的线性关联。皮尔逊②比皮尔逊①表现得更好,因为它使用了波动特征,它删除了KPI的大部分内在特征。Granger①试图用一个KPI来预测另一个KPI,其预测绩效主要依赖于原始KPI而不是波动部分,因此表现不佳。格兰杰②比格兰杰①工作得更好,但也不能达到令人满意的性能,因为在我们的情景中,波动特征通常是由意外事故产生的,不能用回归来预测它们。与原始kpi的相互关联对于波动相关性并不适用,因为波动相关性主要关心波动而不是原始kpi。它在数据集I上的表现比数据集II差,因为数据集I的kpi具有不同的特征,这也证明了波动特征的有效性。
现在我们来看Q2。注意,只有在算法正确识别出KPI对的波动相关Q1后,对Q2和Q3的测试才会继续对这对进行测试。格兰杰因果关系在识别时间顺序上的F1-Score约为0.90,但在识别波动相关的Q1时存在困难。结果,它的整体表现并不令人满意。用Pearson Correlation和Jmeasure无法计算波动相关的时间顺序。另一方面,由于使用了互相关,CoFlux和SIG在识别时间顺序方面表现得非常好。
最后,对于Q3, Pearson Correlation可以表示正或负的波动相关。这个方向不能通过SIG、Jmeasure和格兰杰因果关系得到。同样,CoFlux在这方面有出色的表现。
总结:CoFlux的性能优于基于异常检测的J-measure算法,因为CoFlux不需要定义异常,且其波动特征比异常检测的二进制结果具有更多的信息。对于SIG,利用KL散度计算kpi的异常信号,从而集中于离群点不能识别主要由部分历史数据判断的异常。与SIG相比,我们包含了一组健壮的波动特征,因此CoFlux对各种异常和KPI特征具有健壮性。CoFlux的表现优于Pearson①、Granger①和Cross-correlation,这是因为原始kpi不能很好地反映波动相关性。与皮尔逊②和格兰杰②不同,CoFlux使用了互相关,考虑到振幅和相位的畸变,它可以很好地处理波动特征的形状相似性。而且在实践中,对于J-measure, Pearson②,Granger②,对于不同kpi的异常检测器选择也是非常具有挑战性的,而CoFlux中对于不同kpi的检测器选择是自动确定的。
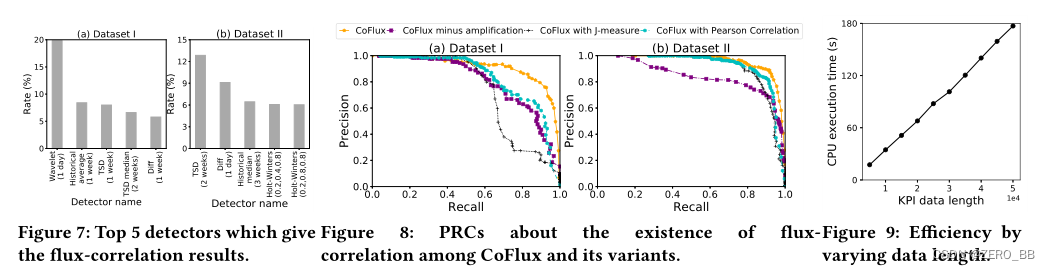
5.4.2 CoFlux中探测器的分析。由于CoFlux使用了一些具有不同参数的时间序列模型作为其波动特征探测器,一个自然的问题是,是否需要这么多的探测器,以及什么探测器最有用。我们分析了用于为每个数据集中的所有kpi对生成最终波动相关性的检测器。图7显示了两个数据集中使用的前5个检测器。小波在数据集I中最流行,而TSD在数据集II中领先。这可以用以下事实来解释:我的数据集中的许多kpi没有固定的结构特征,小波更适合这种类型的kpi。数据集II中的大多数kpi都具有周期性特征,TSD可以很好地处理这些特征。在这两种情况下,Top 1检测器的比例都不超过20%,每个数据集中Top 5检测器的总比例都小于50%。因此,我们可以得出结论,为了增强CoFlux的鲁棒性,有必要在表1中加入各种检测器。
5.4.3 CoFlux特征放大的有效性。在本节中,我们将评估特征放大是否确实能够改善CoFlux的性能。图8显示了有扩增和没有扩增两种版本的CoFlux获得的prc。在没有放大的情况下,CoFlux的性能明显下降。特征放大可以使较大的波动变大,从而降低噪声对磁通特征的影响,从而提高性能。
5.4.4 CoFlux中互相关的有效性。在本节中,我们通过测量CoFlux中波动相关性的存在来评估相互关联的好处。由于格兰杰因果关系的效果不如其他算法,我们在CoFlux中分别使用Pearson Correlation和J-measure来代替互相关,分别表示为CoFlux with Pearson Correlation和CoFlux with J-measure。图8显示了它们的prc,这表明CoFlux通过互相关获得了更好的性能。主要原因是Pearson Correlation和J-measure都不能恰当地处理波动相似性,以及两个kpi的波动之间存在延迟的情况。我们还可以了解到,由于Jmeasure异常定义的困难,Pearson Correlation比J-measure表现得更好。因此,用互相关法进行波动相关测量是一个很好的选择。
5.4.5 CoFlux的效率研究。CoFlux的效率实验是在一台24核Intel® Xeon® CPU E5-2620 v3 @ 2.40GHz、64GB RAM的服务器上进行的。一个KPI的流量特性只计算一次,并在与其他KPI的相互关联度量中反复使用。数据集I和II的执行时间如表6和表7所示。数据长度是KPI中数据点的数量。所有KPI类别和模块的执行时间均小于25分钟。当然,更长或更多的kpi可以增加执行时间。此外,通过使用更多的计算资源可以显著减少执行时间。
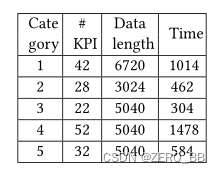
表7:数据集II(长度:6720)的执行时间(秒)。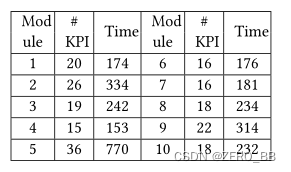
此外,我们还测试了KPI长度对执行时间的影响。为了获得不同长度的kpi,我们使用两个合成kpi并改变它们的长度。如图9所示,执行时间几乎以线性方式随KPI长度增加。当数据长度从5k增加到50k时,它的范围是15 - 180秒,而基线算法小于20秒。考虑到CoFlux是离线的,时间是可以接受的。特征工程的时间对数据长度非常敏感,计算代价为O(n),其中n为KPI长度。在检测器数量一定的情况下,互相关的时间复杂度受数据长度的影响。采用快速傅里叶变换加速互相关,计算复杂度为O(nloд(n))。
6、应用COFLUX
在本节中,我们将演示如何使用CoFlux来帮助运营商协助顶级在线购物服务公司进行服务故障排除。
6.1用于告警压缩的集群kpi
我们评估了CoFlux在公司提供的118个kpi上的告警压缩效果。操作员通过对单个kpi的异常检测,手动分析一个月内生成的699个告警。他们得出的结论是,只有184个告警应该被提出(作为我们评估中的ground-truth),而所有其他告警都与ground-truth中的告警相关。
为了演示如何使用CoFlux压缩告警[8]并减少操作人员的工作负载,我们根据kpi的绝对波动相关值,通过K-Means将这些kpi分组为23个集群。K由剪影系数(silhouette coefficient)[23]确定,该系数在实验中表现出较好的聚类效果,不同聚类数下剪影系数最大,说明聚类K最好。图10显示了由24个kpi组成的3个集群。显然,集群内的KPI对比集群外的KPI具有更强的波动相关值。
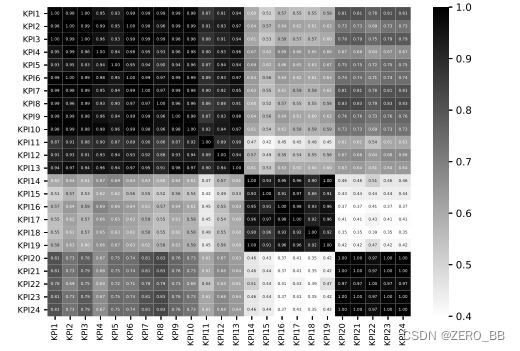
图10:24个kpi聚类结果的热图可视化(x, y)处的值表示KPI x和y之间的绝对波动相关值。Cluster1: KPI1 ~ KPI13;Cluster2: KPI14 ~ KPI19;Cluster3: KPI20 ~ KPI24。
然后,我们可以监控整个集群中的所有kpi,当这些kpi上出现一个或多个异常时,只发出一个告警,只产生208个告警,压缩比达到70.24%(1208/699)。我们通过比较压缩告警与ground-truth告警来计算压缩精度,CoFlux得到0.9748 compression F1-Score。为了比较,我们进行了另一个实验,根据原始kpi的互相关聚类,得到了70.67%的压缩比和0.8322的压缩F1-Score。在实践中,保持较高的压缩F1 - score(即接近1)是告警聚类的关键。尽管这两个实验给出了相似的压缩比,但CoFlux聚类导致的压缩错误远远小于原始kpi的互相关,这表明了它在告警压缩方面的出色能力。
6.2推荐前N个波动相关kpi
图11显示了一个给定的KPI(比如X),以及在剩余的117个按流量相关性排序的KPI中,它的前5个流量相关KPI。显然,这些KPI与KPI X具有高度的波动相关性。因此,当KPI X出现异常时,操作人员可以将他们的分析范围缩小到排名前N的波动相关KPI,以便更有效地诊断。受HitRate@K用于推荐系统[24]的想法的激励,我们使用第6.1节中的kpi计算推荐精度,HitRate@5的结果是0.8051。相比之下,HitRate@5基于原始kpi互相关的推荐仅达到0.5594。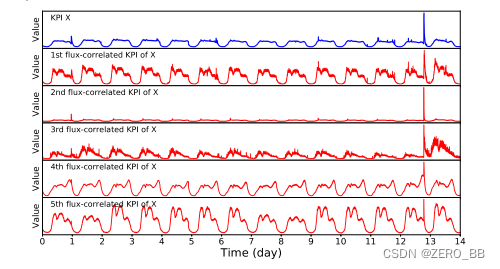
图11:给定KPI X的前5个流量相关KPI
6.3 构造涨落传播链
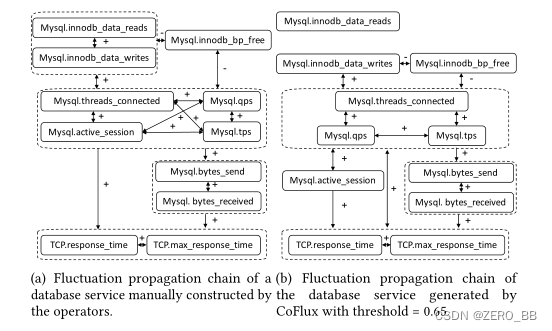
图12:由运营商和CoFlux构建的数据库服务波动传播链。→和↔表示流量相关的时间顺序,+和-表示方向。
了解波动如何通过kpi传播对于根本原因分析非常有用,但这需要对kpi有深入的领域知识。基于波动相关性,可以直观地构造波动传播链。图12为互联网公司数据库服务链,其中每个节点表示KPI,每个边表示KPI之间的波动相关性。要使图形不那么拥挤,以虚线框结束的边意味着此边的初始KPI与此框内的每个KPI具有波动关联。图12(a)给出了操作者基于深度领域知识手工构建的波动传播链,作为我们比较的ground truth。当存储引擎中的SQL执行出现波动时,它首先传播到连接/线程模块,然后传播到为数据库提供托管服务的网络接口卡。图12(b)为CoFlux产生的波动传播链。很显然,图12(b)几乎可以复制图12(a), Q1 ~ 3的F1-scores分别为0.8684,0.9524,1.0。因此,即使不需要深入的领域知识,操作者也可以应用CoFlux自动构建波动传播链。相比之下,原始kpi的互相关达到较低的f1得分:Q1 ~ 3分别为0.5455、0.9412和1.0。
7、相关工作
多年来,人们进行了大量的研究来分析不同类型的相关性,这些相关性可以分为三类:KPI之间的相关性[14,17,25],事件之间的相关性[6],事件与KPI之间的相关性[2]。这些关联算法主要是分析原始kpi之间的相关性,或者将kpi转化为事件,利用事件进行关联分析。根据第5.4.1节的分析,这些算法不能准确地分析波动相关。
除了我们的基线算法,还有其他旨在找到kpi之间关系的通用方法。协整(CoIntegration)[13]通过线性组合将一组非平稳kpi转换为平稳。然而,波动相关的kpi可能有类似的波动,但周期和趋势成分不同。因此,它们不能通过协整很容易地变得稳定。V ARMA[12]是一个对许多KPI变量进行线性预测的模型,并为KPI之间的相关性提供了直观的解释。然而,通过5.4.1节中格兰杰因果关系的实验,我们发现通过回归很难对波动特征之间的相关性进行建模。[10]使用ARCH模型来预测股票市场的波动,并了解它们之间的相关性,但是波动,用时间序列的标准差来衡量,与我们上下文中的波动在概念上是不同的。
综上所述,所有这些方法都不能很好地识别波动相关性。我们的工作与他们的不同之处在于,我们通过时间序列模型提取特征,捕捉波动,并关注波动特征,而不是原始的kpi。
8、结论
根据波动关联kpi对于服务故障排除在许多方面都非常有用,例如告警压缩、推荐与流量相关的Top N kpi以及构造波动传播链。然而,在互联网服务运营管理领域中,这种KPI波动相关性的研究还很少。就我们所知,本文是对波动相关性进行详细阐述和研究的首次尝试。对于数量多且特征多样的kpi,利用CoFlux,我们可以自动且稳健地测量它们的波动相关性。我们的实验表明,CoFlux在很大程度上优于基线算法,CoFlux在一家全球顶级互联网公司的应用也证明了它在协助服务故障排除方面的有效性。
作为我们未来的工作,我们将探索深度学习作为波动相关算法和可能的模型来拟合波动特征,以进一步了解波动相关的本质。
9、感谢
我们感谢孟、刘平、赵能文、张盛林、孙永乾、孙瑜对这项工作的有益讨论。感谢廖珏星对本文的校对。这项工作得到了北京国家信息科学与技术研究中心(BNRist)重点项目和大川研究基金的支持。
参考文献
[1]迈克·帕帕佐格鲁和威廉·扬·范登·赫维尔。面向服务的体系结构:方法、技术和研究问题。中国科学:地球科学,2017,36(3):369 - 372。
[2]罗晨,楼建光,林庆伟,傅强,丁蕊,张冬梅,王哲。将事件与时间序列关联,用于事件诊断。第20届ACM SIGKDD知识发现和数据挖掘国际会议论文集,第1583-1592页。ACM, 2014年。
[3]刘大鹏,赵友建,徐浩文,孙永乾,裴丹,罗姣,景晓伟,冯梅。实践:通过机器学习实现实际的自动异常检测。2015年互联网测量会议论文集,第211-224页。ACM, 2015年。
[4]张盛林,刘颖,裴丹,陈宇,瞿先平,陶世民,臧智,景晓伟,冯梅。漏斗:评估基于网络的服务中的软件变化。IEEE服务计算学报,2016。
[5]孙永乾,赵有建,苏亚,刘大鹏,聂晓辉,袁孟,程世文,裴丹,张盛林,瞿先平,郭宣友。研究热点:具有多维属性的附加kpi异常定位。电子学报,2018,37(6):1097 - 1098。
[6]聂晓辉,赵友建,隋开新,裴丹,陈宇,瞿先平。基于web服务自动诊断的因果图挖掘。国际性能计算与通信会议(IPCCC), 2016 IEEE第35届国际会议,第1-8页。IEEE 2016。
[7]雅各布·科恩。行为科学的统计能力分析,1988年。
[8]徐景民,王远,陈鹏飞,王平。在高度动态的云环境中轻量级和自适应的服务kpi性能监控。2017 IEEE国际服务计算会议(SCC),第35-43页。IEEE 2017。
[9]亚当·J·奥利纳,阿舒托什·V·库尔卡尼,亚历克斯·艾肯。使用相关的惊讶来推断共同的影响。可靠性系统和网络(DSN), 2010 IEEE/IFIP国际会议,第191-200页。IEEE 2010。
[10]Yasushi Hamao, Ronald W Masulis和Victor Ng。国际股票市场价格变化和波动的相关性。金融研究,3(2):281 - 307,1990。
[11]Maurizio Filippone和Guido Sanguinetti。信息论新检测。模式识别,43(3):805-814,2010。
[12]赫尔穆特•Lutkepohl。用varma模型进行预测。经济预测手册,1:287 - 325,2006。
[13]理查德·哈里斯ID。在计量经济学建模中使用协整分析。1995。
[14]邱慧达,刘燕,李伟昌。时间序列异常检测的格兰杰因果关系。数据挖掘(ICDM), 2012, IEEE第12届国际会议,第1074-1079页。IEEE 2012。
[15]范建清,姚启伟。非线性时间序列:非参数和参数方法。施普林格科学,商业媒体,2008。
[16]Shashank Shanbhag和Tilman Wolf。通过并行度精确的异常检测。网络学报,23(1):22-28,2009。
[17]Yasushi Sakurai, Spiros Papadimitriou,和Christos Faloutsos。Braid:通过组滞后相关性进行流挖掘。在2005年ACM SIGMOD数据管理国际会议论文集,第599-610页。ACM, 2005年。
[18]Suk-Bok Lee, Dan Pei, MohammadTaghi Hajiaghayi, Ioannis Pefkianakis, Songwu Lu, He Yan, Zihui Ge, Jennifer Yates, Mario Kosseifi。3g可伸缩监控的阈值压缩。参见INFOCOM, 2012 Proceedings IEEE, 1350-1358页。IEEE 2012。
[19]陈颖颖,Ratul Mahajan, Baskar Sridharan,张志立。web搜索响应时间的提供者侧视图。在ACM SIGCOMM计算机通信评论,第43卷,第243-254页。ACM, 2013年。
[20]David R Choffnes, Fabián E Bustamante,和Zihui Ge。众包服务级网络事件监控。计算机学报,41(4):387-398,2011。
[21]何燕,Ashley Flavel, Zihui Ge, Alexandre Gerber, Dan Massey, Christos Papadopoulos, Hiren Shah, Jennifer Yates。Argus:从isp的角度,端到端服务异常检测和定位。参见INFOCOM, 2012 Proceedings IEEE,第2756-2760页。IEEE 2012。
[22]Keyi Zhang, Ramazan Gençay, M Ege Yazgan。小波分解在时间序列预测中的应用。《经济研究》,2017年第4期。
[23]凯瑟琳S波拉德和马克J范德兰。一种在基因表达数据中识别重要簇的方法。2002。
[24]杨希旺,郭杨,刘勇。使用社交网络的top-k推荐。在第六届ACM推荐系统会议记录中,第67-74页。ACM, 2012年。
[25]威廉·A·加德纳,安东尼奥·纳波利塔诺,路易吉·保拉。循环平稳性:半个世纪的研究。信号处理,32(4):639 - 647,2006。














 1909
1909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









