







过拟合的问题
正则化通过加大对参数Θ的惩罚力度可以减轻过拟合问题。
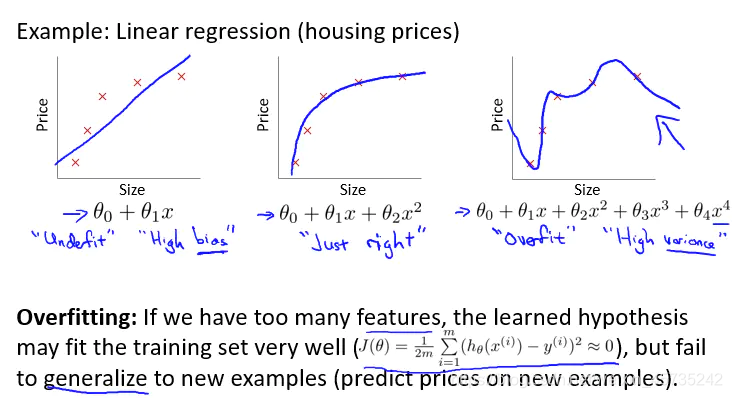
下图左1:欠拟合(underfitting)具有高偏差(high bias)。
下图中1:合适。
下图右1:过拟合(overfitting)具有高方差(high variance)。
泛化(generalize):指假设模型能应用到新样本的能力。
在线性回归中:
在逻辑回归中:
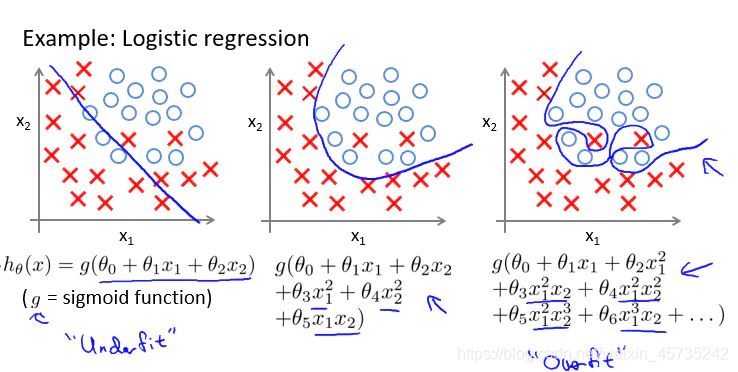
特征维度太多,样本数据太少,过度拟合就会发生:

解决过度拟合方法:
1.减少特征数量(缺点:舍弃了一部分信息):
手动选择;
使用模型选择算法。
2.正则化(regularization):
保留所有的特征,但是减少参数θj的大小(magnitude/values),当我们有很多特征的时候依然工作很好,并且每个特征都对预测y有一定的贡献。

代价函数


正则化的思想:
减小高次项的θ值,使得曲线平滑(即加入惩罚项)。
加入正则项(不将 θ0 加入惩罚项,实际上加不加入影响不大)。
λ是正则化参数,保持我们能很好的拟合数据,保持参数较小从而避免过拟合。
λ不能太大(惩罚力度大),否则就是一条直线,(underfitting/too high bias),肯定也不能太小(惩罚力度小),否则就没效果了。


线性回归的正则化
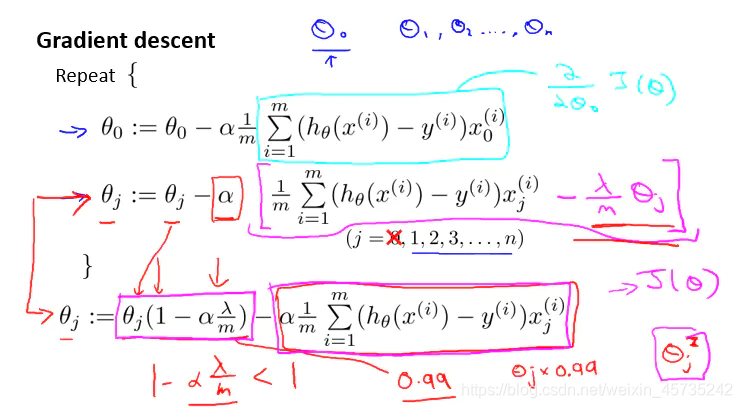
基于梯度下降(gradient decent)算法下的正则化线性回归计算:
通常不将 θ0 加入惩罚项,所以排除在外。
其他相当于把 θj 减小。
基于正规方程(normal equation)中的正则化线性回归计算:
X:每一行代表一个单独的训练样本。

如果样本数量(m)小于特征数量(n)那么矩阵不逆;虽然在Octave中运用pinv函数能得到伪逆矩阵,但是不能得到较好的假设模型。
在正则化中已经考虑到这个问题,所以加入正则化项后,只要 λ>0 那么该矩阵可逆。
正则化还可以解决一些 (XTX)-1 出现不可逆的问题。

Logistic.回归的正则化
改进在线性回归中的两种算法,使其能够应用到正则化逻辑回归中:
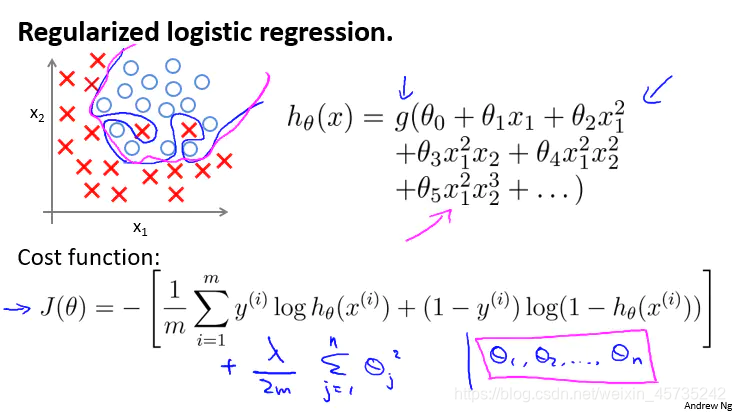
在Octave中:
使用高级优化算法需要我们自己定义一个 costFunction 函数(在Octave中下标从1开始)。
然后将定义的函数赋给 fminunc(@costFunction,…) 函数。















 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









