







基于PaddleX实现电梯电瓶车检测
源地址.
一、项目背景
电动车因为具有便捷、轻巧、无污染等优点,成为了广大民众出行的重要选择,但是电动车自身的电瓶存在安全隐患,目前仍然没有办法实现绝对的安全,近年来,电动车在室内、电梯内发生自燃、自爆的事件在新闻上常有报道,这些现象严重危害到了居民的生命、财产安全。
因此,本项目将以“电梯电瓶车检测”为首要目标进行开发,待项目开发成功以后,可以很容易地将本项目迁移到居民楼门口、办公楼门口、餐厅门口等众多关键场地,而且本项目的成本低廉,检测效率高,可应用的场景十分广泛,具有巨大的商业价值。
二、数据集简介
1. 数据获取
- 为了获取大量数据,以及节省标注时间,所以将
pascal-voc和coco2017中的摩托车数据提取出来,作为数据集。
2. 解压数据集和安装第三方库
!rm -rf data/pascalvoc
!rm -rf data/val2017
!rm -rf data/train2017
!rm -rf data/annotations
!unzip -oq /home/aistudio/data/data4379/pascalvoc.zip -d data/
!unzip -oq /home/aistudio/data/data7122/train2017.zip -d data/
!unzip -oq /home/aistudio/data/data7122/val2017.zip -d data/
!unzip -oq /home/aistudio/data/data7122/annotations_trainval2017.zip -d data/
!rm -rf motorbike
!pip -q install lxml
3. COCO2VOC
import os
import json
import cv2
from lxml import etree
import xml.etree.cElementTree as ET
import time
import pandas as pd
from tqdm import tqdm
import json
def coco2voc(anno, xml_dir):
if not os.path.exists(xml_dir):
os.makedirs(xml_dir)
with open(anno, 'r', encoding='utf-8') as load_f:
f = json.load(load_f)
imgs = f['images']
df_cate = pd.DataFrame(f['categories'])
_ = df_cate.sort_values(["id"],ascending=True)
df_anno = pd.DataFrame(f['annotations'])
categories = dict(zip(df_cate.id.values, df_cate.name.values))
for i in tqdm(range(len(imgs))):
xml_content = []
file_name = imgs[i]['file_name']
height = imgs[i]['height']
img_id = imgs[i]['id']
width = imgs[i]['width']
xml_content.append("<annotation>")
xml_content.append(" <folder>VOC2007</folder>")
xml_content.append(" <filename>"+file_name+"</filename>")
xml_content.append(" <size>")
xml_content.append(" <width>"+str(width)+"</width>")
xml_content.append(" <height>"+str(height)+"</height>")
xml_content.append(" <depth>3</depth>")
xml_content.append(" </size>")
xml_content.append(" <segmented>0</segmented>")
annos = df_anno[df_anno["image_id"].isin([img_id])]
for index, row in annos.iterrows():
bbox = row["bbox"]
category_id = row["category_id"]
cate_name = categories[category_id]
xml_content.append(" <object>")
xml_content.append(" <name>"+cate_name+"</name>")
xml_content.append(" <pose>Unspecified</pose>")
xml_content.append(" <truncated>0</truncated>")
xml_content.append(" <difficult>0</difficult>")
xml_content.append(" <bndbox>")
xml_content.append(" <xmin>"+str(int(bbox[0]))+"</xmin>")
xml_content.append(" <ymin>"+str(int(bbox[1]))+"</ymin>")
xml_content.append(" <xmax>"+str(int(bbox[0]+bbox[2]))+"</xmax>")
xml_content.append(" <ymax>"+str(int(bbox[1]+bbox[3]))+"</ymax>")
xml_content.append(" </bndbox>")
xml_content.append(" </object>")
xml_content.append("</annotation>")
x = xml_content
xml_content=[x[i] for i in range(0,len(x)) if x[i]!="\n"]
xml_path = os.path.join(xml_dir,file_name.split('.')[-2] + '.xml')
with open(xml_path, 'w+',encoding="utf8") as f:
f.write('\n'.join(xml_content))
xml_content[:]=[]
- 转换
coco2voc('data/annotations/instances_train2017.json', 'data/train2017voc/Annotations')
coco2voc('data/annotations/instances_val2017.json', 'data/val2017voc/Annotations')
4. 将pascal-voc和coco2017中的摩托车数据提取出来
- 需要将
coco2017中的motorcycle转换成motorbike
import os
import shutil
from tqdm import tqdm
import cv2
def voc2sc(ann_filepath, img_filepath, img_savepath, ann_savepath, classes, sc_class):
"""
ann_filepath: xml文件夹路径
img_filepath: 原图文件夹路径
img_savepath: 保存原图路径
ann_savepath: 保存xml文件夹路径
classes: 所有类别
sc_class: 挑选类别
"""
if not os.path.exists(img_savepath):
os.makedirs(img_savepath)
if not os.path.exists(ann_savepath):
os.makedirs(ann_savepath)
names = locals()
for file in tqdm(os.listdir(ann_filepath)):
fp = open(ann_filepath + '/' + file)
ann_savefile=ann_savepath+file
fp_w = open(ann_savefile, 'w')
lines = fp.readlines()
ind_start = []
ind_end = []
lines_id_start = lines[:]
lines_id_end = lines[:]
#在xml中找到object块,并将其记录下来
while "\t<object>\n" in lines_id_start:
a = lines_id_start.index("\t<object>\n")
ind_start.append(a)
lines_id_start[a] = "delete"
while "\t</object>\n" in lines_id_end:
b = lines_id_end.index("\t</object>\n")
ind_end.append(b)
lines_id_end[b] = "delete"
#names中存放所有的object块
i = 0
for k in range(0, len(ind_start)):
names['block%d' % k] = []
for j in range(0, len(classes)):
if classes[j] in lines[ind_start[i] + 1]:
a = ind_start[i]
for o in range(ind_end[i] - ind_start[i] + 1):
names['block%d' % k].append(lines[a + o])
break
i += 1
#print(names['block%d' % k])
# xml头
if len(ind_start) == 0:
fp.close()
fp_w.close()
os.remove(ann_savefile)
continue
string_start = lines[0:ind_start[0]]
#xml尾
string_end = [lines[len(lines) - 1]]
#在给定的类中搜索,若存在则,写入object块信息
a = 0
for k in range(0, len(ind_start)):
if sc_class in names['block%d' % k]:
a += 1
string_start += names['block%d' % k]
string_start += string_end
if 'size' not in str(string_start) and a != 0:
s = """ <size>
<width>{}</width>
<height>{}</height>
<depth>3</depth>
</size>
"""
img = cv2.imread(img_filepath + os.path.splitext(file)[0] + ".jpg")
idx = string_start.index('\t<object>\n')
string_start.insert(idx, s.format(img.shape[1], img.shape[0]))
for c in range(0, len(string_start)):
if '\t\t<name>motorcycle</name>\n' == string_start[c]:
string_start[c] = '\t\t<name>motorbike</name>\n'
fp_w.write(string_start[c])
fp_w.close()
#如果没有我们寻找的模块,则删除此xml,有的话拷贝图片
if a == 0:
os.remove(ann_savefile)
else:
name_img = img_filepath + os.path.splitext(file)[0] + ".jpg"
shutil.copy(name_img, img_savepath)
fp.close()
- 提取
pascalvoc中的摩托车
# pascalvoc类别
pascalvoc_classes = ['aeroplane','bicycle','bird', 'boat', 'bottle',
'bus', 'car', 'cat', 'chair', 'cow','diningtable',
'dog', 'horse', 'motorbike', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor', 'person']
# pascalvoc挑选类别
pascalvoc_class = '\t\t<name>motorbike</name>\n'
# 转换
voc2sc('data/pascalvoc/VOCdevkit/VOC2007/Annotations/', 'data/pascalvoc/VOCdevkit/VOC2007/JPEGImages/',
'motorbike/JPEGImages/', 'motorbike/Annotations/',
pascalvoc_classes, pascalvoc_class)
voc2sc('data/pascalvoc/VOCdevkit/VOC2012/Annotations/', 'data/pascalvoc/VOCdevkit/VOC2012/JPEGImages/',
'motorbike/JPEGImages/', 'motorbike/Annotations/',
pascalvoc_classes, pascalvoc_class)
with open('motorbike/labels.txt', 'w') as f:
f.write('motorbike\n')
print('len datas:', len(os.listdir('motorbike/JPEGImages')))
- 提取
coco2017中的摩托车
# coco2017类别
coco2017_classes = []
with open('coco_category.txt') as f:
for line in f.readlines():
coco2017_classes.append(line.strip())
# coco2017挑选类别
coco2017_class = '\t\t<name>motorcycle</name>\n'
# 转换
voc2sc('data/train2017voc/Annotations/', 'data/train2017/',
'motorbike/JPEGImages/', 'motorbike/Annotations/',
coco2017_classes, coco2017_class)
voc2sc('data/val2017voc/Annotations/', 'data/val2017/',
'motorbike/JPEGImages/', 'motorbike/Annotations/',
coco2017_classes, coco2017_class)
with open('motorbike/labels.txt', 'w') as f:
f.write('motorbike\n')
print('len datas:', len(os.listdir('motorbike/JPEGImages')))
5. 将文件路径写入.txt
import os
from tqdm import tqdm
import numpy
def path2txt(images_dir, anno_dir, txt_save_path, split_to_eval=False):
data = []
for line in os.listdir(images_dir):
data.append([os.path.join(images_dir, line), os.path.join(anno_dir, line.replace('jpg', 'xml'))])
if split_to_eval:
numpy.random.shuffle(data)
eval_data = data[:int(len(data)/10*2)]
data = data[int(len(data)/10*2):]
with open(txt_save_path.replace('train', 'val'), 'w') as f:
for item in tqdm(eval_data):
f.write('{} {}\n'.format(item[0], item[1]))
with open(txt_save_path, 'w') as f:
for item in tqdm(data):
f.write('{} {}\n'.format(item[0], item[1]))
path2txt('motorbike/JPEGImages', 'motorbike/Annotations', 'motorbike/train.txt', split_to_eval=True)
三、模型选择与开发
1. 安装paddlex
!pip -q install paddlex==1.3
2. 数据加载与预处理
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from paddlex.det import transforms
import paddlex as pdx
# 定义训练和验证时的transforms
train_transforms = transforms.Compose([
transforms.MixupImage(mixup_epoch=250),
transforms.RandomDistort(),
transforms.RandomExpand(),
transforms.RandomCrop(),
transforms.Resize(target_size=608, interp='RANDOM'),
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
])
eval_transforms = transforms.Compose([
transforms.Resize(target_size=608, interp='CUBIC'),
transforms.Normalize(),
])
# 定义训练和验证所用的数据集
train_dataset = pdx.datasets.VOCDetection(
data_dir='./',
file_list='motorbike/train.txt',
label_list='motorbike/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='./',
file_list='motorbike/val.txt',
label_list='motorbike/labels.txt',
transforms=eval_transforms)
3. 模型选择
- 这里我们选择的模型是
YOLOv3-MobileNetV1,其适合于后期边缘端的部署。 - 详细信息如下:
| 模型 | 模型大小 | 预测时间(ms/image) | BoxAP(%) |
|---|---|---|---|
| YOLOv3-MobileNetV1 | 99.2MB | 11.834 | 9.3 |
4. 模型训练
- 注:有时候会报这样的错,请等notebook空闲几十分钟(刚转换完数据会这样)。

# 初始化模型,并进行训练
num_classes = len(train_dataset.labels)
batch_size = 64
model = pdx.det.YOLOv3(num_classes=num_classes, backbone='MobileNetV1')
model.train(
num_epochs=200,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
train_batch_size=batch_size,
learning_rate=1e-4,
warmup_steps=len(train_dataset.file_list)//2,
save_interval_epochs=50,
save_dir='output/yolov3_mobilenetv1',
metric='VOC',
use_vdl=True,
early_stop=True)
四、效果展示
1. 模型预测
from paddlex.det import transforms
import paddlex as pdx
import os
# 数据处理
eval_transforms = transforms.Compose([
transforms.Resize(target_size=608, interp='CUBIC'),
transforms.Normalize(),
])
# 模型载入
model = pdx.load_model('output/yolov3_mobilenetv1/best_model')
# 结果可视化
for p in os.listdir('example/images'):
img_path = 'example/images/' + p
result = model.predict(img_file=img_path, transforms=eval_transforms)
pdx.det.visualize(image=img_path, result=result, threshold=0.1, save_dir='./visualize')
2. 预测结果可视化
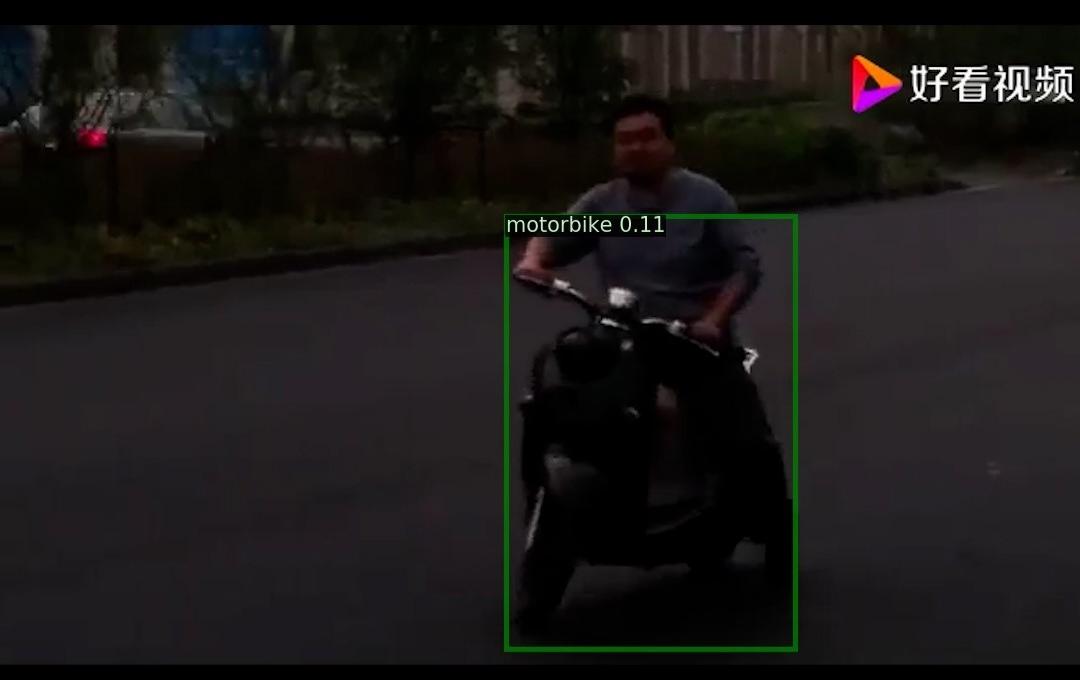
3. 部署模型导出
!paddlex --export_inference --model_dir=output/yolov3_mobilenetv1/best_model --save_dir=inference_model --fixed_input_shape=[608,608]
五、总结与升华
-
- 由于未拿到硬件,部署部分等待更新~
-
- 目前的电瓶车数据较少,需要用
LabelMe标注更多的电瓶车数据。
- 目前的电瓶车数据较少,需要用
-
- 更多详细
paddlex请访问PaddleX。
- 更多详细

















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









