







【团体程序设计天梯赛 往年关键真题 详细分析&完整AC代码】搞懂了赛场上拿下就稳
【团体程序设计天梯赛 往年关键真题 25分题合集 详细分析&完整AC代码】(L2-001 - L2-024)搞懂了赛场上拿下就稳了
【团体程序设计天梯赛 往年关键真题 25分题合集 详细分析&完整AC代码】(L2-025 - L2-048)搞懂了赛场上拿下这些分就稳了
L2-002 链表去重 模拟链表
给定一个带整数键值的链表 L,你需要把其中绝对值重复的键值结点删掉。即对每个键值 K,只有第一个绝对值等于 K 的结点被保留。同时,所有被删除的结点须被保存在另一个链表上。例如给定 L 为 21→-15→-15→-7→15,你需要输出去重后的链表 21→-15→-7,还有被删除的链表 -15→15。
输入格式:
输入在第一行给出 L 的第一个结点的地址和一个正整数 N(≤105,为结点总数)。一个结点的地址是非负的 5 位整数,空地址 NULL 用 −1 来表示。
随后 N 行,每行按以下格式描述一个结点:
地址 键值 下一个结点
其中地址是该结点的地址,键值是绝对值不超过104的整数,下一个结点是下个结点的地址。
输出格式:
首先输出去重后的链表,然后输出被删除的链表。每个结点占一行,按输入的格式输出。
输入样例:
00100 5
99999 -7 87654
23854 -15 00000
87654 15 -1
00000 -15 99999
00100 21 23854
输出样例:
00100 21 23854
23854 -15 99999
99999 -7 -1
00000 -15 87654
87654 15 -1
分析:
数据量不大,可以直接用数组模拟链表,地址当做数组下标,考察基本的删除操作和尾插法。
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
struct node{
int id,val,next,absval;
}LNode[N];
bool cmp(node a,node b){
return a.id<b.id;
}
pair<int,pair<int,int> > p;
vector<pair<int,pair<int,int> > > com,del;
int f[N];
int main(){
int ID,N,i;
cin>>ID>>N;
for(i=0;i<N;i++){
cin>>LNode[i].id>>LNode[i].val>>LNode[i].next;
LNode[i].absval=fabs(LNode[i].val);
f[abs(LNode[i].val)]=0; //避免二分时重复计算
}
sort(LNode,LNode+N,cmp);
while(ID!=-1){ //用-1结束,别用N计数
int l=0,r=N-1; //二分查找下一节点
while(l<r){
int mid=(l+r)/2;
if(LNode[mid].id<ID) l=mid+1;
else r=mid;
}
p.first=LNode[l].id;
p.second.first=LNode[l].val;p.second.second=LNode[l].next;
if(f[LNode[l].absval]==0){
f[LNode[l].absval]=1;
com.push_back(p);
}
else
del.push_back(p);
ID=LNode[l].next;
}
for(i=0;i<com.size();i++){
if(i<com.size()-1)
printf("%05d %d %05d\n",com[i].first,com[i].second.first,com[i+1].first);
else
printf("%05d %d -1\n",com[i].first,com[i].second.first);
}
for(i=0;i<del.size();i++){
if(i<del.size()-1)
printf("%05d %d %05d\n",del[i].first,del[i].second.first,del[i+1].first);
else
printf("%5d %d -1\n",del[i].first,del[i].second.first);
}
return 0;
}
L2-003 月饼 贪心
月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼。现给定所有种类月饼的库存量、总售价、以及市场的最大需求量,请你计算可以获得的最大收益是多少。
注意:销售时允许取出一部分库存。样例给出的情形是这样的:假如我们有 3 种月饼,其库存量分别为 18、15、10 万吨,总售价分别为 75、72、45 亿元。如果市场的最大需求量只有 20 万吨,那么我们最大收益策略应该是卖出全部 15 万吨第 2 种月饼、以及 5 万吨第 3 种月饼,获得 72 + 45/2 = 94.5(亿元)。
输入格式:
每个输入包含一个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N 表示月饼的种类数、以及不超过 500(以万吨为单位)的正整数 D 表示市场最大需求量。随后一行给出 N 个正数表示每种月饼的库存量(以万吨为单位);最后一行给出 N 个正数表示每种月饼的总售价(以亿元为单位)。数字间以空格分隔。
输出格式:
对每组测试用例,在一行中输出最大收益,以亿元为单位并精确到小数点后 2 位。
输入样例:
3 20
18 15 10
75 72 45
输出样例:
94.50
分析:
按照单价排序,优先选择单价最高的。库存量和总售价不一定为整数
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
struct node{
double num,price,dj;
}Mooncake[N];
bool cmp(node a,node b){ return a.dj>b.dj; }
int main(){
int n,m,k=0,i;
cin>>n>>m;
for(i=0;i<n;i++) cin>>Mooncake[i].num;
for(i=0;i<n;i++) cin>>Mooncake[i].price;
for(i=0;i<n;i++) Mooncake[i].dj=Mooncake[i].price/Mooncake[i].num;
sort(Mooncake,Mooncake+n,cmp);
double ans=0;
while(k<n){
if(Mooncake[k].num<=m){
m-=Mooncake[k].num;
ans+=Mooncake[k].price;
}
else{
ans+=Mooncake[k].dj*m;
break;
}
k++;
}
printf("%.2lf\n",ans);
return 0;
}
L2-004 这是二叉搜索树吗? 数据结构
一棵二叉搜索树可被递归地定义为具有下列性质的二叉树:对于任一结点,
- 其左子树中所有结点的键值小于该结点的键值;
- 其右子树中所有结点的键值大于等于该结点的键值;
- 其左右子树都是二叉搜索树。
所谓二叉搜索树的“镜像”,即将所有结点的左右子树对换位置后所得到的树。
给定一个整数键值序列,现请你编写程序,判断这是否是对一棵二叉搜索树或其镜像进行前序遍历的结果。
输入格式:
输入的第一行给出正整数 N(≤1000)。随后一行给出 N 个整数键值,其间以空格分隔。
输出格式:
如果输入序列是对一棵二叉搜索树或其镜像进行前序遍历的结果,则首先在一行中输出 YES ,然后在下一行输出该树后序遍历的结果。数字间有 1 个空格,一行的首尾不得有多余空格。若答案是否,则输出 NO。
输入样例 1:
7
8 6 5 7 10 8 11
输出样例 1:
YES
5 7 6 8 11 10 8
输入样例 2:
7
8 10 11 8 6 7 5
输出样例 2:
YES
11 8 10 7 5 6 8
输入样例 3:
7
8 6 8 5 10 9 11
输出样例 3:
NO
分析:
因为前序遍历是根左右,所以在插入某个孩子节点时,它的父节点肯定已经被插入了,又由于搜索树的限制关系(小的左边,大的右边),所以可以确定一棵唯一的二叉搜索树,然后对其进行两种不同的前序遍历,再分别与题目所给的序列比较即可。
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
struct node{
node *l,*r;
int data;
};
typedef node* Tree;
//s1为正常前序遍历,s2为左右儿子颠倒的前序遍历,s为输入序列
vector<int> s1,s2,s,ans;
int n,cnt,x;
Tree build(Tree root,int x){
if (root == NULL) {
//到达最底部,创建新节点,并赋值
root = new(node);
root->l = root->r = NULL;
root->data = x;
}
//x小于当前节点,说明x在root的左半边,向左递归
else if (x < root->data)
root->l = build(root->l, x);
else
root->r = build(root->r, x);
return root;
}
//正常前序遍历
void pre1(Tree root) {
if (root == NULL) return;
s1.push_back(root->data);
pre1(root->l);
pre1(root->r);
}
//左右颠倒的前序
void pre2(Tree root) {
if (root == NULL) return;
s2.push_back(root->data);
pre2(root->r);
pre2(root->l);
}
//正常后序
void post1(Tree root) {
if (root == NULL) return;
post1(root->l);
post1(root->r);
ans.push_back(root->data);
}
//左右颠倒的后序
void post2(Tree root) {
if (root == NULL) return;
post2(root->r);
post2(root->l);
ans.push_back(root->data);
}
//比较两个序列是否完全相同
bool judge(vector<int> a) {
for (int i = 0; i < a.size(); i++)
if (a[i] != s[i]) return 0;
return 1;
}
int main(){
cin >> n;
for (int i = 0; i < n; i ++)
cin >> x,s.push_back(x);
Tree root=NULL;
for (int i = 0; i < n; i ++)
root = build(root, s[i]);
pre1(root); pre2(root);
if (judge(s1)) {//说明所给序列是二叉搜索树的前序遍历
post1(root);
puts("YES");
for (int i = 0; i < n; i++)
printf("%d%c", ans[i], i == n - 1 ? '\n' : ' ');
}
else if (judge(s2)) {//是镜像的前序遍历
puts("YES");
post2(root);
for (int i = 0; i < n; i++)
printf("%d%c", ans[i], i == n - 1 ? '\n' : ' ');
}
else //不是二叉搜索树
puts("NO");
return 0;
}
L2-005 集合相似度 STL
给定两个整数集合,它们的相似度定义为:Nc/Nt×100%。其中Nc是两个集合都有的不相等整数的个数,Nt是两个集合一共有的不相等整数的个数。你的任务就是计算任意一对给定集合的相似度。
输入格式:
输入第一行给出一个正整数N(≤50),是集合的个数。随后N行,每行对应一个集合。每个集合首先给出一个正整数M(≤104),是集合中元素的个数;然后跟M个[0,109]区间内的整数。
之后一行给出一个正整数K(≤2000),随后K行,每行对应一对需要计算相似度的集合的编号(集合从1到N编号)。数字间以空格分隔。
输出格式:
对每一对需要计算的集合,在一行中输出它们的相似度,为保留小数点后2位的百分比数字。
输入样例:
3
3 99 87 101
4 87 101 5 87
7 99 101 18 5 135 18 99
2
1 2
1 3
输出样例:
50.00%
33.33%
分析:
最多50个集合,预处理出全部的组合,C50 2=49∗25, 用set存放所有的集合,然后预处理的时候遍历两个set中较小的那个,在较大的中查找是否存在,将集合i和集合j共同拥有的数量存在both[i][j]中。Nc就是both[i][j],Nt就是两个集合size加起来再减掉both[i][j]。时间复杂度:25∗49∗10000∗log(10000)=49000000。
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
set<int> s[55];
int main(){
int n; cin>>n;
int i,j,m,x;
for(i=0;i<n;i++){
cin>>m;
for(j=0;j<m;j++){
cin>>x;
s[i].insert(x);
}
}
int q; cin>>q;
for(i=0;i<q;i++){
int x,y;
cin>>x>>y;
x--,y--;
int num1=0,num2=s[x].size()+s[y].size();
for(set<int>::iterator i=s[x].begin();i!=s[x].end();i++){
if(s[y].count(*i)!=0) num1++; //注意指针运算符
// cout<<*i<<endl;
}
printf("%.2lf%\n",num1*100.0/(num2-num1));
}
return 0;
}
L2-006 树的遍历 数据结构
给定一棵二叉树的后序遍历和中序遍历,请你输出其层序遍历的序列。这里假设键值都是互不相等的正整数。
输入格式:
输入第一行给出一个正整数N(≤30),是二叉树中结点的个数。第二行给出其后序遍历序列。第三行给出其中序遍历序列。数字间以空格分隔。
输出格式:
在一行中输出该树的层序遍历的序列。数字间以1个空格分隔,行首尾不得有多余空格。
输入样例:
7
2 3 1 5 7 6 4
1 2 3 4 5 6 7
输出样例:
4 1 6 3 5 7 2
分析:

知道中序+后序或者前序,就能确定一棵唯一的二叉树。所以此题知道后序+中序,可以建立二叉树后层序遍历。由于后序是左右根,所以最后面的节点就是根,然后在中序中找到这个根的位置,左边就是左子树的范围,右边就是右子树的范围,递归处理即可。
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
struct node{
node *lson,*rson;
int val;
};
typedef node* Tree;
vector<int> Mid_order, Post_order;
int n,x,i,now;
Tree build(int l,int r){ //中序和后序建树
if(l>r) return NULL;
Tree root = new(node);
root -> val = Post_order[now];
int mid = l;
while(Post_order[now] != Mid_order[mid])mid++;
now--;
root -> rson = build(mid+1,r);
root -> lson = build(l,mid-1);
return root;
}
void print(Tree root){ //层序遍历输出
queue<Tree> q;
q.push(root);
int tot = 0;
while(!q.empty()){
Tree t = q.front();
if(t->lson != NULL)q.push(t->lson);
if(t->rson != NULL)q.push(t->rson);
printf("%d",t->val);
q.pop();
tot++;
if(tot<n)cout<<' ';
else cout<<endl;
}
}
int main(){
cin>>n;
for(i = 0 ; i < n ; i ++)
cin>>x,Post_order.push_back(x);
for(i = 0 ; i < n ; i ++)
cin>>x,Mid_order.push_back(x);
now = n - 1;
print(build(0,n-1));
return 0;
}
L2-007 家庭房产 并查集
给定每个人的家庭成员和其自己名下的房产,请你统计出每个家庭的人口数、人均房产面积及房产套数。
输入格式:
输入第一行给出一个正整数N(≤1000),随后N行,每行按下列格式给出一个人的房产:
编号 父 母 k 孩子1 ... 孩子k 房产套数 总面积
其中编号是每个人独有的一个4位数的编号;父和母分别是该编号对应的这个人的父母的编号(如果已经过世,则显示-1);k(0≤k≤5)是该人的子女的个数;孩子i是其子女的编号。
输出格式:
首先在第一行输出家庭个数(所有有亲属关系的人都属于同一个家庭)。随后按下列格式输出每个家庭的信息:
家庭成员的最小编号 家庭人口数 人均房产套数 人均房产面积
其中人均值要求保留小数点后3位。家庭信息首先按人均面积降序输出,若有并列,则按成员编号的升序输出。
输入样例:
10
6666 5551 5552 1 7777 1 100
1234 5678 9012 1 0002 2 300
8888 -1 -1 0 1 1000
2468 0001 0004 1 2222 1 500
7777 6666 -1 0 2 300
3721 -1 -1 1 2333 2 150
9012 -1 -1 3 1236 1235 1234 1 100
1235 5678 9012 0 1 50
2222 1236 2468 2 6661 6662 1 300
2333 -1 3721 3 6661 6662 6663 1 100
输出样例:
3
8888 1 1.000 1000.000
0001 15 0.600 100.000
5551 4 0.750 100.000
分析:
用并查集维护集合关系,由于要输出最小编号,合并时将较大的合并给较小的点,由于编号一共最多到9999,记录每个编号是否出现过,然后遍历一遍,将每个编号所拥有的房产等信息贡献给父节点。之后按照题目要求排序输出即可。
坑:编号可能会有0000
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int N = 1e4+10;
struct node{//父节点
//分别表示 编号,人口,房产数量,房产面积
int id, kou, fang, mian;
//分别表示 人均房产套数,人均房产面积
double x1, x2;
const bool operator < (const node &t) const {
if(t.x2 == x2) return id < t.id;
return x2 > t.x2;
}
}p[N];
int n;
int fa[N],vis[N],num[N],s[N];
void init(int n) { for ( int i = 0 ; i < n ; i++ ) fa[i] = i; } //初始化
int find(int x) { return fa[x] == x ? x : fa[x] = find( fa[x] ); } //查找 路径压缩
void merge(int a,int b){ a = find(a), b = find(b); fa[max(a,b)] = min(a,b);} //家族最小值作为祖先
int main(){
cin>>n;
//初始化
init(N);
while(n--){
int id,fid,mid,k,ID;
cin>>id>>fid>>mid>>k;
vis[id]=1;
//活人编号从0开始
if(fid >= 0)merge(id,fid), vis[fid]=1;
if(mid >= 0)merge(id,mid), vis[mid]=1;
while(k--){
int cid; cin>>cid;
vis[cid] = 1;
merge(id,cid);
}
cin>>num[id]>>s[id];
}
//将每个编号所拥有的房产等信息贡献给父节点
for(int i = 0 ; i < N ; i ++) {
if(vis[i]) {
int x = find(i);
p[x].kou ++;
p[x].fang += num[i];
p[x].mian += s[i];
}
}
vector<node> ans;
for(int i = 0; i < N; i++) {
if(vis[i] && find(i) == i) {
p[i].id = i;
p[i].x1 = p[i].fang * 1.0 / p[i].kou;
p[i].x2 = p[i].mian * 1.0 / p[i].kou;
ans.push_back(p[i]);
}
}
sort(ans.begin(), ans.end());
cout << ans.size() << endl;
for(int i = 0; i < ans.size(); i++)
printf("%04d %d %.3lf %.3lf\n",ans[i].id,ans[i].kou,ans[i].x1,ans[i].x2);
return 0;
}
L2-008 最长对称子串 字符串
对给定的字符串,本题要求你输出最长对称子串的长度。例如,给定Is PAT&TAP symmetric?,最长对称子串为s PAT&TAP s,于是你应该输出11。
输入格式:
输入在一行中给出长度不超过1000的非空字符串。
输出格式:
在一行中输出最长对称子串的长度。
输入样例:
Is PAT&TAP symmetric?
输出样例:
11
分析:
回文串问题,manacher模板题
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
string s,s_new;
int p[N*2];
void init(){ //初始化
s_new+='$';
s_new+='#';
for(int i=0;i<s.size();i++){
s_new+=s[i];
s_new+='#';
}
s_new+='\0';
}
void Manacher(){
init();
int mx=0,di,ans=0;
for(int i=0;i<s_new.size();i++){
p[i] = mx > i ? min(p[2 * di - i], mx - i) : 1;
while(s_new[i-p[i]] == s_new[i+p[i]]) p[i]++;
if(i+p[i] > mx)
{
mx = i+p[i];
di = i;
ans = max(ans,p[i]);
}
}
printf("%d\n",ans-1);
}
int main(){
getline(cin,s);
Manacher();
return 0;
}
L2-009 抢红包 排序
没有人没抢过红包吧…… 这里给出N个人之间互相发红包、抢红包的记录,请你统计一下他们抢红包的收获。
输入格式:
输入第一行给出一个正整数N(≤104),即参与发红包和抢红包的总人数,则这些人从1到N编号。随后N行,第i行给出编号为i的人发红包的记录,格式如下:
K**N1P1⋯NKP**K
其中K(0≤K≤20)是发出去的红包个数,N**i是抢到红包的人的编号,P**i(>0)是其抢到的红包金额(以分为单位)。注意:对于同一个人发出的红包,每人最多只能抢1次,不能重复抢。
输出格式:
按照收入金额从高到低的递减顺序输出每个人的编号和收入金额(以元为单位,输出小数点后2位)。每个人的信息占一行,两数字间有1个空格。如果收入金额有并列,则按抢到红包的个数递减输出;如果还有并列,则按个人编号递增输出。
输入样例:
10
3 2 22 10 58 8 125
5 1 345 3 211 5 233 7 13 8 101
1 7 8800
2 1 1000 2 1000
2 4 250 10 320
6 5 11 9 22 8 33 7 44 10 55 4 2
1 3 8800
2 1 23 2 123
1 8 250
4 2 121 4 516 7 112 9 10
输出样例:
1 11.63
2 3.63
8 3.63
3 2.11
7 1.69
6 -1.67
9 -2.18
10 -3.26
5 -3.26
4 -12.32
分析:
就是细节题,题目让你干什么就干什么。结构体中自定义排序规则
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
struct node{
int id,money,num;
const bool operator < (const node &t) const {
if(t.money == money)
return id > t.id;
return money > t.money;
}
}peo[N];
int main(){
int n; cin>>n;
for(int i = 1 ; i <= n ; i ++) peo[i].id = i;
for(int i = 1 ; i <= n ; i ++){
int k,sum=0; cin>>k;
for(int j = 0 ; j < k ; j++){
int x,m; cin>>x>>m;
peo[x].money += m;
sum += m;
peo[x].num ++;
}
peo[i].money -= sum;
}
sort(peo+1, peo+1+n);
for(int i = 1 ; i <= n ; i ++)
printf("%d %.2lf\n", peo[i].id, peo[i].money*1.0/100);
return 0;
}
L2-010 排座位 dfs
布置宴席最微妙的事情,就是给前来参宴的各位宾客安排座位。无论如何,总不能把两个死对头排到同一张宴会桌旁!这个艰巨任务现在就交给你,对任何一对客人,请编写程序告诉主人他们是否能被安排同席。
输入格式:
输入第一行给出3个正整数:N(≤100),即前来参宴的宾客总人数,则这些人从1到N编号;M为已知两两宾客之间的关系数;K为查询的条数。随后M行,每行给出一对宾客之间的关系,格式为:宾客1 宾客2 关系,其中关系为1表示是朋友,-1表示是死对头。注意两个人不可能既是朋友又是敌人。最后K行,每行给出一对需要查询的宾客编号。
这里假设朋友的朋友也是朋友。但敌人的敌人并不一定就是朋友,朋友的敌人也不一定是敌人。只有单纯直接的敌对关系才是绝对不能同席的。
输出格式:
对每个查询输出一行结果:如果两位宾客之间是朋友,且没有敌对关系,则输出No problem;如果他们之间并不是朋友,但也不敌对,则输出OK;如果他们之间有敌对,然而也有共同的朋友,则输出OK but...;如果他们之间只有敌对关系,则输出No way。
输入样例:
7 8 4
5 6 1
2 7 -1
1 3 1
3 4 1
6 7 -1
1 2 1
1 4 1
2 3 -1
3 4
5 7
2 3
7 2
输出样例:
No problem
OK
OK but...
No way
分析:
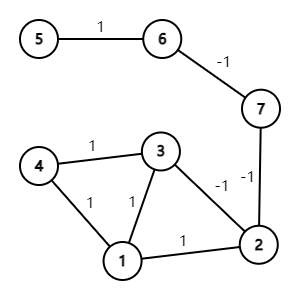
N≤100,说明可以直接建图后进行dfs遍历,只遍历边权为1的点,如果可以从a走到b,说明有共同朋友,再判断mp[a][b]是否为-1即可。其他情况类似。
代码:
#include <bits/stdc++.h>
using namespace std;
int n, m, k, a, b, c;
int mp[111][111],vis[111];
bool dfs(int now,int end) {
if(now==end) return true;
for(int i=1;i<=n;i++){
if(mp[now][i]==1&&vis[i]==0){
vis[now]=1;
if(dfs(i,end)) return true;
vis[now]=0;
}
}
return false;
}
int main() {
cin>>n>>m>>k;
for (int i=0;i<m;i++) {
cin>>a>>b>>c;
mp[a][b]=mp[b][a]=c;
}
while (k--) {
cin>>a>>b;
for(int i=1;i<=n;i++) vis[i]=0;
vis[a]=1;
bool flag=dfs(a,b);
if(flag && mp[a][b]!=-1) cout<<"No problem"<<endl;
if(flag && mp[a][b]==-1) cout<<"OK but..."<<endl;
if(!flag && mp[a][b]!=-1) cout<<"OK"<<endl;
if(!flag && mp[a][b]==-1) cout<<"No way"<<endl;
}
return 0;
}
L2-011 玩转二叉树 数据结构
给定一棵二叉树的中序遍历和前序遍历,请你先将树做个镜面反转,再输出反转后的层序遍历的序列。所谓镜面反转,是指将所有非叶结点的左右孩子对换。这里假设键值都是互不相等的正整数。
输入格式:
输入第一行给出一个正整数N(≤30),是二叉树中结点的个数。第二行给出其中序遍历序列。第三行给出其前序遍历序列。数字间以空格分隔。
输出格式:
在一行中输出该树反转后的层序遍历的序列。数字间以1个空格分隔,行首尾不得有多余空格。
输入样例:
7
1 2 3 4 5 6 7
4 1 3 2 6 5 7
输出样例:
4 6 1 7 5 3 2
分析:
就是两种遍历方式求另外一种,PTA好喜欢这种题,镜面翻转其实就是在求层序的时候反着放入队列就行。
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
struct node{
node *l,*r;
int data;
};
typedef node* Tree;
int i,n,x,now=0;
vector<int> pre_order,mid_order;
Tree build(int l,int r){ //前序和中序建树
if(l>r) return NULL;
Tree root=new(node);
root->data=pre_order[now];
int mid=l;
while(pre_order[now] != mid_order[mid]) mid++;
now++;
root->l = build(l, mid - 1);
root->r = build(mid + 1, r);
return root;
}
void printf(Tree root){ //层序输出
queue<Tree> q;
q.push(root);
int tot=0;
while(q.size()){
Tree t=q.front();
tot++;
printf("%d%c",t->data,tot==n ? '\n' : ' ');
q.pop();
if(t->r!=NULL) q.push(t->r);
if(t->l!=NULL) q.push(t->l);
}
}
int main(){
cin>>n;
for(i=1;i<=n;i++)
cin>>x,mid_order.push_back(x);
for(i=1;i<=n;i++)
cin>>x,pre_order.push_back(x);
printf(build(0,n-1));
return 0;
}
L2-013 红色警报 并查集
战争中保持各个城市间的连通性非常重要。本题要求你编写一个报警程序,当失去一个城市导致国家被分裂为多个无法连通的区域时,就发出红色警报。注意:若该国本来就不完全连通,是分裂的k个区域,而失去一个城市并不改变其他城市之间的连通性,则不要发出警报。
输入格式:
输入在第一行给出两个整数N(0 < N ≤ 500)和M(≤ 5000),分别为城市个数(于是默认城市从0到N-1编号)和连接两城市的通路条数。随后M行,每行给出一条通路所连接的两个城市的编号,其间以1个空格分隔。在城市信息之后给出被攻占的信息,即一个正整数K和随后的K个被攻占的城市的编号。
注意:输入保证给出的被攻占的城市编号都是合法的且无重复,但并不保证给出的通路没有重复。
输出格式:
对每个被攻占的城市,如果它会改变整个国家的连通性,则输出Red Alert: City k is lost!,其中k是该城市的编号;否则只输出City k is lost.即可。如果该国失去了最后一个城市,则增加一行输出Game Over.。
输入样例:
5 4
0 1
1 3
3 0
0 4
5
1 2 0 4 3
输出样例:
City 1 is lost.
City 2 is lost.
Red Alert: City 0 is lost!
City 4 is lost.
City 3 is lost.
Game Over.
分析:
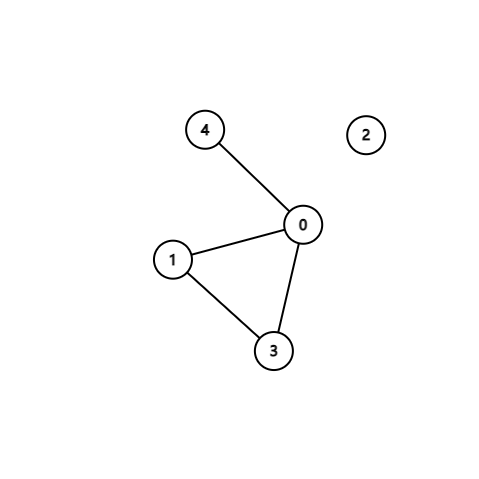
每次删去一个点,可以用一个数组记录标记被删去的点,每删去一个点,对所有不包含被删去点的边求一次并查集,检查有几个集合,如果比之前多则说明有国家被分裂了,注意已经被消灭的城市不会算入一个集合。
代码:
#include<bits/stdc++.h>
using namespace std;
typedef pair<int,int> PII;
const int N=505;
int n,m,k,x,y;
int fa[N],vis[N];
vector<PII> v;
void init(int n) { for ( int i = 0 ; i < n ; i++ ) fa[i] = i; } //初始化
int find(int x) { return fa[x] == x ? x : fa[x] = find( fa[x] ); } //查找 路径压缩
void merge(int a, int b) { a = find(a), b = find(b), fa[b] = a; } //合并
int fun(int x){
init(n);
vis[x]=0; //x城市被攻占
for(int i=0;i<v.size();i++)
if(vis[v[i].first]+vis[v[i].second]==2)
merge(v[i].first,v[i].second);
int res=0;
for(int i=0;i<n;i++)
if(vis[i]==1&&fa[i]==i)
res++;
return res;
}
int main(){
cin>>n>>m;
for(int i=1;i<=m;i++){
cin>>x>>y;
v.push_back({x,y});
}
cin>>k;
for(int i=0;i<n;i++) vis[i]=1;
int num=fun(n);
while(k--){
cin>>x;
int t=fun(x);
if(t>num) printf("Red Alert: City %d is lost!\n",x);
else printf("City %d is lost.\n",x);
if(t==0) printf("Game Over.\n");
num=t;
}
}
L2-014 列车调度 STL
火车站的列车调度铁轨的结构如下图所示。

两端分别是一条入口(Entrance)轨道和一条出口(Exit)轨道,它们之间有N条平行的轨道。每趟列车从入口可以选择任意一条轨道进入,最后从出口离开。在图中有9趟列车,在入口处按照{8,4,2,5,3,9,1,6,7}的顺序排队等待进入。如果要求它们必须按序号递减的顺序从出口离开,则至少需要多少条平行铁轨用于调度?
输入格式:
输入第一行给出一个整数N (2 ≤ N ≤105),下一行给出从1到N的整数序号的一个重排列。数字间以空格分隔。
输出格式:
在一行中输出可以将输入的列车按序号递减的顺序调离所需要的最少的铁轨条数。
输入样例:
9
8 4 2 5 3 9 1 6 7
输出样例:
4
分析:
可以这样调度:先查看当前所有轨道的最左边火车编号是否小于当前编号,插入到最小的比当前火车编号大的火车后,如果不存在则开辟新轨道。可知,轨道的最左端火车编号一定是随轨道下标而递增的,可以用二分查找快速找到那条轨道。当然,可以用set更为方便。
代码:
#include<iostream>
#include<set>
using namespace std;
int main()
{
int n; scanf("%d",&n);
set<int>sc;
for(int i=0;i<n;i++){
int k; scanf("%d",&k);
set<int>::iterator it=sc.lower_bound(k);
if(it!=sc.end()){
sc.erase(it);
sc.insert(k);
}
else
sc.insert(k);
}
cout<<sc.size();
}
L2-015 互评成绩 排序
学生互评作业的简单规则是这样定的:每个人的作业会被k个同学评审,得到k个成绩。系统需要去掉一个最高分和一个最低分,将剩下的分数取平均,就得到这个学生的最后成绩。本题就要求你编写这个互评系统的算分模块。
输入格式:
输入第一行给出3个正整数N(3 < N ≤104,学生总数)、k(3 ≤ k ≤ 10,每份作业的评审数)、M(≤ 20,需要输出的学生数)。随后N行,每行给出一份作业得到的k个评审成绩(在区间[0, 100]内),其间以空格分隔。
输出格式:
按非递减顺序输出最后得分最高的M个成绩,保留小数点后3位。分数间有1个空格,行首尾不得有多余空格。
输入样例:
6 5 3
88 90 85 99 60
67 60 80 76 70
90 93 96 99 99
78 65 77 70 72
88 88 88 88 88
55 55 55 55 55
输出样例:
87.667 88.000 96.000
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
int n,k,m,i,j,x;
vector<int> vi;
vector<double> vd;
int main(){
cin>>n>>k>>m;
for(i = 1 ; i <= n ; i++){
vi.clear();
for(j = 0 ; j < k ; j ++)
cin>>x,vi.push_back(x);
sort(vi.begin(), vi.end());
vi.erase(vi.begin());
vi.erase(vi.end()-1);
int sum = 0;
for(j = 0 ; j < vi.size() ; j++)
sum += vi[j];
vd.push_back(sum*1.0/(k-2));
}
sort(vd.begin(), vd.end());
for(i = vd.size() - m ; i < vd.size() ; i++)
printf("%.3lf%c",vd[i],i==vd.size()-1?'\n':' ');
return 0;
}
L2-016 愿天下有情人都是失散多年的兄妹 dfs
呵呵。大家都知道五服以内不得通婚,即两个人最近的共同祖先如果在五代以内(即本人、父母、祖父母、曾祖父母、高祖父母)则不可通婚。本题就请你帮助一对有情人判断一下,他们究竟是否可以成婚?
输入格式:
输入第一行给出一个正整数()N(2≤N≤104),随后N行,每行按以下格式给出一个人的信息:
本人ID 性别 父亲ID 母亲ID
其中ID是5位数字,每人不同;性别M代表男性、F代表女性。如果某人的父亲或母亲已经不可考,则相应的ID位置上标记为-1。
接下来给出一个正整数K,随后K行,每行给出一对有情人的ID,其间以空格分隔。
注意:题目保证两个人是同辈,每人只有一个性别,并且血缘关系网中没有乱伦或隔辈成婚的情况。
输出格式:
对每一对有情人,判断他们的关系是否可以通婚:如果两人是同性,输出Never Mind;如果是异性并且关系出了五服,输出Yes;如果异性关系未出五服,输出No。
输入样例:
24
00001 M 01111 -1
00002 F 02222 03333
00003 M 02222 03333
00004 F 04444 03333
00005 M 04444 05555
00006 F 04444 05555
00007 F 06666 07777
00008 M 06666 07777
00009 M 00001 00002
00010 M 00003 00006
00011 F 00005 00007
00012 F 00008 08888
00013 F 00009 00011
00014 M 00010 09999
00015 M 00010 09999
00016 M 10000 00012
00017 F -1 00012
00018 F 11000 00013
00019 F 11100 00018
00020 F 00015 11110
00021 M 11100 00020
00022 M 00016 -1
00023 M 10012 00017
00024 M 00022 10013
9
00021 00024
00019 00024
00011 00012
00022 00018
00001 00004
00013 00016
00017 00015
00019 00021
00010 00011
输出样例:
Never Mind
Yes
Never Mind
No
Yes
No
Yes
No
No
分析
先跑一遍dfs标记第一个人的所有五代内的长辈,然后再dfs一遍第二个人的所有五代内的长辈,检查是否有重复。有个坑点就是:父母的性别都是已知的,但是可能不会告诉你父母的祖辈情况,所以要同时记录父母的性别,否则父母性别默认初始值都是相同的了。还有个我自己的问题,直接在结构体内赋值的方式进行初始化,这样是不可行的,正确方法是要么循环遍历初始化,要么写一个构造函数。
代码
#include <bits/stdc++.h>
#define LL long long
using namespace std;
const int maxn = 1e5+10;
const int inf = 0x3f3f3f3f;
const double PI = acos(-1.0);
typedef pair<int,int> PII;
struct node
{
int fa, ma, sex , flag;
node() {
flag = 0;fa = ma = -1;
}
}peo[maxn];
int f;
int vis[maxn];
void dfs(int x, int ceng) {
if(x == -1 || ceng > 5) return;
vis[x] = 1;
if (peo[x].flag == 0) return;
dfs(peo[x].ma, ceng + 1);
dfs(peo[x].fa,ceng+1);
}
void dfs2(int x, int ceng) {
if(x == -1 || ceng > 5 || f == 1) return;
if(vis[x] == 1) {
f = 1;return;
}
if (peo[x].flag == 0) return;
dfs2(peo[x].ma,ceng+1);
dfs2(peo[x].fa,ceng+1);
}
int main(int argc, char const *argv[]) {
int n;
cin >> n;
for(int i = 1; i <= n; i++) {
string s;
int id;
cin >> id >> s;
cin >> peo[id].fa >> peo[id].ma;
peo[id].flag = 1;
if(s[0] == 'M') peo[id].sex = 1;
else peo[id].sex = 0;
if(peo[id].fa != -1)
peo[peo[id].fa].sex = 1;
if(peo[id].ma != -1)
peo[peo[id].ma].sex = 0;
}
int k;
cin >> k;
while(k--) {
memset(vis, 0 ,sizeof vis);
int x, y;
cin >> x >> y;
if(peo[x].sex == peo[y].sex) puts("Never Mind");
else {
f = 0;
dfs(x,1);
dfs2(y,1);
if(f==0) puts("Yes");
else puts("No");
}
}
return 0;
}
L2-017 人以群分 水题
社交网络中我们给每个人定义了一个“活跃度”,现希望根据这个指标把人群分为两大类,即外向型(outgoing,即活跃度高的)和内向型(introverted,即活跃度低的)。要求两类人群的规模尽可能接近,而他们的总活跃度差距尽可能拉开。
输入格式:
输入第一行给出一个正整数N(2≤N≤105)。随后一行给出N个正整数,分别是每个人的活跃度,其间以空格分隔。题目保证这些数字以及它们的和都不会超过231。
输出格式:
按下列格式输出:
Outgoing #: N1
Introverted #: N2
Diff = N3
其中N1是外向型人的个数;N2是内向型人的个数;N3是两群人总活跃度之差的绝对值。
输入样例1:
10
23 8 10 99 46 2333 46 1 666 555
输出样例1:
Outgoing #: 5
Introverted #: 5
Diff = 3611
输入样例2:
13
110 79 218 69 3721 100 29 135 2 6 13 5188 85
输出样例2:
Outgoing #: 7
Introverted #: 6
Diff = 9359
分析:
要先保证人数平均再保证差值尽量大,那么就排序后平均分成两份的差值会最大,如果人数为奇数,中间值分给外向的人群可以使得差值最大。
代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
typedef long long ll;
vector<int> v;
int n,x,i,sum1,sum2;
int main(){
cin>>n;
sum1=sum2=0;
while(n--){
cin>>x;
v.push_back(x);
}
sort(v.begin(),v.end());
for(i = 0 ; i < v.size()/2 ; i ++ ) sum1 += v[i];
for(i = v.size()/2 ; i < v.size() ; i ++) sum2 += v[i];
printf("Outgoing #: %d\n",v.size()-v.size()/2);
printf("Introverted #: %d\n",v.size()/2);
printf("Diff = %d\n",sum2-sum1);
return 0;
}
L2-018 多项式A除以B 模拟
这仍然是一道关于A/B的题,只不过A和B都换成了多项式。你需要计算两个多项式相除的商Q和余R,其中R的阶数必须小于B的阶数。
输入格式:
输入分两行,每行给出一个非零多项式,先给出A,再给出B。每行的格式如下:
N e[1] c[1] ... e[N] c[N]
其中N是该多项式非零项的个数,e[i]是第i个非零项的指数,c[i]是第i个非零项的系数。各项按照指数递减的顺序给出,保证所有指数是各不相同的非负整数,所有系数是非零整数,所有整数在整型范围内。
输出格式:
分两行先后输出商和余,输出格式与输入格式相同,输出的系数保留小数点后1位。同行数字间以1个空格分隔,行首尾不得有多余空格。注意:零多项式是一个特殊多项式,对应输出为0 0 0.0。但非零多项式不能输出零系数(包括舍入后为0.0)的项。在样例中,余多项式其实有常数项-1/27,但因其舍入后为0.0,故不输出。
输入样例:
4 4 1 2 -3 1 -1 0 -1
3 2 3 1 -2 0 1
输出样例:
3 2 0.3 1 0.2 0 -1.0
1 1 -3.1
分析:
模拟手算多项式除法即可,注意细节
代码:
#include<bits/stdc++.h>
using namespace std;
const int maxn=3e3+10;
double c1[maxn],c2[maxn],c3[maxn];
int nonNegativeNum(double c[],int st)//统计非负项个数
{
int cnt=0;
for(int i=st;i>=0;--i)
if(abs(c[i])+0.05>=0.1)cnt++;
return cnt;
}
void printPoly(double c[],int st)
{
printf("%d",nonNegativeNum(c,st));
if(nonNegativeNum(c,st)==0)printf(" 0 0.0");
for(int i=st;i>=0;--i)
if(abs(c[i])+0.05>=0.1)printf(" %d %.1lf",i,c[i]);
}
int main()
{
int max1=-1,max2=-1;
int m;scanf("%d",&m);
for(int i=0;i<m;++i){
int t;scanf("%d",&t);
max1=max(max1,t);
scanf("%lf",&c1[t]);
}
int n;scanf("%d",&n);
for(int i=0;i<n;++i){
int t;scanf("%d",&t);
max2=max(max2,t);
scanf("%lf",&c2[t]);
}
int t1=max1,t2=max2;
while(t1>=t2){
double x=c1[t1]/c2[t2];//最高次幂的商的系数
c3[t1-t2]=x;
for(int i=t1,j=t2;j>=0;--j,--i)
c1[i]-=c2[j]*x;
while(abs(c1[t1])<1e-6)t1--;//如果该项是0,那么最高次幂降1;
}
printPoly(c3,max1-max2);
puts("");
printPoly(c1,t1);
return 0;
}
L2-019 悄悄关注 STL
新浪微博上有个“悄悄关注”,一个用户悄悄关注的人,不出现在这个用户的关注列表上,但系统会推送其悄悄关注的人发表的微博给该用户。现在我们来做一回网络侦探,根据某人的关注列表和其对其他用户的点赞情况,扒出有可能被其悄悄关注的人。
输入格式:
输入首先在第一行给出某用户的关注列表,格式如下:
人数N 用户1 用户2 …… 用户N
其中N是不超过5000的正整数,每个用户i(i=1, …, N)是被其关注的用户的ID,是长度为4位的由数字和英文字母组成的字符串,各项间以空格分隔。
之后给出该用户点赞的信息:首先给出一个不超过10000的正整数M,随后M行,每行给出一个被其点赞的用户ID和对该用户的点赞次数(不超过1000),以空格分隔。注意:用户ID是一个用户的唯一身份标识。题目保证在关注列表中没有重复用户,在点赞信息中也没有重复用户。
输出格式:
我们认为被该用户点赞次数大于其点赞平均数、且不在其关注列表上的人,很可能是其悄悄关注的人。根据这个假设,请你按用户ID字母序的升序输出可能是其悄悄关注的人,每行1个ID。如果其实并没有这样的人,则输出“Bing Mei You”。
输入样例1:
10 GAO3 Magi Zha1 Sen1 Quan FaMK LSum Eins FatM LLao
8
Magi 50
Pota 30
LLao 3
Ammy 48
Dave 15
GAO3 31
Zoro 1
Cath 60
输出样例1:
Ammy
Cath
Pota
输入样例2:
11 GAO3 Magi Zha1 Sen1 Quan FaMK LSum Eins FatM LLao Pota
7
Magi 50
Pota 30
LLao 48
Ammy 3
Dave 15
GAO3 31
Zoro 29
输出样例2:
Bing Mei You
分析:
map记录一下哪些名字出现过,再用一个map记录点赞情况并求出平均值,遍历记录点赞记录的map,将满足条件的名字放入vector,排序输出。
代码:
#include <bits/stdc++.h>
#define LL long long
using namespace std;
const int maxn = 1e5+10;
const int inf = 0x3f3f3f3f;
const double PI = acos(-1.0);
typedef pair<int,int> PII;
map<string,int> zan;
map<string,int> guan;
int main(int argc, char const *argv[]) {
int n;
cin >> n;
string s;
for(int i = 0; i < n; i++) {
cin >> s;
guan[s] = 1;
}
int m, x;
cin >> m;
double sum = 0;
for(int i = 0 ; i < m; i++){
cin >> s >> x;
sum += x;
zan[s] = x;
}
sum = sum*1.0/m;
vector<string> ans;
for(auto it : zan) {
if(guan[it.first] == 0 && sum < it.second) ans.push_back(it.first);
}
if(ans.size() == 0) puts("Bing Mei You");
else {
sort(ans.begin(), ans.end());
for (int i = 0; i < ans.size(); i++) cout << ans[i] << endl;
}
return 0;
}
L2-020 功夫传人 dfs
一门武功能否传承久远并被发扬光大,是要看缘分的。一般来说,师傅传授给徒弟的武功总要打个折扣,于是越往后传,弟子们的功夫就越弱…… 直到某一支的某一代突然出现一个天分特别高的弟子(或者是吃到了灵丹、挖到了特别的秘笈),会将功夫的威力一下子放大N倍 —— 我们称这种弟子为“得道者”。
这里我们来考察某一位祖师爷门下的徒子徒孙家谱:假设家谱中的每个人只有1位师傅(除了祖师爷没有师傅);每位师傅可以带很多徒弟;并且假设辈分严格有序,即祖师爷这门武功的每个第i代传人只能在第i-1代传人中拜1个师傅。我们假设已知祖师爷的功力值为Z,每向下传承一代,就会减弱r%,除非某一代弟子得道。现给出师门谱系关系,要求你算出所有得道者的功力总值。
输入格式:
输入在第一行给出3个正整数,分别是:N(≤105)——整个师门的总人数(于是每个人从0到N−1编号,祖师爷的编号为0);Z——祖师爷的功力值(不一定是整数,但起码是正数);r ——每传一代功夫所打的折扣百分比值(不超过100的正数)。接下来有N行,第i行(i=0,⋯,N−1)描述编号为i的人所传的徒弟,格式为:
K**i ID[1] ID[2] ⋯ ID[K**i]
其中K**i是徒弟的个数,后面跟的是各位徒弟的编号,数字间以空格间隔。K**i为零表示这是一位得道者,这时后面跟的一个数字表示其武功被放大的倍数。
输出格式:
在一行中输出所有得道者的功力总值,只保留其整数部分。题目保证输入和正确的输出都不超过1010。
输入样例:
10 18.0 1.00
3 2 3 5
1 9
1 4
1 7
0 7
2 6 1
1 8
0 9
0 4
0 3
输出样例:
404
分析:
由于每个徒弟严格只会跟一个高一辈的师傅,直接保存每个人的徒弟,然后dfs一遍就行,标记一下超级徒弟dfs的时候判断一下就行,超级徒弟就是叶子节点。
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e5+10;
int n;
int vis[N];
double z,r,sum;
vector<int> v[N];
void dfs(int x,double power){
if(vis[x]){
sum+=power*v[x][0];
return ;
}
for(int i=0;i<v[x].size();i++)
dfs(v[x][i],power*r);
}
int main(){
cin>>n>>z>>r;
r=(100.0-r)/100.0;
for(int i=0;i<n;i++){
int k,x; cin>>k;
if(k==0) {
cin>>x;
vis[i]=1;
v[i].push_back(x);
}
while(k--){
cin>>x;
v[i].push_back(x);
}
}
dfs(0,z);
cout<<(int)sum<<endl;
return 0;
}
L2-021 点赞狂魔 排序
微博上有个“点赞”功能,你可以为你喜欢的博文点个赞表示支持。每篇博文都有一些刻画其特性的标签,而你点赞的博文的类型,也间接刻画了你的特性。然而有这么一种人,他们会通过给自己看到的一切内容点赞来狂刷存在感,这种人就被称为“点赞狂魔”。他们点赞的标签非常分散,无法体现出明显的特性。本题就要求你写个程序,通过统计每个人点赞的不同标签的数量,找出前3名点赞狂魔。
输入格式:
输入在第一行给出一个正整数N(≤100),是待统计的用户数。随后N行,每行列出一位用户的点赞标签。格式为“Name K F1⋯FK”,其中Name是不超过8个英文小写字母的非空用户名,1≤K≤1000,Fi(i=1,⋯,K)是特性标签的编号,我们将所有特性标签从 1 到 107 编号。数字间以空格分隔。
输出格式:
统计每个人点赞的不同标签的数量,找出数量最大的前3名,在一行中顺序输出他们的用户名,其间以1个空格分隔,且行末不得有多余空格。如果有并列,则输出标签出现次数平均值最小的那个,题目保证这样的用户没有并列。若不足3人,则用-补齐缺失,例如mike jenny -就表示只有2人。
输入样例:
5
bob 11 101 102 103 104 105 106 107 108 108 107 107
peter 8 1 2 3 4 3 2 5 1
chris 12 1 2 3 4 5 6 7 8 9 1 2 3
john 10 8 7 6 5 4 3 2 1 7 5
jack 9 6 7 8 9 10 11 12 13 14
输出样例:
jack chris john
分析:
简单的结构体排序,利用结构体存数据,排序后输出前3位即可
坑:标签出现次数平均值就是k
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e3+10;
struct node{ //存 名字 不同标签的数量 标签出现次数平均值
char name[10];
int num,k;
const bool operator < (const node &t) const {
if(t.num==num) return t.k>k;
return t.num<num;
}
}peo[N];
int main(){
int n; scanf("%d",&n);
for (int i = 0 ; i < n ; i++ ) {
scanf("%s",peo[i].name);
int k; scanf("%d",&k);
peo[i].k = k;
set<int> s;
while ( k-- ){
int x; scanf("%d",&x);
s.insert(x);
}
peo[i].num = s.size();
}
sort(peo,peo+n);
if(n>0) printf("%s ", peo[0].name);
else printf("- ");
if(n>1) printf("%s ", peo[1].name);
else printf("- ");
if(n>2) printf("%s\n", peo[2].name);
else printf("-\n");
return 0;
}
L2-022 重排链表 模拟链表
给定一个单链表 L1→L2→⋯→Ln−1→Ln,请编写程序将链表重新排列为 Ln→L1→Ln−1→L2→⋯。例如:给定L为1→2→3→4→5→6,则输出应该为6→1→5→2→4→3。
输入格式:
每个输入包含1个测试用例。每个测试用例第1行给出第1个结点的地址和结点总个数,即正整数N (≤105)。结点的地址是5位非负整数,NULL地址用−1表示。
接下来有N行,每行格式为:
Address Data Next
其中Address是结点地址;Data是该结点保存的数据,为不超过105的正整数;Next是下一结点的地址。题目保证给出的链表上至少有两个结点。
输出格式:
对每个测试用例,顺序输出重排后的结果链表,其上每个结点占一行,格式与输入相同。
输入样例:
00100 6
00000 4 99999
00100 1 12309
68237 6 -1
33218 3 00000
99999 5 68237
12309 2 33218
输出样例:
68237 6 00100
00100 1 99999
99999 5 12309
12309 2 00000
00000 4 33218
33218 3 -1
分析:
用数组模拟链表,用一个指针即可实现重排输出。
坑:输入数据中可能不止一个点的下一地址为-1;
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e6+10;
struct node{ //存每个点的 地址 值 下一点地址
int add, data, next;
}Lnode[N];
int main(){
int add_s,n; scanf("%d %d", &add_s, &n);
int sum=1;
for( int i = 0 ; i < n ; i++ ){
int a,b,c;
scanf("%d %d %d", &a, &b, &c);
Lnode[a].add=a;
Lnode[a].data=b;
Lnode[a].next=c;
}
vector<node> Array; //存链表上的所有点
do{
Array.push_back(Lnode[add_s]);
add_s = Lnode[add_s].next;
}while(add_s!=-1);
int index = 0, length = Array.size() - 1;
printf("%05d %d ", Array[length].add, Array[length].data);
for ( int i = 0 ; i < length ; i++ ){
int pos; //pos指向当前要输出的点
if( i%2 == 0 ){
pos = index;
index ++;
}
else
pos = length-index;
printf("%05d\n", Array[pos].add);
printf("%05d %d ", Array[pos].add, Array[pos].data);
}
printf("-1\n");
return 0;
}
L2-023 图着色问题 简单图
图着色问题是一个著名的NP完全问题。给定无向图G=(V,E),问可否用K种颜色为V中的每一个顶点分配一种颜色,使得不会有两个相邻顶点具有同一种颜色?
但本题并不是要你解决这个着色问题,而是对给定的一种颜色分配,请你判断这是否是图着色问题的一个解。
输入格式:
输入在第一行给出3个整数V(0<V≤500)、E(≥0)和K(0<K≤V),分别是无向图的顶点数、边数、以及颜色数。顶点和颜色都从1到V编号。随后E行,每行给出一条边的两个端点的编号。在图的信息给出之后,给出了一个正整数N(≤20),是待检查的颜色分配方案的个数。随后N行,每行顺次给出V个顶点的颜色(第i个数字表示第i个顶点的颜色),数字间以空格分隔。题目保证给定的无向图是合法的(即不存在自回路和重边)。
输出格式:
对每种颜色分配方案,如果是图着色问题的一个解则输出Yes,否则输出No,每句占一行。
输入样例:
6 8 3
2 1
1 3
4 6
2 5
2 4
5 4
5 6
3 6
4
1 2 3 3 1 2
4 5 6 6 4 5
1 2 3 4 5 6
2 3 4 2 3 4
输出样例:
Yes
Yes
No
No
分析:
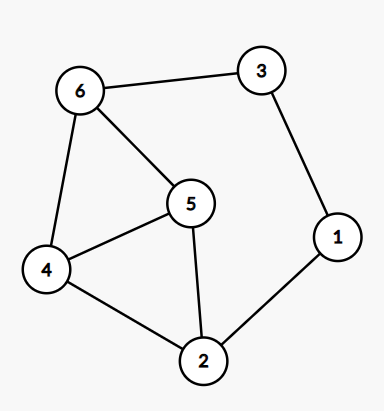
简单题,存好边和点的颜色后,遍历所有边即可,用邻接表存更优。
坑:实际用的颜色和初始给出的颜色数目要一样
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e3+10;
vector<PII> vec; //邻接表存边
int col[N]; //存每个点的颜射
int main(){
int v,e,k;
scanf("%d%d%d", &v, &e, &k);
for ( int i = 0 ; i < e ; i++ ){
int x, y; scanf("%d%d", &x, &y);
vec.push_back({x,y});
}
int q; scanf("%d", &q);
while ( q-- ){
set<int> s; //记录出现过的颜色
for ( int i = 1 ; i <= v ; i++ ){
scanf("%d", &col[i]);
s.insert(col[i]);
}
int flag = ( s.size() == k ); //统计用过的颜料
for ( int i = 0 ; i < vec.size() ; i++ )
if(col[vec[i].first] == col[vec[i].second])
flag = false;
if ( flag ) cout<<"Yes\n";
else cout<<"No\n";
}
return 0;
}
L2-024 部落 并查集
在一个社区里,每个人都有自己的小圈子,还可能同时属于很多不同的朋友圈。我们认为朋友的朋友都算在一个部落里,于是要请你统计一下,在一个给定社区中,到底有多少个互不相交的部落?并且检查任意两个人是否属于同一个部落。
输入格式:
输入在第一行给出一个正整数N(≤104),是已知小圈子的个数。随后N行,每行按下列格式给出一个小圈子里的人:
K P[1] P[2] ⋯ P[K]
其中K是小圈子里的人数,P[i](i=1,⋯,K)是小圈子里每个人的编号。这里所有人的编号从1开始连续编号,最大编号不会超过104。
之后一行给出一个非负整数Q(≤104),是查询次数。随后Q行,每行给出一对被查询的人的编号。
输出格式:
首先在一行中输出这个社区的总人数、以及互不相交的部落的个数。随后对每一次查询,如果他们属于同一个部落,则在一行中输出Y,否则输出N。
输入样例:
4
3 10 1 2
2 3 4
4 1 5 7 8
3 9 6 4
2
10 5
3 7
输出样例:
10 2
Y
N
分析:
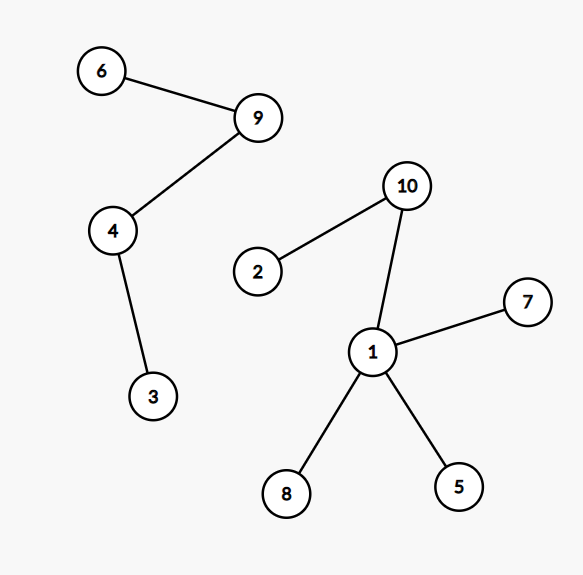
并查集简单题,将同一个部落的人合并和统计部落数,按要求查找并比较他们的祖先
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e4+10;
int fa[N];
void init(int n) { for ( int i = 1 ; i <= n ; i++ ) fa[i] = i; } //初始化
int find(int x) { return fa[x] == x ? x : fa[x] = find( fa[x] ); } //查找 路径压缩
void merge(int a, int b) { a = find(a), b = find(b), fa[b] = a; } //合并
int main(){
int n; scanf("%d", &n);
int m=0; //记录编号最大的人 即 总人数
init(N);
while ( n-- ) {
int k, x, y ; scanf("%d%d", &k, &x);
m = max(m, x);
for ( int i = 1 ; i < k ; i++ ) {
scanf("%d", &y);
merge(x, y); //合并
m = max(m, y);
}
}
int ans = 0; //计算部落数
for ( int i = 1 ; i <= m ; i++ )
if ( fa[i] == i ) ans++;
printf("%d %d\n", m, ans);
scanf("%d", &n);
while ( n-- ){
int x, y; scanf("%d %d",&x, &y);
if ( find(x) == find(y) ) cout<<"Y\n";
else cout<<"N\n";
}
return 0;
}
L2-025 分而治之 并查集
分而治之,各个击破是兵家常用的策略之一。在战争中,我们希望首先攻下敌方的部分城市,使其剩余的城市变成孤立无援,然后再分头各个击破。为此参谋部提供了若干打击方案。本题就请你编写程序,判断每个方案的可行性。
输入格式:
输入在第一行给出两个正整数 N 和 M(均不超过10 000),分别为敌方城市个数(于是默认城市从 1 到 N 编号)和连接两城市的通路条数。随后 M 行,每行给出一条通路所连接的两个城市的编号,其间以一个空格分隔。在城市信息之后给出参谋部的系列方案,即一个正整数 K (≤ 100)和随后的 K 行方案,每行按以下格式给出:
Np v[1] v[2] ... v[Np]
其中 Np 是该方案中计划攻下的城市数量,后面的系列 v[i] 是计划攻下的城市编号。
输出格式:
对每一套方案,如果可行就输出YES,否则输出NO。
输入样例:
10 11
8 7
6 8
4 5
8 4
8 1
1 2
1 4
9 8
9 1
1 10
2 4
5
4 10 3 8 4
6 6 1 7 5 4 9
3 1 8 4
2 2 8
7 9 8 7 6 5 4 2
输出样例:
NO
YES
YES
NO
NO
分析:
先将所有边记录下来,再每次询问时,用并查集处理所有没被摧毁的边,记录连通块即fa[x]=x的数量与没被摧毁的城市数量比较
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e4+10;
int fa[N];
vector<int> v[N];
void init(int n) { for ( int i = 1 ; i <= n ; i++ ) fa[i] = i; } //初始化
int find(int x) { return fa[x] == x ? x : fa[x] = find( fa[x] ); } //查找 路径压缩
void merge(int a, int b) { a = find(a), b = find(b), fa[b] = a; } //合并
int main(){
int n, m; scanf("%d%d", &n, &m);
while ( m-- ) {
int x, y; scanf("%d%d",&x, &y);
v[x].push_back(y);
}
scanf("%d", &m);
while( m-- ){
set<int> s; //用set存被摧毁的城市 方便查找
int k, num; scanf("%d", &k);
num = k;
while ( k-- ) {
int x; scanf("%d",&x);
s.insert(x);
}
init(n);
for ( int i = 1 ; i <= n ; i++ ){
for ( int j = 0 ; j < v[i].size() ; j++ ){
if(s.count(i)==0 && s.count(v[i][j])==0) //路径两端都没被摧毁
merge(i, v[i][j]);
}
}
int cnt = 0;
for ( int i = 1 ; i <= n ; i++ )
if ( fa[i] == i && s.count(i) == 0) cnt++;
if ( cnt >= n-num ) printf("YES\n");
else printf("NO\n");
}
return 0;
}
L2-026 小字辈 递归
本题给定一个庞大家族的家谱,要请你给出最小一辈的名单。
输入格式:
输入在第一行给出家族人口总数 N(不超过 100 000 的正整数) —— 简单起见,我们把家族成员从 1 到 N 编号。随后第二行给出 N 个编号,其中第 i 个编号对应第 i 位成员的父/母。家谱中辈分最高的老祖宗对应的父/母编号为 -1。一行中的数字间以空格分隔。
输出格式:
首先输出最小的辈分(老祖宗的辈分为 1,以下逐级递增)。然后在第二行按递增顺序输出辈分最小的成员的编号。编号间以一个空格分隔,行首尾不得有多余空格。
输入样例:
9
2 6 5 5 -1 5 6 4 7
输出样例:
4
1 9
分析:
先计算出所有人辈分(本文利用递归),再找到所有最小辈分的人
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e5+10;
int fa[N],bf[N];
int fun(int x){ //递归计算辈分
if ( bf[x] ) return bf[x]; //避免重复计算
if ( x == -1 ) return 0;
return bf[x] = 1+fun(fa[x]);
}
int main(){
int n; scanf("%d", &n);
for ( int i = 1 ; i <= n ; i ++ ){
int x; scanf("%d",&x);
fa[i] = x;
}
for ( int i = 1 ; i <= n ; i ++ ) //计算成员辈分
fun(i);
int ans = 0;
for ( int i = 1 ; i <= n ; i ++ ) //寻找最小辈分
ans = max(ans, bf[i]);
printf("%d\n", ans);
vector<int> v;
for ( int i = 1 ; i <= n ; i ++ ) //存答案
if ( bf[i] == ans ) v.push_back(i);
for ( int i = 0 ; i < v.size() ; i ++ )
printf("%d%c", v[i] , i == v.size()-1 ? '\n' : ' ');
return 0;
}
L2-027 名人堂与代金券 排序
对于在中国大学MOOC(http://www.icourse163.org/ )学习“数据结构”课程的学生,想要获得一张合格证书,总评成绩必须达到 60 分及以上,并且有另加福利:总评分在 [G, 100] 区间内者,可以得到 50 元 PAT 代金券;在 [60, G) 区间内者,可以得到 20 元PAT代金券。全国考点通用,一年有效。同时任课老师还会把总评成绩前 K 名的学生列入课程“名人堂”。本题就请你编写程序,帮助老师列出名人堂的学生,并统计一共发出了面值多少元的 PAT 代金券。
输入格式:
输入在第一行给出 3 个整数,分别是 N(不超过 10 000 的正整数,为学生总数)、G(在(60,100) 区间内的整数,为题面中描述的代金券等级分界线)、K(不超过 100且不超过 N 的正整数,为进入名人堂的最低名次)。接下来 N 行,每行给出一位学生的账号(长度不超过15位、不带空格的字符串)和总评成绩(区间 [0, 100] 内的整数),其间以空格分隔。题目保证没有重复的账号。
输出格式:
首先在一行中输出发出的 PAT 代金券的总面值。然后按总评成绩非升序输出进入名人堂的学生的名次、账号和成绩,其间以 1 个空格分隔。需要注意的是:成绩相同的学生享有并列的排名,排名并列时,按账号的字母序升序输出。
输入样例:
10 80 5
cy@zju.edu.cn 78
cy@pat-edu.com 87
1001@qq.com 65
uh-oh@163.com 96
test@126.com 39
anyone@qq.com 87
zoe@mit.edu 80
jack@ucla.edu 88
bob@cmu.edu 80
ken@163.com 70
输出样例:
360
1 uh-oh@163.com 96
2 jack@ucla.edu 88
3 anyone@qq.com 87
3 cy@pat-edu.com 87
5 bob@cmu.edu 80
5 zoe@mit.edu 80
分析:
水题,直接结构体存数据再排序就好,注意排名可以并列即可
代码:
因为用的数据结构不同,所以代码有所不同,区别在于重载处比较的写法
string存邮箱
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e4+10;
struct node{
string name;
int num;
const bool operator<(const node &t) {
if (num == t.num) return name < t.name;
return num > t.num;
}
}stu[N];
int main(){
int n, g, k;
scanf("%d%d%d", &n, &g, &k);
int sum = 0;
for ( int i = 1 ; i <= n ; i ++ ){
cin >> stu[i].name >> stu[i].num;
if ( stu[i].num >= g) sum += 50;
else if ( stu[i].num >= 60 ) sum += 20;
}
printf("%d\n",sum);
sort(stu+1,stu+n+1);
int cnt = 1;
for ( int i = 1 ; i <= n ; i ++ ){
if ( stu[i].num < stu[i-1].num ) cnt=i;
if ( cnt > k ) break;
cout << cnt << " " << stu[i].name << " " << stu[i].num << endl;
}
return 0;
}
char存邮箱
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e4+10;
struct node{
char name[20];
int num;
const bool operator<(const node &t) {
if (num == t.num) return strcmp(name,t.name)<0;
return num > t.num;
}
}stu[N];
int main(){
int n, g, k;
scanf("%d%d%d", &n, &g, &k);
int sum = 0;
for ( int i = 1 ; i <= n ; i ++ ){
scanf("%s %d", stu[i].name, &stu[i].num);
if ( stu[i].num >= g) sum += 50;
else if ( stu[i].num >= 60 ) sum += 20;
}
printf("%d\n",sum);
sort(stu+1,stu+n+1);
int cnt = 1;
for ( int i = 1 ; i <= n ; i ++ ){
if ( stu[i].num < stu[i-1].num ) cnt=i;
if ( cnt > k ) break;
printf("%d %s %d\n", cnt, stu[i].name, stu[i].num);
}
return 0;
}
L2-028 秀恩爱分得快 模拟
古人云:秀恩爱,分得快。
互联网上每天都有大量人发布大量照片,我们通过分析这些照片,可以分析人与人之间的亲密度。如果一张照片上出现了 K 个人,这些人两两间的亲密度就被定义为 1/K。任意两个人如果同时出现在若干张照片里,他们之间的亲密度就是所有这些同框照片对应的亲密度之和。下面给定一批照片,请你分析一对给定的情侣,看看他们分别有没有亲密度更高的异性朋友?
输入格式:
输入在第一行给出 2 个正整数:N(不超过1000,为总人数——简单起见,我们把所有人从 0 到 N-1 编号。为了区分性别,我们用编号前的负号表示女性)和 M(不超过1000,为照片总数)。随后 M 行,每行给出一张照片的信息,格式如下:
K P[1] ... P[K]
其中 K(≤ 500)是该照片中出现的人数,P[1] ~ P[K] 就是这些人的编号。最后一行给出一对异性情侣的编号 A 和 B。同行数字以空格分隔。题目保证每个人只有一个性别,并且不会在同一张照片里出现多次。
输出格式:
首先输出 A PA,其中 PA 是与 A 最亲密的异性。如果 PA 不唯一,则按他们编号的绝对值递增输出;然后类似地输出 B PB。但如果 A 和 B 正是彼此亲密度最高的一对,则只输出他们的编号,无论是否还有其他人并列。
输入样例 1:
10 4
4 -1 2 -3 4
4 2 -3 -5 -6
3 2 4 -5
3 -6 0 2
-3 2
输出样例 1:
-3 2
2 -5
2 -6
输入样例 2:
4 4
4 -1 2 -3 0
2 0 -3
2 2 -3
2 -1 2
-3 2
输出样例 2:
-3 2
代码:
#include <bits/stdc++.h>
using namespace std;
const int N = 1e3 + 3;
typedef long long ll;
int n, m, a, b, t, x, y;
string s; //字符串读入,用于判断"-0".用int无法判断-0的情况
vector<int> v[N]; //记录照片信息
double sum[N][N]; //亲密度总和
int sex[N]; // 1->男 -1->女
void O(int x) { //输出,因为输出"-0" 需要特判
if (x == 0 && sex[0] == -1) cout << '-';
cout << sex[abs(x)] * abs(x); //这样子输入普通i,也能输出正确的性别
}
int work(int i, int a) { //判断有无该情侣,有的话计算亲密度总和
auto q = lower_bound(v[i].begin(), v[i].end(), a);
int tmp = 0;
if (*q == a) { //在照片中有a这个人
x = sex[abs(a)];
for (int j = 0; j < v[i].size(); j++) {
y = sex[abs(v[i][j])];
if (x * y < 0) { //只有异性才计算亲密度
sum[abs(a)][abs(v[i][j])] += 1.0 / (v[i].size() * 1.0);
sum[abs(v[i][j])][abs(a)] += 1.0 / (v[i].size() * 1.0);
}
}
return 1;
}
return 0;
}
int main() {
cin >> n >> m;
for (int i = 1; i <= m; i++) {
cin >> a;
for (int j = 1; j <= a; j++) {
cin >> s;
t = stoi(s); // string 转 int
v[i].push_back(t);
sex[abs(t)] = s[0] == '-' ? -1 : 1; //判断男女
}
sort(v[i].begin(), v[i].end());
} //坑点,性别信息可能不在照片里,在给出的情侣里
cin >> s;
a = stoi(s);
sex[abs(a)] = s[0] == '-' ? -1 : 1;
cin >> s;
b = stoi(s);
sex[abs(b)] = s[0] == '-' ? -1 : 1;
for (int i = 1; i <= m; i++) {
int tmp = 0;
tmp += work(i, a);
tmp += work(i, b);
if (tmp == 2) { //去掉重复相加的
sum[abs(a)][abs(b)] -= 1.0 / (v[i].size() * 1.0);
sum[abs(b)][abs(a)] -= 1.0 / (v[i].size() * 1.0);
}
}
double Max1 = 0, Max2 = 0;
for (int i = 0; i < n; i++) Max1 = max(Max1, sum[abs(a)][i]);
for (int i = 0; i < n; i++) Max2 = max(Max2, sum[abs(b)][i]);
if (Max1 == Max2 && sum[abs(a)][abs(b)] == Max1)
O(a), cout << " ", O(b), cout << endl;
else {
for (int i = 0; i < n; i++)
if (sex[abs(a)] * sex[i] < 0 && sum[abs(a)][i] == Max1)
O(a), cout << " ", O(i), cout << endl;
for (int i = 0; i < n; i++)
if (sex[abs(b)] * sex[i] < 0 && sum[abs(b)][i] == Max2)
O(b), cout << " ", O(i), cout << endl;
}
}
L2-029 特立独行的幸福 数学
对一个十进制数的各位数字做一次平方和,称作一次迭代。如果一个十进制数能通过若干次迭代得到 1,就称该数为幸福数。1 是一个幸福数。此外,例如 19 经过 1 次迭代得到 82,2 次迭代后得到 68,3 次迭代后得到 100,最后得到 1。则 19 就是幸福数。显然,在一个幸福数迭代到 1 的过程中经过的数字都是幸福数,它们的幸福是依附于初始数字的。例如 82、68、100 的幸福是依附于 19 的。而一个特立独行的幸福数,是在一个有限的区间内不依附于任何其它数字的;其独立性就是依附于它的的幸福数的个数。如果这个数还是个素数,则其独立性加倍。例如 19 在区间[1, 100] 内就是一个特立独行的幸福数,其独立性为 2×4=8。
另一方面,如果一个大于1的数字经过数次迭代后进入了死循环,那这个数就不幸福。例如 29 迭代得到 85、89、145、42、20、4、16、37、58、89、…… 可见 89 到 58 形成了死循环,所以 29 就不幸福。
本题就要求你编写程序,列出给定区间内的所有特立独行的幸福数和它的独立性。
输入格式:
输入在第一行给出闭区间的两个端点:1<A<B≤104。
输出格式:
按递增顺序列出给定闭区间 [A,B] 内的所有特立独行的幸福数和它的独立性。每对数字占一行,数字间以 1 个空格分隔。
如果区间内没有幸福数,则在一行中输出 SAD。
输入样例 1:
10 40
输出样例 1:
19 8
23 6
28 3
31 4
32 3
**注意:**样例中,10、13 也都是幸福数,但它们分别依附于其他数字(如 23、31 等等),所以不输出。其它数字虽然其实也依附于其它幸福数,但因为那些数字不在给定区间 [10, 40] 内,所以它们在给定区间内是特立独行的幸福数。
输入样例 2:
110 120
输出样例 2:
SAD
代码:
#include<bits/stdc++.h>
using namespace std;
int is_prime(int n){
if(n<2) return 1;
for(int i=2;i<=sqrt(n);i++)
if(n%i==0) return 1;
return 2;
}
int main(){
int left,right,appear[100001]={0};
cin>>left>>right;
map<int,int> result;
for(int i=left;i<=right;i++){
int n=i,sum=0;
vector<int> v;
while(n!=1){
sum=0;
while(n){
sum+=(n%10)*(n%10);
n/=10;
}
n=sum;
if(find(v.begin(),v.end(),sum)!=v.end())
break; //判断重复
v.push_back(n);
appear[n]=1;
}
if(n==1) result[i]=v.size();
}
map<int,int>::iterator it;
int flag=0;
for(it=result.begin();it!=result.end();it++){
if(!appear[it->first]){
printf("%d %d\n",it->first,it->second*is_prime(it->first));
flag=1;
}
}
if(flag==0) printf("SAD");
return 0;
}
L2-031 深入虎穴 dfs
著名的王牌间谍 007 需要执行一次任务,获取敌方的机密情报。已知情报藏在一个地下迷宫里,迷宫只有一个入口,里面有很多条通路,每条路通向一扇门。每一扇门背后或者是一个房间,或者又有很多条路,同样是每条路通向一扇门…… 他的手里有一张表格,是其他间谍帮他收集到的情报,他们记下了每扇门的编号,以及这扇门背后的每一条通路所到达的门的编号。007 发现不存在两条路通向同一扇门。
内线告诉他,情报就藏在迷宫的最深处。但是这个迷宫太大了,他需要你的帮助 —— 请编程帮他找出距离入口最远的那扇门。
输入格式:
输入首先在一行中给出正整数 N(<105),是门的数量。最后 N 行,第 i 行(1≤i≤N)按以下格式描述编号为 i 的那扇门背后能通向的门:
K D[1] D[2] ... D[K]
其中 K 是通道的数量,其后是每扇门的编号。
输出格式:
在一行中输出距离入口最远的那扇门的编号。题目保证这样的结果是唯一的。
输入样例:
13
3 2 3 4
2 5 6
1 7
1 8
1 9
0
2 11 10
1 13
0
0
1 12
0
0
输出样例:
12
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e5+10;
int fa[N],dis[N];
int dfs(int x, int id){
if ( x == id ) return 0;
if ( dis[x] != 0 ) return dis[x];
return dis[x] = 1 + dfs(fa[x], id);
}
int main(){
int n; scanf("%d", &n);
for ( int i = 1 ; i <= n ; i ++ ) fa[i] = i;
for ( int i = 1 ; i <= n ; i ++ ){
int k; scanf("%d", &k);
while( k -- ){
int x; scanf("%d", &x);
fa[x] = i;
}
}
int id;
for ( int i = 1 ; i <= n ; i ++ )
if ( fa[i] == i ){
id = i;
break;
}
for ( int i = 1 ; i <= n ; i ++ ) dfs(i, id);
int maxdis = -1, maxid = 0;
for ( int i = 1 ; i <= n ; i ++ )
if ( maxdis < dis[i])
maxdis = dis[i], maxid = i;
printf("%d\n", maxid);
return 0;
}
L2-032 彩虹瓶 栈
彩虹瓶的制作过程(并不)是这样的:先把一大批空瓶铺放在装填场地上,然后按照一定的顺序将每种颜色的小球均匀撒到这批瓶子里。
假设彩虹瓶里要按顺序装 N 种颜色的小球(不妨将顺序就编号为 1 到 N)。现在工厂里有每种颜色的小球各一箱,工人需要一箱一箱地将小球从工厂里搬到装填场地。如果搬来的这箱小球正好是可以装填的颜色,就直接拆箱装填;如果不是,就把箱子先码放在一个临时货架上,码放的方法就是一箱一箱堆上去。当一种颜色装填完以后,先看看货架顶端的一箱是不是下一个要装填的颜色,如果是就取下来装填,否则去工厂里再搬一箱过来。
如果工厂里发货的顺序比较好,工人就可以顺利地完成装填。例如要按顺序装填 7 种颜色,工厂按照 7、6、1、3、2、5、4 这个顺序发货,则工人先拿到 7、6 两种不能装填的颜色,将其按照 7 在下、6 在上的顺序堆在货架上;拿到 1 时可以直接装填;拿到 3 时又得临时码放在 6 号颜色箱上;拿到 2 时可以直接装填;随后从货架顶取下 3 进行装填;然后拿到 5,临时码放到 6 上面;最后取了 4 号颜色直接装填;剩下的工作就是顺序从货架上取下 5、6、7 依次装填。
但如果工厂按照 3、1、5、4、2、6、7 这个顺序发货,工人就必须要愤怒地折腾货架了,因为装填完 2 号颜色以后,不把货架上的多个箱子搬下来就拿不到 3 号箱,就不可能顺利完成任务。
另外,货架的容量有限,如果要堆积的货物超过容量,工人也没办法顺利完成任务。例如工厂按照 7、6、5、4、3、2、1 这个顺序发货,如果货架够高,能码放 6 只箱子,那还是可以顺利完工的;但如果货架只能码放 5 只箱子,工人就又要愤怒了……
本题就请你判断一下,工厂的发货顺序能否让工人顺利完成任务。
输入格式:
输入首先在第一行给出 3 个正整数,分别是彩虹瓶的颜色数量 N(1<N≤103)、临时货架的容量 M(<N)、以及需要判断的发货顺序的数量 K。
随后 K 行,每行给出 N 个数字,是 1 到N 的一个排列,对应工厂的发货顺序。
一行中的数字都以空格分隔。
输出格式:
对每个发货顺序,如果工人可以愉快完工,就在一行中输出 YES;否则输出 NO。
输入样例:
7 5 3
7 6 1 3 2 5 4
3 1 5 4 2 6 7
7 6 5 4 3 2 1
输出样例:
YES
NO
NO
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e3+10;
int fun(vector<int> v, int m){
stack<int> s;
int d = 1;
for ( int i = 0 ; i < v.size() ; i ++ ){
s.push(v[i]);
while( s.size() && s.top() == d ){
d ++;
s.pop();
}
if ( s.size() > m ) return false;
}
if (s.empty() ) return true;
else return false;
}
int main(){
int n, m ,k;
scanf("%d%d%d", &n, &m, &k);
while ( k -- ){
vector<int> v;
int d = 1;
for ( int i = 0 ; i < n ; i ++ ){
int x; scanf("%d", &x);
v.push_back(x);
}
if ( fun(v, m) ) printf("YES\n");
else printf("NO\n");
}
return 0;
}
L2-033 简单计算器 栈
本题要求你为初学数据结构的小伙伴设计一款简单的利用堆栈执行的计算器。如上图所示,计算器由两个堆栈组成,一个堆栈 S1 存放数字,另一个堆栈 S2 存放运算符。计算器的最下方有一个等号键,每次按下这个键,计算器就执行以下操作:
- 从 S1 中弹出两个数字,顺序为 n1 和 n2;
- 从 S2 中弹出一个运算符 op;
- 执行计算 n2 op n1;
- 将得到的结果压回 S1。
直到两个堆栈都为空时,计算结束,最后的结果将显示在屏幕上。
输入格式:
输入首先在第一行给出正整数 N(1<N≤103),为 S1 中数字的个数。
第二行给出 N 个绝对值不超过 100 的整数;第三行给出 N−1 个运算符 —— 这里仅考虑 +、-、*、/ 这四种运算。一行中的数字和符号都以空格分隔。
输出格式:
将输入的数字和运算符按给定顺序分别压入堆栈 S1 和 S2,将执行计算的最后结果输出。注意所有的计算都只取结果的整数部分。题目保证计算的中间和最后结果的绝对值都不超过 109。
如果执行除法时出现分母为零的非法操作,则在一行中输出:ERROR: X/0,其中 X 是当时的分子。然后结束程序。
输入样例 1:
5
40 5 8 3 2
/ * - +
输出样例 1:
2
输入样例 2:
5
2 5 8 4 4
* / - +
输出样例 2:
ERROR: 5/0
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e3+10;
void fun(vector<int> vi, vector<char> vc){
stack<int> si;
stack<char> sc;
for ( int i = 0 ; i < vi.size() ; i ++ ) si.push(vi[i]);
for ( int i = 0 ; i < vc.size() ; i ++ ) sc.push(vc[i]);
int ans=1;
while ( sc.size() ) {
int n1, n2;
n1 = si.top(); si.pop();
n2 = si.top(); si.pop();
// cout<<n1<<" "<<n2<<" "<<sc.top()<<endl;
if ( sc.top() == '+' ) ans = n2 + n1;
if ( sc.top() == '-' ) ans = n2 - n1;
if ( sc.top() == '*' ) ans = n2 * n1;
if ( sc.top() == '/' ) {
if ( n1 == 0){
printf("ERROR: %d/0\n", n2);
return ;
}
ans = n2 / n1;
}
sc.pop();
si.push(ans);
}
printf("%d\n", si.top());
}
int main(){
int n; scanf("%d",&n);
vector<int> vi;
vector<char> vc;
for ( int i = 1 ; i <= n ; i ++ ){
int x; scanf("%d", &x);
vi.push_back(x);
}
for ( int i = 1 ; i < n ; i ++ ){
char c[5]; scanf("%s", c);
vc.push_back(c[0]);
}
fun(vi, vc);
return 0;
}
L2-035 完全二叉树的层序遍历 树
一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是完美二叉树。对于深度为 D 的,有 N 个结点的二叉树,若其结点对应于相同深度完美二叉树的层序遍历的前 N 个结点,这样的树就是完全二叉树。
给定一棵完全二叉树的后序遍历,请你给出这棵树的层序遍历结果。
输入格式:
输入在第一行中给出正整数 N(≤30),即树中结点个数。第二行给出后序遍历序列,为 N 个不超过 100 的正整数。同一行中所有数字都以空格分隔。
输出格式:
在一行中输出该树的层序遍历序列。所有数字都以 1 个空格分隔,行首尾不得有多余空格。
输入样例:
8
91 71 2 34 10 15 55 18
输出样例:
18 34 55 71 2 10 15 91
分析:
完全二叉树采用顺序存储方式,如果有左孩子,则编号为2i,如果有右孩子,编号为2i+1,然后按照后序遍历的方式(左右根),进行输入,最后顺序输出即可
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e3+10;
int n, tree[31];
void create(int i) {
if (i > n) return;
create(2 * i);
create(2 * i + 1);
scanf("%d", &tree[i]);
}
int main() {
cin >> n;
create(1);
for ( int i = 1; i <= n; i ++)
printf ("%d%c", tree[i], i==n ? '\n' : ' ');
return 0;
}
L2-036 网红点打卡攻略 模拟
一个旅游景点,如果被带火了的话,就被称为“网红点”。大家来网红点游玩,俗称“打卡”。在各个网红点打卡的快(省)乐(钱)方法称为“攻略”。你的任务就是从一大堆攻略中,找出那个能在每个网红点打卡仅一次、并且路上花费最少的攻略。
输入格式:
首先第一行给出两个正整数:网红点的个数 N(1<N≤200)和网红点之间通路的条数 M。随后 M 行,每行给出有通路的两个网红点、以及这条路上的旅行花费(为正整数),格式为“网红点1 网红点2 费用”,其中网红点从 1 到 N 编号;同时也给出你家到某些网红点的花费,格式相同,其中你家的编号固定为 0。
再下一行给出一个正整数 K,是待检验的攻略的数量。随后 K 行,每行给出一条待检攻略,格式为:
n V1 V2 ⋯ V**n
其中 n(≤200) 是攻略中的网红点数,V**i 是路径上的网红点编号。这里假设你从家里出发,从 V1 开始打卡,最后从 V**n 回家。
输出格式:
在第一行输出满足要求的攻略的个数。
在第二行中,首先输出那个能在每个网红点打卡仅一次、并且路上花费最少的攻略的序号(从 1 开始),然后输出这个攻略的总路费,其间以一个空格分隔。如果这样的攻略不唯一,则输出序号最小的那个。
题目保证至少存在一个有效攻略,并且总路费不超过 109。
输入样例:
6 13
0 5 2
6 2 2
6 0 1
3 4 2
1 5 2
2 5 1
3 1 1
4 1 2
1 6 1
6 3 2
1 2 1
4 5 3
2 0 2
7
6 5 1 4 3 6 2
6 5 2 1 6 3 4
8 6 2 1 6 3 4 5 2
3 2 1 5
6 6 1 3 4 5 2
7 6 2 1 3 4 5 2
6 5 2 1 4 3 6
输出样例:
3
5 11
样例说明:
第 2、3、4、6 条都不满足攻略的基本要求,即不能做到从家里出发,在每个网红点打卡仅一次,且能回到家里。所以满足条件的攻略有 3 条。
第 1 条攻略的总路费是:(0->5) 2 + (5->1) 2 + (1->4) 2 + (4->3) 2 + (3->6) 2 + (6->2) 2 + (2->0) 2 = 14;
第 5 条攻略的总路费同理可算得:1 + 1 + 1 + 2 + 3 + 1 + 2 = 11,是一条更省钱的攻略;
第 7 条攻略的总路费同理可算得:2 + 1 + 1 + 2 + 2 + 2 + 1 = 11,与第 5 条花费相同,但序号较大,所以不输出。
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e3+10;
int main(){
int n, m;
scanf("%d%d", &n, &m);
int mp[n+5][n+5];
for ( int i = 0 ; i <= n ; i ++ )
for ( int j = 0 ; j <= n ; j ++ )
mp[i][j] = mp[j][i] = 0;
for ( int i = 1 ; i <= m ; i ++ ){
int x, y, w; scanf("%d%d%d", &x, &y, &w);
mp[x][y] = mp[y][x] = w;
}
vector<PII> ans;
int q, minw=INF; scanf("%d", &q);
for ( int i = 1 ; i <= q ; i ++ ){
int k; scanf("%d", &k);
vector<int> v;
set<int> s;
v.push_back(0);
for (int j = 0 ; j < k ; j ++ ){
int x; scanf("%d", &x);
v.push_back(x);
s.insert(x);
}
v.push_back(0);
int w = 0;
if(k != n || s.size() != n) continue;
bool flag = true;
for (int j = 0 ; j < v.size()-1 ; j ++ ){
if (mp[v[j]][v[j+1]]!=0) w += mp[v[j]][v[j+1]];
else {
flag = false;
break;
}
}
if (!flag) continue;
minw = min(minw, w);
ans.push_back({i, w});
}
printf("%d\n", ans.size());
for ( int i = 0 ; i < ans.size() ; i ++ )
if ( ans[i].second == minw ){
printf("%d %d\n", ans[i].first, ans[i].second);
break;
}
return 0;
}
L2-037 包装机 栈和队列
一种自动包装机的结构如图 1 所示。首先机器中有 N 条轨道,放置了一些物品。轨道下面有一个筐。当某条轨道的按钮被按下时,活塞向左推动,将轨道尽头的一件物品推落筐中。当 0 号按钮被按下时,机械手将抓取筐顶部的一件物品,放到流水线上。图 2 显示了顺序按下按钮 3、2、3、0、1、2、0 后包装机的状态。
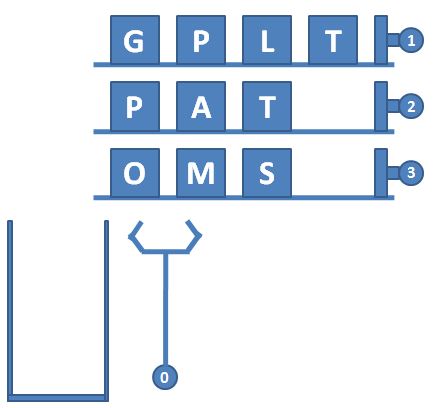
图1 自动包装机的结构
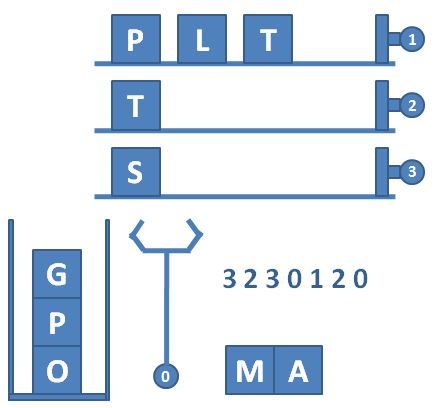
图 2 顺序按下按钮 3、2、3、0、1、2、0 后包装机的状态
一种特殊情况是,因为筐的容量是有限的,当筐已经满了,但仍然有某条轨道的按钮被按下时,系统应强制启动 0 号键,先从筐里抓出一件物品,再将对应轨道的物品推落。此外,如果轨道已经空了,再按对应的按钮不会发生任何事;同样的,如果筐是空的,按 0 号按钮也不会发生任何事。
现给定一系列按钮操作,请你依次列出流水线上的物品。
输入格式:
输入第一行给出 3 个正整数 N(≤100)、M(≤1000)和 Smax(≤100),分别为轨道的条数(于是轨道从 1 到 N 编号)、每条轨道初始放置的物品数量、以及筐的最大容量。随后 N 行,每行给出 M 个英文大写字母,表示每条轨道的初始物品摆放。
最后一行给出一系列数字,顺序对应被按下的按钮编号,直到 −1 标志输入结束,这个数字不要处理。数字间以空格分隔。题目保证至少会取出一件物品放在流水线上。
输出格式:
在一行中顺序输出流水线上的物品,不得有任何空格。
输入样例:
3 4 4
GPLT
PATA
OMSA
3 2 3 0 1 2 0 2 2 0 -1
输出样例:
MATA
分析:
队列模拟传送带,栈模拟筐
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e3+10;
int main(){
int n, m, s; scanf("%d%d%d", &n, &m, &s);
queue<int> q[n+5];
stack<int> sta;
for ( int i = 1 ; i <= n ; i ++ ){ //第i号轨道
char str[m+5]; scanf("%s",str);
for ( int j = 0 ; j < m ; j ++ ) //第j个物品
q[i].push(str[j]-'A');
}
int x;
while ( scanf("%d", &x) && x != -1){
if ( x > 0 && q[x].size() ){
int t = q[x].front();
q[x].pop();
if(sta.size() == s) {
printf("%c", sta.top()+'A');
sta.pop();
}
sta.push(t);
}
if ( x == 0 && sta.size() ){
printf("%c", sta.top()+'A');
sta.pop();
}
}
return 0;
}
L2-038 病毒溯源 dfs
病毒容易发生变异。某种病毒可以通过突变产生若干变异的毒株,而这些变异的病毒又可能被诱发突变产生第二代变异,如此继续不断变化。
现给定一些病毒之间的变异关系,要求你找出其中最长的一条变异链。
在此假设给出的变异都是由突变引起的,不考虑复杂的基因重组变异问题 —— 即每一种病毒都是由唯一的一种病毒突变而来,并且不存在循环变异的情况。
输入格式:
输入在第一行中给出一个正整数 N(≤104),即病毒种类的总数。于是我们将所有病毒从 0 到 N−1 进行编号。
随后 N 行,每行按以下格式描述一种病毒的变异情况:
k 变异株1 …… 变异株k
其中 k 是该病毒产生的变异毒株的种类数,后面跟着每种变异株的编号。第 i 行对应编号为 i 的病毒(0≤i<N)。题目保证病毒源头有且仅有一个。
输出格式:
首先输出从源头开始最长变异链的长度。
在第二行中输出从源头开始最长的一条变异链,编号间以 1 个空格分隔,行首尾不得有多余空格。如果最长链不唯一,则输出最小序列。
注:我们称序列 { a1,⋯,a**n } 比序列 { b1,⋯,b**n } “小”,如果存在 1≤k≤n 满足 a**i=b**i 对所有 i<k 成立,且 a**k<b**k。
输入样例:
10
3 6 4 8
0
0
0
2 5 9
0
1 7
1 2
0
2 3 1
输出样例:
4
0 4 9 1
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e4+10;
int vis[N], maxk;
vector<int> v[N], ans, t;
void dfs(int id, int k){
if ( k > maxk ){
maxk = k;
ans = t;
}
for ( int i = 0 ; i < v[id].size() ; i ++ ){
t.push_back(v[id][i]);
dfs(v[id][i], k+1);
t.pop_back();
}
return ;
}
int main(){
int n;
scanf("%d", &n);
for ( int i = 0 ; i < n ; i ++ ){
int k; scanf("%d", &k);
while ( k -- ){
int x; scanf("%d", &x);
vis[x] = 1;
v[i].push_back(x);
}
sort(v[i].begin(), v[i].end());
}
int id; //病毒源头
for ( int i = 0 ; i < n ; i ++ ){
if( vis[i] == 0 ) {
id = i;
break;
}
}
dfs(id, 1);
printf("%d\n%d", maxk, id);
for (int i = 0 ; i < ans.size() ; i ++ )
printf(" %d",ans[i]);
return 0;
}
L2-039 清点代码库 排序
上图转自新浪微博:“阿里代码库有几亿行代码,但其中有很多功能重复的代码,比如单单快排就被重写了几百遍。请设计一个程序,能够将代码库中所有功能重复的代码找出。各位大佬有啥想法,我当时就懵了,然后就挂了。。。”
这里我们把问题简化一下:首先假设两个功能模块如果接受同样的输入,总是给出同样的输出,则它们就是功能重复的;其次我们把每个模块的输出都简化为一个整数(在 int 范围内)。于是我们可以设计一系列输入,检查所有功能模块的对应输出,从而查出功能重复的代码。你的任务就是设计并实现这个简化问题的解决方案。
输入格式:
输入在第一行中给出 2 个正整数,依次为 N(≤104)和 M(≤102),对应功能模块的个数和系列测试输入的个数。
随后 N 行,每行给出一个功能模块的 M 个对应输出,数字间以空格分隔。
输出格式:
首先在第一行输出不同功能的个数 K。随后 K 行,每行给出具有这个功能的模块的个数,以及这个功能的对应输出。数字间以 1 个空格分隔,行首尾不得有多余空格。输出首先按模块个数非递增顺序,如果有并列,则按输出序列的递增序给出。
注:所谓数列 { A1, …, A**M } 比 { B1, …, B**M } 大,是指存在 1≤i<M,使得 A1=B1,…,A**i=B**i 成立,且 A**i+1>B**i+1。
输入样例:
7 3
35 28 74
-1 -1 22
28 74 35
-1 -1 22
11 66 0
35 28 74
35 28 74
输出样例:
4
3 35 28 74
2 -1 -1 22
1 11 66 0
1 28 74 35
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e4+10;
struct cmp{ //自定义set排序
bool operator() (const pair<int,vector<int> >&a, const pair<int,vector<int> >&b) const{
if(a.first!=b.first) return a.first>b.first;
else return a.second<b.second;
}
};
int main(){
int n, m; scanf("%d%d", &n, &m);
set<vector<int> > st; //存模块
map<vector<int>, int> mp; //存每个模块的个数
set<pair<int,vector<int> >,cmp > St;//排序
for ( int i = 0 ; i < n ; i ++ ){
vector<int> v;
for ( int j = 0 ; j < m ; j ++ ){
int x; scanf("%d", &x);
v.push_back(x);
}
mp[v] ++;
st.insert(v);
}
printf("%d\n", st.size());
//把所有模块存入ST排序
set<vector<int> >::iterator it;
for(it = st.begin() ; it != st.end() ; it ++)
St.insert({mp[*it],*it});
//输出ST
set<pair<int,vector<int> > >::iterator ite;
for(ite = St.begin() ; ite != St.end() ; ite ++){
cout << (*ite).first;
for(int i = 0; i < (*ite).second.size() ; i++)
cout<<' '<<(*ite).second[i];
cout<<endl;
}
return 0;
}
L2-040 哲哲打游戏 模拟
哲哲是一位硬核游戏玩家。最近一款名叫《达诺达诺》的新游戏刚刚上市,哲哲自然要快速攻略游戏,守护硬核游戏玩家的一切!
为简化模型,我们不妨假设游戏有 N 个剧情点,通过游戏里不同的操作或选择可以从某个剧情点去往另外一个剧情点。此外,游戏还设置了一些存档,在某个剧情点可以将玩家的游戏进度保存在一个档位上,读取存档后可以回到剧情点,重新进行操作或者选择,到达不同的剧情点。
为了追踪硬核游戏玩家哲哲的攻略进度,你打算写一个程序来完成这个工作。假设你已经知道了游戏的全部剧情点和流程,以及哲哲的游戏操作,请你输出哲哲的游戏进度。
输入格式:
输入第一行是两个正整数 N 和 M (1≤N,M≤105),表示总共有 N 个剧情点,哲哲有 M 个游戏操作。
接下来的 N 行,每行对应一个剧情点的发展设定。第 i 行的第一个数字是 K**i,表示剧情点 i 通过一些操作或选择能去往下面 K**i 个剧情点;接下来有 K**i 个数字,第 k 个数字表示做第 k 个操作或选择可以去往的剧情点编号。
最后有 M 行,每行第一个数字是 0、1 或 2,分别表示:
- 0 表示哲哲做出了某个操作或选择,后面紧接着一个数字 j,表示哲哲在当前剧情点做出了第 j 个选择。我们保证哲哲的选择永远是合法的。
- 1 表示哲哲进行了一次存档,后面紧接着是一个数字 j,表示存档放在了第 j 个档位上。
- 2 表示哲哲进行了一次读取存档的操作,后面紧接着是一个数字 j,表示读取了放在第 j 个位置的存档。
约定:所有操作或选择以及剧情点编号都从 1 号开始。存档的档位不超过 100 个,编号也从 1 开始。游戏默认从 1 号剧情点开始。总的选项数(即 ∑K**i)不超过 106。
输出格式:
对于每个 1(即存档)操作,在一行中输出存档的剧情点编号。
最后一行输出哲哲最后到达的剧情点编号。
输入样例:
10 11
3 2 3 4
1 6
3 4 7 5
1 3
1 9
2 3 5
3 1 8 5
1 9
2 8 10
0
1 1
0 3
0 1
1 2
0 2
0 2
2 2
0 3
0 1
1 1
0 2
输出样例:
1
3
9
10
样例解释:
简单给出样例中经过的剧情点顺序:
1 -> 4 -> 3 -> 7 -> 8 -> 3 -> 5 -> 9 -> 10。
档位 1 开始存的是 1 号剧情点;档位 2 存的是 3 号剧情点;档位 1 后来又存了 9 号剧情点。
代码:
#include<bits/stdc++.h>
using namespace std;
#define PII pair<int,int>
const int INF = 0x3f3f3f3f;
const int N = 1e3+10;
vector<int> e[100010];
int que[110];
int main(){
int n, m; scanf("%d%d", &n, &m);
for (int i = 1 ; i <= n ; i ++) {
int t; scanf("%d", &t);
while (t--){
int x; scanf("%d", &x);
e[i].push_back(x);
}
}
int now = 1;
while (m--) {
int x, y; scanf("%d%d", &x, &y);
if (x == 0)
now = e[now][y - 1];
else if (x == 1) {
que[y] = now;
printf("%d\n", now);
}
else if (x == 2)
now = que[y];
}
printf("%d\n", now);
return 0;
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











