







1.基本统计分析:一般统计最小值,第一四分位值,中值,第三四分位置。最大值
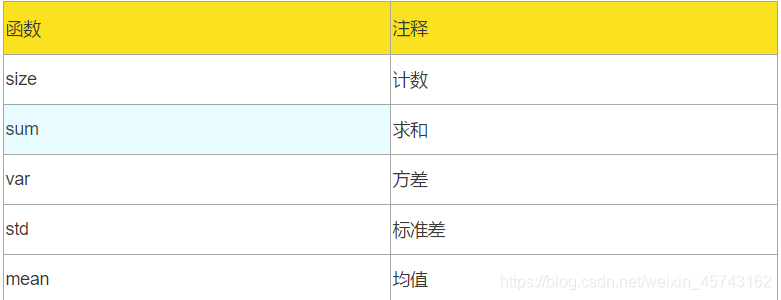
常用统计指标:计数,求和,平均值,方差,标准差
描述性统计分析函数:describe()
常用的统计函数
import pandas
data=pandas.read_csv('D:\BaiduNetdiskDownload\8\8.1\data.csv')
print(data)
print(data.score.describe())
#count 13.000000
#mean 121.076923
#std 12.446295
#min 96.000000
#25% 115.000000
#50% 120.000000
#75% 131.000000
#max 140.000000
#如果要分统计也行
print(data.score.size)
#13
2.分组统计
分组统计函数:groupby(by=[分组1,分组2.。。】)
【统计列1,统计列2】
.agg({统计列别名1:统计函数1.。。。})
解释
by:用于分组的列
中括号:用于统计的列
agg:统计别名显示统计值的名称
import pandas,numpy
data=pandas.read_csv('D:\BaiduNetdiskDownload\8\8.1\data.csv')
data['score2']=data['score']*data['score']
data.groupby(by=['class'])['score'].agg({
'总分':numpy.sum,
'人数':numpy.size,
'平均值':numpy.mean,
'方差':numpy.var,
'标准差':numpy.std,
}
)
# 总分 人数 平均值 方差 标准差
#class
#一班 635 5 127.00 71.000000 8.426150
#三班 484 4 121.00 104.666667 10.230673
#二班 455 4 113.75 290.250000 17.036725
a=data.groupby(by=['class','name'])['score','score2'].agg({
numpy.sum,
numpy.size
}
)
这样拿班级和姓名分组得到这个:
score score2
sum size sum size
class  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4903
4903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









