







 本文详细介绍了如何使用R语言的MatchIt和cobalt包来计算和绘制标准化平均差(SMD)可视化图,用于评估协变量的平衡程度。通过实例数据展示了如何进行倾向得分匹配、SMD的计算以及使用love.plot和bal.plot函数创建各种类型的SMD图,强调了这些图形在观察数据分布和比较不同匹配方法效果中的作用。此外,还提及了SMD在机器学习集群分析中的应用。
本文详细介绍了如何使用R语言的MatchIt和cobalt包来计算和绘制标准化平均差(SMD)可视化图,用于评估协变量的平衡程度。通过实例数据展示了如何进行倾向得分匹配、SMD的计算以及使用love.plot和bal.plot函数创建各种类型的SMD图,强调了这些图形在观察数据分布和比较不同匹配方法效果中的作用。此外,还提及了SMD在机器学习集群分析中的应用。
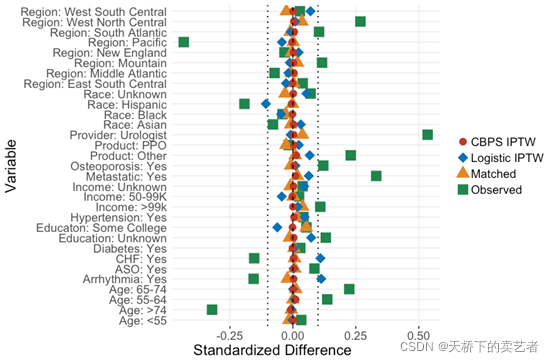
最近收到粉丝投稿要求我出个画个标准化平均差SMD可视化图的教程,就是下面这样的图,还给我推荐了2篇论文。

相关的论文是:
https://www.mdpi.com/2075-4426/11/11/1132/htm
https://sci-hub.se/10.1007/s10742-020-00222-8
看了粉丝推荐我的那篇文章,那老外满屏都在秀操作,看得头晕眼花,不过基本上算是看懂了,首先来看看标准化平均差SMD是什么

这个SMD的图怎么看,下图为例,主要是看协变量之间的平衡程度,我们看绿色的是没有经过调整的时候,各个协变量偏离得很大,但是经过花式操作,偏离得明显减少,特别是红色这个CBPS IPTW,几乎没有什么偏移,很多文章就会说调整了基线资料,有明显可比性。
那么SMD怎么计算呢,以我早产数据为例,假设我要计算早产和没有早产之间年龄(age)的SMD,先算出早产组年龄的平均值和没有早产组年龄的平均值,在算出两组之间的标准差(SD),然后早产组平均值减去非早产组平均值,再除以两组之间的标准差,就是SMD了。这里要注意一下,分类变量和连续变量的计算是不一样的,分类变量中的变量名只是代表一个类别,而不是数字,不能直接拿来加减,要先转成哑变量矩阵,可不是我们平时说的因子哦。
OK,废话不多说,我们现在开始,先导入数据和R包,这里需要两个R包,MatchIt包和cobalt包
library("MatchIt")
library("cobalt")
bc<-read.csv("E:/r/test/zaochan.csv",sep=',',header=TRUE)
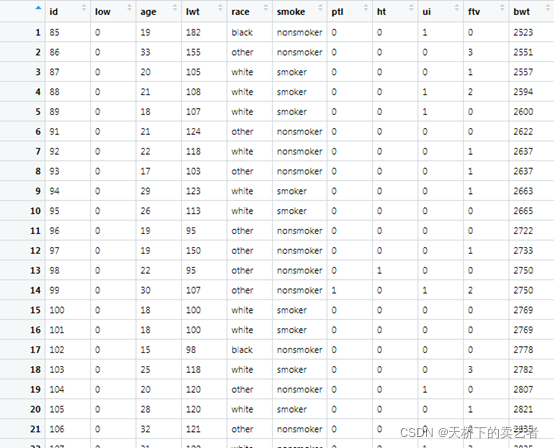
这是一个关于早产低体重儿的数据(公众号回复:早产数据,可以获得该数据),低于2500g被认为是低体重儿。数据解释如下:low 是否是小于2500g早产低体重儿,age 母亲的年龄,lwt 末次月经体重,race 种族,smoke 孕期抽烟,ptl 早产史(计数),ht 有高血压病史,ui 子宫过敏,ftv 早孕时看医生的次数
bwt 新生儿体重数值。
我们先把分类变量转成因子
bc <- na.omit(bc)
bc$race<-ifelse(bc$race=="black",1,ifelse(bc$race=="white",2,3))
bc$smoke<-ifelse(bc$smoke=="nonsmoker",0,1)
bc$low<-factor(bc$low)
bc$race<-factor(bc$race)
bc$ht<-factor(bc$ht)
bc$ui<-factor(bc$ui)
我们先来介绍一下matchit函数,这个是平衡协变量的函数,使用前要先建立一个方程
formula1<-low ~ age + lwt + race + smoke + ptl + ht + ui + ftv
使用matchit函数中,method有多种算法,默认的就是nearest就是倾向得分匹配,full是完全匹配,distance中如果使用倾向得分匹配默认是glm, ratio是设置一条参考线,caliper是设置卡钳,也就是它的宽度
formula1<-low ~ age + lwt + race + smoke + ptl + ht + ui + ftv
m.out<-matchit(formula1, data =bc, method = "nearest",
distance="glm", m.order=
"random",ratio=1,caliper=0.03,replace=FALSE)
如果使用full,部分参数就不需要设置了
m.out2<-matchit(formula1, data =bc, method = "full",
distance="glm",caliper=0.03)
解析函数
summary(m.out)
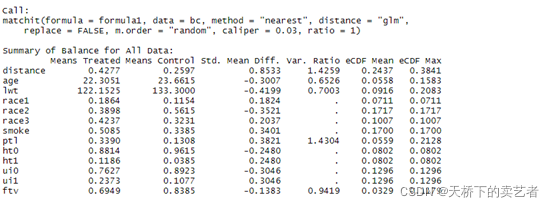
绘图,这样,一个简单标准化平均差(SMD)可视化图就绘制好了
plot(summary(m.out))
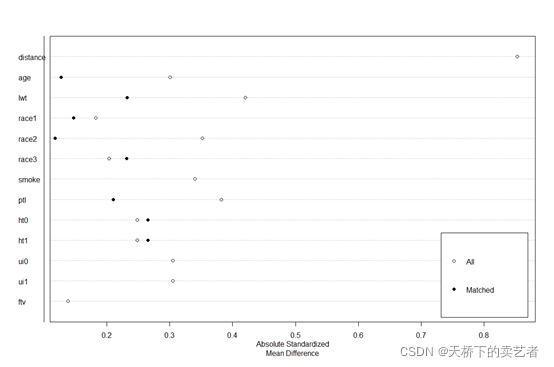
这样的图不够美观,cobalt包登场了,男女搭配,干活不累呀,cobalt也挺有意思的,管这叫这做爱情节点图,函数也叫爱情函数
love.plot(m.out, binary = "std")
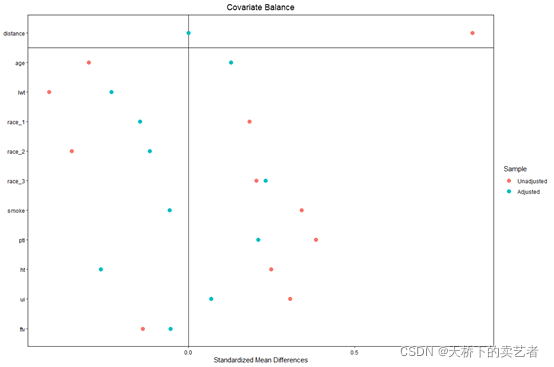
还可以同时或多个图
love.plot(m.out, stats = c("m", "ks"), poly = 2, abs = TRUE,
weights = list(nn = m.out2),
drop.distance = TRUE, thresholds = c(m = .1),
var.order = "unadjusted", binary = "std",
shapes = c("triangle", "square", "circle"),
colors = c("blue", "darkgreen", "red"),
sample.names = c("Full Matching", "NN Matching", "Original"),
position = "bottom")
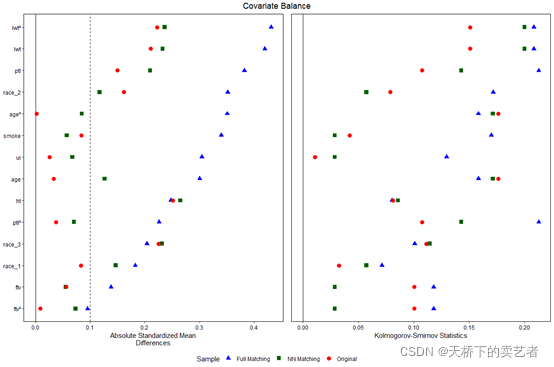
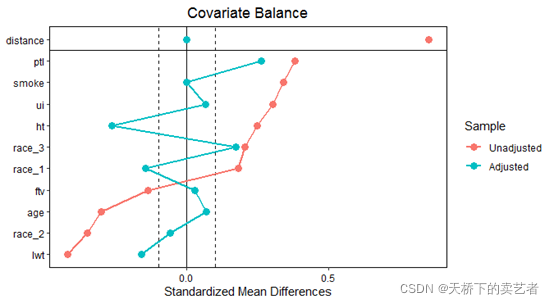
还可以画成这样连线的图,是不是感觉经过经过评分匹配后,协变量的平衡好很多,threshold = c(.1)表示设置0.1为阈值,虚线表示,mean.diffs是平均差异的意思。
love.plot(m.out,binary = "std",stats = c("mean.diffs"),
threshold = c(.1), var.order = "unadjusted", line = TRUE)
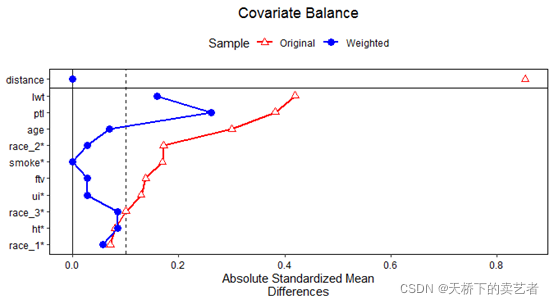
这是另一种画风,在这里stars设置为“std”或“raw”都可以,grid = F表示不要网格,shapes为设置形状,line = TRUE是添加连接线
love.plot(m.out, thresholds = c(m = .1),
var.order = "unadjusted", abs = TRUE,
shapes = c("triangle filled", "circle"),
colors = c("red", "blue"), line = TRUE,
grid = FALSE, sample.names = c("Original", "Weighted"),
stars = "raw", position = "top")
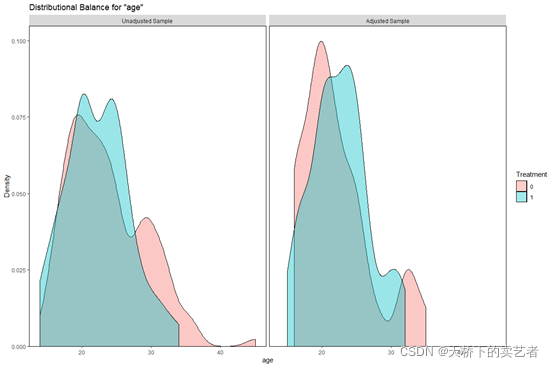
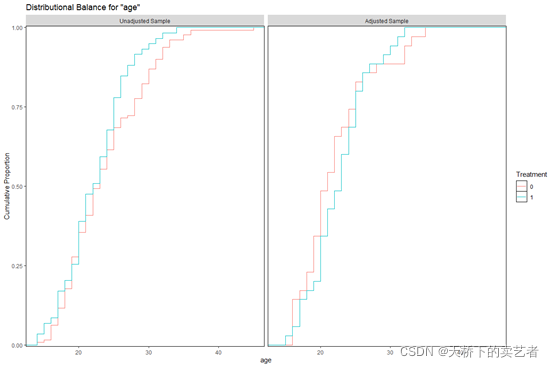
cobalt包还有个bal.plot函数,也能制作出很多很棒的图
bal.plot(m.out, "age", which = "both")
bal.plot(m.out, "age", which = "both", type = "ecdf")
bal.plot(m.out, "race", which = "both")
bal.plot(m.out, "distance", which = "both", mirror = TRUE,
type = "histogram", colors = c("white", "black"))
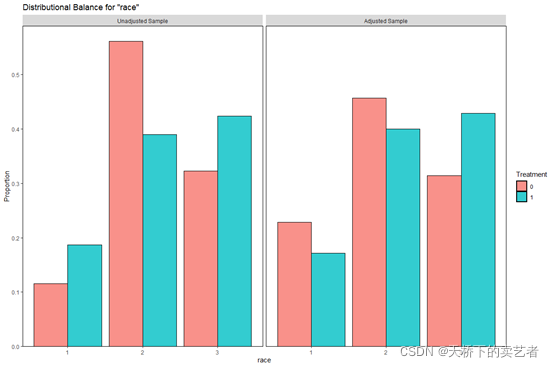
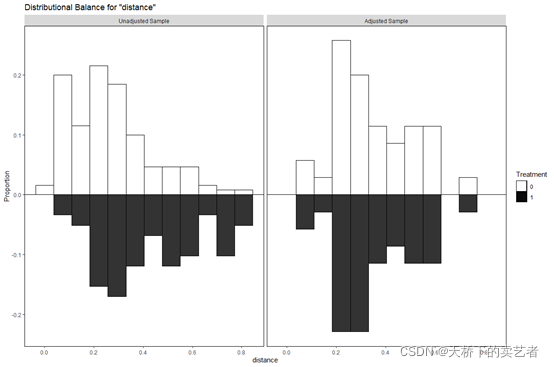
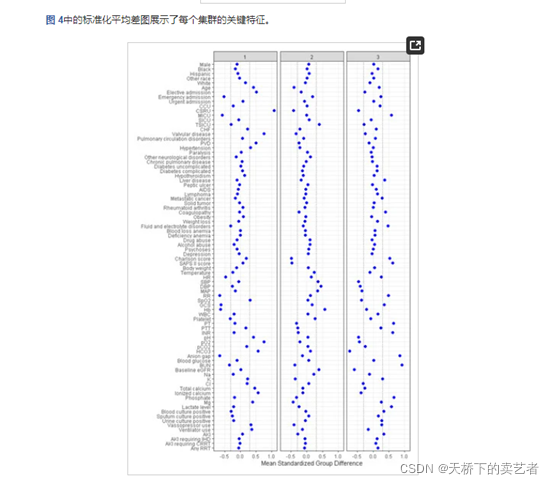
在文章:settings Open AccessArticle Machine Learning Consensus Clustering Approach for Patients with Lactic Acidosis in Intensive Care Units中,标准化平均差(SMD)可视化图有了新的用法

通过机器学习将数据分为3类,观察标准化平均差(SMD)可视化图了解每个集群的数据特征,从而了解集群特点和目标结果的关系,有点潜类别分析的味道。
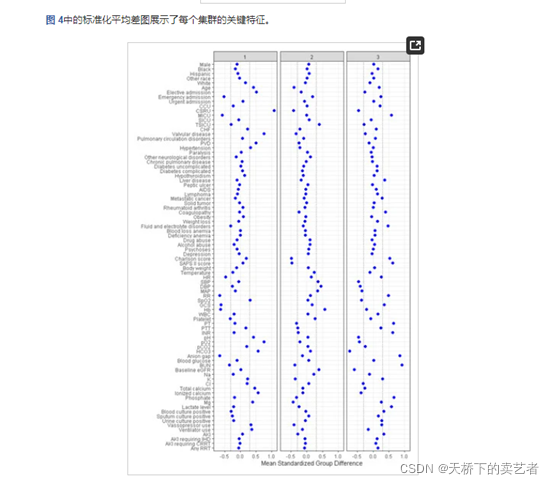

这种3个分类的绘图,以上两个包做不出来这样的图(只能做两组的),这需要了解它的绘图逻辑,先要算出SMD,然后绘图,
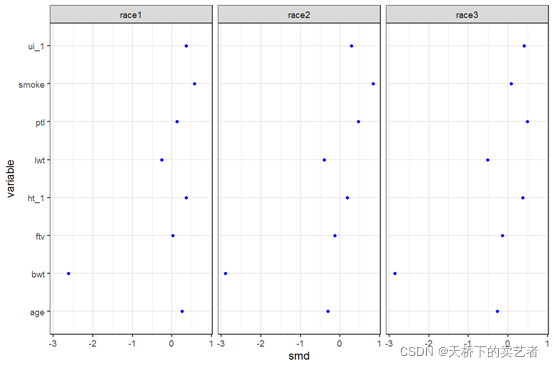
本部分内容属于粉丝投稿,图片相对小众,原创不易,需要上图这部分代码的朋友,请把本公众号文章转发朋友圈集10个赞,截图发给我,嫌麻烦的给我打赏5元截图发给我也可以。
OK,本章内容结束,觉得有用的话请多多分享哟。


















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











