






python爬虫学习记录
1.wireshark抓取网络数据包练习
目标软件: 疯狂聊天
抓取得到以下如下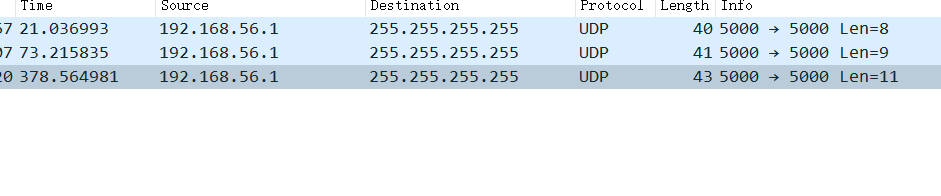
端口号为开始聊天时设置的房间号+5000,通过在本网段广播实现与同房间任意人员进行聊天。采用协议为UDP。
取得数据包如下:
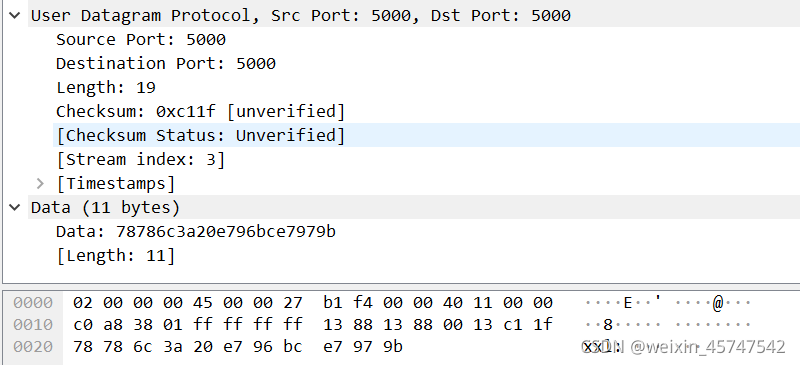
字符在这里不可见是因为字符中文编码采用utf-8编码格式,将其复制进其他软件,采用utf-8格式即可看到数据,具体数据如下:
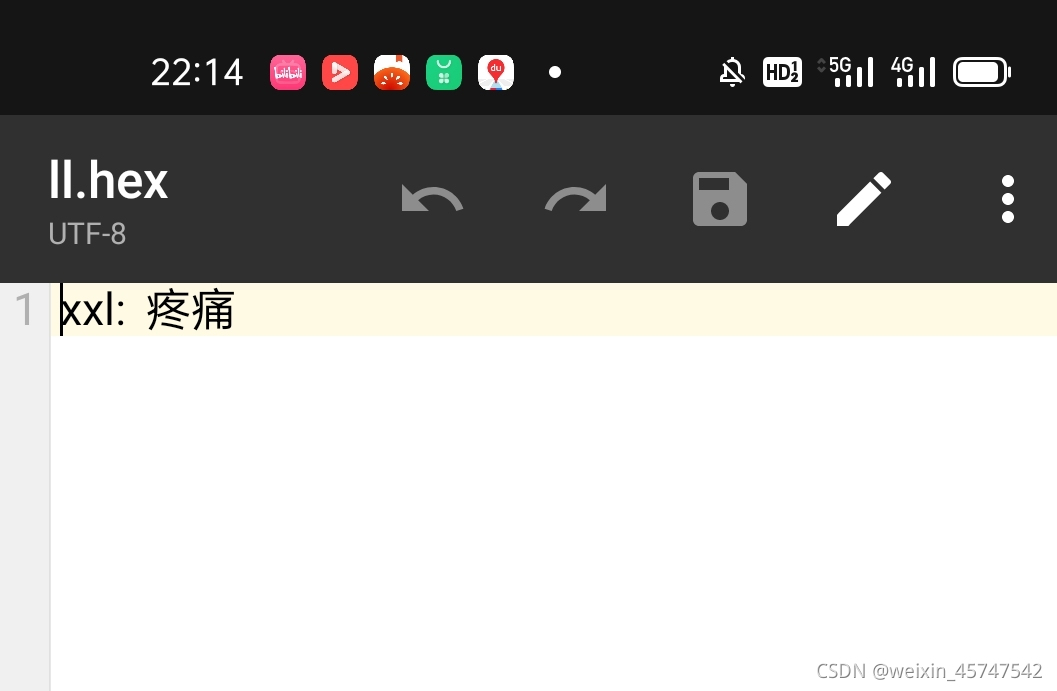
2.python爬虫抓取数据
1.南阳理工学院ACM题目网站练习题目数据的抓取和保存
目标网站:http://www.51mxd.cn/
本次采用requests + beautifulsoup
分析网站源码,可以看到我们需要的信息均在<td>标签内,如下所示
同时,通过浏览器显示的网站,可以得知得到的页面信息由problemset.php-page=x.htm决定,其中x为页面编号,共计11页

且没有其他不保存所需信息的td标签。因此,直接将所有td标签中信息提取出来即可。
具体代码如下:
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm')
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('D://myworks//network//NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
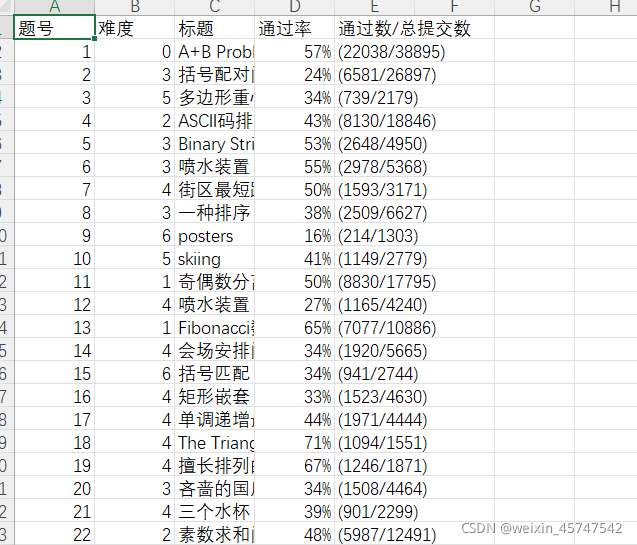
取得数据如下:
2.爬取重庆交通大学新闻网站中近几年所有的信息通知的发布日期和标题
目标网址:http://news.cqjtu.edu.cn/
分析网站地址,可以得知页面编号由xxtz/x.htm决定,其中x为页面编号,编号为倒序,即最后一页编号为1,共计65,第一页为特殊格式,为xxtz.htm
查看网站源码,本次所需信息相关部分代码如下

可以看到两个所需信息均在div标签中,但所属class类不同,通过这个,可以将这两个属性提取出来。
由于采用requests一直报403错误,本次采用urllib+beautifulsoup
具体代码如下:
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import sys
import urllib
# 表头
csvHeaders = ['日期', '标题']
# 数据
subjects = []
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
def remove_upprintable_chars(s):
#移除所有不可见字符
return ''.join(x for x in s if x.isprintable())
print('信息爬取中:\n')
for pages in tqdm(range(1, 66 +1 )):
url="http://news.cqjtu.edu.cn/xxtz"
if pages == 66:
url =url+".htm"
else:
url = f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm'
req = urllib.request.Request(url, headers=headers)
temp = urllib.request.urlopen(req).read().decode('utf-8')
soup = BeautifulSoup(temp, 'html5lib')
li = soup.find_all('div',class_ ='time')
a = soup.find_all('div',class_ = 'right-title')
subject = []
for i in range(0,len(li)):
if li[i].string is not None:
subject.append(li[i].string)
subject.append(a[i].a.string)
for i in range(0,2):
if subject[i].find('\n') != -1:
subject[i] = subject[i].replace('\n','')
if subject[i].isprintable() == False:
subject[i] = remove_upprintable_chars(subject[i])
subjects.append(subject)
subject = []
# 存放题目
with open('D://myworks//network//JW_news.csv', 'w', newline='',encoding = 'utf-8-sig') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
for i in subjects:
for j in i:
if j.isprintable() == False:
print('xxx')
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
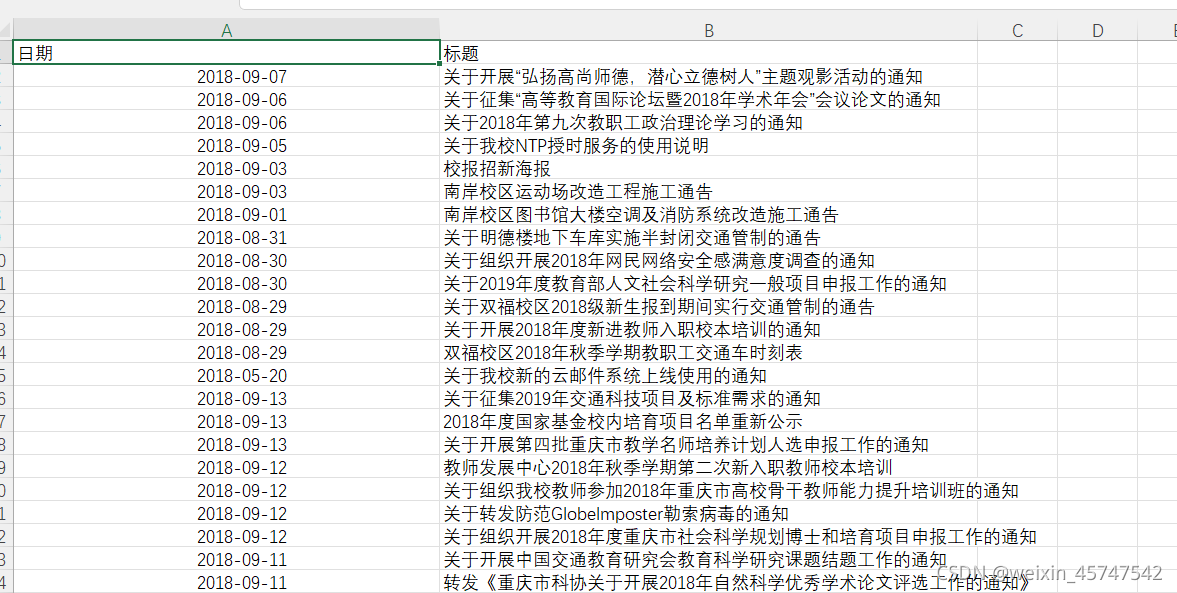
取得数据如下:















 214
214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









