






- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
目录
我的环境
- 语言环境:python3.8.18
- 编译器:jupyter notebook
- 深度学习环境:torch==2.0.1+cu118,torchvision==0.15.2+cu118
一、代码实现
1.导入文件包
import torch.nn.functional as F
import numpy as np
import pandas as pd
import torch
from torch import nn
import os,PIL,pathlib
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"2.导入数据并打印数据
data = pd.read_csv("woodpine2.csv")
data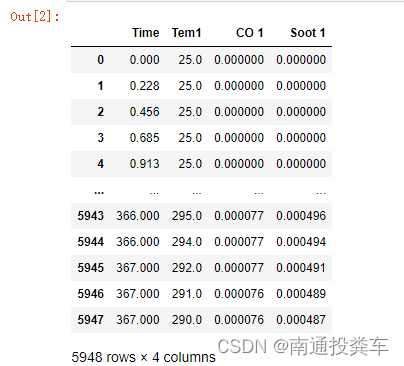
3.数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['savefig.dpi']=500
plt.rcParams['figure.dpi']=500
fig,ax=plt.subplots(1,3,constrained_layout=True,figsize=(14,3))
sns.lineplot(data=data["Tem1"],ax=ax[0])
sns.lineplot(data=data["CO 1"],ax=ax[1])
sns.lineplot(data=data["Soot 1"],ax=ax[2])
plt.show() 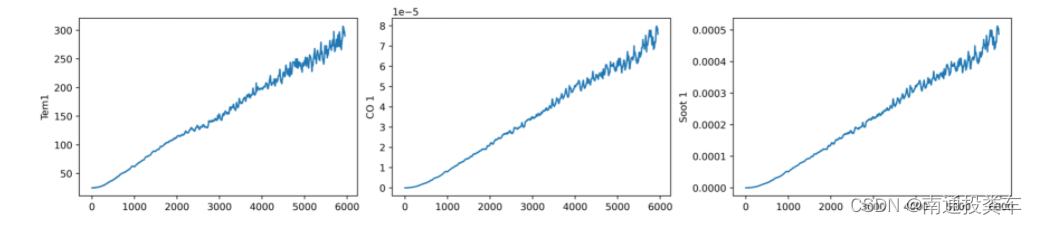
-
import matplotlib.pyplot as plt: 导入matplotlib库中的pyplot模块,并以plt作为别名。matplotlib是一个强大的绘图库,用于创建静态、动态、交互式的可视化图表。 -
import seaborn as sns: 导入seaborn库,并以sns作为别名。seaborn是基于matplotlib的统计图形库,它提供了更高级的接口,用于绘制统计图形,使图形更具吸引力。
3-4. plt.rcParams['savefig.dpi']=500 和 plt.rcParams['figure.dpi']=500: 这两行设置matplotlib的分辨率,savefig.dpi影响保存图像时的分辨率,figure.dpi影响显示图像时的分辨率。这里都设置为500DPI,使得图像更加清晰。
5.fig, ax = plt.subplots(1, 3, constrained_layout=True, figsize=(14, 3)): 创建一个包含1行3列的子图布局。constrained_layout=True 自动调整子图参数,以便子图标签和标题不会重叠。figsize=(14, 3) 设置整个图形的尺寸为宽度14英寸,高度3英寸。
6-8. 分别使用sns.lineplot函数在前面创建的三个子图上绘制数据折线图。
data=data["Tem1"]:在第一个子图(ax[0])上绘制名为"data"的数据框中"Tem1"列的数据。data=data["CO 1"]:在第二个子图(ax[1])上绘制"data"数据框中"CO 1"列的数据。data=data["Soot 1"]:在第三个子图(ax[2])上绘制"data"数据框中"Soot 1"列的数据。9.plt.show(): 显示之前创建的所有图形。这会打开一个窗口展示三条折线图。
4.数据切片
dataFrame = data.iloc[:,1:]
dataFrame 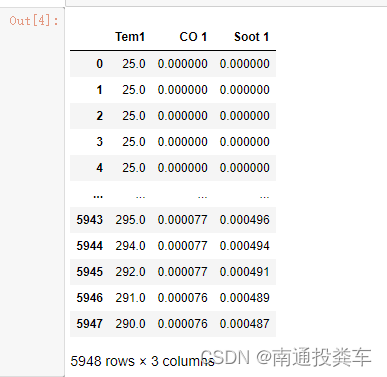
5.归一化处理
from sklearn.preprocessing import MinMaxScaler
dataFrame = data.iloc[:,1:].copy()
sc = MinMaxScaler(feature_range=(0,1))
for i in ['CO 1','Soot 1','Tem1']:
dataFrame[i] = sc.fit_transform(dataFrame[i].values.reshape(-1,1))
dataFrame.shape 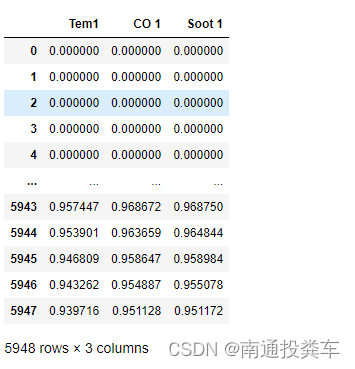
6.划分滑动窗口,设置特征和标签
width_X = 8
width_y = 1
##取前8个时间段的Tem1、CO 1、Soot 1为X,第9个时间段的Tem1为y。
X = []
y = []
in_start = 0
for _, _ in data.iterrows():
in_end = in_start + width_X
out_end = in_end + width_y
if out_end < len(dataFrame):
X_ = np.array(dataFrame.iloc[in_start:in_end , ])
#X_ = X_.reshape((len(X_)*3))
y_ = np.array(dataFrame.iloc[in_end :out_end, 0])
X.append(X_)
y.append(y_)
in_start += 1
X = np.array(X)
y = np.array(y).reshape(-1,1,1)
X.shape, y.shape((5939, 8, 3), (5939, 1, 1))这段代码的目的是从一个DataFrame中提取特征(X)和目标变量(y)以用于时间序列预测或其他机器学习任务。具体而言,它按照以下步骤操作:
1. **初始化参数**:
- `width_X = 8`: 定义了作为特征的输入数据的时间窗口长度,即每个样本包含前8个时间段的数据。
- `width_y = 1`: 定义了输出目标的时间窗口长度,这里为1,意味着我们预测的是第9个时间段的某个值。
2. **初始化空列表** `X` 和 `y`,用于存储特征集和目标变量。
3. **遍历DataFrame的行** 使用`iterrows()`迭代器遍历DataFrame的每一行。对于每一行,执行以下操作:
a. 计算`in_end`为当前处理起始位置加上`width_X`,这是特征提取的结束位置。
b. 计算`out_end`为`in_end`加上`width_y`,这是目标变量对应的结束位置。
c. 检查`out_end`是否小于`dataFrame`的长度,确保不会越界提取数据。
d. 如果条件满足,则从`dataFrame`中提取特征(`X_`)和目标(`y_`):
- 特征`X_`是从`in_start`到`in_end`的所有列数据,形成一个`(width_X, dataFrame的列数)`形状的数组。
- 目标`y_`是单个值,即第`in_end`到`out_end`时间段的"Tem1"列数据,形成一个形状为`(width_y,)`的数组。
e. 将提取的`X_`和`y_`添加到各自的列表`X`和`y`中。
f. 更新`in_start`为下一轮迭代的起始位置。
4. **转换为NumPy数组** 将列表`X`和`y`转换为NumPy数组以便进一步处理。特别是,`y`被重塑为形状`(-1, 1, 1)`,这通常是为了匹配某些机器学习模型(如RNNs)的输入要求。
5. **打印形状** 最后,打印`X`和`y`的形状,展示数据准备的结果。这有助于确认数据是否按预期构造,对于调试和理解数据结构也很重要。
综上所述,这段代码是用来为时间序列分析准备数据的,它将连续时间窗口的数据作为输入特征 (`X`),并试图预测每个窗口之后的某一个时间点(这里是第9个时间段的"Tem1"值)作为目标变量 (`y`)。
7.划分训练集和测试集
X_train = torch.tensor(np.array(X[:5000]), dtype=torch.float32)
y_train = torch.tensor(np.array(y[:5000]), dtype=torch.float32)
X_test = torch.tensor(np.array(X[5000:]), dtype=torch.float32)
y_test = torch.tensor(np.array(y[5000:]), dtype=torch.float32)
X_train.shapetorch.Size([5000, 8, 3])9.加载数据集
from torch.utils.data import TensorDataset,DataLoader
train_dl = DataLoader(TensorDataset(X_train, y_train),batch_size=64, shuffle=False)
test_dl = DataLoader(TensorDataset(X_test, y_test),batch_size=64, shuffle=False)10.定义模型
class model_lstm(nn.Module):
def __init__(self):
super(model_lstm, self).__init__()
self.lstm0 = nn.LSTM(input_size=3 ,hidden_size=320, num_layers=1, batch_first=True)
self.lstm1 = nn.LSTM(input_size=320 ,hidden_size=320, num_layers=1, batch_first=True)
self.fc0 = nn.Linear(320,1)
def forward(self, x):
#h_0 = torch.randn(1, x.size(0), 64) #num_layers * num_directions(单向/双向), bs,hidden_size
#c_0 = torch.randn(1, x.size(0), 64) #num_layers * num_directions(单向/双向), bs,hidden_size
#如果不传入h0和c0,pytorch会将其初始化为0
out, hidden1 = self.lstm0(x)
out, _ = self.lstm1(out, hidden1)
out = self.fc0(out)
return out[:, -1:, :] #取2个预测值,否则经过lstm会得到8*2个预测
model = model_lstm()
#model.apply(init_weight)
model

11.定义训练函数和测试函数
#设置GPU训练
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 训练循环
import copy
def train(train_dl, model, loss_fn, opt, lr_scheduler=None):
size = len(train_dl.dataset)
num_batches = len(train_dl)
train_loss = 0 # 初始化训练损失和正确率
for x, y in train_dl:
x, y = x.to(device), y.to(device)
# 计算预测误差
#pred = model(x)
pred = model(x) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距
# 反向传播
opt.zero_grad() # grad属性归零
loss.backward() # 反向传播
opt.step() # 每一步自动更新
# 记录loss
train_loss += loss.item()
if lr_scheduler is not None:
lr_scheduler.step()
print("learning rate = ", opt.param_groups[0]['lr'])
train_loss /= num_batches
return train_loss
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目
test_loss = 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
# 计算loss
y_pred = model(x)
loss = loss_fn(y_pred, y)
test_loss += loss.item()
test_loss /= num_batches
return test_loss12.开始训练
#训练模型
model = model_lstm()
model = model.to(device)
loss_fn = nn.MSELoss() # 创建损失函数
learn_rate = 1e-1 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate,weight_decay=1e-4)
epochs = 150
train_loss = []
test_loss = []
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt,epochs, last_epoch=-1)
best_val =[0, 1e5]
for epoch in range(epochs):
model.train()
epoch_train_loss = train(train_dl, model, loss_fn, opt, lr_scheduler)
model.eval()
epoch_test_loss = test(test_dl, model, loss_fn)
if best_val[1] > epoch_test_loss:
best_val =[epoch, epoch_test_loss]
best_model_wst = copy.deepcopy(model.state_dict())
train_loss.append(epoch_train_loss)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_loss:{:.6f}, Test_loss:{:.6f}')
print(template.format(epoch+1, epoch_train_loss, epoch_test_loss))
print("*"*20, 'Done', "*"*20)
#print("best_train= ", best_train)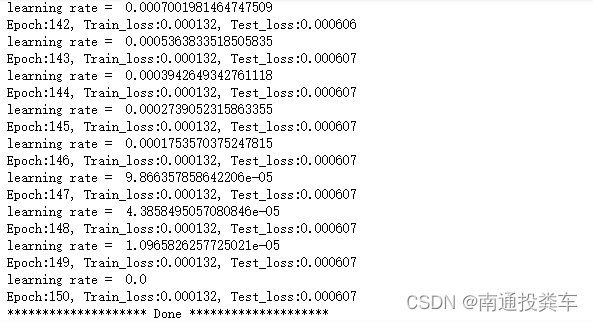
13.Loss图
#LOSS图
# 支持中文
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(5, 3),dpi=120)
plt.plot(train_loss , label='LSTM Training Loss')
plt.plot(test_loss, label='LSTM Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()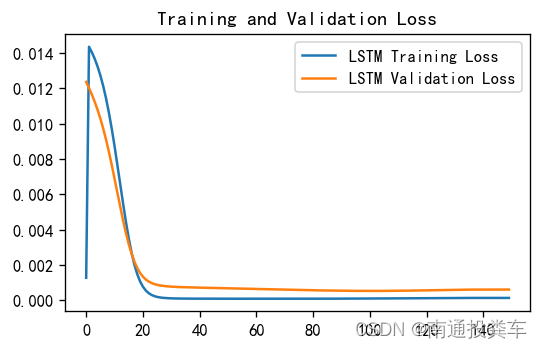
14.调用模型预测
model.load_state_dict(best_model_wst)
model.to("cpu")
predicted_y_lstm = sc.inverse_transform(model(X_test).detach().numpy().reshape(-1,1)) # 测试集输入模型进行预测
y_test_1 = sc.inverse_transform(y_test.reshape(-1,1))
y_test_one = [i[0] for i in y_test_1]
predicted_y_lstm_one = [i[0] for i in predicted_y_lstm]
plt.figure(figsize=(5, 3),dpi=120)
# 画出真实数据和预测数据的对比曲线
plt.plot(y_test_one[:2000], color='red', label='real_temp')
plt.plot(predicted_y_lstm_one[:2000], color='blue', label='prediction')
plt.title('Title')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show() 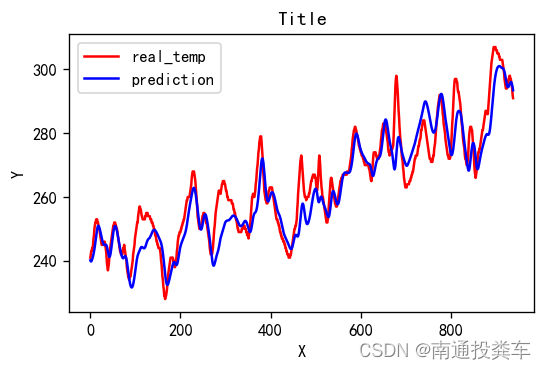
15.R2值评估
from sklearn import metrics
"""
RMSE :均方根误差 -----> 对均方误差开方
R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量
"""
RMSE_lstm = metrics.mean_squared_error(predicted_y_lstm_one, y_test_1)**0.5
R2_lstm = metrics.r2_score(predicted_y_lstm_one, y_test_1)
print('均方根误差: %.5f' % RMSE_lstm)
print('R2: %.5f' % R2_lstm)均方根误差: 6.52872
R2: 0.84910二、个人总结
本周撰写了LSTM的代码,之前对数据维度变化方面有所疑惑,还有前向传播是一些参数设置的疑惑,今天全部都解决了。















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









